There has been a lot of discussion about decadal climate predictions in recent months. It came up as part of the ‘climate services’ discussion and was alluded to in the rather confused New Scientist piece a couple of weeks ago. This is a relatively “hot” topic to be working on, exemplified by two initial high profile papers (Smith et al, 2007 and Keenlyside et al, 2008). Indeed, the specifications for the new simulations being set up for next IPCC report include a whole section for decadal simulations that many of the modelling groups will be responding to.
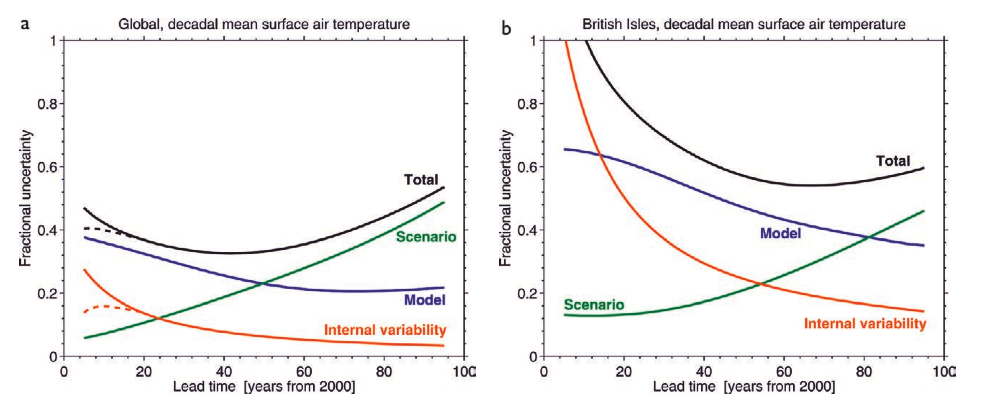
This figure from a recent BAMS article (Hawkins and Sutton, 2009) shows an estimate of the current sources of prediction error at the global and local scale. For short periods of time (especially at local scales), the dominant source of forecast uncertainty is the ‘internal variability’ (i.e. the exact course of the specific trajectory the weather is on). As time goes by, the different weather paths get averaged out and so this source of uncertainty diminishes. However, uncertainty associated with uncertain or inaccurate models grows with time, as does the uncertainty associated with the scenario you are using – ie. how fast CO2 or other forcings are going to change. Predictions of CO2 next year for instance, are much easier than predictions in 50 years time because of the potential for economic, technological and sociological changes. The combination of sources of uncertainty map out how much better we can expect predictions to get: can we reduce error associated with internal variability by initializing models with current observations? how much does uncertainty go down as models improve? etc.
From the graph it is easy to see that over the short term (up to a decade or so), reducing initialization errors might be useful (the dotted lines). The basic idea is that a portion of the climate variability on interannual to decadal time scales can be associated with relatively slow ocean changes – for instance in the North Atlantic. If these ocean circulations can be predicted based on the state of the ocean now, that may therefore allow for skillful predictions of temperature or rainfall that are correlated to those ocean changes. But while this sounds plausible, almost every step in this chain is a challenge.
We know that this works on short (seasonal) time scales in (at least some parts of the world) because of the somewhat skillful prediction of El Niño/La Niña events and relative stability of teleconnections to these large perturbations (the fact that rainfall in California is usually high in El Niño years for instance). But our ability to predict El Niño loses skill very rapidly past six months or so and so we can’t rely on that for longer term predictions. However, there is also some skill in seasonal predictions in parts of the world where El Niño is not that important – for instance in Europe – that is likely based on the persistence of North Atlantic ocean temperature anomalies. One curious consequence is that the places that have skillful and useful seasonal-to-interannual predictions based on ENSO forecasts are likely to be the places where skillful decadal forecasts do worst (because those are precisely the areas where the unpredictable ENSO variability will be the dominant signal).
It’s worth pointing out that ‘skill’ is defined relative to climatology (i.e. do you do a better job at estimating temperature or rainfall anomalies than if you’d just assumed that the season would be just like the average of the last ten years for instance). Some skill doesn’t necessarily mean that the predictions are great – it simply means that they are slightly better than you could do before. We should also distinguish between skillful (in a statistical sense) and useful in a practical sense. An increase of a few percent in variance explained would show up as improved skill, but that is unlikely to be of good enough practical value to shift any policy decisions.
So given that we know roughly what we are looking for, what is needed for this to work?
First of all, we need to know whether we have enough data to get a reasonable picture of the ocean state right now. This is actually quite hard since you’d like to have subsurface temperature and salinity data from a large part of the oceans. That gives you the large scale density field which is the dominant control on the ocean dynamics. Right now this is just about possible with the new Argo float array, but before about 2003, subsurface data in particular was much sparser outside a few well travelled corridors. Note that temperature data are not sufficient on their own for calculating changes in the ocean dynamics since they are often inversely correlated with salinity variations (when it is hot, it is often salty for instance) which reduces the impact on the density. Conceivably if any skill in the prediction is simply related to surface temperature anomalies being advected around by the mean circulation, it could be possible be useful to do temperature only initializations, but one would have to be very wary of dynamical changes and that would limit the usefulness of the approach to a couple of years perhaps.
Next, given any particular distribution of initialization data, how should this be assimilated into the forecasting model? This is a real theoretical problem given that models all have systematic deviations from the real world. If you simply force a model temperature and salinity to look exactly like the observations, then you risk having any forecast dominated by model drift when you remove the assimilation. Think of a elastic band being pulled to the side by the ‘observations’, but having it snap back to it’s default state when you stop pulling. (A likely example of this is the ‘coupling shock’ phenomena possibly seen in the Keenlyside et al simulations). A better way to do this is via anomaly forcing – that is you only impose the differences from the climatology on the model. That is guaranteed to have less model drift, but at the expense of having the forecast potentially affected by systematic errors in, say, the position of the Gulf Stream. In both methods of course, the better the model, the less bad the problems. There is a good discussion of the Hadley Centre methods in Haines et al (2008) (no sub reqd.).
Assuming that you can come up with a reasonable methodology for the initialization, the next step is to understand the actual predictability of the system. For instance, given the inevitable uncertainties due to sparse coverage or short term variability, how fast do slightly differently initialized simulations diverge? (Note that we aren’t talking about the exact path of the simulation which will diverge as fast as weather forecasts – a couple of weeks, but the larger scale statistics of ocean anomalies). This appears to be a few years to a decade in “perfect model” tests (where you try and predict how a particular model will behave using the same model but with an initialization that mimics what you’d have to do in the real world).
Finally, given that you can show that the model with its initialization scheme and available data has some predictability, you have to show that it gives a useful increase in the explained variance in any quantities that someone might care about. For instance, perfect predictability of the maximum overturning streamfunction might be scientifically interesting, but since it is not an observable quantity, it is mainly of academic interest. Much more useful is how any surface air temperature or rainfall predictions will be affected. This kind of analysis is only just starting to be done (since you needed all the other steps to work first).
From talking to a number of people working in this field, my sense is that this is pretty much where the state of the science is. There are theoretical reasons to expect this to be useful, but as yet no good sense for actually how practically useful it will be (though I’d welcome any other opinions on this in the comments).
One thing that is of concern are statements that appear to assume that this is already a done deal – that good quality decadal forecasts are somehow guaranteed (if only a new center can be built, or if a faster computer was used). For instance:
… to meet the expectations of society, it is both necessary and possible to revolutionize climate prediction. … It is possible firstly because of major advances in scientific understanding, secondly because of the development of seamless prediction systems which unify weather and climate prediction, thus bringing the insights and constraints of weather prediction into the climate change arena, and thirdly because of the ever-expanding power of computers.
However, just because something is necessary (according to the expectations of society) does not automatically mean that it is possible! Indeed, there is a real danger for society’s expectations to get completely out of line with what eventually will prove possible, and it’s important that policies don’t get put in place that are not robust to the real uncertainty in such predictions.
Does this mean that climate predictions can’t get better? Not at all. The component of the forecast uncertainty associated with the models themselves can certainly be reduced (the blue line above) – through more judicious weighting of the various models (perhaps using paleo-climate data from the LGM and mid-Holocene which will also be part of the new IPCC archive), improvements in parameterisations and greater realism in forcings and physical interactions (for instance between clouds and aerosols). In fact, one might hazard a guess that these efforts will prove more effective in reducing uncertainty in the coming round of model simulations than the still-experimental attempts in decadal forecasting.
[edit]
3rdOct: New Moon.
Within 24 hours of it, G Karst has repeated a tired old cut n paste that has never worked.
Obviously his posting is driven by the full moon.
[edit–see previous comment. if we can’t keep the discussion civil, we’ll nix it]
Peter Sinclair has posted another video this week;
http://www.youtube.com/watch?v=khikoh3sJg8
Pete
it’s not really about the data. It’s about the unorthodox scientist as hero, challenging the establishment with a cool new idea. It’s about the underdog against the arrogance of the establishment. It’s about publicity, self-promotion, and sexy press releases. It’s about insisting relentlessly from publication to publication that a link has been shown, and a theory is gaining strength. It’s about writing a popular book about oneself, ignoring every objection that has been raised except the one for which one happens to have a good reply. And it’s about wishful thinking that this somehow means greenhouse warming isn’t happening. People want Svensmark to be right.