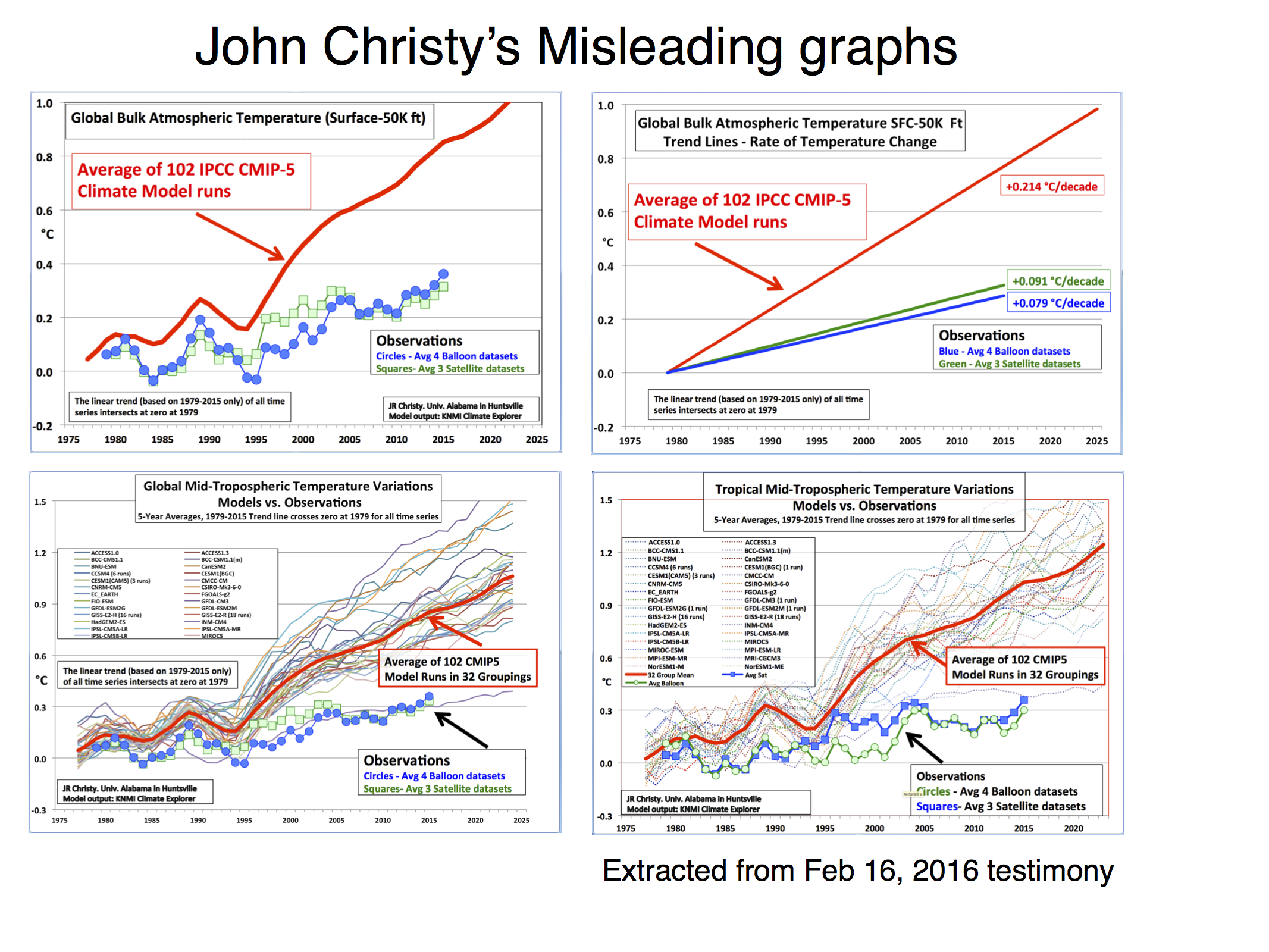
Gavin has already discussed John Christy’s misleading graph earlier in 2016, however, since the end of 2016, there has been a surge in interest in this graph in Norway amongst people who try to diminish the role of anthropogenic global warming.
I think this graph is warranted some extra comments in addition to Gavin’s points because it is flawed on more counts beyond those that he has already discussed. In fact, those using this graph to judge climate models reveal an elementary lack of understanding of climate data.
Different types of numbers
The upper left panel in Fig. 1 shows that Christy compared the average of 102 climate model simulations with temperature from satellite measurements (average of three different analyses) and weather balloons (average of two analyses). This is a flawed comparison because it compares a statistical parameter with a variable.
A parameter, such as the mean (also referred to as the ‘average’) and the standard deviation, describe the statistical distribution of a given variable. However, such parameters are not equivalent to the variable they describe.
The comparison between the average of model runs and observations is surprising, because it is clearly incorrect from elementary statistics (This is similar statistics-confusion as the flaw found in the Douglass et al. (2007)).
I can illustrate this with an example: Fig. 2 shows 108 different model simulations of the global mean temperature (from the CMIP5 experiment). The thick black line shows the average of all the model runs (the ‘multi-model ensemble’).
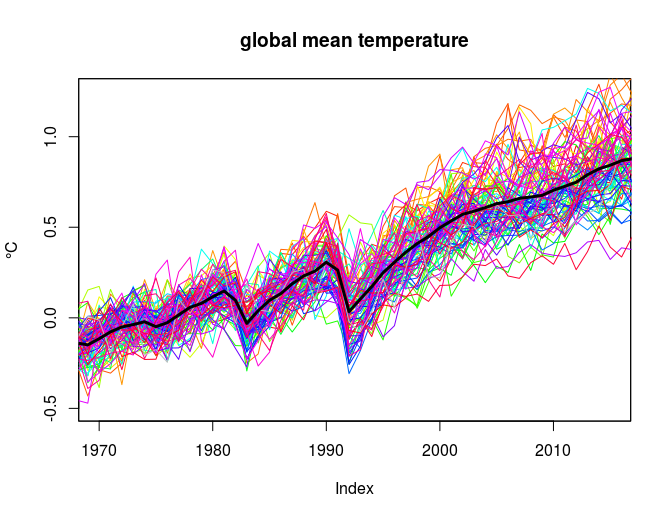
None of the individual runs (coloured thin curves) match the mean (thick black curve), and if I were to use the same logic as Christy, I could incorrectly claim that the average is inconsistent with the individual runs because of their different characters. But the average is based on all these individual runs. Hence, this type of logic is obviously flawed.
To be fair, the observations shown in Cristy’s graph were also based on averages, although of a small set of analyses. This does not improve the case because all the satellite data are based on the same measurements and only differ in terms of synthesis and choices made in the analyses (they are highly correlated, as we will see later on).
By the way, one of the curves shown in Fig. 2 is observations. Can you see which? Eyeballing such curves, however, is not the proper way to compare different data, and there are numerous statistical tests to do so properly.
Different physical aspects
Christy compared temperatures estimated for the troposphere (satellites and balloons) with near-surface temperature computed by global climate models. This is a fact because the data portal where he obtained the model results was the KNMI ClimateExplorer. ClimateExplorer does not hold upper air temperature stored as 3D-fields (I checked this with Geert Jan van der Oldenborgh)(correction: ‘taz’ is zonally integrated temperature as a function of height but does not take into account the differences between land and sea. Nevertheless, this variable still does not really correspond closely with those measured from satellites)
A proper comparison between the satellite temperature and the model results needs to estimate a weighted average of the temperature over the troposphere and lower stratosphere with an appropriate altitude-dependent weighting. The difference between the near-surface and tropospheric temperature matters as the stratosphere has cooled in contrast to the warming surface.
Temperature from satellites are also model results
It is fair to compare the satellite record with model results to explore uncertainties, but the satellite data is not the ground truth and cannot be used to invalidate the models. The microwave sounding unit (MSU), the instrument used to measure the temperature, measures light in certain wavelength bands emitted by oxygen molecules.
An algorithm is then used to compute the air temperature consistent with the measured irradiance. This algorithm is a model based on the same physics as the models which predict that higher concentrations of CO2 result in higher surface temperatures.
I wonder if Christy sees the irony in his use of satellite temperatures to dispute the effect of CO2 on the global mean temperature.
It is nevertheless reassuring to see a good match between the balloon and satellite data, which suggests that the representation of the physics in both the satellite retrieval algorithm and the climate models are more or less correct.
How to compare the models with observations
The two graphs (courtesy of Gavin) below show comparisons between tropospheric mean temperatures (TMT) that are comparable to the satellite data and include confidence interval for the ensemble rather than just the ensemble mean. This type of comparisons is more consistent with standard statistical tests such as the students t-test.
{kind=link}
The graphs also show several satellite-based analyses: the Remote Sensing Systems (RSS; different versions), University of Alabama in Huntsville (UAH; Different versions), and NOAA (STAR). All these curves are so similar (highly correlated) that taking the average doesn’t make much difference.
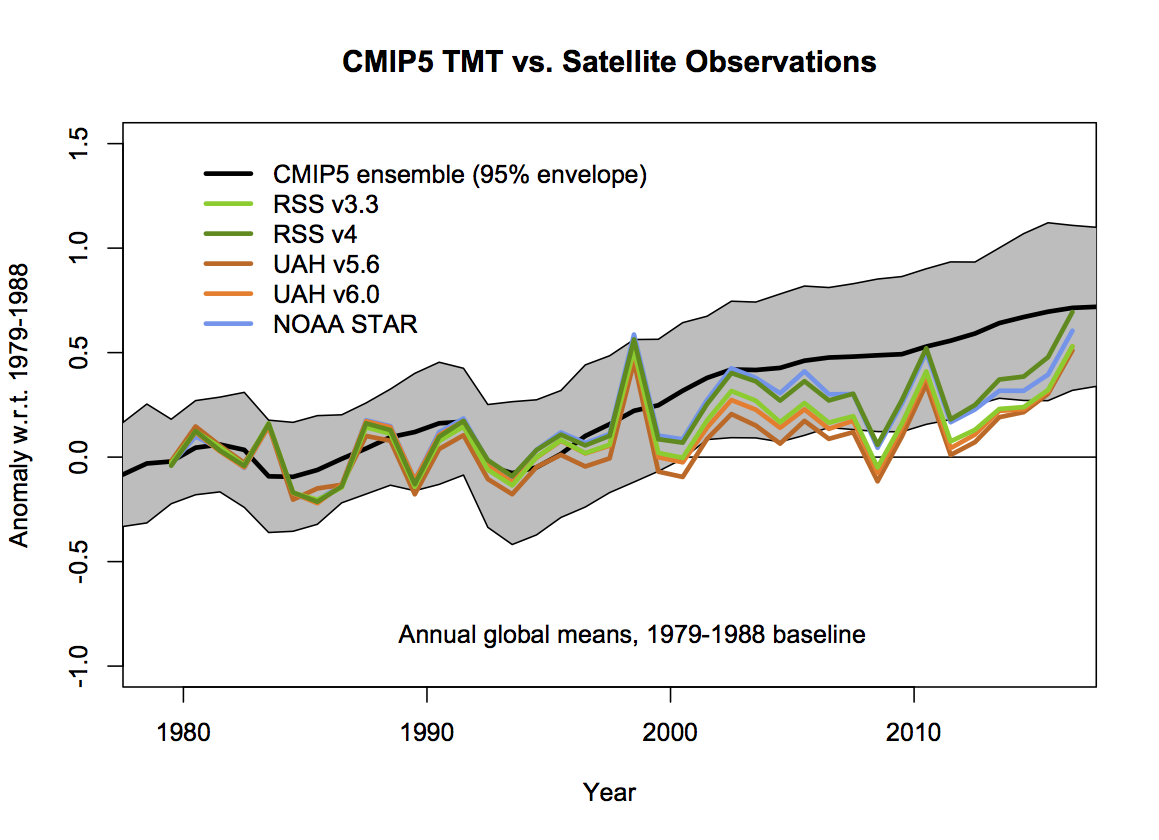
According to Fig. 3, the tropospheric temperature simulated by the global climate models (from the CMIP5 experiment) increased slightly faster than the temperatures derived from the satellite measurements between 2000 and 2015, but they were not very different. The RSS temperatures gave the closest match with the global climate models.
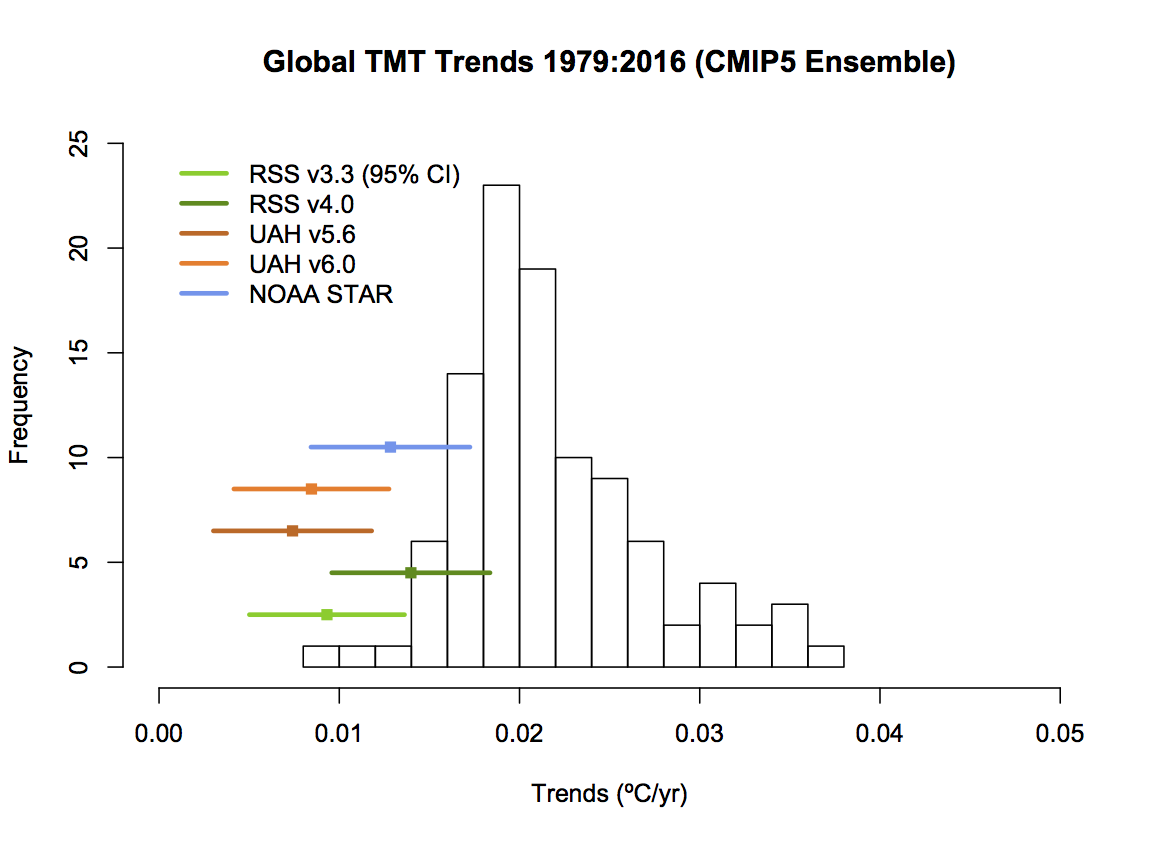
Fig. 4 shows a trend analysis for the 1979-2016 interval where the satellite-based temperature trends are shown with appropriate error bars. The trends from the satellite analyses and the model results overlap if the confidence limits are taken into consideration.
The story behind the upper tropospheric warming
The biggest weight of the troposphere temperature trends come from the tropics because it accounts for the largest volume (half of the Earth’s surface area lies between 30°S and 30°N due to its geometric shape), and they are therefore sensitive to conditions around the equator. This is also where large-scale convection takes place that produce bands of high clouds (the Inter-Tropical Convergence Zone – ITCZ).
Cloud formation through convection and condensation is associated with release of latent heat and influences the temperatures (e.g. Vecchi et al., 2006). It is part of the hydrological cycle, and a slow change in the atmospheric overturning, moisture and circulation patterns is expected to have a bearing on the global tropospheric temperature trend estimates.
This means that the picture is complex when it comes to the global tropospheric temperature trends because many physical processes have an influence that take place on a wide range of spatial scales.
Hard evidence of misrepresentation
Despite the complicated nature of tropospheric temperatures, it is an indisputable fact that Christy’s graph presents numbers with different meanings as if they were equivalent. It is really surprising to see such a basic misrepresentation in a testimony at the U.S. House Committee on Science, Space & Technology. One of the most elementary parts of science is to know what the numbers really represent and how they should be interpreted.
References
- G.A. Vecchi, B.J. Soden, A.T. Wittenberg, I.M. Held, A. Leetmaa, and M.J. Harrison, "Weakening of tropical Pacific atmospheric circulation due to anthropogenic forcing", Nature, vol. 441, pp. 73-76, 2006. http://dx.doi.org/10.1038/nature04744
Olof R. #96 – Nice Work! Your graphs certainly rebut the Spencer/Christy graphic disinformation project. May I reference your work the next time I try to break thru the intellectual blindness of my Republican elected representatives?
Alastair McDonald #92 & #94 – You wrote: “The upper troposphere is not warming as fast as the models predict…”
You base your claim that the upper troposphere isn’t warming on the UAH TMT, but you apparently don’t understand that the TMT is a flawed metric. That’s because the TMT includes some influence from the stratosphere, which is known to be cooling, thus the TMT understates the temperature trend in the actual upper troposphere. The original TLT, last reported as UAH v5, was intended to remove this contamination, as is the U Washington/RSS T24/TTT series, both of which do indicate a warming trend, but at a theoretical peak emissions altitude which is lower than that of the TMT.
Your claim: “I am saying that the infrared radiation emitted by the surface is absorbed in the boundary layer, so it does not affect the OLR at the TOA.” misses the fact that models do include the saturation in the lowest layers. READ THIS REPORT (PDF warning) published almost 40 years ago by Ramathan and Coakley, in which they point out the surface saturation effect in their model. You might also check out the other models of the day which they reference. You are free to use your great math skills to replicate their work…
#102 Eric Swanson,
Of course, feel free to use my charts..
Here is another one, showing the distinct trendbreak of satellites vs sondes, at about year 2000, when the AMSUs were introduced. Comparing the original indices, or subsampled and weighted “apples to apples” doesn”t matter, the break is similar:

Another interesting thing is the new upper troposphere index ( TUT = 1.4*TTP-0.4*TLS) that Spencer invented in a blog post.
http://www.drroyspencer.com/2015/05/new-satellite-upper-troposphere-product-still-no-tropical-hotspot/
He obviously didn’t check very well how this index behaved, especially not in the AMSU era, where it produces a mighty hotspot:

However, I believe that this protruding hotspot partly is caused by too low TMT-trends in UAHv6. This hotspot is not there in RSS data, but it is in STAR v4. The latter dataset has quite large trends (1979-2016) in the tropics (20N-20S), about 0.23 C/ dec for TTT, and 0.28 C/dec for TUT a la Spencer,
Barton re 101,
I’ve read your response to Prof. Essenhigh and it is the model that you describe there that is flawed. If you reproduce it in a spread sheet, you will find that it contains self referencing loops which are not obvious when it is written out as a text file.
BTW, Dr John Koch was not merely Professor K Angstrom’s lab assistant, as you write in that response. He was his PhD student who published his results and is cited by Callendar among others. I have translated Dr Koch’s paper here.
I really ought to be getting on with other work, and this seems to be leading nowhere. However, if anyone is interested there is a full explanation of my ideas on the tropical lapse rate problem and computer models in this poster.
Enjoy :-)
Eric,
I am not basing my claim that the upper troposphere is not warming on the UAH results. I am not even saying the upper atmosphere is not warming. I am saying that the upper troposphere is not warming as much as the models are predicting and I am basing that on the results from the radiosondes not satellites!
Figure 8 in this Thorne et al (2011) paper shows the problem.
Thorne, P. W., Lanzante, J. R., Peterson, T. C., Seidel, D. J. and Shine, K. P. (2011) ‘Tropospheric temperature trends: history of an ongoing controversy’, Wiley Interdisciplinary Reviews: Climate Change, vol. 67, no. 8, pp. 66–88.
which can be accessed through DeepDyve for $6.
None of the radiosonde measurements fit within the climate model 5 – 95 percentile, far less match the mean. (And the UAH MSU MT is the only satellite data to fit within that of the radiosondes.)
I too, thought it was improbable that results from Christy and Spencer could be correct, but when the minor error was found in their work and three papers were published in Science I had my worst fears confirmed. Not only was the satellite data not matching the models, so was the data from the radiosondes!
Sherwood, S. C., Lanzante, J. R. and Meyer, C. L. (2005) ‘Radiosonde Daytime Biases and Late-20th Century Warming’, Science, vol. 309, no. 5740, pp. 1556–1559.
But accepting that the radiosonde data is correct implies accepting UAH as well. You are not going to do that, so I am not going to continue to bang my head against a brick wall.
Olof R #104 – Thanks for the link to Spencer’s site with his corrected TP, which I had not seen. As it happens, I tried a similar approach for a corrected TP calculated using the RSS weighting functions, shown as ES TTP in this graph. The weighting I came up with was less than that which Spencer presented, but I think that was the result of the UAH v6 weightings, which are based on a modeling process with an offset from nadir. The MSU scans at each end of the swath have an angle of of 47.37 degrees from nadir. The “Earth incidence angle” at ground level is greater than the scan angle, due to the curvature of the Earth. With the new UAH v6 approach, they select an incidence angle of 21.59 degrees for all three MSU channels. For the AMSU, with it’s narrower antenna angle and smaller footprints, the maximum scan angle is 48.33 degrees. The UAH v6 calculations use different incidence angles to provide compatibility with the MSU channels, 38.31 degrees for AMSU5, 13.18 degrees for AMSU7 and 36.31 degrees for AMSU 9. Note that they increased the angle for the MT, claiming such was necessary to adjust for the effects of high elevations on the scans. There was no mention of masking out those high elevations while building their 1 degree grids, as RSS does with their TLT. It would be interesting to compare a graph of the UAH v6 weights for their LT, MT and LS vs. the weights from RSS, but one would need to obtain that information from UAH, since these data are not published or archived, to my knowledge.
Spencer’s post about correcting the TP suggested that they intended to include mention of this in their Version 6 paper, but there’s no mention of such in the final version. Could be the political situation made that correction “inconvenient”…
ABM 105,
“Self referencing loops?” Huh? What? Come again?
If my model is flawed, please explain how. Obviously it’s not a complete model as it contains neither reflection nor convection nor clouds nor a thorough band scheme, but the radiation physics is quite straightforward.
Look, I’ll make it even simpler. You have Warm object A atop B atop C. B absorbs all infrared. Now make A warmer, and it will make B and C warmer. So B being “saturated” does nothing to stop greater absorption higher up making a difference. Your idea is just wrong, Arrhenius and Koch were wrong, and we found out why in the 1940s. Your opposition to this is kind of like opposing relativity in the name of Newton, or opposing Darwin in favor of Paley. The evidence just doesn’t support you.
Eric Swanson #107,
For UAH weighting functions, I have digitized the following chart, and used 1976 US standard atmosphere to translate radiosonde pressure levels to height.
http://www.drroyspencer.com/wp-content/uploads/MSU2-vs-LT23-vs-LT.gif
In this chart Spencer calculate RAOB sampled weighted trends, that seemingly agree well with the satellite trends.
However, they must have used Ratpac B to get such low trends in MT and LT. Ratpac B is unadjusted since 1996, and the choice of Ratpac B and RAOBCORE is truly a cherry-pick of the two datasets with the lowest trends in the troposphere.
I am also wondering about satellite weighting functions and the deep layer temperatures that they represent. Since the vertical integration is done by height ( and not by pressure), it means that the temperature of thin air is overweighted compared to that of dense air, which doesn’t make sense regarding the energy content of the layer.
With pressure level data from models and radiosondes, it is possible to compare integration of layers by height and by pressure. Since models warm faster than observations in the upper layers, the “standard” integration by height exaggerate the difference between models and observations, e g in the TMT- layer.
Olof R #108 – As I understand the calculation of weighting function, it’s performed in pressure coordinates. That’s because the broadening of the emission lines is a function of pressure. The narrow band of microwave frequency which each channel measures is picked to represent only the emissions from a portion of the pressure widened oxygen emission line. Sorry to say, I’m not an expert at that level. One can go back to the early work for the details, such as:
Spencer, Christy and Grody 1990, “Global Atmospheric Temperature Monitoring with Satellite Microwave Measurements: Methods and Results 1979-84”, J. Climate 3, 1111. and:
Spencer and Christy 1990, “Precise monitoring of global temperature trends from satellites”, Science 247, 1558. which refers back to:
N.C. Grody 1983, J. Climate Applied Meteorology 22, 609.
The various graphs are based on the temperature/pressure profile of the US Standard Atmosphere, which begins with a surface temperature of 10C (50F) under clear sky conditions, which might be a reasonable situation in mid-latitudes. Under other, real world weather conditions, things would be more interesting.
In discussing the UAH weighting functions, it should be mentioned that RSS also use graphics plotting altitude rather than pressure. This may be simply a decision to use a less precise but less complex method of annotation.
Up-thread @78 I mentioned scaling that UAH graphic and in doing so I was comparing the radiosonde trace of temperature-trend-for-altitude with the satellite-weighting-for-altitude. The throught did occur that this would be a comparison too far because altitude isn’t pressure, the X-axis being dTau/dInP. I did the calculation using altitude and the result fitted with Spencer et al’s assertions so the worry about the comparison being wrong was forgotten. Perhaps I should re-visit it. After all, a log scale is no minor consideration. It may make Spencer et al’s 10% (that I criticised @78) a more meaningful value.
Barton,
You wrote “Look, I’ll make it even simpler. You have Warm object A atop B atop C. B absorbs all infrared. Now make A warmer, and it will make B and C warmer. So B being “saturated” does nothing to stop greater absorption higher up making a difference. Your idea is just wrong, Arrhenius and Koch were wrong, and we found out why in the 1940s. Your opposition to this is kind of like opposing relativity in the name of Newton, or opposing Darwin in favor of Paley. The evidence just doesn’t support you.”
A can only get warmer if it absorbs more radiation, so a warming A will cool B, since B will receive less radiation from A.
It is the latest push from Judith and Christy, “models running hot” is their slogan, Arctic really running hot is what is happening:
https://www.esrl.noaa.gov/psd/map/images/rnl/sfctmpmer_180a.rnl.html
that is 180 day average.
I may remind that there are no Upper Air stations running over any of the Oceans, even the red hot one with sea ice above +4 C anomaly. Reality agrees with the models, it is warming, especially where there is no sun for 6 months.
#111 MA Rodger
I calculated (integration by altitude) the TMT-trend 1979-2014 using Ratpac B, like in the UAH graphic, and got 0.073 C/decade, so their number 0.07 is reasonable. However, it is not reasonable to cherry-pick the two lowest trend datasets for calculations.
If I do the same calculation with Ratpac A the TMT-trend goes up to 0.101 C/decade
If I integrate Ratpac A by pressure instead, the TMT-trend rises to 0.144 C/decade.
I have also calculated TMT-trends for the whole satellite era 1979-2016 as follows.
1) Integration by height:
CMIP5 rcp8.5 37 model average: 0.242 C/decade
Ratpac A: 0.127 C/decade
The model trend is 90% larger than Ratpac A.
2) Integration by pressure
CMIP5 rcp8.5 37 model average: 0.262 C/decade
Ratpac A: 0.170 C/decade
The model trend is 54% larger than Ratpac A.
So yes, the method of integration matters in model/obs comparisons, since the upper levels with thin air has warmed relatively more in the models.
I think method 2 makes more sense since it better reflects the change of energy content in the layer
AM 112: A can only get warmer if it absorbs more radiation, so a warming A will cool B, since B will receive less radiation from A.
BPL: If A is warming, B will receive MORE radiation from A, not LESS. The flux density radiated by a body is
F = ε σ T^4
where ε is the emittance, σ the Stefan-Boltzmann constant, and T the absolute temperature. Double A’s temperature and it will radiate 16 times as much energy per unit time.
Alastair B. McDonald # 106 – I think you should read Sherwood et al. (2005) again. The main thrust of their effort is an analysis of changes in the diurnal temperature range found in the sonde data. They also use that data to determine night time temperature trend from their data sets. As seen in Table 2 and noted in the text:
“Indeed, the tropical trend with this adjustment (0.14 C per decade over 1979 to 1997) would be consistent with model simulations driven by observed surface warming, which was not true previously…”
Their comparison with the MSU (Table 1) involves only diurnal delta T’s, not trends. They do not include the MSU in any comparison of temperature trends. The fact that their data sets end in 1997 excludes the impacts of the 1998 El Nino and any other more recent changes. Of course, they aren’t using the new UAH version 6 results either.
Olof R @114,
Thank you for the numbers.
The UAH use of RATPAC-B is surely worse that the cherry-picking you describe. According to the NOAA, for global use of RATPAC-B is wrong.
Please help stop the world’s largest output new Thermal Coal Mine operating for the next 90 years
https://www.realclimate.org/index.php/archives/2017/03/unforced-variations-march-2017/comment-page-5/#comment-675070
Contacts List
https://www.realclimate.org/index.php/archives/2017/03/unforced-variations-march-2017/comment-page-5/#comment-675077
Sorry, but your explanation of why Christy is wrong or misleading is as clear as mud.
“The comparison between the average of model runs and observations is surprising, because it is clearly incorrect from elementary statistics.”
It is nowhere made clear in your essay what observations ought to be compared to from the output of an ensemble of models.
“An algorithm is then used to compute the air temperature consistent with the measured irradiance. This algorithm is a model based on the same physics as the models which predict that higher concentrations of CO2 result in higher surface temperatures.
I wonder if Christy sees the irony in his use of satellite temperatures to dispute the effect of CO2 on the global mean temperature.”
I hope not. Two models of different things can be based on the same physics, and one can describe reality well, and the other does poorly. Hint: the latter model might have to take into account many more things than the former. The global mean temperature has many more things to take into account than the measurement of a temperature from radiation.
“The two graphs (courtesy of Gavin) below show comparisons between tropospheric mean temperatures (TMT) that are comparable to the satellite data and include confidence interval for the ensemble rather than just the ensemble mean.”
Sorry, this doesn’t help much either.
Why?
What Christy’s audience wants to know is how reliable the model is given the observations. The graphs can make the model appear more reliable if the 95% confidence interval was wider, it would fully encompass the observations instead of them departing from the 95% confidence interval on occasion. But that would be a less predictive model, and that would be fooling the audience, that is subject to errors in thinking about elementary statistics.
Since Wisconsin was brought up, the Washington Post tells us:
“In 2012, 21 percent of Wisconsin voters told exit pollsters that they or a family member belonged to a union. They broke for Barack Obama by 33 percentage points. This year, just as many voters said they were in union households — and Clinton won them by just 10 points”.
FYI only. It might help some commenters mark their beliefs to reality.
Arun 122,
Seriously, I don’t want to be the conspiracy guy, but this exact same nonsensical meme popping up recently just makes me wonder.
“What Christy’s audience wants to know is how reliable the model is given the observations.”
Why? And what would be “reliable enough” so that “Christy’s audience” would support the reduction of fossil fuel burning?
“Two models of different things can be based on the same physics, and one can describe reality well, and the other does poorly.”
But if Christy agrees on the physics, then CO2 is indeed a greenhouse gas. If CO2 is a greenhouse gas, then there would have to be a model that would explain Christy’s results.
Since there is no such model, we work with the existing model. This is called the principle of Parsimony, AKA Ockham’s Razor. And now we are back to the original question:
How “reliable” does the model have to be in order to make stimulating the economy, and creating jobs, by reducing FF burning, a good idea?
Arun @120.
Your statement “what observations ought to be compared to from the output of an ensemble of models” is presumably asking what “output of an ensemble of models” ought to be compared to particular “observations.” I think Fig 4 presents such an output for TMT satellite records and thus Fig 4, unlike Chisty’s comparison, does not contain “incorrect … elementary statistics.”
Arun @121.
You seem to be suggesting that because a climate model will have many more inputs to contend with compared with the inputs required by a temperature measurement based on MSU data, this greater quantity of required inputs will determine the relative accuracy of the two. You ignore the relative sensitivity of a model/measurement output to the various input data and also the relative accuracy of those various input data. Note that the calibration of MSU based satellite data is no trivial task.
Arun @122.
Your comment shows you remain stuck with the notion that it is the satellite data which is good enough to be ‘ the given’ against which the CMIP5 ensemble can be judged. The satellite records are but one set of many, and not the most reliable.
Also note that the confidence interval is not arbitrary but calculated and does not spread greatly over half a century. The major natural wobble impacting global climate is ENSO and the ensemble mean is insensitive to any specific ENSO record. Much of the confidence interval of the CMIP5 ensemble thus results from ENSO. In this regard, note the findings of Risbey et al (2014).
Arun, #123:
“The graphs can make the model appear more reliable if the 95% confidence interval was wider, it would fully encompass the observations instead of them departing from the 95% confidence interval on occasion.”
Maybe I’m missing something, but while estimates of confidence may legitimately vary, they surely are not purely arbitrary?
> Christy’s audience wants to know is how reliable the model is given the observations
Paste that string into Google and search to see where that theme is being promoted lately.
It’s copypaster fodder.
Arun @122,
An apples-with-apples comparison from Berkeley Earth between measurement and model output has just been updated, a comparison that does not rely on the calibration of satellite temperature measurements.
A more direct link to the image MAR alludes to in the current #128:
https://twitter.com/hausfath?lang=en
I’ve been trying to understand Spencer and Christy (2017) did to produce their TMT v6, etc. For the MSU instruments, they took the on orbit measurements of individual foot print position from each scan and binned them into a 1×1 degree grid.
The positioning in the grid depends on the “Earth Angle” of each view, thus the position for the nadir scan is different from those for the end scans. For example, at the equator crossing, a plot of the grid in a vertical direction would show these measurements binned into a V shaped displacement in the longitude direction with the nadir being at the tip of the V, thus there’s no vertical alignment between the nadir grid location and the positions assigned to the other scans. A rough calculation along the Equator indicates that the orbits do not return to the same nadir grid location until 81 orbits later and after 81 orbits, there are still 200 other nadir grid locations with no data. Spencer and Christy fill in these empty locations by arbitrarily “smearing” the grid around each location to the 2 adjacent locations as well. They eventually process this gridded data into another 2.5 degree grid, etc., etc. moving toward a longitudinal average.
As a consequence of this processing, it seems to me that their calculation using the gridded data with their second order polynomial fit procedure may not be so great. First off, it appears that in most cases, there’s no alignment between the upper levels of the grid and nadir, thus they are always mixing different air masses when performing in the calculation. Whether this all works out OK on a monthly average is a question in my mind. Also, at the highest latitude where the MSU/AMSU are scanning in N-S direction, there are no nadir scans corresponding to the scans at the end of the swath, which extend further toward the poles. Does their “smearing” procedure shift from longitudinal along the equator to latitudinal near the poles? They don’t say how they handle this situation. What ever they do, at polar latitudes, the scans are rather close together with considerable overlap, thus the grid positions receive several measurements during each day’s operation, mixing several air masses in each day’s grid binning process.
For the AMSU data, they go straight to the 2.5 degree grid binning, missing out on a great opportunity to provide higher resolution data. As previously mentioned, they trick their polynomial fit by adjusting the selection of an “earth angle” to match the theoretical weighting of the MSU. All this processing results in moving the theoretical peak emission weighting to higher in the atmosphere, with the result being stronger impact from the stratosphere, while assuming that the same emission profile is appropriate at all latitudes and seasons.
Nothing above gets into the other issues of calibration and merging of the data from each satellite. In sum, I’d say there several reasons to question the usefulness of their work in assessing AGW…
Hank Roberts:
It’s pretty insulting for a Google-Galileo to assume RC participants can’t use the same research tool he does, isn’t it?
Mike Mann should be prepared for Christy , Curry & Co to produce the warped graph at tomorrows Science Comittee meeting – and for the Chairman to praise it warmly as Sound Science, as it featured in last weeks Heartland Conference Practice session
https://vvattsupwiththat.blogspot.com/2017/03/the-2347-year-gish-gallop.html
One of the most elementary parts of science is to know what the numbers really represent and how they should be interpreted.
Indeed. It is not perfectly clear what the numbers from the simulations really represent. If the simulations are independent samples from the population defined by the models, then the mean of the simulations will be close to the mean of the population, the sd of the simulations being proportional to about 1/10 (because the sample size is close to 100). The sd of the mean is about 1/10 the sd of the population from which the samples are drawn. The uncertainty envelope of the mean is much smaller than the uncertainty envelope of the population (estimated from the sample standard deviation.) The data have been reliably outside the uncertainty envelope of the mean. That should serve to discredit the model that defines the population from which the simulations are a sample.
If the model runs are not independent samples from the population defined by the model (that is, parts of the models that are in common among them), then not much can be said about the process from the sample runs.
128, M A Rodger: An apples-with-apples comparison from Berkeley Earth between measurement and model output has just been updated, a comparison that does not rely on the calibration of satellite temperature measurements.
Thank you for that link.
At yesterday’s House Science Committee hearing, John Christy presented the latest update for his comparison of MT and other climate records with CIMP5 model results. He made some changes to his tropical graph, as I show in this comparison. In the caption for the latest graph, he admits that: “The last observational point at 2015 is the average of 2013-2016 only, while all other points are centered, 5-year averages.”. And, he has cut the first two points from the graph, which would not appear in a true 5 year “centered” moving average. After my many complaints about their padding the curve, I would like to claim victory for these changes.
Of course, he still leaves the impression that the MT v6 is an accurate representation of the upper troposphere, even though he for many years pointed out that the MT is a flawed metric, since the MSU2/AMSU5 data measurements include the energy from both the troposphere and the stratosphere, which is cooling. There is also some weighting from the surface, which explains much of the difference between land and ocean measurements.
Now that we have Spencer and Christy’s 2017 report on their version 6 products, we find that there appears to be no correction for the influence of precipitation, particularly precipitable ice, called hydrometeors, as was included in earlier versions. With this last change, S & C have implicitly concluded that there is no significant trend in storm intensity, i.e., that there’s the same amount of influence from storms in recent years as there was in the early years. I suggest that such an assumption is an unproven hypothesis which should be tested, given that the tropics are the region of the stormy Inter-tropical Convergence Zone, as well as the region of much hurricane and typhoon activity. I submit that the MT must be rejected as a climate measure until this hypothesis is validated.
Eric Swanson @135,
As well as updating his graph of tropical mid-troposphere temperatire series, Christy’s testament goes so far as to say to his non-scientifc audience that if they want “some very different conclusions regarding the human impacts on climate,” he Dr John “Red-Team” Christy is their man. Indeed, he tells the hearing he presents data-supported proof that recent warming is entirely natural and not the result of AGW. That is, he says of his Fig 5:-
And Christy accuses the IPCC of consciously preventing the revelation demonstrated by his Fig 5 being discussed.
For a grown-up scientist to set out his stall thus is unforgivable. Consider what Christy, the deluded fool that he is, is ignoring in setting out his grand theory that climate models are “untruthful.”
He does not make plain to his audience of non-scientists that his Fig 5 is a re-drawing of just a part of one of the four graphs in his Fig 4. He ignores IPCC AR5 Fig 10.8 which presents (with great clarity) the same analysis excepting for the period 1961-2010 instead of 1979-2010 and the conclusion drawn from Lott et al (2013) from which Fig 10.8 was sourced.
All Christy is doing is restating the denialist ‘missing red dot’ argument, a contoversy which is not ignored by IPCC AR5 but which is set out and discussed at some length in Section 9.4.1.4.2.
So, where in all this does the “untruthfulness” actually lie.
MAR #136 – After wading thru the IPCC FAR WG I web site, I was unable to locate anything resembling the “IPCC AR5 Supplementary Material” which Christy referenced in his testimony. I did look back at the first draft of chapter 10 and found an earlier version of Figure 10.8, which appeared much like the final version. In either figure, the blue band representing natural forcings was much narrower than that of Christy’s version. One wonders where Christy’s figure came from.
Also, I looked back at earlier work by Spencer (1993), “Global Oceanic Precipitation from the MSU 1979-1991 and Comparisons to Other Climatologies”, J. Climate 6, 1301. In that report, Spencer describes the impact of hydrometeors on the MSU, which has a large impact on Channel 1, a fact which Spencer used along with the data from channels 2 and 3 to determine rainfall. One point of interest was Spencer’s calculation of “air temperature” using a combined MSU 2 and 3, with this equation:
Tair = 1.6 Tb2 – 0.6 Tb3
The new Spencer and Christy UAH version 6 products make use of a similar calculation, combining channels 2, 3 and 4 in this equation:
LT = 1.538 MT – 0.548 TP + 0.01 LS
The big difference now is the processing of the combination of scan angles to produce MT, TP and LS. In that processing, there is no compensation for the effects of hydrometeors or high elevations as was used to compute prior versions. Thus, any trend in the effects of rain and hydrometeors will contaminate the MT and thus the LT products. It may be possible to test for such trends in other more recent measures of rainfall, such as the SSMI data. The data is out there and may have already been assessed in published papers.
Fun stuff for a grad student, I suppose…
Eric Swanson @137,
Concerning AR5, the figure that Christy is complaining about being hidden away is Figure 10.SM.1 within the SM10, the supplimentary information attached to Chapter 10. As the searching you describe @137 suggests, Christy is correct to consider this an obscure place for this issue to be set out. But it is discussed at some length elsewhere in the main body if AR5. His complaint that they “opted to … fashion the chart in such a way as to make it difficult to understand and interpret” results from using the same format as used in IPCC AR5 Fig10-08/Lott et al (2013) Fig 1. The main resulting difficulty is the broader 95% confidence interval for the ‘naturally-forced’ model-runs over the shorter 1979-2010 period tends to overwhelm the format.
But then Christy was not complaining about that in his comments in the IPCC AR5 review. His comment (Comment 10-953 and maybe elsewhere in his other four comments) was that use of the 1960-2010 period did not show that:-
And having vented his spleen, Christy continues to ignore the response to his comment which explains that the issue is raised in a number of paces within the main body of AR5 (as I set out @136).