Guest commentary by Shaun Lovejoy (McGill University)
Below I summarize the key points of a new Climate Dynamics (CD) paper that I think opens up new perspectives on understanding and estimating the relevant uncertainties. The main message is that the primary sources of error and bias are not those that have been the subject of the most attention – they are not human in origin. The community seems to have done such a good job of handling the “heat island”, “cold park”, and diverse human induced glitches that in the end these make only a minor contribution to the final uncertainty. The reason of course, is the huge amount of averaging that is done to obtain global temperature estimates, this averaging essentially averages out most of the human induced noise.
Two tough sources of uncertainty remain: missing data and a poor definition of the space-time resolution; the latter leads to the key scale reduction factor. In spite of these large low frequency uncertainties, at centennial scales, they are still only about 13% of the IPCC estimated anthropogenic increase (with 90% certainty).
This paper is based on 6 monthly globally averaged temperature series over the common period 1880-2012 using data that were publically available in May 2015. These were NOAA NCEI, NASA GISTEMP, HadCRUT4, Cowtan and Way, Berkeley Earth and the 20th Century Reanalysis. In the first part on relative uncertainties, the series are systematically compared with each other over scales ranging from months to 133 years. In the second part on absolute uncertainties, a stochastic model is developed with two parts. The first simulates the true temperatures, the second treats the measurement errors that would arise from this series from three different sources of uncertainty: i) usual auto-regressive (AR)-type short range errors, ii) missing data, iii) the “scale reduction factor”.
The model parameters are fit by treating each of the six series as a stochastic realization of the stochastic measurement process. This yields an estimate of the uncertainty (spread) of the means of each series about the true temperature – an absolute uncertainty – not simply the spread of the series means about their common mean value (the relative uncertainty). This represents the absolute uncertainty of the series means about a (still unknown) absolute reference point (which is another problem for another post).
Key science
- The usual uncertainties have short-range auto-regressive correlations, so that when averaged over long enough periods, the differences between series will eventually be close to white noise. This is presumably the main type of error that we could expect if there were the usual human glitches caused by changing station locations, technologies and the like; the usual sources of human bias. The corresponding fluctuations fall off relatively rapidly with time interval
 t: as t-1/2. This type of behaviour is never observed even at scales of a century (see figs. 1, 2; Haar fluctuations were used, see the note at the bottom). If this type of error were indeed dominant, then the centennial scale differences between the series would be about ±0.005oC, which is about ten times smaller than those we calculate.
t: as t-1/2. This type of behaviour is never observed even at scales of a century (see figs. 1, 2; Haar fluctuations were used, see the note at the bottom). If this type of error were indeed dominant, then the centennial scale differences between the series would be about ±0.005oC, which is about ten times smaller than those we calculate. - All the series seemed to be both statistically very similar to each other and each was pretty much equally distant from the mean of all the others (i.e. equally similar or dissimilar to each other, depending on your view). Significantly, this included the 20th Century Reanalysis (20CR) that didn’t use any land temperature station data whatsoever (fig. 2) and even turned out to be the closest (with NOAA) to the mean of all the others!
- Up until a scale of about 10 years (the “macroweather” regime), the fluctuations in the series and in the differences between the series have different amplitudes (the ratio is between 2 and 3), but both are scaling with roughly the same fluctuation exponent H ≈ -0.1 (fig. 1, 2). This implies strong long-range statistical dependencies (long range memories) in both the series themselves and in their differences. The obvious interpretation is that over this range of scales that each of the series are missing data (typically about 50% of pixels have no data), but each series misses somewhat different data.
- For scales longer than about 10 years, the global temperature fluctuations begin to increase with time scale: the internal macroweather variability is increasingly dominated by low frequency changes due to anthropogenic warming: this is the beginning of the climate regime. At the same time, the fluctuations in the differences between the series stops following the fluctuations in the series themselves, leveling off at about ±0.05oC (fairly independently of the time scale). This is a kind or irreducible uncertainty (figs. 1, 2).
- These differences below about (10 yrs)-1, can be explained by poorly defined space-time data resolutions. Fig. 4 in CD shows that the amplitudes of the fluctuations are quite sensitive to the amount of space-time averaging and they systematically decrease with the averaging scale according to somewhat different exponents in both space and in time.
Let’s say that the basic data were gridded at 5o resolution in space and at one month in time. In that case, there is a typical amplitude of 5o x 5o x 1 month space-time temperature fluctuation, but since there are generally insufficient data in each 5o x 5o x 1 month “space-time box” they are not perfectly estimated, there is not enough data to sufficiently average it over the nominal space-time scales. Because the fluctuation exponents in fig. 3 (in both and in time) are negative, this implies that the amplitudes of the fluctuations are spuriously large by a multiplicative factor that depends on the difference between the actual “effective” resolution and the nominal resolution (5o x 5o x 1 month). This is the origin of the scale reduction factor and it has the particularity of being multiplicative: it affects all scales. This is the dominant source of error at scales beyond a decade. It gives the dominant contribution to errors in estimating anthropogenic warming.
This effect is actually familiar to long-range forecasters who routinely “rescale” model outputs so that the amplitude of the model internal variability is realistic when compared to empirical temperatures. The scale reduction factor is simply the same mechanism but applied to the empirical series themselves.
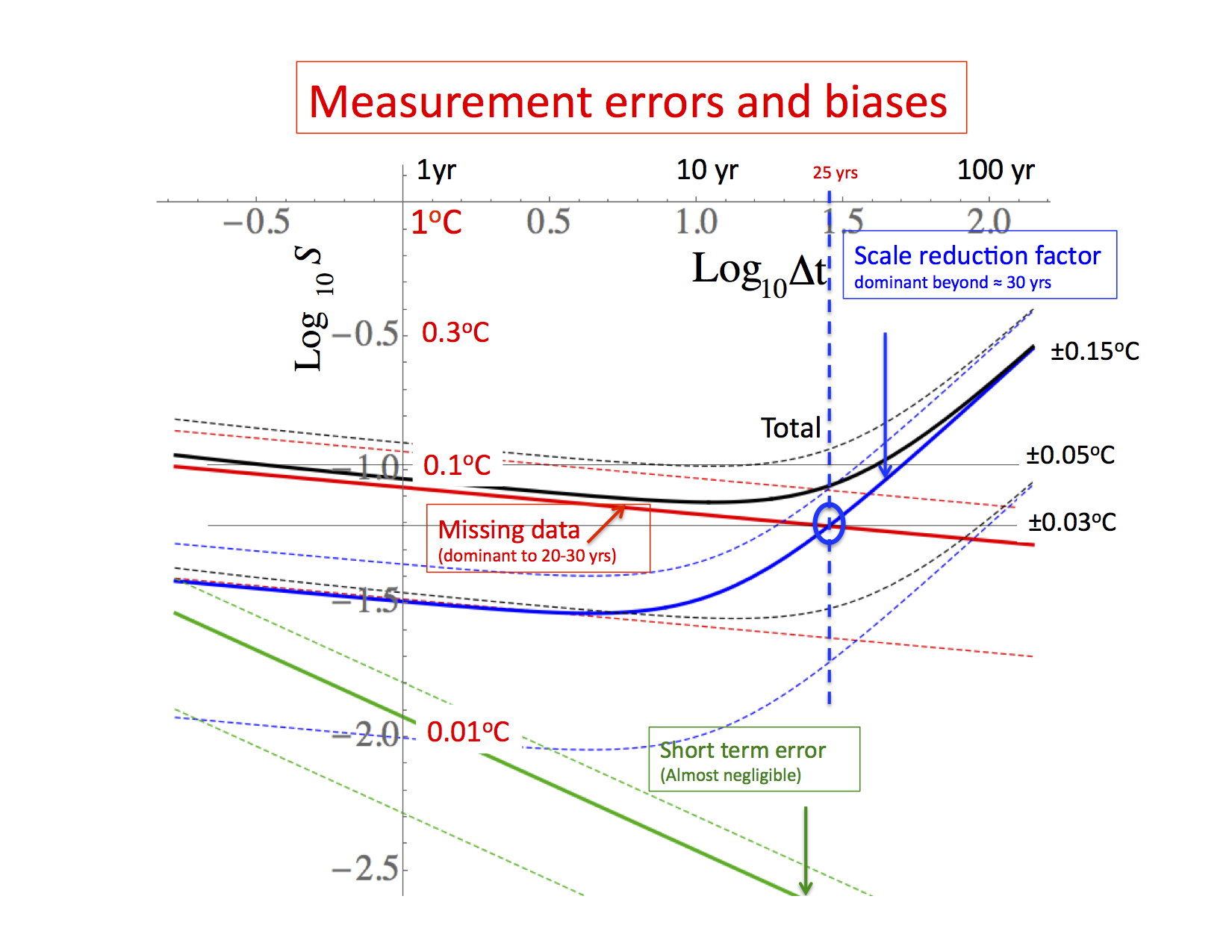
- In order to go beyond relative errors estimated via the series to series differences, to obtain the absolute errors, we constructed a simple stochastic model (fig. 4) of both the actual temperature and the three sources of error: the classical short range error, the missing data term and the scale reduction factor. Using statistical analysis of the fluctuations of the series to series differences, we estimated the statistics of the amplitudes from each contribution (fig. 5). The key results of the paper follow, notably:
- Up to 10 years, missing data was the main source of error: 15±10% of the temperature variance. The ±10% about the 15% refers to series to series variation in the amount of missing data (these are one standard deviation limits).
- After ten years, the scale reduction factor was dominant giving an error of 11%±8% error. This is the main source of centennial scale error.
- Overall, with 90% confidence it was found that the true temperature lies in the range -0.11oC to 0.13oC of the reported monthly values (90% confidence).
- Overall: the change since the 19th century can be estimated with nearly the same uncertainty as for the monthly value: ±0.11oC (90% confidence).
- This uncertainty is much higher than conventional (AR type) approaches predict, (about ±0.005oC).
- All of these numbers are much smaller than the roughly 1oC of warming that has occurred since the 19th century, so that we can be quite confident of the magnitude of the warming.

Fig. 3: The RMS fluctuations (structure functions, S) of the various measurement errors with one standard deviation limits shown as dashed lines (corresponding the variation from one measurement series to another). The blue curve is the contribution of the scale reduction factor, the red is from missing data (slope = H = -0.1) and the green is the short-range measurement error (slope -1/2). The black curve is the sum of all the contributions. Notice that most of the contributions to the errors are from the scaling parts. These Haar structure functions have been multiplied by a canonical factor of 2 so that the fluctuations will be closer to the anomalies (when decreasing) or differences (when increasing). Note that these show essentially the difference between the true earth temperature and the measurements; the difference between two different measured series will have double the variances, the difference structure function should thus be increased by a further factor 21/2 before comparison with fig. 2, 3 or the figures below. Adapted from fig. 6 of CD. - The stochastic model was able to closely reproduce not only the temperature statistics but also the differences between series, and this at all scales from one month of > 100 yrs. This is a strong validation (see figs. 9, 10, 11 of CD).
- The 20CR series is not based on anomalies but absolute temperatures, yet it was statistically just as close to the others as if it had been based on anomalies. We can therefore use it to determine the absolute temperature of the earth; the error estimates in the above paragraph will hold.
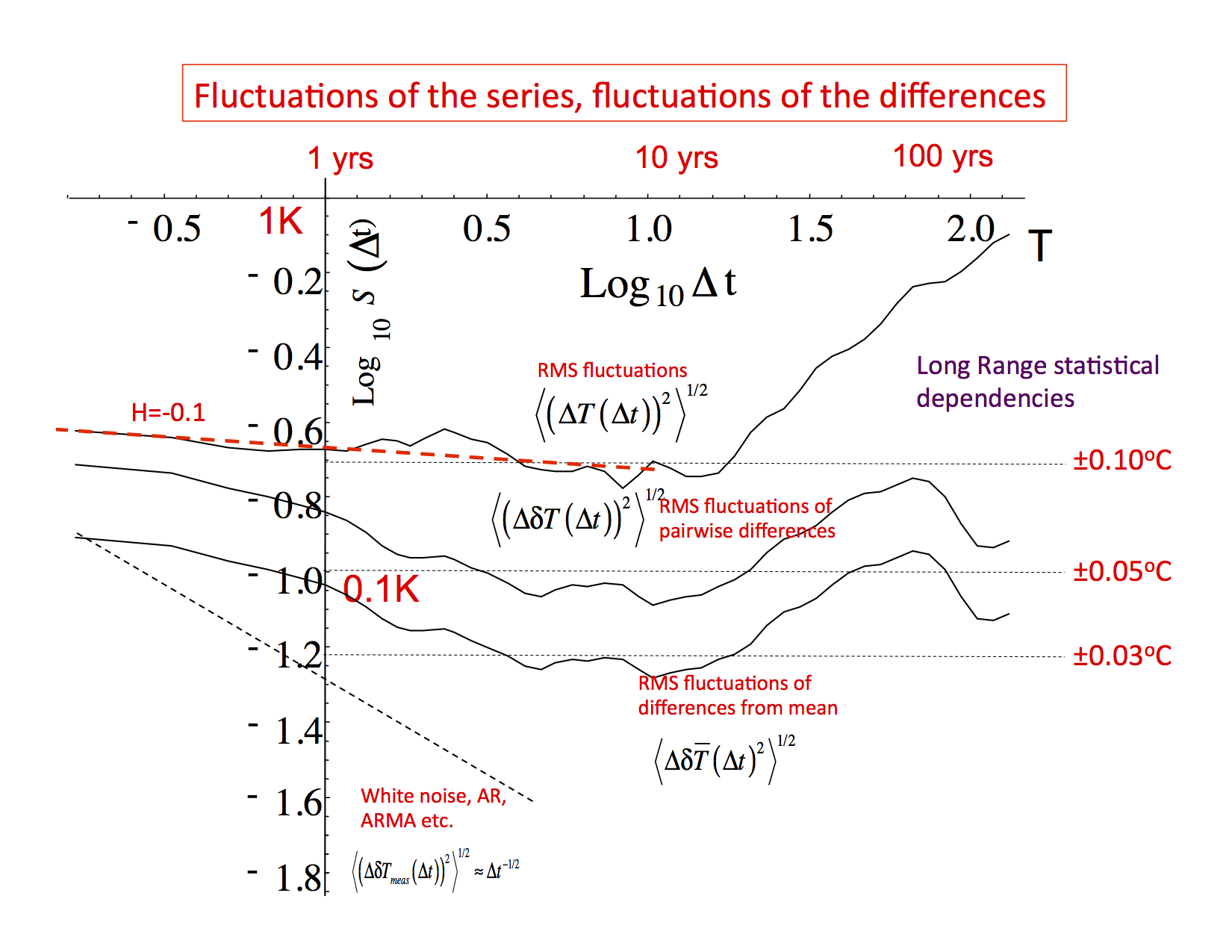
Fig. 1: The Root Mean Square (RMS) Haar fluctuations (structure functions S( t)) averaged over the six series (top), averaged over all the 15 pairs of differences (second from top), averaged over the differences of each with respect with the overall mean of the six series (third from top), and the standard deviation of the S(t) curves evaluated for each of the series separately (bottom). Also shown for reference (dashed) is the line that data with independent Gaussian noise would follow (Adapted from fig. 2).
t)) averaged over the six series (top), averaged over all the 15 pairs of differences (second from top), averaged over the differences of each with respect with the overall mean of the six series (third from top), and the standard deviation of the S(t) curves evaluated for each of the series separately (bottom). Also shown for reference (dashed) is the line that data with independent Gaussian noise would follow (Adapted from fig. 2).
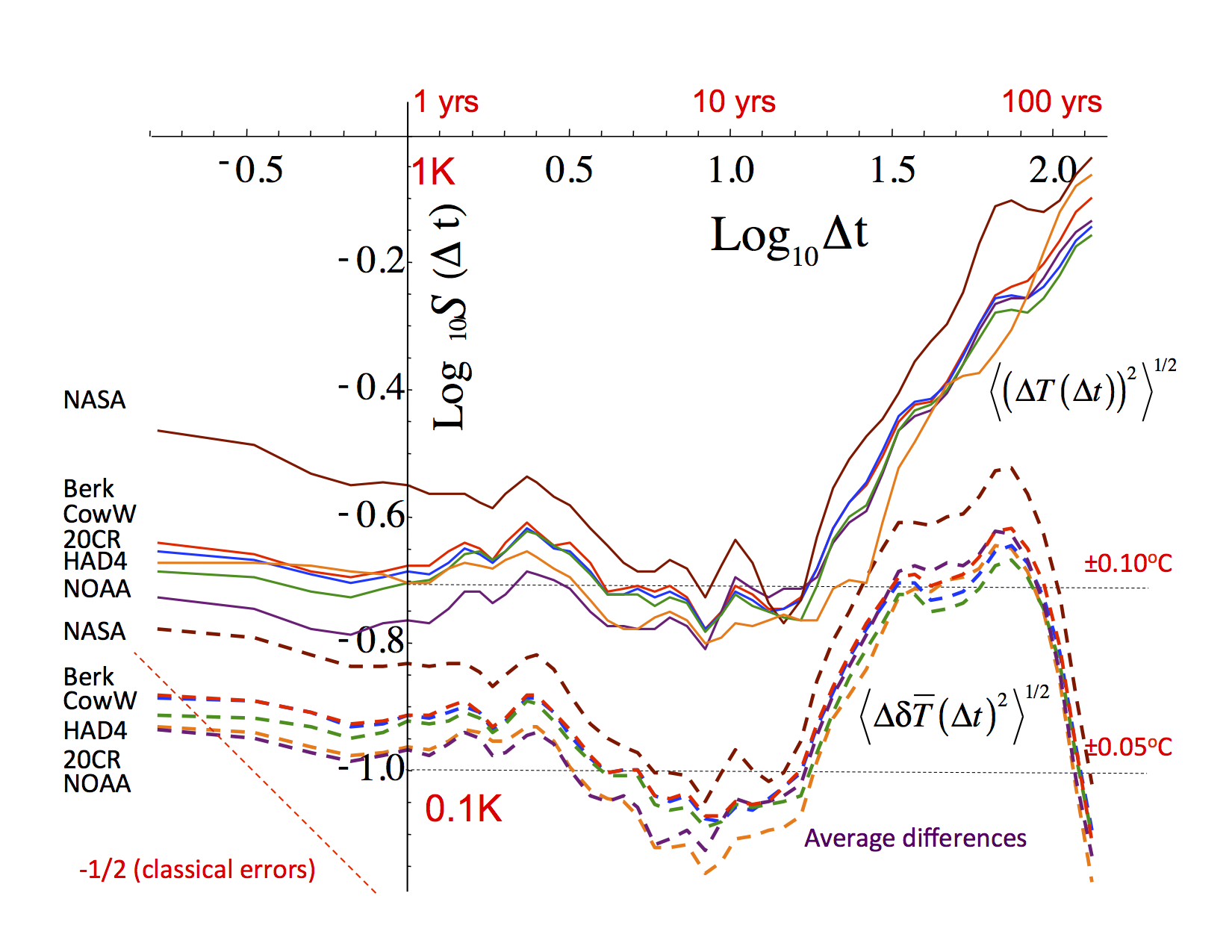
Fig. 2: The top set of curves (solid) are S(t) for each of the different series, the bottom set (dashed) are the differences of each with respect to the mean of all the others: NOAA dark purple, NASA (brown), HadCRUT4 (green), Cow (blue), 20CR (orange), Berkeley Earth (red) (indicated at the left in the order of the curves). Adapted from fig. 3 of CD.
Notes:
“Haar fluctuations” are a very simple form of wavelet. A Haar fluctuation T(t) of the temperature T(t) over a time interval t is simply the average of T(t) over the first half of the interval minus the average over the second half (i.e. the average from T(t) to T(t– t/2) minus the average from T(t– Dt/2) to T(t– t)). That it! The interpretation is simple: when the mean (or RMS) of T(t) is increasing with interval t, it is close to the mean difference in temperature, when decreasing, it is close to the mean anomaly (here defined as the average over an interval t of series with the long term mean removed).
The slightly corrected proofs (not subject to copyright) can be found here.
There is a popular summary that was published in The Huffington Post. A French language version may be found in Le Huffington Post
References
- S. Lovejoy, "How accurately do we know the temperature of the surface of the earth?", Climate Dynamics, vol. 49, pp. 4089-4106, 2017. http://dx.doi.org/10.1007/s00382-017-3561-9
I am a little surprised that RealClimate would allow someone to suggest there is a spatial and/or temporal resolution problem. When I brought this subject up I was ridiculed and was pointed to an anonymous blogger Tamino, who is apparently one of the foremost statisticians in the world. They have supposedly proven that, by simply doing non-linear sampling, you get 10 times the resolution of linear sampling. So having vast areas of 5×5 degree tiles isn’t a problem, in fact just having a handful of randomly located weather stations is actually better than a good world-wide coverage.
Should have read “5×5 degree EMPTY tiles”
Keith,
Do not worry about the anonymous Tamino. We have sparred on numerous occasions. He discounts everything that he cannot reduce to a simple mathematical equation. If he cannot model it, it doesn’t exist. This paper at least acknowledges what many (including you and me) have been saying for years. It is about time that RealClimate admits to what we do not know.
Dan H.:
LOL! If Dan H. did not exist, RC would have to invent him! He’s almost too good to be true, as a model of the most-easily mocked sort of AGW-denier.
Here, Dan H. fails to distinguish “anonymous” from “pseudonymous”, and gives away his ignorance of refereed climate science. IRL, the pseudonymous Tamino is a professional statistician with several peer-reviewed, climate-related publications. His real name is known to many, just not to Dan H. It’s true Tamino evinces little patience for AGW-denial on his blog, so Dan H. is unlikely to have spent much time there.
re: 3. “It is about time that RealClimate admits to what we do not know.” What balderdash. If you take the time to actually read the posts over the months and years instead of shooting from the hip, you would know that limitations to what we know are always are key fundamental point. Goodness, what insulting, scientific arrogance. You owe an apology to the peer-reviewed scientists but of course we know you won’t admit to being wrong.
@3 – “It is about time that RealClimate admits to what we do not know.”
What do we not know?
The resolution dependence of temperature anomalies is particularly strong since the fluctuation exponent of monthly temperatures is negative in both space and in time. This means that when anomalies are averaged in either space or in time, that the amplitudes of the fluctuations systematically decrease as power laws. If the averaging is not quite adequate, the amplitudes will be multiplicatively in error. This is the main source of low frequency errors in temperature anomalies. The factors are small, but these errors still dominate the multidecadal errors.
Dan@5, says “It is about time that RealClimate admits to what we do not know.”
I read this website from time to time, and they do often acknowledge limitations of data or knowledge. The IPCC report goes to extreme lengths to acknowledge uncertainties around extent of data, and various specific predictions or findings. This is a simple fact, beyond dispute, although they express high confidence we are altering the climate.
In my experience its sceptical blogs that never, ever acknowledge uncertainty in their positions. This really stands out to me. If you have personally expressed uncertainty about a sceptical climate theory in the past, here is your chance, show me a link.
You guys just seem completely oblivious. You aren’t normal sceptics, you are either politically motivated, or have some amazing lack of self awareness.
Keith Woolard @1 says “So having vast areas of 5×5 degree tiles isn’t a problem, in fact just having a handful of randomly located weather stations is actually better than a good world-wide coverage.”
You make some outrageous claims. Nobody has ever claimed that. More data is always better, but we already have enough data for very high confidence about global temperature trends and averages.
re: 8, for the record, I was quoting Dan H. ;-)
Dan
“The model parameters are fit by treating each of the six series as a stochastic realization of the stochastic measurement process.”
I don’t see the justification for this. I am certainly no expert on this, but surely the differences between the datasets are not stochastic, but structural?
Dan, you’ve never “sparred with Tamino” — he’s pointed your confusions out.
https://www.google.com/search?q=tamino+“dan+h”
nigelj, to Dan H.:
One has come to have confidence in your conclusions contemporaneously with confidence in the consensus for AGW.
I swear I did not compose that sentence to be alliterative, but now that I see it I’m going with it.
It’s probably more important to know the temperature and heat storage history of the Earth’s oceans since 1880 than the temperature of the near-surface Earth atmosphere, as far as future projections go. For a general discussion of why this is so:
Measuring ocean heating is key to tracking global warming, John Abraham, The Guardian Feb 2016
See also
NOAA Global Ocean Heat and Salt Content data
and
An imperative to monitor Earth’s energy imbalance, von Schuckmann et al. Nature Climate Change (2016)
As far as uncertainty in future projections? Well, there’s the melting permafrost emission issue; there’s the global carbon sink exhaustion issue; and we might have a supervolcano, or a asteroid impact, or global thermonuclear warfare wiping out most of human civilization. But otherwise the business-as-usual projections and the rapid-transition-to-renewable-energy projections seem roughly reliable – warming and destabilization either way, just less quickly in the latter case.
Okay here’s a discussion of the permafrost emissions uncertainty:
http://www.biogeosciences-discuss.net/bg-2016-544/
And here’s a discussion of the global carbon sink uncertainty:
http://news.nationalgeographic.com/news/2014/09/140909-record-greenhouse-gases-carbon-sinks-global-warming-ocean/
Both those uncertainties tend to undermine the effects of rapid-transition-to-renewables emissions scenarios so any sane policy planning should include adapting to unstable warming climates and rising sea levels; raiding the coffers of the fossil fuel sector to pay for this seems entirely justified given their record of dishonesty and obfuscation on these issues.
Hmmm. . . “Climate science obfuscator” has a nice ring to it. Perhaps a more accurate description than “Climate science denier”?
Keith W., #1–
“…in fact just having a handful of randomly located weather stations is actually better than a good world-wide coverage.”
Apparently a “handful” is now defined as “approximately 6000 temperature stations, 7500 precipitation stations and 2000 pressure stations.”
https://en.wikipedia.org/wiki/Global_Historical_Climatology_Network
Kevin @ #15
So even using your 6000 stations, that means they each cover 85,000km2 on average. An 100 years ago each represented more than 300,000km2 And very far from evenly distributed.
And Nigelj @#8 – yes Tamino says exactly that. He claims that you get more than ten times the resolution if you use random sample rate
I would be nice to have a single temperature series that one can use, instead of several lines often presented in trend charts, which is confusing. What about the mean of the six? This paper uses the mean and says that is the “best estimate of the truth” but does not give the data. The mean is only the best if all six are equally good. Can one of the six be considered closest to average, such that it can represent a “consensus”? The paper specifically does not say any of the six are better. The NOAA and 20CR series are closest to the mean. Is one justified in presenting one of them to represent the average?
Root mean square can only be used to calculate errors when data is HOMOGENOUS. Global temperature data is far from it. If it were true, we could estimate global temperature at a very high accuracy, by having 7 billion people hold a finger in the air.
The nonsense started with CRU’s Jones et al, which led to the utterly ridiculous recording of HadCrut temperature data to 0.001 degrees. What a farce, especially when recoding accuracy, until recent years, was +/- 0.5 degrees.
TB 18: What a farce, especially when recoding [sic] accuracy, until recent years, was +/- 0.5 degrees.
BPL: Have you ever had a statistics course? Do you understand how the error for a group of points can be lower than the error on the individual points?