In January, we presented Lesson 1 in model-data comparison: if you are comparing noisy data to a model trend, make sure you have enough data for them to show a statistically significant trend. This was in response to a graph by Roger Pielke Jr. presented in the New York Times Tierney Lab Blog that compared observations to IPCC projections over an 8-year period. We showed that this period is too short for a meaningful trend comparison.
This week, the story has taken a curious new twist. In a letter published in Nature Geoscience, Pielke presents such a comparison for a longer period, 1990-2007 (see Figure). Lesson 1 learned – 17 years is sufficient. In fact, the very first figure of last year’s IPCC report presents almost the same comparison (see second Figure).
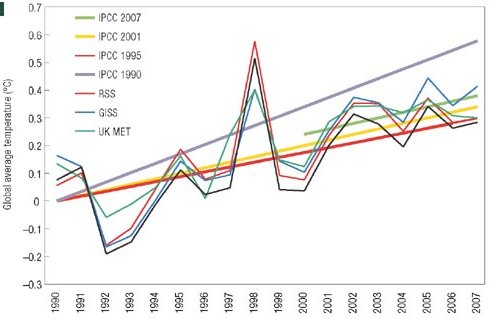
Pielke’s comparison of temperature scenarios of the four IPCC reports with data
There is a crucial difference, though, and this brings us to Lesson 2. The IPCC has always published ranges of future scenarios, rather than a single one, to cover uncertainties both in future climate forcing and in climate response. This is reflected in the IPCC graph below, and likewise in the earlier comparison by Rahmstorf et al. 2007 in Science.

IPCC Figure 1.1 – comparison of temperature scenarios of three IPCC reports with data
Any meaningful validation of a model with data must account for this stated uncertainty. If a theoretical model predicts that the acceleration of gravity in a given location should be 9.84 +- 0.05 m/s2, then the observed value of g = 9.81 m/s2 would support this model. However, a model predicting g = 9.84+-0.01 would be falsified by the observation. The difference is all in the stated uncertainty. A model predicting g = 9.84, without any stated uncertainty, could neither be supported nor falsified by the observation, and the comparison would not be meaningful.
Pielke compares single scenarios of IPCC, without mentioning the uncertainty range. He describes the scenarios he selected as IPCC’s “best estimate for the realised emissions scenario”. However, even given a particular emission scenario, IPCC has always allowed for a wide uncertainty range. Likewise for sea level (not shown here), Pielke just shows a single line for each scenario, as if there wasn’t a large uncertainty in sea level projections. Over the short time scales considered, the model uncertainty is larger than the uncertainty coming from the choice of emission scenario; for sea level it completely dominates the uncertainty (see e.g. the graphs in our Science paper). A comparison just with the “best estimate” without uncertainty range is not useful for “forecast verification”, the stated goal of Pielke’s letter. This is Lesson 2.
In addition, it is unclear what Pielke means by “realised emissions scenario” for the first IPCC report, which included only greenhouse gases and not aerosols in the forcing. Is such a “greenhouse gas only” scenario one that has been “realised” in the real world, and thus can be compared to data? A scenario only illustrates the climatic effect of the specified forcing – this is why it is called a scenario, not a forecast. To be sure, the first IPCC report did talk about “prediction” – in many respects the first report was not nearly as sophisticated as the more recent ones, including in its terminology. But this is no excuse for Pielke, almost twenty years down the track, to talk about “forecast” and “prediction” when he is referring to scenarios. A scenario tells us something like: “emitting this much CO2 would cause that much warming by 2050”. If in the 2040s the Earth gets hit by a meteorite shower and dramatically cools, or if humanity has installed mirrors in space to prevent the warming, then the above scenario was not wrong (the calculations may have been perfectly accurate). It has merely become obsolete, and it cannot be verified or falsified by observed data, because the observed data have become dominated by other effects not included in the scenario. In the same way, a “greenhouse gas only” scenario cannot be verified by observed data, because the real climate system has evolved under both greenhouse gas and aerosol forcing.
Pielke concludes: “Once published, projections should not be forgotten but should be rigorously compared with evolving observations.” We fully agree with that, and IPCC last year presented a more convincing (though not perfect) comparison than Pielke.
To sum up the three main points of this post:
1. IPCC already showed a very similar comparison as Pielke does, but including uncertainty ranges.
2. If a model-data comparison is done, it has to account for the uncertainty ranges – both in the data (that was Lesson 1 re noisy data) and in the model (that’s Lesson 2).
3. One should not mix up a scenario with a forecast – I cannot easily compare a scenario for the effects of greenhouse gases alone with observed data, because I cannot easily isolate the effect of the greenhouse gases in these data, given that other forcings are also at play in the real world.
Tom Watson, Remember: it is climate CHANGE. Look what is changing–and it ain’t water. Anthropogenic causation HAS BEEN proven. You just haven’t bothered to read the papers. Please do so.
Dear Hank Roberts Re: 349
First, I literally draft on and off line simultaneously. http://toms.homeip.net/global_warming/what-the-hell-is-air.html#349.
After creating a post, I cut and paste into the forum and preview. Often seeing the new preview format makes some of my error appear.
As to the word salad, I had no knowledge of the possible laser biomedical term uses. I also still consider my description a reasonable universal laymen terms visualization.
To me it is self explicit. But all have there own opinion that is, I say with a friendly smile, inferior to mine.
Dear Phil. Felton Re 350
I agree concentration is not the signal. I believe or I am not aware of any contradiction of the idea that CO2 and H20 absorb photon in any different way. The only difference is the wavelength of the particular photons absorbed. Also CO2 and H20 do have the ability to absorb photons of the same wavelength. I do not know how to express the metrics of what angles of orientation an interception of a particular wavelength photon must possess to assure absorption some other redirection or no interaction. I guess or proffer that for some wavelengths the width or “scope of interception” are larger and thus absorption is more likely.
From the properties as I have described above I proffer that the sum of number of absorbing targets weighted by it’s “scope of interception” is proportional to the probability of absorbing a particular photon.
For a specific photon wavelength H2O and CO2 can be assigned a probability number from it’s NIST or other transmission graph.
From this the possibility of absorption is the sum of the number of CO2 molecules times it’s NIST probability This is also true for H20.
From this it seems to me that in the path of a photon the probability of meeting CO2 or H20 is a function of the number in PPM.
From this the probability of a being absorbed is a function of sum of probabilities for each for that path.
All photons will likely intercept 10, 20, 50, H20 (the variation of humidity) for every CO2 at 260 or 460 PPM
This addresses the CO2 only or mostly photons. This does not even consider that H20 can absorb a far greater percentage of all photon in the black body spectrum of earth temperatures.
The H20 signal is the sum of all it alone absorbs and all it absorbs that CO2 might absorb if it every sees it.
To me the amplitude of the signal is a function of the total population C02 + H20 vs the ppm population change of CO2.
Gain has been mentioned. I do not see in my understanding of what absorption is to introduce a gain function.
Now I do not claim I have a perfect or totally correct understanding of absorption. But I have not seen any convincing explanations that contradict or confirm with certainty I have the correct understanding.
MODTRAN… I am looking now, but a specific pointer through all the weeds of the internet would be helpful.
.. superimposed graphs of a known concentration of CO2 with an unknown (but high) concentration of H2O, secondly you plotted the graph over too large a range of cm-1 (no point in anything over 2000 cm-1)…
Do you know the concentration of CO2 and H20? Even relative, high is not quantitative. And h20 at 2% or 20,000 PPM is high compared to CO2 386 PPM, but realistic.
I used the graphs that NIST makes available.
I also believe the the NIST graphs I used do take into account the black body radiation spectrum of earth’s temperature.
I have collected all kinds of plots of absorption at http://e6.ath.cx/gw/
http://e6.ath.cx/gw/absorbspec.jpg
http://e6.ath.cx/gw/Atmospheric_Transmission-sm.jpg
http://e6.ath.cx/gw/AtmosphericAbsorption-n-Transmission.jpg
http://e6.ath.cx/gw/chriscolose.h20.co2.absorption.gif
http://e6.ath.cx/gw/earth-emisson-spectrum.jpg
http://e6.ath.cx/gw/IR-SPEC.GIF
http://e6.ath.cx/gw/TerrestrialRadiation-energy_wavelength.gif
[Response: Watson, just give up. You’re going around in circles and not scoring any points. The absorption data you’re showing in the graphs is just the same stuff GCM radiation codes are based on. These codes explicitly model the degree of overlap between water vapor and CO2, taking into account the fact that water vapor decreases with height whereas CO2 does not (to a radiatively significant extent). The radiation codes still give a strong radiative forcing from doubling of CO2, and when embedded in a model that simulates the full hydrological cycle, gives a substantial warming. If you really want to learn something about CO2 vs. water vapor radiative effects, look at (a) Gavin’s RC article on “Water vapor: Feedback or Forcing?”; my chapter in the Princeton University Press general circulation volume (Schneider and Sobel, eds); Chapter 4 of my planetary climate textbook (available online through my web site). You are not allowing yourself to be educated by the astute remarks of the various commenters who have set you straight. You are just trying to re-invent radiative transfere modelling, but doing it in words without mathematics, and you are making a dog’s breakfast of it. If you want to argue about water vapor feedback, that’s one thing, but to argue against AGW on the basis of CO2/H2O overlap is just alchemy and I won’t let this go on forever. –raypierre]
I heartily endorse Raypierre’s remarks, while you profess to want to learn all you’re doing is arguing with the experts who’re trying to help you, at the same time revealing your lack of knowledge!
Some examples:
“The only difference is the wavelength of the particular photons absorbed. Also CO2 and H20 do have the ability to absorb photons of the same wavelength.”
Not true, linewidths and absorption cross-sections for example.
“Do you know the concentration of CO2 and H20?”
I read the data on the NIST pages that you took the graphs from!
Depending on which of the CO2 graphs you used the concentration is either:
‘Notice: Concentration information is not available for this spectrum and, therefore, molar absorptivity values cannot be derived.’
or:
‘GAS (200 mmHg DILUTED TO A TOTAL PRESSURE OF 600 mmHg WITH N2)’
And for the H2O graph you used:
‘Notice: Concentration information is not available for this spectrum and, therefore, molar absorptivity values cannot be derived.’
Which render the comparison you attempt to make with your graph totally meaningless.
“To me the amplitude of the signal is a function of the total population C02 + H20 vs the ppm population change of CO2.”
Figure 11 in this page of yours illustrates the error of your statements if you had the wit to see it!
http://e6.ath.cx/gw/IR-SPEC.GIF
As a public service, I have extended the research in #290, as this thread may become a classic for students of blogging behavior:
Of 354 posts so far, 94 (27% of the total):
43 are by Tom Watson
51 are by others replying to Tom Watson
Of the *last* 65 posts 47 (72%):
21 by Tom Watson
26 by others replying to Tom Watson
I suspect the word percentages are higher. I may have missed a few.
So, back to the topic then?
Re #355 John Mashey:
I am tempted to refer to the history of operations research, like described in
http://en.wikipedia.org/wiki/Operations_research
especially the part about Blackett and armouring RAF bombers. There are a few other examples (cannot find the links now) of such counter-intuitive results: What you see is not all there is!
That the Tom Watsons of the world are immune to learning doesn’t establish that those reading over his shoulders are :-)
Tom,
I also find your arguments unconvincing and circular, but don’t ‘give up’ altogether. Every brilliant scientist is first and foremost a skeptic. Having said that, the first rule of skepticisim is to question your own ideas more rigoursly than you question the ideas of others.
I highly recommend Carl Sagan’s book The Demon Haunted World, it expands on the notion of skepticism in science and everyday life in far more eloquent prose than I am capable of.
Just eyeballing fig 1.1, it seems like Pielke is right that forecast reliability has not improved since 1990. I see that 7 of the 16 data points fall in the FAR error range while only 2 and 1 are in the ranges of the TAR and SAR forecasts resp. Assuming the error bars are 1 std dev, SAR/TAR should be rejected with very, very high confidence. Taking FAR as the hypothesis, there’s only a ~4% chance 7 or fewer would fall in range so it too is very suspect.
Ed, I would be careful assuming that things are distributed normally. When it comes to noise on global mean temperature, I’d guess that’s a lousy assumption. What I take away from the chart is that FAR is a reasonable bounding estimate, while the other two projections are conservative–not surprising given that the models probably do not have all the positive feedbacks included.
And in any case, since the data are not a fit to the temperature, the right thing to do is put in the forcings at their best constrained values and look for the missing feedbacks. I don’t think Pielke’s way of looking at the problem is particularly fruitful.
(Y+e)=m*(x+e1)+m2*x2+m3*x3 ….*mq*xq +e2
Where e, e1, and e2 are probably not independent and m2…mq artificially restricted to zero being estimated be least squares is a little silly. Even if your estimator had any statistical properties (which it does not), you are using the wrong approach. There are direct methods to test the change in slope. Which, in this case, does flatten out significantly 2001-2007.
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.674e+01 8.215e+00 -3.255 0.00324 **
year 1.361e-02 4.128e-03 3.296 0.00293 **
yearswitch 7.201e-05 3.843e-05 1.874 0.07268 .
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ‘ 1
Residual standard error: 0.1166 on 25 degrees of freedom
Multiple R-Squared: 0.6842, Adjusted R-squared: 0.6589
F-statistic: 27.08 on 2 and 25 DF, p-value: 5.527e-07
Hypothesis:
year – yearswtich = 0
Model 1: anom ~ year + yearswtich
Model 2: restricted model
Res.Df RSS Df Sum of Sq F Pr(>F)
1 25 0.33977
2 26 0.48383 -1 -0.14406 10.600 0.003241 **
—
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ‘ 1
I do not under any circumstances place any confidence the above results because all of the variables have unsubstantial measurement error. If you cannot figure out why year is measured with error in a climate model immediately, just have a beer and think on it.
Maybe someone can answer this and it will help with people deciding WHY 7 years (or whatever) is too short for climate.
Globally (well, hemipsherically, really), how many years does it take to work out when summer arrives and leaves.
you’d have to say something like “summer is when the maximum daily temperature rises above 25degrees” to define your beginning of summer. Then work out how many years it would take to get a “summer” date to the nearest day.
My thought is that it would take at least 10 days to figure it out with a one-day error bar based on historical records. Maybe longer if the weather is for some years very unstable.
But does anyone have a better answer, based on historical records.
The point of this is that if you can’t tell when *summer* is, how can you tell whether summer is getting hotter/colder or longer/shorter (which is the change in climate)?
Mark, just look up the definition that is being used in the particular study; keep it consistent to study a trend.
Just one example:
http://www3.interscience.wiley.com/journal/109062129/abstract?CRETRY=1&SRETRY=0
—–
On the models-and-observations issue, this from the end of 2007 in the IEEE journal is interesting:
http://csdl2.computer.org/persagen/DLAbsToc.jsp?resourcePath=/dl/mags/cs/&toc=comp/mags/cs/2007/06/mcs06toc.xml&DOI=10.1109/MCSE.2007.125
DOI Bookmark: http://doi.ieeecomputersociety.org/10.1109/MCSE.2007.125
Abstract
Models help researchers understand past and present states as well as predict scenarios of environmental change in the Arctic. The authors analyze results on melting sea ice from a regional coupled ice-ocean model and demonstrate their robustness independent of timescales for surface temperature and salinity relaxation.