1. What are “pseudo-proxies” and why are they useful?
Our only information from before the “instrumental period” (the period from which we have systematic measurements with thermometers, starting around 1850) comes from proxy records of climate (like tree rings, ice cores, corals, sediments, pollen etc.). Therefore it is important to know what the available kind and distribution of proxy records can tell us about quantities that we care about (like changes in the average temperature of the northern hemisphere). A typical question is: what accuracy for the northern hemisphere temperature can one expect, given the available number and spatial distribution of proxies? How much uncertainty arises from the non-climatic ‘noise’ in these records? How do the different methods for combining the proxies compare? And so on…
If there was sufficient length of good instrumental data, then we would be able to answer these questions simply by comparing measurements with proxy records. But the instrumental record is short – after all this is the prime reason why we have to rely on proxies.
Enter the virtual world of climate models. This world may not exactly match the real world – but within this world, we have complete information about any changes in climate. Recently a number of simulations using different models have been made for the last 1000 years. These simulations can be used as a numerical laboratory in which we can test the reconstruction methods and assess their potential limitations, by pretending to derive proxy records of the model climate, called “pseudo-proxies”.
The first stage is to designate points in the model where you want to derive a proxy record. A good idea is to take the same points on the globe that are used for a real proxy reconstruction – then you can test, e.g., how good this particular spatial coverage is for capturing the hemispheric mean. Secondly, you need to determine what is recorded in your pseudo-proxy. This can be simple or it can be complicated. The simplest is to assume that the pseudo-proxies depend on local temperature (which is known in the model world, of course), plus some non-climatic noise (this is the approach taken by von Storch et al.). This could be significantly more complicated if desired – the pseudo-proxy could be dependent on precipitation as well, or on more sophisticated climate metrics (such as growing degree days for tree rings for instance).
However, there are a few caveats that one needs to be aware of. First, the climate field reconstruction (CFR) methods (like MBH98 and more recently the RegEM methodology in Rutherford et al, 2005) rely on the observed tele-connections between local processes recorded in the proxies and large-scale climate patterns. For instance, a precipitation record that is influenced by ENSO contains information about ENSO and hence regional temperatures, even if it is not locally reflecting temperature changes. If the climate model has different tele-connections from the real world, or a different balance of different sources of variability (ENSO vs. NAO etc.), the cross-correlations of the pseudo-proxies to the large scale patterns might be different. Since the models that we are discussing do not tend to have very realistic ENSO variability, this is a significant point. Secondly, all the CFR methods implicitly rely on the stationarity of some aspects of climate variability over the modern period compared to the last 1000 years (specifically that the patterns of variability are not hugely different over the last 150 years than they are in the previous 850 years). There is no hard evidence that this isn’t the case (as it might be over the glacial period for instance), but the same must be true in the model as well. If there is an important cause of variability in the model that is not operating in the calibration/verification period, then that could cause problems. Large climate drifts in the beginning of the simulation might fall into that category (see below).
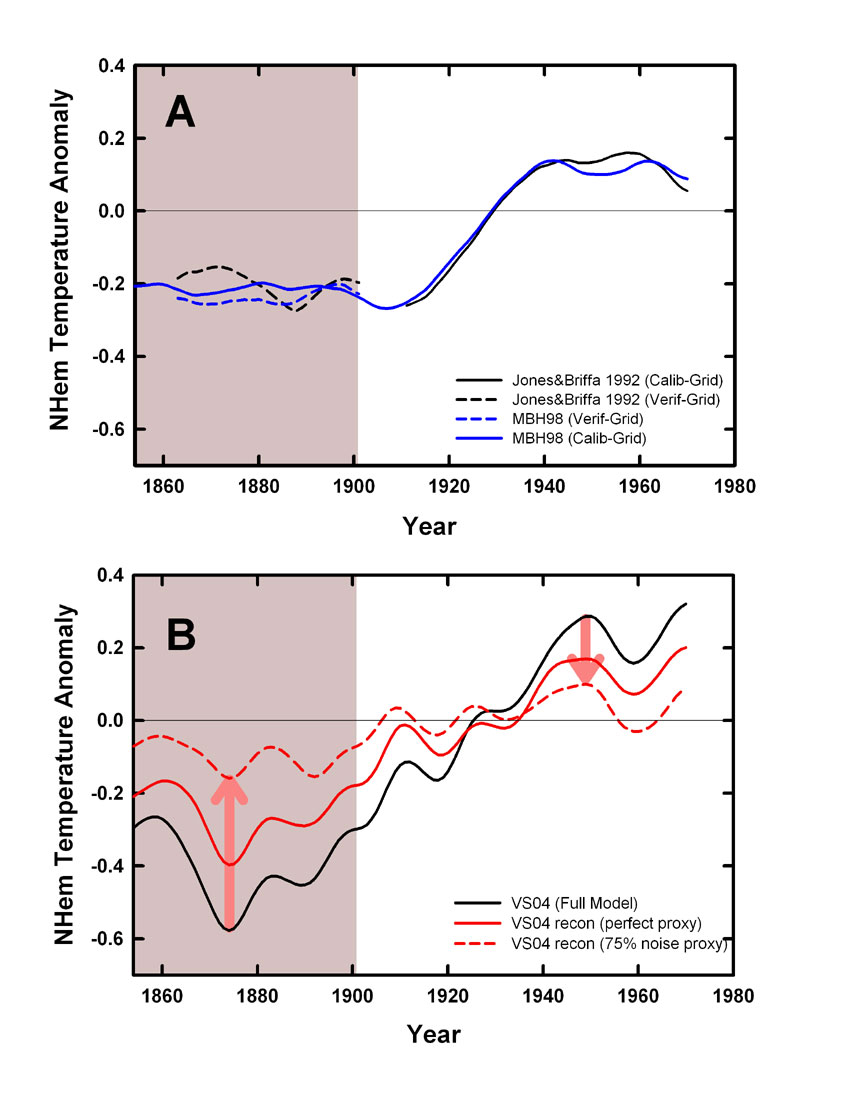
Figure: The upper panel shows the how the MBH methodology matches the trends and variability in the calibration period (the unshaded area). The estimate over the verficiation period (shaded region) can then be compared to see what predictive power it has. In the lower panel, the von Storch et al emulations are shown as a function of the non-climatic ‘noise’ that is added. The large difference between the black solid line and its reconstruction, the red dashed line, shows that the Von Storch method already fails in the calibration and verification periods. This should have alerted the authors that something is wrong.
The basic problem is illustrated in the above figure. The MBH method is designed so that the mean and variance over the calibration period in the proxies and the observations are the same, and the overall trends will be similar. The ‘verification’ period is used to see whether the reconstruction of the proxies matches the mean offset during that period seen in the observations. The results from the von Storch et al emulation demonstrate that this is not so for their methodology and that it is clear that their emulations would fail verfication tests. Detrending during the calibration interval is thus equivalent to removing a substantial part of the low frequency signal (though exactly how much will depend on the simulation). As an aside, Burger and Cubasch (GRL,2005; Tellus, 2006) suggest that detrending is simply an arbitrary choice in these kinds of methodologies, but these results show that it is clearly deliterious to the skill of the reconstruction, and thus there is an a priori reason not to use it.
3. The problem of climate drift
Von Storch et al. (2004) started their model from an initial climate state that was in equilibrium with 372 ppm CO2, which already includes the anthropogenic rise of carbon dioxide. However, their model experiment was meant to start at 1,000 AD, when carbon dioxide levels were only 280 ppm. Therefore, CO2 concentration was dropped in the model from 372 down to 280 ppm over 30 years, followed by a 50-year adjustment period with constant 280 ppm CO2, before the start of the 1000-year run proper. Not surprisingly, the global temperature dropped by about 1.5 ºC during this transition phase. None of this is reported in their paper or online supplement.
This initialisation procedure is a rather unsatisfactory as it would be expected to cause a large climate drift during the experiment. It is as if someone wanting to measure temperature variations outside was using a thermometer that he just brought out from a heated room. If you looked at this thermometer before it had fully adjusted to the outside temperature, you would see a cooling trend that has nothing to do with actual temperature changes outside.
Those experienced with coupled climate models know that the time scale to fully adjust after such a major drop in CO2 concentration is many hundreds of years, due to the slow response time of the oceans. Even if the Von Storch team had not expected this problem, they must have clearly seen it unfold: the trend in their model during the transition phase reveals that it was far from equilibrium, and they should at the very least have mentioned this problem as a caveat in their papers.
In the absence of this information, many colleagues were puzzled by the strong cooling trend throughout the pre-industrial era in this simulation, which made it an outlier compared to all other available simulations of the past millennium. Was this due to a particularly high climate sensitivity of this model? Or was this due to the forcing used? Correspondence with the Von Storch group brought no clarification. Finally, Osborn et al. (2006) identified this as due to a climate drift problem.
The latest publication by the Von Storch team (Gonzalez-Rouco et al. 2006) shows a second run with their model, where the medieval time is about 0.5 ºC colder and the subsequent cooling trend to the 19th Century is only about half as large. This shows that the medieval time was about 0.5 ºC too warm due the lingering anthropogenic warmth in their earlier model, and about half of the long-term climate cooling in their Science paper must have been due to the artificial drift. Several further papers in other journals are based on the ECHO-G simulation affected by the large drift, and their editors may now have to consider appropriate corrigenda.
4. Are the HadCM3 and ECHO-G results similar?
Von Storch et al. performed their pseudo-proxy test with two models: the ECHO-G model and the HadCM3 model. The results of both tests are compared in the figure. In the ECHO-G model (red lines) the performance of the pseudo-proxies is very poor, as the difference between the full and dotted red lines is huge. In the HadCM3 model (blue lines) however, the performance is much better – those results would not have served as a cause for dramatic headlines.
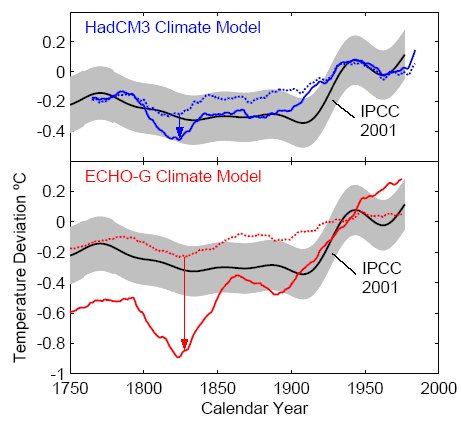
Figure: Test of proxy climate reconstruction method with two climate models, HadCM3 and ECHO-G. Solid lines show Northern Hemisphere temperature in the models (31-year running means), the dotted lines show simulated proxy reconstructions where the proxies are degraded with 75% noise. The error of the proxy method is the difference between the solid and dotted lines (arrows). For comparison, we show the Mann et al. 40-year-smoothed reconstruction for the Northern Hemisphere temperature (black) with its 95% confidence interval (grey), as shown in the IPCC Third Assessment Report (Fig. 2.21). (Note that results from both models are affected by the calibration error discussed in 2.) We thank Von Storch and coauthors for providing the data of their model experiments.
These rather different results of the two models should have raised a red flag – most scientists would in this situation have paused to investigate the cause of the difference, which could have pointed them to their detrending problem. Von Storch et al. instead show the HadCM3 results only in the online supplement, which very few readers look at. In the paper itself they only show the ECHO-G results where the pseudoproxies perform poorly; about the HadCM3 results we only learn that they are “similar”.