There has been a lot of discussion about decadal climate predictions in recent months. It came up as part of the ‘climate services’ discussion and was alluded to in the rather confused New Scientist piece a couple of weeks ago. This is a relatively “hot” topic to be working on, exemplified by two initial high profile papers (Smith et al, 2007 and Keenlyside et al, 2008). Indeed, the specifications for the new simulations being set up for next IPCC report include a whole section for decadal simulations that many of the modelling groups will be responding to.
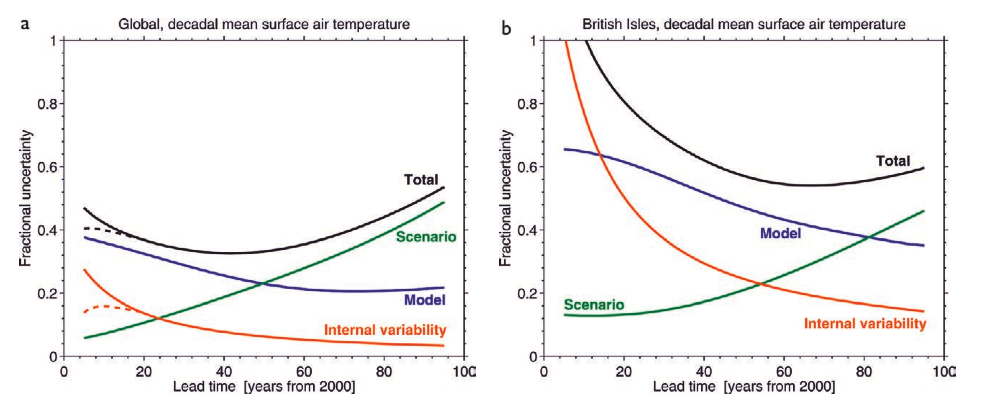
This figure from a recent BAMS article (Hawkins and Sutton, 2009) shows an estimate of the current sources of prediction error at the global and local scale. For short periods of time (especially at local scales), the dominant source of forecast uncertainty is the ‘internal variability’ (i.e. the exact course of the specific trajectory the weather is on). As time goes by, the different weather paths get averaged out and so this source of uncertainty diminishes. However, uncertainty associated with uncertain or inaccurate models grows with time, as does the uncertainty associated with the scenario you are using – ie. how fast CO2 or other forcings are going to change. Predictions of CO2 next year for instance, are much easier than predictions in 50 years time because of the potential for economic, technological and sociological changes. The combination of sources of uncertainty map out how much better we can expect predictions to get: can we reduce error associated with internal variability by initializing models with current observations? how much does uncertainty go down as models improve? etc.
From the graph it is easy to see that over the short term (up to a decade or so), reducing initialization errors might be useful (the dotted lines). The basic idea is that a portion of the climate variability on interannual to decadal time scales can be associated with relatively slow ocean changes – for instance in the North Atlantic. If these ocean circulations can be predicted based on the state of the ocean now, that may therefore allow for skillful predictions of temperature or rainfall that are correlated to those ocean changes. But while this sounds plausible, almost every step in this chain is a challenge.
We know that this works on short (seasonal) time scales in (at least some parts of the world) because of the somewhat skillful prediction of El Niño/La Niña events and relative stability of teleconnections to these large perturbations (the fact that rainfall in California is usually high in El Niño years for instance). But our ability to predict El Niño loses skill very rapidly past six months or so and so we can’t rely on that for longer term predictions. However, there is also some skill in seasonal predictions in parts of the world where El Niño is not that important – for instance in Europe – that is likely based on the persistence of North Atlantic ocean temperature anomalies. One curious consequence is that the places that have skillful and useful seasonal-to-interannual predictions based on ENSO forecasts are likely to be the places where skillful decadal forecasts do worst (because those are precisely the areas where the unpredictable ENSO variability will be the dominant signal).
It’s worth pointing out that ‘skill’ is defined relative to climatology (i.e. do you do a better job at estimating temperature or rainfall anomalies than if you’d just assumed that the season would be just like the average of the last ten years for instance). Some skill doesn’t necessarily mean that the predictions are great – it simply means that they are slightly better than you could do before. We should also distinguish between skillful (in a statistical sense) and useful in a practical sense. An increase of a few percent in variance explained would show up as improved skill, but that is unlikely to be of good enough practical value to shift any policy decisions.
So given that we know roughly what we are looking for, what is needed for this to work?
First of all, we need to know whether we have enough data to get a reasonable picture of the ocean state right now. This is actually quite hard since you’d like to have subsurface temperature and salinity data from a large part of the oceans. That gives you the large scale density field which is the dominant control on the ocean dynamics. Right now this is just about possible with the new Argo float array, but before about 2003, subsurface data in particular was much sparser outside a few well travelled corridors. Note that temperature data are not sufficient on their own for calculating changes in the ocean dynamics since they are often inversely correlated with salinity variations (when it is hot, it is often salty for instance) which reduces the impact on the density. Conceivably if any skill in the prediction is simply related to surface temperature anomalies being advected around by the mean circulation, it could be possible be useful to do temperature only initializations, but one would have to be very wary of dynamical changes and that would limit the usefulness of the approach to a couple of years perhaps.
Next, given any particular distribution of initialization data, how should this be assimilated into the forecasting model? This is a real theoretical problem given that models all have systematic deviations from the real world. If you simply force a model temperature and salinity to look exactly like the observations, then you risk having any forecast dominated by model drift when you remove the assimilation. Think of a elastic band being pulled to the side by the ‘observations’, but having it snap back to it’s default state when you stop pulling. (A likely example of this is the ‘coupling shock’ phenomena possibly seen in the Keenlyside et al simulations). A better way to do this is via anomaly forcing – that is you only impose the differences from the climatology on the model. That is guaranteed to have less model drift, but at the expense of having the forecast potentially affected by systematic errors in, say, the position of the Gulf Stream. In both methods of course, the better the model, the less bad the problems. There is a good discussion of the Hadley Centre methods in Haines et al (2008) (no sub reqd.).
Assuming that you can come up with a reasonable methodology for the initialization, the next step is to understand the actual predictability of the system. For instance, given the inevitable uncertainties due to sparse coverage or short term variability, how fast do slightly differently initialized simulations diverge? (Note that we aren’t talking about the exact path of the simulation which will diverge as fast as weather forecasts – a couple of weeks, but the larger scale statistics of ocean anomalies). This appears to be a few years to a decade in “perfect model” tests (where you try and predict how a particular model will behave using the same model but with an initialization that mimics what you’d have to do in the real world).
Finally, given that you can show that the model with its initialization scheme and available data has some predictability, you have to show that it gives a useful increase in the explained variance in any quantities that someone might care about. For instance, perfect predictability of the maximum overturning streamfunction might be scientifically interesting, but since it is not an observable quantity, it is mainly of academic interest. Much more useful is how any surface air temperature or rainfall predictions will be affected. This kind of analysis is only just starting to be done (since you needed all the other steps to work first).
From talking to a number of people working in this field, my sense is that this is pretty much where the state of the science is. There are theoretical reasons to expect this to be useful, but as yet no good sense for actually how practically useful it will be (though I’d welcome any other opinions on this in the comments).
One thing that is of concern are statements that appear to assume that this is already a done deal – that good quality decadal forecasts are somehow guaranteed (if only a new center can be built, or if a faster computer was used). For instance:
… to meet the expectations of society, it is both necessary and possible to revolutionize climate prediction. … It is possible firstly because of major advances in scientific understanding, secondly because of the development of seamless prediction systems which unify weather and climate prediction, thus bringing the insights and constraints of weather prediction into the climate change arena, and thirdly because of the ever-expanding power of computers.
However, just because something is necessary (according to the expectations of society) does not automatically mean that it is possible! Indeed, there is a real danger for society’s expectations to get completely out of line with what eventually will prove possible, and it’s important that policies don’t get put in place that are not robust to the real uncertainty in such predictions.
Does this mean that climate predictions can’t get better? Not at all. The component of the forecast uncertainty associated with the models themselves can certainly be reduced (the blue line above) – through more judicious weighting of the various models (perhaps using paleo-climate data from the LGM and mid-Holocene which will also be part of the new IPCC archive), improvements in parameterisations and greater realism in forcings and physical interactions (for instance between clouds and aerosols). In fact, one might hazard a guess that these efforts will prove more effective in reducing uncertainty in the coming round of model simulations than the still-experimental attempts in decadal forecasting.
“but where is the model that can predict at least a fair number of these results in its own right?”
What does that mean?
The change in models is because they improve the models. Yet they still go back and run hindcasts to show that the new model too predicts those features in the past.
So it is already done for subsequent models.
And doing it for earlier models just tells you that, if it fails, the model then was insufficient for the prediction. But that is why you made the newer model, isn’t it.
Regarding #48
I think “Bushy” is expecting that individual models simulate all the observed effects. IE, that the TopKnot model V1.x projects temperature changes at various altitudes, ENSO states, global temperatures, ocean currents, regional weather, and all the other things that scientists now model about climate.
Bushy appears to think that BPL is cherry picking to say that TopKnot V1.x got the atmospheric temps right at various altitudes but got the ocean currents wrong, and that NasaMod V4.y got the ocean circulation right but everything else wrong, and that BPL is taking the part of each that it got right and ignoring all the things it got wrong.
I think the problem is in the basic assumption that there are any such all-encompassing models. Suites of models might look at radiative physics, CO2 distribution throughout the atmosphere, partial pressures and whatnot and project temperature stratifications. But that same model doesn’t predict global temperatures, ocean currents, or migration of Hadley cells.
— David
#33 – Pete Best wonders how much CO2 1 ppm represents.
It’s funny you should ask that Pete. Just this morning I was calculating the energy trapped by CO2 compared to the energy release by its formation. I found some fairly different calculations of that. The one that looks properly calculated is at http://answers.yahoo.com/question/index?qid=20070908101242AALwgLr and concludes that it takes about 8 gigatons of CO2 to add 1 ppm to the atmosphere.
The answer I got was that takes just about a year for the CO2 from burning a ton of carbon to trap as much heat as was released during the combustion. Given that the residence time in the atmosphere is measured in centuries, we add a lot of heat to the planet every time we burn a ton of coal.
— David
Gavin, your response to #46. What’s your take on the multimodel mean being better than any single model – do you think that is also “noise” (i.e. uncorrelated model error) canceling out? And do you think a multimodel mean would also perform better than any single model in decadal prediction?
[Response: Not yet clear. It is clear that for a lot of fields the multi-model mean is better than any single model, implying that there is at least some random component associated with any individual model error. But it remains mysterious as to why that is or whether you can’t do better. More research needed as they say… – gavin]
BPL – I see you have that models gave a pretty good prediction of the amount and duration of cooling that the increased aerosols from the Mt Pinatubo eruption caused you could also include the consequent change in humidity, providing increased confidence that the models have the positive water vapour feedback about right.
References:
http://www.sciencemag.org/cgi/content/full/296/5568/727 [free sub required]
http://pubs.giss.nasa.gov/abstracts/1996/Hansen_etal_2.html
Phil Clarke
#xx: [edit – post now deleted]
Your story already falls apart at the very first point, but for that you probably need to be aware of the meaning of “detrended”. Is it just me, or is there a growing group of people with a university education who don’t understand that concept? First McLean et al removed the trend and then claimed to have explained the trend, on Jennifer Marohasy’s blog Tim Curtin removes a trend and then claims there is no trend, and here we have a Dr. Löbert who looks at de-trended data, and then claims the data shows there is no AGW…
Oh, and if you are so certain of your analysis about the universe, why isn’t any of it published in a physics journal? In fact, have you EVER published anything in a physics journal? Spamming it all over the internet does not make it valid, but rather indicates you can’t get it into even the most low-ranked physics journal.
[Response: Sorry – we shouldn’t have let that through. This is not a repository for people to post their crackpot physics ideas! (Thanks for the swift rebuttal though!). – gavin]
@ Various people in reply to my post at #32.
Yes, I _have_ to “do it myself”. I hope my maths are up to it. I remember something about root mean squares from school – but that is 50 or more years back.
But yes, only “do it yourself” will work. Relying on the skills of others means relying on “authority” and that means if one is challenged, say by a denier, one is on weak ‘mental’ ice.
Thanks in advance.
Theo.
Re #56,
It should be noted that Marco is not referring to the existing post 54; he is referring to a crank post which briefly appeared in the 54 slot. ‘Twas a pity that the crank got deleted — it’s not often that you see all of climate science *and* Albert Einstein simultaneously swept into oblivion.
[Response: I’ve made that clearer. Comedic potential aside, that kind of stuff is not worth our time. – gavin]
Barton P. L., nice list!
It might be fun also to look at how far back some of these predictions were made. I was just reading Oreskes (“How do we know…”), and she cites Manabe and Stouffer (1980) as predicting your #5 (polar amplification). I looked it up. They put a GCM with a simple mixed layer model of the oceans through a quadrupling of atmospheric CO2. My layman’s take is that they also got your #2 (tropospheric warming, stratospheric cooling), #4 (winter temperatures increase more than summer temperatures), and #6 (Arctic warming faster than Antarctic). As for the warming, this particular study got 2ºC for 2xCO2 (based on 4º for 4xCO2).
Considering recent events, I find this bit rather poignant: “It is of interest that the sea ice disappears completely from the Arctic Ocean during a few summer months in the 4 x CO2 experiment”.
As time goes by, the different weather paths get averaged out and so this source of uncertainty diminishes.
I am wondering about justification for the above. Certainly in my work with non-linear coupled dynamics, this is emphatically not the case. Thresholds are reached, feedback sensitivities change as a function of output state variables, coupling coefficients evolve. All of this combines to produce system evolution that may bifurcate or move to an entirely different limit cycle trajectory. In these systems (of which I think climate dynamics is a member), one could never state a priori that all possible state trajectories average to a mean of any predictive value. What is different about GCMs that makes this true?
[Response: There are very significant constrains on energy fluxes to and from space, and strong negative feedbacks through the fourth power dependency on the emitting temperature that keep things bounded. The same constraints occur in the real world, though it isn’t obvious (nor provable) that the real climate itself is not chaotic. The GCM climates are not – the statistics are stable over time and do not have a sensitive dependence on initial conditions. Think of the structural stability of the Lorenz butterfly even while individual trajectories are truly chaotic. – gavin]
Sort of on topic: On a previous thread here there was discussion on the possibility of attributing extreme single events (2003 French heatwave) to AGW. So following the tragic impact of typhoon Ketsana on Manila, I’m wondering if there’s more one justifiably say could say beside “this is the kind of thing we expect to have more of due to man-made warming, and over the last decade(s) there has, indeed, been more of it”?
This sounds like an exciting and, if models can successfully project decadal temperatures, a very interesting attempt at short term analysis. I would hope that from time to time modelers will state reminders that decadal numbers,regardless of direction, don’t indicate a trend.
Mr. Miller writes at 12:32 PM, 30th Sep. 2009:
“The answer I got was that takes just about a year for the CO2 from burning a ton of carbon to trap as much heat as was released during the combustion.”
the mass cancels out of the equation ? i.e. any mass of carbon burnt to CO2 released into the atmosphere will trap the same amount of heat in a year as was generated during combustion ?
or i am quite muddled up ?
I have some experience with modelling in engineering fields. I’m not a climate scientist. One concern I have with modelling is that with enough fiddling, a model can be made to fit past history, but that says nothing about how well it will predict the future. When a model does not accurately predict the future, then it is typically tweaked to fit the recent past that the previous model failed to predict. Failure of the climate models to predict accurately leaves me wondering, with so many climate variables, how can we be sure that increases in CO2 levels has caused the current global warming trend? Just because CO2 is going up with the temperature does not mean its is the cause. How has the causal relationship been proven?
[Response: We discuss what goes into the models and how they are developed in a couple of FAQs (Part I, Part II) on the subject. Much of what you are asking is answered there. As for the big question of attribution of current trends, see the relevant chapter in the IPCC report – it isn’t that difficult a read. – gavin]
Sidd (#63):
Not a cancel, but a double whammy. 2X heat + 1X heat each of subsequent years.
Steve
Sidd asks if the mass cancels out in #63.
Yes, Sidd. Mass cancels out. Carbon releases ~33 GJ/ton when you burn it, and according to my calculations the resulting CO2 traps 32 GJ per year. Multiply by the residence time of the CO2 for the final tally.
It’s completely unrelated to mass – 10 tons produce 10 times as much CO2 that traps 10 times as much IR energy.
Perhaps someone here could clarify something for me. I took the value for heat trapped as 1.66 watts/m^2 from an epa.gov web page. I know that’s in the ballpark, but two things about it are not clear to me:
1) Does 1.66 watts/m^2 include the additional water vapor effects?
2) Is the square meter referred to the surface area of the earth or the disk facing the sun? IE, pi*r^2 or 4*pi*r^2.
I was trying to get a rough calculation, but it would be nice to get as close as possible.
> 10 times as much CO2 that traps 10 times as much IR energy.
No. Citation needed — why do you think this is true? What source are you relying on and why do you trust it enough to repeat it as though it’s a fact?
See what you find here, e.g.
https://www.realclimate.org/index.php/archives/2007/06/a-saturated-gassy-argument/
CO2 or any other greenhouse gas isn’t capturing and holding the energy — it catches and releases it. What matters is the proportion in the atmosphere.
Take a big sheet of window glass. You can see right through it.
Look at it edge on. It looks dark blue-green.
Why?
This is really basic. Start with Weart, first link under the Science heading.
David Miller: The way I would do the calculation would be to state that 2.1 gigatons of C produce about 1 ppm of CO2. However, that 1 ppm will slowly decrease over time: using the Bern Cycle approximation, over 100 years it totals to about 48 ppm-years (reality may vary from the approximation for all sorts of reasons).
1 ppm of CO2 is about 0.014 W/m2 at the current concentration of CO2 (5.35*LN(C/C0)). That’s averaged over the entire surface area of the earth. That doesn’t include any feedback effects, which could lead to a gain of 1.7 to 3.7 times the original forcing (for the standard 2 to 4.5 degree sensitivity, according to Roe and Baker) or more.
Does that help?
“No. Citation needed — why do you think this is true?” “Not a cancel, but a double whammy”
Hank and Steve: I think you didn’t read the statements quite right. Basically, he’s just trying to say that if you are trying to determine the energy added to the system from the CO2 greenhouse effect, and compare it to the energy added to the system by the burning of the carbon that led to the CO2, that, for reasonable quantities of CO2 it doesn’t matter how much you are adding because it cancels out in the ratio (integral of total top-of-the-atmosphere radiative forcing over time) divided by (energy from burning).
Yes, if you add enough CO2, you’ll have to start caring about the logarithmic relationship. Yes, if you care about total energy added to the system, you need to add burning energy to greenhouse energy. But if you just care about comparing greenhouse energy to energy released from burning for small quantities of coal burned, it is much simpler. And I’ll note that greenhouse energy is much greater than combustion energy (my back of the envelope calculation a few years back suggested by more than two orders of magnitude: hopefully David’s approach will yield something similar).
My apologies. My previous comment is not what I intended. (I blame lack of preview.) This is what I intended:
CM says:
30 September 2009 at 4:57 PM
Some background on the effect of global warmiing on precipitation can be found in AR4 chapter 3. See question 3.2 on page 262 (page 28 in the pdf). In particular:
See also section 9.5.4.2.2, Changes in extreme precipitation, page 714 (page 52 in the pdf).
The possibility that global warming will result in more rainfall from tropical cyclones has been mentioned by Trenberth and others many times, for example in Uncertainty in Hurricanes and Global Warming . (Interestingly, about two years ago there was a paper arguing that the models were underestimating increases in rainfall due to global warming: How Much More Rain Will Global Warming Bring? .)
I highly recommend people to Reto Knutti’s article on the subject of believing model predictions in the future. It is not primarily concerned with decadal predictions in the sense of a lot of recent literature, but it’s very informative on model usage and I’ve found myself citing it a lot.
http://www.iac.ethz.ch/people/knuttir/papers/knutti08ptrs.pdf
A relatively recent report by USCCP on the Strengths and Limitations of climate models is also a very comprehensive treatment (maybe even moreso than IPCC) of the subject.
Just suggestions.
Re: Mr. Miller, energy imbalances:
is this your calculation ?
if m0 is the current mass of CO2 in the air, j0 is the current radiative forcing in watts/sq. m., and you add dm more mass of CO2
then do you take the additional forcing dj to be given by
dm/m0=dj/j0
(of course, i expect this relation might hold only when dm is much less than m0 and dj is much less than j0…)
and then go to additional heat dQ by multipling by area and time thus
dQ=dj*A*T=dm*j0/m0*A*T
where j is in watts, A is the appropriate area in sq. m. and T is the the number of seconds in a year
re BPL list of model predictions;
Svante Arrhenius (1859-1927)
“On the Influence of Carbonic Acid in the Air upon the Temperature of the Ground”(excerpts) Philosophical Magazine 41, 237-276 (1896)[1]
at http://web.lemoyne.edu/~giunta/arrhenius.html
“The influence is in general greater in the winter than in the summer, except in the case of the parts that lie between the maximum and the pole. The influence will also be greater the higher the value of ν, that is in general somewhat greater for land than for ocean. On account of the nebulosity of the Southern hemisphere, the effect will be less there than in the Northern hemisphere. An increase in the quantity of carbonic acid will of course diminish the difference in temperature between day and night. A very important secondary elevation of the effect will be produced in those places that alter their albedo by the extension or regression of the snow-covering (see p. 257 [omitted from this excerpt–CJG]), and this secondary effect will probably remove the maximum effect from lower parallels to the neighbourhood of the poles[12].”
“I should certainly not have undertaken these tedious calculations if an extraordinary interest had not been connected with them.” Still is, except in some (wilfully ignorant) quarters.
Of course, denialists will try to conflate “inaccurate” with “wrong”,(he overestimated the drop in CO2 for an ice age) but he did remarkably well for a paper & pencil model.
Phil, CM, Brian Dodge: Thanks! That’s some really useful information. I’ll acknowledge yinz in the final version of the web page.
Not entirely OT … with September over it’s again time to update the Bitz curve (well, Holland, Bitz and Tremblay if you like).
Recall that this effort was the first to project Arctic sea ice collapse by mid century (by as early as 2040); and also to project that “abrupt reductions are a common feature of (the) 21st century”. That was back in 2006; and the “abrupt reduction” happened in, well, 2007. Surely the most prescient sub-decadal projection in the history of climate science!
Through 2009, this work is still looking damn fine (if a touch conservative):
[The labelled September extents are from NSIDC. Extents through 2006 are Bitz’s, and differ slightly from NSIDC.]
My calculation of the ratio between heating from formation of co2 vs its heating as a greenhousegas.
3e12 ton co2 in atmosphere (wikipedia)
Radforce = 5.35 ln(co2new/co2old)
2x co2: 5,35ln(6/3)=3,7W/m2 including some feedbacks (ipcc)
0,75K/(W/m2) would mean 2,8 deg most people agree on this
One ton extra co2 5.35ln(3e12+1/3e12)=1,783333e-12 W/m2
Earthsurface 510072000km2
1 ton heats 510,072*1,7833333=909,6W/earthsurface (the first year)
Co2 residence time from globalwarmingart, estimation of the surface under the curve just by mesuring with a ruler on the screen
After 50 years 40% co2 is remaining in the atmosphere
Year1=909W year50 0,4*909=363,8W an average of 636,3W during those 50 years
Energy year1 909*365*24*3600=28666MJ
Energy år50 …..=11466MJ
Whole 50 year period 1003310MJ about 1TJ
A nice round number for one ton co2 during 50 years
1l gasoline 2,8kg co2 (i think)
Year1 28,666*2,8=80,300MJ/l
During 50 years 1TJ*0,0028=2810,5MJ/l
1l gasoline energy 35MJ (i think)
gwp gasoline about 2,3 times its heatingvalue the first year
gwp gasoline about 80,3 times its heatingvalue the first 50 years
From the curve in globalwarmingart i estimate just as much heating during the next 150 years so in 200 years 1l gasoline will heat the earth 160 times its heatingvalue.
Not included in this calculation are future emissions that will reduce the effect because of the ln behavior of added co2.
#46 Richard
Ensemble mean forecasts have greatly helped in weather prediction over the years for the reasons that Gavin states. Here is a good link:
http://www.hpc.ncep.noaa.gov/ensembletraining/
#48 BPL,
LOL. I was actually going to email you today or tomorrow to ask you for citations for your excellent list. I want to add your list to my “Climate Models & Accuracy” page.
John Phillips,
One might have trouble with this if one knew absolutely nothing about radiative physics, but then model overfitting would be the least of your problems in understanding climate science.
Fortunately, the modelers DO know the the physics and base their models on it. Since the physics is well understood, that leaves far fewer knobs to twiddle in such a dynamical, physics-based climate model. You might want to start your education by learning the difference between a statistical and a dynamical model.
Recently we have had new measurements of icesheet ice loss and its disappearing faster than projections seems to allow so how does this not affect computer models where ice is being lost faster than projections project.
The icesheets were measured by using lasers from space and hence it does sound quite accurate. James Hansen said that the computer models are usrful tools but its the paleoclimatic data that tells the real story for our future with BAU scenarios.
if the media get the stories wrong or are confused and tell it wrong then what is the significance of that. Copenhagen is going to happen and the USA is close to passing a climate change bill.
Yes, Sidd, (72) that’s exactly what I was figuring.
Judging by the results, Henrik came up with just about the same answer in # 76
Marcus, you had a perfect summary in #69. I’m just looking for a rough ratio for the heat from combustion to heat trapped by the resulting CO2 for the next small unit (ton, kilo, pound) of carbon burned. Decreased values for increasing levels of CO2 need not apply, I’m looking for the right order of magnitude here.
General Perspective on Decadal Predictions
Actually, I’m not sure how important decadal predictions are to agriculture? 1 to 3 years would help though. Generally, I sort of see the refinement going in two directions from 30 years toward less, and from the current weather predictions of 1 to 2 weeks + seasonal predictability based on what is now known of ocean current influences.
It would be great to have better predictability for sure though, especially in the 1 to 3 year range for agriculture and disaster planning.
As decadal was a big topic at WCC-3, I spoke with a few people about the fact that it will take some time to get relevant predictability and that from an adaptation point of view, just plan on the general changes that are becoming more probable. Expecting that will help with current adaptation planning. i.e. more droughts, floods, snowstorms etc. as time rolls on. My point there was don’t wait for the resolution to improve when you already know the general direction of the trends.
My argument runs into problems when you examine quantifiability for insurance, but regional governments can reasonably expect certain things averaged over time.
“if the media get the stories wrong or are confused and tell it wrong then what is the significance of that. Copenhagen is going to happen and the USA is close to passing a climate change bill.”
I don’t think the people in the discussions for the climate bill get their information from the tabloids, pete…
llewelly #70,
thanks for the pointers! Table 10.3 from WG2 was also pertinent, though I’m a bit confused about the dates: “On an average, 20 cyclones cross the Philippines Area of Responsibility with about 8 to 9 landfall each year; with an increase of 4.2 in the frequency of cyclones entering PAR during the period 1990 to 2003 (PAGASA, 2001).”
(Typhoon Ketsana (aka ‘Ondoy’) flooded Metro Manila with a record 45.5 cm rain in 24 hours, leaving more than 250 dead, and now Filipinos are already bracing for Parma (‘Pepeng’), a category 4 typhoon.)
Re BPL list of model predictions:
BPL #74, you’re very welcome. If time permits I’ll look for more.
Brian Dodge #73, your Arrhenius (1896) sure trumps my Manabe (1980).
#75
Bitz update is here.
[Did someone tell us img tags no longer work?]
The misinterpretations and distortions of Mojib Latif’s presentation at WWC-3 in Geneva have really got out of hand, with George Will quoting Revkin misquoting Latif, and Canada’s Lorne Gunter getting it all spectacularly wrong, this time in the Calgary Herald.
Admittedly, I’ve spent too much time on this (going so far as to email back and forth with Latif), but these misinterpretations and distortions of Keenlyside et al 2008 Nature article (on which Latif was co-author) are really upsetting.
“Anatomy of a lie: How Marc Morano and Lorne Gunter spun Mojib Latif’s remarks out of control”
http://deepclimate.org/2009/10/02/anatomy-of-a-lie-how-morano-and-gunter-spun-latif-out-of-contro/
I’ve also transcribed key parts of Latif’s remarks, along with key slides, so that everyone can see just how badly they have been misinterpreted and distorted.
http://deepclimate.org/2009/10/02/key-excerpts-from-mojib-latifs-wcc-presentation/
And I’ve put up my email exchange with Latif as well.
Deep Climate (#86), I have linked to your useful discussion (and this thread) in the comments at the New Scientist story.
I am not sure if September ice extent figures are helpful to this discussion… but here they are:
September (month end averages) NSIDC (sea ice extent)
30 yrs ago
1980 Southern Hemisphere = 19.1 million sq km
1980 Northern Hemisphere = 7.8 million sq km
Total = 26.9 million sq km
Recorded Arctic min yr.
2007 Southern Hemisphere = 19.2 million sq km
2007 Northern Hemisphere = 4.3 million sq km
Total = 23.5 million sq km
Last yr.
2008 Southern Hemisphere = 18.5 million sq km
2008 Northern Hemisphere = 4.7 million sq km
Total = 23.2 million sq km
This yr.
2009 Southern Hemisphere = 19.1 million sq km
2009 Northern Hemisphere = 5.4 million sq km
Total = 24.5 million sq km
On September 12, 2009 Arctic sea ice extent dropped to 5.10 million square kilometers (1.97 million square miles).
Source plates:
ftp://sidads.colorado.edu//DATASETS/NOAA/G02135/Sep/N_200909_extn.png
ftp://sidads.colorado.edu//DATASETS/NOAA/G02135/Sep/S_200909_extn.png
ftp://sidads.colorado.edu//DATASETS/NOAA/G02135/Sep/N_200809_extn.png
ftp://sidads.colorado.edu//DATASETS/NOAA/G02135/Sep/S_200809_extn.png
ftp://sidads.colorado.edu//DATASETS/NOAA/G02135/Sep/N_200709_extn.png
ftp://sidads.colorado.edu//DATASETS/NOAA/G02135/Sep/S_200709_extn.png
ftp://sidads.colorado.edu//DATASETS/NOAA/G02135/Sep/N_198009_extn.png
ftp://sidads.colorado.edu//DATASETS/NOAA/G02135/Sep/S_198009_extn.png
http://climateinteractive.org/state-of-the-global-deal
Another full text article found on an author’s page:
http://sciences.blogs.liberation.fr/files/climat-2009-2019-2.pdf.
How will Earth’s surface temperature change in future decades?
GEOPHYSICAL RESEARCH LETTERS, VOL. 36, L15708, doi:10.1029/2009GL038932, 2009
No comment on http://www.washingtonpost.com/wp-dyn/content/article/2009/09/24/AR2009092402602.html
Re: Hank’s #30 and Ed’s #42 — I had the same question as Hank, and I wonder if the results would differ at all if only runs that captured the historical patterns were used to predict the future (rather than constraining all runs to match the past). Am I understanding this correctly?
The 9/24 WaPo article Larry points to in his posting of Oct 4 refers to the same Ventana/Sustainability/MIT model I mentioned 10/2 above — there’s a laptop version apparently widely in use by the delegates who will be going to Copenhagen.
I’m hoping someone who actually has, or was involved in creating, the laptop version will show up to talk about it. The website version is a very simple demo of the interface, near as I can tell, but it appears the people using it aren’t bloggers.
Re: #92 – Steve L,
Is a good question. In the Hawkins & Sutton study there is a weak weighting applied to the models so that the models which performed better in predicting recent global trends were given a (slightly) higher weight. In fact, it made little difference to the overall results.
However, how to best constrain predictions using how well models do at reconstructing past climate using more complex methods is a very active current area of research. There are immediately issues about what observations you use, i.e. just global averages, regional patterns, rainfall, temperature, sea level pressure, variability or mean state etc etc, and each model has strengths and weaknesses, so what do you prioritise? A google search on ‘climate model metrics’ brings up a host of articles and webpages on these kinds of issues.
And, this is also an aspect of climate research which the planned decadal predictions will be invaluable for. We will be able to test the climate models in real forecasts for the first time and see which ones work well (and not so well), and perhaps more importantly, why they work well/not so well. With a bit of luck, we might then even be able to improve them!
Ed.
The text says “uncertainty associated with uncertain or inaccurate models grows with time”, but the graphs show “fractional uncertainty” for models going down with time. Seems like a contradiction, but what does “fractional uncertainty” mean?
Re #95 – Tom Adams,
It is a slightly confusing graph. Try reading comment #1, and Gavin’s reply, and the graph linked to in comment #3. Or the paper itself, which is linked in the article and freely available.
Ah, good od G Karst with his continuous and eternal cut n paste.
Stll insisting that including the winter maximum in a list of summer minima is worthwhile. And STILL insisting that the sea ice extent tells you much about the total sea ice volume.
What a [edit]
Temperature is rising and polar bears are drowning earth is turning to A WATER WORLD!fUTURE GENERATIONS WILL NOT SURVIVE ITS UP TO US NOW TO MAKE A CHANGE!
Jean Michael, I’m just one of the readers here, not a scientist, but since you post your website behind your name, my opinion:
After taking a look — seems to me you need to work on your own understanding of the science first before setting up as a teacher. Ask someone for help with your website description of global warming. It’s too simple and has some basic ideas very unclear.
Jean Michael #98: I’m sure you mean well, but please… listen to Hank.