The difference between a single calculation and a solid paper in the technical literature is vast. A good paper examines a question from multiple angles and find ways to assess the robustness of its conclusions to all sorts of possible sources of error — in input data, in assumptions, and even occasionally in programming. If a conclusion is robust over as much of this as can be tested (and the good peer reviewers generally insist that this be shown), then the paper is likely to last the test of time. Although science proceeds by making use of the work that others have done before, it is not based on the assumption that everything that went before is correct. It is precisely because that there is always the possibility of errors that so much is based on ‘balance of evidence’ arguments’ that are mutually reinforcing.
 So it is with the Steig et al paper published last week. Their conclusions that West Antarctica is warming quite strongly and that even Antarctica as a whole is warming since 1957 (the start of systematic measurements) were based on extending the long term manned weather station data (42 stations) using two different methodologies (RegEM and PCA) to interpolate to undersampled regions using correlations from two independent data sources (satellite AVHRR and the Automated Weather Stations (AWS) ), and validations based on subsets of the stations (15 vs 42 of them) etc. The answers in each of these cases are pretty much the same; thus the issues that undoubtedly exist (and that were raised in the paper) — with satellite data only being valid on clear days, with the spottiness of the AWS data, with the fundamental limits of the long term manned weather station data itself – aren’t that important to the basic conclusion.
So it is with the Steig et al paper published last week. Their conclusions that West Antarctica is warming quite strongly and that even Antarctica as a whole is warming since 1957 (the start of systematic measurements) were based on extending the long term manned weather station data (42 stations) using two different methodologies (RegEM and PCA) to interpolate to undersampled regions using correlations from two independent data sources (satellite AVHRR and the Automated Weather Stations (AWS) ), and validations based on subsets of the stations (15 vs 42 of them) etc. The answers in each of these cases are pretty much the same; thus the issues that undoubtedly exist (and that were raised in the paper) — with satellite data only being valid on clear days, with the spottiness of the AWS data, with the fundamental limits of the long term manned weather station data itself – aren’t that important to the basic conclusion.
One quick point about the reconstruction methodology. These methods are designed to fill in missing data points using as much information as possible concerning how the existing data at that point connects to the data that exists elsewhere. To give a simple example, if one station gave readings that were always the average of two other stations when it was working, then a good estimate of the value at that station when it wasn’t working, would simply be the average of the two other stations. Thus it is always the missing data points that are reconstructed; the process doesn’t affect the original input data.
This paper clearly increased the scrutiny of the various Antarctic data sources, and indeed the week, errors were found in the record from the AWS sites ‘Harry’ (West Antarctica) and ‘Racer Rock’ (Antarctic Peninsula) stored at the SCAR READER database. (There was a coincidental typo in the listing of Harry’s location in Table S2 in the supplemental information to the paper, but a trivial examination of the online resources — or the paper itself, in which Harry is shown in the correct location (Fig. S4b) — would have indicated that this was indeed only a typo). Those errors have now been fixed by the database managers at the British Antarctic Survey.
 Naturally, people are interested on what affect these corrections will have on the analysis of the Steig et al paper. But before we get to that, we can think about some ‘Bayesian priors‘. Specifically, given that the results using the satellite data (the main reconstruction and source of the Nature cover image) were very similar to that using the AWS data, it is highly unlikely that a single station revision will have much of an effect on the conclusions (and clearly none at all on the main reconstruction which didn’t use AWS data). Additionally, the quality of the AWS data, particularly any trends, has been frequently questioned. The main issue is that since they are automatic and not manned, individual stations can be buried in snow, drift with the ice, fall over etc. and not be immediately fixed. Thus one of the tests Steig et al. did was a variation of the AWS reconstruction that detrended the AWS data before using them – any trend in the reconstruction would then come solely from the higher quality manned weather stations. The nature of the error in the Harry data record gave an erroneous positive trend, but this wouldn’t have affected the trend in the AWS-detrended based reconstruction.
Naturally, people are interested on what affect these corrections will have on the analysis of the Steig et al paper. But before we get to that, we can think about some ‘Bayesian priors‘. Specifically, given that the results using the satellite data (the main reconstruction and source of the Nature cover image) were very similar to that using the AWS data, it is highly unlikely that a single station revision will have much of an effect on the conclusions (and clearly none at all on the main reconstruction which didn’t use AWS data). Additionally, the quality of the AWS data, particularly any trends, has been frequently questioned. The main issue is that since they are automatic and not manned, individual stations can be buried in snow, drift with the ice, fall over etc. and not be immediately fixed. Thus one of the tests Steig et al. did was a variation of the AWS reconstruction that detrended the AWS data before using them – any trend in the reconstruction would then come solely from the higher quality manned weather stations. The nature of the error in the Harry data record gave an erroneous positive trend, but this wouldn’t have affected the trend in the AWS-detrended based reconstruction.
Given all of the above, the Bayesian prior would therefore lean towards the expectation that the data corrections will not have much effect.
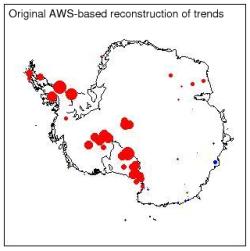
 The trends in the AWS reconstruction in the paper are shown above. This is for the full period 1957-2006 and the dots are scaled a little smaller than they were in the paper for clarity. The biggest dot (on the Peninsula) represents about 0.5ºC/dec. The difference that you get if you use detrended data is shown next.
The trends in the AWS reconstruction in the paper are shown above. This is for the full period 1957-2006 and the dots are scaled a little smaller than they were in the paper for clarity. The biggest dot (on the Peninsula) represents about 0.5ºC/dec. The difference that you get if you use detrended data is shown next.
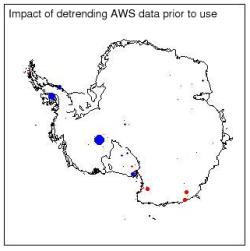
As we anticipated, the detrending the Harry data affects the reconstruction at Harry itself (the big blue dot in West Antarctica) reducing the trend there to about 0.2°C/dec, but there is no other significant effect (a couple of stations on the Antarctica Peninsula show small differences). (Note the scale change from the preceding figure — the blue dot represents a change of 0.2ºC/dec).
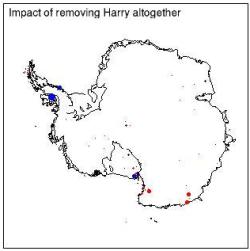 Now that we know that the trend (and much of the data) at Harry was in fact erroneous, it’s useful to see what happens when you don’t use Harry at all. The differences with the original results (at each of the other points) are almost undetectable. (Same scale as immediately above; if the scale in the first figure were used, you couldn’t see the dots at all!).
Now that we know that the trend (and much of the data) at Harry was in fact erroneous, it’s useful to see what happens when you don’t use Harry at all. The differences with the original results (at each of the other points) are almost undetectable. (Same scale as immediately above; if the scale in the first figure were used, you couldn’t see the dots at all!).
In summary, speculation that the erroneous trend at Harry was the basis of the Antarctic temperature trends reported by Steig et al. is completely specious, and could have been dismissed by even a cursory reading of the paper.
However, we are not yet done. There was erroneous input data used in the AWS reconstruction part of the study, and so it’s important to know what impact the corrections will have. Eric managed to do some of the preliminary tests on his way to the airport for his Antarctic sojourn and the trend results are as follows:
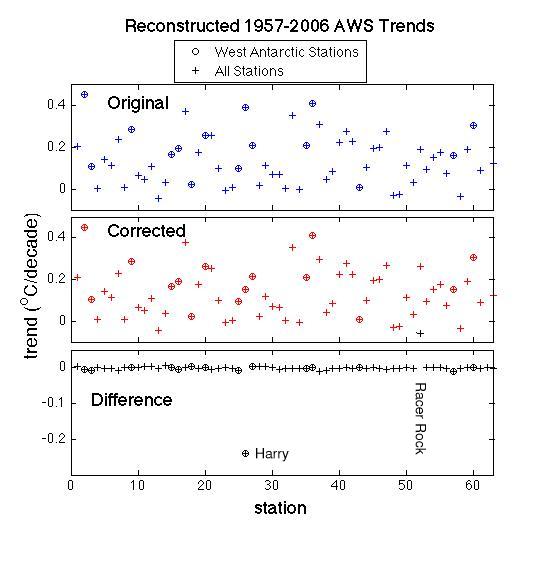
There is a big difference at Harry of course – a reduction of the trend by about half, and an increase of the trend at Racer Rock (the error there had given an erroneous cooling), but the other points are pretty much unaffected. The differences in the mean trends for Antarctica, or WAIS are very small (around 0.01ºC/decade), and the resulting new reconstruction is actually in slightly better agreement with the satellite-based reconstruction than before (which is pleasing of course).
Bayes wins again! Or should that be Laplace? ;)
Update (6/Feb/09):The corrected AWS-based reconstruction is now available. Note that the main satellite-based reconstruction is unaffected by any issues with the AWS stations since it did not use them.
Sorry for the digression, Gavin, my bad.
People, read the study. It’s mentioned here in a broader article:
http://www.unc.edu/~sanna/ljs07aesp.pdf (find “CDC” for that bit).
Here’s the source:
http://www.journals.uchicago.edu/doi/abs/10.1086/426605
DOI: 10.1086/426605
How Warnings about False Claims Become Recommendations
“… Repeatedly identifying a claim as false helped older adults remember it as false in the short term but paradoxically made them more likely to remember it as true after a 3 day delay. This unintended effect of repetition comes from increased familiarity with the claim itself but decreased recollection of the claim’s original context. Findings provide insight into susceptibility over time to memory distortions and exploitation via repetition of claims in media and advertising.”
These are the voters you’re looking for. Note how effectively the PR sites use this repetition of false claims. Don’t do it.
#49: Thanks, I like MY lawyer too. I hesitated and was going to put columnists but the original post I was alluding to used lawyers so I followed on.
#50: I apreciate the point but I belive there is much more to it than simply stating the myth, “care factor” and comprehension skills are just two of the most obvious. If repitition was the only thing at play then how does it explain the roaring success of badastronomy.com that (almost) single handedly turned the “moon landings were faked” from a long standing myth (with it’s own documentry) into an international joke?
Eric, you snark: ” What is there about the sentence, “The code, all of it, exactly as we used it, is right here,” that you don’t understand? “
I don’t understand how you think that could be true. You link to a nicely documented and from all appearances elegant library of matlab functions. Where are the data files? Where is the script that invoked those functions and plotted those graphs?
There is absolutely no substantive reason this should not be distributed along with the relevant publication. You shouldn’t be sniffing at people who want to replicate your work in toto. You should be posting a complete makefile that converts input data into output data. This is common practice in exploration seismology, thanks to the example of John Claerbout at Stanford University, and that in a field where there are sensible commercial reasons for confidentiality. A related effort, called Madagascar, is being developed at U Texas and is 100% open source.
The paradoxical backwardness of science in regard to adopting the social lessons of high tech is well analyzed in this blog entry by Michael Nielsen.
RC again climbs on its high horse, doing none of us any good. You guys are the good guys. Please act like it.
[Response: Michael, with all due respect, you are holding climate science to a ridiculously high ideal. i.e. that every paper have every single step and collation available instantly upon publication for anyone regardless of their level of expertise or competence. I agree that would be nice. But this isn’t true for even one of the 1000’s of papers published each month in the field. It certainly isn’t a scientific necessity since real replication is clearly best done independently and science seems to have managed ok up til now (though it could clearly do better). Nonetheless, the amount of supplemental information has grown enormously in recent years and will likely grow even more extensive in future. Encouraging that development requires that the steps that are being taken by the vanguard be praised, rather than condemned because there are people who can’t work out how to set up a data matrix in Matlab. And what do we do for people who don’t have access to Matlab, IDL, STATA or a fortran 95 compiler? Are we to recode everything using open source code that we may never have used? What if the script only runs on Linux? Do we need to make a Windows GUI version too?
Clearly these steps, while theoretically desirable (sure why not?), become increasingly burdensome, and thus some line needs to be drawn between the ideal and the practice. That line has shifted over time and depends enormously on how ‘interesting’ a study is considered to be, but assuming that people trying to replicate work actually have some competency is part of the deal. For example, if there is a calculation of a linear trend, should we put the exact code up and a script as well? Or can we assume that the reader knows what a linear trend is and how to calculate one? What about a global mean? Or an EOF pattern? A purist would say do it all, and that would at least be a consistent position, even if it’s one that will never be satisfied. But if you accept that some assumptions need to be made, you have a responsibility to acknowledge what they are rather than simply insist that perfection is the only acceptable solution. Look, as someone who pretty heavily involved in trying to open out access to climate model output, I’m making similar points to yours in many different forums, but every time people pile on top of scientists who have gone the extra mile because they didn’t go far enough, you set back the process and discourage people from even doing the minimum. – gavin]
Looks like there are more problems with BAS data identified over at CA.
[Response: Identified at BAS you mean. The first two changes are dealt with above, with only minimal impact. However, if you look at what was changed in the last two changes, it was only months with very spotty coverage which doesn’t make it into the mean monthly data used in the Steig et al paper. For instance, look at the difference between the .html and .txt files (http://www.antarctica.ac.uk/met/READER/aws/Clean_Air.All.temperature.txt and http://www.antarctica.ac.uk/met/READER/aws/Clean_Air.All.temperature.html). Obviously if any further errors are found, the analysis will be looked at again. – gavin]
My last OT post on “simplicity and clarity” vs “hard and fast rules” in mythbusting and science in general.
What I am saying is:
Politics and advertising aim to convince the audience via emotional resposes such as trust, fear, etc. Science aims to enlighten their audience by asking them to think, but i gets worse, science also asks it’s audience to be self critical in the first instance.
Some acedemic backup:
Dawkins, Sagan and many others have pointed out that a very large portion of mandkind who were taught science were taught the way I was (ie: a dictionary of factoids), most still do not even realise science is a philosophy, let alone what it is that’s unique about that philosophy.
My $0.02
If all you want to do is convince voters then by all means use a PR firm rather than a website such as this one. Personally I want to have my cake and eat it, ie: convince via enlightenment.
Re #48: See NASA sea surface topography information: http://topex-www.jpl.nasa.gov/index.html
Release the “complete code” or not?
(Assuming straight-forward code.)
Methinks to not immediately release it verbatim is a better service to science/software quality assurance:
1) If the complete code contains an error, then an unwitting auditor might run it and get the same (but wrong) values, and thus an error could get overseen.
2) If an auditor has to assemble the code independently, an error could be avoided (or perhaps a different one introduced), resulting perhaps in different values, and then it is clear that an error exists.
If existence of an error is established, THEN the complete code should be released asap to locate the error.
On the other hand, the complete code should be released ONLY after independent verifications have shown identical results.
There is good reason to keep some details “secret”.
(A good practice in software QM would be to recode things in an entirely different language. Not easy to grasp for some. I once got yelled at for verifying C/Tcl-generated results in Perl.)
Dear RC,
Isn’t part of the verification and peer review of these types of studies one that references the software used or/and written to analyse the data and the algorithms and testing proedures involved. I am presuming that all scientific software written for such purposes is of a scientific standard and if not then verified by other teams of developers to verify it.
Therefore I am presuming that CA and other peope raging/waging war here on this subject are in error about this study and its data sources, software, algorithms and methods used. All completely scientific in nature and valid?
So what evidence do you have that a study such as this, working with a presumably random sample of older people, applies to the kind of self-selecting, possibly more educated than average, and on average likely younger audience scavenging for knowledge at a science site?
I’d say you’re skating on thin ice to claim that the efficacy of myth debunking in a science blog addressing such an audience necessarily parallels the efficacy of advertisements during Perry Mason reruns (for instance).
I don’t buy it, I doubt that you have supporting data, and I will continue to repeat and debunk myths in forums such as this whenever I please.
#54 R
“Obviously if any further errors are found, the analysis will be looked at again.”
Just to clarify, I take it by the title of the thread that RC’s view is that Nature’s cover story is sound, the data are robust, and the the last week’s questions and corrections amount to mere quibbles. Further, RC is convinced that these errors are stand-alone, and do not indicate potential sloppiness in the rest of the data. Do I assume correctly?
[Response: The results featured on the cover and in the paper are based on AVHRR satellite data, not AWS data. The latter was used only as a secondary check on the results. And even the results using the AWS data are insensitive to the issues raised thus far. Really not that difficult to understand. -mike]
Gavin,
In response to #53 you say that:
“you are holding climate science to a ridiculously high ideal. i.e. that every paper have every single step and collation available instantly upon publication for anyone regardless of their level of expertise or competence”
I agree that this is a very high standard, and one that is not realistic.
But it IS important that sufficient information be released that experts in the field can replicate your results.
Pointing somebody to the Matlab RegEM package and to the original source data is most certainly not sufficient.
[Response: For someone who is an expert? For sure it’s enough. I might post on a recent replication exercise I did and how it really works, rather than how people think it should work. – gavin]
[edit – Eric isn’t here to discuss this, and so lay off that until he is.]
I fail to see how access to the code is useful to anyone other than the crank and the dilettante. The code is not the process being described. The code isn’t the reality. A scientist hoping to duplicate the results of an experiment would go his own way.
pete #58.
Try writing that again. There is nothing that lasts long enough to work out what you’re saying.
E.g. if you’re saying that all data has to be made available and all processes, then you’re wrong. The paper itself has enough information to say what the conclusions and the way they were arrived at was.
You can recreate a similar study and if you get a different answer, you can post that you had a different result. If you got the same, post that you got the same result through a different avenue (this proves the robustness of the original conclusion).
Full data disclosure can HELP when such a repeat test comes up with an experimental answer that is different in that why can be investigated (but BOTH systems need their original data exchanged. After all, the second could be wrong.
However, full disclosure can be BAD. If you just repeat the same thing, you may not have any different result since you repeated the same thing. And thereby miss out on the inherent error in the original.
But it can also be bad if you pass all your info to all and sundry. Then someone sees a fit that looks odd and complains. Not knowing that this was already countered within the original paper. Why? Because they aren’t looking for how accurate the paper is, they’re looking for how it could be WRONG. Skeptical of the paper, they are not skeptical of their own conclusions.
A bit like some of the more infamous names on RC.
HOWEVER
I don’t know whether this post was needed. Your post was that bad.
In reply to Gavin at #53:
I agree that there is no general solution. Indeed, I have just spent two weeks trying to get CAM3.1 running on a machine where it worked fine eight months ago! Distributing HPC cluster code and helping people run it is a huge problem, but not the one I am addressing here.
It’s clear we are talking about pure Matlab scripts in the present case. That’s a different matter: moderate sized plain text scripts running on a widely available commodity platform. Stuff you can archive and track and ship. Stuff that could be extremely useful to other people doing research on related matters, whether they are our colleagues or self-appointed “auditors”.
The basis for my complaint is the claim that a URL pointing to the libraries can realistically be called not just “the code” but “all of it” with emphasis (editorial comment to #6 above).
That is simply and, to anyone who actually touches code, obviously, ridiculously, false.
Whether actually keeping track of the complete workflow with each bit of output is onerous is another question. It is indeed the case that climate scientists are not trained to do so, but in fact once you get in the habit, it turns out to be considerably less work, rather than more so. Since this is well-known to commercial programmers, (or even commercial designers and writers) who tend to be better trained in software tools, their expectation is that you are being disingenuous rather than just missing the point of how software (and other digital production) is normally produced in professional settings.
So there are really two main questions: if this is hard work for the scientist, for heaven’s sake, why is it hard work? (And the corrolary: how are you confident that your results are correct?)
The second question is, if you have the workflow properly organized, should you share it? In most cases the answer to this second question would, in my opinion, be affirmative.
Claiming that “the code, all of it” is at the link provided in #6 is risible. It doesn’t help in improving the reputation of climate science, which I thought after all was a main point of the exercise here.
A single statement by an RC editor that is demonstrably and visibly false is a very large error. You guys have taken on a big and important job with this site, and you have my gratitude and respect for it. However, that implies taking some care to avoid obvious and embarrassingly wrong mistakes. This sort of thing is costly, and you need to take as much care with your commentary as with your articles.
Finally, there is the question as to why scientists refuse to make any explicit effort to learn anything or adopt anything from the private sector in matters of management or software development in particular. This is a long-standing complaint of mine. Scientists have an attitude that we are in some sense superior to other professionals. We are different but not especially smarter or better, and our isolation does us no credit.
[Response: Michael, you are grossly overstating your case here. “scientists refuse”? In general? This is obviously false. Scientists are adopting new things all the time – but there is a learning curve which can’t be wished away, and people have to have a good idea that it is worth learning something new. To that end, the importance of the IPCC AR4 archive in demonstrating to modelling groups the benefit from external analysis can not be overstated. Showing that this helps the scientific process is much more efficient than hectoring scientists about how closed minded they are. Scientists are actually quite rational, and allocate investments according to relatively well known potentials for return. This doesn’t change in an afternoon because someone comes up with a neat API for a new python script. – gavin]
Dr. Schmidt, I think you are taking the argument about posting code and processes to the extreme. No one is assuming that you have to do something so that someone who is not literate in the particular area can reproduce the result. On the other hand having read through the on line description of methods in the paper I can’t conceive of how I would even begin to process the satellite data. I don’t know which sites have been selected and why, and I’m sure I don’t know what functions precisely with various options would be required.
Having looked at the AWS data for example I’m sure that Dr. Steig has scraped it from the original site. I’m equally certain that the satellite data has been scraped and processed from the original site. I think a reasonable request is to simply make available the data files and intermediate steps in their current form. Essentially what Dr. Steig has said that he provides to “legitimate” researchers.
As a final note, while putting up the complete process and data may sound burdensome, it is my experience that the discipline of putting this together in a repeatable way would most likely save time in the long run when doing this type of work, as well as substantially improving the quality. This is why it is standard practice in commercial enterprises.
[Response: Open source is not standard in commercial enterprises. – gavin]
This is something that I have had difficulty following from the paper. If the AVHRR data only begins in 1979 how can it be the main source of the trends that begin in 1957?
[Response: It’s not. The trends come primarily from the long-term manned stations. The spatial pattern comes from the satellites. – gavin]
Well, here’s what Jeff Id is really saying …
[edit — thanks for your support dhogaza, but I’m not allowing ‘jeff id’s’ rants to show up here, even if passed on to me by someone else–eric]
Minus the bluster at the end, it’s the same-old same-old – climate science is a fraud.
People like this should simply be ignored. He’s going to claim fraud no matter how patient
Eric is or how much help Eric gives him.
[edit]
If Jeff Id wants to be taken seriously, then he should follow the example of “John V” of opentemp.org and perform his own independent analysis.
IIRC, What started out as a skeptic’s (John V’s) critical look at GISSTemp turned out to be a nice confirmation of the quality of the GISSTemp product. And that, as I recall, kinda took the wind out of surfacestations.org’s sails.
So this is also unclear to me from the paper. So the occupied land station results are used unmodified, but the satellite data is used to compute how temperatures in unmeasured areas co vary with the manned weather stations?
[Response: Yes. – gavin]
Also since the results were changed albeit only slightly with the change in the AWS data they are influencing the trends in some way. Are they used as primary data like the manned sites, or more in the way that the satellite data is used to fill in the gaps?
[Response: Just like the satellite. – gavin]
Dr. Schmidt, as the chairman of a public company that produces one of the most popular open source reporting products in the world I know for a fact that large commercial enterprises use open source every day! We can start with Apache and go from there. (Can I include a plug? :-)
Re#63, Nicolas.
Perhaps your request is reasonable… similarly, I’d like to see all correspondence between the American Petroleum Insitute directors, their PR firm Edelman, and the corporate management of all the members of the American Petroleum Institute. A complete record of all communications between Edelman & API employees and media corporation managers would be great, too.
Likewise, can we have the same for all members of the Edison Electric Insitute (the coal-electric lobby group) and the Western Fuels Association?
As you say, “As a final note, while putting up the complete process and data may sound burdensome, it is my experience that the discipline of putting this together in a repeatable way would most likely save time in the long run when doing this type of work, as well as substantially improving the quality. This is why it is standard practice in commercial enterprises.”
Unfortunately, the API doesn’t have a very good record:
There’s nothing new about this: in 1998, the API was caught trying to recruit “independent scientists” to act as covert spokespeople for their agenda: INDUSTRIAL GROUP PLANS TO BATTLE CLIMATE TREATY, By JOHN H. CUSHMAN JR, April 26, 1998
It appears that they’ve run out of credible “independent third party spokespeople” – but it would be nice to have the complete record of all their activities – don’t you agree?
Following up on my earlier post, after reading Dr. Schmidt’s reply to my query and going back to the article I think I can explain in English how this reconstruction worked. I think it is pretty clever, which I guess shouldn’t be surprising.
They wanted to figure out continent wide trends for the Antarctic over a significant period of time, but the issue is that the sites providing temperature data are quite sparse, with poor coverage in some areas. However since about 1979 there is satellite coverage that can be used for temperature measurement. So what they did was to take observations during the period of time where there was satellite coverage and see whether they could predict the temperature of the areas covered by satellite alone. They additionally tested using AWS data to see if they could predict that.
The math to do the prediction is non trivial as it seems the covariance depends on things like the season, and other factors, but including all these factors they report that they get a good result. In other words by plugging the manned station data into their prediction machine they come up with a reasonable approximation of the values that are recorded by the satellite and the AWS.
To test this they made sure that the system worked well in two different time periods of the satellite era. It seems they also took the most complete 15 manned sites and ran it through the engine to see if it did a good job of predicting the other sites. I can’t tell whether they did this for the entire temperature record, or just the satellite era.
They then ran their engine from the pre satellite era to the satellite era to fill in the gaps in spatial coverage. I assume that in the satellite era they just filled in using the actual satellite data. This is probably automatic with the Regem algorithm.
I would like to verify that they tested over the entire period the ability of the 15 “best” sites to predict the rest of the sites. Then the only other question is whether the manned station data is solid over the entire period from 1957.
Eric’s remark appears to have set off quite a blogsturm, but if you go past the first few pages Google finds you’ll see his offer was serious:
OCEANOGRAPHY … INTRODUCTORY TOPICS WILL INCLUDE THE BASICS OF:
1) USING MATLAB 2) STATISTICS FROM DATA 3) LINEAR …
15613 A 3 TTh 1000-1120 JHN 027 STEIG,E Open 4/ 5 J …
http://www.washington.edu/students/timeschd/SPR2007/ocean.html
Does MIT have an online free course that teaches the equivalent?
Clearly a lot of people do want to learn how to use MatLab.
Here’s one page that discusses making MATLAB available online:
http://hess.ess.washington.edu/math/docs/al_be_stable/al_be_calc_paper_v2.pdf
“The MATLAB Web Server is an extension to MATLAB that allows a web browser to submit data to a copy of MATLAB running on a central server, and receive the results of calculations, through standard web pages. We have chosen to use a central server, rather than distributing a standalone application that runs on a user’s personal computer, because: i) the web-based input and output scheme is platform-independent; ii) the existence of only a single copy of the code minimizes maintenance effort and ensures that out-of-date versions of the software will not remain in circulation; and iii) the fact that all users are using the same copy of the code at a particular time makes it easy to trace exactly what method was used to calculate a particular set of results.”
Note in that paper that even with those precautions, more accurate calculation than MATLAB provides can be done; they say which scientists’ papers to consult. You’ll recognize some of the names.
Point being — a brief search turns up, besides the current tsurris, quite a few serious studies associated with Eric’s name and MATLAB use. Many of those describe various ways of teaching the tool, or refer to ways to get better results when MATLAB isn’t sufficient. Some of the websites you’ll find offer links to toolkits and tutorials.
This is not all that hard to find, and I’d never looked for it til now. People who sit demanding what they want be brought to them need to get up and go ask a librarian what’s available for the asking.
Else you get multiple copies of advice — all outdated — accumulating. That’s seriously discussed as a problem.
The cautions therein are being illustrated in this thread as people demand access to a toolbox.
J. Baldwin of the old Whole Earth Catalog cautioned:
You don’t know how to use a tool until you know six ways to break it — or break what you’re working on with it. You will learn.
This true statement is very different than your original false statement which was:
Open Source is not standard practice in commerical enterprises.
If you believe it is, perhaps you can point me to vendor-authorized sources for:
1. MS Vista
2. Oracle 10g
3. Adobe PhotoShop CS
4. Apple Aperture
This list is not meant to be complete.
#69,
API hides and otherwise obfuscates its correspondence because they have something to hide. Their results are tainted by their agenda, and access to their internal correspondence would reveal that.
Steig et al do not have anything to hide. We (or at least most of us) assume that their methodology is free of any material bias.
It is for this reason that we expect much greater disclosure.
Steig et al is NOT some advocacy paper by a paid interest group. It is a Nature cover story. Our expectations are justifiably different.
I know correlation is not causation, but in re those deniers who say the correlation between temperature and CO2 is vague and temporary, here’s where I checked and found out they were dead wrong:
http://www.geocities.com/bpl1960/Correlation.html
Remove the hyphen before pasting the URL into your browser.(fixed!)
Open Source is not standard practice in commerical enterprises.
As an employee of a commercial software vendor (mentioned in post #70) I can assure you that open source IS a standard in most, if not all, of the Fortune 100 companies that I work with. Dr. Schmidt, if you have a cite that says otherwise, I’d be glad to see it. As it is, I’m not inclined to take your statement as fact.
[Response: That’s great. But it is clearly true that most commercial software is not open source: SAP, Windows, Oracle, Adobe etc. Someone must be keeping them in business. – gavin]
Re: #3 (Ricki),
What will it take to really close the deniosphere? Do we need more ground-based temperature stations in Antarctic?
The nails in the coffin are not doing the job. For example, on Feb. 18th in Minnetonka, MN … “Wiita’s class will show the Al Gore movie “An Inconvenient Truth,” which suggests man is to blame for a warming planet, and the British-made movie “The Great Global Warming Swindle,” which suggests Al Gore’s claims are a farce.” …
Is this the best they can do? Who should teach and what should be shown?
http://www.chanvillager.com/news/schools/climate-change-open-discussion-minnetonka-101
Gavin (#53),
I have no horse in this race and I won’t doubt the science because of trifles such as this one but I have to say that I’m disappointed.
Of course there’s no need to release anything in order to prove that the paper is not a fraud or something…
[edit – Eric isn’t around to respond to these kinds of claims, and I do not want to speak for him. Please lay off until he can answer fro himself]
I find the notion that scientists should adopt PR practices quite repelling by the way. PR may fool some people but hopefully not the types who would follow a blog such as RC.
Which is why y’all have the same expectations for work done in all fields of science, not just climate science, right? I mean … when Nature publishes a paper on particle physics y’all flood the blogosphere with demands for immediate publishing of all the data, code, etc used by the researchers, right? Y’all are pestering CERN and other facilities for the source code to all the software that runs various colliders, instruments, etc, right?
I hope any perception on my part that perhaps climate science is being singled out due to political considerations is proven false by evidence that a steady, unwavering series of requests for openness greets the publication of every paper in Science, Nature and other high-profile papers, regardless of subject matter.
Can you help me out a bit here? Can you document that authors of papers in other fields are being held to the same level of criticism and subjected to the same pressure as climate scientists?
Is there a “physics audit” or “population ecology audit” site you could point me to, to put any perception of bias I might hold to rest?
#70: why not do that yourself? If the figures are the same then the authors can continue without interruption.
Oracle says: Masses arriving.
He knows his stuff…
> “… is a standard”
That’s the nice thing about standards.
There are so many of them.
dhogaza says:
“Which is why y’all have the same expectations for work done in all fields of science, not just climate science, right?”
Climate Science affects many of us very personally, as it will take each one of us doing his part to solve this crisis. I can tell you that is the highest reason this topic is so heated.
You and your boss are making the claim, *you* provide the cite.
I’m curious, is this an ANSI standard or ISO open source standard Fortune 100 companies are following.
Or, perhaps, are you claiming that many Fortune 100 companies *use* some open source software?
Which of course is totally irrelevant to the original claim, which is that it’s standard practice for business to release the source to *their* code.
You guys aren’t just moving the goalposts, you’re knocking them to the ground.
#69 ike solem:
API as referenced in Gavin’s response in #63 refers to “Application Programming Interface”, not “American Petroleum Institute”.
Gavin, Many of us concerned citizens really appreciate the long hard work you guys put in to try to keep the public informed. We owe a great deal of what we have learned about climate change from you and other dedicated scientists like James Hansen. My children & grandchildren & I thank you. Keep up the good work.
What is the best link at RealClimate that addresses in layman terms why the Milankovitch cycles are not the principal cause of the global warming we have been experiencing since the 1800s? Or is there a better treatment of the subject elsewhere, for laymen of course?
I often encounter claims that Milankovitch cycles are to blame for the current warming, esp. by self-proclaimed earthscientists at blogs like SciGuy. thx http://blogs.chron.com/sciguy/archives/2009/01/since_the_skept.html#c1231955
[Response: Try the IPCC FAQ 6.1, 2.1, and perhaps Coby. – gavin]
> the notion that scientists should adopt PR practices …
And where did read this notion? Not here. You think that was said somewhere? And why do you trust the source?
Nobody suggested scientists adopt PR methods. I (a reader, not a scientist) suggested that repeating bad information, because we know doing so makes the bad information more memorable. I and a third reader pointed to the research. That’s about how people learn and remember facts.
Whoever’s spinning this is really good — at PR. You believed it.
dhogaza wrote: “Can you document that authors of papers in other fields are being held to the same level of criticism and subjected to the same pressure as climate scientists?”
Scientists in other fields whose work has illuminated certain “inconvenient truths” that threatened the profits of wealthy, powerful industries — e.g. the tobacco, meat or pesticide industries — have been subjected to similar pressures, similarly bogus “skepticism”, and similar accusations of “ideological” motives.
RE:
Michael Tobis #53
Jason #61
Michael Tobis #64
Nicolas Nierenberg #65
Anonymous Coward #78
Transparency, is always good, whether in business or in science. Anytime someone avoids transparency, it doesn’t mean they have something to hide, but it makes you wonder. And I think that is really the crux of this type of issue. Archiving (which really means publishing) the code and data used to perform the research has many benefits and no downside. If the methods used are correct, then confidence in your research is enhanced. If your methods are not correct, then they can be corrected and science is advanced.
I don’t think that reasonable people are going to hold your code to same standard as commerical software. Noone expects research code to be anywhere nearly as robust as a commercial software package, but clearly it must meet some minimum standards. Basically that it correctly performs as intended. While I don’t dispute the argument that there would be some overhead involved in properly archiving this information, it is minimal and has to be less than the amount of time spent justifying not archiving it.
To me the bottom line is, if you are confident that your methodology is correct, you have no reason not to archive it, and the only reason not to archive it would you that you are not confident that your methods are correct. As Michael Tobis says in #53: “You guys are the good guys. Please act like it.”
@Bart Paul Levenson,
Thanks for the link to your “test” page! I have just one nit pick and one suggestion. The nit pick is that you said “(this data uses the mean for 1961-1990 as the base figure).” I do believe that GISS uses 1951-1980 as the “base figure”. The suggestion is that you put keep that table up to date for each new year. That way when I link to your to page the inactivist can not claim that the link is dated.
Once again I want to say thanks for the effort.
Heh … yes, SecularAnimist, but it’s not just because they were publishing in highly-regarded journals and therefore held to “higher standards” by “critics” whose only interest was to “hold science to the highest standard”. :) Just like climate science …
Florifulgurator #57) “If an auditor has to assemble the code independently, an error could be avoided (or perhaps a different one introduced), resulting perhaps in different values, and then it is clear that an error exists.”
Yes, but where does the error exist? The best way to find out would be a direct comparison of the two codes, but you only have one.
[Response: But you save a huge amount of effort if the independent replication of the result is achieved without that, and that can add a great deal of scientific progress over and above checking someone’s arithmetic. See this comment I made when this came up previously. – gavin]
Re: #88 (Mike Walker)
The downside is that the level of transparency demanded by far too many “hacks” is work. And when vultures are waiting to tear it to shreds because they want to undermine science rather than advance it, it’s vastly more work. When you’re underfunded in spite of your research being critical to the future progress of civilization, and you have way better things to do than respond to an endless stream of critics with an agenda, you have to make a choice: is my time better spent providing transparency for those who don’t really want that but just want to find fault, or is my time better spent advancing our knowledge of climate science?
Believe it or not, science already has self-correction mechanisms. Responsible scientists report corrections to the interested parties and knowledge is improved. Vultures blog about what a fraud the scientists are.
Gavin wrote:
“I might post on a recent replication exercise I did and how it really works, rather than how people think it should work.”
1. It looks like you did NOT replicate the results in question. :)
2. Although I haven’t even read your paper (I have read the paper I imagine you are failing to replicate) I can confidently predict that the authors of the original analysis will blame your non-replication on your use of different procedures, procedures which they deem less legitimate than those employed in the original paper.
Certainly the details of what you and they did in your respective analyses is highly relevant, and absolutely essential to resolving the discrepancy.
If non-scientists are going to tell scientists how to do their job, should there be some tit-for-tat?
Like, say, maybe scientists should insist that professional software engineers should be required to prove their software correct, using the mathematical methods developed in the late 1960s and early 1970s.
Since non-practitioners are apparently more qualified than practitioners to determine what practices are acceptable in any given field, software types telling scientists how to do their job shouldn’t balk if scientists insist that software types provide proofs of correctness, right?
Terry #76. Your statement is almost categorically refuted by ANY open discussion thread that talks about FOSS software and especially about how Linux is ready (or not) for the desktop.
Pop over to El Reg for example (www.theregister.co.uk). Slashdot (slashdot.org) and ZDNet (www.zdnet.com).
Reading that you get the distinct impression that ANY FOSS program is infinitely inferior to any Microsoft product and that NO “real” company would use it. And anyone looking after such a system is
a) Expensive
b) Hard to find
c) Irreplacable
d) not a replacement for the Easy, Secure MS AD system that Works So Well(tm)
Not to mention the strange names.
Either this horde is a bunch of trained and paid shills or your assertion is incorrect.
BPL #75. It’s even more inane than that. There is causation and correlation is used to TEST IF THE CAUSE IS SEEN!!!!
It isn’t “Hey, we have warming temperatures. Wonder what’s causing it. CO2 fits the bill, we’ll go with that”.
It’s “Hey, CO2 is being pumped out and that’s a greenhouse gas. I wonder if there’s evidence of this happening in the real world? If it is, we may need to rethink our energy strategy.”.
Dr. Schmidt,
I was hoping for an attaboy for my brief explanation (post #71) of how the study worked. It may have been obvious to you, but I had the feeling that very few people on this blog actually understood it. The study is very clever, interesting, and well worth understanding. Anyway I guess I just gave myself one!
For me this blog worked brilliantly in this case. I asked a couple of clarifying questions, went back and read the article again, and the light went on. Thanks!
As to open source I must be missing your point about this. I don’t understand how that was related to my post #65 which doesn’t mention open source.
You might want to read the paper before claiming that Gavin didn’t do what he claims to have done. The paper describes the calculations performed, and notes items that were clarified by the author of the original paper with personal communication (helping ensure that the calculations were, indeed, replicated).
The paper also notes that more recent datasets were used – this doesn’t affect Gavin’s claim that the original paper’s methodology was replicated.
Gavin reaches a different conclusion than the authors of the original paper, but not because he didn’t replicate their methodology.
BTW still waiting for the vendor-authorized source release of Oracle 10g, in particular. I’d like to hack it to be more compliant with the latest SQL standard, and this is impossible without the source.
dhagoza, how about myself, an unknowing ordinary guy (as far as knowing how petrol works) demand proof from the oil companies that their product isn’t safe and isn’t going to go all apocalyptic on us when we hit a magic number? I mean, I don’t know how it COULD destroy the earth, but has ANYONE checked to see if the earth will explode when we take out 100 more barrels?
I DEMAND PROOF!!!
PS I demand they stop now until they know and have proven that oil extraction is safe and will not cause the world to explode.