Roger Pielke Sr. has raised very strong allegations against RealClimate in a recent blog post. Since they come from a scientific colleague, we consider it worthwhile responding directly.
The statement Pielke considers “misinformation” is a single sentence from a recent posting:
Some aspects of climate change are progressing faster than was expected a few years ago – such as rising sea levels, the increase of heat stored in the ocean and the shrinking Arctic sea ice.
First of all, we are surprised that Pielke levelled such strong allegations against RealClimate, since the statement above merely summarises some key findings of the Synthesis Report of the Copenhagen Climate Congress, which we discussed last month. This is a peer-reviewed document authored by 12 leading scientists and “based on the 16 plenary talks given at the Congress as well as input of over 80 chairs and co-chairs of the 58 parallel sessions held at the Congress.” If Pielke disagrees with the findings of these scientists, you’d have thought he’d take it up with them rather than aiming shrill accusations at us. But in any case let us look at the three items of alleged misinformation:
1. Sea level. The Synthesis Report shows the graph below and concludes:
Since 2007, reports comparing the IPCC projections of 1990 with observations show that some climate indicators are changing near the upper end of the range indicated by the projections or, as in the case of sea level rise (Figure 1), at even greater rates than indicated by IPCC projections.
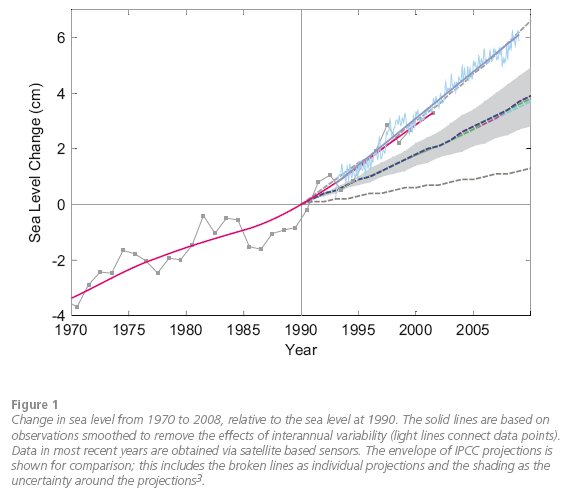
This graph is an update of Rahmstorf et al., Science 2007, with data through to the end of 2008. (Note the comparison is with IPCC TAR projections, but since AR4 projections are within 10% of the TAR models this makes little difference.)
Pielke claims this is “NOT TRUE” (capitals and bold font are his), stating “sea level has actually flattened since 2006” and pointing to this graph. This graph shows a sea level trend over the full satellite period (starting 1993) of 3.2 +/- 0.4 mm/year and is very similar to an independent French analysis of those very same satellite data shown in the Synthesis Report (blue lines above). The best estimate of the IPCC models for the same time period is 1.9 mm/year (coloured dashed lines in the middle of the grey uncertainty range). Hence the conclusion of the Synthesis Report is entirely correct.
{kind=link}
The “flattening of sea level since 2006” that Pielke refers to is beside the point and deceptive for several reasons (note too that Anthony Watts has extended this even further to declare that sea level from 2006 to present is actually “flat”!). First of all, trends over such a short sub-interval of a few years vary greatly due to short-term natural variations, and one could get any result one likes by cherry-picking a suitable interval (as Pielke and Lomborg both have). The absurdity of this approach is see by picking an even more recent trend, say starting in June 2007, which gives 5.3+/-2.2 mm/yr! Secondly, this short-term trend (1.6 +/- 0.9 mm/yr) is not even robust across data sets – the French analysis shown above has a trend since the beginning of 2006 of 2.9 mm/year, very similar to the long-term trend. Third, the image Pielke links to shows the data without the inverted barometer correction – the brief marked peak in late 2005, which makes the visual trend (always a poor choice of statistical methodology) almost flat since then, disappears when this effect is accounted for. This means the 2005 peak was simply due to air pressure fluctuations and has nothing to do with climatic ocean volume changes. The trend from 2006 in the data with the inverse barometer adjustment is 2.1 +/- 0.8 mm/yr.
{kind=link}
2. Ocean heat content. The Synthesis Report states:
Current estimates indicate that ocean warming is about 50% greater than had been previously reported by the IPCC.
This is a conclusion of a revised analysis of ocean heat content data by Domingues et al., Nature 2008, and it applies to the period 1961-2003 also analysed in the IPCC report. Pielke claims this is “NOT TRUE” and counters with the claim: “There has been no statistically significant warming of the upper ocean since 2003.” But again this is not relevant to the point the Synthesis Report actually makes and again, Pielke is referring to a 5-year period which is too short to obtain statistically robust trends in the presence of short-term variability and data accuracy problems (the interannual variability for instance differs greatly between different ocean heat content data sets):
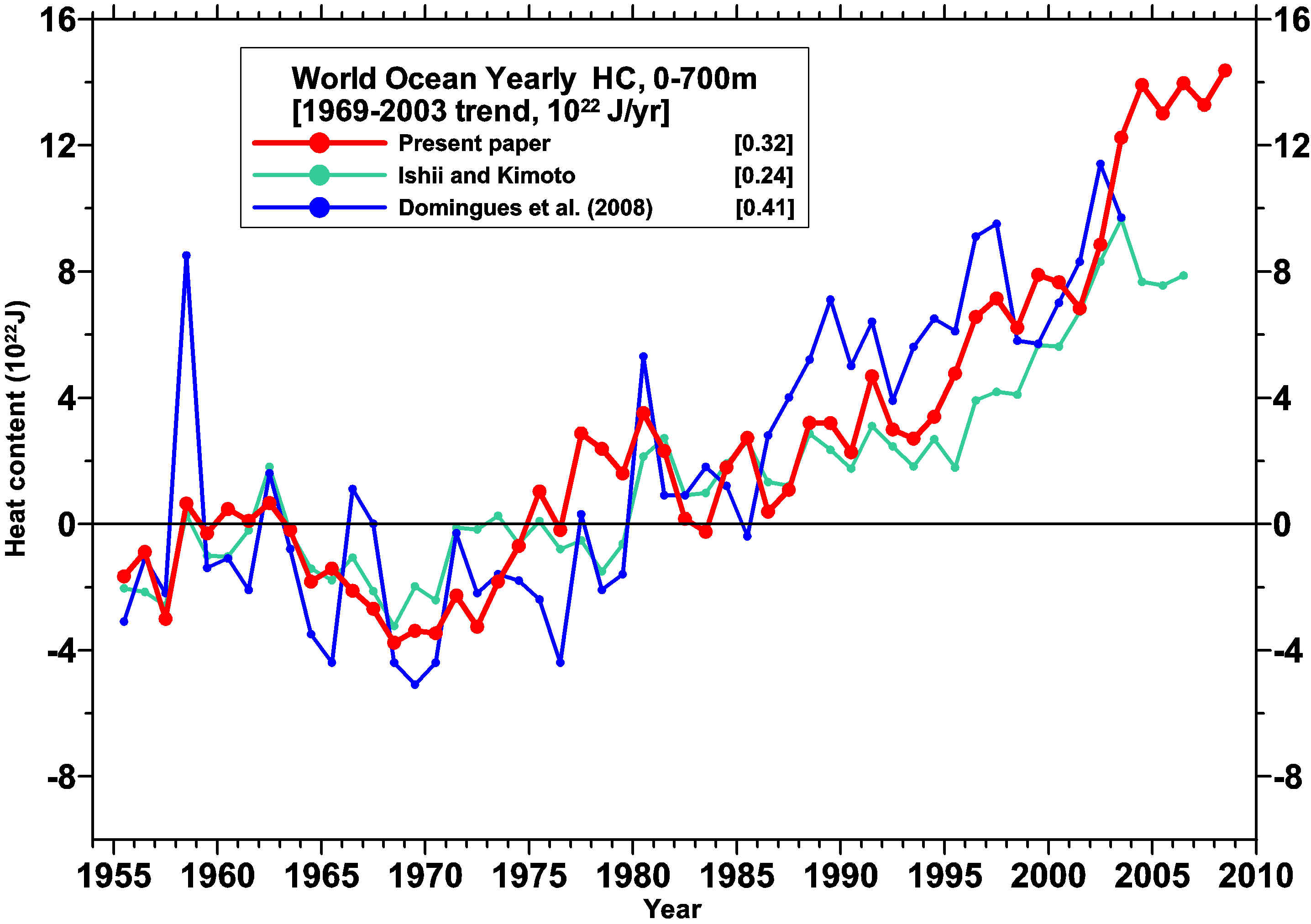
For good reasons, the Synthesis Report discusses a time span that is sufficiently long to allow meaningful comparisons. But in any case, the trend in from 2003 to 2008 in the Levitus data (the Domingues et al data does not extend past 2003), is still positive but with an uncertainty (both in the trend calculation and systematically) that makes it impossible to state whether there has been a significant change.
3. Arctic Sea Ice. The Synthesis Report states:
One of the most dramatic developments since the last IPCC Report is the rapid reduction in the area of Arctic sea ice in summer. In 2007, the minimum area covered decreased by about 2 million square kilometres as compared to previous years. In 2008, the decrease was almost as dramatic.
This decline is clearly faster than expected by models, as the following graph indicates.
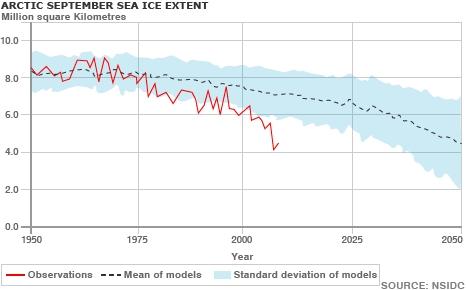
Pielke’s claim that this is “NOT TRUE” is merely based on the statement that “since 2008, the anomalies have actually decreased.”
Yes, same thing again: Pielke’s argument is beside the point, since the Synthesis Report is explicitly talking about the summer sea ice minimum reached each September in the Arctic, and we don’t even know yet what its value will be for 2009. And Pielke is again referring to a time span (“since 2008”!) that is far too short to have much to do with climatic trends.
We thus have to conclude that there are no grounds whatsoever for Pielke’s wild allegations against us and implicitly the Synthesis Report authors. The final sentence of his post ironically speaks for itself:
Media and policymakers who blindly accept these claims are either naive or are deliberately slanting the science to promote their particular advocacy position.
Indeed.
OT, a pretty sea ice picture from yesterday. Cap Morris Jesup, the northernmost land, more-or-less reachable by sea from the Atlantic. Meanwhile, just to the west, the ice in the Lincoln Sea is coming apart. http://rapidfire.sci.gsfc.nasa.gov/realtime/single.php?2009187/crefl1_721.A2009187200000-2009187200500.2km.jpg
“My guess is that the combinatorial explosion of computations that results when one shrinks the grid far outweighs the costs of incorporating new physics when processing an individual grid during each time step”
Yup. You need to make sure that your timestep is short enough that only a little of the content that is contained in the box leaves it and little can get in.
So a smaller box by half requires 8x the number of boxes and (at least) 2x the number of timesteps.
The “at least” is because if you get small enough, you can have variations that change your instantaneous velocity. E.g. if your model has a box small enough to have sound waves represented with several boxes, each clap of thunder can significantly empty your box at the speed of sound.
You learn a lot when you fail at creating a model of an accreting white dwarf binary system in university.
You learn it too late to get honours for it, but you learn it…
> How many climate scientists does the world HAVE!!!!
After counting all retired economists, geologists, physicians, dead people, potty peers and Britney Spears? …eh, beats me!
#296 Burgy yes, Copenhagen is approaching. Expect much more.
#295, #297
Yes, I know why parameterization is being done in the first place and how its being done. I can also imagine that there are a number of physical phaenomena that can be parameterized sufficiently for the purposes of a climate model. However with clouds I doubt that this approach will lead anywhere soon, seeing as even a halfed gridsize would still be orders of magnitude larger than a cloud. Therefore I wondered whether an object oriented approach, treating individual clouds or at least cloud systems as separate entities with inherited properties, the ability to spawn and merge etc. would be more effective than static cells (which could still be used for everything else).
#Mark
I don’t know what you’re getting at. I’m here to learn about climate simply because I’m interested. Like all of us, I have some ideas and wonder about why some things are being done the way they are. Am I sure my questions MUST be answered and that they are IMPORTANT in the cosmic scale of things? No. Are you sure that cloud parameterization in climate models works perfectly? Probably not. So don’t be an ass and act like I was trying to make a point here. If you can explain why cloud parameterization can’t be replaced and why it wouldn’t matter anyway if it could, because its not an issue and its nothing that modelers still worry about – then I’d be happy to listen.
Have you read any of these?
http://scholar.google.com/scholar?sourceid=Mozilla-search&q=%22object+oriented%22+%2Bgrid+%2B%22climate+model%22
Except as I understand this, you have grid size and then thinner vertical layers (atmosphere is a thin blanket surrounding the planet). So I visualize this as pizza boxes layered a dozen or two deep, tiling the surface. Apparently HadCM3 uses 19 levels.
So if only the grid size is shrunk, without adding layers, you get 4x for the physical shrinkage of the grid, 2x for the timesteps, so it goes up by the cube 8x rather than 16x. Still that’s a huge increase in the amount of time needed to do a run.
For given levels of computational power available, I can imagine that perhaps shrinking the grid size alone while not adding layers can be very useful given that the grid sizes used are apparently on the order of three hundred km. Thus the “boxes” being “pizza boxes” rather than cubes, i.e. each of the 19 layers is far less than three hundred km thick.
re 308, there’s a lot more vertical constraint on movement than horizontal. The atmosphere really doesn’t go that far up, when you compare it to how far round it goes.
I don’t believe you can get away with not increasing the layer count if you increase horizontal resolution, though it’s not a 2x . Mostly because there’s a better constraint on vertical. But it is unwise to not increase layers.
But then again, you shouldn’t use the idea of “pizza boxes”. In terms of how far things can move, the vertical scale is far larger than its physical dimension would lead you to believe.
A cloud, after all, is relatively tall compared to its extent when you compare to the full size available.
So the short (from what I remember on the explanation of what I did wrong) is that you have to worry about 3d movement and that to a large extent goes up vertically and so a higher resolution there is warranted. Missing out increasing vertical resolution will hide mixing that you’re trying to bring out horizontally because your height is too coarse.
There was a lot about space-centred and time-centred interpolation that stops your model becoming inherently unstable (our problem. I went “D’OH!” when I read the first flipping CHAPTER on how weather models do it…) and that is possibly *why* you should increase level numbers when increasing horizontal resolution.
#307
I have. I found some reference to the Met Office using object oriented convection models to model percipitation properties in weather forecasts, but nothing about climate modeling (still browsing – its a lot of stuff and most of it is not related to actually treating clouds (or anything else) as objects but just referring to object oriented programming with GCMs in general).
“I don’t know what you’re getting at. I’m here to learn about climate simply because I’m interested.”
I’m getting at your questions are leading.
You’re ASSUMING that what you think is a real problem is, actually, a real problem.
It isn’t.
Ensemble modeling shows how not-a-problem this is.
That this is how people who DO this sort of thing don’t do, should be another pointer.
But your position is not correct.
It’s not the problem with climate and clouds. Or at least not to an extent that is solvable and doesn’t have EXTREME constraints based on past evidence, making using resource to “crack” this “problem” a waste of time and energy.
But if you’re here to learn, learn to ask yourself questions. Stop making me type them out because you aren’t asking yourself them.
There is a second anti-AGW article in the WSJ, dated 7-1-2009, titled GLOBAL WARMING AS MASS NEUROSIS. The author is one Brett Stephens.
“Much of the science has been discredited.”
“Data shows that over the past 5 years the oceans have been cooling.”
“Why do some people still believe in AGW? 1. Ideological (socialist) biases. 2. Theological (end times) mindset. 3. Psychological (the world needs penance).
Net: Global Warming is sick-souled religion.
Brett’s email is bstephens@wsj.com
The article (as the previous one) invites blog comments.
Burgy
[Response: actually this is from 2008. It hasn’t improved in the meantime. – gavin]
#311, Mark
Yes, having read things like…
“Standard GCMs have most of this physics included, and some are even going so far as to embed cloud resolving models in each grid box. These models are supposed to do away with much of the parameterisation (though they too need some, smaller-scale, ones), but at the cost of greatly increased complexity and computation time. Something like this is probably the way of the future.”
(from the realclimate model FAQ)
… I indeed assumed this was a real problem – or at least something worth improving.
It with some wry amusement that I note the following….
1. Dr Pielke, in his July 6th post complains about the ‘personal insults’ levelled at him on this very blog.
2. Mr Anthony Watts is apparently a Pielke fan, having reproduced no fewer that 5 Pielke postings on his blog since June 30th.
3. The admiration seems mutual, Dr Pielke describes Watts’ hopelessly one-sided ‘report’ into surface station siting issues as ‘excellent’.
4. Based on Pielke’s description of the recent trend in sea level as ‘flattening’, Mr Watts added this subtle annotation to the Univ Colarado graphic: http://wattsupwiththat.files.wordpress.com/2009/06/pielke_slr.gif?w=510&h=367
Gavin notes above that the trend in this ‘flat’ period is actually +2.9mm year, and Dr Pielke concurs, stating that ‘This finding is not flat’.
5. Dr Pielke is apparently exercised about the spreading of ‘misinformation’ by one of Scientific American’s Top 50 researchers, Mr Watts frequently points out how much more traffic than RC his modest online presence receives…
6. Although he apparently has the time to trawl picture libraries for an image of the Iraqi Information Minister with which to illustrate his echoing of Dr Pielke’s latest example of RC’s ‘misinformation’ [nothing but the highest standards of debate here], Mr Watts apprently does not have the time to correct his egregious (and horribly colour-co-ordinated) annotation. This is not bad undergraduate science, this is not even bad high school science.
It is a given over on our side of the pond that Americans cannot do irony, add the above to the awarding to WUWT of ‘Science Blog of the Year’ and I think I have a pretty convincing case to the contrary.
In the UK Guardian recently, Dr Schmidt was quoted thus … A lot of the noise when it comes to climate is deliberate because the increase of noise means you don’t hear the signal, and if you don’t hear the signal you can’t do anything about it, and so everything just gets left alone. Increasing the level of noise is a deliberate political tactic. It’s been used by all segments of the political spectrum for different problems. With the climate issue in the US and not elsewhere, it’s used by a particular segment of the political community in ways that is personally distressing. How do you deal with that? That is a question that I’m always asking myself and I haven’t gotten an answer to that one.
A friendly word of advice, lifted from that traditionally given by the Scott Trust to a new incoming Guardian Editor … continue the same lines and in the same spirit as heretofore. By which I mean continue in the classical spirit of evidence-based science; and please do not be tempted to mudwrestle with those unable accurately to label a graph. The noise merchants are recognised for what they are, in the long term they cannot compete with science, as classically defined.
Phil Clarke.
Could not have stated it better Phil (314). Let Watts play mr blog scientist; he appears to need a fantasy life. The actual scientists will carry on with that damnedest habit of engaging with reality.
Re #314
4. Based on Pielke’s description of the recent trend in sea level as ‘flattening’, Mr Watts added this subtle annotation to the Univ Colarado graphic: http://wattsupwiththat.files.wordpress.com/2009/06/pielke_slr.gif?w=510&h=367
Gavin notes above that the trend in this ‘flat’ period is actually +2.9mm year, and Dr Pielke concurs, stating that ‘This finding is not flat’.
And yet note his response to being challenged on that (below):
I have extended Pielke’s analysis to the full period, it’s amazing how while most of the period was ‘Flat’ the sea level still managed to grow by ~50mm.
http://i302.photobucket.com/albums/nn107/Sprintstar400/pielke_slr.gif
REPLY: ah more snark from Princeton’s leading intellectual coward. Can’t meet Pielke on equal terms eh? – Anthony
> on equal terms
He’s really eager to encourage you to stoop to the same level, isn’t he?
Oh, well, Anthony’s the radio/tv forecaster world’s leading intellectual showing all of science to be bullshit, even though apparently he doesn’t even possess and undergraduate degree.
“… I indeed assumed this was a real problem – or at least something worth improving.”
Nope, it means there’s improvements possible, bob.
Newtonian gravity has errors in it. But at the moment, they don’t make a difference when working out probe trajectories.
Improvements ARE possible, but aren’t necessary.
Quantum gravity doesn’t work with relativity, so improvements are possible. Like, make them work together.
But we aren’t being flung off the earth because we don’t know how it works.
And note: it says “some parameterisations”.
And you’re still wrong. It isn’t a big problem.
If you rerun the models with a slightly different cloud parameterisation, you can see the sensitivity of the climate forecasts to that parameter.
Then again, you don’t care about that, do you. You want to keep alive “well, you don’t really know what’s going on, do you, so maybe we should *wait*. I’m not saying AGW is false, but please ignore that what I want you to do is the same as if it were…”
Burgy writes:
Plimer is the guy who thinks the sun is made out of iron.
“Then again, you don’t care about that, do you. You want to keep alive “well, you don’t really know what’s going on, do you, so maybe we should *wait*. I’m not saying AGW is false, but please ignore that what I want you to do is the same as if it were…””
I don’t know what the greeks have to say about paranoia or strawmen but I’m sure you do. Is that a reflex? “Don’t pretend complex things like cloud modelling aren’t sufficiently solved or you’re a denialist?” Come off it.
“Improvements ARE possible, but aren’t necessary.”
Aren’t necessary for what? For us to think that AGW is real? Guess what – I agree. If you believe they’re not necessary beyond that, you may want to penetrate the modelers burning a lot of time and money on improving models with some of your wisdoms on soldiers and gravity. I’m sure they wouldn’t think in their wildest dreams that their job is done – especially when it comes to clouds.
“I don’t know what the greeks have to say about paranoia or strawmen but I’m sure you do.”
It’s called “observational evidence” and “cognitive reasoning”.
This may seem like paranoia to some, bob.
“Aren’t necessary for what?”
To know that if we continue on this course, we WILL see massive changes.
You don’t need to know what the chemical breakdown in your liver is to know that your renal failure will not be good for you.
You don’t need to know if you’re going to die or just have internal injuries if you drop from the second floor onto concrete. You know enough just from a ballpark estimate that you are unlikely to walk away whistling, so maybe NOT jumping would be a good idea.
But if there’s a fire raging and no other way out, you don’t need to know what the statistical chances are of surviving the fall, or the survival rate of the fire reaching toward you to make you know that you’re better off jumping.
Did you know a 4ft fall can kill you?
You don’t need the complex mathematics that proved that to know that you’re unlikely to die falling from a stool, though.
Just wanted to thank Abi (110), Francois (121), and Aaron (140) and some others for their helpful insights and link re climate change and food (re my post 102).
Aaron (140), your experience and insights are an especially important holistic complement to the science, since science usually only looks at a few variables. There are a lot of straws out there to break the camel’s back (& harm food production); they just can’t all be included in scientific studies. Or can they???
Also the nonlinear effects that Francois pointed out are just up my alley of thinking. Why do we have such a one-track, linear mind? Well, at last partly it’s our European male culture heritage.
Sorry, I’ve had very poor internet connectivity these past 2 months….
It seems like the main confusion is that the synthesis report says that the climate “studies” over the past few years suggest that climate change is progressing more than was believed just a few years ago. Whereas Pielke notes that climate “data” over the past few years actually suggests the opposite, if anything.
Because the studies over the past few years primarily use data from before 2006, there is no inconsistency there. But a lot of people are out there saying that wow, the synthesis report shows that since 2006, global warming is actually accelerating–even though the synthesis report doesn’t even use much data post 2006.
MaybePielke would be right to guess that climate studies over the next few years (when they include data up through 2009), will suggest a less rapid climate change than studies using data through 2006.
You might be right, Colin, but as far as evidence is concerned, the one who made that mistake first (and, since he blogged it and gets a lot of adoring fans reading his blog, with AW copying as fast as possible for WUWT for wider consumption) was Pielke himself.
Since it is a mistake HE started as far as available evidence goes, he can’t really shift the blame off to “well, it read like that, have a look at all the others who did the same..”, can he.
#322
After having looked at the modelE source (and yes, I am old enough to be able to read fortran) I’ll at least have to agree that my proposal for an object oriented approach to handling clouds in models can NOT be a top priority. Top priority should be redesigning the entire thing from scratch. The physics may be sufficient but from a software engineering point of view, the code is a structural disaster. That doesn’t necessarily mean that the people writing it don’t have the first idea about how to do it on such a scale. My guess is that it started out as a quick and dirty prototype long ago and the point at which somebody would have had to pull the plug and invest the extra time for a redesign was simply missed (which is a common problem with many evolving software projects). So it grew and grew to the point where it is today. Just look at a sub like “MSTCNV”. Hats off to whoever has to debug that large pot of spagetti (let alone take a shot at optimizing it on an object code level). There are far better, faster, better maintainable and more flexible techniques for modeling abstract, externally defined rules such as physics than hard-coding them line by line directly into a routine. But I’m sure the people at GISS know all this.
bobberger 9 July 2009 at 4:51 AM
We are are unwilling to pay more tax because we’re neurotically obsessed with the relatively tiny fraction of tax dollars wasted, so the refactoring you mention does not get done.
Same deal as the discussion elsewhere about unprocessed satellite data return. Instead of risking that a fraction of our money might be wasted by the government, we’d rather spend all of it on important things such as DVD rentals, pizzas, or innumerable other vital, indispensable products.
Put another way, we paid to gather the data, but we don’t want to waste money so we waste the money we paid to gather the data. Irrational, but there you have it.
“Top priority should be redesigning the entire thing from scratch. The physics may be sufficient but from a software engineering point of view, the code is a structural disaster.”
And now you see why he wanted the source code.
NOT to learn from it, but to waste time by saying “It’s poorly written! Rewrite from scratch!”
Got any proof it needs rewriting, bob? Does it actually have a bug?
Go bug hunting.
Or rewrite the code yourself and release it PD (or BSD).
‘course you may find someone looks at your code and goes “I can read the code (yet, I am old enough to read Fortran) and the TOP Priority MUST be to rewrite this code from scratch! It’s terrible!”.
#327
Doug. I think its one of those investments that would pay off very well in the future but doesn’t have any immediate, positive effect and is therefore probably hard to justify. Stragely enough, this seems to work with things like satellites but is often more of a problem with relatively cheap stuff like this.
Mark. You keep missing the point with remarkable accuracy. “Proof it needs rewriting”? Come on. Look at it (or maybe you better don’t). The question is not whether its buggy. Software usually is and a redesign won’t change THAT (although it would, if done properly, make debugging a lot easier). The question is how flexible it is, how long it takes to introduce new functionality, adjust the underlying logic and principles (mostly physics in this case), trace it and probably more important than anything else – speed it up. (there you go – another two minutes of your invaluable time wasted away just like that and for nothing at all).
I agree with Bob that this code should be rewritten, for a number of reasons. That’s why I started the Clear Climate Code project last year. Most of my intervening time has been spent on other activities, but I have recently been working towards version 0.2 of a Python reimplementation of GISTEMP.
There is a systemic problem with scientific software, because scientists are not software engineers. The code is poorly documented, inflexible, hard to maintain, and often inefficient. It also contains bugs, as all code contains bugs.
This observation is not a criticism of scientists, and climate scientists are certainly neither better nor worse at software than those in other fields, but does suggest a way in which software specia/ists could help. It’s a lot more positive and productive than commenting on RC.
Incidentally, I’m very sceptical of an OO approach to cloud modelling in a GCM, although I am sure that OO modelling could be used to study, develop, refine, and validate statistical properties of clouds which could then be applied to a GCM.
By the way, the stupid anti-spam filtering system on RC is an excellent example of crappy software written by software specia/ists. Very poor. What sort of dumb-ass string matching is it using that can’t tell that the word s p e c i a l i s t is not pharma spam? 0/10 for effort.
bobberger says (9 July 2009 at 3:15 PM):
“The question is how flexible it is, how long it takes to introduce new functionality, adjust the underlying logic and principles (mostly physics in this case), trace it and probably more important than anything else – speed it up.”
Look, I know object-oriented programming has become something of a religion in certain circles, but (and I write as someone who’s made a living doing this for some years) you aren’t very likely to speed up a program simply by making it object-oriented. Quite the reverse: part of my master’s thesis involved re-writing a complex object-oriented modeling code (in another field). In addition to adding a good bit of functionality, I sped it up by almost two orders of magnitude, reduced memory footprint by a factor of 10, and decreased the size of the source code by a quarter.
I know – all too well – that code written by scientists for their own use is often not as well-written as it could be, but objectifying it usually makes the problem worse, not better. Ever tried to decipher a poorly-written OO code? In my experience, it’s far more difficult than any tangled mass of spagetti.
#330
James. I never suggested replacing poorly written fortran with poorly written c++ (or whatever). The main problem I see with ModelE is that there seems to be practically no abstraction whatsoever. Just an example (from CLOUDS2.f)
C**** calculate subsiding fraction here. Then we can use FMC1 from the
C**** beginning. The analagous arrays are only set if plume is actually
C**** moved up.
IF (MCCONT.le.0) THEN
FCONV_tmp=MPLUM1/AIRM(LMIN+1)
IF(FCONV_tmp.GT.1.d0) FCONV_tmp=1.d0
FSUB_tmp=1.d0+(AIRM(LMIN+1)-100.d0)/200.d0
IF(FSUB_tmp.GT.1.d0/(FCONV_tmp+1.d-20)-1.d0)
* FSUB_tmp=1.d0/(FCONV_tmp+1.d-20)-1.d0
IF(FSUB_tmp.LT.1.d0) FSUB_tmp=1.d0
IF(FSUB_tmp.GT.5.d0) FSUB_tmp=5.d0
FSSL_tmp=1.d0-(1.d0+FSUB_tmp)*FCONV_tmp
IF(FSSL_tmp.LT.CLDMIN) FSSL_tmp=CLDMIN
IF(FSSL_tmp.GT.1.d0-CLDMIN) FSSL_tmp=1.d0-CLDMIN
FMC1=1.d0-FSSL_tmp+teeny
ELSE
C**** guard against possibility of too big a plume
MPLUME=MIN(0.95d0*AIRM(LMIN)*FMC1,MPLUME)
END IF
As you can see, there is no separation of logic, data, parametrization and actual computation. Its all put together in actual code. If you want to change the bahavior of clouds, you have to change the code, recompile it, test it, debug it, restrain it, set boundary conditions, test again etc.
I spent half may professional carreer being responsible for a CAE project (still more or less pure ANSI C, btw.) and we’d never dreamed of hard-coding the properties of, say, any specific material or tool into the code itself for obvious reasons. These days we rarely touch the code any more and our team has changed over the years from 15 programmers and 6 engineers to 2 programmers and 5 engineers (who know practically nothing about the code – and fortunately don’t have to).
With ModelE, it wouldn’t work like that. Whenever a scientist wants to try a slightly different behavior for any of the physics involved, he or she can’t just define the new rules abstractly and trust the model to handle it appropriately – they have to go in there and change the code itself. To me, that sounds like a lot of time wasted for both – scientists who would probably want to focus on science rather than fortran as well as programmers who probably want to focus on fortran rather than science.
The thing I don’t get about this: If we look at the importance of the climate change issue and of the weight models have in researching it – why are these cornerstones of research apparently not funded appropriately? A few years ago, Gavin noted in a discussion about the ModelE code on Dan Hughes’ blog:
“The level of software engineering support for Numerical Weather Prediction models for instance, is an order of magnitude ahead of what is available for us.”
In the light of what faces humanity, that sounds totally unacceptable.
I would agree with James. My first job in IT was looking after a large software library which was written by 100-odd developers, who were mostly mathematicians. Standard programming training was to be given a copy of Knuth. As a result, some of the code they produced was pretty curly – one genius (he really was a maths genius) managed to bring a Cray to its knees by doing something very odd with file input.
Having said that, their code generally did the job, and did it fast. I rewrote one of their programs in Java – the original was a C program with a command line interface. My program was several times slower at doing calculations, and its only saving grace was that it had a GUI, which actually made it easier for the user to use.
Now, I may have made the program friendlier for the users, but that was about all my formal IT training and OO techniques could do. The underlying maths of the application that the original programmer did was spot on, and I was certainly in no position to make that part of it any better. OO in and of itself would have done nothing to improve the quality of the program – and indeed, the calculation parts of the Java program I wrote were rather more functional than OO.
So while I have not seen the code that you have looked at, I would be very surprised indeed converting it to C++ or Java would make it better just because of being OO.
Great remarks on coding.
I suppose it’s possible that– as with so many software projects that are originally envisioned as a one-off effort not really intended for application by a wider user base or even intended to be run often– nobody imagined how important this would become, nor perhaps how many times the code would need to be revisited and extended or modified.
Certainly I can picture that not only were budgets lacking to bring in software-specific talent, but even producing requirements specifications at the time to feed to engineers would have been enormous friction in terms of getting results. It is a fact that much software is used as a calculational jig with no intention for production operations.
Reading Spencer Weart’s –excellent– synopsis of climate science, I can just picture how some of these projects were started.
Not a criticism, at all, quite likely wrong for that matter.
Now there’s no excuse to starve this important work. To the extent they’d like assistance, folks operating models should be provided with that. It’s so little money, after all, compared to what’s in play as an upshot of their work.
Nick,
If it would help at all I could give you the Fortran code I wrote for a recent radiative-convective model of Earth’s atmosphere. I’ve been told I have an unusually clear coding style.
The simulation isn’t great in terms of accuracy. I get 293 K for the Earth’s mean global annual surface temperature (should be 288 K), and doubling CO2 alone raises Ts by 3.4 K (should be 1.2 K). But it illustrates some of the principles involved.
Re: large climate codes, FORTRAN, legacy code
I have some experience dealing with substantial bodies of old code. The reason scientists (at least in physics and engineering) prefer to use these codes is that they have been debugged well over the years, their accuracy under various floating point schemes is very well characterized, and (very important) their output is reproducible.
I am personally acquainted with codes from the 1960’s running today. I have written FORTRAN code thirty years ago that is still in use. These are not in use because they are pretty. They are in use because they are well understood.
Barton: that’s very generous. Although clearer Fortran would be an improvement, the CCC project is moving away from Fortran altogether towards programming languages which are intrinsically more accessible to non-scientists.
However, we would definitely appreciate help from anyone who can read Fortran code (mostly F77-ish) and accurately document the algorithm in English (and maths).
sidd: in terms of “accuracy under various floating point schemes”, I observe that GISTEMP’s answers depend on the Fortran compiler used (different compilers, and different releases of the same compiler, have radically different notions of rounding).
Many of the intermediate results of GISTEMP are also basically impossible to reproduce to a bitwise level in languages which prefer 64-bit floats. For instance, there are several phases which combine many data points in an order determined by sorting computed weights, and the sort order changes when using 64-bit floats as opposed to 32-bit, and the combining function is not symmetric. This doesn’t seem to make much of a difference to the final results – although a few of the sub-box monthly temperatures do change significantly – but does make it hard to test piece-wise replacement of Fortran phases with Python phases. I’d like to be able to use binary diff, to maximise confidence in the Python code (which encapsulates our understanding of the algorithms).
Mr. Barnes writes:
“I observe that GISTEMP’s answers depend on the Fortran compiler used (different compilers, and different releases of the same compiler, have radically different notions of rounding).”
Yes. This is an old problem, partially addressed in MIL-STD 1750 and later, IEEE-754. I have had issues in the past when larger hardware allowed us to ‘upgrade’ our algorithms to double, and then (in some cases) quadruple precision. Occasionally, we found that doing so provoked instabilities in the algorithms which were not previously revealed in lower precision schedules, as you are seeing. I recall that these issues were addressed by carefully examining the routines, sometimes rewriting them entirely, and even sometimes returning to lower precision in a few parts of the calculation, where the extra precision was unnecessary. This was always accompanied by careful testing against the original routines to verify that previous results were a)correct and b)reproducible.
Re: help with reading/documenting F77
My time is limited, but I will help as I may.
Further to James’ comment “Look, I know object-oriented programming has become something of a religion in certain circles, ”
Worse, too many people Objectify EVERYTHING.
They make a class that does nothing but three lines of code. Tacking a bug is impossible because of inherent constructors/base methods.
Some problems really ARE better solved by procedural programming, but too many programmers think they MUST solve it in an OO-stylee.
May be elegantly written, but a PITA to work out where something is going wrong.
You can seriously screw up in absolutely every language – fortran being just one of them. And there surely is lots of code out there that was never changed and works just fine (I think the first banking project I worked on for my current employer back when I was a student is still in production – at least they did some Y2K testing with it back in the late 90s – and that was in COBOL) but it was never really changed and of course when a new company hit the market, they didn’t have to edit the code and add mindbogglingly specific lines.
ModelE changes all the time and it HAS to change because its structured in a way that won’t allow it to learn any new tricks through anything but reprogramming. It practically begs for OOP. If NASA is afraid of that for whatever reason, they could still stick with a strictly procedural approach and put in some extra work but either way – they’ll have to introduce some serious abstraction if they want to improve the way this thing handles and performs.
“ModelE changes all the time and it HAS to change because its structured in a way that won’t allow it to learn any new tricks through anything but reprogramming. It practically begs for OOP.”
Well, go ahead.
Use the source, Luke…
On the subject of bupkis, Peter Sissons cannot count
http://www.bbc.co.uk/blogs/climatechange/2009/07/bbc_stifles_climate_change_deb.html
the number of scientists who say AGW is wrong.
“Well, go ahead.”
Even when used purely as a “shut up” kind of argument, this displays an astounding (though rather common) naivitee about computing.
As a software professional, I find bobberger’s comments on the maintainability of old code pretty reasonable in general. They don’t go much beyond motherhood and apple pie for practitioners in the field, though. Discussion of OO in particular is just way OT, and a yawn on this thread.
Stefan, wouldn’t you admit that your non-linear trend line in your Science paper is flawed? A better way to do this would clearly have been to compare the linear trend of the data to the projections!
[Response: We agree on the main point: only the linear trend can be meaningfully compared with such a short noisy time series. As the TAR projections start in 1990, there is simply not enough data points to say any more, e.g. about the curvature (whether the trend has accelerated or slowed down). That is why we chose the parameters of the smooth curve so that it is almost linear after 1990, and we verified it is practically the same as the linear trend line. (We explained this more in our online-update of the diagrams.) A non-linear trend line has the added advantage that it joins smoothly to the pre-1990 data and is less sensitive to the choice of start year. So in my view this is the best way to do it – but if you prefer using a linear trend, that’s also fine and gives the same result. -stefan]