What determines how much coverage a climate study gets?
It probably goes without saying that it isn’t strongly related to the quality of the actual science, nor to the clarity of the writing. Appearing in one of the top journals does help (Nature, Science, PNAS and occasionally GRL), though that in itself is no guarantee. Instead, it most often depends on the ‘news’ value of the bottom line. Journalists and editors like stories that surprise, that give something ‘new’ to the subject and are therefore likely to be interesting enough to readers to make them read past the headline. It particularly helps if a new study runs counter to some generally perceived notion (whether that is rooted in fact or not). In such cases, the ‘news peg’ is clear.
And so it was for the Steig et al “Antarctic warming” study that appeared last week. Mainstream media coverage was widespread and generally did a good job of covering the essentials. The most prevalent peg was the fact that the study appeared to reverse the “Antarctic cooling” meme that has been a staple of disinformation efforts for a while now.
It’s worth remembering where that idea actually came from. Back in 2001, Peter Doran and colleagues wrote a paper about the Dry Valleys long term ecosystem responses to climate change, in which they had a section discussing temperature trends over the previous couple of decades (not the 50 years time scale being discussed this week). The “Antarctic cooling” was in their title and (unsurprisingly) dominated the media coverage of their paper as a counterpoint to “global warming”. (By the way, this is a great example to indicate that the biggest bias in the media is towards news, not any particular side of a story). Subsequent work indicated that the polar ozone hole (starting in the early 80s) was having an effect on polar winds and temperature patterns (Thompson and Solomon, 2002; Shindell and Schmidt, 2004), showing clearly that regional climate changes can sometimes be decoupled from the global picture. However, even then both the extent of any cooling and the longer term picture were more difficult to discern due to the sparse nature of the observations in the continental interior. In fact we discussed this way back in one of the first posts on RealClimate back in 2004.
This ambiguity was of course a gift to the propagandists. Thus for years the Doran et al study was trotted out whenever global warming was being questioned. It was of course a classic ‘cherry pick’ – find a region or time period when there is a cooling trend and imply that this contradicts warming trends on global scales over longer time periods. Given a complex dynamic system, such periods and regions will always be found, and so as a tactic it can always be relied on. However, judging from the take-no-prisoners response to the Steig et al paper from the contrarians, this important fact seems to have been forgotten (hey guys, don’t worry you’ll come up with something new soon!).
Actually, some of the pushback has been hilarious. It’s been a great example for showing how incoherent and opportunistic the ‘antis’ really are. Exhibit A is an email (and blog post) sent out by Senator Inhofe’s press staff (i.e. Marc Morano). Within this single email there are misrepresentations, untruths, unashamedly contradictory claims and a couple of absolutely classic quotes. Some highlights:
Dr. John Christy of the University of Alabama in Huntsville slams new Antarctic study for using [the] “best estimate of the continent’s temperature”
Perhaps he’d prefer it if they used the worst estimate? ;)
[Update: It should go without saying that this is simply Morano making up stuff and doesn’t reflect Christy’s actual quotes or thinking. No-one is safe from Morano’s misrepresentations!]
[Further update: They’ve now clarified it. Sigh….]
Morano has his ear to the ground of course, and in his blog piece dramatically highlights the words “estimated” and “deduced” as if that was some sign of nefarious purpose, rather than a fundamental component of scientific investigation.
Internal contradictions are par for the course. Morano has previously been convinced that “… the vast majority of Antarctica has cooled over the past 50 years.”, yet he now approvingly quotes Kevin Trenberth who says “It is hard to make data where none exist.” (It is indeed, which is why you need to combine as much data as you can find in order to produce a synthesis like this study). So which is it? If you think the data are clear enough to demonstrate strong cooling, you can’t also believe there is no data (on this side of the looking glass anyway).
It’s even more humourous, since even the more limited analysis available before this paper showed pretty much the same amount of Antarctic warming. Compare the IPCC report, with the same values from the new analysis (under various assumptions about the methodology).
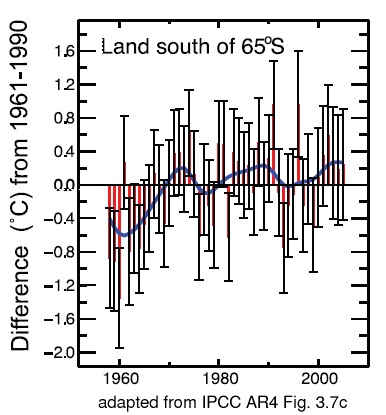
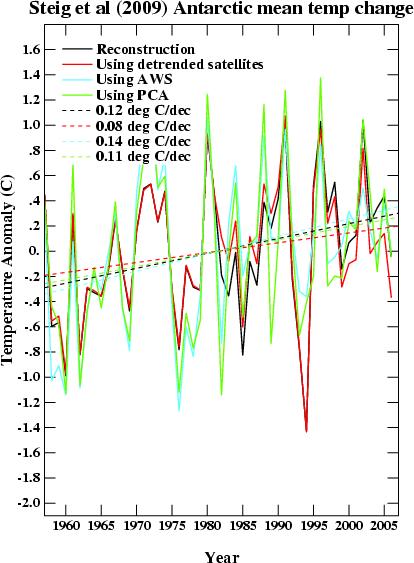
(The different versions are the full reconstruction, a version that uses detrended satellite data for the co-variance, a version that uses AWS data instead of satelltes and one that use PCA instead of RegEM. All show positive trends over the last 50 years).
Further contradictions abound: Morano, who clearly wants it to have been cooling, hedges his bets with a “Volcano, Not Global Warming Effects, May be Melting an Antarctic Glacier” Hail Mary pass. Good luck with that!
It always helps if you haven’t actually read the study in question. That way you can just make up conclusions:
Scientist adjusts data — presto, Antarctic cooling disappears
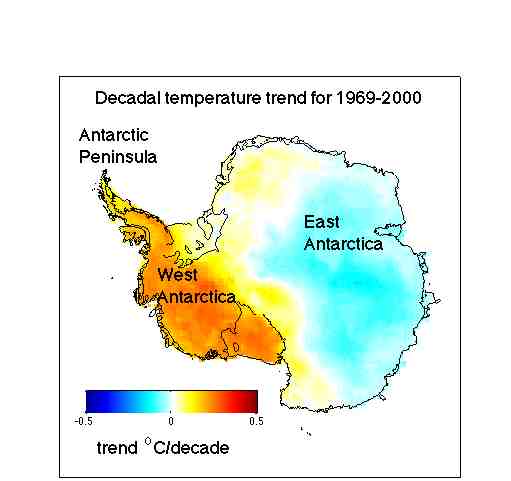
Nope. It’s still there (as anyone reading the paper will see) – it’s just put into a larger scale and longer term context (see figure 3b).
{kind=link}
Inappropriate personalisation is always good fodder. Many contrarians seemed disappointed that Mike was only the fourth author (the study would have been much easier to demonise if he’d been the lead). Some pretended he was anyway, and just for good measure accused him of being a ‘modeller’ as well (heaven forbid!).
Others also got in on the fun. A chap called Ross Hays posted a letter to Eric on multiple websites and on many comment threads. On Joe D’Aleo’s site, this letter was accompanied with this little bit of snark:
Icecap Note: Ross shown here with Antarctica’s Mount Erebus volcano in the background was a CNN forecast Meteorologist (a student of mine when I was a professor) who has spent numerous years with boots on the ground working for NASA in Antarctica, not sitting at a computer in an ivory tower in Pennsylvania or Washington State
This is meant as a slur against academics of course, but is particularly ironic, since the authors of the paper have collectively spent over 8 seasons on the ice in Antarctica, 6 seasons in Greenland and one on Baffin Island in support of multiple ice coring and climate measurement projects. Hays’ one or two summers there, his personal anecdotes and misreadings of the temperature record, don’t really cut it.
Neither do rather lame attempts to link these results with the evils of “computer modelling”. According to Booker (for it is he!) because a data analysis uses a computer, it must be a computer model – and probably the same one that the “hockey stick” was based on. Bad computer, bad!
The proprietor of the recently named “Best Science Blog”, also had a couple of choice comments:
In my opinion, this press release and subsequent media interviews were done for media attention.
This remarkable conclusion is followed by some conspiratorial gossip implying that a paper that was submitted over a year ago was deliberately timed to coincide with a speech in Congress from Al Gore that was announced last week. Gosh these scientists are good.
All in all, the critical commentary about this paper has been remarkably weak. Time will tell of course – confirming studies from ice cores and independent analyses are already published, with more rumoured to be on their way. In the meantime, floating ice shelves in the region continue to collapse (the Wilkins will be the tenth in the last decade or so) – each of them with their own unique volcano no doubt – and gravity measurements continue to show net ice loss over the Western part of the ice sheet.
Nonetheless, the loss of the Antarctic cooling meme is clearly bothering the contrarians much more than the loss of 10,000 year old ice. The poor level of their response is not surprising, but it does exemplify the tactics of the whole ‘bury ones head in the sand” movement – they’d much rather make noise than actually work out what is happening. It would be nice if this demonstration of intellectual bankruptcy got some media attention itself.
That’s unlikely though. It’s just not news.
Ur shouldn’t mock, but……
http://n3xus6.blogspot.com/2009/02/parable.html
Please explain how you can exactly reconstruct Harry, including its incorrect splicing with Gill, if Harry was not used in the reconstruction. Thanks.
[Response: The reconstruction using the AWS stations obviously used AWS stations and the existing data is not ‘reconstructed’ – the method fills in missing data points, it doesn’t change the data that was measured. But the main reconstruction uses AVHRR data, where none of the AWS stations are used. – gavin]
Re #122, the idea of sinking enourmous heaters after freezing the surround of the earth is a non starter from a CO2 perspective and an energy return perspective. I read up on this issue of Shells r&D and it come up as pretty much a load of rubbish simply because of the length of time it takes to heat the earth to make the oil run requires a massive coal fired power station for one and years of energy to. So forget your 15 trillion barrels of tar/shale/heavy oils for its probably not viable for both a carbon reason and an energy return on energy invested reason to.
Electricity is the only way forward for everything, liquid fuels have a limited lifetime to come and hence its probably best to stop burning it all in vehicles. Electricity is a highly ordered enery (low entropy) and vehicles can run on it and its available in the USA in large amounts via the three wind corridors and the deserts to make it via CSP.
Re #200 “Response: It’s not nonchalance. Errors in data and code should be looked for and fixed when found. It’s simply that this is not the most important issue when deciding whether a result is interesting or not. Someone could have perfect data and absolutely correct code, but because their analysis is based on a fundamentally incorrect assumption, the result will be worthless. But errors in data are ubiquitos, as are bugs in code (Windows, anyone?) – interesting results therefore need to be robust to these problems. Which is why we spend time trying to see whether different methods or different data sources give the same result. That kind of independent replication is the key to science, not checking arithmetic. – gavin]#
Gavin
VS.
Steig
“People were calculating with their heads instead of actually doing the math,” Steig said. “What we did is interpolate carefully instead of just using the back of an envelope. While other interpolations had been done previously, no one had really taken advantage of the satellite data, which provide crucial information about spatial patterns of temperature change.”
(http://uwnews.org/article.asp?articleID=46448)
So Gavin are you saying “Someone could have perfect data and absolutely correct code, but because their analysis is based on a fundamentally incorrect assumption”, instead back of an envelope thinking is the correct scientific method to use just as long as it comes to the right conclusion? Who is correct, you or Steig? /Jens
[Response: Huh? Perhaps it’s just me, but I fail to see how the two quotes are contradictory in any way. Your assumption that anyone is advocating using any ‘method as long as it comes to the right conclusion’ is ridiculous and frankly insulting. – gavin]
I think the current discussion illustrates wonderfully why you don’t want a bunch of clueless “auditors” mucking about in science. Science recognizes that errors are inevitable. It also recognizes that some errors are significant–that is, they alter the conclusions of the research. Others are trivial, having only insignificant effects. Knowing which is which is one of the reasons why it takes a decade of schooling and several years of post-doc experience to become a productive scientist. It is also one of the reasons why it is difficult to cross into a different field of research.
The significance of a study depends on whether or not it advances understanding of the subject. This study obviously does, and it’s pretty unlikely that a bunch of amateur “auditors” looking for misplaced commas or other minor errors would even know a significant error if they found one.
> a copy of the data, and that he sends it to “legitimate” researchers
…
And if he’d put it all up for everybody and it had been copied widely, the error would be in every single copy out there the day of publication. You imagine every single copy would be corrected later?
> I don’t see why everything has to be a political debate
Speak to those making it go that way about this.
Let us know what they say.
I think they’ll tell you the most important thing to them is to stop the scientists from being considered credible to prevent policy being based on the science. Look up “sound science” — their alternative.
Gavin:
BAS has now apparently identified who alerted them to the problem with the Harry data:
http://www.antarctica.ac.uk/met/READER/data.html
“Note! The surface aws data are currently being re-proccessed after an error was reported by Gavin Schmidt in the values for Harry AWS(2/2/09) ”
I do not understand why you would not simply have said this and acknowledged what alerted you to the issue. The way you stated this earlier clearly suggests that whoever alerted BAS did so after independently identifying the issue. That I am afraid is now extremely hard to believe.
[Response: Why? SM made a coy point about Harry, I looked, worked out (independently) that the Gill and Harry had been mashed together incorrectly and let BAS know – others worked it out too. If he’d said what he knew when he knew it instead of playing games, there would have been no need for me to do anything. As it was, he didn’t report what the data error was. I stress, the most important thing when finding errors is to get them fixed, not jump up and down declaring how clever you are to see them. – gavin]
Ray: “The significance of a study depends on whether or not it advances understanding of the subject. This study obviously does…”
It may (even probably will) turn out to ‘advance understanding of the subject’, but to take on faith that it is obvious at this point appears unscientific to me.
And why business doesn’t allow clueless “auditors” (those untrained in financial matters) to muck about their internal financial documentation in order to “prove” some political point.
The fundamental myth being propagated by SM at CA is that one need no expertise to be an “auditor”, that any joe schmoe running around shouting catchphrases like “open source”, “publish the data”, etc is qualifed to “audit” science they clearly don’t understand.
There’s a reason why professional firms that do audits employ CPAs. There’s no special license required to perform an audit, but a CPA at least gives one some confidence that the person you’re dealing with understands financial stuff reasonably well.
> don’t see why everything has to be a political debate
Here: http://scholar.google.com/scholar?q=%22sound+science%22
Public health has a perspective much like what climatologists are starting to adopt. Industry is actively opposed to that perspective.
On the answer to 196.
One of the problems is that in THE REAL WORLD, unless you’re counting unitary objects, you don’t GET “precisely 2”. Even if you take such a seemingly arbitrarily accurate measurement of “what is my height”, it changes depending on when you take the measurement.
So you have to ask whether the difference between what you measured and what the measurement difference means. When it comes to fitting me with a pair of trousers or a shirt, no, the errors in measuring my height are irrelevant.
Hence someone can sell a “17 collar” shirt and I can wear it. As can people who are taller or shorter than me. Even though NONE OF US have exactly a 17″ collar. Or shirts in “S/M/L”, which means a lot of us are all the same height, yes?
So Gavin’s response is like saying in the real world, can I sell three size L shirts to the three people:
Mr A: 40.098740374″ chest
Mr B: 41.837460038″ chest
Mr C: 39.92003″ chest
Answer? Yes.
Which from a mathematical shop assistant POV is the same as
is
40.098740374 + 41.837460038 + 39.92003 = 3 x L
where L = 42
(the median size of a L shirt chest)
Yes.
Mr. Roberts,
Yes the error would be in every single copy which would be the exact right result. This is the data that the paper was based on so the person looking at methods and data could see exactly how the result was derived. Knowing that they are starting from the right point they could then apply any changes to the data that they feel are appropriate, explain the changes and demonstrate the change in the result. Alternatively they could start with the same data, apply a different analysis and come up with a confirming or different result. The whole idea is to reduce the number of moving parts.
Rather than all this bickering I would actually like to see this happen now. Apply the changes to this one particular site, and let’s see the new result. In the paper the comparison with the AWS trends is considered important to confirm the result. Does this affect the comparison or is it indeed insignificant?
Dr. Schmidt has promised a new post on the topic which I assume will do this.
[I already answered this question at least once above. The answer should have been obvious from the beginning to anyone that actually sat down and thought about it, but I’ve done the calculations anyway. I’ll give you a sneak preview of Gavin’s post: the difference it makes is about 8% at the offending AWS site (Harry) and less than 2% overall. Oh, and less than 1% in West Antarctica. Oh, and I forgot to mention that the reconstructed AWS now agrees better with the satellite data than before. Not suprising either, if you think about it for a minute.–eric]
There is a reported prayer by St. Francis of Assisi:
“Lord, give me the power to change what I can, the strength to endure what I cannot change, and the wisdom to understand the difference.”
Handling errors is similar: you fix or eliminate the ones you can find, and make sure that the ones you cannot find but know are there, cannot hurt you.
Wisdom is always a useful commodity ;-)
Martin, I prefer Calvin’s version.
“The strength to change what I can, the inability to accept what I can’t, and the incapacity to tell the difference.”
Gavin:
“It would have been nice had SM actually notified the holders of the data that there was a problem (he didn’t, preferring to play games instead).”
Actually, it’s not a game. It’s a story. A mystery. The ironical thing is that you contributing to the “mystery” and “game playing” by referencing “independent people” who reported the error to BAS. You could have just said.
‘ I read CA, SM hinted at a problem with Harry, a couple of posters found some interesting similarities between Gill and Harry. I looked at the problem, found the error and reported it.” the simple truth takes all the drama out of this thing.
[Response: Independent people (including posters on CA and myself) all found the Gill/Harry thing independently once there was a hint that there was something wrong. I have no interest in the issue other than to see that the error is fixed. I didn’t claim credit because I don’t particularly care who reported it. It was curious that no-one else did. – gavin]
Mark, I grew up in a calvinist country. No need to rub it in ;-)
A bit off topic, but regarding data archiving (comment 161): here at the NOAA PMEL lab, we have developed a beta version of a Web site that might be of interest to some of the RC readers. Our site allows users to archive georeferenced datasets that are in the netCDF format. Since it’s a government site, you have to apply and be approved for an account. However, the approval is pro-forma at this point.
More info:
FAQ
Open an account
Example
Gavin
It is not 120 people working full-time just working on this product.
I am guess there is one or two person working one or two days a week on published GISS product. Everything done by scripts. Probably cost less than 100K$ per year.
Too little humans resource to time to check anything, or chase up data not supplied. What is needed is a serious team with the time to call folks and investigate station locations. But the department see no need to spend the extra money, as the product will look much the same even if you survey the sites in Ireland, and call the Romanian who is late with his data.
Is that about right? If it is, I am understand your frustration…
People are taking decisions based of theses figures which have unbelievably high economic consequences. One coal power station is around a billion dollars, and a nuclear a lot more.
[Response: The main people who deal with data quality and collation are the National Weather Services (UK Met Office, or NOAA in the US), they have much bigger staff and the resources to deal with this. GISTEMP is just an analysis of that data (and not something that I’m directly involved in), and as you say, a much smaller enterprise. If they see problems, they report them to the upstream agencies, but they don’t control those databases in any real way. – gavin]
Nicolas, you’re proposing completely changing the way the science journals handle corrections. Why?
What’s broken?
What is the effect on the temperature measured by the weather sensors once it becomes buried in snow ?
Regards,
Will
[Response: The effect on the data actually used by Steig et al for the results featured in the paper (the satellite-derived ice surface temperature estimates) is precisely zero. The effect on the AWS data used as a secondary check by Steig et al could conceivably be non-zero. But for it have any noticeable impact, snow burial between successive AWS checks would have to be decidedly non-random in nature, exhibiting a continental-scale coherence, and a long-term temporal trend to boot. And somehow one would still have to get the same answer using the satellite data, you know, the data that were actually used for the results featured in Steig et al. -mike]
The key words in Gavin’s statement is that “BAS were notified by people Sunday night who independently found the Gill/Harry mismatch.
It was not found “independently”. It was not even “found”.
Unless you found this very same error, with no input from SM, on the very same day, then you were dependent on SM as the original finder of the mismatch.
As he pointed it out to you (or someone told you about the CA story), it was obviously not “found”.
I won’t comment on “notified by people”.
[Response: Wrong on all counts. i) discovering that Gill was mismatched with Harry was found independently by at least three people (SM, myself, and a poster on CA). ii) the source of the confusion was indeed found and not given to me by anyone else, iii) we are all dependent on many things, including that SM had alluded to data problem at Harry – I don’t see anywhere that I denied this. And BAS were notified by ‘people’ (plural) – not just by me. – gavin]
So let me get this straight, Gavin.
You found the very same problem that SM alluded to, on the very same day he did, with no direct or indirect input from CA?
Is this correct?
[Response: Huh? Let’s try again. He alluded to an unspecified problem, and I looked into it. I found the source of the problem with no further input from anyone. This isn’t that complicated. – gavin]
So everyone, Gavin’s answer is “Yes”, he found the problem Steve pointed him to with no other help than just the name of the station.
So, it wasn’t independent, then. You would not have found it without SM’s alluding to the problem.
“Found” would also be the wrong word, as SM had already “found” it. “Confirmed” would be more accurate.
[Response: I disagree. I had no idea what SM thought he had found. I don’t think I can confirm something I didn’t already know. – gavin]
This whole discussion on who got credit for discovery of an error is rather tedious. Let’s get something straight–
a) No scientist or organization is under obligation (or should be expected) to follow the news coming out of every science blog out there. Blogs are thus not appropriate venues for the spread and sharing of information. If people privately investigating (or ‘auditing’) data find a problem, they should report that issue to appropriate workers who handle the data. Posting that there is a mistake on a blog without doing anything else is quite unproductive… that is, if your goal is to actually advance data quality.
b) Playing “mystery man” games and flinging around (or allowing and supporting) conspiracies and accusations is also very unproductive. People have much better things to do.
c) If I am told by someone that there may be a data quality issue but that person doesn’t work out and report the details, I’m not under any obligation (ethically, legally, etc) to reference that person in my work if I go pursue the data myself and independently find and report the problem. If SM noticed an error, then kudos to him, but he obviously has issues on what to do next if he finds errors. Complaining and playing “I’m the victim” is not fooling anyone.
If I may be so bold, is there something more productive now that we can talk about?
Mr. Roberts,
I didn’t make any comment about how science journals handle corrections, so I have no idea what you are talking about.
Do the dozen or so people who’ve come here from CA flinging down their gauntlets care about being productive?
Looks to me like they’re trying to push the same old CA “climate scientists are incompetent, dishonest (“Gavin’s lying when he says he found the problem independently!”)”, etc.
Certainly productive for those trying to monkeywrench science and any political response to science.
Undoubtably frustrating and unproductive for those trying to DO science. Oh, yeah, that’s another goal, ain’t it? Waste people’s time.
“Oh, yeah, that’s another goal, ain’t it? Waste people’s time.”
Indeed. And behold what a lovely and self-righteous infestation they can mount.
If only their energy and zeal were directed to something actually useful, say actually understanding the underlying science?
Mr. Nierenberg, point is, the paper, and the correction, and the data files, all have routines for correcting information. Adding your notion of giving lots of copies to people doesn’t seem to accomplish anything but opportunities for confusion.
Why, you’d need an auditor to check every copy anyone claimed was good against the original before doing anything, if people were relying on copies to do work. How can you trust a copy, if you don’t verify it against the source? And as you can get the source, what reason is there not to use it?
You know journals handle typos and assess whether a change makes a difference in the results — all the time. Look at the satellite weather record where a single character was wrong for years — and the papers were corrected. There are still people making blog arguments based on the old bad information — but only because they don’t go and look up the references and find the corrections.
You make the opportunity for great mischief if you do what you recommend. Why bother? The data is available, the correction mentioned above is available, ongoing corrections are always made and available. But people have to look to get them.
This is a _good_ thing, that people have to look to the source files rather than relying on copies.
Here’s one of the great examples of how it works. I’m sure you know it, but for any youngster looking for a paper topic or home work help, read up on this:
http://www.ncbi.nlm.nih.gov/pubmed/16141071?ordinalpos=1&itool=EntrezSystem2.PEntrez.Pubmed.Pubmed_ResultsPanel.Pubmed_DiscoveryPanel.Pubmed_RVAbstractPlus
Correcting Temperature Data Sets
Christy et al.
Science 11 November 2005: 972-973
DOI: 10.1126/science.310.5750.972
re: data archiving and reproducibility…
Any who are interested should google “reproducible research”, a widespread initiative begun in the early 1990’s. It works. There are even methods for embedding the latest R language analysis into the body of your journal article so all figures etc can be automagically reproduced.
Any further comments should go on the new thread, thanks.