What is the actual hypothesis you are testing when you compare a model to an observation? It is not a simple as ‘is the model any good’ – though many casual readers might assume so. Instead, it is a test of a whole set of assumptions that went into building the model, the forces driving it, and the assumptions that went in to what is presented as the observations. A mismatch between them can arise from a mis-specification of any of these components and climate science is full of examples where reported mismatches ended up being due to problems in the observations or forcing functions rather than the models (ice age tropical ocean temperatures, the MSU records etc.). Conversely of course, there are clear cases where the models are wrong (the double ITCZ problem) and where the search for which assumptions in the model are responsible is ongoing.
As we have discussed, there is a skill required in comparing models to observations in ways that are most productive, and that requires a certain familiarity with the history of climate and weather models. For instance, it is well known that the individual trajectory of the weather is chaotic (in models this is provable; in the real world, just very likely) and unpredictable after a couple of weeks. So comparing the real weather at a point with a model simulation outside of a weather forecast context is not going to be useful. You can see this by specifying exactly what the hypothesis is you are testing in performing such a comparison in a climate model – i.e. “is a model’s individual weather correlated to the weather in the real world (given the assumptions of the model and no input of actual weather data)”. There will be a mismatch between model and observation, but nothing of interest will have been learnt because we already know that the weather in the model is chaotic.
Hypotheses are much more useful if you expect that there will be a match; a mismatch is then much more surprising. Your expectations are driven by past experience and are informed by a basic understanding of the physics. For instance, given the physics of sulphate aerosols in the stratosphere (short wave reflectors, long wave absorbers), it would be surprising if putting in the aerosols seen during the Pinatubo eruption did not reduce the planetary temperature while warming the stratosphere in the model. Which it does. Doing such an experiments is much more a test of the quantitative impacts then, rather than the qualitative response.
With that in mind, I now turn to the latest paper that is getting the inactivists excited by Demetris Koutsoyiannis and colleagues. There are very clearly two parts to this paper – the first is a poor summary of the practice of climate modelling – touching all the recent contrarian talking points (global cooling, Douglass et al, Karl Popper etc.) but is not worth dealing with in detail (the reviewers of the paper include Willie Soon, Pat Frank and Larry Gould (of Monckton/APS fame) – so no guessing needed for where they get their misconceptions). This is however just a distraction (though I’d recommend to the authors to leave out this kind of nonsense in future if they want to be taken seriously in the wider field). The second part is their actual analysis, the results of which lead them to conclude that “models perform poorly”, and is more interesting in conception, if not in execution.
Koutsoyiannis and his colleagues are hydrologists by background and have an interest in what is called long term persistence (LTP or long term memory) in time series (discussed previously here). This is often quantified by the Hurst parameter (nicely explained by tamino recently). A Hurst value of greater than 0.5 is indicative of ‘long range persistence’ and complicates issues of calculating trend uncertainties and the like. Many natural time series do show more persistent ‘memory’ than a simple auto-regression (AR) process – in particularly (and classically) river outflows. This makes physical sense because a watershed is much more complicated than just a damper of higher frequency inputs. Soil moisture can have an impact from year to year, as can various groundwater reservoirs and their interactions.
It’s important to realise that there is nothing magic about processes with long term persistence. This is simply a property that complex systems – like the climate – will exhibit in certain circumstances. However, like all statistical models that do not reflect the real underlying physics of a situation, assuming a form of LTP – a constant Hurst parameter for instance, is simply an assumption that may or may not be useful. Much more interesting is whether there is a match between the kinds of statistical properties seen in the real world and what is seen in the models (see below).
So what did Koutsoyiannis et al do? They took a small number of long station records and compared them to co-located grid points in single realisations of a few models and correlate their annual and longer term means. Returning to the question we asked at the top, what hypothesis is being tested here? They are using single realisations of model runs, and so they are not testing the forced component of the response (which can only be determined using ensembles or very long simulations). By correlating at the annual and other short term periods they are effectively comparing the weather in the real world with that in a model. Even without looking at their results, it is obvious that this is not going to match (since weather is uncorrelated in one realisation to another, let alone in the real world). Furthermore, by using only one to four grid boxes for their comparisons, even the longer term (30 year) forced trends are not going to come out of the noise.
Remember that the magnitude of annual, interannual and decadal variability increases substantially as spatial scales go from global, hemispheric, continental, regional to local. The IPCC report for instance is very clear in stating that the detection and attribution of climate changes is only clearly possible at continental scales and above. Note also that K et al compare absolute temperatures rather than anomalies. This isn’t a terrible idea, but single grid points have offsets to a co-located station for any number of reasons – mean altitude, un-resolved micro-climate effects, systematic but stable biases in planetary wave patterns etc. – and anomaly comparison are generally preferred since they can correct for these oft-times irrelevant effects. Finally (and surprisingly given the attention being paid to it in various circles), K et al do not consider whether any of their selected stations might have any artifacts within them that might effect their statistical properties.
Therefore, it comes as no surprise at all that K and colleagues find poor matches in their comparisons. The answer to their effective question – are very local single realisations of weather coherent across observations and models? – is no, as anyone would have concluded from reading the IPCC report or the existing literature. This is why no one uses (or should be using) single grid points from single models in any kind of future impact study. Indeed, it is the reason why regional downscaling approaches exist at all. The most effective downscaling approaches use the statistical correlations of local weather to larger scale patterns and use model projections for those patterns to estimate changes in local weather regimes. Alternatively, one can use a regional model embedded within a global model. Either way, no-one uses single grid boxes.
What might K et al have done that would have been more interesting and still relevant to their stated concerns? Well, as we stated above, comparing statistical properties in the models to the real world is very relevant. Do the models exhibit LTP? Is there spatial structure to the derived Hurst coefficients? What is the predictability of Hurst at single grid boxes even within models? Of course, some work has already been done on this.
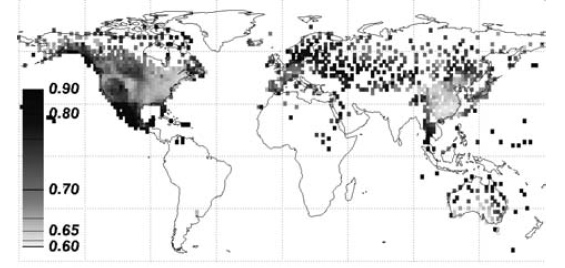 For instance, Kiraly et al (2006, Tellus) calculated Hurst exponents for the entire database of weather stations and show that there is indeed significant structure (and some uncertainty in the estimates) in different climate regimes. In the US, there is a clear difference between the West Coast, Mountain States, and Eastern half. Areas downstream of the North Atlantic appear to have particular high Hurst values.
For instance, Kiraly et al (2006, Tellus) calculated Hurst exponents for the entire database of weather stations and show that there is indeed significant structure (and some uncertainty in the estimates) in different climate regimes. In the US, there is a clear difference between the West Coast, Mountain States, and Eastern half. Areas downstream of the North Atlantic appear to have particular high Hurst values.
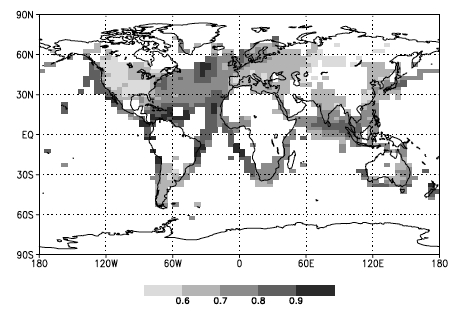 Other analyses show similar patterns (in this case, from Fraedrich and Blender (2003) who used the gridded datasets from 1900 onwards), though there is enough differences with the first picture that it’s probably worth investigating methodological issues in these calculations. What do you get in models? Well in very long simulations that provide enough data to estimate Hurst exponents quite accurately, the answer is mostly something similar.
Other analyses show similar patterns (in this case, from Fraedrich and Blender (2003) who used the gridded datasets from 1900 onwards), though there is enough differences with the first picture that it’s probably worth investigating methodological issues in these calculations. What do you get in models? Well in very long simulations that provide enough data to estimate Hurst exponents quite accurately, the answer is mostly something similar.
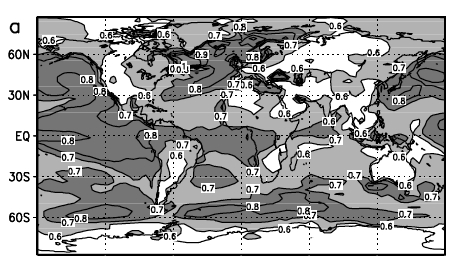 The precise patterns do vary as a function of frequency ranges (i.e. the exponents in the interannual to multi-decadal band are different to those over longer periods), and there are differences between models. This is one example from Blender et al (2006, GRL) which shows the basic pattern though. Very high Hurst exponents over the parts of the ocean with known multi-decadal variability (North Atlantic for instance), and smaller values over land.
The precise patterns do vary as a function of frequency ranges (i.e. the exponents in the interannual to multi-decadal band are different to those over longer periods), and there are differences between models. This is one example from Blender et al (2006, GRL) which shows the basic pattern though. Very high Hurst exponents over the parts of the ocean with known multi-decadal variability (North Atlantic for instance), and smaller values over land.
However, I’m not aware of any analyses of these issues for models in the AR4 database, and so that would certainly be an interesting study. Given the short period of the records are the observational estimates of the Hurst exponents stable enough to be used as a test for the models? Do the models suggest that 100-year estimates of these parameters are robust? (this is testable using different realisations in an ensemble). Are there sufficient differences between the models to allow us to say something about the realism of their multi-decadal variability?
Answering any of these questions would have moved the science forward – it’s a shame Koutsoyiannis et al addressed a question whose answer was obvious and well known ahead of time instead.
Thank you for the review.
Given the strength of the Hurst coefficients – something we all agree on – is it not possible that a large portion of the current warming trend is a product of internal climate variability, as mediated by complex dynamics of ocean circulation? I want to understand better how it is you decide that GHGs are responsible for a deterministic forced trend when you have this powerful but poorly understood stochastic noise rocess operating in the background. How do you estimate the precision of your forcings when the background noise is so poorly understood?
How well do the GCMs perform at generating suitably high Hurst coefficients?
Estimating the Hurst parameter from observed data is very tricky business. Clegg concludes that
Essentially, Clegg finds that it’s hard to estimate the Hurst parameter even for artificial time series where the answer is known ahead of time, even when working with 100,000 data points.
And if the estimates are made from monthly data, then a century of observations gives us only 1200 data points. For accuractly pinning down the Hurst parameter, that can only be called a pittance. Even using daily data, a century only gives 36,525 data points, which frankly is not a lot. If the process is anything other than pure LRD (e.g. corrupted with AR1 or other noise), then an already difficult task is made immensely more so. And if the time series is not stationary, then if the detrending isn’t just right — well, all bets are off.
So even though I haven’t looked at Kiraly et al. (2006) or Fraedrich and Blender (2003), let alone given them careful study, I have to admit I’m skeptical. They would have to have been extraordinarily thorough and extraordinarily careful in order to get meaningful results. This is not to say they weren’t — just that extreme caution is in order. As for Koutsoyiannis et al. (2008), what you’ve told us of their research convinces me that it’s not worth careful study.
It is worth noting that LRD has less impact on trend analysis than it does on, say, estimating the series mean. This is due to the impact of autocorrelation on trend analysis (which was one of the subjects of my post). Increasing the Hurst parameter always makes averages more uncertain, but beyond a certain point it actually makes trends less uncertain.
So, you’re saying that places with a high Hurst coefficient are more likely to have lasting anomalies – e.g. multi-year droughts or multi-year seasonal flooding? While places with a low Hurst coefficient tend to regress to their “normal” weather patterns faster?
And you’re pointing out that it’s a reasonable test of a model to ask if the spatial distribution of Hurst coefficients it predicts resemble observed values to date, if the observed data set is sufficient. If I’ve understood that right, I’d agree that it’s a clever and useful test of the models.
You’re *not* saying that the models are good enough to predict changes in the spatial distribution of Hurst coefficients, right? I suppose a good model could do so, but wouldn’t have to because it would be possible to have all sorts of significant AGW effects without any change to Hurst coefficients over time. Is there any suspicion that Hurst coefficients will change or are changing? From the nature of the definition, I imagine you’d need a really long, detailed data set to say.
Gavin, you give a couple of parenthetical references, but don’t give the full citation at the end. Is this an oversight or an exercise for the reader?
What is perfectly clear is that the average bloke with an IQ of 100 and a high school education is 100% lost in this discussion. They have no way of understanding any part of it, no idea who is telling the truth and no time or money to go to school. To rephrase the song: “Only their extinction will tell.” If we actually deserved the name “Homo Sapiens,” they would know who to trust, at least.
It’s kind of a sinking feeling.:
I have to get off of this planet. I have to get off of this planet. I have to get off of this planet.
RE: #1
I think that Richard Sycamore has asked some key questions – “is it not possible that a large portion of the current warming trend is a product of internal climate variability” and “how it is you decide that GHGs are responsible for a deterministic forced trend”. I suspect these are the questions that would be at the root of any doubts about the validity climate models. It would be very helpful if Gavin or someone else could have a serious go at answering them.
Re: #1 (Richard Sycamore)
Neither Kiraly et al. (2006) nor Fraedrich & Blender (2003) establish LRD in temperature time series. They find it in the fluctuations of daily temperature. Furthermore, the methods they use remove the long-term trend from the data, so the temperature trend is already gone by the time they find LRD in the fluctuations. Fraedrich & Blender find persistence up to decades, Kiraly et al. find persistence lasting several years, so even if their analysis applied to temperature time series (which it doesn’t) rather than fluctuations (which it does), those time scales aren’t long enough to explain the trend on a century time scale in observed temperature time series. Fraedrich & Blender did find long-range persistence on century time scales, but only for fluctuations (not for temperature), and only in the output of computer model runs.
Edward Greisch wrote in 2:
… better than the “skeptic” mantra:
… I suppose.
Off on a tangent: question about the ITCZ:
Why is their a double ITCZ (in the Western Pacific, right?)? Is it due to equatorial upwelling? Does anyone know why models have trouble with it? Actually, I vaguely recall seeing a model map that showed the double ITCZ – or maybe I was mistaken?
Why is the ITCZ at other latitudes generally displaced northward from the equator in the annual average? (I think I read once that it was because greater water area south of the equator allows the trade winds to blow relatively more unimpeded, thus pushing the ITCZ north a bit.)
If the Hadley cells are to expand polewards with global warming, does that mean the ITCZ will have greater seasonal shifting, and is that an opportunity for greater interannual variability?
With the greatest warming in the tropics generally being in the mid-to-upper troposphere, does that mean the level of non-divergence in the Hadley cell will rise?
Should the Hadley cell, monsoons, and Walker circulation be expected to increase in strength due to greater water vapor concentrations (except where aerosol emissions throw a wrench into it)? Would that amplify the low-frequency variability due to SST anomalies?
“Why is the ITCZ at other latitudes generally displaced northward”
Sorry, I meant “at other longitudes”…
“With the greatest warming in the tropics generally being in the mid-to-upper troposphere, does that mean the level of non-divergence in the Hadley cell will rise?”
Perhaps I should explain what I was thinking there: it isn’t just that the lapse rate decreases in the tropics, but that it decreases more – the meridional horizontal temperature gradient GENERALLY will decrease in the lower troposphere but will GENERALLY increase in the upper troposphere. One might expect the weaker gradient at lower levels to cause the Hadley cells to weaken or become less organized?? (before accounting for increased water vapor), but with the greater warming at upper levels, … etc. Hence the question.
Please see:
1) Marković, D., and M. Koch, 2005. Sensitivity of Hurst parameter estimation to periodic signals in time series and filtering approaches. Geophys. Res. Lett., 32, L17401, doi:10.1029/2005GL024069, September 3, 2005
“…. In summary, our results imply that the first step in a time series long-correlation study should be the separation of the deterministic components from the stochastic ones. Otherwise wrong conclusions concerning possible memory effects may be drawn.”
2) Hamed, Khaled H., 2007. Improved finite-sample Hurst exponent estimates using rescaled range analysis. Water Resour. Res., 43, W04413, doi:10.1029/2006WR005111, April 10, 2007
“Rescaled range analysis is one of the classical methods used for detecting and quantifying long-term dependence in time series. However, rescaled range analysis has been shown in several studies to give biased estimates of the Hurst exponent in finite samples…The application of the proposed modified rescaled range estimator to a group of temperature, rainfall, river flow, and tree-ring time series in the Midwest USA demonstrates the extent to which classical rescaled range analysis can give misleading results. ”
Well, wrong conclusions….temperature and tree-rings included.
Re #4 where # S. Molnar Says:
Not specifying to which references you allude makes the exercise even more challenging, and I could not resist :-)
Kiraly et al (2006, Tellus) is easily found using Gogle at http://www3.interscience.wiley.com/journal/118587932/abstract?CRETRY=1&SRETRY=0
Blender et al (2006, GRL)required Altavista givng the full reference as Blender, R., K. Fraedrich, and B. Hunt, 2006: Millennial climate variability: GCM-simulation and Greenland ice cores. Geophysical Research Letters, 33, L04710, 10.1029/2005GL024919. The PDF file can be found at http://www.mi.uni-hamburg.de/fileadmin/files/forschung/theomet/docs/pdf/BleFraHuntMill05.pdf .
HTH,
Cheers, Alastair.
The comment made by Edward Greisch is very important. It is very difficult for the average bloke (or indeed well qualified blokes if they are not climatologists) to make sense of the discussion. This is why it is vital that papers are submistted to the journal addressing the errors of papers such as this. The “sceptics” can and do ignore criticisms made on a blog, a peer reviewed comment in the journal is much more difficult to dismiss.
I do hope that someone send in a comment on this paper, just as I hope someone has submitted a formal criticism of Douglass et al.
The links to Kiraly et al, 2006 and Fraedrich and Bender 2003 are here:
http://www3.interscience.wiley.com/journal/118587932/abstract?CRETRY=1&SRETRY=0
http://prola.aps.org/abstract/PRL/v90/i10/e108501
Both paywalled, but the abstracts are already informative.
The conclusion is as tamino says: you only see Hurst behaviour in the models if you first remove the trend, i.e., including 20th century warming. After that, you just won’t find enough power left in the residual fluctuations to explain this anthropogenic upturn.
In a way, the models (and note that the one(s) used by Fraedrich and Bender include realistic ocean modelling, as they must to get the longest time scales right) confirm the empirical finding by Mann et al. and many others that there isn’t a whole lot of power in natural variation for these long periods that we don’t know about. The same can be seen in the famous Figure 9.5 of AR4 WG1: the coloured band capturing natural variability is not able to accomodate the antropogenic contribution.
What is perfectly clear is that the average bloke with an IQ of 100 and a high school education is 100% lost in this discussion.
Generally the critiques of papers like this are less accessible, there is plenty of other material on the site that your average bloke should be able to understand. A high school understanding of statistics and physics is probably enough to get you started on the subject, and from there you can build up enough knowledge of the basics to be able to either understand or at least follow the key points of the more complicated parts.
Perhaps I’m missing something, but the main point of the paper seems to be that due to the inaccuracy of the models demonstrated for any particular station and time period, they will also have questionable validity for regional or global prediction at longer time scales.
The reason for that is that weather ultimately becomes climate. The temperature in Albany has an effect on the regional weather which has an effect on the larger scale weather which, past a few weeks or so, is climate. The (IMO) overused argument of chaos does not cover errors such as figure 5. Over the long run, those can only be due to microclimate modeling errors which can be fixed.
The authors give four explanations in the paper which I believe is a bit of a false dichotomy. The major explanation IMO is (1) the models are poor, but (3) the comparison is invalid, also applies somewhat but not completely for any one station and less so as the number of comparisons is increased. Rejecting explanation (1) is only a recipe for confusion.
Gavin, Thanks for this. When I first came across this, my initial reactions was “Huh?” I mean, why the hell would you concentrate on only 4 stations and look for whether climate models could do something that nobody has ever claimed they could do. Upon further reflection, I had to revise my initial reaction to “WTF?”
Curious, I looked to see if Koutsoyiannis had published anything previously that was of note here. It appears that he did comment on some entries in 2005-2006–rather confused comments at that. Given his latest effort, it would appear that the learning curve doesn’t have a positive slope. This one, to paraphrese Pauli, doesn’t even rise to the level of being wrong.
About long-term persistence, I have been wondering about Figures 9.7 and 9.8 in the AR4 WG1 report (pp. 686,687).
Comparing with the similar graph in the TAR, it looks like
1) these are plots of power spectral (i.e., per unit of frequency) density, while nevertheless being plotted against time scale (i.e., the inverse of frequency);
2) global temperature appears to be almost a 1/f process; and
3) the unit stated on the vertical axis, degrees^2 / yr, is wrong; it should be degrees^2 yr.
Did I get this right?
S. Molnar:
Kiraly: just paste what Gavin wrote into Scholar and it pops up.
Blender: GEOPHYSICAL RESEARCH LETTERS, VOL. 33, L04710, doi:10.1029/2005GL024919, 2006
Eric, Yes, you are indeed missing something. Weather is highly dependent on local intitial conditions. However this dependence damps out over time. Weather does not “become” climate. Rather climate represents long-term, global TRENDS in weather. That’s an important distinction.
It is easier to get the public to believe something that is easy to understand but wrong, then to get them to accept a correct concept that is complex. K et al, 2008 tells an easy to understand story that will be popular with people that have doubts about global warming. It has “sound bites” that can be recited at parties, over plates of BBQ without putting down your beer to check the details. It is the kind of story that someone like Karl rove would concoct using focus groups. I expect this myth to spread rapidly and widely. It might be countered by a massive and sophisticated education campaign, but no organization is likely to mount such a campaign in the next few months.
Every university should make climate science a required freshman subject. Climate science should be required in high school. It should be in every elementary science text. The citizenship test has questions about American history. It should also have questions about climate science. There should be questions about automobiles role in global warming on every driver’s license test.
Unless me make this kind of an effort in climate science, and take a leadership role leading others to make similar efforts, we will pass too many tipping points and lose everything that is American.
Timo (#12), you’re the resident spec-ialist in wrong conclusions ;-)
Ray, The climate models may well only model “climate” as global (or regional) and trends. But that is in fact what the authors are comparing, a global set of stations (albeit a relatively small number) and long term trends. Their fault with the models did not depend on my definitions of how weather becomes climate.
Perhaps I’m missing something, but the main point of the paper seems to be that due to the inaccuracy of the models demonstrated for any particular station and time period, they will also have questionable validity for regional or global prediction at longer time scales.
I cannot tell you with any reliability whether the high temperature one week from today will be higher or lower than today’s high. I can tell you with high reliability that the high temperature 6 months from now will be lower than today’s high (where I live, anyway, ymmv).
It’s true that 6 months from now is composed of 26 weekly periods, so your reasoning would be that I shouldn’t be able to do this (ie have a highly reliable estimate over that period when I can’t provide one for the short term periods that compose it). But I can- the day-to-day trend is chaotic, but the longer-term trend is not.
This is also true spatially.
Or, consider sports- I can say with fairly high reliability that the Los Angeles Lakers will have a winning season next year. But I cannot easily predict the outcome of any particular game, My season-long prediction is much more reliable because it’s based on the averaging together of a number of events; the noise (ie chaos) tends to average out, and we’re left with the underlying trend (ie that the Lakers are an above-average team).
Carleton (25), I agree with summer/winter argument, otherwise I wouldn’t be chopping wood. But the authors are showing yearly trends in their figure 5, not short term chaotic effects. Your argument would then reduce to whether the authors evaluated enough stations when they made their reality/model comparison and whether they did it properly or not.
Eric, please read the OP, it is clear that either you haven’t read it, or haven’t digested what’s being said.
If you believe the OP misrepresents the paper, then please state so clearly. If you agree with the OP’s representation of the paper, but disagree with the analysis, then please bring up points refuting those made in the OP.
dhogaza, IMO this sentence “The IPCC report for instance is very clear in stating that the detection and attribution of climate changes is only clearly possible at continental scales and above.” is not what the K paper is about. The authors obtain their test of falsifiability by testing a series of grid points against the same series of real world points because the real world doesn’t provide a pristine regional or worldwide temperature series.
The paper is not about detecting and attributing climate change, it is about modeling climate. If climate change can’t be modeled correctly at some number of grid points then I wouldn’t expect accuracy at other grid points. To reiterate my previous post, my explanation is (1) the models are poor, and (3) the models and observed time series are not compatible (I would say inadequately represented due to the limited number of points used).
“By correlating at the annual and other short term periods they are effectively comparing the weather in the real world with that in a model. Even without looking at their results, it is obvious that this is not going to match…”
So if the hypothesis was something you think is reasonable, are there good model based regional projections?
How well do the best model results for regional hydrology compare with observations?
Steve Reynolds (29) — I’m an amateur with enough background, by now, to compare some of the ‘regional hydrology’ predictions with paleoclimate at times with warm regional temperatures. For southern South America there seems to be good agreement. I know far less about other regions, but to the extent that I am correctly understanding the paleoclimate, I’ll say that the predictions for the American mid-west and also for central East Africa appear to agree with the past.
For at least one other region, roughly the Congo River basin, there appears to be some striking differences. But this may just be my misinterpretation.
Uh, Eric, the sentence you quote is hardly the meat of the OP.
David B. Benson: “…there seems to be good agreement.”
Thanks, but a more quantitative comparison would be more helpful.
[Response: I agree. K et al would have been much better doing that. Maybe someone else will step up. – gavin]
Eric: perhaps I misunderstand you, but let me ask you this:
If it is well-known and expected that testing a series of grid points from one model run against the same series of grid points from _a second model run_ will show wide divergence;
A) is there then any reason to expect that testing a series of grid points against the same series of real world points would produce a better match?
B) does this constitute evidence, to your way of thinking, that the models are poor?
Dhogaza, how about “Furthermore, by using only one to four grid boxes for their comparisons, even the longer term (30 year) forced trends are not going to come out of the noise.” This seems to attack the meat of the results although it is not the meat of the review. I think the reasoning in the paper for 4 nearest grid points was fairly clear, to falsify or validate the model. I don’t know why the 30 year series of localized part of a model would suffer from noise.
Aaron Lewis #22:
There are on the Finnish test… also low-emissions driving is actively taught.
Gavin – lovely post, especially the first three paragraphs. If “the average bloke” had a better understanding of what climate scientists actually do, that would help tremendously. I’m currently studying how climatologists use computational models. My original goal was to look just at the “software engineering” of models -i.e. how the code is developed and tested. But the more time I spend with climate scientists, the more I’m fascinated by the kind of science they do, and the role of computational models within it. The most striking observation I have is that climate scientists have a deep understanding of the fact that climate models are only approximations of earth system processes, and that most of their effort is devoted to improving our understanding of these processes (cf George Box: “all models are wrong, but some are useful”). They also intuitively understand the core ideas from general systems theory – that you can get good models of system-level processes even when many of the sub-systems are poorly understood, as long as you’re smart about choices of which approximations to use. The computational models have an interesting status in this endeavour: they seem to be used primarily for hypothesis testing, rather than for forecasting. A large part of the time, climate scientists are “tinkering” with the models, probing their weaknesses, measuring uncertainty, identifying which components contribute to errors, looking for ways to improve them, etc. But the public generally only sees the bit where the models are used to make long term IPCC-style predictions.
I have never witnessed a scientist doing a single run of a model and comparing it against observations. The simplest use of models I have seen is for a controlled experiment with a small change to the model (e.g. a potential improvement to how it implements some piece of the physics), against a control run (typically the previous run without the latest change), and against the observational data. In other words, there is a 3-way comparison: old model vs. new model vs. observational data, where it is explicitly acknowledged that there may be errors in any of the three. I also see more and more effort put into “ensembles” of various kinds: model intercomparison projects, perturbed physics ensembles, varied initial conditions, and so on (in this respect, the science seems to have changed a lot in the last few years, but that’s hard for me to verify).
It’s a pretty sophisticated science. I think the general public would be much better served by good explanations of how this science works, rather than with explanations of the physics and mathematics of climate systems.
[Response: I try! – gavin]
Here are examples of two papers that don’t seem to have huge gaping flaws, and cover the data and the modeling of hydrologic changes:
Regonda et al 2005 : “Seasonal Cycle Shifts in Hydroclimatology over the Western United States”
http://civil.colorado.edu/~balajir/my-papers/regonda-etal-jclim.pdf
Here, the authors used the timing of maximum spring stream flows as their main dataset. The stream flow meters are accurate and the data doesn’t involve a lot of estimation (consider estimates of total seasonal flow volume, instead – huge uncertainties would be introduced – evaporation, groundwater flow, plant evapotranspiration, stream volume estimates, etc.).
If you look at the figures in the paper, you’ll see they have far more than 8 locations. Their paper shows that choice of location matters. If Regonda et. al had chosen one subset of their data to look at, they’d have a different result:
If you look at the paper, you see the data coverage was pretty extensive. Even though the paper is based on statistical analysis, their choice of data to look at is logical – it captures the diversity of the overall western U.S. hydrology over the past 50 years.
The authors make no specific claim about the cause of the noted spring temperature increase, other than to point to El Nino and global warming. Their paper is simply an analysis of the historical dataset.
2) For a paper that then uses models to make hydrologic forecasts for the future for the western U.S., see:
Amplification of streamflow impacts of El Nino by increased atmospheric greenhouse gases
EP Maurer, S Gibbard, PB Duffy – GEOPHYSICAL RESEARCH LETTERS, 2006
http://www.engr.scu.edu/~emaurer/papers/maurer_nino_amplification.pdf
Taken together, these two papers (and several similar ones, at least) should convince anyone that “A fundamental and societally relevant conclusion from these studies is that the use of the IPCC model predictions as a basis for policy making is” a valid and reasonable approach.
Time series analysis: http://www2.ocean.washington.edu/oc540/lec01-12/
#33, Kevin, I’m not sure those are yes or no questions. Are you talking about wide divergence at many grid points on a multi-decade model run? If many points, how many? There seems to be a general belief that all climate is global and all weather is local even over large time periods.
But IMO over large enough time scales, weather becomes climate so Albany will likely warm over a multi-decade run, perhaps cool, but not vary from run to run or much from reality. Repeat that comparison for enough locales and gain increasing confidence in the model.
Eric, you seem to have a fundamental misunderstanding of what the models do. It doesn’t make sense to look at a single model run and compare it to anything in the real world–let along to look at results for 4 gridpoints on a single run. You don’t use models to predict the future; you us them to elucidate the physics. The physics is what tells you the likely future path of the system.
(something went wrong with Captcha…am trying again…feel free to delete any duplicate)
Gavin: since Koutsoyiannis et al inspired you at least three questions that could move \the science forward\, I am not sure I understand your criticism. Someone had to start the analysis somewhere, and if the first article is too simple, all more the reason for more articles to appear on the subject
[Response: The questions aren’t inspired by a paper that adds nothing, but of the papers that already did more that K et al did. That I use the attention that K et al got to address them, is not a support of that publication. Of course, this isn’t the only time an uninteresting paper has been published (the literature is unfortunately full of them), it is however a missed opportunity. That is something to lament, not celebrate. – gavin]
@ Eric 38:
I’m not sure what you mean by “long enough time scales,” and I don’t know all that much about models (so help me out, those who do), but my sense is that you’re wrong about Albany. I think that local (and possibly even regional) variability are sufficiently chaotic that it would not, in fact, be reasonable to expect good agreement at particular locations among single realizations or between single realizations and observations over the course of, say, 30 years. It is one thing to be able to say that North America will warm on average, but there will be a lot of little swirls within that, not necessarily following a stable pattern from run to run, or in reality. Albany could be in a multidecadal cool swirl in one (or have enough cool snaps to bring down the average) and be in a multidecadal warm swirl in another (or have enough heat waves to bring up the average). All this with a model that is perfectly adequate for reliably predicting the aggregate behavior of climate in continent-sized regions. People who know–how far off am I?
Eric, let’s try a thought experiment. You are an observational physicist who wants to model absolutely everything involved in boiling a liter of water. You have the best equipment and methodology. After several runs, you will be able to make many reliable macro-pedictions about the process–things like time to boil under specified conditions.
However, will your ultra-high speed high-resolution video camera detect the same pattern of bubbles each time? And should you be discouraged if none of your model runs produce the same pattern of virtual bubbles, either?
. . . . pause for thought. . . .
I hope you said no to both questions. That’s chaos, and it won’t go away just because you don’t like people to use its existence in arguments!
Eric. A thought experiment:
You are at the top of a steep hillside. There are rocks, dells, dips, drops and bushes scattered around beneath you. You are at the top. You have a rugby ball (Football for the USians) sitting on its point at the top of this slope.
Give it a little push down the slope.
Where will it go?
In rough terms: down. 100% certain.
The actual path? Pff. Who knows.
Will it hit a bush? Well, how many bushes are there and is there any pattern? Did you ask that question while the ball was partway down? Because that changes the probable answer because it isn’t going back uphill to hit a bush over there, so some are excluded.
The Earth’s Weather: the ball.
Gravity: climate forcings
Path taken: Weather
Hitting a bush: Will Arkansas be warmer/drier/wetter/whatever
This may help you understand.
#42, KevinM: I’m not sure that’s a good analogy of what is being compared. If I were to apply heat to a kettle and take measurements of slight temperature variations within due to heated water circulation, that would indeed not match any simulation of the kettle for those location while the overall temperature in the simulation and real kettle would match quite nicely.
However, the earth is not a kettle and Albany is not an indistinguishable location, it has specific climate characteristics and weather patterns which can be simulated in climate models, for example http://www.mmm.ucar.edu/mm5/workshop/ws00/Zheng.doc (although their initial conditions do not seem to be random, that fact won’t matter over the course of years or decades as in the K paper figure 5).
Also the Albany discrepancies are repeated for 7 more locations worldwide, but is that enough locations to say the model is poor? I don’t know.
Steve Reynolds (32) — I don’t know about a quantitative assessment, but a more descriptive one is. For example, here are two quotations from page 14 of
http://www.oecd.org/dataoecd/29/2/36448827.pdf
“- the Patagonian region (Neuquén, Río Negro, La Pampa, Chubut, Santa Cruz and Tierra del Fuego Provinces): Temperature increase. More frequent intense precipitations; fluvial valley floods. Glacier diminution. Floods. Wood biomass fires. Desertification. Coastal erosion.”
“For preparing climate change scenarios for Argentina, the Global Model HadCM3 (UK) on IPCC scenarios has been utilized. … A remarkable trend to decrease of precipitation is also observed for the central region of Chile, and the Argentinean Region of Cuyo, Province of Neuquén and the western part of Río Negro and Chubut. These scenarios indicate a continuity of the climatic trends observed during the last decades.”
The flooding and desertification is observed in the geological record of Rio Neuquen and Rio Negro, I recall (without rechecking). But I don’t know how to be quantitative about comparing these observations to the model studies quoted above.
Re:#5 Edward Greisch says:”What is perfectly clear is that the average bloke with an IQ of 100 and a high school education is 100% lost in this discussion. They have no way of understanding any part of it, no idea who is telling the truth…”
This is heavy going,to be sure, but to paraphrase physicist Leon Lederman,from his book “The God Particle”- Just because I don’t understand it doesn’t mean it’s correct.
“Dire Predictions” by Mike and Lee Kump arrived in today’s mail and I must say its a lot more user friendly than Hurst coefficients and autoregression analysis.It contains some startling graphs,i.e.,
page 33 showing the recent spike in three of the GHGs, and (so far) contains good summariess to use as responses to the usual skeptics arguments.
> Albany
Eric writes:
> Albany … can be simulated …
How the heck big IS Albany, and why don’t they mention it at all in the Zheng et al. document you link to?
That .DOC file says:
” In this study, we investigate the weekly to monthly predictability of clouds and precipitation over the LSA-East, defined roughly by 33 – 430N latitude and 78 – 890W longitude …”
Is Albany really that large? Where are you getting your beliefs, Eric? Did someone claim this was a study about Albany? Did you somehow read it and decide for yourself it was about Albany?
#43, Mark: Your analogy would continue on the thesis of the paper with a real world and simulated topology in which the bushes are placed. The ball is rolled down the hill every day for 30 years with and yearly averages of how each bush is hit are compared between the simulations and reality, although only eight bushes scattered across the hill are considered (is that enough?)
Obviously the model granularity and physical fidelity is going to make a big difference. If a rock in front of a bush is not modeled the ball hits it in the model but not in reality. But there are 8 bushes under consideration so a rock or two should not matter.
To accurately predict climate, the basic topology of the hill must be modeled, some bushes are in gullies, some beside other bushes. Remember that by hitting one bush in a particular angle the ball will tend to hit another particular bush, just as weather affects weather elsewhere.
I don’t doubt the ability of a climate model to predict climate given a world with no land, or one or two circular land masses with no terrain, or perhaps a more complex shape. But the climate does depend on the irregularities of the planet which must be accounted for accurately in the model. Those irregularities affect weather, which over the 30 years of the test becomes climate.
Re 46
“Those irregularities affect weather, which over the 30 years of the test becomes climate.”
Yes, in so far as the pattern/texture of weather becomes/is climate.
But don’t you think there are some underlying patterns in the global climate that can be understood even with greatly simplified models? The Hadley cells, for example. The continents will perturb them from what they would be with a global ocean, and SST anomlies will perturb them further, but you can mathematically break this into a ‘basic state’ plus one or more ‘perturbation’ components (although those terms are more typically applied to perturbations relative to a time and/or zonal average, whereas in this case the ‘basic state’ is not necessarily the average in either time or any space dimensions).
—
A single grid cell may have to characterize the average of some number of points within it.
While colder and warmer air masses are shifting around, cold air and warm are being ‘produced’ at certain rates that globally averaged may not shift around quite so much. My impression is it will be easier to predict the changes in the ‘amount of cold and warm’ then the distribution of it for a given external forcing, though I’d like confirmation on that (although if I took the time I might be able to justify that view based on some physical arguments, maybe?)
Likewise, there are many ways to distribute precipitation in time and space that would balance a particular global average evaporation rate.
“(although if I took the time I might be able to justify that view based on some physical arguments, maybe?)”
Well, to start with:
greenhouse forcing: a global average change in LW radiative forcing (With some spatial variation that can be understood from physics).
A change in the LW radiative forcing of atmospheric gases will, if applied to the same climate, result in some disequilibrium. On the long term, a climate, with all it’s shorter term fluctuations, may be near equilibrium (in the sense that the patterns can be expected to recur – not exactly like a tesselation, but generally like the same texture (is climate a glass?)). On the shorter term, fluctuations occur because a state would not be in equilibrium if it were constant, but the change in external forcing means that with the same climate, the shorter term imbalances would be changed, so the weather patterns even in the shorter term would evolve differently. Thus the climate must change before a longer term equilibrium can be approached again. In the case of the positive LW forcing, equilibrium requires an increase in temperature. The distribution of this temperature is not specified by the forcing because wind can carry heat and the wind pattern has not been specified. But some basic physical arguments lead to certain expectations about the temperature change distribution, from which certain other arguments can lead to expectations of other changes, and then there are feedbacks, etc… So, for example, I expect more rain. And a greater fraction of rain in intense downpours. Do I know where or in what seasons or how this might correlate with ENSO indices? Not so much (though others might)… And I expect some changes in the midlatitude westerlies. This implies a potential for change in the quasi-stationary planetary wave patterns. From that I expect at least a potential for some change in longitudinal as well as latitudinal distribution of different kinds of weather, including precipitation. But without some number crunching I don’t know where and what. … And with a general increase in SSTs, I expect certain kinds of low-frequency variability, in particular those in which SST anomalies produce a perturbation wave train in the westerlies allowing for global teleconnections, to be more sensitive to the same SST anomalies, because of the exponential temperature dependence of water vapor concentration (involved in latent heating, enhances deep convection, etc.). And there’s the implied physical arguments in my ITCZ questions from earlier. The point I’m trying to make, I guess, is that it is easier to project that there will be more change than otherwise if x,y,z… with some generalized numbers and distances, then it is to say what the change will be in, for example, Albany.