Do different climate models give different results? And if so, why? The answer to these questions will increase our understanding of the climate models, and potentially the physical phenomena and processes present in the climate system.
We now have many different climate models, many different methods, and get a range of different results. They provide what we call ‘multi-model‘ and ‘multi-method‘ ensembles. But how do we make sense out of all this information?
And, do we really need all these different models? Global climate models tend to give roughly similar estimates for the climate sensitivity, but there is nevertheless a spread between the different model estimates. The models often diverge more radically if we zoom down to a region.
Furthermore, a single model may give different answers for the future temperature over North America, depending on which day is used to describe the weather at the starting point of the model simulation (Deser et al., 2012).
So the question is whether the differences in model set-up affect the range of the results, and whether a mix of models is superior to many simulations with a single model in terms of accounting for the unknowns of climate modelling.
The fuzziness associated with the spread between the model results is often referred to by the catch-all phrase ‘uncertainty‘, referring to (unpredictable) chaotic internal variations, vaguely known forcing estimates, and climate model limitation.
Whereas climate scientists find ‘uncertainty’ difficult, it plays a central role in statistics (Katz et al., 2013). The statisticians are experts at drawing knowledge from a large volume of information, incomplete data samples, and have methods for ‘distilling’ the data (using a phrase coined by Bruce Hewitson). Some interesting methods are regression analysis and factorial design.
It is necessary to bring on board more statisticians to participate on climate research. Hence, the motivation for a Statistics and Climate workshop with a high proportion of statisticians among the participants (supported by the SARMA network, Met Norway, Norwegian computing, and the Bjerknes centre).

Bringing together people from different fields can be challenging, and we sometimes realise that we speak about ‘uncertainty’ or ‘models’, but mean different things. Is ‘uncertainty’ a probability distribution, model error, gaps in observations, inaccuracy, or imprecision?
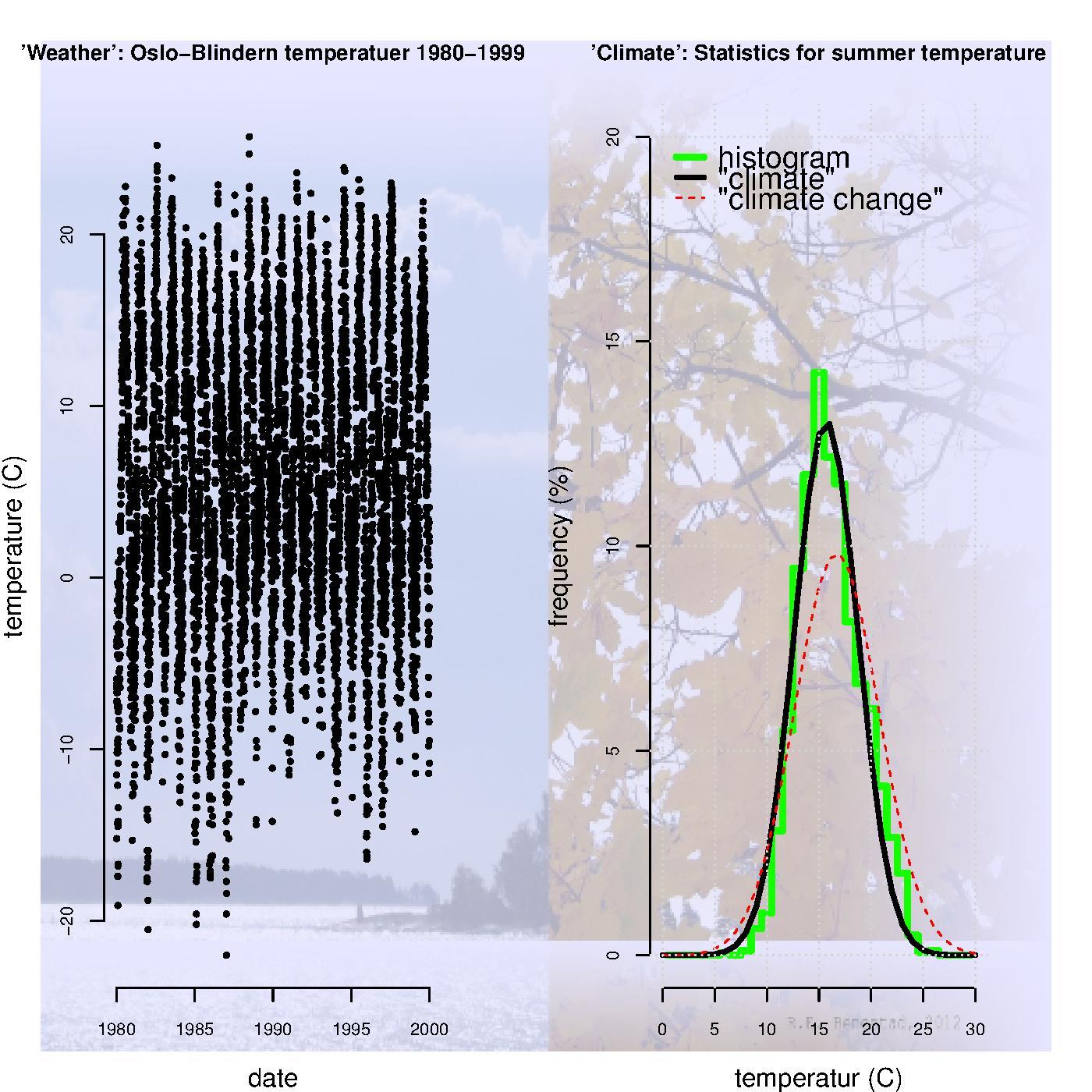
In statistics, a ‘model’ may be a probability distribution or an equation whose coefficients are estimated from the data (‘best-fit’). We can also define ‘weather’ as a time series describing when and how much, and ‘climate’ as a probability distribution saying something about how typical such an event is (illustration below).
During the workshop there were discussions about what is meant by ‘prediction‘ – is it the same as a ‘forecast‘? It is difficult to collaborate before we speak the same language and understand each other.
Sometimes it also may be useful to take a step back and re-examine concepts that we take for granted. It is interesting that the exact meaning of ‘storm‘ and ‘extreme‘ were topics of discussion at the workshop.
Our understanding of physics is needed to identify key scientific questions, but the statisticians have the expertise to design tests based on data and statistics. For instance, we can ask whether the model set-up has a systematic effect on the results of the simulation – as in the text above.
Another aspect is the question of proper sampling. It may be tempting to pick the ‘best’ model for a region, even though the same model performs poorly elsewhere. From a statistical point of view, however, we know that selective sampling will give spurious results, also referred to as a bias.
The Economist recently printed an article with the title ‘How science goes wrong‘, explaining how a bias arises when mostly positive results are reported in the medical literature. This is another form for selective sampling, and for the climate models, it can only be justified if there are physical reasons to exclude a particular model.
Another contribution from statisticians in climate research is to bring in their experience with ‘infographics’ (Spiegelhalter et al., 2011) and ways to convey complex messages through illustrations. This and the ability to make sense of data and model results are valuable for climate services.
We also need reliable data, but there is a concern about the quality (homogeneity) of some of the surface temperature (The International Surface Temperature Initiative ISTI). Resources are also needed for ‘data rescue‘, but it is difficult to find funding for such activity because it is often not regarded as ‘science’.
In addition to high-quality data, we need a common data structure for creating a platform for collaboration that includes observations and different kinds of products (e.g. empirical orthogonal functions), both in terms of data files on disks (e.g. netCDF and the ‘CF’ convention) and in the computer memory.
Standard conventions can reduce the risk of misrepresenting data and make the analysis more transparent. Advanced data structures also make better use of advanced facilities, e.g. the ‘S3’ method in R.
References
- C. Deser, R. Knutti, S. Solomon, and A.S. Phillips, "Communication of the role of natural variability in future North American climate", Nature Climate Change, vol. 2, pp. 775-779, 2012. http://dx.doi.org/10.1038/nclimate1562
- R.W. Katz, P.F. Craigmile, P. Guttorp, M. Haran, B. Sansó, and M.L. Stein, "Uncertainty analysis in climate change assessments", Nature Climate Change, vol. 3, pp. 769-771, 2013. http://dx.doi.org/10.1038/nclimate1980
- D. Spiegelhalter, M. Pearson, and I. Short, "Visualizing Uncertainty About the Future", Science, vol. 333, pp. 1393-1400, 2011. http://dx.doi.org/10.1126/science.1191181
Hi, I’m a theoretical physicist and have followed climate research for something like 20 years. I have actually often been wondering about exactly the topic of this post: the employment of advanced statistical analysis within climate research. From the friends and acquaintances that I have within climate research I never got the impression that the full force of statistical analysis was being used – something which seems to be confirmed by your post. I think it is very important to do so – to perform credible test of hypotheses and to extract information from large sets of data modern statistics seems indispensable.
Thanks for another enlightening post. I found it interesting how much of the issue revolves around language and definitions. When you mention “standard conventions” in the last paragraph, is that what you are talking about: making sure everyone is using the same meaning for the same word (such as ‘uncertainty’) in a given context?
[Response: Yes, that’s part of it, but not the whole story.
There are some conventions already regarding results from model results, naming of variables, and meta-data/attributes (netCDF ‘CF’ conventions used in the WCRP community). The range of data is wider than just model results (e.g. station records, climate proxies and indexes, and various types of analytical results such as empirical orthofonal functions and gridded data), and there is a wider range of formats used among these (try different portals for getting station records and you get ASCII files with differnt looks).
The attributes which already exist are well-defined, but there seems to be a need for a more extensive glossary and more attributes (e.g. on evaluation of the methods in addition to new aspects coming in with more elaborate earth system models). Hence, the idea is to link the attributes and a commonly respected glossary, both for exchanging data between methods or scientists, and between climate services and non-scientists. A common convention could lead to more fruitful collaboration – I call it the ‘lego-principle’ where it’s easier to build on others work. -rasmus]
Thank you for an excellent post!
As a student of climate science with some Physics training, member of AGU and AMETSOC, and as professional statistician, my view of what I have seen is less like the situation in the medical community where sometimes statistics is brought in as an afterthought (but see http://biostat.mc.vanderbilt.edu/wiki/pub/Main/FHHandouts/bayes.short.course.pdf), and more that climate science is being asked to do more and more with less and less, including being coupled to economic and policy models. As it stands, Geophysics (catchall for Climate Science and Oceanography and Atmospheric Sciences and …) is a descriptive and explanatory discipline. It has, in many areas, properly adapted to the Bayesian revolution. But to the degree to which The Public asking what, from a purely scientific viewpoint, might be Unreasonable Questions regarding time frames and attributions of specific phenomena, the standard Bag of Tricks seems strained.
Here, then, is the place, need, and role for a fervent community of statistically minded explorers, ones who can, because of experience with Economics and even Political Science, bridge the gap between phenomena and characterizations of risk, and do it in ways that can inform policy and The Public. This is why in climate work, as in my own professional practice, I find Bayesian approaches so valuable: They allow answers and estimates and decisions from nearly any motley assortment of information, and declare how good their assessments are.
There’s also a need, I think, to work these at multiple time scales. We, collectively, want to know what the next decade or two will bring. But, in the end (or in the limit), greenhouse gas emissions need to get to as close to zero as they can be, irrespective of what’s finally decided about geoengineering, and asymptotic impacts on civilization are likely to be substantial, even if we do get our collective act together. The long view is one of the purposes of The Azimuth Project (see http://www.azimuthproject.org/azimuth/show/HomePage) spearheaded by Professor John Carlos Baez.
Meanwhile, there’s lots that can be done with checking assumptions of analyses, and bringing the best known to bear upon climate questions, in the small and in the large. My sense is that statisticians working in time series and Bayesian methods just love to crank on new kinds of problems, in part to show off new algorithms, in part to strain and test them with genuinely hard tests, and in part to serve.
Thanks again.
Is there some kind of a summary article or book I could read on statistical methods in climate science? Statistical inference is a subject close to my heart, and I am particularly interested in the methods used to reconstruct historical temperatures from various proxies, as well as CO2 content. I imagine these are well-understood problems, so I am hoping for a reference that is readable by a physicist with a background in statistics but very little in climatology.
[Response: Von Storch and Zwiers, Statistical Analysis in Climate Research is an excellent reference. CO2 content does take much statistics (other than the statistics of instrumentation — reproducibility of measurements –something that is pretty simple and really well understood) since it is a globally well mixed gas. Temperature is harder since getting from proxies to temperature is not straightforward, and then averaging properly over the globe requires some form of interpolation. Lots and lots of literature on this. –eric ]
Is Nassim Nicholas Taleb invited?
This ties in nicely with the recent paper by Cowtan and Way. Geostatistics is an advanced discipline at this point and I was really quite surprised that something like their work wasn’t already part of the routine workflow.
I am starting a small software business based on science apps. The first one available lets you generate a semigray greenhouse scheme for Venus, Earth, and Mars. http://bartonpaullevenson.com/International%20Levecor.html
If you get a chance, check out pp.38 in the current (Dec 2013) issue of Wired. In their Jargon Watch dept, you’ll find a definition for “cli-fi” … pretty cool, huh?
Wonderful post, thank you so much.
It is refreshing to see source climate statistics instead of seeing its vocabulary misapplied to support self-delusion of climate change causation – as: “Did global warming cause this weather event?”
It may be worth further simplifying your perfect weather/climate definition, now to say that a series of weather events makes up a climate, and climate is defined as a group of weather events. Your definition is more concise and correct, but in plain speaking, I want to say that EVERY weather event – even the most anomalous, works to define a climate, and any newly defined climate will include the weather events that define that climate.
In the past I have been shocked to hear meteorologists publicly address the issue and apply the 30 year rule to define a changed climate. By confusing causation and correlation- it works to misdirect a lay audience. I, along with the press need a fundamental understanding of climate statistics, Thanks for the links and lesson plan.
Perhaps we can now answer this way: “No. global warming did not cause this storm, but it certainly correlates with our warming, destabilizing climate.”
Standards in data formats is a great idea. To see this in a wider context, I wish biologists could get their heads around this (I do bioinformatics). Take just one kind of data: short segments of DNA sequence. These are usually published as genomic coordinates (chromosome, start and end positions), rather than the actual sequences, since this is generally more compact. Now you start running into problems:
– there can be more than one instance of the same genome with slight variations even though they are ostensibly the same version
– some use 0-based coordinates, others 1-based coordinates, and the format doesn’t always make it clear which is intended
– coordinates are often reported in tables in formats not designed for easy extraction by scripts like MS Word, Excel or worst of all, PDF
A big part of the problem is that the reward system targets publishing, rather than data management. Even journals that actively encourage supplying data don’t police the reusability of the data too closely.
On the whole reusability of climate data is not that bad compared with some other sciences. At least a fair amount is published in clearly documented formats.
@5 Greenish says:
“Is Nassim Nicholas Taleb invited?”
LOL! Thanks Greenish, you just made my day! BTW, Good to see ya here.
Cheers,
Fred
I enjoy this site even as only a science dilettante. I need help (ideally from a real climate scientist). A long time online chess buddy is claiming to be a scientist and is showing signs of denialism saying the media is exaggerating and in turn influencing science. Could you please visit the following link and please at least make a short response to his posts – his username is turbojuice (I am billyraybar). Thank you.
http://rybkaforum.net/cgi-bin/rybkaforum/topic_show.pl?dln=526141;pid=491840
Sorry, Bill–following the link brought up “access denied.”
Some media do, in fact, exaggerate warming claims. The point is to focus on the science and the peer-reviewed literature not the politics and the blogs. Of course he won’t want to hear that unless he’s a scientist.
For some additional context, see Climate and Statistics Workshop @ NCAR, 2007, which had both good climate scientists who did statistics and statisticians generally involved with climate and/ore geospatial work, on this agenda.
Most talks are good (one isn’t), but I especially recommend (statistician) Jim Bergman’s presentation, including thoughful comments p.19:
‘How can statisticians become involved?
The Key: Becoming involved in a ‘team environment’ with scientists.
Facilitating infrastructure:
• NCAR, where teams operate
• SAMSI (and NPCDS), where teams can be formed
• National labs (both LANL and LLNL have climate/stat teams)
• Large interdisciplinary grants available today
Barriers:
• Statistics cannot generally fund involvement of statisticians in other
disciplines which, in turn, rarely have much money for statistics.
• Shortage of statisticians
• The time needed for a statistician to get deeply involved with
another science and to also learn the statistics needed for it.
• Scientists often have a hard time judging what they can do
themselves and when they should seek statistical help.’
Bill #12: what the media exaggerate is the contrarian case. It’s tobacco and AIDS denial all over again – a faux debate. There are many uncertainties in the science and the occasional finding that pokes holes in details, but claims that warming stopped in year X, there is an ice age imminent, etc. are given undue prominence when there is no real evidence for this sort of position, just as there is no real evidence that tobacco isn’t a health hazard, or HIV doesn’t cause AIDS.
Science is never 100% certain – anyone taking a contrarian position who is 100% certain is not taking a scientific position, but the media mistake this sort of bravado for a real position on the science.
Nice article thanks. Yes there’s complexity of experts managing mathematical models and statics. The major over-riding issue that causes ‘extreme events’ in understanding across the board about climate science is “semantics” – not enough attention is spent on this.
what can make sense to scientists and mathematicians still will not make sense to 99% of the worlds population.
and thus the Blogosphere and think tanks of raving nutters on climate science.
The responsibility of being clearly understood is totally upon the shoulders of those wishing to communicate something from themselves to others. Until that is improved doesn’t make much difference how good or accurate the science is.
imho, the worst thing that has negatively affected global understanding of the importance of climate science and future risks was in fact Al Gore’s Inconvenient Truth. Good intentions can sometimes be a road to hell. cheers fwiw. sean
The ASA’s blog seems to have gone silent, anyone know more?
http://statisticsforum.wordpress.com/
Sean: “The responsibility of being clearly understood is totally upon the shoulders of those wishing to communicate something from themselves to others.”
Horse crap! Communication is a two-way street, and half the fricking country has barricades of burning tires set out just to forestall any efforts at scientists trying to make inroads. There is no shortage of talented communicators telling anyone who will listen how deep we’re in the mud. They can express it at any technical level with any degree of politeness, and they will be met with morons who insist that their ignorance is superior to the expertise of the expert.
Here’s a newsflash, Sean. Al Gore got most of the science right! He and his message were attacked solely because he was Al Gore. What is more, Al Gore was saying the same things for over a decade before AIT. At any time, one of his many conservative colleagues from the Senate–who know as well as Gore does that the threat of climate change is real–could have stood up with him. Voila! The politics would have been neutralized. But where was John McCain? Where was Colin Powell? Hell, even Dubya had to ultimately admit climate change was real.
Climate change is only a political issue because half of the political spectrum in the US, the UK and Oz lack the courage to admit it is real.
@19 Hi Ray. ‘relax’?
re “Horse crap! Communication is a two-way street,..” No it is not mate. Dialogue and discussion is a two way street. Moving knowledge from point A to point B in a manner that it will “effectively” be understood by B is a ONE WAY street.
That is the issue I was speaking to. And it is not ‘horse crap’, it’s valid true and correct. In my personal experience (including mngt and staff training 1on1 and in a classroom) and my firm opinion. I also believe there is manifold evidence of this in academic circles in particular linguistics, advertising, and human psychology fields. You may disagree, that’s fine.
My comment about Al Gore (who I admire for doing what he did btw) had nothing to so with what % of the science he got right. This is a comments section so i try to keep it short. have another look what I said “the worst thing that has negatively affected global understanding”. In retrospect I believe there was a better way, as it caused more problems in understanding over time than it solved.
The IPCC or some other formal body would have been better placed to “produce” such a work as Gore did and simultaneously taken full responsibility for what was presented .. and then followed through with such a marketing / information / education campaign to politicians, public leaders, business, and the public.
These “one offs” uncoordinated attempts by individuals incl real climate have very limited positive impact in public opinion overall. Why? Because they are easily undermined by a more coordinated “marketing campaign” that is highly funded by very serious self-interest groups and self-opinionated elites with an over inflated view of their own abilities, insights, and wisdom.
also fwiw re: “Climate change is only a political issue” … because it was always a “political” and “public policy” issue and not a science issue. On this score ex-PM John Howard is correct. But that’s the only bit he got right in his recent speech. Best to you.
@19 ps And I stick to this …. “The responsibility of being clearly understood is totally upon the shoulders of those wishing to communicate something from themselves to others.”
It doesn’t mean that some people on the receiving end might well be intellectually incapable of comprehending nor may refuse to listen. But that is a different story. The responsibility first rests with the speaker not upon the receiver. If one cannot gain and hold the attention of the public, it is NOT the public’s fault. Is this not true? If not why not?
These comments go back to the statistics issue of the article. Even between intelligent acadmeics issues arise over “semantics” and meanings of statistical terms and methodoliges. If they have difficulty, then poor old Joe Public with the matter of “semantics”. Poor use of words leads to confusion.
In the IPCC glossary AR4 & AR5 they speak of forecasts, projections, predictions and predictablilty. The nuances may be clear to a climate scieitists or IPCC report author, but the only thing the public get is the glossary. menawhile the IPCC Reports do not in all cases follow the word meansing in the glossary anyway – plus sceptics never follow the meaning s and make it up as they go. With no care no resposnibility whe they misrepresent the IPCC Authors.
How dare they do that and get away with it? I say this – the IPCC allows it in the first place and left the field of play leaving it to Al Gore, and any other motivated individual to do the “communication” job they have not done. Thus it is all screwed up over crap like “hiatus / pause / not hitting “the IPCC predictions” etc. What ‘predictions’ I ask? The IPCC don’t do ‘predictions’ anyway. Not in the SEMANTIC sense that word has in the real world of Joe Public. THUS the naysayers win, because it was so easy to win.
Unless Ray or anyone else can prove to me that a 6 month old baby or a 3 year old child is 50% or equally responsible for the communication process of a parent educating them about life’s basics and who is in charge… & responsible for ‘communication’ …… ? Cheers
Sean: “Poor use of words leads to confusion.”
There’s quite a.bit of both in your posts.
You have pretty clearly communicated your desire for conflict.
Please, take that somewhere else.
If you’d like to try again,
an outline might help you organize your thoughts.
Complete sentences, capitalization, and punctuation are important,
Then, one or two points clearly stated and supported.
Constructive dialogue is possible here, in these comments.
But you’ll have to try a lot harder.
Sean,
Communicating something as complex as AGW, essentially involving the whole field of climatology, in a complex, global, political environment is never going to be tidy as say, a chess game. Though I’ll admit there has occasionally been some resistance when it comes to prying tetchy climate nerds out of their ivory towers.
Sean,
A few comments.
Sean: “The responsibility first rests with the speaker not upon the receiver.”
I’m gonna go out on a limb here and guess that you haven’t interacted with teenagers much. Dude, if an audience is not willing to entertain the message, it doesn’t matter how the speaker presents that message.
Sean: “The IPCC or some other formal body would have been better placed to “produce” such a work as Gore did and simultaneously taken full responsibility for what was presented.”
Because nobody has ever challenged anything the IPCC has said. Unh-unh. No way. Never. Dude, did you just wake up after a 30 year nap? The IPCC is one of the most villified organizations on the planet. There are nutjobs that think they have their own black helicopters and death squads! And some of them are in the US Senate!
OK, Sean, convince me. Give me 10 concrete things scientists should be doing that they aren’t already doing–keeping in mind that they are first and foremost scientists who already have the overwhelming responsibility of increasing human understanding of the planet’s climate. Don’t give me BS suggestions like “Scientists need to speak up!” They are already doing it–and getting death threats when they do. Don’t tell us they need to engage the public and explain the science–they are already doing that and being shouted down when they do. Don’t tell me that they need to advise policy makers. They are already doing so for those who will listen. And for their trouble, they are branded “activists” and accused of perverting science.
Sean, you may get the feeling I am sensitive about this. I am. I’ve been fighting this fight for 2 decades, and at this point it appears to me that we have convinced all of the reasonable humans already. The rest are ineducable–or put another way, too cowardly to face the truth. As with every other existential threat humans have faced in the past century, the only ones who can save our pathetic species are the scientists, and as usual if we succeed, the thanks we will get is being called alarmists by the great unwashed we have saved. If we fail, we’ll be blamed by the likes of you.
Sean wrote: “the worst thing that has negatively affected global understanding of the importance of climate science and future risks was in fact Al Gore’s Inconvenient Truth.”
With all due respect, that’s utter nonsense.
Al Gore’s movie did not in any way “negatively affect GLOBAL UNDERSTANDING of the importance of climate science and future risks”.
On the contrary, by effectively and accurately communicating the current scientific understanding of anthropogenic global warming, Al Gore’s movie contributed powerfully to better “global understanding” of the nature, severity and urgency of the problem.
Your error is to confuse the delusions of brainwashed mental slaves of partisan Republican propaganda that has demonized and vilified Al Gore for over 20 years with “global understanding”.
In reality, the victims of Fox News who turn red-faced with rage and begin spouting crackpot conspiracy theories about the IPCC at the mere mention of “Al Gore” are actually a miniscule minority compared to “global” public opinion.
> Sean
Refute his opinion with data. E.g.
Refute! Refute! Refute!
PS: Andrew Gelman was soliciting vignettes from scientists using statistics, early this year; perhaps he never got any, or he got distracted by the Wegman stuff, or … dunno. Y’all might try sending him some sketches and see if he’s interested.
http://andrewgelman.com/2013/01/17/wanted-365-stories-of-statistics/
As far as contrarian arguments go:
I have found that most of the arguments (if not all) are simply “raising reasonable doubt.” The contrarians essentially do what a good lawyer would do in criminal court when there is no exculpatory evidence. And I have to admit, some of the contrarians have been doing this very skillfully.
Unfortunately (for them) reasonable doubt has very little weight in scientific research – because it shouldn’t. Oddly they don’t seem to understand that.
But reasonable doubt appeals very much to common sense intuition. And so it dominates the discussion – in the minds of skeptics – and seems to be a valid reason to reject global warming.
It’s not that scientists don’t communicate – they do – it’s that they can’t break through this barricade created by the contrarian’s reasonable doubt.
Retrograde Orbit wrote: “I have found that most of the arguments (if not all) are simply ‘raising reasonable doubt.’ The contrarians essentially do what a good lawyer would do in criminal court when there is no exculpatory evidence … Unfortunately (for them) reasonable doubt has very little weight in scientific research …”
The problem with that is that the so-called “arguments” of the so-called “contrarians” don’t actually raise “reasonable” doubt. They just spout lies and nonsense.
A “lawyer in criminal court” would be held in contempt if his defense consisted of nothing but blatant laughable falsehoods, and accusations that the judge, prosecution, police, and indeed every law enforcement agency and judicial system in the world were all conspiring to frame his client:
“The prosecution’s case rests on multiple eye-witnesses and ballistic evidence which they claim prove that my client shot the victim — but ladies and gentlemen of the jury, the explosive properties of gunpowder are merely an unproven theory and what’s more the prosecutor is a liberal, and fat.”
The “reasonable doubt” argument relies on the idea that we shouldn’t make radical changes to our way of life before being absolutely sure. This argument fails in two important ways. First, we can’t be absolutely sure of anything in science. Second, not doing anything about our fossil fuel habits is highly likely to make radical changes to our planet’s environment. Turning the argument around, we shouldn’t continue to burn fossil fuels without limit UNLESS we can be reasonably sure that doing so won’t lead to significant harms. But, in fact, we can be reasonably sure that continuing on the present course will lead to serious problems in as short a time as 50 to 100 years.
“But reasonable doubt appeals very much to common sense intuition. And so it dominates the discussion – in the minds of skeptics – and seems to be a valid reason to reject global warming.” If a tidal wave seems to be approaching your house on the beach, does “reasonable doubt” suggests you shouldn’t move to higher ground unless you can be absolutely sure you will be swept away if you don’t?
@24 Ray .. “I’m gonna go out on a limb here and guess that you haven’t interacted with teenagers much.” Poor call there: Would father of 4 and a manager of McD+ more count? :)
“Dude, if an audience is not willing to entertain the message, it doesn’t matter how the speaker presents that message.” Totally agreed. imho Al Gore proved that people were willing to listen and they went in droves. People who go to Blogs for whatever reason are also willing to listen too. Problem there is they are manipulated via sophistry and don’t realise it. Once you lose those people they are gone. Some people who went to see Gore and accepted have later switched to believing the blogosphere and Monckton level BS instead.
I get your angry and frustrated. So am I. I am not your enemy.
So I will close on this good point of yours Ray point especially in regard one particular sensitive reply : “if an audience is not willing to entertain the message” … see you, it’s a waste of time here.
My parting gift is http://www.abc.net.au/local/stories/2013/11/18/3893227.htm?site=conversations
See you all on the other side of the climate disaster that’s coming.
Would father of 4 and a manager of McD+ more count?
How about a State Training Manager role? How about being in charge of running all aspects of a $40 million per annum business 7 days per week with 900 staff and 90% of them under 25 years old? Just a glib passing comment.
None so blind as those that do not wish to see.
“But how do we make sense out of all this information?” I think there is a album from Rush that depicts your conundrum.
The fact that different models produce different results is a good example of something that could be exploited to seed reasonable doubt. No, the contrarians don’t need to lie, a little bit of rhetoric will do the trick. That’s why seeding reasonable doubt is such a hideous tactic.
And I am going off topic here, sorry …
Seeding reasonable doubt to sink a scientific theory is not exactly brand new. The proponents of Creation have used it for 150 years to battle the theory of evolution. And they have been fairly successful – as far as public opinion goes. And I am worried the same will happen for climate change.
Sean,
Yup. No concrete suggestions. Just, “Communicate better.” Great. Thanks.
(Several year reader, first time commenter)
A recent survey published in USA Today and elsewhere shows, to my mind surprisingly, that significant majorities in every surveyed US state–something like 45 of them–think AGW is real and want something done about it. That very little is done is, to my mind, thus not really a communication problem (a convincing problem) anymore. Yes, scientists and statisticians can always learn to communicate their knowledge more effectively and that definitely can help, but I think it’s mostly at the margins. The problems are power politics, money, and status-quoism, generally speaking. Thus I find this particular discussion in the comments section much ado about very little. (FWIW I’m never convinced by blog commenters referring to their own longtime experience as warrant for the veracity of their arguments, so I’ll refrain from sharing mine.)
Ray,
Yup. No concrete suggestions. Just, “Can’t Communicate any better.” and “It’s all THEIR fault!” Great. Thanks. Cya.
@ 29 SA .. that argument of yours is as good as any on a climate science denier website. Full of holes throughout it. But to you, you’re a genius, with nothing left to learn. Therein lays the nexus of the problem. people who do not know how they themselves communicate telling others why their ideas and communication is all so wrong. Don’t go defending yourself in court, or taking civil law suits out on others. You have no idea about how a Court operates and how little reliance there is on ‘evidence’.
Retrograde Orbit, don’t waste your time, go back to lurking and using the site as a source only. These guys know it all already. That’s why the everything is going so smashing with the IPCC and UNFCCC and GHG cuts.
@38 Aaron maybe the recent US survey you mentioned is one I’m also aware of which I won;t bother giving a link to either. There are others of course by academics sources in 2011 and 2012 which paint a very different picture entirely. Which is more accurate requires more thorough analysis than a comment. A bit like GCMs perhaps? Not as simple as it may appear on the surface. :) And drawing conclusions from the latest news report and using that to suggest a pov is probably flawed by default is risky business. imho and ime.
Meanwhile what’s the reality? The IPCC process started 25 years ago now. What’s the outcomes on the ground today? Has the US ratified Kyoto or been able to lead the world to an even better global agreement yet? If any vote went to congress on Climate Change issues would it pass both houses? Has the EPA been empowered to monitor Shale gas/csg projects according to the Clean Air Act yet? Would that get through Congress or the media scoundrels? What actual position did the US take to COP19 in Copenhagen 2009 and now the meeting at Warsaw? These are the questions in my mind that count for more than the latest public opinion poll.
This is where the tyres meet the road. Theory is wonderful, so too positive thinking, as are thought bubbles and assumptions without solid evidence to support them bar an ‘opinion’ that well ‘it feels right to me.’
But luckily the IPCC formally did take on Lord Monckton publicly proved to all he was a flake who manipulated materials, lied through his teeth, had no basis for his claims, and destroyed his ludicrous reputation across the world as an intelligent human being interested in the truth of Climate Science. Oh, hang on. Sorry, I got that wrong. That didn’t happen because Monckton is still out there and pops up all over the world on radio talk backs shows and the Murdoch print media or Fox News where everyone makes fun of these deluded climate scientists … people just like Gavin, Rasmus, and Stephan without a word being said, and not one single press release in 25 years.
By saying “scientists and statisticians can always learn to communicate their knowledge more effectively” shows you are not really interested in the issue I raised. So i’ll leave it there.
Wotan and Way have been posting to Curry’s blog this week. I hope they know what they are doing. And don’t end up like a polar bear dancing on the melting arctic ice flows as a result.
Aaron when someone defaults to presumptuous rhetorical questions as a tool to put another down and dismiss their pov out of hand, one has a choice of ignoring it or responding. But when someone asks a question on a discussion board the first thing they should assume is that someone might just answer it. The response will likely follow the original tone and attitude of the question and how respectful and genuine that was. Had Ray been genuine I would have gladly emailed him life’s Resume. But of course that wasn’t the point was it? :)
I have been online since 1995 ie 18 years. I have a ‘little’ experience on Usenet and Discussion boards along the way. Very direct and confronting at times. But not always. I think I have a learnt a lot. One of those was to never make hasty decisions about others. Another was how to ask really good and genuine questions to illicit much needed information from others.
But that’s not all I learnt. Now that link I left as a gift. The author is a high grade academic with an excellent reputation. Richard King, look him up. But please whatever you guys do do not listen to the 1 hour interview nor read his book. I’d hate to hear about the impact of any cognitive dissonance such a step may cause innocent victims as a result of me sharing that URL. So best ignore that too, and I’ll just run along. Best to you, and yours. [sincere apologies for the length and wasted bandwidth]
Yes I too see a disturbing trend of digging trenches and drawing battle lines.
Yup. When paid lobbyists start showing up in large numbers at scientific meetings, paid results can’t be far behind.
That’s not what I mean. Above Ray said:
“and at this point it appears to me that we have convinced all of the reasonable humans already. The rest are ineducable–or put another way, too cowardly to face the truth”
That sounds like drawing a battle line: You are either with me or you are against me! If you are still on the other side of the line you must be against me! I stopped trying to convince you I am going to fight you now!
I understand Ray’s anger and frustration. But still, the drawing of battle lines is not helping.
That’s not what I mean. Ray said above:
“and at this point it appears to me that we have convinced all of the reasonable humans already. The rest are ineducable–or put another way, too cowardly to face the truth”.
That sounds like drawing a battle line: “You are either with me or against me, and if you are still on the other side of the line you are against me.” I understand Ray’s anger and frustration, but I doubt that drawing battle lines will be of any help.
Er, it’s when the lobbyists turn up at the science sessions — money, in large amounts, starts to be obviously spent — that yer battle lines are getting not just drawn but entrenched. That’s big money, coming out of the shadows.
Remember, it’s better to fund the controversy on all possible sides — that’s how you set scientists up to teach the controversy.
There’s no question of commercial importance that can’t be put off by a pious appeal to and funding of further research.
Similarly, there is a significant gap between public perception of scientific consensus and the 97% reality.
A 2012 survey found that 57% of Americans either disagreed with or were unaware of the fact that most scientists agree global warming is happening.
This matters because perceived consensus is a strong predictor of support for climate policy. When people think the scientists agree, they are more likely to support climate action.
http://environment.yale.edu/climate-communication/files/Climate-Beliefs-September-2012.pdf
Unfortunately, mainstream media outlets are perpetuating the misconceptions. One way they achieve this is by granting outlier voices disproportionate visibility in the public arena, creating misleading and counterproductive debates.
http://link.springer.com/article/10.1007/s10584-013-0704-9
In the survey of surveys was Q. “Warming is extremely important personally (and is likely to influence voting)”.
Here are the results for some the states, random sample. Nevada 12%, Florida 14%, Louisiana 9%, Alabama 7%, Montana 5%, New Jersey 12%, West Virginia 6%, New York 11%, Rhode Island, Delaware 8%, Michigan 8%. I could have looked at more but a pattern is emerging. (It looks more like the green vote?)
Something is going on in this survey behind the top line figures, I suspect that respondents are trotting out the “right” answers to the **motherhood** questions like “Global warming has been happening” but giving some more thought to those questions that require a more measured PERSONAL response.
This can be seen in the huge disparity (disconnection) between the strong agreement with, say, the question “Warming will be a serious problem for the world” [ ~70% ] Compared with the massive disagreement with the “Warming is extremely important personally” [ ~7-12% ]
These kinds of disconnects have been showing up in many surveys for many years, across all nations not only the US. imho.
Sean,
You did not ask for any concrete suggestions. You merely sought to blame the current situation on poor communication by scientists. I’ve actually been meaning to write up some general guidelines for the public consumer of scientific information since the piss poor article in The Economist about how science is on the verge of failure. That article suffered from the same myopic view of how science works that you are demonstrating.
Part of the problem is that people view this situation in isolation. There is a very, very long history of scientists calling attention to potentially severe threats to civilization. They are invariably met with derisive cries of “Alarmist!” by laymen who have neither the acumen to understand the problem nor the courage to accept that it is real. When the scientists eventually come up with a technical solution and the problem ameliorates, the doubters take the resolution as proof they were right all along.
One of the first examples I can think of was the crisis near the turn of the 19th and 20th centuries when soils were becoming depleted of nitrogen. This problem was deemed sufficiently severe that Fritz Haber was given a Nobel in Chemistry for figuring out how to synthesize ammonia despite his later role as the father of chemical warfare.
Later scientists who called attention to the dangers of exponentially growing population were deemed with the same epithet of alarmist when the green revolution postponed the inevitable demographic catastrophe.
The ozone hole? Identical. You often see climate denialists trotting out this example as “proof” that scientists are lying to keep people in a state of fear. This was also a good example of industry PR lasting long after the industries involved had moved on.
The Y2K bug. Same thing. People claim it was overblown. I know for a fact how much work it took to fix it, because I know people involved.
The dangers of tobacco–this is the most direct analogue, since the denial industry features many of the same players. John Mashey has written extensively on the connections. It is also interesting to look at the connections and similarity of tactics adopted by the anti-science forces here and those adopted by anti-evolution/creationist movements.
In all of the late 20th century/early 21st century examples, there has been a concerted effort by spin doctors to erode peoples’ faith in science. And I am afraid that faith may be all science has to offer the crowd who are more concerned with the antics of the Kardashians and UFC/NASCAR than the real world.
Retrograde Orbit, your post reminds me of the observation that class warfare occurs whenever the poor become so exasperated that they return fire on the filthy rich. We are already in a war. If we don’t draw the battle lines, they will draw themselves.
Op. cit.: Why did business not react with precaution to early warnings?
[PDF]
Sean, I was responding to the idea that the reasons for public misunderstanding of the science ‘n statistics, and much more importantly, public inaction on climate change, belongs to bad communication on the part of scientists. I was trying to suggest that in the broadest terms, this seems now to be untrue and that the problems lie elsewhere. Your own most recent post all but confirms this (with some wiggles around the issue of “scientific consensus”). The percentage difference between those who think AGW is real and those who think it’s “extremely important personally” is huge, as are the two ideas themselves. This is not a problem for scientists communicating science. It’s a cultural/political problem, and in that instance it’s much more about dialogue and on-the-ground interaction between stakeholders than any abstract concern with scientific consensus, etc. (Poll your neighbors: I will wager two things: 1)a very large percentage of them will have an opinion on climate change. 2)a very small percentage of them will have even heard of the “pause,” whatever their opinion.) Communicating science is only one relatively small part of a huge mosaic of responses to the reality of the climate crisis.