Hot on the heels of last months reporting of a discrepancy in the ocean surface temperatures, a new paper in Nature (by Domingues et al, 2008) reports on the revisions of the ocean heat content (OHC) data – a correction required because of other discrepancies in measuring systems found last year.
Before we get to the punchline though, it’s worth going over the saga of the OHC trends in the literature over the last 8 years. In 2001, Syd Levitus and colleagues first published their collation of ocean heat content trends since 1950 based on archives of millions of profiles taken by oceanographic researchers over the last 50 years. This showed a long term upward trend up, but with some very significant decadal variability – particularly in the 1970s and 1980s. This long term trend was in reasonable agreement with model predictions, but the decadal variability was much larger in the observations.
As in all cases where there is a data-model mismatch, people go back to both in order to see what might be wrong. One of the first suggestions was that since the spatial sampling became much coarser in the early part of the record, there might be more noise earlier on that didn’t actually reflect a real ocean-wide signal. Sub-sampling the ocean models at the same sampling density as the real observations did increase the decadal variability in the diagnostic but it didn’t provide a significantly better match (AchutaRao et al, 2006).
Other problems came up when trying to tally the reasons for sea level rise (SLR) over that 50 year period. Global SLR is a product of (in rough order of importance) ocean warming, land ice melting, groundwater extraction/dam building, and remnant glacial isostatic adjustment (the ocean basins are still slowly adjusting to the end of the last ice age). The numbers from tide gauges (and later, satellites) were higher than what you got by estimating each of those terms separately. (Note that the difference is mainly due to the early part of the record – more recent trends do fit pretty well). There were enough uncertainties in the various components so that it wasn’t obvious where the problems were though.
Since 2003, the Argo program has seeded the oceans with autonomous floats which move up and down the water column and periodically send their data back for analysis. This has at last dealt with the spatial sampling issue (at least for the upper 700 meters in the ocean – greater depths remain relatively obscure). Initial results from the Argo data seemed to indicate that the ocean cooled quite dramatically from 2003 to 2005 (in strong contradiction to the sea level rise which had continued) (Lyman et al, 2006). But comparisons with other sources of data suggested that this was only seen with the Argo floats themselves. Thus when an error in the instruments was reported in 2007, things seemed to fit again.
In the meantime however, calibrations of the other sources of data against each other were showing some serious discrepancies as well. Ocean temperatures at depth are traditionally made with CTDs (a probe that you lower on line that provides a continuous temperature and salinity profile), Nansen bottles (water samples that are collected from specified depths) or XBTs (eXpendable bathy-thermographs) which are basically just thrown overboard. CTDs are used over and again and can be calibrated continuously to make sure their pressure and temperature measurements are accurate, but XBTs are free falling and the depths from which they are reporting temperatures needs to be estimated from the manufacturers fall rate calculations. As the mix of CTDs, bottles, XBTs and floats has changed over time, minor differences in the bias of each methodology can end up influencing the trends.
(If this is all starting to sound very familiar to those who looked into the surface stations or sea surface temperature record issues, it is because it is the same problem. Almost all long historical climate records were not collected with the goal of climate in mind.)
In particular, analysis (or here) of the XBT data showed that it was biased warm compared to the CTDs, and that this bias changed over time, and was dependent on the kind of XBT used (deep versus shallow). Issues with the fall rate calculation were well known, but corrections were not necessarily being applied appropriately or uniformly and in some cases were not correct themselves. The importance of doing the corrections properly has been subject to some ongoing debate (for instance, contrast the presentations of Levitus and Gourteski at this meeting earlier this year).
So where are we now? The Domingues et al paper that came out yesterday, along with a companion paper from essentially the same group (in press at Journal of Climate) have updated the XBT corrections and dealt with the Argo issues, and….
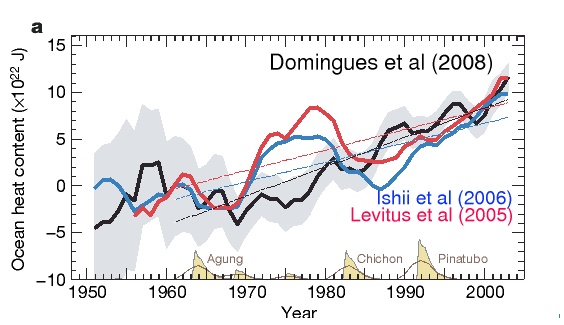
… show a significant difference from earlier analyses (the new analysis is the black line). In particular, the difficult-to-explain ‘hump’ in the 1970s has gone (being due to the increase in warm-biased XBTs at that time). The long term trend is slightly higher, while the more recent trends are slightly lower. Interestingly, while there still decadal variability, it is much more obviously tied to volcanic eruptions than was previously the case. Note that this is a 3-year smooth, so the data actually goes to the end of 2004.
So what does this all mean? The first issue is tied to sea level rise. The larger long term trend in ocean warming reported here makes it much easier to reconcile the sea level estimates from thermal expansion with the actual rises. Those estimates do now match. But remember that the second big issue with ocean heat content trends is that they largely reflect the planetary radiative imbalance. This imbalance is also diagnosed in climate models and therefore the comparison serves as an independent check on their overall consistency. Domingues et al show some comparisons with the IPCC AR4 models in their paper. Firstly, they note that OHC trends in the models that didn’t use volcanic forcings are consistently higher than the observations. This makes sense of course because each big eruption cools the ocean significantly. For the models that did include volcanic forcings (including the model we used in Hansen et al, 2005, GISS-ER), the match is much better:
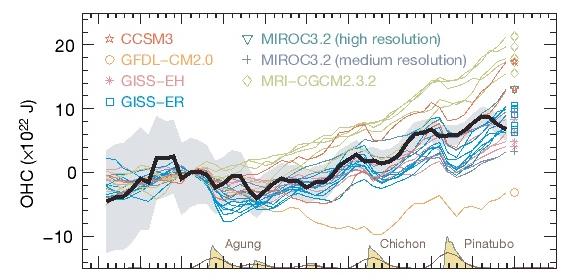
(Note that the 3-year smoothed observations are being compared to annual data from the models, the lines have been cut off at 1999, and everything is an anomaly relative to 1961). In particular, the long term (post 1970) observational trends are now a better match to the models, and the response to volcanoes is seen clearly in both. The recent trends are a little lower than reported previously, but are still within the envelope of the model ensemble. One interesting discrepancy is noted however – the models have a slight tendency to mix down the heat more evenly than in the observations.
This isn’t going to be the last word on OHC trends, and different groups are going to be publishing their own versions of this analyses relatively soon and updates to the most recent years are still forthcoming. But the big picture is that ocean heat content has indeed been increasing in recent decades, just like the models said it should.
#26 L. David Cooke,
If Gavin said you were citing regional effects I’d agree.
This 7 year lag. I know it sounds stupid but I can only guess from the first link that you’re attributing the 1998 (ENSO related?) dip, to 1991’s eruption of Pinatubo. As I’ve obviously got the wrong end of the stick, could you clarify?
There are known issues with the most recent data that as far as I know still need to be addressed. Yet some consider themselves so much ahead of the oceanography field that they can claim implications from that data. The Domingues paper makes a significant revision as compared to Levitus, but it’s still in reasonable agreement with the models. Indeed in removing the 1970-1980 hump it seems to make a better fit.
So are we really supposed to believe that the models were working OK until a few years ago when they “fail” and that “failure” is best interpreted not as “there’s something else afoot here”, but as “the models are wrong”?
Sounds desperately contrived to me! ;)
RE: 51
Hey Cobbly,
The first statistically significant dip in the Pacific Ocean SST and heat content to occur after the Mt. Pinatubo eruption appears to coincide with the 1998 ENSO dip when the average global surface atmospheric land temperature appeared to take a significant rise. In review of the precipitant and historic record following large tropical volcanic releases there appears to be a similar pattern. Though it is entirely possible I am seeing a pattern where there is not one. Though if you were to remove up to 5% of the energy input to a region of the ocean during the peak input time it could take several years for the anomaly to circulate and be detected.
Another interesting pattern seems to be related to volcanic activity as well. According to the data record that I researched, I have seen there is an anomaly that appears to occur between 15 and 20 years after a large eruption. Historically, there appears to be a curious signature of a NH temperate zone drought associated with the volcanic activity. Though again it is possible these are only observations due to a search for them and they are not necessarily truly correlated.
As to the Argo and the satellite data I concur; however, I suspect that for the TOA/Triton and PIRATA data sets the data is generally worthy in its raw form of not requiring much in the way of correction. If the data collected by these arrays are correct and there is not an invalidation of the raw measurements then I suggest that the measurement data record would be more correct then the model record used in the heat content study above. If this is true then yes I would suggest there might be a problem with the models. I know a lot of ifs; however, as usual my preference is to go with known data rather then “created” data when I can.
As to models being wrong or describing an alternative variable, maybe I have not done enough research. Most of the model work I have seen described by Dr. Schmidt and others here has indicated that they are very careful in the creation of single variable attributes to reduce the possibility of competing or confounding variables. Based on due diligence by these experts I would suspect that there may be more of an issue with the description of the nature of the described attribute rather then an error in the model itself.
Cheers!
Dave Cooke
I realize that this is way of topic, but it concerns arctic ice, which we have discussed at length in the past. We are now coming to the time of year when, looking back at the data with 20/20 hindsight, this was the start of the big melt in 2007. From here on, for the next few weeks, we will have an idea of whether 2008 is going to follow in the steps of 2007. 1st July (Canada Day) 2007 was when the largest single day’s ice melt, recorded since 1979, occurred. May I suggest that
http://nsidc.org/data/seaice_index/images/daily_images/N_timeseries.png is a good reference. It seems to be updated daily.
CobblyWorlds
“So are we really supposed to believe that the models were working OK until a few years ago when they “fail” and that “failure” is best interpreted not as “there’s something else afoot here”, but as “the models are wrong”?”
Why not? The models were largely constructed around the data at the time, therefore when the models are run against the gathered data and are subsequently tweaked a little, it is no surprise that they were a good fit.
As an example send me a random data sample of roulet*e spins and I will send you a betting model that will earn you money at roulet*e. You can prove its efficacy by running it against the supplied data and you will see that it works. I can do that every time 100% guaranteed. The trick is to keep the model working when you send me new data I can keep it working for a time by tweaking the sequencing , betting amounts etc but it will eventually be overwhelmed by new data and be falsified.
That is because this model operates in an area of science that is settled, Probability Theory, unlike Climate Science which clearly isn’t.
Except, as has endlessly pointed out, this isn’t how they are constructed.
And, because models are built on our best understanding of the underlying physics, rather than built to match old data, models do much better than perform that trick.
They predict things that haven’t been previously measured, like stratospheric cooling … in other words they send you new data before you measure it, rather than simply match new data you send them.
dhoghaza
“And, because models are built on our best understanding of the underlying physics, rather than built to match old data, models do much better than perform that trick.”
The underlying physics were present in the period 1945 – 1975, why therefore were there no large scale models produced at that time that predicted the subsequent warming to 1998?
[Response: There were. Look up Spencer Weart’s site on the discovery of global warming, or look up Manabe and Weatherald (1967) discussed in Petersen. Connolley and Fleck (2008). – gavin ]
I would have far more more impressed and convinced if there had been. But of course models constructed using data at that time would not have shown the subsequent warming because there was not an obvious relationship between CO2 emmissions and warming observable at that time.
Mankind always want instant solutions and gratifications, it’s natural, but the scientific community and approach must recognise this and be cautious with its pronouncements until it is has a very high confidence level in its theories.
We are way short of this in relation to how the planets various climatic processes react and combine to the huge number of forcing and feedback factors.
#53 OT – watching the ice:
NCEP’s weekly analysis also gives a nice perspective. Put these beside each other in your browser:
Ice concentrations: 14 June 2008 and 14 June 2007. There’s slightly more this year (but it’s younger and, presumably, thinner).
Sea surface temperatures: 14 June 2008 and 14 June 2007.
Last year a large positive SST anomaly developed in the Bearing Sea in July, and extended into the East Siberian Sea. Water temps north of the Bearing Strait were as high as +8°C. Almost swimmable…
“Except, as has endlessly pointed out, this isn’t how they are constructed.”
Quite true, dhogaza. Amazing how some people just don’t want to absorb that inconvenient fact, though.
I Love you guys. The data doesn’t fit the model predictions so we’ll just apply “corrections” to the data to make it fit. And you call it science? I mean this is what he said to Reuters
http://africa.reuters.com/top/news/usnBAN946269.html see paragraphs 5 and 6
[Response: You are interpreting something that isn’t there. They corrected data that was incorrect and that led to a better match. They did not correct the data in order to get a better match. Given the demonstrated problem in the XBT data, what would you have them do instead? – gavin]
Ref #57 from GlenFergus “(but it’s younger and, presumably, thinner).” We have been through this before. Most of the ice that is currently turning into open ocean is what I call “annual ice”; ice which is, by definition less than one year old. Each year about 9 million sq kms of open ocean turn into ice, and each year about the same amount changes from ice into open ocean. This is “annual ice”. So far as I am aware, the thing that controls how much annual ice there is, and how thick it is, is the length and coldness of the winter. Last winter in the Arctic was, in comparison to recent years, long and cold. So one would not necessarily expect the current annual ice to be “thinner”. In any event, “thinner” than what?
RE: 59
Hey Greg and Dr. Schmidt,
It would be helpful though if the nature of the how the data was corrected was generally known. For us who are layman, we would expect that the data correction is only for data where there is missing data. Given this then how do you fill in the holes? Two methods come to mind, one is where you would use the thirty year average high and low. Another method would be where you would interpolate between the day before and the day after. It would seem that the best method would be to use the 30 year average for that day and adjust it by the deviation seen in the prior and following measured period.
As for data fitting the model, Greg, I think I can see your point based on my former bias. It just seems terribly convenient when a “correction” is reported and the description of the application of the correction is not part of the data set.
That there have been occurrences in the past where a corrective value has been used to broad stroke correct a data set where there is a known and possibly tested offset. For example even today there is a corrective value that needs to be applied to about 2% of the ARGO buoys in the Atlantic based on the serial number of the depth gauge. However, the remaining 98% do not require a correction, nor do all the “deviant” buoys need to get the same correction.
If you were to review the USCHN data sets there is a correction applied to certain data sets that are related to Urbanization. The question is are these corrections applied even during days in which the cloud cover would be dense enough to negate or reduce the necessity of the correction? You also have the issue of non-insolation heat source corrections. To go a little off topic myself, I think I can share why this question reappears so often when talking about models.
The point is layman are being asked to trust and not to look over the shoulder of experts when they clearly question the validity of the experts due to the chaotic nature of the data sets appearing to invalidate the experts predictions. That “everyman” is being asked to trust when a trust condition does not exist leads to more distrust in many minds. Full disclosure, as was the embodiment of the nature of science in the early part of the 20th century would be welcome. However, we perceive an issue when data is withheld or enveloped in higher math where it is difficult for us to understand.
The point is, it is not incumbent on the part of the expert to disclose the data correction or algorithm? If the data set or calculations can lead to commercial value or funding restrictions the evident answer is no. The idea of science for the sole purpose of science appears to have been lost. On the other hand if this avenue is not taken there are insufficient funds to perform the science. I suspect it has become a balancing act as budgets come in to play….
Greg, I suspect you may have to make a decision. Does the historic record of the source invoke trust. If yes then accept the data as represented. If no, then pursue expert evaluation by experts you trust. In short, know your source…
Cheers!
Dave Cooke
#56 Alan Miller,
Over 95% good enough for you? It is for me.
Re models I refer you to the replies above. In addition, you may prefer to use Occams Razor to whittle away the most straightforward explanations to suit your preconceptions. I prefer to use it to leave me with the simplest and least contrived explanations.
#52 L David Cooke,
I still see that as ENSO related. Given the immense local and seasonal variability of the oceans (as with the atmosphere) I recommend not trying to draw conclusions with regards AGW from local observations, although when studying ENSO etc such local observations can be very helpful.
#57 Glen Fergus,
The thinning currently extending from Beaufort/Chucki to the pole is less extensive for June this year than June 2007 (Cryosphere Today / AMSR-E). Furthermore last year’s exceptional melt rate occurred early July (NSIDC 2007). So things are looking as uncertain as before, although I still expect acceleration in July August I am now less sure William Connelly will lose his bet (I’d expected greater thinning and Polnya formation by now). Watch out for the June outlook from ARCUS, it’ll be interesting to see if stances change.
I’m new to this and have a couple of simple questions:
Why are climatologiusts always adjusting their data? How do they know in which direction to adjust them?
[Response: The fundamental problem is that long climate time series are based on data that was designed to do something else. Weather stations were there for weather reports and forecasts, ocean temperatures were for all sorts of reasons – none of which were estimating 50 year long trends. That means that people made decisions about changes of technique, instruments, data treatment etc. without thinking about what effect it would make on the long term trend. Now, we have a different perspective on these data and those decisions need to be dealt with in some way. Corrections usually come from either physical modelling of what changed (i.e. the bucket issue or the XBT fall rate), or on comparison across different stations, change point analysis etc. Those corrections are made and can be of either sign. If, additionally, they end up giving a better fit to the models, that adds to the confidence that the models are reasonable. – gavin]
I think most of the misunderstanding about all this comes from people always getting suspicious if anybody corrects measurements and/or feeds the measurements thru a statistical model rather than using the raw values. But with something like this, the raw values would probably not reveal anything usefull. Measuring the temperature in my garden at noon tells me how warm it was at 12 o’clock in my garden and nothing more. To derive a global trend from something like this, one has to correct for location, time of observation, kind of thermometer, wind and all sorts of other factors – or just drop the effort alltogether. How and based on what these calculations take place needs a solid understanding of the underlying physics, obviously, but in the end there’s no way around them. The fact that these corrections mostly seem to correct measurements closer towards modeled values could be explained either by the Rosenthal effect or the fact, that the models have it about right. I believe the Rosenthal effect is real but I can’t imagine it dominating climate science on such a scale.
I guess another possible explanation would be, that a particular (not necessarily correct) assumption in a model is at the same time used to correct measurements – but while this would be hard to detect on its own, it would probably only apply to a rather small subset of a bigger picture and would sooner or later stick out and lead to an improved understanding.
RE: 62
Hey Cobbly,
Here is the list of the measured ENSO history. As you can see the TAO/Triton measured values do not coincide with the ENSO lows that you express explanatory confidence in. http://www.cpc.noaa.gov/products/analysis_monitoring/ensostuff/ensoyears.shtml
Hence, I suspect we need a better explanation of why the period and variation in the data record does not appear to match up with the graph. This does not invalidate your observation, it only suggests that your observation is a partial explanation for the anomaly.
The most interesting thing is, when looking further back in the history there appears to be similar periods of deviation, though the the depth of the deviations do not match up even though the temperature deviation measures are similar. This would have a tendency to suggest there is likely multiple variables moving in the same direction at the same time.
Do you have any suggestions to explain the anomaly, I have offered mine…
Cheers!
Dave Cooke
Take a good look at the computer you used to type your blitheringly ignorant response. It is hundreds of thousands of times more powerful than the computing power available in the ENTIRE WORLD in 1945. The Manhattan Project did its modeling using rooms of people pulling handles on manual calculating machines, card sorters, etc. The first implosion models were two-dimensional because preliminary results for three-dimensional models took so long to calculate. Into the 1950s computers were still so slow and primitive that they could only provide limited insight fusion bomb design. And these were the super computers of the day.
So, to bounce your question back to you, why were airplanes designed without the benefit of the detailed aerodynamic modeling used to test today’s designs? Does the fact that the computing power didn’t exist somehow lead you to the conclusion that aerodynamic theory is all wrong?
As Gavin points out, modeling of climate and weather grew as computing power grew, as is true of modeling in every field you can think of, and it was a lot earlie than you imagine.
re 56.
A much more interesting paper is Robocks 1978 paper.
http://ams.allenpress.com/perlserv/?request=get-abstract&doi=10.1175%2F1520-0469(1978)035%3C1111:IAECCC%3E2.0.CO%3B2&ct=1
RE: 62 continued
Hey Cobbly,
I forgot to add that the comments I have been making do not relate to AGW or CC. The point of my posts were simply to demonstrate measure of the Oceanic Heat Content data sets within the ITCZ, for both the Pacific and Atlantic. To me it appears there is a conflict, with the long term data reconstructed in the reported study driving this thread, during the time frame of the TOA/Triton data set. Granted the TOA/Trition data set is small; however, it covers the greatest percentage change in the measured oceanic heat content known in recent history.
(That the heat content represented in the NOAA data sets are limited as to statistical confidence of between 58 to 89% this is not entirely unlike the current confidence level I would expect for the IPCC data sets related to AGW/CC.)
When I perform a side by side comparison of the data table and rotate the graphic in the original post relating to the Ocean Volume change in response to heat content graphic, the deviation of change in the graph looks relatively as expected up until the 1998/1999 time period. That the heat content was cooler longer should not have made the volume significantly lower. Hence the reason I suspect that there was likely a separate variable playing a part. Whether it was an after effect of Mt. Pinatubo or a massive heat release from overturing, transitional barrier salinity, clouds, storms, … Ad Nausium
The point being is the observation of a reduction in heat content was not limited to the Pacific; but, appeared to be Zonal for nearly 180 Deg. My research to date shows a low correlation for most of the more commonly suggested alternate variables. Hence, my consideration that the depth of the deviation may be related to a recent volcanic event, only that it took 7 years for it to be detected.
Does this help reduce the apparent miscommunication?
Cheers!
Dave Cooke
Alan Millar and Greg Smith, Now let me see if I’ve got this straight. You come in here with absolute ignorance of climate modeling and climate science and are ready to levy a charge of scientific fraud against the entire scientific community. That about right?
Realclimate is a wonderful resource for finding out how climate science acutally works. You can use it for that, or you can continue to make ignorant accusations. Your choice.
Re #60
“Ref #57 from GlenFergus “(but it’s younger and, presumably, thinner).” We have been through this before. Most of the ice that is currently turning into open ocean is what I call “annual ice”; ice which is, by definition less than one year old. Each year about 9 million sq kms of open ocean turn into ice, and each year about the same amount changes from ice into open ocean. This is “annual ice”. So far as I am aware, the thing that controls how much annual ice there is, and how thick it is, is the length and coldness of the winter. Last winter in the Arctic was, in comparison to recent years, long and cold. So one would not necessarily expect the current annual ice to be “thinner”. In any event, “thinner” than what?”
Than the multiyear ice it replaced since last year. Even during the last winter there was a loss of multiyear ice due to outflow through the Fram strait.
http://nsidc.org/images/arcticseaicenews/200804_Figure5.png
http://nsidc.org/images/arcticseaicenews/200804_Figure4.png
http://nsidc.org/arcticseaicenews/2008/040708.html
To see the flow out through the Fram checkout the Quikscat movie at the foot of this page:
http://ice-glaces.ec.gc.ca/App/WsvPageDsp.cfm?Lang=eng&lnid=43&ScndLvl=no&ID=11892
“hundreds of thousands” — Not enough. The MANIAC’s floating point division was so slow you could watch it on the front panel lights. On debugging technique was to tune an AM radio to static and then place in up by the multiplier circuits. If it didn’t sound right, you knew something went wrong, either the code of the physical computer.
Think billions.
That’s just per uni-core processor.
In all cases where the data does not match the model one modifies the data?
I think I learned in High School science class something about rejecting the theory instead of the data… but that’s so old school. I mean who rejects a hypothesis that everyone believes in anymore, that just downright 19th century.
[Response: Of course not. There are plenty of data that show that the models have problems (tropical rainfall, cloud distributions etc.) that are not going to change. But there are plenty of datasets where there are known problems. What would you have the people that produce them do? Not fix known problems? If there is still a a discrepancy with the model, you start again – is there a reason why the model could be wrong? are you comparing like with like? are there additional issues with the data product? – gavin]
#65 L David Cooke,
I think I get where you’re coming from.
You’re comparing 2 variables.
1) ENSO index – which is related to sea surface temperature.
http://www.cpc.noaa.gov/products/analysis_monitoring/ensostuff/ensoyears.shtml
2) Warm Water Pool volume West of Galapagos – which is related to the volume enclosed by the 20degC isotherm and the surface.
http://www.pmel.noaa.gov/tao/elnino/wwv/gif/wwv.gif
The reason these 2 indices don’t match up as you expect is what goes on at depth throughout the evolution of the El Nino event. Check out this graphic: http://www.pmel.noaa.gov/tao/elnino/nino_profiles.html
What’s happening is that in Spring 1998 the sea surface temperatures give a +ve ENSO index. However as seen in the above graphic, in March the the warm pool’s volume has decreased because the warm water has migrated to leave a much thinner warm pool. Hence the warm pool volume is decreasing in the early part of March even as the ENSO index shows it’s an El Nino.
Re 52,
The Temperate NH drought associated with a plinean eruption may be interesting. Just going back onto the issue of looking at temperature or some other variable in a small location. Here in the UK a significant part of the warming trend is due to atmospheric circulation changes not direct enhanced greenhouse effect. This is because changes in the winter Arctic Oscillation have caused a decline in the number of wintertime blocking highs from continental Europe blocking the jetstream. The blocking high pressure was a frequent British pattern in the winter, it brought colder continental/arctic air and the blocking stopped mild air from the Atlantic (jetstream deflection). The change in the AO behaviour is thought to be driven more by stratospheric cooling due mainly to the enhanced greenhouse effect. e.g. Shindell 1999 “Northern Hemisphere winter climate response to greenhouse gas, ozone, solar and volcanic forcing”. Google pubs.GISS Shindell et al. 1999 – you should find it in the top 3, free from GISS.
Plinean eruptions eject particulates into the stratosphere and whilst they cool the surface/troposphere by reducing incident sunlight. They warm the stratosphere by absorbing the light they don’t reflect. Such changes could well impact jetstream tracks, as the change in the Arctic Oscillation has impacted Britain. I’ve not read about it (as far as I can remember right now) but it sounds quite feasible.
The PIRATA data shows only 2 years which is way too short.
You almost certainly wouldn’t see anything looking at individual sites, it’s hard enough on land. But water has a specific heat capacity of 4.186 joule/gram degC.
10^22 j is 10,000,000,000,000,000,000,000.
Looks like a big number, until you consider it’s context.
Imagine how many grams there are in the ocean at down to 300 or 700 metres….
The Ocean surface is 169.2 million square kilometers (Wikipedia), that’s 169,200,000,000,000 square metres. A cubic metre of water is about 1 ton, which is 1,000,000 grams. So it takes 1 ton of water 4,186,000 joules to warm by 1 degC. I can’t factor in the depth profile, so I’m not going to calculate based on those figures. But see how fast all the zeros in 10^22 ballpark figure get eaten up.
10,000,000,000,000,000,000,000 joules is enough to warm the top 14 metres of the ocean’s surface area by a bit over 1 degree C. You’d have to allow for a bit of shallower water than that for the coasts, but ultimately when you factor in 300 or 700 metre depth you get a tiny temperature increase. The only way to find that amongst the noise of short term and local variance is by careful processing of masses of data.
re: #66 & #71
Historical correction:
In 1945, pretty much the total of electronic computers was: Atanasoff-Berry Computer, some Colossus machines at Bletchley Park, and the Harvard Mark I, ENIAC was just starting to come up, and its clock was 60-125KHz. It started with 20 words of memory, although it later acquired a 100-word core memory.
Hence, even an iPhone’s 620Mhz ARM CPU is about 5000-10000X higher in clock rate, better than that on performance, and vastly larger in memory.
MANIAC didn’t get turned on until 1952 [it was among the small batch of “open source” machines derived from John von Neumann’s plans, of which the only one left is JOHNNIAC, from RAND Corp.]
As for later dates:
1964: CDC 6600, first really successful supercomputer
Clock = 10Mhz, main memory = 256K (60-bit) words, call it 2MB.
1976: Cray-1, first really successful vector supercomputer; typically $8M or so.
Clock = 80Mhz, main memory = up to 1M 64-bit words, i.e., 8MB [huge!].
Any current laptop could easily beat it.
At the Computer history Museum, we have a tiny piece of a Colossus, one rack of the ENIAC, and the entire JOHNNIAC. [And for the next year, courtesy of Nathan Myrhvold, we have one of the two working mechanical Babbage Engines in the world, which is cranked daily, and must be seen to be appreciated.] Of course, we have a CDC 6600 and Cray-1 as well.
Anyway, it *was* possible to run a “large-scale” simulation in 1976, if by large-scale, someone means “fits in 8MB of memory, with processor much slower than laptop, and costs $8M.”
“1976: Cray-1, first really successful vector supercomputer; typically $8M or so.
Clock = 80Mhz, main memory = up to 1M 64-bit words, i.e., 8MB [huge!].
Any current laptop could easily beat it”
Even the iphone could beat it by a fairly wide margin. That doesn’t even take into account the fact the Cray 1 wasn’t available in the time frame we are talking about and was a huge jump in it’s time.
RE: 73
Hey Cobbly,
Actually, for the purpose of clarity I was using the table to define the period of occurrence of an El Nino pattern. It was not for comparative purposes. The comparison that I had intended, is between the ocean heat content of the study and the Pacific ocean heat content noted by the TOA/Triton system.
The original graphic was used to demonstrate the strong negative Heat Content spike that occurred between 1998 and 2000. The point I was attempting to make in 65 was the occurrence of the spike did coincide with an El Nino; however, the depth of the spike exceeded recent historic values.
Looking over the data set that was used in the study it would appear that the amplitude of the 1998-2000 cooling exceeded any prior data set which would suggest that El Nino alone must not have been responsible for the depth of the amplitude of the measured signal.
To me it would seem there is a high possibility that the additional variable for the spike has to be outside direct ENSO influence. I appreciate your preliminary analysis; however, your preliminary analysis should suggest for the deviation in amplitude noted there had to be a significant event that could have influenced the amplitude as measured. It appears it either had to be an equipment error or a very large phenomena. I imagine a reduction in insolation for a year would have played a part, though I do not know this for a fact.
That the heat content was demonstrated at a few of the initial long term PRIATA sites as well suggests that the cooling extended to bodies of water other then those that would be directly affected by an El Nino Wind or ocean current. The end result as I see it is the pattern noted in the study may have been mirrored in the TOA/Triton data set up until 1998; however, it appears to have diverged since then.
As to the introduction of the new subject regarding the normal winter time blocking anti-cyclonic that sets up NW of Ireland. On UKweatherworld I have tried to address the anti-cyclonic pattern that has been in absence recently, (having advanced to the Barents north of Norway for the 2004-2007 winter seasons). Last year was the first time that the normal pattern has set up in nearly 5 years, though it was still around a hundred miles north and further west then normal. The interesting thing I saw was the location of the pressure wave at the 250mb altitude and the surface phenomena that occurred both NW of Ireland and over Austria/Switzerland for the last three years. It almost appeared the upper level High split into two forming the two surface features with the same cold air pocket driving the two pressure centers.
The major difference I saw in the NCEP* data set was the location of a cyclonic pressure wave that appeared to take up residence at the Pole this past winter as opposed to a anti-cyclonic pressure wave of the past two years.
* http://nomads.ncdc.noaa.gov:9091/ncep/dates
“Chart Type: No Hemp 250MB Analysis Hgts_Isotachs Stn Plots”
and again the similar chart based on either 950mb or the surface.
Cheers!
Dave Cooke
Sea levels still seem to be a problem. Annual rise 1mm to 3mm depending on who is measuring. Accuracy for NASA Jason 3cm to 4cm. Note current falling sea level by NASA http://www.jpl.nasa.gov/images/jason/20080616/chart-browse.jpg
I am unclear on something.
I understand ENSO events to principally be redistributions of water of different temperature in the Pacific.
As a redistribution there should be no effect on overall global average sea level.
Is there some other process that is being posited? Escape of heat to the atmosphere or vice versa?
77 the problem seems to be open mindedness. Chaos is not easily anticipated. I would be more comfortable with responses that indicated uncertainty than certainty. Overconfidence is not a virtue predicting climate or weather.
Re 69 Ray This is what he actually said in the Reuters article if you had bothered to look
Fellow report author John Church said he had long been suspicious about the historical data because it did not match results from computer models of the world’s climate and oceans.
“We’ve realigned the observations and as a result the models agree with the observations much better than previously,” said Church, a senior research scientist with the climate centre.
“And so by comparing many XBT observations with research ship observations in a statistical way, you can estimate what the errors associated with the XBTs are.”
Maybe climatologists have a different set of glasses with which to look at data. If I did this in my profession I would be fired and rightly so
[Response: I hope that you are not in a profession that the public relies on – if you ignored known problems with your data and refused to deal with them, then you would deserve to be fired. – gavin]
#74 John Mashey:
CSIRAC, circa 1949, is a von Neumann machine, and is intact in a Museum in Melbourne. No longer goes, of course…
Paulidian, I’m not sure you were paying much attention in High School Science class. I teach first year university physics experimental technique. In one experiment my students test the equations of circular motion. It’s not uncommon for their results to disagree with these equations.
Rather than encouraging them to run from the room screaming “where’s my Nobel Prize” I tell them first to check their calculations, at which point most of the discrepancies disappear. In those cases where they don’t I suggest they review their experimental technique. Occasionally unexplained discrepancies remain, but usually they realise they were doing something wrong. If they have time to retake the data it’s usually much better.
It’s always possible that these 400 year old theories are wrong, but not even a first year student would seriously believe we would throw out the model based on a single set of data. In this case the data from the more accurate measuring devices fits well with the models. The data from the older, less accurate devices does not, so people have checked whether the older devices might have a systematic problem and no one is surprised to discover they do. When corrected both devices fit well with the models.
I am disappointed that the study only goes to 2004. It seems odd to cut off analysis at 2004 when the Lyman paper shows a cooling trend to 2005. Is there an explanation for such an arbitrary cut off point?
And even though vulcanism correlates with a few cooling inflection points, there are other cooling inflection points that lack volcanic explanations. At best it may explain 50% of the variation.
I am curious if people have read the recent article and could comment.
Greenland Ice Core Analysis Shows Drastic Climate Change Near End Of Last Ice Age
http://www.sciencedaily.com/releases/2008/06/080619142112.htm
“The ice core showed the Northern Hemisphere briefly emerged from the last ice age some 14,700 years ago with a 22-degree-Fahrenheit spike in just 50 years, then plunged back into icy conditions before abruptly warming again about 11,700 years ago.”
Such changes certainly do not seem to be the result of vulcanism or CO2. What energy source could create such changes? 22 degrees in 50 years makes the recent trend pale.
One very interresting part of the paper is the speculation that thermal expansion of the deep ocean (depth>700m) is the unknown contributor in the sea level rise budget (see fig3a, orange line in paper). To close the budget they pick a deep-ocean thermal expansion of 0.2 mm/yr (which corresponds to 0.2 W/m2 at 700m depth).
#76 L David Cooke,
With any event in the climate system it’s often impossible to be sure whether what you’re seeing is just the feature at hand (like an EN event), or whether there’s complication from other processes. However the 1998 EN was particularly intense (in terms of it’s impact on Global Temperatures) so it wouldn’t surprise me if it had a particularly intense impact upon the Warm Pool volume. There may be something else going on, but I haven’t the time to start searching journals for discussion of the ’98 EN event.
I wasn’t intending to introduce a new issue, merely to illustrate an analogous process that seems to support your suggestion of a link between of NH droughts and volcanic activity. With what’s going on in the Arctic we may (should) already see impacts on Northern Hemisphere synoptic patterns, my over-riding interest at present. I shall go and lurk over at UK Weatherworld to see what’s being said. But I prefer to rely on primary published research (as I’m all too aware I don’t know enough to start looking at raw met. data to try to find any impact).
Regards
Cobbly.
Dallas Tisdale (re #79), Uncertainty is an integral part of science–but it has to be quantified. This is invariabley done in studies of climate change. Within any reasonable level of uncertainty, anthropogenic causation of climate change is beyond doubt. Weather is indeed chaotic. Climate is not.
re: 83
“22 degrees in 50 years makes the recent trend pale.”
Of course, the scary thing is that the climate is capable of changing 22 degrees in 50 years. Were it to suddenly ramp up like that tomorrow, the world in 5 years would be dramatically different and in 50 years, we wouldn’t recognize it.
Greg Smith, I did indeed read the piece, and I find nothing wrong with applying a correction to data when I find a source of error. You are assuming that the data were corrected because they did not conform to theory. Were that the case, why would Church have “LONG been suspcious”? Rather, a discrepancy was found between data and model. Both sets of researchers went back and looked at the model and the data. The error was found in the data, not the model. It takes a pretty jaundiced and paranoid view of the scientific process to find anything there that is not above board. I think you need to go back and read over what was done and examine what it says about YOUR underlying attitudes. They reveal much more about you than they do about the scientific process.
Re gusbob @ 83: “What energy source could create such changes? 22 degrees in 50 years makes the recent trend pale.”
Yep, amazing what a relatively small change in insolation, plus a rapid change in albedo, plus a rapid change in atmospheric water vapour, CO2 and methane can do, isn’t it?
RE: #63 Why are climatologists always adjusting their data? How do they know in which direction to adjust them?
In order to compare the price of, say, gasoline in 1973 to the price in 2008, economists correct the 1973 values for inflation so they can report it in 2008 dollars. When civil engineers measure distances using a metal tape, they may have to correct their values for ambient temperature due to the thermal expansion or contraction of the tape. In the laboratory, very precise temperature measurements (e.g.,to the nearest 0.001 degree C) made with a glass thermometer have to be corrected by reference to calibration data specific to that thermometer to account for flaws in the glass capillary. To see the kinds of corrections oceanographers apply to ocean temperatures measured at sea, read this:
https://darchive.mblwhoilibrary.org/bitstream/1912/169/3/Nansen_Bottles.pdf
Failure to correct for a known bias would leave economists, engineers, and scientists, with data having limited utility.
Re: 63 & 90. Here’s another analogy. If I gave you copies of all the maps of part of the coastline for the last hundred years, and ask you to calculate local sea level changes from them over that time I think it would be very likely that you could refine your answer with successive attempts backed by increasing research into the map makers and their methods etc.
re:” #81 GlenFergus
Oops, forgot that one – thanks for the reminder.
However, just to be precise, there are von Neumann machines (most) and the tiny handful of them derived from his Princeton plans, and CSIRAC is one of the former, but not the latter, i.e., it was an independent effort.
I’m glad it has a safe home. If for some reason anyone wants to throw it away, and no one in Australia wants it, give us a call. [That’s how we got JOHNNIAC, rescued about a day before it was hauled away for junk, because an engineer who’d worked on it just happened to park in a back parking lot of the museum that was dumping it.]
In any case, this history is a reminder that people take a lot of compute power for granted, but it certainly didn’t didn’t exist in 1945, and even a 1976 Cray-1 wasn’t much in current terms.
For anyone interested in a readable introduction to the topic,
Smarr and Kauffman, Supercomputing and the Transformation of Science
is a little old, but pretty useful, and cheap on Amazon used.
Gary writes: “note currently falling …” and points to:
http://www.jpl.nasa.gov/images/jason/20080616/chart-browse.jpg
Gary, what is charted there and how long a time span do you need to assess whether there is a change in the trend? How do you know what you claim to see there? You’re not just following wiggles are you?
89# Jim Eager Says:
Yep, amazing what a relatively small change in insolation, plus a rapid change in albedo, plus a rapid change in atmospheric water vapour, CO2 and methane can do, isn’t it?
Did the authors attribute both the rapid rise and fall in temperatures to water vapor CO2 and methane? That seems unlikely due to observed lag times. Cahnes in inoslation would be my first suspect. They mentioned changing atmospheric circulation and I would think changing ocean oscillations and temperatures would contribute.
RE: 90
Hey Chuck,
I don’t know that it would limit the utility as much as it would limit the precision you could apply to the data set. Hence, part of the question that comes into play is how do scientists extend the precision so that it can be tied to the original instrument? A lack of understanding by many laymen can be linked to this question. The point being (at the risk of my being redundant), the question of trust. (Regardless that people use engineered bridges or work/live/travel in engineered structures everday. Seems they are willing to trust what they can see…)
I believe you have touched on one of the issues that I had and others have, when dealing with AGW/CC theories. When the level of precision cannot be confirmed for the data set and the analysis carried out falls outside of the precision limits, (IE: CC variation of 0.65 Deg C and raw measurement precisions of +/- 2 Degrees.
If you replace an instrument with a more precise measure it is usually important that the two run concurrently to insure the variation can be confirmed over the normal range of measurement. What makes it even more difficult is the measurement techniques that may have changed. Depending on the person, the reading of the value can have some level of subjectiveness. Hence, not only could a measure change because of an instrument change; but, also because of a change in the reader.
So beyond the technical bias aspects which affect the precision, as you suggest, we have confidence issues by some in regards to data set validity. Then we also have the additional issues that can be introduced when you add proxies where there could be multiple variables affecting the amplitude of an attribute. This does not mean that the science is faulty, only that we laymen may be ignorant of the protocols for the experiments and measurements used to establish the data sets.
Cheers!
Dave Cooke
gusbobb @ 83:
“Such changes certainly do not seem to be the result of vulcanism or CO2. What energy source could create such changes?”
Catastrophic release of methane from clathrate, perhaps. That would also nicely explain the short duration of the event.
It’s clear from a number of contributions here that what denialists want is a rule that errors in data can only be corrected if the correction leads to a worse fit between climate models and the data.
Gavin et al,
Question for you guys. It seems clear to me that adjustments made to raw surface data should [overall] adjust recent data down (or past data up) due to UHI. Yet every statistical audit of GISS and GHCN adjustments (that I can find so far) find them to do the exact opposite overall.
What are the contributors stronger than UHI that explain this? In simple terms. Thank you.
[Response: Not sure why you think this. The non-UHI corrected GISS analyses show a larger trend than the corrected product (See Hansen et al 2001). But there are UHCN corrections that are related to time-of-observation biases, location changes (city centre to airport for instance) that go the other way. – gavin]
RE: #63 & #90:
Corrections to observations are made without regard to the theory. Corrections are made to better reflect reality, whatever that reality happens to be. If the corrections turn out to better support the theory, that’s more evidence that the theory is correct.
Perhaps skeptics are confusing the actual making of the correction with the stimulus for investigating whether a correction is needed. The former is done without regard to theory. The latter often is prompted by mismatch to theory. There’s nothing at all wrong with that; it is the standard way that science in all fields is done.
Gavin I hope you (or other RC folks but you are the insider at NASA) will do some posts about the latest James Hansen testimony in congress. Rightly or wrongly, I think Hansen’s dramatic interpretations of the threats from AGW are going to be the key media “reference points” going forward.