We’ve been a little preoccupied recently, but there are some recent developments in the field of do-it-yourself climate science that are worth noting.
 First off, the NOAA/BAMS “State of the Climate 2009” report arrived in mailboxes this week (it has been available online since July though). Each year this gets better and more useful for people tracking what is going on. And this year they have created a data portal for all the data appearing in the graphs, including a lot of data previously unavailable online. Well worth a visit.
First off, the NOAA/BAMS “State of the Climate 2009” report arrived in mailboxes this week (it has been available online since July though). Each year this gets better and more useful for people tracking what is going on. And this year they have created a data portal for all the data appearing in the graphs, including a lot of data previously unavailable online. Well worth a visit.
Second, many of you will be aware that the UK Met Office is embarking on a bottom-up renovation of the surface temperature data sets including daily data and more extensive sources than have previously been available. Their website is surfacetemperatures.org, and they are canvassing input from the public until Sept 1 on their brand new blog. In related news, Ron Broberg has made a great deal of progress on a project to use the much more extensive daily weather report data into a useful climate record. Something that the pros have been meaning to do for a while….
Third, we are a little late to the latest hockey stick party, but sometimes taking your time makes sense. Most of the reaction to the new McShane and Wyner paper so far has been more a demonstration of wishful thinking, rather than any careful examination of the paper or results (with some notable exceptions). Much of the technical discussion has not been very well informed for instance. However, the paper commendably comes with extensive supplementary info and code for all the figures and analysis (it’s not the final version though, so caveat lector). Most of it is in R which, while not the easiest to read language ever devised by mankind, is quite easy to run and mess around with (download it here).
The M&W paper introduces a number of new methods to do reconstructions and assess uncertainties, that haven’t previously been used in the climate literature. That’s not a bad thing of course, but it remains to be seen whether they are an improvement – and those tests have yet to be done. One set of their reconstructions uses the ‘Lasso’ algorithm, while the other reconstruction methods use variations on a principal component (PC) decomposition and simple ordinary least squares (OLS) regressions among the PCs (varying the number of PCs retained in the proxies or the target temperatures). The Lasso method is used a lot in the first part of the paper, but their fig. 14 doesn’t show clearly the actual Lasso reconstructions (though they are included in the background grey lines). So, as an example of the easy things one can look at, here is what the Lasso reconstructions actually gave:

‘Lasso’ methods in red and green over the same grey line background (using the 1000 AD network).
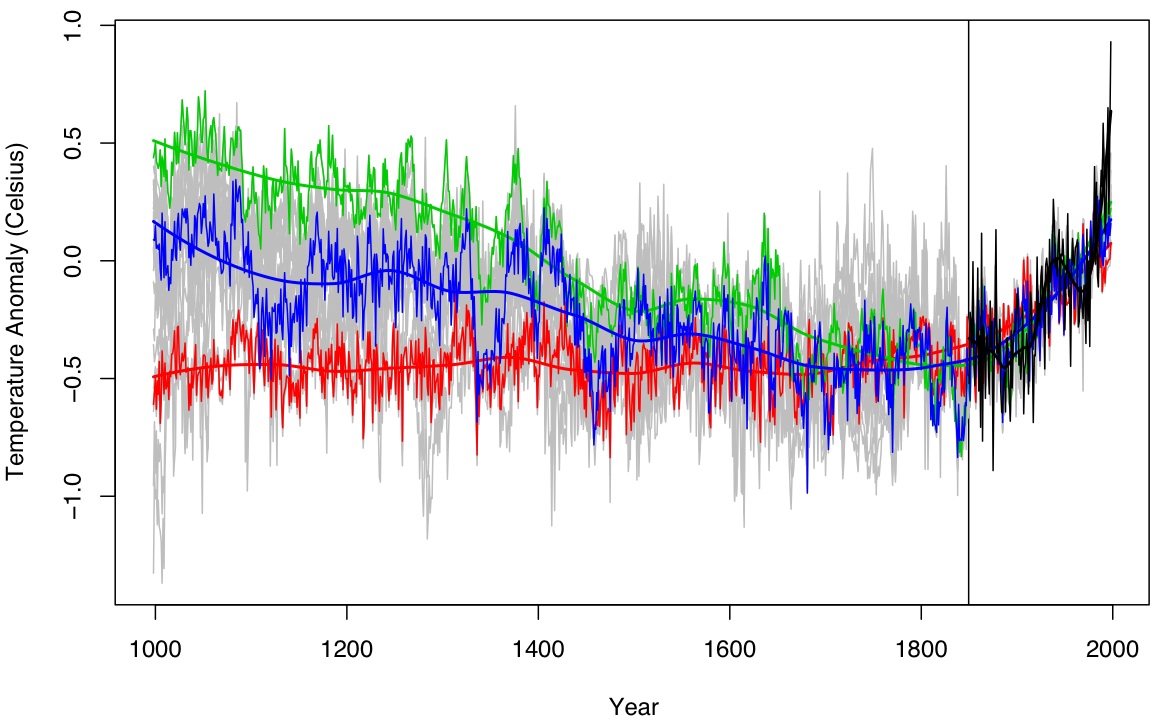{kind=link}
It’s also easy to test a few sensitivities. People seem inordinately fond of obsessing over the Tiljander proxies (a set of four lake sediment records from Finland that have indications of non-climatic disturbances in recent centuries – two of which are used in M&W). So what happens if you leave them out?
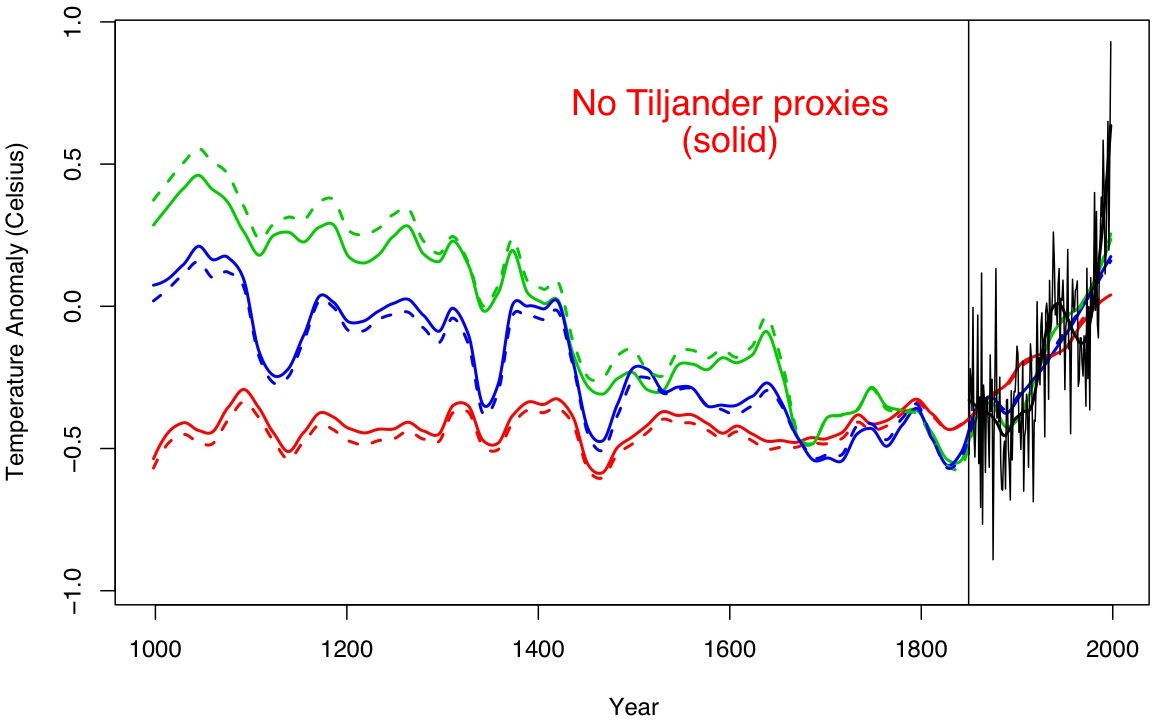
No Tiljander (solid), original (dashed), loess smooth for clarity, for the three highlighted ‘OLS’ curves in the original figure).
… not much, but it’s curious that for the green curves (which show the OLS 10PC method used later in the Bayesian analysis) the reconstructed medieval period gets colder!
There’s lots more that can be done here (and almost certainly will be) though it will take a little time. In the meantime, consider the irony of the critics embracing a paper that contains the line “our model gives a 80% chance that [the last decade] was the warmest in the past thousand years”….
Watts, true to form, left the 80% business out of his selected quotes, so I served notice of the omission to WUWT’s long suffering readers last week.
Too bad the proxies remain as underwhelming as the funding available for augmenting them.
Gavin, that was clear, thanks. No, nothing McKitrick’s been up to make me think that he’s driven by a wish to get it right. But the journal and its readers might want to, so hopefully someone will take you up on the tip how to correct him.
Anders M #14: upon further consideration I don’t think this idea is valid as I described it there. I was too quick. I now rather tend to think that it also has to do with their choice of the number (10) of PCs to include.
There is some discussion of this at DeepClimate.
I think that “Statistics, Politics and Policy” is the Journal that Wegman started up recently. If this is the case, I’m not sure the journal is interested in getting it right.
Um.
“… the current level of inaccuracy in our understanding of these processes is insufficient to invalidate the basics of AGW …”
Help needed with that somehow.
54 (Hank Roberts),
Come on, you can’t not misunderstand what wasn’t unsaid, nor doubly and negatively implied, by the reverse of the opposite of that contrariwise statement.
[Response: :)]
Hank, I’m not entirely sure but that might have something to do with the flux capacitor, not being properly aligned with the quantum wave generator?
Sorry, I’m not sure. Maybe, someone else has a clue?
suyts,
They calculate Bayesian probabilities in their model which enable them to construct probabilistic interpretation of their results. I think the main reason they present the 80% result was to illustrate this feature in their model. They also calculate this result:
They then “emphatically” minimize the significance of this particular result because the model could not capture the recent upswing in temp. Therefore, they argue, that the 80% result (which goes over the whole reconstruction) may be a bit too high a result because it won’t detect the MWP (kinda fluffy logic).
So there are two results: 80% and the 0%. The latter of which they think is unrealistic, and the former they think is a tad charitable… At least that’s my interpretation.
Also, I don’t think articulating uncertainties (what essentially M&W2010 are doing) is a “worthless result” — that’s basically a statistician’s job. But I would have liked to see some more forward-thinking in producing models with a greater signal instead of just giving a warning. Of course that would require collaboration with physicists!
Bill Hunter
Plant physiologists aren’t as naive or ignorant as you assume. There’s a reason why tree proxies for paleoclimatology are chosen from regions near a species’ altitudinal or latitudinal range limit, where precipitation is KNOWN TO BE MORE THAN ADEQUATE to support healthy growth.
57 apeescape says:
Thank you for better articulating what I’ve been trying to state. The 80% quote has to taken in context of their statements.
Thanks, Rattus, and everyone who offered help. I appreciate it.
Edward (17):
R is an extremely powerful tool–I would definitely install it and begin to play around with it (if you have time). You can learn a lot that way, and it comes with a set of manuals, one of which is an introduction to R. If you’re doing basic stuff it’s not so bad. Problems arise when you try to program something complex without sufficient background in the various exceptions and ins and outs of the language. Frankly, R exacerbates this issue with some vagaries that will absolutely make you tear your hair out and which make no obvious sense (I can give numerous examples from recent experience). Because the help menus are generally poor/cryptic, you almost have to buy at least one or two books. I highly recommend Joseph Adler’s “R in a Nutshell”–very helpful, a very good blend of statistics and programming how to.
The USGS offers an online course yearly, starting soon and I believe they archive past years’ sessions. It’s geared more toward standard statistical analysis using existing R packages, not programming. There are others too. I think the best way though is to experiment on your own, with a good book.
http://www.fort.usgs.gov/brdscience/LearnR.htm
http://www.stats.ox.ac.uk/~ruth/RCourse/
On my blog I am trying to describe the the climate change debate in Russia as it relates to the wildfires.
http://legendofpineridge.blogspot.com/2010/08/ria-novosti-explores-possible-causes-of.html
I just have a question.
An RIA Novosti article quotes a prominent Russian scientist, Roman Vilfand, the head of the Russian state meteorological center. This may be the agency known in Russia as the Federal Service for Hydrometeorology and Environmental Monitoring or ROSHYDROMET (“Росгидромет”) or it may be a different agency. Dr. Vilfand is described by RIA Novosti (8-13-10) as “the head of the Russian state meteorological center” and by Business News (8-16-10)as “previously the head of Russia for Hydrometeorology.”
Snapple have you read the NOAA report about the Russian heatwave?
http://www.esrl.noaa.gov/psd/csi/moscow2010/
Dear Warmcast,
I had not read this authoritative report and will link it on my post. They say the heatwave was due to blocking as do the articles I cited. Thanks
Regarding http://www.esrl.noaa.gov/psd/csi/moscow2010/
“The current heat wave is therefore all the more remarkable coming on the heals of such extreme cold.”
I think the author meant “heels”….
Stuff like that drives me buggy!! How can I take the study & data seriously with such stupid mistakes?
With respect to BPL’s frustration starting with R, and others:
For those new to \R\, its power is in the vast array of 3rd party packages – libraries, if you like. R itself is a fairly small language, one which provides real/complex numerics, vector, matrix, array and list entities, more statistically oriented data frames, and a fair bit more. The real meat is in the packages provided at the CRAN site (Comprehensive R Archive Network); at last count there are 2473 packages available, covering every contingency I should expect.
Tutorial and primer style documents, provided by third parties and also some of the R team, may be found here. Plenty to look at and work through – for a solid coverage of not just R, but also a suitable Windows editor that can work with R (ie hooks up with R to run your edited scripts etc), and quite a few environment handling issues not well covered elsewhere, check out Petra Kuhnnert and Bill Venables notes here.
62 Jim Bouldin: Thanks
Bob (Sphaerica)@56
Yeah, yeah.
#63 Snapple
I have a summary report that addresses recent events including work from Jim Hansen, the NOAA/ESRL report, NCDC, the OMM/WMO (World Meteorological Organization) and some news highlights
http://www.ossfoundation.us/projects/environment/global-warming/summary-docs/leading-edge/2010/aug-the-leading-edge
I continue to update the page as the month progresses though.
—
Fee & Dividend: Our best chance – Learn the Issue – Sign the Petition
A Climate Minute: The Natural Cycle – The Greenhouse Effect – History of Climate Science – Arctic Ice Melt
A bit OT but meanwhile in Virginia…
http://www.newsplex.com/vastatenews/headlines/101155564.html
Isn’t it time from someone in climate science community to do something like this?
http://rationalwiki.org/wiki/Lenski_affair
The actual correspondence is posted at the rationalwiki.org link I provided, I believe they are a must read and could serve as a template for anyone in the science based community who has to deal with attacks against their own integrity and honesty regardless of their area of expertise.
Nice to see you guys bringing this up for comment.
I read the paper, and will commend the authors on writing the paper so it can be easily understood. Many academic papers are indecipherable when they don’t need to be. The target audience is typically other academics though.
The central point of the paper is that the proxies are simply not good enough to make any reasonable conclusions from. Anybody can confirm this intuitively by examining the graphs of the individual proxies, they are a mess.
I thought they made a good point on how the confidence of the reconstruction was over estimated due to the method for verification. Using start and end blocks allowed the verification to know the starting and ending points and it filled in the rest. This ave it an “unfair” advantage in reconstruction ability. When only giving a starting point, it faired worse.
The use of a smarter null model, one that tracks local temperatures, but has no long term trending skill, was also enlightening. This null model performed as well as the constructed model, which indicates backcast skill of the constructed model was questionable.
Probably the most important point which is glossed over in most reviews is that different models that have almost identical verification scores have wildly different backcasts. Who’s to say which model is really best?
[Response: Read the paper more carefully. They only tested ‘lasso’ for verification scores, not any of the other models, and not any model that other groups have used. You can test which methods work best, but they did not do these tests. One must be careful therefore not to over-interpret. – gavin]
Arguing over the minutia of the statistics isn’t very useful, trees just aren’t very good thermometers.
[Response: Tell us another one. Better yet, explain why the rings of the trees in a stand very often go in the same direction wrt ring width, from year to year, far beyond what could be explained by chance. When you’re done with that, we’ll start into the experimental forestry and tree physiology literature–Jim]
I think climate science would be wise to not engage in a math war against the professional statisticians in this case.
[Response: …or some statisticians (and posters) who might bother to consider biological reality before getting lost in numbers.–Jim]
It’s not really very relevant when the main concern is where the climate is going, not where it has been.
#66 Cstack
You apparently can’t take it seriously because your are too busy looking at the molehill to see the mountain.
It is a serious problem in some peoples brains though. i suppose if you found a comma out of place in a version of Mark Twains Huckleberry Finn, you would conclude that Twains work is not that good because some editor missed that comma.
—
Fee & Dividend: Our best chance – Learn the Issue – Sign the Petition
A Climate Minute: The Natural Cycle – The Greenhouse Effect – History of Climate Science – Arctic Ice Melt
Second estimate: 2051 is the year the fraction of Earth’s land surface in severe drought hits 70%, and global human agriculture collapses. My previous estimate was 2037, so we’re a little better off.
I’ve written up the statistical analysis as an article. I’ve asked Tamino to check the statistical work; waiting for his reply. Would any pro climatologists be willing to look at the article before I submit it? I desperately want this to pass peer review.
And if I’m right, the word has to get out. Soon. Please help.
“[Response: Read the paper more carefully. They only tested ‘lasso’ for verification scores, not any of the other models, and not any model that other groups have used. You can test which methods work best, but they did not do these tests. One must be careful therefore not to over-interpret. – gavin]”
This is true. But it does look like they did test verification scores for different models in Fig 9, in which the lasso scored similarly to the PC and other methods. They did not show the reconstructions of all the methods.
I just take from it that there are some statistical methods which generate a hockey stick, and there are some methods that don’t generate a hockey stick, and the methods are roughly equal from a purely statistical point of view.
It may be that climate science has some proprietary “secret sauce” that shows the hockey stick method clearly superior (proxy selection, etc.), I’m just not convinced of that. Of course I am equally subject to confirmation bias as everyone else.
[Response: There are ways to test whether methods work by using synthetic data derived from long model runs. These are obviously less complex or noisy than the real world, but if a method doesn’t work for that, it is unlikely to do so in the real world. As I said, these tests were not done in M&W. – gavin]
Tom Scharf says: “I thought they made a good point on how the confidence of the reconstruction was over estimated due to the method for verification. Using start and end blocks allowed the verification to know the starting and ending points and it filled in the rest. This ave it an “unfair” advantage in reconstruction ability. When only giving a starting point, it faired worse.”
I’m not sure I understand this. To me it looks like it is their method (M&W's) that consists in giving the model the starting bit and the ending bit, and see how well it does at guessing the (small) bit in the middle.
By contrast, I was under the impression (perhaps misguided) that usual validation methods in climate science involve giving one end of the data to the model, and see how well it matches the (unseen) other end, without "showing" it the other end point.
Did I get it hopefully wrong?
I’ll be the first to admit my knowledge of statistics is minimal (OK almost 0), but my knowledge of logic and my knowledge of programming give me a few insights.
So when I read:
“Second,
the blue curve closely matches the red curve from 1850 AD to 1998 AD because
it has been calibrated to the instrumental period which has served as
training data”
Now logic, to me anyway, states that you must be able to match the proxies to the instrument record. Otherwise you don’t have the slightest clue what the proxies actually represent.
So do they, or don’t they?
And if they do, why does this paper attempt dismiss that correlation? Seeing as it’s vital to the whole excercise.
Then secondly the paper gets a firm thumbs down by me the second that it tries to predict future change by extending a hindcast forward into the future.
My logic says that if we can determine the impact on the proxies by climate we can reconstruct the past climate from the proxies (within the limits of known error). However unless we know significantly more about climate triggers and include them into the statistical model; we cannot predict anything in the future because we must know much, much more about the changes in clmiate change triggers (CO2, methane, solar cycle etc), in order to be able to do so.
As soon as it does that, to my logic, their credibility goes down the pan.
But then I’m neither a statistician nor a climate sicentist…..
But their spectacular failure to predict any future change, imho, does not mean the data is rubbish. It means the climate is different to any in the last 1,000 years.
Or did I miss something?
Here is Wegmans DIY review of his new DIY statistics journal- I am deeply (at least three sigma) shocked that it accepts submissions by invitation only
WIREs is a WINNER
0. Edward J. Wegman1,*, Yasmin H. Said David W. Scott
Ahttp://onlinelibrary.wiley.com/doi/10.1002/wics.85/fullbstract
“A group of us met with the editorial management of John Wiley and Sons… our new journal was launched officially in July-August 2009 titled as Wiley Interdisciplinary Reviews: Computational Statistics. … a hybrid review publication that is by invitation only, “
the success of PR focus rroups , left and right, in powering up new vanity presses to dumb down climate science call what Auden wrote of the power of comic rhyme .“instead of an event requiring words to describe it, words had the power to create an event”. Pop science becomes self parody when words take over and leave sense behind.
Tom Scharf #75
Surely you mean Figure 12? I don’t agree — the two Lasso versions score clearly poorer than even ten PCs, which arguably isn’t the even best among the OLS solutions. And this presupposes that the way the authors do cross-validation is proper and relevant for testing the suitability of a reconstruction technique for what it is actually used for. As Gavin says, there are more definitive ways of doing that, and they weren’t used. And plotting the spread of the reconstructions by a couple dozen not-quite-optimal (by a questionable metric) alternative techniques, and referring to that as the uncertainty of reconstruction, is surprisingly fuzzy thinking for statisticians.
BTW don’t trust your intuition too much. Only scientifically trained intuition works… sometimes :-)
re: #78 Russell Seitz
Oh, that is not the only strange thing about that journal.
See its Editorial Board, which claims (noticed by Deep Climate a while back):
“Edward J. Wegman, Bernard J. Dunn Professor of Data Sciences and Applied Statistics, George Mason University
Yasmin H. Said, Professor, Oklahoma State University, Ruth L. Kirschstein National Fellow, George Mason University this is very strange.
David W. Scott, Noah Harding Professor of Statistics, Rice University”
<a href="http://www.okstate.edu/registrar/Catalogs/E-Catalog/2009-2010/Faculty.html" OSU catalog,
and the associated PDF, created 08/05/09 both list Yasmin H. Said as an Assistant Professor in Statistics, still there 08/12/10, but not at
<a href="http://statistics.okstate.edu/people/faculty.htmOSU statistics department
=======
A. In any case, back to the original topic. There is a fascinating chain of connections that may illuminate the provenance of this strange paper published by statisticians with no obvious prior experience in this turf. This chain includes:
McShane (now in Marketing @ Northwestern), Wyner Wharton statistics … which references a paper by:
J. Scott Armstrong, Wharton Marketing … in same building
A regular speaker @ Heartland conferences and founder/cofounder of Intl. J. of Forecasting, of whom one of the Assoc Editors is:
Bruce McCullough, Drexel (~ 1 mile away)
http://www.pages.drexel.edu/~bdm25/
“Associate Editor, International Journal of Forecasting (1999 – now)
and he is also:
Associate Editor, Computational Statistics and Data Analysis (2003 – now)
of which WEGMAN has been advisor and frequent author since 1986.
But that leads back to an odd sequence around the Wegman Report:
Anderson, Richard G., Greene, William H., McCullough, Bruce D., and Vinod, H. D. (2005) “The role of data and program code archives in the future of economic research,” Federal Reserve Bank of St. Louis, Working Paper 2005-014B.
http://research.stlouisfed.org/wp/2005/2005-014.pdf
http://climateaudit.org/2005/04/22/anderson-et-al-2005-on-replication
The paper is about economics, with the *lead author* at the St. Louis Federal Reserve (i.e., tax funds are paying for this), and a strange footnote that whacks MBH and praises MM, with 6 citations about paleo, and the bibliography includes an uncited reference to a “mimeo” from McKitrick.
After this was published, McIntyre referenced it.
I.e., this is “meme-laundering”: McK gives this to one of the authors, most likely McCullough. Now it’s in a more credible place.
Then, the WR cites that, a second wash. Then:
2008
Richard Anderson, William H. Greene, B. D. MCCULLOUGH and H. D. Vinod “The Role of Data/Code Archives in the Future of Economic Research”
Journal of Economic Methodology 15(1), 99-119, 2008 http://www.pages.drexel.edu/~bdm25/agmv.pdf
This includes all 7 paleoclimate references, including the mimeo.!
This looks like the third wash cycle, finally in a peer-reviewed journal, presumably.
2009
B. D. MCCULLOUGH and Ross R. MCKITRICK
Check the Numbers: The Case for Due Diligence in Policy Formation The Fraser Institute, February http://www.pages.drexel.edu/~bdm25/DueDiligence.pdf
This includes a cornucopia of climate anti-science references, via thinktank Fraser [MAS2010].
The mimeo reference finally disappeared.
I haven’t yet untangled all the relationships through the journals …
but the way I’d put it is that there is a TINY handful of {economists, marketing folks, and statisticians) who:
a) Often start DIY journals of one sort or another
b) Have strong dedication to obscuring inconvenient climate science, often publishing such in places unlikely to face credible peer review.
Of course, then Wegman and Said organized 2 sessions at Interface 2010 (statistics conference), inviting Fred Singer, Jeff Kueter (GMI) and Don “imminent global cooling.” Said comments strongly on awful behavior of climate scientists.
Re: #43 Rattus Norveigicus
The book title is “El Nino in History: Storming through the Ages” by
César N. Caviedes. Gainesville : University Press of Florida, c2001
ISBN 0813020999; LC catalog # C296.8 .E4 C39 2001X
http://www.amazon.com/El-Nino-History-Storming-Through/dp/0813020999/ref=sr_1_5?ie=UTF8&s=books&qid=1282592961&sr=8-5
This sounds interesting – first I’d heard of it. Caveides works in historical geography at UFL. The Amazon.com writeup mentions another “magesterial” work in this genre:
Late Victorian Holocausts: El Niño Famines and the Making of the Third World by Mike Davis, 2002. ISBN 978-1859843826
http://www.amazon.com/Late-Victorian-Holocausts-Famines-Making/dp/1859843824/ref=sr_1_1?s=books&ie=UTF8&qid=1282593147&sr=1-1
The latter author is described in one review as Marxist; in any event it’s clear this book is sharply critical of European colonialism, attributing massive famines to its influence (set in a context of El-Nino-driven shifts in regional climate).
Homer-Dixon on the need to prepare for possible climate shocks: http://nyti.ms/HDshoc
The Caviedes book is quite good. I’ve had it in my library for several years and it provides quite a bit of interesting information including such gems as historical shipwreck counts in areas prone to El Nino storminess. Really interesting stuff.
Why highlight such garbage as that statistical analysis paper? They fail the basic mechanistic test, that of applicability of their datasets to the questions they ask.
For example, consider regional reconstructions of temperature based on lake sediment analysis in areas that were once covered by glaciers. Who doubts that periods of glaciation and persistent ice cover could be distinguished from periods of biological productivity and high rainfall, or periods of drought?
So, if you look specifically at lake sediment profiles across a wide range, and correlate them to one another, you can start to understand how the deglaciation since the last glacial maximum progressed.
Trying to shoehorn all the proxies into one dataset and then make claims about a single variable, the “global average surface temperature” is nonsensical.
Each type of proxy has different rules and tells you different things, some very qualitative, some very quantitative. You can’t lump them all together in this manner – well, you can, using a statistical formula, but that’s just gibberish masquerading as science.
That argument applies to the initial hockey stick graph, too – a more convincing argument might be a video reconstruction of global ice extent over the last 50,000 years. However, if you used that ice extent in an effort to get temperature estimates, resulting in a “hockey stick” graph, you’d be attacked by statisticians out to respin the numbers.
What the statistician will not do, however, is attempt to question the global ice coverage map c. 5000 ya, for example – that’s far too specific for a general smear effort.
Do it yourself reply to http://dotearth.blogs.nytimes.com/2010/08/23/study-finds-no-link-tying-disaster-losses-to-human-driven-warming/
“Study Finds No Link Tying Disaster Losses to Human-Driven Warming”
AMERICAN METEOROLOGICAL SOCIETY
Laurens M. Bouwer
I think RealClimate debunked this kind of thing some time ago. RealClimate search gives me too many articles. I don’t see the right one, do you? Dotearth needs some expert commenting.
suyts #47, apeescape #58, I read it a bit differently. Their remark
to me very much reads “the proxies are worthless”.
What is worse is that the above implication is just factually wrong. This “loss of sensitivity” meme is widespread, but consider that, even over the late 20th C divergence period, the response of (specifically) tree rings to year-to-year temperature variations remains full strength, without any “divergence”… loss of sensitivity just cannot explain this.
The above remark would never have made it past domain-savvy reviewers. There is an extended history to this subject, see, e.g.,
http://www.cce-review.org/evidence/Climatic_Research_Unit.pdf
that M&W seem blissfully unaware of.
Of course it is unsatisfactory that we don’t know the real reason for the divergence phenomenon, although progress has been made. But in research like this you do the best you can, based on the knowledge you have, noting the caveats. The quoted remark is much more than a caveat, and IMHO (as also a non-expert, but somewhat familiar with backgrounds) inappropriate.
Ike Solem: “Each type of proxy has different rules and tells you different things, some very qualitative, some very quantitative. You can’t lump them all together in this manner – well, you can, using a statistical formula, but that’s just gibberish masquerading as science.”
Well you can, actually, but it’s harder than it looks to these authors. You gave part of the reason in your post – that these many proxies really bear witness to lots of things, and the model was fit in a way which didn’t adequately reduce the scope of the sort of explanation which was sought – just the biggest explanation.
What makes things a little worse is that knowing how the proxies relate to lots of things seems to make you think that they should be sorted out intelligently. This makes sense if there is so much information that you are really only using light duty statistics. When you are up against really difficult problems with high dimensionality and noise, then the “meaning” of the various sources of information falls by the wayside, and what matters most is how all the data can be “holographically” combined to maximize the flow of information from all the observations to the inference being attempted.
This may sound a little like hand waving, but we can give the classic example from meteorology – if you have two bad thermometers in a sealed room with a fan and you want to know the history of the room temperature from the sequences of thermometer readings, one strategy is to decide which thermometer was the good one and ignore the other. Another strategy is to average the two thermometers. Depending on how accurate the two thermometers are, either one of these strategies could be better than the other. But if you do the simple calculus problem based on mean square error, you find that the optimal combination of the two thermometers is their average weighted by their “accuracies” (inverse variances). So if the two thermometers are equally accurate, the simple mean of the two is best. However, (and this is my point), it is NEVER the best combination to ignore one of the two thermometers unless it has unbounded variance. That is not really that likely.
Now if the fan doesn’t mix the air too well, you have to take into account the cross-correlation of the errors, but this is easy enough.
Now one can also take into account that one might not really care about the overall mean temperature of the room, one might care about how long it will take paint to dry on the walls, which is a somewhat different question. One might find that for this purpose, a different combination of the thermometers is best than the best combination for the overall average. And if one wanted to know whether the paint was drying uniformly, then yet another combination might be best.
This argument extends both to multiple thermometers, or multiple weather stations with multiple quantities measured, etc. If one follows along this trail a bit, one arrives in the well undertood field of “Data Assimilation”.
So far, we have thought about Mean Squared Error, and how to minimize it. This will end up providing us with unbiased estimators.
But we probably know by now that unbiased estimators are not “all that” and we might consider that there are reasons to prefer biased estimators – robustness for one, and better accuracy in the high noise regime. When we go there, other combinations come into play – not always linear.
And then there is the situation where we can combine additional data – say one of the thermometers is part of a thermometer-barometer instrument and we get pressure readings. We might assume that the ideal gas law would tell us how to connect pressure and temperature, leading to a likely nonlinear combination of the pressure and temperature readings. It would be entirely possible that the noise in the thermometer signals would not be that much like the noise in the barometer signal, depending on how frequently the instruments were sampled. If the sampling frequency is high enough, then the different response times of the various instruments introduce dynamic correlations (e.g. lagged covariances, etc.).
Even so, you can dump just about any such concoction of instruments, physics, and “questions to be answered” into something called an Extended Kalman Filter. This has been around for a long time, and indeed people use it for Data Assimilation, and it works pretty well as long as you have enough data and are willing to slosh a little structured linear algebra around.
OK so what comes out of this relatively simple starting point are some reasonable principles for modeling noisy data:
1. It’s rarely a good idea to forgo the use of any data, no matter how unlikely it may seem.
2. The way to combine data series depends strongly on the question which is being asked – so even if you have the same data, asking different questions can lead to much different ways in which the data are combined.
3. When you have plenty of data, this is a fairly well understood problem with a good old solution.
What’s not to like here?
Well it’s that “have enough data” thing. There is a vast variation in the quantity, quality, and “physics” of the various proxy series. To get what we want from it, we are pretty much up against it for getting lots more data.
In and of itself, that is not the biggest problem in the world since the statistical methods being used in this part of the climate science world were kind of improvised, sort of old school. It’s pretty clear that one should be able to get a lot of mileage out of higher bias estimators. I’ve said it here for years. So I really don’t blame McShane and Whyner for breaking open the wrapper on this sort of attack. However, the Lasso is not exactly the first tool I would reach for (precisely for the same reason M&W chose it, oddly enough). When I was reading their paper, this was when I thought the wheels might not stay on the cart for the whole road. There are lots and lots of ways to gain efficiency of estimation, and sparsity is a brutal choice which introduces extreme dependence on arbitrary coordinate choice, an effect which increases with dimension. Essentially, the Lasso works if your high dimensional problem is really a low dimensional problem, except that someone just stuck in a lot of useless extra data series and you don’t know which ones those are. It is very common in social sciences, public health, and economics, where data sets are frequently a pile of questionnaires that someone originally wrote a long time ago that have been unchanged (to keep them fixed) even though the people filling them out have changed a lot. Or business surveys were the economists really didn’t know what predicts inflation so they covered as many things as were easy to ask for. So you get handed this giant heap of data series, and many of them are irrelevant, but it is hard for a human to sort out. The Lasso (and his friends the Garotte, etc.) can chop off uninformative data series very well indeed.
But the Lasso is not so good if you are trying to sieve out information which is common to the many different series, but which in each one is obscured by different noise distributions. As we saw above, it’s rarely the best idea to completely ignore the worst thermometer when the better thermometers are still bad. Even after transforming to a different coordinate system, throwing out components only works if there is such a thing as an “efficient basis” – in other words if after changing coordinates, most of the coordinates are useless. Useless for what?
This is where we bring in the dependence on the “question being answered”. Because the Fourier transform is unitary (of if you don’t speak math, because I said so – ) mean square error gives equal weight to prediction skill at every frequency. Now the best combination of the data for that chore is not going to be the same as the best combination for predicting on some small frequency range – such as only the low frequencies. However if you don’t filter out prediction of high frequencies, then the lasso will keep combinations of data according to how well they predict temperature on ALL frequencies, and most of that temperature variation is not climate.
You can very likely expose this behavior of their method by randomly choosing a combination of several of the proxy series, then passing that through a narrowband filter, adding the complementary frequencies of the true target, and seeing how that gets modeled by Lasso based technique of M&W. The Lasso will very likely zero out some of the component series that make up this target, even though that component is preset in the target. Well, yes, but it’s only present in a narrow band. This would not be the first time a high bias estimator couldn’t see one particular tree due to the surrounding forest.
OK so at this point, I think I have explained that yes, you DO want to toss all the data into a big pot and apply good statistics, and with enough data, that’s been a done deal for a long time. But to cope with the problem at hand, there is not enough data, so one has to use a better statistical method.
And M&W are not crazy to pick a high bias superefficient estimator, that’s really the only game in town. I am encouraged that people are going in that general direction.
However M&W have made an unfortunate choice of method, which says more about what field they come from, and their lack of experience with some aspects of high dimensional superefficient estimation than anything else. (Yes I’ve seen other people mention their lack of climate science, but that’s not as big a problem.) The mistake of aiming at a sparse model is not confined to climate science problems – similar disasters await them in some aspects of finance. Had they gotten their ducks in a row statistically, I don’t think they would have been fooled by the lack of interpretability resulting from their model, nor would their predictions have been so awful.
That being said, what would have been better? I haven’t thought too deeply about it, but obviously, to the extent that one can HONESTLY filter out extraneous components from the model target, one will get a better result. This will require care, but it doesn’t seem Herculean when so many times we see people using what amounts to a five year Nyquist rate.
Then one should avoid using hard thresholding, or things that amount to it (like the L1-penalty in the Lasso, etc.). Yes, lots of econometricians “like” that, because they “like” to believe that the world really is simple if only you look at it the right way. One must use superefficient methods, but one must respect that high dimensional signals can go in a lot of directions. Happily it’s not too hard to come across superefficient methods that suit – e.g. Rudolf Beran’s “REACT”, etc.
I think its time to stop quibbling over past research and focus on the important question: How do glean reliable paleo-temperature data from the various temperature proxies, (given their known drawbacks)? We must develop a method agreeable to researchers on both sides of the debate, and go from there. Any suggestions?
IMO, “researchers on both sides of the debate” is an erroneous presumption.
“The debate” doesn’t define “research”–rather the reverse. Debaters quibble. Researchers don’t (or at least, shouldn’t.) Researchers evaluate evidence as objectively as possible (or should) and modify, discard or develop their theories accordingly.
So my suggestion, in short, is that if “we” stick to substance, are guided by evidence as it develops, and generally allow the scientific process to work, “we” won’t constantly be “quibbling over past research.” In fact, we’ll probably find that some of the “past research” is pretty valuable, and that the methods already developed retain considerable utility, even as new methodologies are created and applied.
Maybe someone can answer to discussion about how you choose PCA factor in your reconstruction. For me it is pretty forward to use an estimation of noise level as a guideline. Once you have a noise estimation, the weight factor is only the signal over its variance.
Re : #78 and #80
Re: Politicised stats. journal.
The culmination/application of their ‘original’ research into social networks.
Any chance of setting up a permanent open thread? There are times when I would like to ask a question or note something that is not connected to the topic du jour.
You might even want multiple open threads: headline news (Pakistan, Russia, etc.), scientific news (papers, conferences, events, etc.), and communications/politics (how to present results to a lay public, dealing with denialists, pending legislation, etc.).
It might encourage participation by lay people who feel uneasy diving into technical discussions, but do have real concerns and would like to learn more. (Which could be a good thing or a distraction, depending on your mission.)
Just my 2 cents…
#92 JimCA
Please keep in mind that the moderators of this site are working scientists that actually need to sleep once in a while. . ., well okay, not Gavin so much, but vampire qualities aside, rest can be quite healthy.
You know what they say ‘A healthy scientists is a day, helps keep the denialists away’.
—
Fee & Dividend: Our best chance – Learn the Issue – Sign the Petition
A Climate Minute: The Natural Cycle – The Greenhouse Effect – History of Climate Science – Arctic Ice Melt
My general assessment, at this time, about the McShane and Wyner paper is that it is a McKi ‘trick’
http://www.ossfoundation.us/projects/environment/global-warming/myths/ross-mckitrick
The illuminating connections provided by John Washey in post #80 do show connections to the Fraser Institute and McKitirick.
I know, probably just a coincidence ;)
Hmmm. . ., fancy that, M&M are referenced four times in the M&W paper.
And Yasmin Said is an Editor in Chief? Where have I heard that name before?
I’m going by memory here, but wasn’t she used by M&M somehow? And wasn’t she put on an investigating panel to investigate M&M results in connection to the Wegman report and continued investigation on the Hockey Stick?
I will dig around, but it is interesting I think.
—
Fee & Dividend: Our best chance – Learn the Issue – Sign the Petition
A Climate Minute: The Natural Cycle – The Greenhouse Effect – History of Climate Science – Arctic Ice Melt
84 Ike Solem: “periods of glaciation and persistent ice cover could be distinguished from periods of biological productivity”
Leads to an interesting question. I remember from somewhere something like the following:
Tropical oceans are clear because they are too hot for phytoplankton. Cold oceans are turbid because lots of phytoplankton grow in them. [neglecting nutrients] Thus ice ages [not snowball Earth ages] are more lively than interglacials. Besides, the continental shelves are dry during glacial maxima, increasing land area for land organisms.
So humans should be happy to have increased glaciation? Is the holocene really all it’s cracked up to be? Or are our previous cities just hidden by 400 feet of water?
My fingers and my brain sometimes are at odds with each other…
‘A healthy scientist a day, helps keep the denialists away’.
I think that was Goethe (paraphrased of course)?
On the Yasmin Said thing. If that was her on the Wegman investigation committee, it may be a case of the fox guarding the hen house.
Perhaps someone can clear up my reservations about using tree-ring data at all for temperature reconstructions?
I have two main doubts – one, while it is plausible that tree growth should be dependent on climate factors such as rainfall or hours of sunlight, is it realistic to expect that variations of global temperature of 1°c or less should be detectable. Secondly, the variation of tree-ring growth from one season to the next is substantial. However, this “signal” lies in a frequency range outside of what one would expect of a global temperature change, which should have a frequency in the per decade or per century range. In other words, can such a low frequency signal be extracted reliably out of the high frequency noise.
M&W seem to be saying no to both questions, so why even attempt to use tree-ring data?
[Response: M&W have no insight into tree-rings at all. Where did you get that from? But to answer your question, tree rings do show fidelity to temperatures if you go to areas where trees are sensitive to temperatures. Read Salzer et al for instance. – gavin]
[Response: Plausible? Trees, as much or more than any group of organisms on the planet, are 110% integrated with environmental variables, with temperature arguably of first importance among them. They constantly respond, in a bazillion ways, directly and indirectly to temperature–they have no choice. Their carbon balance, and hence fitness and survival, is directly and strongly related to temperature, as selected over tens of millions of years. Any suggestion that growth (and hence tree ring characteristics) from thermally limited sites are insensitive to temperature is wrong at the most fundamental level. As for your question: (1) we are often talking about more than 1 degree C variation over long time spans, and (2) you enhance regional/global s:n by including as many sites as you can, just as you enhance it at the local scale by sampling a collection of trees, and at the tree level by taking two or more cores.–Jim]
re: #97
M&W seemed to have learned what they know of tree-rings from that authoritative source on the topic called the Wegman report … which plagiarized/mangled it from Bradley(1999), as per Deep Climate, Dec 2009 and recently updated into the modern age of color (or colour) DC, July 2010.
Following WR tradition, M&W vaguely reference Bradley … with even less evidence of actually studying it. The WR at least looked at it enough to extract a few tables and diddle a a few pages of text, although with lots of “confounding factors” added to the mix, as well as at least one direct inversion of Bradley’s conclusions.
However, the WR, p.10 did make a major contribution, the use of “artifacts” in an innovative way:
“Paleoclimatology focuses on climate, principally temperature, prior to the era when instrumentation was available to measure climate *artifacts.* Many natural phenomena are climate dependent and, where records are still available, these phenomena may be used asproxies to extract a temperature signal. Of course the proxy signals are extremely noisy and thus temperature reconstruction becomes more problematic as one attempts reconstructions further back in time…”
In bits and pieces, WR p.10 fairly clearly comes from Bradley(1999), pp.1-10, especially p.1, which does *not* use “artifacts”. The last sentence above betrays some misunderstanding, of course.
McShane&Wyner write, p.1:
“The key idea is to use various *artifacts* of historical periods which
were strongly influenced by temperature and which survive to the present.”
Who knows, maybe paleoclimate will adopt this exciting new terminology, the idea that proxies are artifacts? Maybe not.
Stefan Rahmstorf and Martin Vermeer has in their latest sea level study projected sea level rise to 2100 based on current and past warming trends.
Would it be possible to do it the other way around – indicate past temperatures (last 2000 year or so) based on sea level?
Has it been done? Hope I’m not too off topic.
‘artifact’ may go back a ways:
http://www.google.com/search?q=climate+%2Bartifact