What is the actual hypothesis you are testing when you compare a model to an observation? It is not a simple as ‘is the model any good’ – though many casual readers might assume so. Instead, it is a test of a whole set of assumptions that went into building the model, the forces driving it, and the assumptions that went in to what is presented as the observations. A mismatch between them can arise from a mis-specification of any of these components and climate science is full of examples where reported mismatches ended up being due to problems in the observations or forcing functions rather than the models (ice age tropical ocean temperatures, the MSU records etc.). Conversely of course, there are clear cases where the models are wrong (the double ITCZ problem) and where the search for which assumptions in the model are responsible is ongoing.
As we have discussed, there is a skill required in comparing models to observations in ways that are most productive, and that requires a certain familiarity with the history of climate and weather models. For instance, it is well known that the individual trajectory of the weather is chaotic (in models this is provable; in the real world, just very likely) and unpredictable after a couple of weeks. So comparing the real weather at a point with a model simulation outside of a weather forecast context is not going to be useful. You can see this by specifying exactly what the hypothesis is you are testing in performing such a comparison in a climate model – i.e. “is a model’s individual weather correlated to the weather in the real world (given the assumptions of the model and no input of actual weather data)”. There will be a mismatch between model and observation, but nothing of interest will have been learnt because we already know that the weather in the model is chaotic.
Hypotheses are much more useful if you expect that there will be a match; a mismatch is then much more surprising. Your expectations are driven by past experience and are informed by a basic understanding of the physics. For instance, given the physics of sulphate aerosols in the stratosphere (short wave reflectors, long wave absorbers), it would be surprising if putting in the aerosols seen during the Pinatubo eruption did not reduce the planetary temperature while warming the stratosphere in the model. Which it does. Doing such an experiments is much more a test of the quantitative impacts then, rather than the qualitative response.
With that in mind, I now turn to the latest paper that is getting the inactivists excited by Demetris Koutsoyiannis and colleagues. There are very clearly two parts to this paper – the first is a poor summary of the practice of climate modelling – touching all the recent contrarian talking points (global cooling, Douglass et al, Karl Popper etc.) but is not worth dealing with in detail (the reviewers of the paper include Willie Soon, Pat Frank and Larry Gould (of Monckton/APS fame) – so no guessing needed for where they get their misconceptions). This is however just a distraction (though I’d recommend to the authors to leave out this kind of nonsense in future if they want to be taken seriously in the wider field). The second part is their actual analysis, the results of which lead them to conclude that “models perform poorly”, and is more interesting in conception, if not in execution.
Koutsoyiannis and his colleagues are hydrologists by background and have an interest in what is called long term persistence (LTP or long term memory) in time series (discussed previously here). This is often quantified by the Hurst parameter (nicely explained by tamino recently). A Hurst value of greater than 0.5 is indicative of ‘long range persistence’ and complicates issues of calculating trend uncertainties and the like. Many natural time series do show more persistent ‘memory’ than a simple auto-regression (AR) process – in particularly (and classically) river outflows. This makes physical sense because a watershed is much more complicated than just a damper of higher frequency inputs. Soil moisture can have an impact from year to year, as can various groundwater reservoirs and their interactions.
It’s important to realise that there is nothing magic about processes with long term persistence. This is simply a property that complex systems – like the climate – will exhibit in certain circumstances. However, like all statistical models that do not reflect the real underlying physics of a situation, assuming a form of LTP – a constant Hurst parameter for instance, is simply an assumption that may or may not be useful. Much more interesting is whether there is a match between the kinds of statistical properties seen in the real world and what is seen in the models (see below).
So what did Koutsoyiannis et al do? They took a small number of long station records and compared them to co-located grid points in single realisations of a few models and correlate their annual and longer term means. Returning to the question we asked at the top, what hypothesis is being tested here? They are using single realisations of model runs, and so they are not testing the forced component of the response (which can only be determined using ensembles or very long simulations). By correlating at the annual and other short term periods they are effectively comparing the weather in the real world with that in a model. Even without looking at their results, it is obvious that this is not going to match (since weather is uncorrelated in one realisation to another, let alone in the real world). Furthermore, by using only one to four grid boxes for their comparisons, even the longer term (30 year) forced trends are not going to come out of the noise.
Remember that the magnitude of annual, interannual and decadal variability increases substantially as spatial scales go from global, hemispheric, continental, regional to local. The IPCC report for instance is very clear in stating that the detection and attribution of climate changes is only clearly possible at continental scales and above. Note also that K et al compare absolute temperatures rather than anomalies. This isn’t a terrible idea, but single grid points have offsets to a co-located station for any number of reasons – mean altitude, un-resolved micro-climate effects, systematic but stable biases in planetary wave patterns etc. – and anomaly comparison are generally preferred since they can correct for these oft-times irrelevant effects. Finally (and surprisingly given the attention being paid to it in various circles), K et al do not consider whether any of their selected stations might have any artifacts within them that might effect their statistical properties.
Therefore, it comes as no surprise at all that K and colleagues find poor matches in their comparisons. The answer to their effective question – are very local single realisations of weather coherent across observations and models? – is no, as anyone would have concluded from reading the IPCC report or the existing literature. This is why no one uses (or should be using) single grid points from single models in any kind of future impact study. Indeed, it is the reason why regional downscaling approaches exist at all. The most effective downscaling approaches use the statistical correlations of local weather to larger scale patterns and use model projections for those patterns to estimate changes in local weather regimes. Alternatively, one can use a regional model embedded within a global model. Either way, no-one uses single grid boxes.
What might K et al have done that would have been more interesting and still relevant to their stated concerns? Well, as we stated above, comparing statistical properties in the models to the real world is very relevant. Do the models exhibit LTP? Is there spatial structure to the derived Hurst coefficients? What is the predictability of Hurst at single grid boxes even within models? Of course, some work has already been done on this.
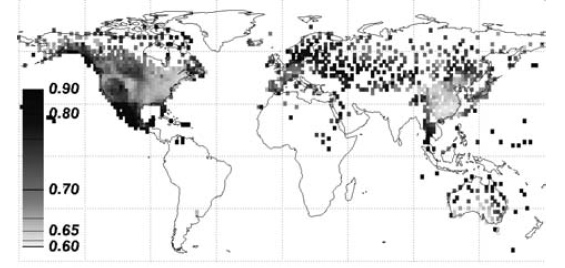 For instance, Kiraly et al (2006, Tellus) calculated Hurst exponents for the entire database of weather stations and show that there is indeed significant structure (and some uncertainty in the estimates) in different climate regimes. In the US, there is a clear difference between the West Coast, Mountain States, and Eastern half. Areas downstream of the North Atlantic appear to have particular high Hurst values.
For instance, Kiraly et al (2006, Tellus) calculated Hurst exponents for the entire database of weather stations and show that there is indeed significant structure (and some uncertainty in the estimates) in different climate regimes. In the US, there is a clear difference between the West Coast, Mountain States, and Eastern half. Areas downstream of the North Atlantic appear to have particular high Hurst values.
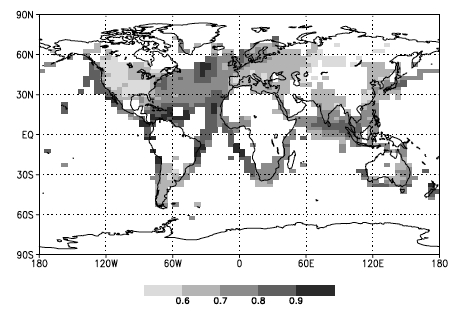 Other analyses show similar patterns (in this case, from Fraedrich and Blender (2003) who used the gridded datasets from 1900 onwards), though there is enough differences with the first picture that it’s probably worth investigating methodological issues in these calculations. What do you get in models? Well in very long simulations that provide enough data to estimate Hurst exponents quite accurately, the answer is mostly something similar.
Other analyses show similar patterns (in this case, from Fraedrich and Blender (2003) who used the gridded datasets from 1900 onwards), though there is enough differences with the first picture that it’s probably worth investigating methodological issues in these calculations. What do you get in models? Well in very long simulations that provide enough data to estimate Hurst exponents quite accurately, the answer is mostly something similar.
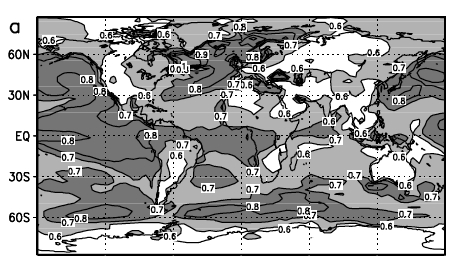 The precise patterns do vary as a function of frequency ranges (i.e. the exponents in the interannual to multi-decadal band are different to those over longer periods), and there are differences between models. This is one example from Blender et al (2006, GRL) which shows the basic pattern though. Very high Hurst exponents over the parts of the ocean with known multi-decadal variability (North Atlantic for instance), and smaller values over land.
The precise patterns do vary as a function of frequency ranges (i.e. the exponents in the interannual to multi-decadal band are different to those over longer periods), and there are differences between models. This is one example from Blender et al (2006, GRL) which shows the basic pattern though. Very high Hurst exponents over the parts of the ocean with known multi-decadal variability (North Atlantic for instance), and smaller values over land.
However, I’m not aware of any analyses of these issues for models in the AR4 database, and so that would certainly be an interesting study. Given the short period of the records are the observational estimates of the Hurst exponents stable enough to be used as a test for the models? Do the models suggest that 100-year estimates of these parameters are robust? (this is testable using different realisations in an ensemble). Are there sufficient differences between the models to allow us to say something about the realism of their multi-decadal variability?
Answering any of these questions would have moved the science forward – it’s a shame Koutsoyiannis et al addressed a question whose answer was obvious and well known ahead of time instead.
Well, that’s not actually what she said, though I can understand why you might interpret it as you did.
She said it’s all part of the same DATASET. She needs to answer for herself, but I interpret her statement to mean that taken as a whole, all the data shows warming despite local cold weather phenomena.
Read closely, she did NOT attribute the cold weather example to AGW. Her exact words:
No attribution of the single datapoint to AGW there …
dhogaza, well, one really has to parse the hell out of her statement, and unless one does that the implication at least is clear. None-the-less, as you point out, I can see how I might have misinterpreted what Lynn said; I didn’t mean to do that.
RE 149-151, I guess it’s really not so important to me whether any part of Katrina’s intensity can be attributed to climate change.
I’ve been reducing my GHGs since 1990 with the idea that it might help in reducing various AGW effects (assuming enough other people also join in reducing their GHGs). So when Hurricane Rita greatly damaged a friend’s home, I emailed him that I had known that GW might increase such harms, and I had been reducing my GHGs in hopes of reducing just such harms. And I’m reducing them now with the hope of reducing such harms in the future.
[edit]
[Response: Please note that using alternate names on threads you have already commented on is extremely bad form. Feel free to repost your question under your more usual login. – gavin]
Re Rod @ 143: “my plants came up early, my pond froze a month late, cherry blossoms bloomed a few weeks early”
As individual anecdotal events these are of course unattributable to climate change, but as a series of recorded dates of plant germinations, pond freezings, or blossoming dates they do form a record of climate change.
As analogies go, consider the following…
You start a journey on the highway, with given common speed limits, and being an ordinary law-abiding citizen you set your car cruise control accordingly. Low level or alertness, thinking about matters of importance.
Fifty miles down the road, a bull moose is considering the relative merits of grass resources on his side of the road and the other. He comes to the conclusion that it is appropriate to make a taste test.
As a result, your car and the bull try to occupy the same spot in space-time. Ambulance will recover you, a wrecker will take your car for recycling, and the bull will provide many a feast dinners for the dogs of the local hunters’s club.
Attribution of this unfortunate event? Was the accident caused by the particular speed limits? What was the role of the Government? Had the Government engineers’s arbitrary decision concerning the speed limit been i.e. a bit higher, the accident would not have happened at all. Both you and the bull moose would have passed the spot safely. This appears quite certain.
So, must we draw the conclusion that the Government should institute generally higher speed limits and this act would end all accidents of this kind?
Of course not. The result of higher speed limits is marginally more accidents, with markedly heavier risk to life and property. Scientific theory and observations tell us that.
So, can Katrina be attributed to AGW or not? Prior to that day, many of the (approximately ten) oceanic and atmospheric factors that drive and steer the start-up, development and movement of a hurricane would have been different in a non-AGW world. Different sea surface temperature distributions, jet streams, pressure fields, atmospheric temperature and humidity profiles, cloud distributions, less or more Saharan dust in the area, different easterly waves, width of the tropical climate band … Assuredly no way for the Katrina event to have happened as experienced as such then and there.
Which does not mean that the probability of a major tropical storm hitting a vulnerable major Gulf city has been radically modified. Single events just are not predictable with our current knowledge (data and models) and probably will never be. It is reasonable that some changes in the statistics can be predicted, though.
A general point: when people complain “why doesn’t it just keep getting hotter and hotter, yadda yadda year/s were actually cooler than yadda yadda” it helps to remind them that climate is a bit like the economy. It is not a simple system under the strict influence of a single causation. For example, CO2 is a a bit like interest rates in reverse: lower interest rates tend to “heat up” the economy, but of course other factors affect the economy. A decision to lower interest rates may not spruce up the economy because other factors may outweigh the rate change to bring the activity down. However, low interest rates can be “expected” on average to pump up the economy. Also, the economy is going to fluctuate anyway up and down (as will the stock market) and that puts “noise” into any attempt to make correlations.
BTW, what’s the deal on solar cooling? I mean, what’s allegedly happening/will happen right now, re the sunspot level below expectation, e.g. Victor Manuel Velasco Herrera in Mexico predicting upcoming 60-80 year colder spell, etc?
http://www.sott.net/articles/show/164133-60-80-year-little-ice-age-coming
Oddly (?), headlined on Drudge but not a lot of play in the “conventional” media – for good reason?
tyrannogenius
Neil, you might look at
http://www.leif.org/research/The%20Open%20Flux%20Has%20Been%20Constant%20Since%201840s%20(SHINE2007).pdf
and
http://www.leif.org/research/AGU%20Fall%202006%20SH21A-0313.pdf
Leif Svalgaard has suggested there’s good reason to doubt the notion that a low solar cycle would lead to a sudden great cooling. See his posts at solarcycle24.com too.
We know a lot more now about what volcanos were happening during the previous cool spell, which can explain some of it, for example:
http://scholar.google.com/scholar?sourceid=Mozilla-search&q=Maunder+minimum+volcanos
There is also some reason to doubt that there is anything unusual about this solar cycle.
http://science.nasa.gov/headlines/y2008/11jul_solarcycleupdate.htm
This brings me to wonder how the big question can be answered.
Given that we have climatic models of the Earth and an Earth can we tell the difference?
That is the test, could a sentient being tell whether the models reproduce Earthly weather and climate?
Could that being say; “This is real climate and that realisation is not an Earthly climate”.
Conceptually the first problem is that, if one gives the models and the Earth equal status, one must ask is; “Was the particular realisation that is the history of the Earth’s climate likely”?
Could it all have turned out very differently.
If the actual realisation we have enjoyed turns out to have been highly unlikely then it should turn out to be highly unlikely in the models; and conversely.
So the models have countless numbers of realisations and the Earth may have produced but one of countless realisations how do we tell if they are akin.
Well we cannot rerun the Earth history.
But like monkeys and typewriters we can produce endless model runs and presumably some of those runs will resemble the actual realisation we have experienced close enough to give us confidence that they are good models.
The trouble is that past successes are no guarantee of future glories. Even such a realisation is no guarantee of accurate prediction.
For now it would be good to know that the current models are capable in principle of reproducing the real climate at least once amongst their countless runs.
Best Wishes
Alexander Harvey
Re 160 – It’s not an ‘all or nothing’ game. Also, there’s basic overall physical arguments that don’t require quite so much computation to understand (arguments exist that a human mind can grasp. Granted, some such arguments are informed by computer modelling, but they aren’t just the results of models).
#161
But to figure out at what temperature negative feedbacks like clouds and moist convection (and local human interventions) will cap GHG warming requires something like a computationally intensive GCM. i.e. Something spatially explicit with a great many equations, parameterization, and a bit of tuning. Is this not true, Gavin?
The PETM is probably a decent model for the sort of extreme case you’re wondering about, pushing the system to an extreme — at least in relatively recent paleoclimate. I’ll hope one of the real scientists corrects my attempt here:
Abrupt reversal in ocean overturning during the Palaeocene/Eocene …
http://www.nature.com/nature/journal/v439/n7072/full/nature04386.html
That page points the kind of intervention needed to reverse such a major hot spell.
In that case, plankton species evolved that drew down the CO2.
Local interventions won’t change a global event.
Global change: Plankton cooled a greenhouse
Nature News and Views (14 Sep 2000)
http://www.nature.com/nature/journal/v407/n6801/fig_tab/407143a0_ft.html
The illustration of the latter article rather dramatically sums it up:
http://www.nature.com/nature/journal/v407/n6801/fig_tab/407143a0_F1.html#figure-title
Alexander Harvey,
I’m not sure exactly what you mean by “reproduce Earth’s climate”. Certainly, climate models exhibit realistic behavior on the scales of their resolution. However, in a large physical system, there will be so many different possible realizations of climate signal + weather noise that no two will likely ever repeat. The question you probably want to ask is how often we get “close to” a particular outcome. In this sense, the situation is not unlike that with statistical thermodynamics–no two Monte Carlo runs will yield exactly the same results, but the macroscopic properties of the vast majority of runs will yield something close to the equilibrium properties of the system. Likewise, even though weather is different in every run, the climates yielded by the models are recognizable as Earthlike.
Alexander Harvey #160 asks a valid question: what are the criteria by which model “realism” is judged? Is the double ITCZ problem a problem, or isn’t it? What kinds of errors or misrepresentations are tolerated? This is not a hard question to answer.
Ray #164 suggests: “climate models exhibit realistic behavior”
yet no one has answered my question in #1:
“How well do the GCMs perform at generating suitably high Hurst coefficients?”
Here I am talking about the stochastic internal variability in GMT in unforced control runs, not deterministic responses to extermnal forcings and not gross qualititative aspects of circulation (which Gavin notes above are NOT always realistic, e.g. double ITCZ problem). I want to know: do the control runs exhibit the proper kind of scale-free distributins of weather and climate phenomena that we know happen in the real world? This too is a simple question.
[Response: No it isn’t actually. What would one compare the control run statistics with? The real world has had forcings – greenhouse gases, volcanoes, solar etc. Given the way the statistics work they cannot extract a purely intrinsic signal from the externally forced one (that is an attribution problem that requires some kind of model). Indeed, people have already reported that including forcings changes the Hurst coefficients (i..e Vyushin et al, 2001 for volcanoes). – gavin]
Re 162 – yes,but – how sensitive is the climate to the tinier of perturbations in the boundary conditions and physics? If adding a small lake completely throws off the global average surface temperature response to some change in CO2, that would imply that the climate is so unpredictable that it’s not even … (basically, as I recently wrote somewhere else, if 3/4 of an elephant is covered up by a tarp, you can probably still tell that it’s not a monkey that’s under there – you don’t need to know everything in order to know something. Figuring out the climate sensitivity to CO2 changes down to the nearest 0.1 deg may be nearly impossible and perhaps not very meaningful to the single model run that is reality – but figuring out the sensitivity with a bit less precision is more likely to be doable and still yields meaningful information, for science and for policy implications)
> tiny perturbations
Not very, Patrick.
You write: “If adding a small lake completely throws off the global average …. ”
Are you making that up, as a hypothetical?
Do you believe it’s true?
Where do you find any support for that idea?
#165
Thanks as always for your patient reply, Gavin, and also the reference. Unfortunately the “improved” scaling behavior discussed in that paper is merely a band-aid for a model that does not produce correct intrinsic scaling behavior when unforced. And THAT is what LTP is about – the scale-free patterning that occurs as a result of *intrinsic* maximum entropy thermodynamics. It is NOT about the quick responses that happen as a result of external forcings. These authors have misunderstood and/or misrepresented the long-term pesistence phenomenon, and they have taken you along for the ride. What they are dealing with is short-term persistence, not long-term persistence.
You will ask “How do I know the unforced climate exhibit long-term persistence, if we’ve never seen an unforced climate?”. And that is a very good question. If you look at other model thermodynamic systems that are climate-like, but unforced you will see they have scale-free patterning, aka long-term persistence. Thermodynamic theory suggests the climate system should be no different.
Granted, arguments based on theory or worse, analogy, are weak.
However your citation of this paper indicates to me that you, like the authors of that paper, are only half-informed about the nature and problem of long-term persistence. That would explain your review of the Koutsoyiannis et al (2008) paper. It’s a paper that is easy to dismiss based on weak methodology. It’s value lies in the last sentence of the abstract. Which is not understandable by anyone who has a weak understanding of the problem of long-term persistence.
I am happy to be proven wrong on that. If you can do that, then feel free to delete this comment. I’m not here to try to embarrass anyone. I’m here to understand your arguments by probing their assumptions.
Uninformed? About what? Sources would really help.
Looking:
http://scholar.google.com/scholar?num=100&q=%2Bclimate+%2B%22long-term+persistence%22&as_ylo=2007
it seems there’s plenty written, and the climate models already have passed this test.
E.g., http://w3k.gkss.de/staff/storch/pdf/rybski-etal.2007.pdf
JOURNAL OF GEOPHYSICAL RESEARCH, VOL. ???, XXXX, DOI:10.1029/
_________excerpt follows____________
Abstract. We study the appearance of long-term persistence in temperature records, obtained from the global coupled general circulation model ECHO-G for two runs, using detrended fluctuation analysis. The first run is a historical simulation for the years 1000−1990 (with greenhouse gas, solar, and volcanic forcing) while the second run is a 1000 year “control-run” with constant external forcings. …
…
… most continental sites have correlation exponents γ between 0.8 and 0.6. For the ocean sites the long-term correlations seem to vanish at the Equator and become non-stationary at the Arctic Circles. In the control-run the long-term correlations are less pronounced. …
… The expressions “long-term correlated”, “long-term persistent” or “long-term memory” refer to time series, whose
auto-correlation functions do not decay exponentially, as is the case with autoregressive processes, but decay much
slower following a power-law. It has been suggested that the narrow spatial distribution of the exponent γ at continental and coastline stations may be used as an efficient test for the quality of climate models [Govindan et al., 2002]. Newer analysis [Vyushin et al., 2004] has revealed, that climate simulations taking into proper account the natural forcings and in particular the volcanic forcings, reflect quite well this quite ”universal” feature of the observable data.. …”
——end excerpt—-
So, I”m an amateur. Reading this, it seems to me that they say the simulations “reflect quite well” what was suggested. As a test of the quality of the models, they’re saying, this issue came up, the analysis was done, and the models proved to handle it okay.
Citing references, where’s the issue going these days? Sources please?
Re 167 – Sorry, you misunderstood my intention. I don’t believe a small lake or even a large one would throw it off – indeed while the climate sensitivity could certainly vary with such things as continental drift and the mix of species present, I expect based on the physical arguments that there is some generality to it. I guess I could have been clearer though.
Re 167 – well, now I may have made another error… certainly continental drift over millions of years (and the resulting mountains and ocean current changes) would have strong effects on regional climate and regional climate sensitivity (for the same reason that not every location on earth will experience global warming in the same way with today’s geography). But the effect on climate sensitivity in so far as change global average surface temperature… well, maybe it would be more subtle, although rearranging the continents could certainly change the threshold at which an ice age starts, etc, and could affect the way glacial-interglacial positive CO2 feedback works… but anyway…
#169
Ah, a paper so new it has not even been cited once.
They study an unforced control run in one model, EchoG. (Where are the others?) About this model they state:
“In some cases, as we will show below, semistable oscillations occur in the fluctuation functions. Consequently, there is no scaling and a power law fit is not meaningful.”
And this is suposed to be an example of realistic scaling behavior?
They go on to state:
“In some areas, in particular in the equatorial Pacific, biannual cycles occur, a feature at variance with observational evidence. Unfortunately, these cycles cannot be eliminated simply by a seasonal detrending analog to equation (1), since the period of 2 years is too unstable. For the same reason, we were not able to remove the oscillations (automatically) in the Fourier spectrum. Therefore, in order to get rid of these oscillations, we additionally consider time series of biannual temperatures (i.e., temperature
averaged over 2 years of daily data).”
In other words, in order to detect correct scaling behavior it is necessary to patch over a more fundamental flaw in the model’s predicted circulation.
But the most telling comment is the last paragrph of the conclusion:
“Finally, in this paper, we only studied temperature records and focused exclusively on the linear correlation properties. It is an interesting question how far the global climate models are able to reproduce also the nonlinear ‘‘multifractal’’ features of the climate system [see Koscielny-Bunde et al., 1998;Weber and Talkner, 2001; Govindan et al., 2003; Ashkenazy et al., 2005; Bartos and Ja´nosi, 2006;
Livina et al., 2007]. It is known that in particular rainfall is significantly multifractal [see, e.g., Tessier et al., 1996; Kantelhardt et al., 2006], and it will be interesting to see if this feature is also reflected in model rain fall data.”
So it appears my question regarding multifractal scaling has not, in fact, been answered, but “will be interesting” to address in future work.
One hopes that in the future they will examine more than just one model. That model was selected for a reason.
[Response: All of the AR4 data is now available for people to do want they want (it’s a little mean to criticise authors who did not have access to other models at the time they were writing). I stated right up at the top that analysing that data properly would have been a much more productive use of K et al’s time and indeed, the results may be interesting. If you are in a hurry to find the answers, I suggest doing it yourself. If you prefer not too, then I’d suggest waiting for someone else to do it before deciding anything. The work done so far indicates that the forcing makes a difference to the statistics, which implies that control runs are not going to behave the same way as the real world, and indeed, that some of the ‘LTP’ defined from the observations, far from being a problem for attribution studies, may in fact be a signature of the forcing! (I don’t know that’s the case, but it would be somewhat ironic if it was). – gavin]
> a paper so new …
I wrote “e.g.” — that’s one example. See their references.
I gave you the search link for more work.
You can look at the papers citing Vyushin’s later work for more examples.
You quote extensively from the source I found you, but you’re blathering. What supports what you believe?
Cite sources and quote from them please. Declaiming your superior knowledge without cites is asking us to do the homework for you.
___________________
reCaptcha: models UNTANGLE
Richard Sycamore,
OK, let me see if I’ve got this straight. You are castigating a paper that at least made a reasonable effort to gain knowledge you think is important and using the shortcomings you see in that paper to justify the piss poor, ill conceived paper by K. et al., which is so confused it doesn’t really answer anything corresponding to the real world. Hey, whatever, dude.
Re 171 – … of course changes in the nature of CO2 feedback wouldn’t have direct bearing on the climate sensitivity to CO2, just to clarify…
See also, as a further example, not as the definitive statement of the current state of the literature:
http://coast.gkss.de/staff/storch/pdf/bunde.detection.GRL.2006.pdf
One of the authors (I wonder which?*) has a sense of irony; note the final paragraph of that paper:
“We conclude that the previous claim that the most recent warming, observed by quality controlled instrumental data, would be inconsistent with the hypothesis of purely natural dynamics [Hasselmann, 1993; Hegerl et al., 1996; Zwiers, 1999; Barnett et al., 2005] is supported by our long-term persistence analysis of different proxy-based reconstructions extending over many centuries and even up to two millennia. In case of the rather smooth reconstructions, the detection appears feasible even before 1985. An interesting detail is that the two fiercely arguing groups around Mann and McIntyre lead both to very early detections, while the most conservative detection result is obtained when the more ”bumpy” reconstruction by Jones and coworkers is used.”
_______________________________________________________
*http://coast.gkss.de/staff/storch/BILDER/donaldNEU.jpg
Seems there’s indeed plenty of work, it’s an active area. Don’t fail to read and check the footnotes and look for citing articles. The DOI reference is more current than the journal references in Google Scholar at the bleeding edge of research publication.
#174 Castigating? Far from it. They studied one model of many, just as Koutsotyiannis studied only 8 points of many. There are good reasons why people study a part of a problem before tackling the whole of it. In both cases the follow-up papers should prove very interesting. We are learning new things all the time about how well the models in comparison to the real world. I agree that Koutsoyiannis paper is not definitive. But I also think there’s a provocative line in the abstract worth thinking about seriously.
#173 Blathering? I am merely letting the record show that the scaling behavior of the unforced GCMs was not studied prior to IPCC AR4, which is confirmed by the fact that Gavin has invited me to do the analysis myself. I had to establish that fact before I could assert it. If that’s blathering … well, whatever.
[Response: That’s not correct. The Fraedrich and Blender papers studied it in a long control run and it’s shown graphically in the post above! I am only unaware of anyone doing it systematically with the AR4 models (but it could be ongoing). – gavin]
#177 inline reply
You’re right, it’s not strictly correct. I read the OP attentively, so allow me to correct myself.
Regarding Blender et al. (2006) Gavin states in the OP:
“This is one example from Blender et al (2006, GRL) which shows the basic pattern though. Very high Hurst exponents over the parts of the ocean with known multi-decadal variability (North Atlantic for instance), and smaller values over land.”
However note the comment in Rybski et al. (2008):
“[38] We could verify neither the claim that the long-term correlations vanish in the middle of the continents [Fraedrich and Blender, 2003; see also Bunde et al., 2004] nor that the strength of these correlations increases from the poles to the equator [Huybers and Curry, 2006]. Both claims not only differ from our findings for the model runs, but are also in remarkable contrast to the enormous number of observational data [Eichner et al., 2003; Kira´ly et al., 2006].”
So although the question has been “studied”, it has not been answered to the point where there is an established consensus. (I dithered over whether to use the word “studied” or “established”. Make that change and my point stands.)
This gets back to Gavin’s qualitative assertion in the OP that the results of the model-data comparisons are “mostly something similar”. One wonders what that means.
Let the record show that a *consensus* on this issue was not reached prior to the publication of IPCC AR4.
Attributing the warming in AGW to something other than greenhouse gases is a bit like Mark Twain’s saying that Shakespeare’s plays were either by Shakespeare or by someone else with the same name. The calculated increase in energy that falls on the planet due to the increase in CO2 in the atmosphere is sufficient to cause the warming. If it hasn’t caused the warming the energy went somewhere else and warmed something there.
reCaptcha: Lt coarse
#179
You miss the point. The choice of noise model affects conclusions that fall out from a trend attribution analysis. In any attribution exercise an error in the estimation of one parameter has downstream consequences for the other estimated parameters. Similarly, the amount of variance attributed to unexplained factors (“noise” and other poorly understood processes including some feedbacks, nonlinearities and synergies) is variance NOT available to be attributed to various forcings. To presume the consequences would be “unscientific” as someone here likes to say.
That is why the choice of null noise model matters. Because you can’t simply presume the magnitude of
GHG forcing effects. As with the other forcings (solar, aerosols, volcanoues, …) these effects have to be estimated objectively from data (or inferred by subjective tuning to data). Use of a linear additive model with i.i.d. noise may be a problem if it is a poor approximation to reality.
So it is not a matter of GHG effects occurring at point A or B. It is a matter of forced trend vs. internal thermodynamic noise. A bit of Shakespeare, a bit of monkeys typing sonnets – to use your analogy.
Gavin is welcome to delete any of comments or smash them to bits, if he can.
[Response: It’s very much a function of what you are looking at. For the global mean temperature the physics of the situation preclude large natural variability in the absence of forcings. In particular, the rise in ocean temperatures over the last 50 years imply a net and persistent radiative imbalance – not just ‘noise’. People sometimes forget that internal variability has to be a real phenomena – heat has to come and go from somewhere. For long time scales (greater than a year or so), this can only mean the ocean, and for that case the long term trends are clear. No physically constrained noise model will match that (however LTP). At local scales, or different metrics, the issues are less clear, but #179 is correct, LTP does not provide an explanation for global warming. – gavin]
Ray,
You wrote:
“I’m not sure exactly what you mean by “reproduce Earth’s climate”.”
Nor am I. Your quote is not what I wrote.
Which of these statements (in quotes) have you picked from.
“That is the test, could a sentient being tell whether the models reproduce Earthly weather and climate?”
That is a legitimate question. What are the criteria?
“But like monkeys and typewriters we can produce endless model runs and presumably some of those runs will resemble the actual realisation we have experienced close enough to give us confidence that they are good models.”
Nothing argumentative in that.
“For now it would be good to know that the current models are capable in principle of reproducing the real climate at least once amongst their countless runs.”
This is also a simple question. Do they show that they are likley to ever get really close JUST ONCE.
**************
Perhaps the more important question is my:
“Conceptually the first problem is that, if one gives the models and the Earth equal status, one must ask is; “Was the particular realisation that is the history of the Earth’s climate likely”?
Could it all have turned out very differently.
If the actual realisation we have enjoyed turns out to have been highly unlikely then it should turn out to be highly unlikely in the models; and conversely.”
To suspect the stated question to be true, would I feel lead to madness. To suspect that the climatic history of the last 100+ years was a fluke would mean that we can make little progress.
There would be no point validating climatic models against the record if it was an outlier.
To suspect that is totally false, and that the climatic record is largely determined and typical of all possible realisations means that we can make progress. But it also means that true models must share that tendency and all the twists and turns of the last 100+ years should be commonly (but not inevitably) reproduced and that we can make verifiable predictions. Not just of the next 10 years but by turning a blind eye of the last 10 years.
*********
Going back to what I said:
Could a sentient being in anyway tell the difference between a computer model and the Earth’s historic climate.
This is an important question. I am not sure I could, could any of you?
If we cannot, not for any of the models, then we have no way of judging between them.
If we cannot tell the difference then perhaps there is nothing salient in the historic record and perhaps indeed the historic realisation is but one of a similarly varied range of possibilities. If that be so then we face madness.
Personally I think that the climate is well constrained. I suspect that with luck will may have another decade that is free of major volcanoes and major El Ninos and we may gain a major insight to what is going on to an unprecedented level of detail. That is my hope. It simplifies things immensely.
Just now the 10 year CRU temperature gradient has just passed a minimum in which it was essentially flat. centred on 2003 (1998-2008).
It was also flat centred on 1992 and 1982. In between in peaked at .4C/decade (1979 and 1997). Personnaly I suspect this shows the balance between GHG and solar variation. If we can go another complete solar cycle without a any other major interference then we might expect the 10 year gradient to peak once again at around .4C/decade around 2113 and then slow again. Also around 2119 we could expect the temperatures to be around .2C greater than now. That is if you like my prediction. I just hope for two things, that we have no more volcanoes in the next 11 years and I live to see the outcome.
Best Wishes
Alexander Harvey
“LTP does not provide an explanation for global warming”
I think all reasonable, rational people understand and agree with the spirit of this statement. (Yes, there are a few inactivists and deniers out there.) The issue is the *magnitude* of the GHG effect. It is extremely unhelpful to spin this into a black and white issue of LTP vs GHGs. Let’s just get the LTP and the radiative imbalance components correct and let the GHG chips fall where they may.
The point is: there is currently little reason to believe that the models used to measure attribution exhibit realistic LTP. What this exchange has showed me is that this is still an open question.
[Response: I don’t see how you come to this conclusion at all. The examples looked at so far all show LTP with spatial structure that makes sense. In the comparisons with widespread data the magnitudes and patterns look similar (though I haven’t quantified that). Therefore, there is no reason to believe that there is a problem here. I agree more work might profitably be done with the AR4 models (and the observations) and perhaps we can get a clearer answer about what fits and what doesn’t. But I see no reason to a priori assume that the models don’t have realistic LTP. – gavin]
For the record, I agree with Ray, Hank, Gavin and others here that uncertainties are no excuse for inactivism. But that doesn’t mean one should deny their existence or role in downstream calculations.
#181 Alexander Harvey’s question is quite clear. He wants to know how you judge a model to be “mostly something similar” to data. i.e. What are the criteria? It is a very simple question. A list of criteria and an objective measure of fit is probably all he is looking for.
If no such list can be produced, or if there is no such list, there is no shame. Pattern-matching is not an easy thing. (As these captcha phrases prove.)
Let me see if I can make sense of this. “He wants to know how you judge a model to be “mostly something similar to data.'”
At the top of the thread, the quoted bit is pulled out of this context:
“…. calculated Hurst exponents for the entire database of weather stations and show that there is indeed significant structure (and some uncertainty in the estimates) in different climate regimes. …. What do you get in models? Well in very long simulations that provide enough data to estimate Hurst exponents quite accurately, the answer is mostly something similar. ”
That seems clear: similar structure — illustrated by the two pictures shown along with that quoted text.
They look similar. No?
One wouldn’t want to, say, count pixels to try to quantify the similarity, it’d make more sense to work from the data that was used to create the pictures. Good opportunity for some grad student, if it’s not already being done or already been published. Anyone else looking further into the literature? Lots more there than I can read.
_________________
“and experts”
Gavin #182 says:
“I see no reason to a priori assume that the models don’t have realistic LTP”
This I take as an invitation to explain why this is not an “a priori assumption”, but a demonstrable fact? Realize that it matters quite a bit which “models” you are referring to. I was referring there to the attribution model by which the various forcings are estimated. Will you tell me what the assumptions are for the distribution of residuals (errors) in that model, or shall I go look that up?
[Response: I don’t understand your last statement at all. The forcings are derived from first principles – radiative effects of CO2, CH4 etc, or from more complicated chemical-transport modelling (ozone, aerosols etc). This has nothing whatsoever to do with with what we’ve been discussing. Attribution is done by comparing the signatures of these forcings in various fields (temperature changes by latitude, in height, in the ocean etc) and allowing for uncertainties in sensitivity and the amount of intrinsic variability. The whole of chapter 9 discusses this in IPCC AR4. However, whatever assumptions are made there it has no bearing on whether the models have realistic LTP or not – that can only be demonstrated by doing the appropriate comparisons – and the ones so far (though incomplete) don’t give any reason to think there is a problem. – gavin]
Richard,
Thanks, yes I feel it is important to know what we are looking for not just what we are looking at.
If I may I should just like to say that whilst taking a walk with my dogs I reminded myself of two great thinkers.
Turin & Rogers.
In case you haven’t guessed I mean Will Rogers, that’s right.
He amongst others (including Twain) is attibuted with the saying:
“It’s not what we don’t know that’s the problem, it’s what we know that ain’t so.”
It is a criterion I often judge my opinions against.
So I reminded myself that Turin gave us the Turin test.
And I asked myself: could I tell the difference between a climate model simulation and Earthly reality.
Answer: I do not know.
Which is humbling.
Then I asked: Where would I start to look.
As it happens I have whiled away the last few weeks analysing the Hadcrut3 baseline data to extract the seasonal components, the amplitude and phase of the annual, bi-annual, etc. Not a mean feat as it has to be repeated for each 5×5 grid square.
So I am pretty familiar with the seasonal shape, harmonic amplitude and lag for most of the world.
The global representation of fundamental harmonic’s phase makes quite a pretty picture and is quite data rich and as it happens.
So I thought to myself, well that would make a good criterion to judge between a model run and our Earthly realisation. That would be easy and I could do that.
Unfortunately I remembered Rogers, and concluded that I have know means of knowing that such a subtle test would be valid as I simply do not know if our experienced realisation was indicative of anything.
There are times when one gets the uneasy feeling that one is looking down the wrong end of a Howitzer. I may believe that the problem is soluble but I have no means of knowing.
Going back to the phase data: It is reasonable coherent, no large discontinuities, in the Northern extratropical region at least. It shows promise as a criterion I could comprehend and test against. As it is derived from the baseline averages it is possibly quite solid and it does represent an aspect of climate. But is it typical? Who knows?
So I asked myself well typical or untypical it happened and the models should be capable “at least in principle” of producing results that show that the are capable of reproducing it given enopugh runs.
I think by this I mean that they are not constrained to a markedly different climate. I am sure statisticians know how to handle such things. But to my mind it would be; if it seems to be a duck which swims on a pond and the model has long arms and swings in a tree, then they simply have too little in common.
Sometimes when looking down a barrel it might be better to shout “Fire”.
My Best Wisshes to you all.
Alexander Harvey
Alexander Harvey #186 says
“It’s not what we don’t know that’s the problem, it’s what we know that ain’t so.” Attributed to Will Rogers, or maybe Mark Twain.
It appears that the most likely correct attribution is to Josh Billings.
I don’t know what bearing this may have on any other confusion about attribution.
Alexander, 186 and 18 :
“Could a sentient being in anyway tell the difference between a computer model and the Earth’s historic climate.
This is an important question. I am not sure I could, could any of you?
If we cannot, not for any of the models, then we have no way of judging between them.”
That first sentence is OK the middle one is assumption and the last one is your “what we know that ain’t so”. Or at least your implication as taken from your 186 comment on duck vs man.
I ask of you: is it important to be able to tell the difference? Surely if we can’t tell the difference, then as far as we can tell, they are the same.
But the last query has no basis in the first two and so I call “wrong” on it. Judging between them? Should we? Why? And if we can’t, what does that matter?
Now where models may well break down is that they don’t allow nearby phase spaces to be moved to unless they are seamless from the current phase spaces. Like Ice Ages and Interglacials. But a *possible* phase space is a runaway Venus climate. The models don’t see that as being likely because there is nothing that we know that will push our climate that far out of the current “possible” without having feedbacks that pull us away. But it IS in the phase space and there may be a mechanism to move us over there. Such a process is narrow and unlikely therefrom (if it were likely it would fall out of what we do know more easily because when there are more ways, some of those ways will fall in the realm of what we know).
So models are true and accurate. For a given value of “true” and “accurate”, but then again, that’s what’s the base truth of Science has. QCD is “true” but not really “the truth” but
a) we don’t know anything better than the standard model
b) we don’t have any measurement that tells us what we would change
c) it still works damn well where we need or want to apply it
a and b are your queries in the first part of my quote. c is where I call your “duck vs man” judgment wrong.
And if we get a better climate model it will be mostly the same as the one we have now. It will just have more possibilities covered and more accurate constraints on where it will go. That may open up new areas of possibility but does not change that what we have is “right enough”.
Also, I think it’s “Turing test,” named for the late computer scientist Alan Turing.
Dear Barton,
Thanks, yes I meant the mathematician not the shroud. I am getting tired and feeling rather old but it is no excuse, particularly as I studied his work many moons ago.
Dear Mark,
I will get back to you, hopefully today.
Dear All,
If anyone is interested in the phase lag of the seasons and either has some data they could point me to, or would be interested in what I have found please let me know. Plotted as a contour map it clearly describes the oceans and continents and even appears to have an anomaly around the Norwegian Sea. In the oceans it has features that I suspect are linked to the major gyres.
Best Wishes
Alexander Harvey
model: climate
map: territory
phylogenetic tree: life
tasty bait: worthwhile pursuit
Richard Sycamore, I’m not sure what you are advocating. If the models took a best fit of sensitivity to data, I might be concerned. However, sensitivity is determined independently and constrained by many different lines of data–all of which favor a sensitivity in the 2-4.5 K/doubling range. Energy is conserved even in a system with LTP.
This may be an OT question, but I wasn’t sure where it actually belongs: how many cat-5 hurricanes would have to form over the next decade to prove scientifically (more than just give common credibility to) the notion that climate change includes increased frequency and intensity of tropical storms?
Better than just an answer, if someone can show me where/how to look for the answer, I’d appreciate it a lot.
I think that the number of parameters or interactions make it impossible to proove conculsively my mathematical models that the climate is changing because of man-made greenhouse gasses. But it is not forbidden to make some judgements based on reason. And these judgements points to one important fact: The fossile fuel is running out. So the threat will decrease of it own. What is important is finding new energy sources to replace fossile fuel.
Knut Holt, let me get this straight. You are contending
1)that climate models cannot be verified
and
2)that the problem will take care of itself due to the finite supply of fossil fuels.
Where in the hell did you get either of these two ideas?
Re:1–complicated models are not needed to demonstrate anthropogenic causation–there simply is no other viable explanation for simultaneous warming of the troposphere and cooling of the stratosphere
Re:2–Ever year of coal, tar sands, oil shale, methane clathrates…
There’s plenty of carbon based fuel to anti-terraform Earth for whatever species will thive in the environment we will create. It won’t be us.
Many sites saying that “petroleum” is running out are quite visible.
Don’t mistake “petroleum” as meaning all fossil fuels.
That’s the confusion that led to the claims a few years ago that there wasn’t enough “petroleum” to cause global warming.
They ignored coal.