Every so often people who are determined to prove a particular point will come up with a new way to demonstrate it. This new methodology can initially seem compelling, but if the conclusion is at odds with other more standard ways of looking at the same question, further investigation can often reveal some hidden dependencies or non-robustness. And so it is with the new graph being cited purporting to show that the models are an “abject” failure.
The figure in question was first revealed in Michaels’ recent testimony to Congress:
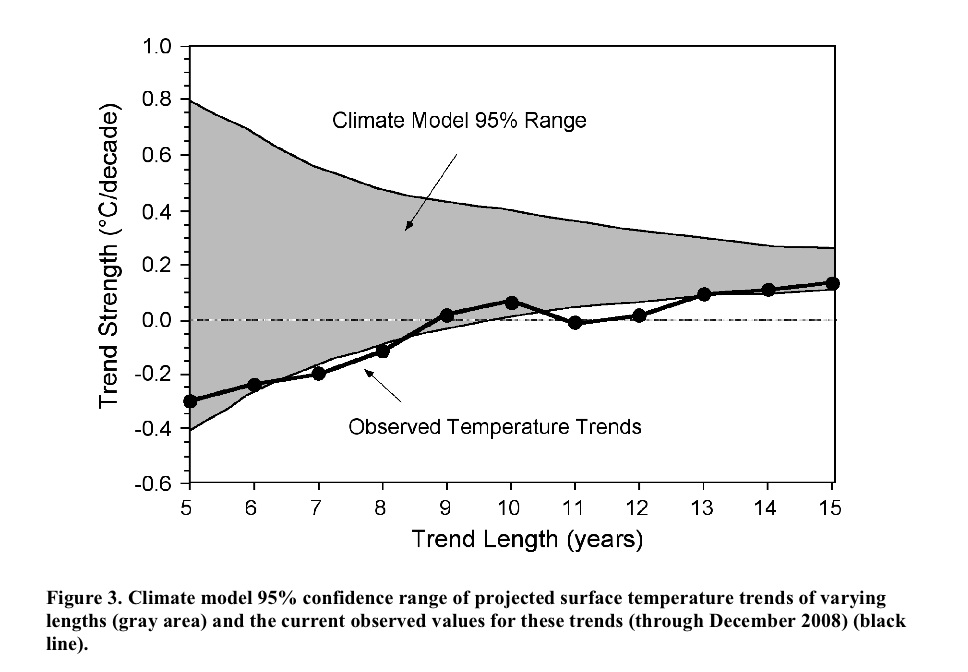
The idea is that you calculate the trends in the observations to 2008 starting in 2003, 2002, 2001…. etc, and compare that to the model projections for the same period. Nothing wrong with this in principle. However, while it initially looks like each of the points is bolstering the case that the real world seems to be tracking the lower edge of the model curve, these points are not all independent. For short trends, there is significant impact from the end points, and since each trend ends on the same point (2008), an outlier there can skew all the points significantly. An obvious question then is how does this picture change year by year? or if you use a different data set for the temperatures? or what might it look like in a year’s time? Fortunately, this is not rocket science, and so the answers can be swiftly revealed.
First off, this is what you would have got if you’d done this last year:
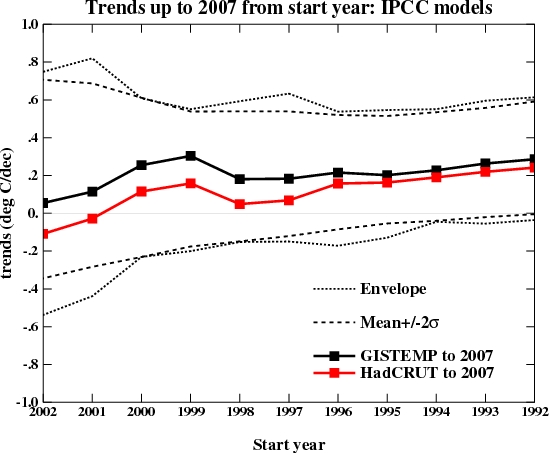
which might explain why it never came up before. I’ve plotted both the envelope of all the model runs I’m using and 2 standard deviations from the mean. Michaels appears to be using a slightly different methodology that involves grouping the runs from a single model together before calculating the 95% bounds. Depending on the details that might or might not be appropriate – for instance, averaging the runs and calculating the trends from the ensemble means would incorrectly reduce the size of the envelope, but weighting the contribution of each run to the mean and variance by the number of model runs might be ok.
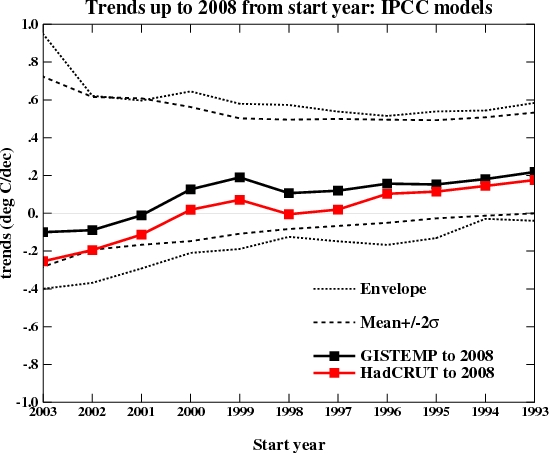
Of course, even using the latest data (up to the end of 2008), the impression one gets depends very much on the dataset you are using:
More interesting perhaps is what it will likely look like next year once 2009 has run its course. I made two different assumptions – that this year will be the same as last year (2008), or that it will be the same as 2007. These two assumptions bracket the result you get if you simply assume that 2009 will equal the mean of the previous 10 years. Which of these assumptions is most reasonable remains to be seen, but the first few months of 2009 are running significantly warmer than 2008. Nonetheless, it’s easy to see how sensitive the impression being given is to the last point and the dataset used.
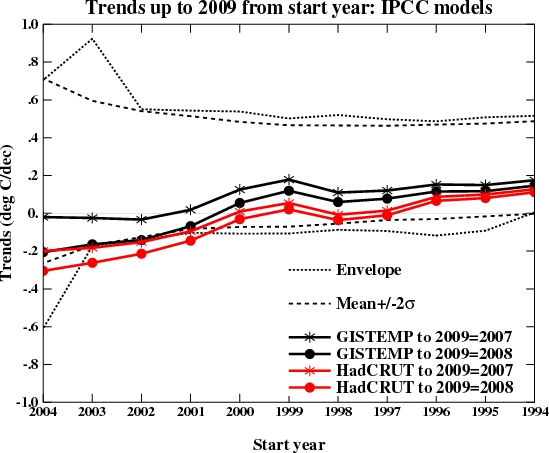
It is thus unlikely this new graph would have seen the light of day had it come up in 2007; and given that next year will likely be warmer than last year, it is not likely to come up again; and since the impression of ‘failure’ relies on you using the HadCRUT3v data, we probably won’t be seeing too many sensitivity studies either.
To summarise, initially compelling pictures whose character depends on a single year’s worth of data and only if you use a very specific dataset are unlikely to be robust or provide much guidance for future projections. Instead, this methodology tells us a) that 2008 was relatively cool compared to recent years and b) short term trends don’t tell you very much about longer term ones. Both things we knew already.
Next.
Thanks for your continued debunking. Just think if we all got a nickle for everytime we had to answer this nonsense!
There is a difference between a skeptic and a denier, a skeptic does not play rhetorical games nor plays statistical tricks. When such games are played, how can one not call them denialists?
“Next” will be:
http://jennifermarohasy.com/blog/2009/03/the-available-evidence-does-not-support-fossil-fuels-as-the-source-of-elevated-concentrations-of-atmospheric-carbon-dioxide-part-1/
presumably.
[Response: Well, we probably wont’ bother as we debunked this stupidity a couple of times in our first few months of launching RealClimate (and it really is an idea that exposes anyone subscribing to it as a truly phenomenally ignorant person, more than just about anything else out there, on par with the earth-is-flat idea (if not stupider, since the earth *does* look flat from where we stand on it…)). See here and here–eric]
It almosy makes one wish that 2008 had been much hotter, doesn’t it? Why, I thought that I must have forgotten how to read graphs for a moment there.
Thanks for being honest enough to tell the truth, even if it does hurt our chances of driving these facts home.
[Response: Don’t be an ass. It’s unbecoming. – gavin]
Why? What could possibly be his motives to do such sloppy work?
If it is scientific oversight then he really harms his stature as a Research Professor at the University of Virginia.
If it is duplicity motivated by ideology then he becomes dangerous.
Poor fellow, he must be torn between his “stature as a Research Professor at the University of Virginia” and his fellowship at the Cato Institute.
That would be “Research Professor of Environmental Sciences,” and “Senior Fellow in Environmental Studies.”
Nope, no ideology to see here. Move along.
Thank you! This thread will certainly be useful in replying to the ignoranti.
David B. Benson, the idea that ‘anyone who questions conventional AGW theories is ignorant’ has been thoroughly debunked – here and elsewhere. Please use the start here link at the top of the page.
Why would he do it?
Because millions (well tens of thousands really, this is not an important graph really) will see it and in a short time.
Six months from now they will remember it as fact, and whats worse, even some of the people that read Gavin’s nice explanation of why it’s wrong will still remember it as having be “true”.
That’s why he does it.
It doesn’t even matter if it is a lie, as long as people hear it several times, it will be excepted by most as having been fact.
Michael says, “…the idea that ‘anyone who questions conventional AGW theories is ignorant’ has been thoroughly debunked – here and elsewhere.”
OK, so where are the smart ones?
Michael, who are you quoting?
You seem to have misread a reference to “ignoranti” and put your misreading into quotes as though someone else said it. Nobody did.
David’s mock-latin refers to those more traditionally called know-nothings or ignoramuses (those whose eternal posture is that they “do not know” — no matter how informed; whose stance is that of “constant adversary” — look it up*).
__________
* http://en.wikipedia.org/wiki/Ignoramus_(drama)
Gavin, I’m wondering what you and Michaels did differently: his up to 2008 picture looks different from yours. Also, what would your response be if 2009 looked like 2008, and the data stayed near the lower boundary of confidence in the models? Would the trend be robust then? At what point would it be, if not?
Michael (8) — The statemnt you quoted was not even implied by what I wrote.
If I correclty understood you critisize Michaels for misusing short term data (actually cherry-picking end points) to make impression that future observations will be close to the low end of IPCC range.
RC: “However, while it initially looks like each of the points is bolstering the case that the real world seems to be tracking the lower edge of the model curve, these points are not all independent”
If so, why dind’t you plot graphs since 1979 where satellite measurmeents began, if you are so sensitive on procedures that cherry-pick start and end points? Just to check out whether real world really “tracks low end” or not?
So, RSS shows 0.16 deg C per decade 1979-2009, UAH shows 0.13 deg per decade 1979-2009 and Had Crut 0.17 in the same period. Lower end of IPCC range is somewhere about 0.15 deg C per decade if I am not wrong. Now, what do you exactly think to accomplish with such a critique of Michaels? Both satellite data sets, and HadCru as well, pretty closely track lower end of IPCC range in period 1979-2009. Models predict by and large constant rate of warming, which is around 0.15 deg C in previous 30 years. What’s controversial in projecting that rate of warming into the future? Do you think that basic IPCC science captured by models is somehow wrong? That rate of warming shouldn’t be constant?
[Response: The models track the temperatures since 1979 very well so I’m not sure what point you are making. The warming is not expected to be constant. – gavin]
#3 Jennifer Marohasy is employed by an Australian extreme right wing think tank, whose job description seems to involve taking a contrarian view towards anything that suggests rampant laissez faire capitalism is not good for the environment. She has, for example, stated that the drying up of the once mighty Murray River is perfectly natural and nothing to worry about. But global warming is obviously the big one for these people as it is in the US. Greenhouse temperature rise is a massive refutation of the proposition that the world should be run by businessmen for businessmen (http://www.blognow.com.au/mrpickwick/33318/Addicted_to_CO2.html), and the ideological representatives of business employ people like Marohasy to try to muddy the waters and the air.
Ah yes, the infamous Cato Institute…I remember them with an ‘article’ in the Arizona Republic here in Phoenix, claiming that second hand smoke was harmless. This was only a couple of years ago. Kind of takes your breath away.
[Response: Literally. – gavin]
The conceit of using segments this short at all needs some justification. The whole exercise is rather silly…let’s look at long-term trends that are interesting statistically. Or more importantly, trends that are interesting mechanistically! This wouldn’t move me even if Michaels were right.
Please don’t use that “rocket science” cliche. Not least because rocket science is the simplest science there is — action and reaction are equal and oppsite.
But rocket engineering — now, that’s tricky!
Re #2: “There is a difference between a skeptic and a denier, a skeptic does not play rhetorical games nor plays statistical tricks. When such games are played, how can one not call them denialists?”
I personally think the term “psuedo-skeptic” is more acurate and descriptive. The stereotypical psuedo-skeptic is the pet shop owner in Monty Python’s dead parrot sketch.
What troubles me most is that this has been presented to the US Congress as something authoritative.
Re #20
I hope that the relevant people in the US Congress will be /(will have been) informed of this correction directly.
My two cents worth….
Until we can show a dew point increase at 10km, which is a CO2 forcing
requirement for the current models we will probably have skeptics. At present,
satellite data taken sine 1979 has shown a stable dew point, which if correct
would reduce the CO2 forcing argument.
Perhaps more work needs to be done with the satellite measuring systems &
techniques. The world may be getting warmer due to rising CO2 but you still
need to close off any holes. Simply stating from our side that the sensors
or readings are faulty is not good enough.
I’m sure the skeptics will get plenty of air time in the interim !
[Response: You are possibly a little confused. The ‘Dew point’ is the temperature at which an air parcel needs to be cooled in order to cause water vapour to condense (I’m sure you know that, but I repeat it for clarity). Thus it is a measure of specific humidity (the total amount of water vapour in the parcel). And specific humidity has been increasing at all levels of the troposphere (IPCC AR4 3.4) (the stratosphere too, but that is a somewhat separate issue). Thus the dew point has been increasing as well. I unfortunately see no let up in the number of pseudo-skeptics. – gavin]
“I personally think the term “psuedo-skeptic” is more acurate and descriptive.” But what is the purpose in seeming skeptic yet not acting as one? To deny a proposition that they do not wish to accept.
Denial is the creed. Denialist the name.
Did you (the good people at RC) sent some sort of correction to the US Congress?
The Michaels graph is very deceptive indeed (probably purposely so) – I must admit it took me a minute or so to see what exactly was depicted and why it is the sheerest nonsense.
Unfortunately your own graph does not help much, seen from a PR viewpoint. I am afraid that the message people will take from your graph is: “Hey, even the AGW-scientists get a cooling trend” (because the leftmost points are below zero), while not realising that a trend based on a few years (and hence the whole graph) is rubbish.
[Response: The graph is cut off at 5 years, but if you extend it further the overall impression changes considerably (since both the model spread and the very short term trends are much wider). If I was in the business of propaganda, I would have used that instead of just using the parameters set by Michaels. But that’s the difference. – gavin]
Absolutely hilarious. Failure to check that result for dependence on the endpoint would be unforgivable even in my field (economics) let alone in the hard sciences.
So what is it with these people? I used to think that a lot of the mistakes among denialist scientists were due to their failure to grasp the difference between experimental data and observational (non-experimental) data. For a lot of folks trained in experimental method, the error term associated with a data point is the measurement error, period. So they can’t quite grasp that the error term when you model something from observational data is a different thing entirely.
If that is the root cause of their confusion, then this analysis is of a piece with the Douglass et al tropical tropospheric trends analysis. There, they treated each model prediction as if it were a datapoint, ignoring the large irreducible uncertainty around each datapoint. Here, the terminal datapoint is treated as if it had no transient component. What I see in common is that in both cases, they completely failed to come to grips with the nature of the error term they were dealing with. As if it were just some tiny little measurement error that could be ignored (as usual).
So, never assume conspiracy when stupidity provides an adequate explanation of the facts. But for this one, I really do wonder. If you don’t grasp that there is a large transient component in any one year’s temperature measurement, you have no business talking about trends. Let alone testifying in front of the Congress.
I personally think the CATO institute is over rated as the science institution it
may claim to be. The real argument with the lay is over how serious AGW is:
http://www.nytimes.com/2009/03/29/magazine/29Dyson-t.html?pagewanted=1&_r=2&hp
As the future can be theorized at will, can actually morph in many shapes, the battle lines are drawn now, how will we shape it? Freeman Dyson offers the greatest counter arguments , the most potent ones, than anything Michael’s has done. However his wife reasons correctly on this issue, so much for spousal influence!
A couple of things, he states are flat wrong:
“Most of the time in history the Arctic has been free of ice,” Dyson said. “A year ago when we went to Greenland where warming is the strongest, the people loved it.”
The first part is flat out rubbish, shocking statement from a man of science, there is no evidence of a wide open Arctic ocean until very recently…. it still is, apparently a thriving old English myth, to the demise of many explorers, Martin Frobisher, Sir John Franklin , Cabot etc. I suggest Dyson to check out the history of Bowhead whalers (17th to 20th centuries), never going from Alaska to Greenland chasing their prey. Always separated by the frozen Northwest passage, which is no longer so frozen in the summer anymore. Not even the fierce Norse, in the middle of the medieval warming period, are said to have visited Alaska. Alice, his wife should know that Polar bears are threatened at the fringes of the ice world, not where there is still a lot of ice, so anyone can comfortably say that they are doing fine.
The latter statement from Greenlandic people may be true for some residents who don’t particularly love long winters, virtually everyone in the Arctic enjoys warm weather, but not at the detriment of their entire way of life.
Dyson’s claim “where is the AGW damage?” is the most frequently used statement by all anti AGW theorists, the answer is again most clearly seen in the wide open Arctic ocean, no longer a hiding place for Nuclear submarines, Where Polar Stern, a German ship, ventured where no ship has sailed freely without ice before, amazingly close to the North Pole last year. It is also astounding, all Polar Nations are scrambling as they never had before, to claim vast swats of Ocean now seasonally open for trade, may be this is not damage, per say, but one may only imagine what will come next if the climate doesn’t cool down. Finally, surely, the biology of ice dwelling creatures, is forever transformed, if there is …. no ice….
[Response: Dyson is wrong on many issues and displays a shocking ignorance of climate modelling despite holding very strong views on the matter. However, the example you picked out here is mainly semantic. ‘History’ as you assume means recorded history – and certainly the Arctic has not been ice free for any of that, but Dyson is referring to ‘Earth history’ (i.e. the geological timescale), and if you look at that he is likely correct – Arctic ice started forming in earnest about 14 million years ago having been absent for most of the last 65 million years. However, the relevance of this for today’s situation is zero. Thus while he can rightly be accused of offering up red-herrings, this isn’t quite as damning as you imply. – gavin]
Christopher Hogan, that’s why “pseudo skeptics” isn’t right. If anything they are credulous. ANYTHING that says “AGW is false” is accepted without thought.
26r
Dyson wrote, a couple of years ago:
“I have studied the climate models and I know what they can do. The models solve the equations of fluid dynamics, and they do a very good job of describing the fluid motions of the atmosphere and the oceans. They do a very poor job of describing the clouds, the dust, the chemistry, and the biology of fields and farms and forests.”
I was more or less inclined to take him at his word, given his reputation as a thoughtful and accomplished scientist. Where is it in particular that you believe his “shocking ignorance” lies?
[Response: First off, he is confusing models that include the carbon cycle with those that have been used in hindcasts of the 20th Century and are the basis of the detection and attribution of current climate change. Those don’t need a carbon cycle because we already know what the atmospheric CO2 concentration was. Second, his slanders of Jim Hansen reveal someone who has never actually read a Hansen paper nor met him in person (I would be astonished if this was not the case). Statements such as “They come to believe models are real and forget they are only models” reveals he has never had a conversation with a climate modeller – our concerns about ice sheets for instance come about precisely because we aren’t yet capable of modelling them satisfactorily. If you want to read about what modellers really say (as opposed to how they are stereotyped) try here. Where is this religious environmentalism he thinks we modellers revel in? It doesn’t exist – and that demonstrates clearly his ignorance on these matters. I’d be more than happy to discuss these things with him if he had any interest in furthering his education. – gavin]
#26 Thanks Gavin, Ha, but the citation article implies “history”, not geological history, which left alone, needs a reply. However Dyson’s argument becomes still pretty bad and disconnected,
if he claims an open Arctic ocean is “normal” as per Earth history, then where will the Polar bears and walruses and seals hang out? Even more compelling, what would happen to the entire Earth’s climate if the ice disappears? We know other damages, coral bleaching is still a scurge not often told, ocean acidification is another. He seems not to grasp the damage done by quick climate transitions. Its not been a question of AGW triggering an end to the world, but a rapid change causing chaos to not only humans, but all living things.
“I was more or less inclined to take him at his word, given his reputation as a thoughtful and accomplished scientist.”
So why don’t you take the hundreds of thoughtful and accomplished scientists who are part of the consensus at their word?
Re:https://www.realclimate.org/images/2008_from1979.jpg
The temperature vs time data are noisy. Slopes derived from this graph will be noisier. Isn’t it much better to look at the actual T vs t graph than the trends derived from the differences of arbitrary endpoints ?
Re: Dyson
I’m afraid he’s gone emeritus.
https://www.realclimate.org/images/2008_from1979.jpg
What a mess!
Does this suggest that the claims of increases in the order of 4.5-6 (or more) K are highly unlikely, as temperatures do seem to be bumping along the bottom of the predicted ranges?
Also what about publishing how modelled predictions from 5 or 10 years ago compare with measured temperatures?
That would be an interesting test as to the accuracy of models, as I believe that GisTemp E, as modelled 5 years ago, is now .15K above current temperature.
[Response: What is GisTemp E? GISTEMP is the analysis of station and satellite data, while GISS ModelE is a GCM that was part of the simulations done for AR4. They have little or nothing to do with each other except by virtue of being in the same building. Those simulations are included in the figures I showed before, and your ‘belief’ is not accurate. For the 8 runs I have easily available (GISS-ER and GISS-EH), 2008 temperatures range from 0.12 to 0.59 deg C above the 1980-1999 mean. GISTEMP was 0.19 (0.17 for HadCRUT3v) on the same baseline. Thus while 2008 was cooler than the expected trend in the absence of any natural variability, it is still well within the envelope of the what the models expect. – gavin]
30. That’s why the “more or less”. Appeals to authority are problematic, as are appeals to consensus. In the age of blogs and confirmation bias, there is no question it is difficult to navigate the opposing points of view and to determine who, if anyone, has it right. It’s a complex topic. Dyson’s is an interesting perspective, and obviously not the only one.
Dyson should serve as a cautionary tale to any scientist commenting well outside the area of his expertise. While I do not know the motivation behind his animus against climate science, some other technophiles I know are horrified by the prospect that for a while the march of their pet scientific subject might have to take a back seat to survival.
That looks like a fatal flaw for Michaels. I wonder what would happen if the same approach was applied to other climate metrics, like sea surface temperature, water vapor feedback strength, and precipitation-evaporation changes. That approach is avoided by Michaels & co, because despite various levels of uncertainty in each dataset, they all point in the same direction.
Probably the best thing to show Congress (after a short explanation of those graphs) is a video of the model results, as seen on Google Earth:
http://www.metoffice.gov.uk/climatechange/guide/keyfacts/google.html
The various layers of interest for Google Earth are here:
Global climate model temperature projections
USA regional CO2 emissions
Global per capita CO2 emissions
NSDIC Glaciers and Climate Change
British Antarctic Survey ice shelf retreat
Here, you can see a geologic history of plate tectonics – worthwhile for thinking about past climate regimes.
That shows there are a whole lot of effects that go with a rise in temperature, and any honest analysis would examine all of those issues, not just one.
For example, the energy increase represented by a rise in atmospheric and surface temperatures is a fraction of the energy increase represented by ocean warming.
IPCC FAR points:
“Over the period 1961 to 2003, global ocean temperature has risen by 0.10°C from the surface to a depth of 700 m”
“The patterns of observed changes in global ocean heat content and salinity, sea level, thermal expansion, water mass evolution and biogeochemical parameters described in this chapter are broadly consistent with the observed ocean surface changes and the known characteristics of the large-scale ocean circulation.”
By the way, Reuters published a decent article on the role of global warming, the oceans and other factors in Australia’s drought:
http://www.reuters.com/article/latestCrisis/idUSSP141565
For more background, see Humans and Nature Duel Over the Next Decade’s Climate, Richard A. Kerr, Science, Aug 10, 2007 – a generally sympathetic treatment of natural variations (including a review of Peter Baines and the AMO).
Where the natural variation claims fail is in their presumption of periodic oscillatory behavior. We do see such periodic behavior in seasons and tides, which is due to planetary orbits. There, the time series analysis and the physical mechanism are both reliable and well-understood. That is definitely not the case for the other natural variations such as the PDO and the AMO, which rely on fairly crude statistical correlations (fish catches?) and suffer from a huge lack of observational ocean data, especially subsurface data, as well as from short time periods. The longer the time period, the more robust the time series analysis – pulling out a 20-30 year cycle from a 100 years worth of data is not very robust. Notice also that this really is a curve-fitting procedure, unlike climate models.
Time series analysis takes a dataset and fits a series of harmonic curves to it. It is like “rocket science” in that the details are highly complicated, and fiddling with those complex details can have a large result on the outcome. Thus, the situation is ripe for bogus but hard-to-evaluate claims, and everything related to it needs careful examination.
For example, due to the lack of ocean data, secondary data is often used to infer what the ocean is doing – thus, the AMO analysis relies not on ocean temperature measurements, but rather on air pressure measurements as a proxy for ocean behavior – iffy at best.
The point here is that if climate denialists focused their nitty-gritty questions on the issue of natural variations to the same extent they did with climate models, then you would see that forecasts based on climate models are far more reliable than forecasts made using the purely statistical, curve-fitting approach of time series analysis. The natural variations contain a large random component, depending on the specific variation – for example, a huge volcanic eruption six months from now would require new short-term climate predictions (but the long-term forecast would remain unchanged).
Thus, when Don Easterbrook gets up and says that the world is locked into a new cooling cycle “because of the PDO”, you should be able to tell him why that’s nonsense.
Gavin,
Thanks for providing more details of the results of this type of analysis.
First, a minor clarification, you write:
“The idea is that you calculate the trends in the observations to 2008 starting in 2003, 2002, 2001…. etc, and compare that to the model projections for the same period. Nothing wrong with this in principle.”
But that is not exactly what we do. We don’t compare observations with the same time period in the models (i.e. the same start and stop dates), but to all model projections of the same time length (i.e. 60-month to 180-month) trends from the projected data from 2001-2020 (from the A1B run) (the trends of a particular length are calculated successively, in one month steps from 2001 to 2020). This provides us with a sample of all projected trend magnitudes from a particular model run under an emissions scenario (A1B) that is close to reality (at least for the next 20 years). I bring this up just to clarify that we are comparing observations with the distribution of all model trends of a particular length, not just those between a specific start and stop date (i.e. we capture the full (or near so) impact of internal model weather noise on the projected trend magnitudes). I’ll gladly provide you with more details if you would like them to try to exactly replicate what we have done so far.
While this methodology doesn’t eliminate your point that the trends from different periods in the observed record (or from different observed datasets) fall at various locations within our model-derived 95% confidence range (clearly they do), it does provide justification for using the most recent data to show that sometimes (including currently), the observed trends (which obviously contain natural variability, or, weather noise) push the envelop of model trends (which also contain weather noise). If the observed trends (at any time—now, or last year, or 10 years ago, or 5 years from now) fall outside the range of model expected trends of a particular length, then there is the possibility that something is amiss.
The things that possibly are amiss are numerous. They include possible issues with the models (e.g., weather noise, climate sensitivity), the observed temperatures (e.g., GISS vs. HadCRUT), the forcings (e.g., observed forcings don’t match A1B forcings), or simply that rare events do happen.
We have not, as of yet, sorted all these things out. Consequently, I personally think that it is still too soon to conclude from only our analysis (as it now stands) that the models are “abject” failures (although, admittedly, I am not exactly sure that means). In my comments in a previous thread, I said that our analysis is a more appropriate reference for the statement in the Cato ad than is the Douglass et al. paper—primarily because ours directly assesses the most recent period and uses a global dataset—but, I fully understand that the issue is far more complex that a single citation can do justice.
An entire Chapter of the IPCC AR4 is devoted to model evaluation, which is the subheading under which I think our analysis falls. So, I think that the dismissal of our work with “Next” is a bit unjust, instead, I we have developed a legitimate methodology for illuminating several important issues—whatever the cause of the current observation/model mismatch, it probably deserves greater scrutiny. I would think you would be encouraging us to push this issue forward in the peer-reviewed literature—although perhaps with more guarded conclusions than are bandied about in the popular press.
In that light, I appreciate any constructive suggestions/comments that you may have. I think once you fully understand our methodology that you will find it to be a reasonable approach to comparing observations with model expectations on large spatial (global), but intermediate (5-15 years) temporal scales. Perhaps you will differ in how we interpret our results, perhaps not—as they have yet to be fully arrived at.
-Chip
[Response: But Chip, who is bandying these things about? Who described this as a proof that the models were “abject” failures? I’m pretty sure that it wasn’t us….. – gavin]
So you want to say that flat trend since 1996/97, according both UAH and RSS, is consistent with models? You Mr Schmidt once on this blog, if I correctly remembered, said that you would consider a decade without warming inconsistent with models. What about 1996-2009 without warming?
[Response: Not flat. Do please fact check before posting. – gavin]
Apart from his genius (Emeritus or not, he is still a better man than most of us), Freeman Dyson is the sort of contrarian I cherish. He delights in disturbing any consensus that shows signs of becoming a matter of belief rather than evidence; but he always has a reasonable position to advocate. His position on climate change is that if it gets out of hand, we can probably find a technical fix. (He has suggested genetic engineering to produce a trillion carbon-eating trees.) I think he is probably right (though I do not think that he figured in the time needed to genetically engineer of his trees nor to check the stability of that engineering; nor indeed the loss of what those trees would have to displace. My own hunch is that the best bet for such a fix may be in genetically engineering carbon-absorbing monocellular marine life).
The problem Dyson does not address is central. It not one of science or modelling. It is that “we probably can” does not equal “we will”. Maybe we can’t. In that case we had better get on with doing the job the hard, greenhouse gas emissions reducing way now because the longer we put it off, the harder it will be; and the higher the risk of disasterous positive feedbacks setting in. Maybe we can, but will we? We are very unlikly to develop and prove a worthwhile and effective technical fix if we do not recognise the problem and devote to it sufficient resources to create the effective demand for the fix. The conclusion Dyson points to of just letting global warming chug along for now only makes sense if we are, collectively, willing to take risks that really scare me with the only place we have to live on.
As for Dyson on modelling: most complex simulation modellers in all fields slip from time to time into thinking that their models picture reality. I have caught myself doing that a couple of times. Our present climate forcasting models do not include the carbon cycle; but in some years time are we not likely to want it in? And I guess Dyson noted that the models he looked at simply could not assess a possible carbon-absorbing technical fix.
Dyson on Hansen? As most people on Real Climate will know, Hansen has done a magnificent job not only on the science but also on fighting the argument through the various establishments. I guess that Dyson does not understand the way the latter necessarily conditions the presentation of the science. If he met Hansen, I suspect the Hansen would educate him in a way that you Gavin, good as you are, could not manage (and I could not even aspire to). And they would get on very well together.
#28. So Gavin,
So in regards to Dyson’s climate change credibility,
can’t you approach it in the way that says Dyson is not a current publishing scientist in peer-reviewed journals whose current work stands up under peer review?
His graph shows ~0.12C/decade over a period of 15 years while yours shows perhaps 0.2. That’s a durn good fit for people on opposite sides of the fence. Yeah, his timing smells of cherry pie, but then we know some of the reasons why 2008 was on the cool side: decreased solar output, Chinese pollution, and the PDO. 95% is not a magic number, especially when one has answers for much of the variance.
wmanny said:”In the age of blogs and confirmation bias, there is no question it is difficult to navigate the opposing points of view and to determine who, if anyone, has it right.”
No, it isn’t. Defer to the experts if you are not one. To determine who is expert in a particular area of science, look at publications in the field’s peer reviewed journals and grant funding.
gavin: “The idea is that you calculate the trends in the observations to 2008 starting in 2003, 2002, 2001…. “
Maybe you stated this somewhere and I missed it, but how are you defining ‘the trends’? Is this a least squares fit or just a difference of end points? Same question for Chip.
[Response: OLS. – gavin]
Dyson wants to genetically engineer carbon-eating trees? What does he think trees do?
Yes, since 1996 trend is not flat, but since 1997 is. Since 2001 we have sharp global cooling. Most probably, trend 2001-2010 will be negative. If 12 years of flat trend and 8 years of negative trend are not inconsitent with models, predicting 3 degrees C of warming on century scale, what is? Is there any imaginable state of affairs on decadal or slighlty longer time scale which is inconsistent with models? Do you still stick to your earlier assertion that decade without warming would be a problem for models? If yes, you should reconsider your present attitude toward models. If not, what is new theory – when models become inconsistent with observations? With two decades of cooling or flat trend? Or three? Or four?
#5 and #6: Michaels is only a retired professor now at University of Virginia, so his current employed position should be identified as the Cato Institute:
http://www.dailyprogress.com/cdp/news/local/article/former_climatologist_will_pursue_research_work/1857/
Looks like staying employed at UVA would have required disclosing his private clients, and that was unacceptable.
Re #43: Dyson want trees that produce diamonds as fruit, like just about everything else he says it is within the context of his Dyson Sphere. Most of his stuff is really just informed science fiction but he has contributed to Maths.
Re #23: Dyson is a psuedo-skeptic, he has failed to question his own ideas on AGW after having his errors pointed out. Dyson is also a WW2 veteran, calling a WW2 veteran a “denier” is akin to calling them a Nazi.
Re: #42
Same answer as Gavin.
-Chip
t_p_hamilton: “Defer to the experts if you are not one. To determine who is expert in a particular area of science, look at publications in the field’s peer reviewed journals and grant funding.”
Do you also apply that technique to economics? Most people here do not seem willing to be consistent about believing economic experts the way they believe science experts.
“Quirk’s Exception” (failed attempt to shut thread down prematurely).
Please proceed.
Do not your figures show a 2 sigma deviation and Michaels’ figure shows the 95% CI? A 2 sigma ellipse allows for 86.5% confidence and is therefore a wider level of acceptance than the 95% CI.
[Response: The difference is .4499736% – you wouldn’t be able to see it due to the thickness of the line. – gavin]