
The 4th UArctic congress on the Faroe islands finished with the message that the Arctic Council is still alive. It has overcome recent setbacks with difficulties concerning two of its member states, Russia and the US. The Arctic Council represents 8 nations together with indigenous peoples and has observers from around the world, and this wide-ranging diversity of course coloured the congress. It … Read Full Article about “The Arctic Council is not dead”
Main Content
Featured Story
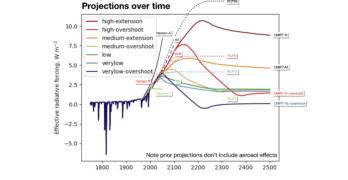
Scenarios, schmenarios…
The fantasy version of the normal updating of scenarios for a new round of CMIP simulations doing the rounds is bad faith BS. … Read Full Article about Scenarios, schmenarios…
Recent Posts
Unforced Variations: June 2026
This month's open thread on climate topics. Please be respectful and substantive. … Read Full Article about Unforced Variations: June 2026
Unforced Variations: May 2026
This month's open thread on climate topics. El Niño coming (shades of 2023), competitive predictions, ill-advised geo-engineering ideas, and massive shifts in renewable energy roll out. Surely something there to discuss... … Read Full Article about Unforced Variations: May 2026
Unforced Variations: Apr 2026
Somewhat belated open thread for this month! (Oops). Please stick to climate related topics, and remain respectful. … Read Full Article about Unforced Variations: Apr 2026

A reflection on reflection
Confirmation bias and a profound lack of curiosity mark the latest ABC (Anything But Carbon) contrapalooza in DC this week and a decade-old albedo error trips them up. … Read Full Article about A reflection on reflection

Spencer’s Shenanigans: Part II
We previously highlighted Roy Spencer's poor practices in comparing models with observations, but we've now dug down a little deeper, and it's not pretty. … Read Full Article about Spencer’s Shenanigans: Part II

The Puzzling Pleistocene
The mystery of why the last million or so years of glacial variability are so different to what came before just got more mysterious... … Read Full Article about The Puzzling Pleistocene

How robust is our accelerometer?
Guest commentary from Nathan Lenssen (Colorado School of Mines) A new analysis of historical temperatures suggests that things are getting warmer faster, but what does it mean for the future? … Read Full Article about How robust is our accelerometer?
Unforced Variations: Mar 2026
This month's open thread for climate related topics. … Read Full Article about Unforced Variations: Mar 2026
EPA’s final* ruling on CO2
The EPA has announced its final* ruling on the CO2 Endangerment Finding. *not even close to final. … Read Full Article about EPA’s final* ruling on CO2

The Climate Science reference they don’t want Judges to read
For the first time, the Federal Judicial Center (FJC) commissioned a chapter on climate science for the manual they put out (with the NASEM) for judges, the Reference on Scientific Evidence (4th Edition). This week, a month after it was published, they pulled the chapter out after being pressured by … Read Full Article about The Climate Science reference they don’t want Judges to read