What is the actual hypothesis you are testing when you compare a model to an observation? It is not a simple as ‘is the model any good’ – though many casual readers might assume so. Instead, it is a test of a whole set of assumptions that went into building the model, the forces driving it, and the assumptions that went in to what is presented as the observations. A mismatch between them can arise from a mis-specification of any of these components and climate science is full of examples where reported mismatches ended up being due to problems in the observations or forcing functions rather than the models (ice age tropical ocean temperatures, the MSU records etc.). Conversely of course, there are clear cases where the models are wrong (the double ITCZ problem) and where the search for which assumptions in the model are responsible is ongoing.
As we have discussed, there is a skill required in comparing models to observations in ways that are most productive, and that requires a certain familiarity with the history of climate and weather models. For instance, it is well known that the individual trajectory of the weather is chaotic (in models this is provable; in the real world, just very likely) and unpredictable after a couple of weeks. So comparing the real weather at a point with a model simulation outside of a weather forecast context is not going to be useful. You can see this by specifying exactly what the hypothesis is you are testing in performing such a comparison in a climate model – i.e. “is a model’s individual weather correlated to the weather in the real world (given the assumptions of the model and no input of actual weather data)”. There will be a mismatch between model and observation, but nothing of interest will have been learnt because we already know that the weather in the model is chaotic.
Hypotheses are much more useful if you expect that there will be a match; a mismatch is then much more surprising. Your expectations are driven by past experience and are informed by a basic understanding of the physics. For instance, given the physics of sulphate aerosols in the stratosphere (short wave reflectors, long wave absorbers), it would be surprising if putting in the aerosols seen during the Pinatubo eruption did not reduce the planetary temperature while warming the stratosphere in the model. Which it does. Doing such an experiments is much more a test of the quantitative impacts then, rather than the qualitative response.
With that in mind, I now turn to the latest paper that is getting the inactivists excited by Demetris Koutsoyiannis and colleagues. There are very clearly two parts to this paper – the first is a poor summary of the practice of climate modelling – touching all the recent contrarian talking points (global cooling, Douglass et al, Karl Popper etc.) but is not worth dealing with in detail (the reviewers of the paper include Willie Soon, Pat Frank and Larry Gould (of Monckton/APS fame) – so no guessing needed for where they get their misconceptions). This is however just a distraction (though I’d recommend to the authors to leave out this kind of nonsense in future if they want to be taken seriously in the wider field). The second part is their actual analysis, the results of which lead them to conclude that “models perform poorly”, and is more interesting in conception, if not in execution.
Koutsoyiannis and his colleagues are hydrologists by background and have an interest in what is called long term persistence (LTP or long term memory) in time series (discussed previously here). This is often quantified by the Hurst parameter (nicely explained by tamino recently). A Hurst value of greater than 0.5 is indicative of ‘long range persistence’ and complicates issues of calculating trend uncertainties and the like. Many natural time series do show more persistent ‘memory’ than a simple auto-regression (AR) process – in particularly (and classically) river outflows. This makes physical sense because a watershed is much more complicated than just a damper of higher frequency inputs. Soil moisture can have an impact from year to year, as can various groundwater reservoirs and their interactions.
It’s important to realise that there is nothing magic about processes with long term persistence. This is simply a property that complex systems – like the climate – will exhibit in certain circumstances. However, like all statistical models that do not reflect the real underlying physics of a situation, assuming a form of LTP – a constant Hurst parameter for instance, is simply an assumption that may or may not be useful. Much more interesting is whether there is a match between the kinds of statistical properties seen in the real world and what is seen in the models (see below).
So what did Koutsoyiannis et al do? They took a small number of long station records and compared them to co-located grid points in single realisations of a few models and correlate their annual and longer term means. Returning to the question we asked at the top, what hypothesis is being tested here? They are using single realisations of model runs, and so they are not testing the forced component of the response (which can only be determined using ensembles or very long simulations). By correlating at the annual and other short term periods they are effectively comparing the weather in the real world with that in a model. Even without looking at their results, it is obvious that this is not going to match (since weather is uncorrelated in one realisation to another, let alone in the real world). Furthermore, by using only one to four grid boxes for their comparisons, even the longer term (30 year) forced trends are not going to come out of the noise.
Remember that the magnitude of annual, interannual and decadal variability increases substantially as spatial scales go from global, hemispheric, continental, regional to local. The IPCC report for instance is very clear in stating that the detection and attribution of climate changes is only clearly possible at continental scales and above. Note also that K et al compare absolute temperatures rather than anomalies. This isn’t a terrible idea, but single grid points have offsets to a co-located station for any number of reasons – mean altitude, un-resolved micro-climate effects, systematic but stable biases in planetary wave patterns etc. – and anomaly comparison are generally preferred since they can correct for these oft-times irrelevant effects. Finally (and surprisingly given the attention being paid to it in various circles), K et al do not consider whether any of their selected stations might have any artifacts within them that might effect their statistical properties.
Therefore, it comes as no surprise at all that K and colleagues find poor matches in their comparisons. The answer to their effective question – are very local single realisations of weather coherent across observations and models? – is no, as anyone would have concluded from reading the IPCC report or the existing literature. This is why no one uses (or should be using) single grid points from single models in any kind of future impact study. Indeed, it is the reason why regional downscaling approaches exist at all. The most effective downscaling approaches use the statistical correlations of local weather to larger scale patterns and use model projections for those patterns to estimate changes in local weather regimes. Alternatively, one can use a regional model embedded within a global model. Either way, no-one uses single grid boxes.
What might K et al have done that would have been more interesting and still relevant to their stated concerns? Well, as we stated above, comparing statistical properties in the models to the real world is very relevant. Do the models exhibit LTP? Is there spatial structure to the derived Hurst coefficients? What is the predictability of Hurst at single grid boxes even within models? Of course, some work has already been done on this.
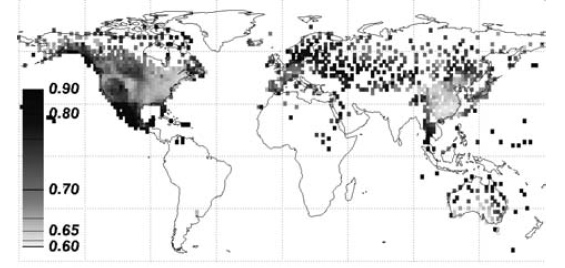 For instance, Kiraly et al (2006, Tellus) calculated Hurst exponents for the entire database of weather stations and show that there is indeed significant structure (and some uncertainty in the estimates) in different climate regimes. In the US, there is a clear difference between the West Coast, Mountain States, and Eastern half. Areas downstream of the North Atlantic appear to have particular high Hurst values.
For instance, Kiraly et al (2006, Tellus) calculated Hurst exponents for the entire database of weather stations and show that there is indeed significant structure (and some uncertainty in the estimates) in different climate regimes. In the US, there is a clear difference between the West Coast, Mountain States, and Eastern half. Areas downstream of the North Atlantic appear to have particular high Hurst values.
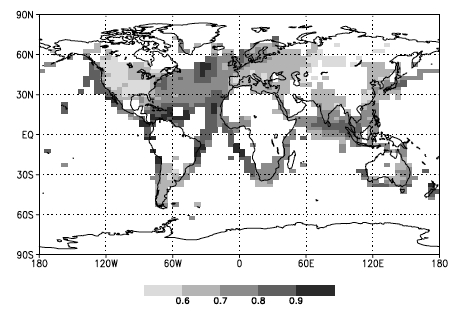 Other analyses show similar patterns (in this case, from Fraedrich and Blender (2003) who used the gridded datasets from 1900 onwards), though there is enough differences with the first picture that it’s probably worth investigating methodological issues in these calculations. What do you get in models? Well in very long simulations that provide enough data to estimate Hurst exponents quite accurately, the answer is mostly something similar.
Other analyses show similar patterns (in this case, from Fraedrich and Blender (2003) who used the gridded datasets from 1900 onwards), though there is enough differences with the first picture that it’s probably worth investigating methodological issues in these calculations. What do you get in models? Well in very long simulations that provide enough data to estimate Hurst exponents quite accurately, the answer is mostly something similar.
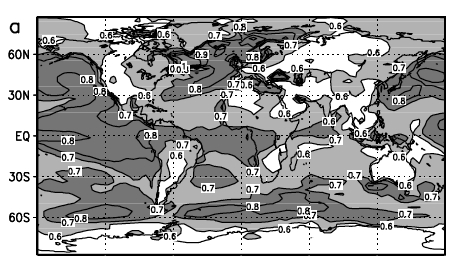 The precise patterns do vary as a function of frequency ranges (i.e. the exponents in the interannual to multi-decadal band are different to those over longer periods), and there are differences between models. This is one example from Blender et al (2006, GRL) which shows the basic pattern though. Very high Hurst exponents over the parts of the ocean with known multi-decadal variability (North Atlantic for instance), and smaller values over land.
The precise patterns do vary as a function of frequency ranges (i.e. the exponents in the interannual to multi-decadal band are different to those over longer periods), and there are differences between models. This is one example from Blender et al (2006, GRL) which shows the basic pattern though. Very high Hurst exponents over the parts of the ocean with known multi-decadal variability (North Atlantic for instance), and smaller values over land.
However, I’m not aware of any analyses of these issues for models in the AR4 database, and so that would certainly be an interesting study. Given the short period of the records are the observational estimates of the Hurst exponents stable enough to be used as a test for the models? Do the models suggest that 100-year estimates of these parameters are robust? (this is testable using different realisations in an ensemble). Are there sufficient differences between the models to allow us to say something about the realism of their multi-decadal variability?
Answering any of these questions would have moved the science forward – it’s a shame Koutsoyiannis et al addressed a question whose answer was obvious and well known ahead of time instead.
#98 I tried to explain this on another thread. Uncertainties, errors, small differences in initial conditions propagate, yes – but only up to a point. As unpredictable weather integrates over time to become predictable climate, the law of large numbers kicks in and all those errors in all those grid cells, all those processes, start canceling. Radiative balance severely constrains how the system may evolve, what states it may take on. That is why Eric’s (and Pat Frank’s) argument is incorrect.
Of course the numerous local departures from equilibrium don’t cancel completely (due to all the temporal and spatial process lags) so you are left with the internal climate variability that is revealed to us as ENSO, PDO, NAO, THC, etc.
That is why you need 1000s of data “points” (or better, grid cells) – not 8 – to reliably test model predictive power. Because with too small a time and space scale you are dealing with weather, not climate.
Mark (96) — Actually, the first flip of the coin is worth about 0.03 bits of information.
Ray #95 thanks for responding it does make sense I appreciate it’s not a one-run linear model set up – forgive me if I don’t respond further now as it’s late in europeland! I will aggregate the various initial conditions conditions and respond tomorrow…
In comment #36, Steve E. says in part:” The computational models have an interesting status in this endeavour: they seem to be used primarily for hypothesis testing, rather than for forecasting. A large part of the time, climate scientists are “tinkering” with the models, probing their weaknesses, measuring uncertainty, identifying which components contribute to errors, looking for ways to improve them, etc. But the public generally only sees the bit where the models are used to make long term IPCC-style predictions.”
Unfortunately there’s a general misconception among the public that models make predictions. My understanding is that the digital models make projections of possible future outcomes, dependent on measureable data,known physical principles and numerous uncertain and hard to predict variables.
They don’t forecast the future as much as tell what we can likely expect from given scenarios,which include human social and economic behavior. (Although Hansen’s Scenario B in his three projected climate model scenarios of surface temperatures made in 1988, sure looks as if he had a crystal ball!)
#95 Ray Ladbury says:
“Actually, you are more interested in the behavior that persists across various initial conditions and in spite of fluctuations. You are also interested in the RANGE of behaviors. The results of any single run are not that interesting. That’s why the paper is so baffling.”
This viewpoint is what is baffling. The authors should have used multiple runs of FIXED initial conditions. The inline reply to #67 makes it clear why this, though desirable, is unfortunately not possible. So although I agree you are interested in the range of behaviors, and you are interested in ensemble behavior, you are NOT interested in behavior across various initial conditions. If your goal is to compare model output to reality, that is.
Studying model behavior across a range of initial conditions is useful, but answers a different question than what this paper tried to address.
Which would be what the models predict given a fixed, known-wrong, set of initial conditions?
Wow, that’s really going to tell us a lot.
What Koutsoyiannis et. al seem to be upset about is the use of output from global climate models to make hydrological predictions. So, here is another example of just that: a paper on the Western U.S. snowpack that compares historical temperature and precipitation observations to hydrology. The authors use the output of global climate models to make general projections about the future of the snowpack:
http://sciencepolicy.colorado.edu/admin/publication_files/resource-1699-2005.06.pdf
Mote et .al (2005) DECLINING MOUNTAIN SNOWPACK IN WESTERN NORTH AMERICA, Bulletin of the American Meteorological Society, vol. 86, Issue 1, pp.39-49
Instead of data from eight locations, we have:
The t/p data was fed into the VIC hydrology model, which produced estimates of snowpack, which were then compared to the observed snowpack record, with a close match. Thus, Mote et al show that the VIC model, when forced with historical temperature and precipitation records, gives a decent match to observed snowpack records. If a global or regional climate model produces a given temperature/precipitation forecast, the VIC model should produce a realistic estimate of snowpack based on that.
Mote et al also discuss the influence of El Nino and PDO indices on the year-to-year variability in precipitation (the long-term memory issue):
Then, they use global climate model projections to predict future trends, which is what K et. al claim is unjustified:
So, here is what Koutsoyiannis et. al can do: take the ~400 locations used in Mote et. al and compare that historical dataset to predictions of global climate models for that region. That would allow them to at least address their stated question, which was, quote, “the credibility of the geographically distributed representation of climate by GCMs.”
The model for doing that could be Salathe 2005, available here: http://cat.inist.fr/?aModele=afficheN&cpsidt=16653268
For more, just read Chapter 11 of the IPCC FAR, Regional Climate Predictions, which goes into great detail on the sources of regional uncertainty in climate models.
After looking at these observations and models, what would the rational response for denizens of the Western U.S.? Well, first, stop burning coal. Second, include the reality of water scarcity in any future growth planning. Third, start investing in solar and wind energy to replace the coal.
Speaking of which, our wonderful Congress has failed yet again to pass the renewable energy tax credit, thereby bringing the entire industry to a grinding halt, with companies racing to finish all projects in a few months. Shamelessly, the Senate Energy committee has also been hosting a fight over what sector of the coal industry will receive billion-dollar DOE largess, and what district that largess will go to (the May 8th hearings featuring Bodman & Thompson). Must be seen to be believed… http://appropriations.senate.gov/hearings.cfm?s=erg
Opening quote (Byron Dorgan, ND): “…with 50% of the electricity coming from coal, and with climate change legislation being enacted calling for targets and timetables and so on, how do we continue to use our coal resource? The answer to that is through technology, and through learning, and through demonstration projects and going from demonstration to commercial application of projects that will capture carbon…”
In 2006, the U.S. dug up and burned 1.054 billion tons of coal, resulting in CO2 emissions of 2.134 billion tons (Energy Information Administration). The claim that we will be capturing and storing any meaningful fraction of the carbon dioxide produced from burning that coal (every year, no less) is just ludicrous nonsense.
Solar and wind-based technology is the only real answer. For something more positive, see the latest major breakthrough in solar energy conversion technology: http://www.sciencedaily.com/releases/2008/07/080731143345.htm
‘Major Discovery’ Primed To Unleash Solar Revolution: Scientists Mimic Essence Of Plants’ Energy Storage System, Aug 01, MIT
Richar, #105
No, if we were running a physical experiment, we would use the same initial conditions. Reality and the finite ability to be accurate in the real world will do the fuzzing.
In a mathematical model, however, the same number put through the same equation will always produce the same value.
So running an equation through multiple times will produce the same result.
David #102, what use is 0.03 bits of information when you need a yes or no answer?
Rather like having a half-penny when you are shopping. Technically you’re not broke. You have a half-penny. You can’t spend it, which is the point of money. So are you broke?
And it’s really less than that, because the coin could do a lot more than “fall heads” or “fall tails”. You could drop it, it could land its edge, someone could steal it midair, you could give up and walk away…
Richard Sycamore, Sorry, in the interest of brevity, I was probably less specific than I should have been. Actually both studies are interesting, but they tell you different things. We are certainly interested in multiple runs with the same starting conditions–that tells you how much fluctuations affect the end result. However, we never have perfect knowledge of initial conditions, so varying the initial conditions is also interesting. Frankly, I am uncertain what question K. et al. could possibly have been trying to answer. Their approach makes no sense unless you want to use GCMs for long-term weather prediction–and that’s not an enterprise I’d bet on.
Thanks for #110, Ray. Replies directly to #106.
You say:
“Their approach makes no sense unless you want to use GCMs for long-term weather prediction”
Your distinction between “weather” and “climate” is traditional and understandable, but is it verging on dogmatic? Ocean tempeartures vary hugely, but on slow, “climatic” time scales. I would contend that “long-term weather prediction” is exactly what the AOGCMs do, if by “weather” you take to mean the chaotic dynamics of “O” in the AOGCM.
So maybe their approach DOES make sense, when viewed from a different perspective.
Richard, you’re entitled to your own opinions, but when you apply your own definitions to support them, your ideas become disconnected from the subject under discussion and fly off tangentially.
If you redefine climate as weather, then, yes, climate is the same as weather. This is a perspective, but I shudder to think of the contortions required to view their paper from that perspective. Ouch!
“Contrariwise, if it was so, it might be; and if it were so, it would be; but as it isn’t, it ain’t. That’s logic.” — Lewis Carroll
Richard, Individual runs are not completely uninteresting. If they exhibit extreme behavior, one can try to figure out why. Those that cluster around median behavior give an idea of what sorts or perturbations the system is stable to. There is no reason to expect any single run to correspond to anything in the real world, though, so K. et al.’s approach is misguided. It’s a little like doing a Monte Carlo run. Individual runs will be more of interest in telling you about the model than about the system you are trying to model, but take enough runs and you will elucidate the physics of the system.
#113 “take enough runs and you will elucidate the physics of the system”
Take enough runs and you will elucidate the *conjectured* physics of the system.
Otherwise, agreed.
#112 Sit back, be patient, and maybe you’ll learn something.
Richard 114
What’s the difference?
Physics is not equal to the reality.
But they either conform to as good as we can read our instruments TO reality.
So although we “conjecture” that gravity acts as per Newtonian physics (while gravity isn’t listening: it’s too busy being gravity), this IS the “physics of the system”.
And what the clucking bell was your “sit back” comment apart from hugely offensive and derogatory?
Weather is NOT CLIMATE.
We have
Weather: what we are getting THIS INSTANT. Hugely variable.
Seasons: Winter will generally be colder than Summer
Climate: In an ice age it will be colder than an interglacial
But even in a climatic ice age, we still have summer (which is still warmer than winter) and we still have weather that can, on any particular day, be warmer than a day in another season.
If you shut your yap and THOUGHT maybe you’d learn something.
#115
“what the clucking bell was your “sit back” comment apart from hugely offensive and derogatory?”
I meant sit back and learn something from Gavin, not me. I was asking Hank to please stop getting in the way all the time. I want Gavin to clarify where weather stops and climate starts, and how this relates to the characteristic time scales of ocean fluid dynamics. How this might relate to the title of the opening post.
“If you shut your yap and THOUGHT maybe you’d learn something.”
I’m all ears, thinking cap on, ready to learn. Please, proceed.
My captcha phrase is “Gavin suffer”. That’s ptrobably a bad sign.
Richard, Where climate starts and weather stops is not a particularly productive way of looking at things.
It is a little like asking when the microworld stops being quantum, or when you can’t do physics without relativity. The answer is going to vary depending on the phenomenon being discussed. In the case of climate, it depends on how the noise diminishes over time. Gavin and Raypierre have both emphasized that there are many different timescales to climate–even with respect to the oceanic interactions.
> stop
Delighted.
Richard, How about this as a suggested definition of the timescale of climate? A climatic trend emerges at a confidence level CL on a timescale such that the proportion two series of climate model runs–one possessing the trend, the other not–the proportion of runs with the trend that clearly exhibit it is CL and the proportion of runs without the trend that appear to exhibit is 1-CL. Of course it likely means that different climatic trends will have different timescales, and it makes the timescale dependent on CL the desired confidence level, but I think it makes sense.
The topic is “hypothesis testing and long-range memory”. Where weather stops and climate starts is, in fact, the issue – insofar as “weather noise” may become “climatic noise” if it persists long enough. It is the issue that eminent hydrologists such as Dr. Koutsoyiannis are exploring in papers such as this one. Rather than dismiss the paper as being methodologically flawed, why don’t you ask yourselves what he is trying to get at? You have been trying to sweep this issue of weather vs. climate under the rug, saying “it doesn’t matter”, or “it isn’t helpful to look at it that way”, or providing inexpert definitions in terms of expectation vs. realization. But I am very glad to say that Ray has thought about it overnight and has come back with an attempt at a potentially workable definition. It shows perhaps you understand that this may be an important issue after all. I will think about Ray’s definition, whether I agree with it and what it’s implications are. Thank you, Ray, for listening and trying to address my question.
Re: #120 (Richard Sycamore)
The only one trying to “sweep this issue of weather vs. climate under the rug” is Koutsoyiannis. That’s one of the points of this post.
Richard, remember, I am hardly an expert. I’m just thinking about this from my own experience with modeling complex systems–also not unlimited. In the case of climate you are looking at a time series that is affected by many factors, but factors such as CO2 stand out because while not as large as other factors, they are persistently positive. Over time, since there are not many such signals, particularly that are changing, they will emerge from the noise–how rapidly depends on how many other influences there are and their time dependence.
Isn’t the difference between weather and climate much simpler than that? Like in, climate is forced, weather unforced variability. The latter being completely removable by ensemble averaging. And completely unpredictable over more than a few years (and that only for the ocean related stuff).
When studying climate, weather is the noise. There is no ‘climate noise’ then.
No, this doesn’t help for empirical separation of the two; for that, Ray’s approach may have a point.
Martin, At the risk of being a pain, what do we really mean by “unforced variability”? Isn’t that effectively saying that there are many forcers acting on a nonlinear system on that timescale, so deterministic predictions are not possible? I mean, at some level, even weather events are “forced” in that they have a proximate cause, even if it is altered by a butterfly flapping its wings in the Amazon.
Well I can’t build models using math, but my 30 year old pear trees, were a close run thing to establish (one died back to the ground) and used to bear at the very end of September/early October and I had to beat the storms to pick the fruit. Now, here in Duluth Mn, I can start picking today. No matter the quibbles, my pear trees attest to the general accuracy of the models.
Ray:
https://www.realclimate.org/index.php/archives/2005/09/what-is-a-first-order-climate-forcing/
“… It is helpful to distinguish forcings that are important in the global mean, from those which might be important locally but not have much impact for ‘global warming’….”
See a statistical distribution of balls in a Pachinko machine.
Then the entire mechanism loses its level, two legs tilt the level to one side, and if one leg was lower then the entire table would be out of level and violently tipping.
Fortunately, the Pachinko machine sits atop another Pachinko machine.
It’s Pachinko machines all the way down.
Ray,
not quite. Yes, I mean variability that would happen anyway even if all external forcings were strictly constant. And yes it is the chaotic, “fading memory” part of variability.
Whether you can say that weather events have a proximate cause, I suppose formally so. But that is not a “forcing”, it’s an initial condition. As a metaphor think of an ODE: the forcing is the F(t) on the right side, what makes the solution different from the homogeneous solution. The complication here is that there isn’t just one solution but a whole bundle of them, even for a strictly prescribed external forcing regime. Due to the chaoticness, prescribing initial conditions will help only for a limited time.
I am having great difficulty with the expression “internal forcing” used by some.
Hank, Thanks for the vector. When we talk about climate, though, we are not necessarily talking about something “global”. Climatic effects manifest at all scales. Richard had asked when “weather” becomes “climate”, and I am trying to say that that isn’t really the best way to look at it. Weather and climate are two different attributes of the same Land-Water-Atmosphere system. On short timescales, the behavior of the system is dominated by weather, which is chaotic, while on longer timescales (how long depends on the particuar climatic trend under discussion) climate trumps weather. Climate seems to not be chaotic–its behavior being determined largely by energy balance. Maybe the way to look at this is not so much that climate is “average weather” as to say that once you average out weather effects, climate manifests.
when “weather” becomes “climate”
When does the boy become the man?
When you die, when does death arrive?
When does the embryo become a baby?
where does life begin?
Yes, precisely. With the interesting difference that with climate models you can do “ensemble averaging”. With the real thing you’re stuck with climate plus a single instance of weather. Then you can only rely on long enough time series, and even then it will never be perfect.
Ray, just pointing out, from the original post:
> There are very clearly two parts to this paper – the
> first is a poor summary of the practice of climate modelling
> …. This is however just a distraction …. The second part
> is their actual analysis, the results of which lead them
> to conclude that “models perform poorly” …
Didn’t want to lose the focus or end up getting turned around.
Mark #130: not even wrong ;-)
tamino Says: “Estimating the Hurst parameter from observed data is very tricky business.”
Unpublished work of mine from the early 1990’s confirms this. There was a whole bunch of interest in whether financial markets exhibited long time behavior, and if so, how to estimate it.
There are lots and lots of problems with empirical observation of fractals, although in fluid dynamics the example of the Kolmogorov-Obukhov scaling of homogeneous turbulence does provide a useful example – there are actually three regimes that can be observed – the molecular diffusion regime (Heisenberg’s Ph. D. dissertation, actually), the 3-D inertial regime (Kolmogorov-Obukhov), and then the 2-D inertial regime, where, if you have a big enough box of fluid, it stops looking like a 3-D box and more like a 2-D shell.
If you look at a plot of the log of the energy in the flow against the log of the wavenumber (or wavelength), then in principle you can see the three straight-ish line segments, and the three slopes are pretty well explained by the scaling theory. So you have in some sense a successful fractal theory – over the right window of scales, you get the predicted scaling.
The problem is that in fact you have three unsuccessful fractal theories – because they only hold over a range of scales before the physics in the other regimes takes over. And the limited window of scales may or may not be enough to get good estimates of the scaling. Of course, you can might around this issue if you have many replications of the experiment – with enough realizations you can do lots of things. So in the lab, it’s really just a problem of experimental design to see if you can tease out the scaling.
And now, another problem. Back in the early 1980’s, Chuck Leith had found in the literature about twenty different explanations of the Kolmogorov-Obukhov scaling exponent, many of them mutually contradictory. I don’t know if in the intervening years more of these explanations have arisen, although to some extent the Yakhot-Orszag theory should have consolidated things a bit. So in the case that you careful enough to verify the scaling exponent, the next question is which “theory” did you verify? A good idea for people that want to go around fitting fractal explanations to observed data is to have a good reason to believe that they are excluding something.
But there is a good reason to believe that lots of scaling explanations lurk around every corner – probably the first to draw attention to the abundance of fractal approximations was Michael Barnsley who even wrote a book “Fractals Everywhere” about the ubiquity of scaling representations of, well, everything. And it is not just that there is one scaling representation of some arbitrary bunch of data, there have to be many different ones; (consider the fractal compression of an image, or of any slight distortion of that image – you can think of this as lots of different scaling explanations for the original image).
An experiment that most people here could do on whatever computer they are using to read this, would be to generate a bunch of points in a plane by their favorite fractal; now embed that plane in three dimensions on a smooth surface. Now compute the fractal dimension of those points. Topologically, the fractal dimension should be the same. Well go measure it; is it the same? (Good luck getting the number to come out the same…)
So yeah, you can stick data into an algorithm and get Hurst exponents, or any number of other scaling parameters. But as tamino points out, there are a lot of other values for these scaling parameters which are also very close to the observed data. A surprisingly small perturbation is usually all it takes to completely derange the estimates of scaling.
And of course we haven’t even started to bring intermittency into the question.
Based on what’s been said here, I understand that if you look at the weather over a spatial scale which is less than, say, 1000 km, and/or over a time scale which is less than, say, 30 years, it’s extremely unlikely that you’re seeing the CO2 “signal” and not the random “noise”.
In fact, every day in the press there are stories about how the change in weather in some small region, over the course of a couple decades or less, is due to global warming.
Will this blog join me in denouncing such stories as inaccurate?
[Response: depends on the case and on whether there is a larger scale and longer time period context. But we’ve said over and again, that short term weather events are difficult to impossible to attribute to climate change. – gavin]
re # 130 Mark wrote: “when “weather” becomes “climate””
Hmmm, I don’t know what you mean. Climate is usually defined as 30-50 years mininum averages according to the IPCC and the WMO…and has been for quite some time.
Richard, #130.
It was a response to elicit rational though as to why asking (or even trying to draw a line between) the difference between climate and weather. As per Richard Sycamore and alluded to by Ray’s comment #129.
The answer, like the other analogues I used, depends on what you define as climate and what you define as weather (with the middle state, what do you define as seasonal, but that also depends on where you are on the planet too). In fact, to draw a line is completely wrong. As they are with the analogues. There’s a point at which IT really is and another point, maybe a long way off, where IT really isn’t.
And it really isn’t “weather” when you average over 30 years.
It really isn’t climate when you average over a year.
But that’s what Richard is trying to do. Get us to draw a line where one side is weather and one side is climate. And if we don’t define one, he’s going to do it himself and show that the other side of the line is also weather, hence
weather == climate
However, if you aren’t good at setting an argument, this may have been a bit too subtle for you.
;-)
The time period necessary to find climate could vary with different purposes. A bacteria that divides every 20 minutes might (were it not a bacteria :) ) have the perspective that a snow storm is an ice age and each snowflake is a weather event. A rock might think of each ice age as a weather event A craton might see ice house and hot house conditions as being weather events, as well as the individual comings and goings of supercontinents (manifestation of mantle weather), although over billions of years these may form a climate, or if the mantle climate changes to fast to find it in a single instance, one could comb the universe for similar planets to get more data (like an ensemble of model runs) etc…. As the time scale lengthens, some factors that could be considered external forcings start to become more dependent on the system itself.
Climate is the average of all things about the weather, not just a simple average. It’s the average of the standard deviation. It’s the average of the shape of the statistical distribution. It’s the average of the standard deviation of the shape of the statistical distribution. It’s the average of the shape of the distribution of the variations of the shape of the distribution… of every variable, which is the Temperature, wind, etc, at every point in the system at every moment in time. Luckily all these things don’t vary completely independently of each other, so even a single number like average global surface temperature has at least some important meaning.
A single glacier’s retreat over a year may be enhanced by global warming, a single glacier’s growth may be reduced by global warming, – depending on expected regional effects. But it’s hard to know just how much, because global warming isn’t just hidden in shorter-term weather noise, it may have an effect on that weather noise. But when many many glaciers, most of them over much of the globe, have a longer term trend, of a size and persistence that natural variability isn’t expected to cause, and that forced global warming can account for, than it can be evidence of that forced global warming working at least in some way as expected, and each individual glacier’s change over any small time period contributes to the statistics, and in that way is a part of it.
I have used the term ‘internal radiative forcing’ but I use it in single quotes as I have just done. In the forcing/feedback dichotomy it’s a feedback, an aspect of the internal variability. I think a possible source of confusion is that radiative feedbacks are sometimes named as radiative forcings – ie the water vapor feedback has a radiative forcing of … etc. On the time scales of ice ages, CO2 and ice sheets are feedbacks but they can be discussed as having radiative forcings even in that context (whereas even for low-frequency variability (interannual to intraseasonal), water vapor and cloud feedbacks (PS includes weather-dependent aspects of how clouds would respond to aerosols, but not including changes caused by changes in aerosols themselves) are so much more rapid that they are still feedbacks). In the context of change, forcing may be defined as relative to some baseline – preindustrial CO2 concentration, for example. Yet in an investigation of the total greenhouse effect (for an equilibrium climate, no time dependence), one might tally up the ‘radiative forcings’ of each agent, including clouds and water vapor (but watch out for the overlaps – order of adding greenhouse agents affects the individual contributions but leaves the total the same). I’m not sure if such use of the term forcing (for water vapor and clouds in particular) is technically wrong or not, but it’s really not confusing at all if you know what’s being discussed; you can tell what is meant from the context. (But for the sake of the ‘average’ person who doesn’t have time to study the science in any detail, it’s obviously more important to use precise terminology or otherwise explain the context.)
Gavin (135), I appreciate and respect your comment, “…short term weather events are difficult to impossible to attribute to climate change…” and do recall your saying that many times before. But to be accurate, in deference to Steve’s comment, you should not be so loose with your term “we.” It probably applies to most if not all of the RC moderators (if that is what you meant, never mind this post), but can not include most AGWer posters who can inundate us with localized “proofs” of GW.
[Response: Who are these people? I find myself inundated with requests to condemn exaggerations on an almost daily basis, only to find that no-one ever said any of the things the accusers are complaining about. So, here is a new rule. Instead of demanding restatements of generalities which we have made clear over and again (and by we in mean not only the RC contributors, but also the authors of the IPCC reports and 99% of the field), how about actually linking to these people and comments you are being inundated with? I’m happy to discuss case by case assertions where there is an actual statement to be discussed, rather than say, some nonsensical interpretation on a blogger. – gavin]
Richard Sycamore & others may care to read W.F. Ruddiman’s “Earth’s Climate: Past and Future” for the perspective offered of climate timescales.
Here’s what NOAA has to say about weather and climate:
“Climate – The average of weather over at least a 30-year period. Note that the climate taken over different periods of time (30 years, 1000 years) may be different. The old saying is climate is what we expect and weather is what we get.”
And about climate change:
“Climate Change – A non-random change in climate that is measured over several decades or longer. The change may be due to natural or human-induced causes.”
http://www.cpc.noaa.gov/products/outreach/glossary.shtml#C
Re: myself:
“because global warming isn’t just hidden in shorter-term weather noise, it may have an effect on that weather noise.”
… individual bits of noise are weather but the noise overall may have a ‘texture’ that is an aspect of some climate.
“It’s the average of the shape of the distribution of the variations of the shape of the distribution… of every variable,”
… and any number of derived quantities, like the temperature gradient, the temporal relationships of weather patterns or low frequency variability, the average frequency of ENSO fluctuations, the correlation of A and B in time and/or space…
“one could comb the universe for similar planets to get more data (like an ensemble of model runs)”
… being careful to note the variation among the population and note relationships between variation in behavior to variation in the population…
Gavin (139), just to clarify, you can’t possibly read and edit all of the posts on RC, as you moderators do, and not see an abundance of posters saying (paraphrasing) ‘my plants came up early, my pond froze a month late, cherry blossoms bloomed a few weeks early, it’s hotter here than it’s been for 75 years, it’s dryer there than its been for 50 years, it’s wetter than …, high temps in Europe a few years ago killed …. people, etc., etc., etc., all because of global warming. I simply suggested these not be included in your common “we“.
[Response: The issue is context. Individual events do not prove anything, but they can be examples of something that is happening on a wider scale which can be attributed. Take a different subject – foreclosures for instance. If you are foreclosed, that doesn’t imply that there is a rise in a foreclosures, but if there is a rise in a foreclosures, and you get foreclosed, the latter is perfectly valid as an example. It doesn’t mean that you wouldn’t have been foreclosed in any other circumstance (who can tell?), but within context it makes sense. And if you look at any newspaper, their mainstay of reporting is finding specific people who exemplify some larger trend. Why should climate be different? – gavin]
“…Why should climate be different? – gavin.”
Because the connectors between climate change and localized weather are magnitudes more tenuous and ill-defined with any specificity, than the connection, say, between foreclosures going up and me getting foreclosed.
I meant to comment only on the use of “we” in your comment, (“… we’ve said over and again, that short term weather events are difficult to impossible to attribute to climate change. – gavin.”), not the main point. You now seem to be implying the opposite of your first point. But, I didn’t intend to and am not inclined to start a debate on the point, so I’ll just write it all off to my misreading your comments. Sorry.
Rod B., It is one thing to say “Katrina proves climate change is real.” That’s BS, and every knowledgeable climate scientist would agree. It is quite another thing to say that Spring comes earlier than in the past–that’s a manifestation of a global trend that has been observed due to climate change. On the one hand, you have a single event and someone asserting that it is proof. On the other hand, you have an event and someone saying it is consistent with an observed and recognized global, long-term trend.
Rod B, if I may interject
Regular people are probably not very concerned about the statistical averages of events, but rather about the “here and now.” It’s not very convincing to tell people that they should be worried about global warming, but then claim that the anomalous event that just happened yesterday is unrelated. On the other side, it’s not scientifically accurate to say that the event yesterday was necessarily a result of global warming. So I have a problem with statement like “Katrina was caused by global warming” but not statement like “Here was Katrina, this is what may happen more as the climate warms.” I’m not sure there is a perfect way to communicate this issue.
If we have a fair die (with say, two sides representing normal conditions, two for hotter than average, and two for colder than average) represnting the 1951-1980 climatology. Now say we make three of those sides hotter than average, two average, and just one colder than average. If I roll the die and get a “hotter than average” you might not think much, but after I roll the die a few more times (enough times where we can statistically say the die is unfair) then what will you say? Do you attribute the next “hotter than average” to my unfair die, or to random chance? And will you be happy?
Increase in the amount of heat on the Earth predicts certain changes, globally and locally. It takes quite drastic a change laymen to notice it. Scientific obvervation and reports from layman coherently show the predicted changes happening increasing numbers. They nicely demonstrate the validity of the predictions and the models used in the prediction.
Climate is changing, and weather is becoming more extreme, these are the facts supported by scientific theories and direct observations.
This post is against my better judgment, but, what the hey…
Chris, I got lost in your die analogy but think I understand your point, similar to Ray’s. My initial point was that there are many AGW advocates who do not subscribe to Gavin’s first statement that, “… short term weather events are difficult to impossible to attribute to climate change… ,” and contrarily do cite local weather anamolies as proof of global warming. (“Many” is certainly not all, probably not even a majority, and includes very few, if any, of the professional climate scientists — my sole and simple point ala the use of “we”.) If you cite Katrina as ‘the kind of thing that global warming might cause a few decades from now’, that is probably acceptable, though just barely. Spring showing up early this year is not. If it shows up a teeny earlier on a trend line (remember those? ;-) ) over 50 years or so (30 bare minimum), maybe. Likewise it is not appropriate to attribute the few thousand “extra” deaths during Europe’s hot spell a few years back (a one-off anomaly) on GW, or any other of a myriad of like examples. Secondly, the folks that cite Texas’ recent hot spell as GW proof completely turn their back on and reject any relevance of the midwest’s cold spell to anything, as example.
I do agree with the difficulty of convincing people of AGW that this poses (seriously). It’s true that making stuff up might make the convincing easier, but that’s orthogonal to the topic.
RE weather v. climate, & single events v. statistical datasets.
This might help to distinguish between weather and climate.
Emile Durkheim, a father of sociology, claimed that “social facts [not psychological or individual level facts] cause social facts.” An example he used is suicide, a highly personal decision and event. Whereas all sorts of factors may cause a person to commit suicide, including psychological factors, suicide rates of a nation, group, or category are caused by “social facts,” such as culture and other more pervasive, larger happenings (e.g., the Great Depression).
Whereas predicting single suicides (the behavior of a single person) is difficult, if not impossible (like predicting a tornado, its exact path, and which buildings it will demolish), Durkheim found that suicide rates for countries, genders, single/married, social classes, age groups, and religions remain about the same year to year, perhaps slightly increasing or decreasing due to shifts in the larger society/culture (note, he didn’t distinguish between the social and cultural).
Some 100 years ago the pattern he found was that suicide rates were higher for men, the rich, singles, Protestants and Protestant countries, and in cities. And these rates held fairly constant year to year (similar to the global average temperature — which does not increase or decrease, whether under natural conditions or global warming, as much as a 24 hour period on an autumn day in Illinois.
So, what’s going on, I ask my students. Do they get to November and the suicide limit has been reached that year, so they say “no more for this year,” or the limit has not been reached, so they say, “we need more to fill the quota”?
It is social facts that are causing this fairly steady rates. Durkheim came up with the theory of anomie (normlessness) to explain it, at least for Western countries — a condition where certain people (men, Protestants, rich, singles) and social conditions of cultural change are not under rules and controls the way women, Catholics, the poor, and traditional societies are. I guess the anomie factor would sort of be like the forcings of greenhouse gases in this analogy.
Now what’s interesting when my Soc 101 students use a recent, simple “U.S. states” dataset, they find that there’s an association for ruralness and higher suicide (also for “% newcomers” and suicide, also “Westness of state” and suicide). But we figure that anomie may still be at work, since our cities are well settled and most are old, but the suburbs and rural West are more recently settled by diverse people who don’t know each other as well, so there is more anomie in such areas, esp areas with higher % of newcomers.
So I hope this helps with the notion of climate (v. weather) — it is a statistical artifact created from a vast amount of weather data. It is fairly stable and constant, esp year to year or decade to decade. It’s why I still refer to my 1980 world atlas re regional climates; it’s why people like to move to California. And then it’s raining cats and dogs on the day they arrive, but most have faith that the climate (if not that day’s weather) is warm and sunny, so they don’t turn around.
For people who wonder when does weather become climate, I would guess that the more the weather data the higher the confidence — so its more a matter of more data is better for predicting things. Less data (or data just from one locality, even though over a very long time period) just wouldn’t help increase the confidence much.
Now if climate, esp world climate, is changing, even a tiny bit, we have to look for some very strong forcing to move that elephant of a dataset even a tiny bit. And it’s really quite amazing, nearly unbelievable to a layperson, that what we can’t even see (CO2 molecules or anomie) could have such a big impact. But that’s where science leaves common sense in the dust.
But I still say AGW caused hurricanes Katrina & Andrew, etc — at least these single weather events are part of the dataset that show an increase in hurricane intensity over the past several decades.
And all the local data that seemingly contradicts AGW (like it’s getting colder in Himodflethclseville), well, that’s also a part of the dataset which shows AGW is upon us.
Lynn (149), good description and analysis. I take it to mean that you can not attribute weather events to climate change with anything short of clear multidecadal — maybe longer — trends, but this doesn’t mean that a one-year weather anomaly can’t be climate change related, it just means that it can not be substantiated and attributed as such.
Your belief then that climate change caused Katrina is nothing more than that — your own belief or hunch or suspicion — something any person can do even if he can’t spell climate change — and not anywhere close to substantiation (proof to the commoner). This is where your credibility can suffer, depending on your audience.
But then you nail it with your last statement, which really blasts one’s credibility IMO. That is basically attributing any and all weather anomalies on AGW: hotter and drier than years in Texas this spring and summer? AGW! Colder and wetter than years in the midwest? AGW! I’ll name it; you’ll attribute it to climate change. Now, in the final analysis 100years from now you might, in a highly improbable scenario, be proven correct. But today, getting any commoner to believe that you have the faintest idea of what you’re talking about is out of the question.
Arctic and northern Canada/Greenland, and southern US get hot, while deep southern Canada and northern US get cold — all because of GW? Is this what the models say (serious question)??