The difference between a single calculation and a solid paper in the technical literature is vast. A good paper examines a question from multiple angles and find ways to assess the robustness of its conclusions to all sorts of possible sources of error — in input data, in assumptions, and even occasionally in programming. If a conclusion is robust over as much of this as can be tested (and the good peer reviewers generally insist that this be shown), then the paper is likely to last the test of time. Although science proceeds by making use of the work that others have done before, it is not based on the assumption that everything that went before is correct. It is precisely because that there is always the possibility of errors that so much is based on ‘balance of evidence’ arguments’ that are mutually reinforcing.
 So it is with the Steig et al paper published last week. Their conclusions that West Antarctica is warming quite strongly and that even Antarctica as a whole is warming since 1957 (the start of systematic measurements) were based on extending the long term manned weather station data (42 stations) using two different methodologies (RegEM and PCA) to interpolate to undersampled regions using correlations from two independent data sources (satellite AVHRR and the Automated Weather Stations (AWS) ), and validations based on subsets of the stations (15 vs 42 of them) etc. The answers in each of these cases are pretty much the same; thus the issues that undoubtedly exist (and that were raised in the paper) — with satellite data only being valid on clear days, with the spottiness of the AWS data, with the fundamental limits of the long term manned weather station data itself – aren’t that important to the basic conclusion.
So it is with the Steig et al paper published last week. Their conclusions that West Antarctica is warming quite strongly and that even Antarctica as a whole is warming since 1957 (the start of systematic measurements) were based on extending the long term manned weather station data (42 stations) using two different methodologies (RegEM and PCA) to interpolate to undersampled regions using correlations from two independent data sources (satellite AVHRR and the Automated Weather Stations (AWS) ), and validations based on subsets of the stations (15 vs 42 of them) etc. The answers in each of these cases are pretty much the same; thus the issues that undoubtedly exist (and that were raised in the paper) — with satellite data only being valid on clear days, with the spottiness of the AWS data, with the fundamental limits of the long term manned weather station data itself – aren’t that important to the basic conclusion.
One quick point about the reconstruction methodology. These methods are designed to fill in missing data points using as much information as possible concerning how the existing data at that point connects to the data that exists elsewhere. To give a simple example, if one station gave readings that were always the average of two other stations when it was working, then a good estimate of the value at that station when it wasn’t working, would simply be the average of the two other stations. Thus it is always the missing data points that are reconstructed; the process doesn’t affect the original input data.
This paper clearly increased the scrutiny of the various Antarctic data sources, and indeed the week, errors were found in the record from the AWS sites ‘Harry’ (West Antarctica) and ‘Racer Rock’ (Antarctic Peninsula) stored at the SCAR READER database. (There was a coincidental typo in the listing of Harry’s location in Table S2 in the supplemental information to the paper, but a trivial examination of the online resources — or the paper itself, in which Harry is shown in the correct location (Fig. S4b) — would have indicated that this was indeed only a typo). Those errors have now been fixed by the database managers at the British Antarctic Survey.
 Naturally, people are interested on what affect these corrections will have on the analysis of the Steig et al paper. But before we get to that, we can think about some ‘Bayesian priors‘. Specifically, given that the results using the satellite data (the main reconstruction and source of the Nature cover image) were very similar to that using the AWS data, it is highly unlikely that a single station revision will have much of an effect on the conclusions (and clearly none at all on the main reconstruction which didn’t use AWS data). Additionally, the quality of the AWS data, particularly any trends, has been frequently questioned. The main issue is that since they are automatic and not manned, individual stations can be buried in snow, drift with the ice, fall over etc. and not be immediately fixed. Thus one of the tests Steig et al. did was a variation of the AWS reconstruction that detrended the AWS data before using them – any trend in the reconstruction would then come solely from the higher quality manned weather stations. The nature of the error in the Harry data record gave an erroneous positive trend, but this wouldn’t have affected the trend in the AWS-detrended based reconstruction.
Naturally, people are interested on what affect these corrections will have on the analysis of the Steig et al paper. But before we get to that, we can think about some ‘Bayesian priors‘. Specifically, given that the results using the satellite data (the main reconstruction and source of the Nature cover image) were very similar to that using the AWS data, it is highly unlikely that a single station revision will have much of an effect on the conclusions (and clearly none at all on the main reconstruction which didn’t use AWS data). Additionally, the quality of the AWS data, particularly any trends, has been frequently questioned. The main issue is that since they are automatic and not manned, individual stations can be buried in snow, drift with the ice, fall over etc. and not be immediately fixed. Thus one of the tests Steig et al. did was a variation of the AWS reconstruction that detrended the AWS data before using them – any trend in the reconstruction would then come solely from the higher quality manned weather stations. The nature of the error in the Harry data record gave an erroneous positive trend, but this wouldn’t have affected the trend in the AWS-detrended based reconstruction.
Given all of the above, the Bayesian prior would therefore lean towards the expectation that the data corrections will not have much effect.
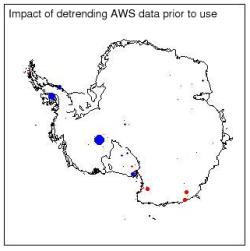 The trends in the AWS reconstruction in the paper are shown above. This is for the full period 1957-2006 and the dots are scaled a little smaller than they were in the paper for clarity. The biggest dot (on the Peninsula) represents about 0.5ºC/dec. The difference that you get if you use detrended data is shown next.
The trends in the AWS reconstruction in the paper are shown above. This is for the full period 1957-2006 and the dots are scaled a little smaller than they were in the paper for clarity. The biggest dot (on the Peninsula) represents about 0.5ºC/dec. The difference that you get if you use detrended data is shown next.
As we anticipated, the detrending the Harry data affects the reconstruction at Harry itself (the big blue dot in West Antarctica) reducing the trend there to about 0.2°C/dec, but there is no other significant effect (a couple of stations on the Antarctica Peninsula show small differences). (Note the scale change from the preceding figure — the blue dot represents a change of 0.2ºC/dec).
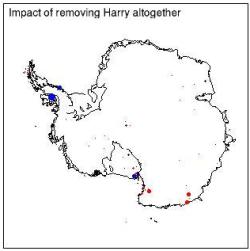 Now that we know that the trend (and much of the data) at Harry was in fact erroneous, it’s useful to see what happens when you don’t use Harry at all. The differences with the original results (at each of the other points) are almost undetectable. (Same scale as immediately above; if the scale in the first figure were used, you couldn’t see the dots at all!).
Now that we know that the trend (and much of the data) at Harry was in fact erroneous, it’s useful to see what happens when you don’t use Harry at all. The differences with the original results (at each of the other points) are almost undetectable. (Same scale as immediately above; if the scale in the first figure were used, you couldn’t see the dots at all!).
In summary, speculation that the erroneous trend at Harry was the basis of the Antarctic temperature trends reported by Steig et al. is completely specious, and could have been dismissed by even a cursory reading of the paper.
However, we are not yet done. There was erroneous input data used in the AWS reconstruction part of the study, and so it’s important to know what impact the corrections will have. Eric managed to do some of the preliminary tests on his way to the airport for his Antarctic sojourn and the trend results are as follows:
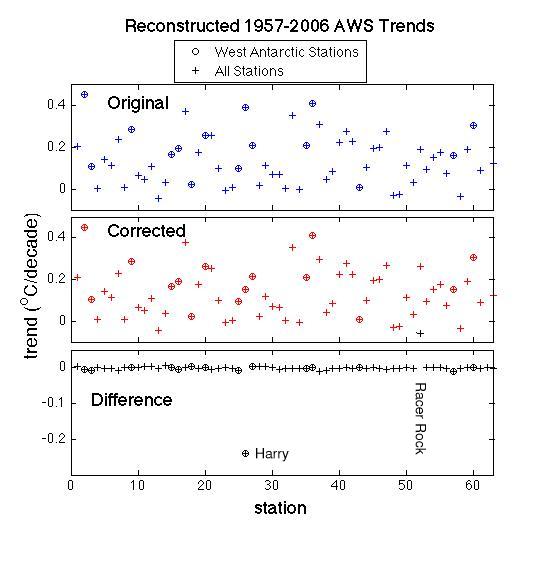
There is a big difference at Harry of course – a reduction of the trend by about half, and an increase of the trend at Racer Rock (the error there had given an erroneous cooling), but the other points are pretty much unaffected. The differences in the mean trends for Antarctica, or WAIS are very small (around 0.01ºC/decade), and the resulting new reconstruction is actually in slightly better agreement with the satellite-based reconstruction than before (which is pleasing of course).
Bayes wins again! Or should that be Laplace? ;)
Update (6/Feb/09):The corrected AWS-based reconstruction is now available. Note that the main satellite-based reconstruction is unaffected by any issues with the AWS stations since it did not use them.
Tell it to Google.
As for your other posts, I have no idea what you’re talking about.
re: 88 Mike Walker
I’m always interested in why people believe what they believe, because often differing beliefs come from different histories. [We’ve gone through multiple cases here of that due to differing experiences with different kinds of software models].
Can you tell us some more where your opinions about software come from? I.e., what sorts of software development (product, research, application domain, sizes, staffing) you’ve been involved with?
dhogaza #94 -6 February 2009 at 4:51 PM wrote: “Like, say, maybe scientists should insist that professional software engineers should be required to prove their software correct, using the mathematical methods developed in the late 1960s and early 1970s.”
Let me get this right, you are saying climate science shouldn’t be held to a high standard because the computer software industry isn’t? Even if your insights about the software industry are correct, that hardley sounds like a logical argument. “Why should I have to eat my spinach if he doesn’t?”
Most large business have become very strict about software standards compliance in the last 10 years. Very few of our customers will accept software that is not ISO 90003 compliant, and in the US, SOX compliance is also mandatory. Meeting these standards is expensive, but it is no longer optional for most software companies that sell B2B.
tamino #92 6 February 2009 at 4:45 PM wrote: “The downside is that the level of transparency demanded by far too many “hacks” is work. And when vultures are waiting to tear it to shreds because they want to undermine science rather than advance it, it’s vastly more work.”
If the science is correct it will stand on its own. I recently read about the efforts to disprove Einstein’s theory of relativity in the early 20th century. We tend to think of relatively as something that has always been accepted, but it met with a lot of resistance when he first proposed it. And the only reason that it is accepted now is because it was vigorously tested and many people tried to prove him wrong.
Again, I think it boils down to this, if your methods are correct, then transparency will prove that. The only reason to oppose transparency is if you are not confident.
[Response: No, often it’s just a desire not to waste time, because as you say, the science will out. – gavin]
dhogaza 6 February 2009 at 4:51 PM writes: “Since non-practitioners are apparently more qualified than practitioners to determine what practices are acceptable in any given field, software types telling scientists how to do their job shouldn’t balk if scientists insist that software types provide proofs of correctness, right?”
I think climate science would benefit greatly if it accepted more help from professional statisticians and professional software developers. No one can be expected to be an expert at everything. You won’t find me making critical statements about the scientific or statistical elements of the research, because I am not qualified to do so. But software development is my area of expertise.
IMO software development experience has almost nothing to do with climatology,
Maybe we could stick with the latter here on RealClimate?
John Mashey #101: 6 February 2009 at 6:35 PM writes: “Can you tell us some more where your opinions about software come from? I.e., what sorts of software development (product, research, application domain, sizes, staffing) you’ve been involved with?”
I am the founder and CEO of a small computer software development company I founded 25 years ago, snf that specializes in providing ERP related software to large agricultural companies. Our systems integrate financial and operational data to perform planning and forecasting functions. These systems are based heavily on financial and operational data analysis and utilize both statistical and physical models as well as linear programming to plan and monitor company operations. My company has about 50 development staff, not counting specialized consultants working under contract such as mathematicians, accountants and veternarians. We have customers on every continent except Antartica. A typical customer would be Cargill, Inc., so we work mostly with large companies.
I am NOT an AGW skeptic. But I do have a number of criticisms of climate science in its current state, mostly based on issues relating to computer science. Obviously, I favor more transparency regarding the publishing of the methods used to process the data behind the research. While I do realize there is some history between the principals here and at CA, I think the science is more important than these types of personal issues, and publishing the data and the code would lend a lot of credibility to the research. At least it would with me. And I can’t see why someone who is confident in his methods would not do this enthusiastically.
#95: El Reg, eh? Does the name “Steven Goddard” ring a bell, at all?
Circling back to the original nit about publishing source code, Tamino is entirely correct in asserting that –publishing– versus –using– code is real work. Code can function perfectly but may be extremely difficult for a another party to analyze and (almost as bad from the coder’s perspective) just plain –ugly–. Sort of like going out in public with your shirt and pants on backwards; the basic function of the clothing is still met, but you won’t be happy.
How about another analogy? If you could fix your own roof, would you be satisfied if your roofer forbade you access to a ladder to do the work? That’s more to with Free versus closed source thing. If you can’t code, you really can’t understand why real coders care so much about the issue, but if you can pound a nail you can certainly understand how annoying it would be if you were not allowed the use of a hammer.
dhogaza #94 6 February 2009 at 4:51 PM writes: “Since non-practitioners are apparently more qualified than practitioners to determine what practices are acceptable in any given field, software types telling scientists how to do their job shouldn’t balk if scientists insist that software types provide proofs of correctness, right?”
Not at all. We have a huge budget that goes entirely to outside entities who specialize in auditing and testing software to insure compliance with a number of ISO and non-ISO standards. None of our customers would trust their companies operations to our systems if we didn’t.
But are you implying that climate scientists are some how special in that they could not benefit from having experts in specific fields contribute or audit their work? Are climate scientists expected to be masters of all the fields utilized in their research? I would never trust one of my programmers to design the accounting functionality or the linear programming logic we use in our systems. I have accountants and mathematicians on staff or on retainer for those functions.
David B. Benson #106 6 February 2009 at 8:06 PM writes: “IMO software development experience has almost nothing to do with climatology, Maybe we could stick with the latter here on RealClimate?”
Software has little to do with climatology, but everything to do with climate science. Virtually everything done in climate science uses computers and computer software to analyze the data. And GCMs, those things don’t run on an abacus or a slide rule.
Doug Bostrom #108: 6 February 2009 at 8:49 PM writes: “How about another analogy? If you could fix your own roof, would you be satisfied if your roofer forbade you access to a ladder to do the work?…”
I think you make my point precisely. I have tried to fix my own roof and my own plumbing. Now I do not hesitate to call a roofer or a plumber. These are not my areas of expertise, and in the long run it is much cheaper for me to fork it over up front than call them in to fix what I broke. I don’t do my own taxes either.
So why should a climate scientist do all of his own computer programming, without at least being willing to have it audited for free by posting it on the Internet? Its the whole OpenSource thing. There are tons of people, especially in computer science, only too willing to give away their expertise.
Everyone likes to be right, myself no less than anyone else. But AGW and the science behind it are too important to our future. Getting the science right should be the over riding concern, and if someone finds a mistake in someone else’s computer code or statistical methods, then that will advance the science and we are all better off.
tamino #92: 6 February 2009 at 4:45 PM writes: “The downside is that the level of transparency demanded by far too many “hacks” is work. And when vultures are waiting to tear it to shreds because they want to undermine science rather than advance it, it’s vastly more work.”
This is the same problem Einstein encountered when he published the theory of relativity. But hardly anyone remembers the “hacks” and “vultures” that tried to tear down his theories… why? Because he was right and they were wrong. And it was the process of trying to prove Einstein wrong that actually proved his theories to be right. Which is how science works. Its called the scientific method.
Re: Mike Walker
It’s so easy to trivialize the effort required for others to do things your way. Especially when you don’t have to lift a finger.
Tamino’s point in #92 is partly true. I find his argument that on the difficulty in publishing results such that they can easily be replicated unconvincing. One should always organize one’s work in that way as a matter of elementary sound practice, and it is commonly practiced elsewhere.
On the other hand, it is certainly true that the hacks want to find errors to use as weapons in their overdrawn attacks on the core conclusions of science. Coping with those attacks is indeed an important larger issue here. The advantage in this matter to eschewing openness is not clear, though. The failure to use new tools to enhance the efficacy of the scientific method dominates any convenience effect from having unqualified people poking at the code.
Any confidence that the scientific method will win in the end only works if the scientific method is sufficiently followed for its advantages to work. Not only that but we need it to work fast enough to keep us from that cliff we seem to be barreling toward. Remember that cliff? In principle science will out, maybe, but in practice it can take generations.
If standard practice in software engineering can accelerate the advantages of the scientific method and nonstandard practice (inattention to workflow as a component of work product integrity) can obscure those advantages, which choice should we take? Perhaps Gavin is right in suggesting that I overgeneralize when I say that scientists generally arrogantly refuse to learn from commercial practice. But those scientists who complain about ‘learning curves’ and ‘demonstrated benefits’ in the context of elementary best practices are not serving as counterexamples to the generalization.
Rather than being entirely argumentative here, allow me to commend to those willing to address this matter constructively the work of Greg Wilson of the University of Toronto: here is his excellent article called Where’s the Real Bottleneck in Scientific Computing? and his course on software carpentry is here. The relevant lesson for present purposes is automated builds.
re: #107 Mike Walker
Thanks, useful.
You’d dropped off the earlier thread, but here I explicitly addressed some of the differences between commercial enterprise software products and software written to do science. Could you perhaps go back and take a look at that?
I have run into this before: especially if someone has spent much of their career in one particular domain, it is all too easy to over-generalize the rules from that into others. This was true even inside Bell Labs 30 years ago, as there were at least half a dozen different combinations of requirements. Messes often occurred when managers moved from one division to another were too dogmatic about bringing all their methodology with them.
Scientists understand the scientific method. I dare say they understand it better than the self-proclaimed software hackers who insist on telling them how to do their job.
There’s an implication in your statement that is absolutely false, and that is that climate scientists are somehow trying to prevent people from trying to prove them wrong.
I suspect you know better.
Michael Tobis #114: 6 February 2009 at 10:43 PM
John Mashey #115: 6 February 2009 at 10:49 PM
I really don’t understand how either of your responses have anything to do with archiving code. I haven’t made any comments implying that researchers write bad code, should write better code or should use better tools and procedures. I’m sure that in general most researchers code is not upto standards I would require of my programmers, but my programmers are not scientists and scientists (probably) are not professional programmers. Some may be, I don’t know.
And, how elegant their code is (or is not) has nothing to do with archiving it. The ultimate measure of computer code is does it work. It can be the ugliest, most poorly written, unmaintainable monstrousity imaginable, but if it has a onetime use, who cares. The reason for researchers to archive their code isn’t to show off their programming skills, it is to allow others to evaluate their research and analytical methods. It is actually more like supplemental but very detailed documentation of their step by step methods. It would be nice if the code were well written from a CS standpoint, but does it really matter? Only if the code doesn’t work, or if there are material errors in the code that affects the results and conclusions reached by the researcher.
I think you can come up with a million reasons not to archive one’s code, but they are just excuses. There is no legitimate reason not to provide the code that explains the researchers methods better than any SI he can provide.
[Response: I’m not sure this is true. In the environment that climate studies find themselves, putting out anything that is functional but poorly written simply invites politically motivated attacks on the quality of the code. You can see from this week’s shennanigans that anything is fodder for those attacks, and so in many ways legitimate scientists face a damned if you do/damned if you don’t dilemma. It is actually not surprising that many opt out. – gavin]
No. Einstein’s audience were his fellow physicists, not “hacks” and “vultures”.
If the local hilltop moonshine distiller had demanded that Einstein publish his papers at a level he could understand, documented from the level of basic algebra up, piling on accusations of fraud, dishonesty, intentional refusal to provide enough information for him to replicate the work … Einstein’s eyes would’ve bugged out, I’m sure.
I’m exaggerating, but in principle this is what’s being asked for. Not the level of openness and accessibility professional scientists in the field – the researcher’s peers – need to understand and, if necessary, undermine or disprove the work. But rather some unachievable level of “openness” that will allow any tom, dick, and harry – jeff id, for instance – to “audit” the work.
It’s odd that individual, random people outside science seem to feel that they, personally, should be able to tell scientists how they must do their jobs.
Oh, by the way, demonstrating that software adheres to a standard is not a proof of correctness, but since you said “not at all” when I asked my question, can I expect a proof of correctness, along with the source to your ERP product, soon?
It is open source, I trust.
Dr. Schmidt, there has been a lot of back and forth here about generalities of software development and data management. However, in this particular case it seems that the intermediate data and methods are available to “legitimate” researchers. So it seems more a question of willingness to post these, than it is a question of effort or style of development.
I think then, that the discussion ought to focus on this question. What is the advantage to science of not simply making this available?
Tell us why you put “legitimate” in quotation marks, Mr. N.
I recall this or similar words from one of the big ice core grants years back — the cores and data required shared with legitimate researchers who would pay a proportion of the cost of the work done to acquire them. Reasonable.
How do you know who’s legitimate in a field? Look at their work.
The cost of the work in time and effort is always considerable.
The obvious waste of time that can be created by people whose goal is to interfere with what they think politicians will decide, by interfering with the scientific work in the area, is another cost.
There’s a whole industry devoted to that interference. You know it.
This is a caution about that sort of cost — it’s well avoided:
http://www.ajph.org/cgi/content/abstract/91/11/1749
EK Ong, SA Glantz – American Journal of Public Health, 2001
Cited by 127
Climatology is overlapping now with public health. Same conflicts.
“The life so short, the craft so long to learn.”
“There are in fact two things, science and opinion; the former begets knowledge, the later ignorance.”
Cited by 127 — here’s that link, working:
http://scholar.google.com/scholar?num=50&hl=en&lr=&newwindow=1&safe=off&cites=13366054661093759722
One from those 127 really should be read, for those who didn’t bother to look at any of the rest of them. Ask yourself what you want to know about this:
Health Affairs, 24, no. 4 (2005): 994-1004
doi: 10.1377/hlthaff.24.4.994
© 2005 by Project HOPE
Tobacco Control
The Power Of Paperwork: How Philip Morris Neutralized The Medical Code For Secondhand Smoke
Daniel M. Cook, Elisa K. Tong, Stanton A. Glantz and Lisa A. Bero
A new medical diagnostic code for secondhand smoke exposure became available in 1994, but as of 2004 it remained an invalid entry on a common medical form. Soon after the code appeared, Philip Morris hired a Washington consultant to influence the governmental process for creating and using medical codes.
Tobacco industry documents reveal that Philip Morris budgeted more than $2 million for this “ICD-9 Project.” Tactics to prevent adoption of the new code included third-party lobbying, Paperwork Reduction Act challenges, and backing an alternative coding arrangement.
Philip Morris’s reaction reveals the importance of policy decisions related to data collection and paperwork.
———————————————-
No other industry except the tobacco industry has had their tactical document files opened to public view — these archives aren’t documenting only one industry’s tactics. This is how it is done.
This is one reason why scientists in fields under attack share work with legitimate scientists — those who have shown they can do the work.
It would be very rare if the software for a GCModel was written from scratch. Rather I would expect that it’s made up of a series of fragments of code that have been developed and tested a bit at a time and then combined with the latest bits to make a viable lump of code that reflects the prevailing state of the art.
With this development style it is very likely that many of the important components are written in obscure and often very ‘expedient’ code, which is likely to be utterly opaque to the casual decompiler, and often similarly difficult for the author to re-visit a few months or years after it was first put together and its function proven.
I imagine that making code do what the climatologist wants it to do is a very hands-on process – a line; a tweak at a time until the subroutine performs as it should. Its unlikely that it’s like coding a bit of accounting software where the development brief is nailed before it starts. But always if the block diagram doesn’t work the code won’t either, so a lot of time gets spent on the whiteboard.
My point being that while it is dutiful of authors to make the code of their GCMs available there are very few people in the world who can both understand the syntax and then see how that code relates to the climate parameters involved. Invariably the code will be capable of improvement, but the point is; does it make an acceptable job of telling the story so far.
Only by checking the code’s output against the skilled expectations a grid square at a time can it be seen to be valid. No mean feat for those who have written it; Next to impossible for any outsider to prove that it works, but easy for them to find some trivial potential fault.
If critics want to do better they should build their own CGMs from scratch, like the big boys do.
dhogaza #118 7 February 2009 at 12:28 AM writes: “Oh, by the way, demonstrating that software adheres to a standard is not a proof of correctness, but since you said “not at all” when I asked my question, can I expect a proof of correctness, along with the source to your ERP product, soon?”
SOX Certification requires a ton of testing for correctness. And, of course, as a privately developed product the source code is proprietary.
But what does this have to do with “archiving” code for government sponsered public research. We are not publishing research conducted on the taxpayers dime that will be used to form public policy. If I were, I would expect to archive the code where it was publicly available.
When you say “professional scientists in the field – the researcher’s peers”, would you not consider computer scientists peers, at least for that part of the work that is in their area of expertise?
I’m not expecting the researcher to make any extra effort to explain his code. If it works and correctly produces the results that support the researchers work, then it speaks for itself. If it doesn’t, it also speaks for itself. Why should any climate scientist not welcome experts in related fields to confirm his work. If his work is correct, then why do you think that is not what will happen?
Nicolas Nierenberg 7 February 2009 at 12:36 AM writes: “I think then, that the discussion ought to focus on this question. What is the advantage to science of not simply making this available?”
I agree.
Dr. Schmidt, why do (some) climate scientists appear so apprehensive about having their work reviewed by experts from other fields? Specifically that part of their work that is outside of climate science itself, such as statistics and computer science?
[Response: I see no evidence for that at all. I see a reluctance to have hordes of know nothings magnify every typo into federal case, but all the good scientists I know welcome constructive advice from any quarter. The key is the word ‘constructive’ – scientists are mostly driven by the desire to understand something about the world, and help in doing so is always appreciated. People whose only contribution is to malign or cast aspersions, whatever their background, are simply of no use in that endeavour. – gavin]
RE: Gavin’s response to my post #117: Gavin wrote: “and so in many ways legitimate scientists face a damned if you do/damned if you don’t dilemma”.
While this may be true, I think you have too little faith in science. Advances in our scientific understanding have always been controversial. Galileo, Darwin, Einstein. They all had their detractors, but who remembers their detractors names? If you let your detractors prevent you from doing the best science possible, then they have already won.
BTW-Am I the only the that can’t see Captcha? It usually takes me 3 or 4 times to get words I can actually make out.
Mike walker, #107, you’re not doing any of the bloody work either.
Someone can try their own climatology work and publish THEIR paper. If their paper agrees with the current swathe of papers, then these papers are true. Problem is that the ones who don’t believe (and they aren’t skeptics either) don’t want to do their own paper because it won’t show anything remarkably different from the other papers and won’t show what they want to tell either. At least not without so many deliberate errors that the debunking of the paper becomes trivial.
They can’t stop the papers of others either.
So they demand that work is done in “make work” to take time away from the science and put it into digging up all the data, explaining each semi-colon and how computers work (all the way up from the hollerith machine to quantum computing).
Having no time left, they can’t produce any more papers. And so they can then crow “SEE! They can’t prove that AGW is happening any more, so they stopped looking! HA!”.
And what’s a CEO doing on here demanding open sourcing the code, data, personal history etc? Is your work under GPL3? If not, go and do the work yourself and open your code.
re 101. Well, I have posited that there is a risk in drilling and extracting oil. The risk is the earth blows up at a certain extraction.
I have not seen any scientific papers trying to assess the risk, so the risk is unknown.
And, like the people who say “I don’t believe in either side, so let’s do nothing until they BOTH clean up their acts” (which is what the denialists want, so hardly a punishment for them), I say we should do nothing about extracting oil until the risk is PROVEN unfounded.
Again, like the denialists, I don’t know WHAT could make oil extraction cause the world to blow up, but then again, THEY are the engineers and scientists involved in it, so they should look for it.
I agree that skeptic critics WILL over-magnify typos. Will NOT publish in archived journals (allowing fair responses and a fixed position of criticism and easy to read, well written snark-free science/math comments) and instead will do their blog games. Will NOT finish their speculative blogged forays. Will NOT write up analyses that show robustness of the work. All that said, the benefits of openness are still far greater than restricting acess because of fear of unfair critics. Especially for something like the Antarctica work that is really a bolf approach to the problem. Analysis of the method here and its suitability may be even more useful than the result from the infilling exercise.
What does re-use of the use of the code prove about the underlying reality? Nothing. What will prove that the experiment as described shows something about reality is an independent methodology.
What cranks and denier know is that code is a threshing floor of arcana. Lots of chaff to throw in the public’s eyes. Look at how long lasting is the issue of CO2 as leading and lagging indicator. And that’s easy to understand. Look at the efforts to debunk the “hockey stick”. Deniers still bring it up even though completely independent studies discovered the same phenomenon.
Demand for access to code is a demand for ever tinier bits of minutiae to carp over. You want to debunk an experiment? Re-do it.
Guys, thanks for the compliments on the web page. I’ll see what I can do about keeping it updated, or at least pointing people to primary sources for the data.
On the revealing-code issue. That’s not how real peer-reviewed science works. I’ll try to give an example.
Let’s say a stellar astronomy paper computes a lot of absolute magnitudes. The original code is for a Cray supercomputer, written in a Fortran-95 compiler that cost the university $6,000. Here it is:
But that code is never published. Now, an amateur who is well-read in astronomy decides to check the calculations. He’s running Windows 95 on an ancient Pentium with software coprocessor emulation turned on to avoid the floating-point bug. The input data file the astronomers used is available on the journal’s web site. He selects three stars as test cases, downloads a freeware Basic compiler, and writes his own code:
for i = 1 to 3 read V, p, nam$ M = V + 5 + 5 * (log(p) / log(10)) print i; " "; print nam$; " "; print using("##.##", V); " "; print using("#.###", p); " "; print using("##.##", M) next i end‘ Data:
data 11.01, 0.772, “Proxima Centauri.”
data 9.54, 0.549, “Barnard’s Star. ”
data 3.50, 0.274, “52 Tau Ceti. ”
He gets 15.45, 13.24, and 5.69 as the absolute magnitudes of the three stars, respectively. He then checks the astronomers’ output file. Let’s look at three scenarios.
1. The astronomers got the same figures. Code confirmed.
2. The astronomers list 15.47, 13.26, and 5.71 for those three stars. The amateur checks his own code for bugs, putting in some simple test cases like parallax = 0.100. Then he writes to the journal. The journal informs the authors. The authors check their code. Turns out the coder dropped some LSD when he was coding and put down “5.02d0” where he should have put down “5d0”. A correction is printed in the next issue of the journal, but there’s no change to the authors’ conclusion, which is, let’s say, that Hipparcos satellite parallaxes are superior to Yerkes Observatory parallaxes from 1928.
3. The astronomers’ figures are totally off. Note to journal, journal tells authors, authors check, find a major error which vitiates their entire thesis. The journal prints a retraction, or possibly invites the amateur to draw up his critique in a follow-on paper. This is rare but it does happen.
In no case does the amateur himself need the original code.
Gavin, Mike, somebody, is there some way to display a monospaced font in this blog? My code examples always turn out looking lousy no matter how I play with & nbsp ; and similar tricks.
[Response: I surrounded the code bits with ‘pre’ and ‘/pre’. That seems to do the trick. – mike]
Captcha: “entire secret”
Dr. Schmidt, with regard to your answer to #124. Let’s agree that casting aspersiions, ad hom attacks, and trivial observations are a waste of time. This has nothing to do with what the problem is with just posting what Dr. Steig already has available. If other people choose to waste their time with it, why is that your problem?
#130, no problem in the case where the algorithm, and the description of process is trivial and clear. This is not the case in Dr. Steig’s paper. Even reading the on line methods section of the paper would not provide enough information to know exactly what was done.
Someone was mentioning Einstein earlier. I can tell you that when a physicist or mathematician publishes they need to include all the work. If someone tries to prove them wrong they don’t have to speculate on how they arrived at the result. The argument can center on much more fundamental grounds.
In any event the process is moving inexorably towards full disclosure. Because the space limitation in journals is not an issue on line, things like more complete methods are included. Authors are expected to put supplemental information on line. Despite any resistance I’m sure it will simply become standard practice to put all the intermediate work required to get to the result on line, and researchers who are used to holding this type of stuff back will just have to deal with it.
The nice side effect is that their own work will be more effective and reproducible. This way when that grad student who has been doing the analysis decides to go to another lab, the new person will be able to figure out what is going on.
To summarize
“Great fleas have little fleas
upon their backs to bite ’em,
And little fleas have lesser fleas,
and so ad infinitum.
Yet data set fleas are larger still
Than the great disks which hold em
And no one knows where a misprint lurks
Until they stumbles upon one”
Captcha: barked all right
-ER with apologies Augustus de Morgan
Yeah. Mr. N, Eric’s in Antarctica for 3 months.
You want a 3-month field day by the WTFU crowd while he’s out of town.
What does this accomplish?
You do understand the point of the uproar is to influence legislation and regulation, don’t you?
Remember this thread? It’s one of the great examples of how this is being done:
– Prometheus: Less than A Quarter Inch by 2100 Archives
Once CO2 is regulated by EPA, then I’d agree with your analogy. …. To show standing, then, Massachusetts needs to show a particular stake in EPA making the … Roger, you asked what possible difference a quarter inch average rise in …
http://sciencepolicy.colorado.edu/prometheus/archives/climate_change/001004less_than_a_quarter_.html
If you don’t recall it, you should reread it and think about what you’re trying to accomplish and what he’s trying to accomplish there.
Remember:
“… more than $2 million for this ‘ICD-9 Project.’ Tactics to prevent adoption of the new code …”
That’s the way industry uses this.
Nobody here thinks Microsoft was the first company to use FUD (“Fear, uncertainty, doubt”) in the market, do you?
Candle in the dark. Lots of windbags around. Keep it lit.
NN should have a talk with Bill Gates.
Re #125 Mike said … “If you let your detractors prevent you from doing the best science possible, then they have already won”.
I agree with that, but doing your best science possible despite the detractors can be costly.
http://talkingpointsmemo.com/docs/files/1233855544%5BUntitled%5D_Page_2.jpg
There’s the proposal to cut the science budget.
This is what creating uncertainty and mistrust of science accomplishes.
While I agree with the general points you (Gavin) make about there being no requirement to open source code, I thought I would comment on the prevalence of Free Open Source in business and the software world in general.
First most of the internet infrastructure is run with open source code, including two thirds of the webservers:
http://news.netcraft.com/archives/2009/01/16/january_2009_web_server_survey.html
including https://www.realclimate.org
http://uptime.netcraft.com/up/graph?site=www.realclimate.org
Although open source on the desktop is pretty rare in business, on the server side it is common.
As for SAP, one of the database variants is open source
http://www.sapdb.org/
ORACLE provide and contribute to many open source projects. Including InnoDB, the transactional database engine for MySQL the M in LAMP.
http://oss.oracle.com/
As for the code for things like MS Vista, this is available under certain circumstances to Governments http://www.out-law.com/page-3296
The code for more than a few GCMs is available. Two that come to mind are the Community Model and the GISS model. So far, none of the usual suspects have had at it
BPL (75), Your link is curiously interesting, but hardly a proof certain of your implication. In substance, you first blow out of the water the GW explanation of CO2 following by long periods the rise of temperatures in long ago times. Secondly it does not address the relative marginal changes when the concentration is much smaller or much greater than the data (though you might not have meant that.) Then, what’s very intriguing, if not amusing, you come up with a chance of randomness a million times smaller than Planck’s Constant a la Heisenberg’s uncertainty principle . I know the uncertainty principle does not address probability — but really!! All of which shows that mathematics is a construct and has no control over physics. Your analysis seems to show a decent correlation of CO2 concentration and global temperature within the range measured; this is interesting in its own right and might be indicative of something, but proves nothing.
dhogaza wrote in 118:
Then there are the talk show hosts who have found that they can achieve higher ratings by playing to distrust of science and conspiracy theories among the toms, dicks and harrys of the world, conspiracy theories which are never disproven but only become more elaborate when faced with counterevidence (as in, “… all these other scientists must be in on it, too!”), the well-documented Exxon-funded think tanks, etc..
It is possible that you might achieve a level of evidence and detail which might satisfy a particular Tom, Dick or Harry, but there will be ten who are just a little more paranoid or ideological or a little less honest or bright ready to fill there shoes and require even more, always resenting the mere existence of any shred of evidence that their politics might have to make room for discoveries of science.
Hank Roberts wrote in 136:
Hank, you might want to see this:
Science funding cuts stayed, still in Senate version of recovery bill
http://www.writeslikeshetalks.com/2009/02/07/science-funding-cuts-stayed-still-in-senate-version-of-recovery-bill/
It looks like a fair amount of the science funding was preserved. Instead of a 52.32 percent cut we are seeing a 10.74 percent cut. Still, the Senate version isn’t the final version: the final is supposed to be some sort of compromise between the House and the Senate. We will see what happens between now and then, to that, the funding for renewables, the grid, etc..
Re: #139 (Rod B)
When you say “you first blow out of the water the GW explanation of CO2 following by long periods the rise of temperatures in long ago times” you reveal how ignorant you are. BPL’s analysis does nothing of the kind, and you have to have a rather perverse prejudice to think it does.
Your statement about “a chance of randomness a million times smaller than Planck’s Constant” is silly. Probability is a dimensionless quantity while Planck’s constant is not, and with a different choice of units I can make Planck’s constant take any numerical value at all (in fact a common choice in particle physics is to choose units such that h = 2*pi). You just wanted to mention Planck and Heisenberg to make yourself look educated.
As for “proves nothing,” in fact it proves exactly what BPL set out to show: that idiotic claims of no recent correlation between CO2 concentration and temperature depend on cherry-picking, using such a small time span that the noise in the data drowns out the signal.
I’ve said it before and I’ll say it again: providing source has nothing to do with scientific replication. Running the code a scientist provides and getting the same result proves nothing scientifically; all it proves is that the result was not made up (and thus insisting on doing this is an implicit insult). Real replication is done writing your own code which for Eric’s work would presumably be just a ‘harness’ of scripts using standard library code and loading and saving data files. All in a day’s work for a practicing scientist.
The reason this may not be obvious to some is lack of familiarity with standard methods used in the field and well documented in Eric’s link: http://web.gps.caltech.edu/~tapio/imputation/ and Tapio Schneider’s article linked from there. There is a simple backgrounder in SVD and PCA analysis techniques, with a simple example that you may want to read first, linked from my name; Ch. 12.
Providing source is a courtesy to people outside the community of peers, and contrary to some here, I don’t demand it but, for the record, do highly appreciate it.
http://www.cosis.net/abstracts/EGU2008/05209/EGU2008-A-05209-1.pdf
Geophysical Research Abstracts,
Vol. 10, EGU2008-A-05209, 2008
SRef-ID: 1607-7962/gra/EGU2008-A-05209
EGU General Assembly 2008 © Author(s) 2008
Significant warming of West Antarctica in the last 50 years
http://www.pnas.org/content/105/34/12154.abstract
August 12, 2008, doi: 10.1073/pnas.0803627105
PNAS August 26, 2008 vol. 105 no. 34 12154-12158
Ice cores record significant 1940s Antarctic warmth related to tropical climate variability
David P. Schneider, Eric J. Steig
Edited by Richard M. Goody, Harvard University
There are a few other papers out there; at least one (which was it?) was reassessed after the current paper was published.
Total, a handful of serious papers.
Weigh this against the total volume of bloggery committed on the subject if anyone has a handy tool to get a total (Google, somehow, maybe?). And from experience we can be sure that months and years from now there will still be people new to the subject dropping the name “Harry” into conversations with vague insinuations of fraud picked up by reading the kind of garbage that gets blogged.
Making the details of the work behind published papers sounds wonderful from the outside. Scientists who’ve experienced having their work taken by someone who can use it faster to their own benefit know the risks of giving away one’s tool kit and knowledge to one’s competitors. That game was played much harder thirty years ago when I was last in academia — no Internet; getting someone’s lab notes or draft grant application and beating them to publication or application wasn’t even wrong. It happened. As Jesse Unruh remarked about California, faculty fought because there was so little at stake.
I recall people used to set traps for that kind of behavior — ‘carelessly’ leaving out fake lab notebooks (and later even laptops) where they could be stolen, to take down people willing to steal that kind of information and tie them up wasting time instead of doing their own honest work.
There are always people who’d rather mess with someone else’s work than do their own, for many reasons.
Openness — and the plagiarism detection tools online — are a good thing. Better documentation of detailed background makes it hard to jump into publication using someone else’s work.
But the new crowd — the politically active, and the businesses that want to fog and confuse the science to avoid regulation — are far more able to do damage to the research and the chance for support. letting them have all the work and all the background sounds really noble.
But you need to read the tobacco papers — the only industry that’s had much of its archive disclosed after losing all the way through the court system. What’s disclosed are tactics that are standard business lobbying — they include faking papers, faking science, pressure on journals — and they consider this normal and fair.
A few other such patterns have been documented — even more recently.
See below.
I respect Michael Tobis’s point of view. But when you’re going to open up everything to everyone, you have to know this happens, and think about the amount of money at risk from the science and the payback for those out to destroy your reputation as a scientist.
Seriously, folks, read the top five here:
http://scholar.google.com/scholar?num=50&hl=en&lr=&newwindow=1&safe=off&cites=16026924779708694907
And for those who don’t look, this one at least:
Int J Occup Environ Health. 2007 Jan-Mar;13(1):107-17.Links
Comment in: Int J Occup Environ Health. 2007 Jul-Sep;13(3):356; author reply 356-8.
Industry influence on occupational and environmental public health. Huff J.
National Institute of Environmental Health Sciences, Research Triangle Park, NC 27709, USA.
Traditional covert influence of industry on occupational and environmental health (OEH) policies has turned brazenly overt in the last several years. More than ever before the OEH community is witnessing the perverse influence and increasing control by industry interests. Government has failed to support independent, public health-oriented practitioners and their organizations, instead joining many corporate endeavors to discourage efforts to protect the health of workers and the community. Scientists and clinicians must unite scientifically, politically, and practically for the betterment of public health and common good. Working together is the only way public health professionals can withstand the power and pressure of industry. Until public health is removed from politics and the influence of corporate money, real progress will be difficult to achieve and past achievements will be lost.
_____________
Climatology _is_ an issue of public health
Mr. Schmidt,
You do not seem to grasp how software conceptually works.
In claiming that it could be used for “politically motivated attacks” you seem to believe that a piece of software in the hands of an “evil minded” person can get other results compared to when it is used “nicely”. I am a software engineer, I don’t know much about climate science (I’m interested though) but I know for sure that SW always does the same thing over and over again. that is actually the point in using it.
Linking to a library of functions and saying -here it is, all of it, is like pointing to a tool box with hammers, nails and saws and tell someone to go build a house. You NEED to explain in what order the tools shall be used (makefile…).
Best Regards,
Rob
[Response: Thanks, but I think I do know what software does ;) . The point I was making above concerns people who aren’t generally interested in running the code at all. For some, the names of variables inefficient looping, or cryptic inline comments all become fodder for ridicule whether or not the code works as advertised. Code can always be improved of course, but not everything that people use (with its imperfections) is going to fare well exposed to the glare of people whose only goal is to make you look bad. Thus people who don’t have the time to make their code bullet proof often hesitate to make it public at all. This is just an observation, not a reason. – gavin]
Mike, thanks. I can’t believe I forgot and . Shows what years away from my old field of computer programming can do…
Mr. Schmidt,
It doesn’t matter how crappy a SW becomes, it does what it always have done and if someone isn’t serious enough to avoid making a point out of the crappiness they are disqualified for further comments. Does that really bothers you?
If you were to publish the SW, anyone the are truly interested in replicating your work can do so with the help from the original SW, crappy or not.
Doing so however REQUIRES some basic step by step instructions (makefile, script etc.). This is really my point, please comment.
[Response: It doesn’t bother me particularly, and the code I work on is available for all to see, warts and all. Other people may be more sensitive. As to your real point, the answer is that it depends. I’ll have another post tomorrow sometime discussing this in more detail. – gavin]
Nicholas, in an ideal world I would agree with total openness. But you may not realize the level of damage being done to public understanding and policy discussions by dishonest denialists. In the current environment, I would stick with advice I was given by a colleague in an entirely different context some years ago: Do not give arms to the enemy!
People are making lots of comparisons between their areas and the request for information from scientists, so I’ll add my own opinion based on my experience.
In lawsuits the opposing parties routinely make requests for information. Each side wants to win and a tactic commonly used is to make requests that are onerous. The goal is not to find facts, it’s to make the opponent spend undue amounts of time and money to derail the opponent’s efforts. This type of behavior unchecked could grind the legal system to a halt. To ensure that the system functions there are whole sets of rules that govern the process.
When rules and regulations are made in the US the public is allowed to get involved, including asking for information about the science that was used making the decisions. Again rules govern the process to make sure it is not bogged down by unreasonable requests.
Climate science has become as adversarial as the legal and regulatory systems but without the necessary safeguards. I think its no coincidence that some people are focusing on the science.