Guest commentary from Zeke Hausfather and Robert Rohde
Daily temperature data is an important tool to help measure changes in extremes like heat waves and cold spells. To date, only raw quality controlled (but not homogenized) daily temperature data has been available through GHCN-Daily and similar sources. Using this data is problematic when looking at long-term trends, as localized biases like station moves, time of observation changes, and instrument changes can introduce significant biases.
For example, if you were studying the history of extreme heat in Chicago, you would find a slew of days in the late 1930s and early 1940s where the station currently at the Chicago O’Hare airport reported daily max temperatures above 45 degrees C (113 F). It turns out that, prior to the airport’s construction, the station now associated with the airport was on the top of a black roofed building closer to the city. This is a common occurrence for stations in the U.S., where many stations were moved from city cores to newly constructed airports or wastewater treatment plants in the 1940s. Using the raw data without correcting for these sorts of bias would not be particularly helpful in understanding changes in extremes.
Berkeley Earth has a newly released homogenized daily temperature field is built as a refinement upon our monthly temperature field using similar techniques. In constructing the monthly temperature field, we identified inhomogeneities in station time series caused by biasing events such as station moves and instrument changes, and measured their impact. The daily analysis begins by applying the same set of inhomogeneity breakpoints to the corresponding daily station time series.
Each daily time series is transformed into a series of temperature anomalies by subtracting from each daily observation the corresponding monthly average at the same station. These daily anomaly series are then combined using similar mathematics to our monthly process (e.g. Kriging), but with an empirically determined correlation vs. distance function that falls off more rapidly and accounts for the more localized nature of daily weather fluctuations. For each day, resulting daily temperature anomaly field is then added to the corresponding monthly temperature field to create an overall daily temperature field. The resulting daily temperature field captures the large day-to-day fluctuations in weather but also preserves the long-term characteristics already present in the monthly field.
As there are substantially more monthly records than daily records in the early periods (e.g. 1880-1950), treating the daily data as a refinement to the monthly data allows us to get maximum utility from the monthly data when determining long-term trends. Additionally, performing the Kriging step on daily anomaly fields simplifies the computation in a way that makes it much more computationally tractable.
You can find the homogenized gridded 1-degree latitude by 1-degree longitude daily temperature data here in NetCDF format (though note that a single daily series like TMin is ~4.2 GB). We will be releasing an individual homogenized station series in the near future. Additional videos of daily absolute temperatures are also available.
Climate Data Visualization with Google Maps Engine
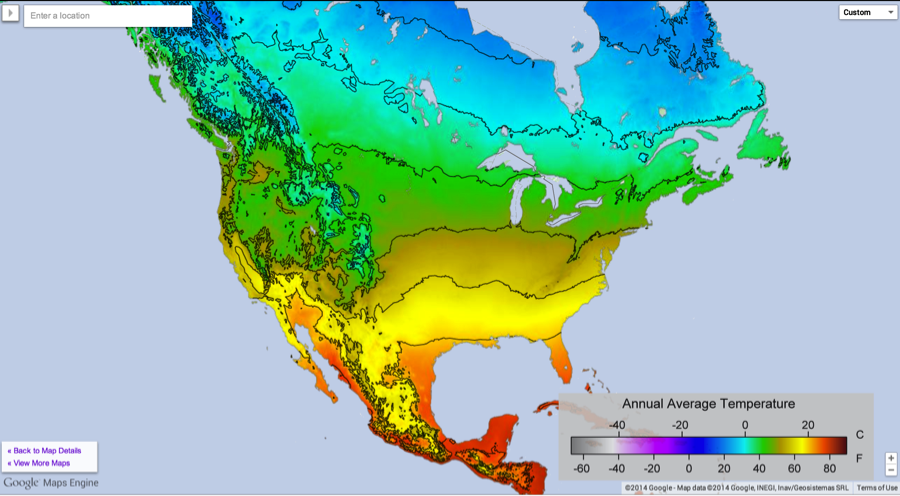
Through a partnership with Google we’ve created a number of different interactive climate maps using their new Maps Engine. These include maps of temperature trends from different periods to present (1810, 1860, 1910, 1960, 1990), maps of record high and low temperatures, and other interesting climate aspects like average temperature, daily temperature range, seasonal temperature range, and temperature variability.
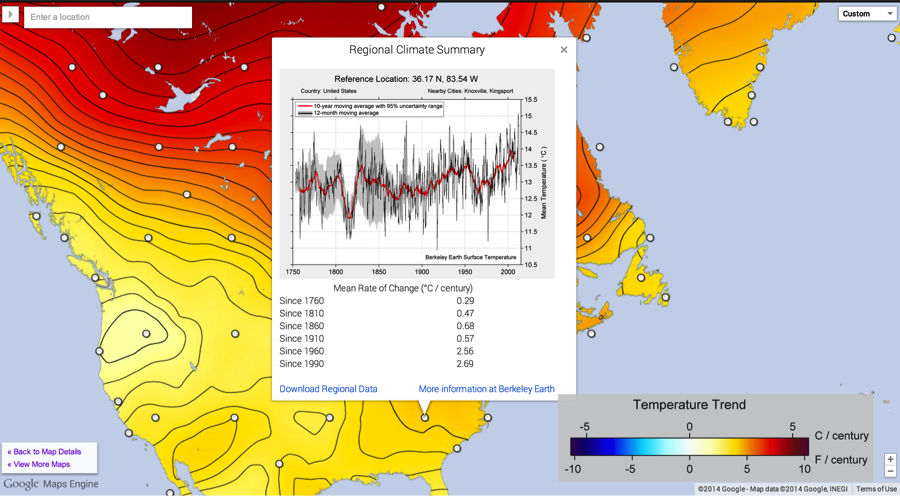
These maps utilize a number of neat features of Google’s Maps Engine. They dynamically update as you zoom in, changing both the contour lines shown and the points of interest. For example, in the 1960-present trend map shown above, you can click on a point to show the regional climate summary for each location. As you zoom in, you can get see more clickable points appear. You can also enter a specific address in the search bar and see aspects of the climate at that location.
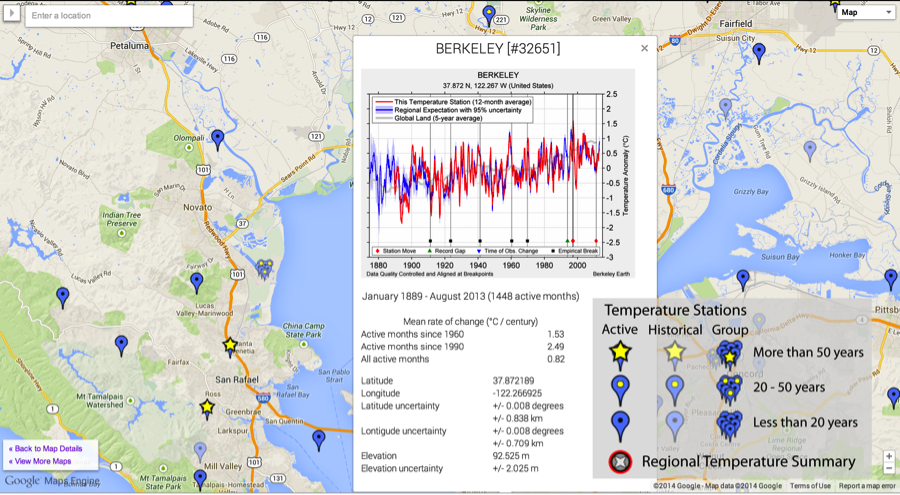
We also have a map of all ~40,000 stations in our database, markers for each that show the homogenized record for that station when clicked. These highlight all the detected breakpoints, and show how the station record compares to the regional expectation once breakpoints have been corrected. You can also click on the image to get to a web page for each station that shows the raw data as well as various statistics about the station.
New Global Temperature Series
Berkeley Earth has a new global temperature series available. This was created by combining our land record with a Kriged ocean time series using data from HadSST3. The results fit quite well with other published series, and are closest to the new estimates by Cowtan and Way. This is somewhat unsurprising, as both of us use HadSST3 as our ocean series and use Kriging for spatial interpolation.
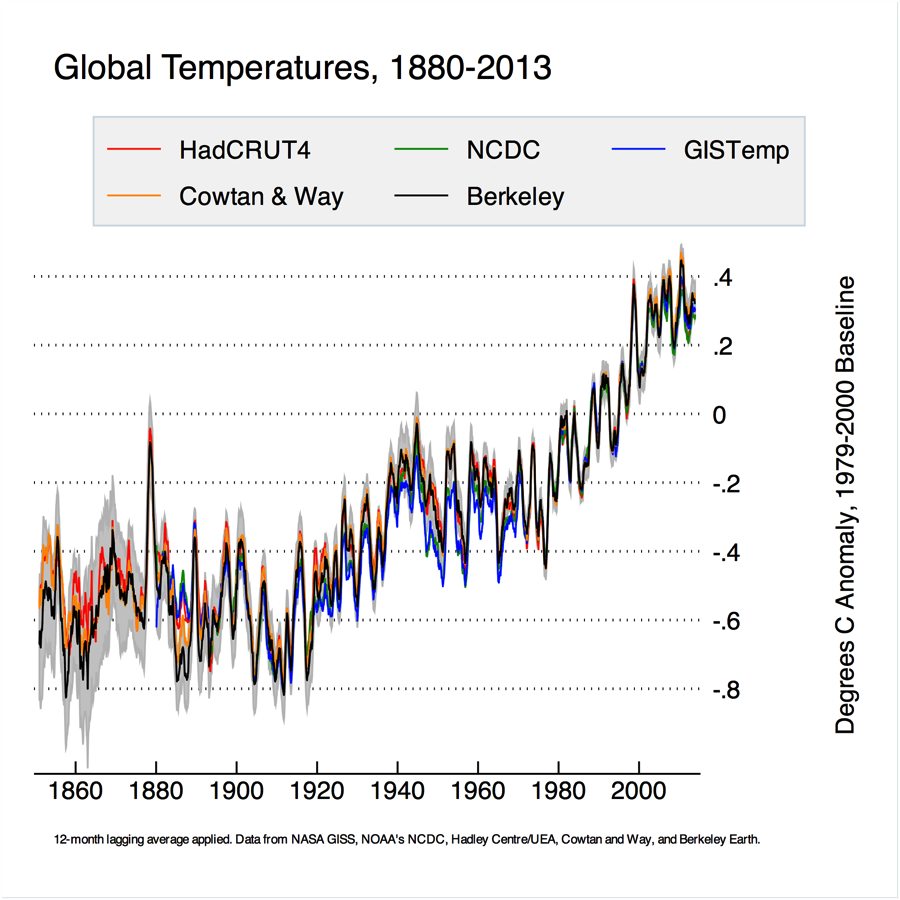
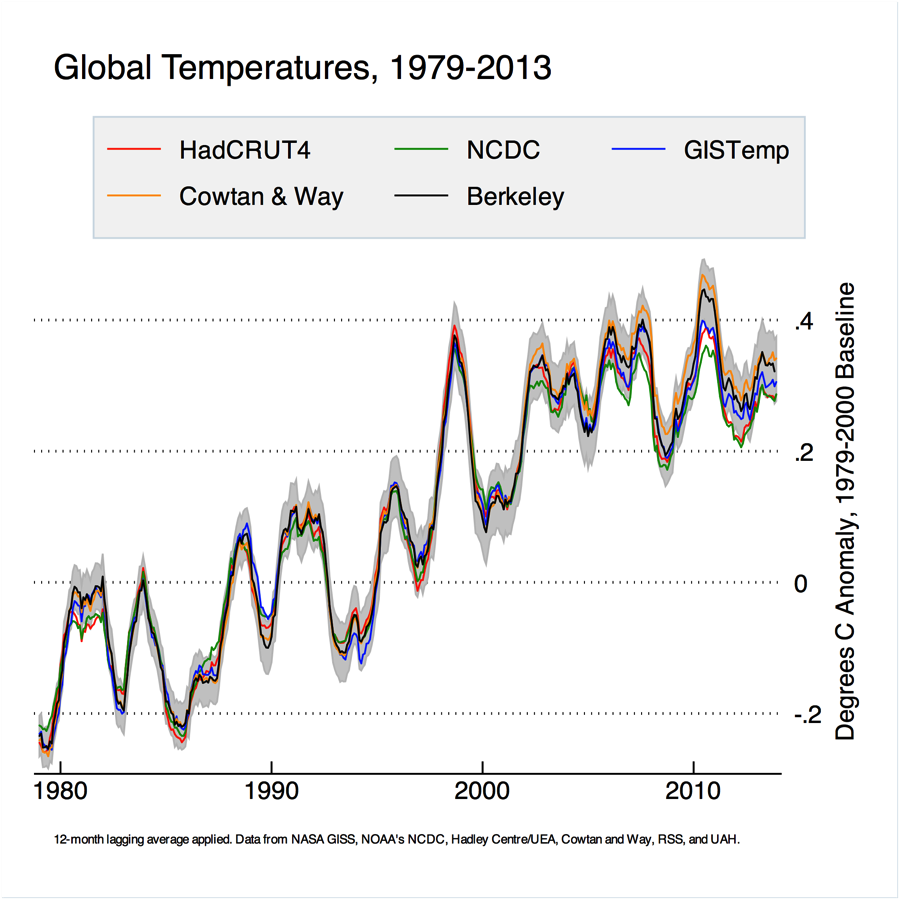
If we zoom into the period since 1979, both Berkeley and Cowtan and Way have somewhat higher trends than other series over the last decade. This is due mainly to the coverage over the arctic (note that we use air temperature over ice instead of sea temperature under ice for areas of the world with seasonal sea ice coverage).
This is fantastic work. I’ve been making constant use of the BEST/Google maps station browser to tackle the very interesting question of why our trends are higher than GISTEMP (which also extrapolates air temperatures over sea ice). It’s unfortunately far from simple, but the combination of your tools and MERRA have allowed us I think to crack an important piece of the puzzle.
Writing it up is taking a while though. Hopefully we’ll have a rudimentary report later in the month.
Kevin,
Glad the maps are useful! Let us know if you have any other suggestions of interesting maps to make, as we can probably expand a bit in future releases. We have a figure showing the difference between HadSST3 and our Kriged version which might also be of interest: http://static.berkeleyearth.org/graphics/land-and-ocean/land-and-ocean-sst-interpolation-nov-1997-large.png
Folks can also find full (1880-2013) daily temperature movies below. Note that they are each an hour or so long, so unless you are really a daily data aficionado they are mainly useful for finding specific days of interest.
Anomalies (1880-present): http://www.youtube.com/watch?v=mzBm1ra23lE
Absolutes (1880-present): http://www.youtube.com/watch?v=0aemzFhg1ZQ
It turns out that, prior to the airport’s construction, the station now associated with the airport was on the top of a black roofed building closer to the city. This is a common occurrence for stations in the U.S., where many stations were moved from city cores to newly constructed airports or wastewater treatment plants in the 1940s.
This effect can be seen with even “dead simple”*** processing of raw temperature data. Exclude the stations that have been moved to airports, and the raw data results align amazingly closely with the published NASA “met stations” results.
Below are 3 plots. The first shows the results of simple anomaly gridding/averaging using all temperature stations. The second shows the results of the same procedure using only stations located at airports. And the third shows the results using only stations *not* located at airports. (The airport/non-airport station status can be found in the GHCN metadata files).
The simple gridding/averaging results are shown in green. The official NASA/GISS “meteorological stations” results are shown in red (included for comparison purposes).
1) All Stations: https://drive.google.com/file/d/0B0pXYsr8qYS6ZElMLXViN1ZuYlU/edit?usp=sharing
2) Stations at airports: https://drive.google.com/file/d/0B0pXYsr8qYS6Y1NnOG45ZWtXM3c/edit?usp=sharing
3) Stations not at airports: https://drive.google.com/file/d/0B0pXYsr8qYS6eVI2SWlMRkNOWVU/edit?usp=sharing
The pre-1940 warm bias is clearly seen in (1) and especially in (2). When all airport stations are excluded from the processing (3), the bias largely disappears.
*** Gridding with 20deg x 20deg grid-cells (at the Equator), longitude dimensions adjusted to keep the grid-cells as nearly constant as possible as you move N/S. (No grid-cell interpolation — just baselining, gridding, and averaging.) You could teach this stuff to on-the-ball first-year programming students.
I am not sure whether this dataset is such an improvement. When I understand the homogenization procedure of BEST right, it only corrects errors in the mean. The example of a move from black roof in a city to an airport is also a good example that not only the mean changes. The black roof will show more variability because on hot sunny days the warm bias is larger than on windy cloudy days. Thus we would need a bias correction of the complete probability distribution and not just its mean. Or we should homogenize the indices we are interested in, for example the number of days above 40°C. The BEST algorithm being fully automatic could be well suited for a an approach.
Another problem I see is the use of kriging. The variability will change with the number of stations available to estimate the daily means of a grid box. It will be hard to distinguish changes in weather variability with changes in the error in this estimate due to changes in the configuration of the station network. Thus I would feel it is saver to analyse changes in extremes and weather variability on station data and avoid the additional problems of gridded datasets, especially at daily scales.
Robert, Zeke,
Congratulations on these two new products.
Here is an updated comparison of models to 2013, including the new BE land+ocean set.
http://deepclimate.files.wordpress.com/2014/03/cmip5-rcp4-5-comp-2013.jpg?w=777
I take it that difference between your data set and Cowtan and Way in recent years is mainly due to a greater slowdown in the BE land temperature analysis (although the C&W hybrid methodology probably accounts for a small part of the difference as well). I have some ideas of the source of that slightly more pronounced slowdown in BE, and I look forward to discussing these with you.
Meanwhile, this does provide yet more confirmation that coverage bias is increasingly problematic in the data series that do not attempt to address observational gaps.
From the data of caerbannog on airports, mentioned above, I have made the following figure:
pic.twitter.com/TBTit3fdew
One should be careful with daily data only homogenized with respect to the mean. And when studying extremes and variability one should be careful with kriging.
I have explained why on my blog: Be careful with new daily temperature dataset from Berkeley.
The problem Victor is that “now at an airport” doesn’t tell you anything about the history of a station. Plus, the GHCN metadata is not exactly current or accurate. “at an airport” can mean associated with an airport but located some distance away. So the charts indication perhaps the upper boundary on the effect. Further, Zeke was talking about the practice in the US. whether that was the same world wide is an open question
This is good work but something has bothered me about the underlying SST data.
The new BEST Land+Ocean is largely the Berkeley Land data set tacked on to the HadSST3 data set with minimal changes to the latter (I can’t see any). BEST could have made the decision to go with the ERSST data set from NOAA but Steve Mosher indicated that the HadSST3 had better documentation on the errors than the ERSST.
HadSST3 I think does a better job than the ERSST on capturing the early years, for example it seems to detect the Krakatoa cold excursion better than did the ERSST.
Where I think HadSST3 fails is in capturing the WWII anomaly, and the years thereafter.
http://imageshack.com/a/img35/3662/1jy8.gif
How can HadSST3 and ERSST both show a similar level during the 1940-1945 time frame, but HadSST3 have all those adjustments in the subsequent 10-20 years? I don’t understand this. One side of the Atlantic must think much differently about adjustments than the other.
Between GISS, NOAA-NCDC, HadCRUT, and BEST, there has to be some sort of “ground truth” here and I believe that an agreed upon common time series can be established. I hoped that BEST would act as a tie-breaker and figure this difference out because I thought that was their original charter — to make sense out of the confusion over the way people viewed historical temperature readings.
How about a map showing changes in population density over time? Correlate this with a change in temps and I’m sure we’ll see a connection between them.
RHP.
Steven Mosher says: “The problem Victor is that “now at an airport” doesn’t tell you anything about the history of a station. Plus, the GHCN metadata is not exactly current or accurate. “at an airport” can mean associated with an airport but located some distance away. So the charts indication perhaps the upper boundary on the effect. Further, Zeke was talking about the practice in the US. whether that was the same world wide is an open question.”
I am not sure which point you are making. Methodological questions should go to caerbannog. I only plotted his data. I think it is intriguing and I hope someone will find the time to make a scientific study out of it. There is a similar simple analysis by Nick Barnes on airports, which find similar numbers.
We actually have one advantage over Watts et al., which only have information on the end point. In case of airports we also know that in 1880, the stations were not at an airport.
The plot shows a trend bias for the stations that are now at an airport. It does not show the trend bias in the total dataset. Then we would need good metadata and would also need to know exactly how many stations are at airports.
“If we zoom into the period since 1979, both Berkeley and Cowtan and Way have somewhat higher trends than other series over the last decade.”
For recent short-term trends, I see Berkeley Earth between Cowtan & Way and GISTemp, but closer to GISTemp (depending on start of short-term trend).
http://deepclimate.files.wordpress.com/2014/03/cmip5-rcp4-5-comp-2013.jpg?w=777
Victor.
A couple points.
I made my comment to you because I know you. It’s a pretty simple point regardless of who did the charts or who had similar results.
1. The metadata on airports in GHCN is dated. It’s easy to update it using current airport locations. ask me if you’d like the code.
2. Even with that you need to look at station history which is no simple
task.
So, I would say, that the effect one sees is a good indication that there
may be an issue, but its not as definitive as the title of your chart indicates. That’s all.
Next: I’m not so sure your about concerns over kriging. First to qualify for use a daily station required 100% coverage during the month.
But your concern is noted and it might be interesting to see if we can come up with a test for how important that is.
Sorry Victor, yes it would make a good study. I started looking at it some time ago, but the station history data in much worse shape then. perhaps I’ll revisit it or at least try to make the metadata available for somebody who wants to do the work.
Best
Steve
“How about a map showing changes in population density over time? Correlate this with a change in temps and I’m sure we’ll see a connection between them.
I’m working on that for another post related to some errors in mckittrick and micheals (2007, 2010) it may be done a few weeks.
There are several difficulties with this.
1. Station locations. For a good number of the stations the location data may only be good to 10km or so. For other stations the location data is good down to 30 meters or so. and locations change.
2. Because of the station location differences you have to make some choices about what population data to use and what resolution. Do you use gridded data what resolution?( 1arc second, 2.5 minutes, 5 minutes? etc )
3. What time periods do you want to look at? depending on your answer to #2 you have different choices.
In any case I’m assembling a data set of population density back to 1750 so that folks can look at this if they want to. I don’t think the picture will be as clear as you suggest.
Hi Victor,
Thanks for the comments. I agree that our homogenization is necessarily imperfect; it relies on detecting larger changes in the mean and will not effectively capture some types of changes in variability. That said, there have been a number of papers trying to look at questions of variability and extremes using raw daily data, and this dataset should at the very least provide an improvement on that.
On airports, I also looked at that question a few years back, though I found that spatial coverage differences between airport and non-airport stations introduced some bias in the comparison. The article is here: http://rankexploits.com/musings/2010/airports-and-the-land-temperature-record/
A good approach would be to find pairs of stations close to one another with overlapping records where one is an airport station and one is not. Updating airport classifications in the station metadata, as Mosher suggests, would also be helpful.
Hi Zeke, Yes, there are much too many studies where people analyse raw data for changes in extremes and weather variability. Homogenization wrt to the mean is an improvement, but only a partial one. I thought this post was a good occasion to bring that to the attention. Too many authors and reviewers do not seem to worry enough.
The climate sceptics of the IPCC warned quite clearly that inhomogeneities in the tails of the distribution are more problematic as the ones in the mean.
Nice to see you have studied airports already in more detail. Looks like collocation is important. Strange that the difference becomes even smaller.
If the UHI has some importance, you would expect that a relocation from a city to an airport would on average result in a strong cooling trend bias. Thus I was already somewhat surprised that the data of caerbannog showed so little effect. What seemed to fit quite well that the jump was around WWII, which at least in Europe was a frequent date for such relocations.
Naturally this jump would only be there for stations that were in a city before, so one may want to restrict such a study to long series and remove shorter stations that may have been erected together with the airport.
Steven and Zeke, why do you worry so much about the metadata? The stations mentioned as airport, especially the ones with airport in the name, will be airports at the moment, not? Seems hard to do that wrong. The non-airport class, may not be perfect.
I vaguely remember that the Berkeley product includes data from many, many more stations than HadCRUT. Is it correct?
[Response: Yes. – gavin]
@Victor Venema, especially beginning at Comment #4,
These kinds of issues are one reason why I find Bayesian procedures in experimental work to be particularly compelling. Sure, you build in models comparable to kriging and there are commitments to general forms of priors (although that is less of an issue these days), but the setting of kriging parameters is not done primarily by numbers of points, but by hyperpriors which borrow information not only from the locale but from other cells. It’s hard to be specific without math. The availability of a hierarchy for a model also lets the student build in terms to account for possible distortions, and then regress on data to see directly how important or unimportant they are based upon the data.
I see a significant risk in a detailed, highly manual procedure trying to account for This Bias And That. You can never be sure if you have them all, you can never be sure you did them all right, and, worst, it’s not easy to put a number of these procedural risks. I’d rather let the data speak.
Anyone working on a comparison of these new datasets with HadCRUT4 ensembles? I’m interested and working on a study of how resampling of HadCRUT4 ensembles can in many instances deceive the student by producing an estimate of variance in them which is substantially too small. There are a couple of reasons for that which are too technical to go into here. I’m trying to figure out, however, how much an understatement in coverage affects that, and if I can quantify in the HadCRUT4 data how much is due to missing data effects and how much this understatement of variance. In particular, Arctic or anywhere, if there are missing observations in HadCRUT4, I’m interested in what’s typically used as a means of imputation or, more in the spirit of that dataset, how to correct in its variance for these missing values.
BTW, there’s an R workspace with HadCRUT4 in it available according to the links and procedures specified at http://hypergeometric.wordpress.com/2014/01/22/hadcrut4-version-hadcrut-4-2-0-0-available-as-rdata-r-workspace-or-image/
Hi Victor,
You are right to note that there are many kinds of inhomogeneities, and some are going to harder to deal with than others. In part, we hope this first version of the data set will help to generate feedback from potential users about possible issues and limitations.
As you note, spurious changes in variability are a particularly challenging problem. In some small part, we improve this situation by determining homogeneity adjustments for max, min, and mean temperatures separately. This will help in some situations where the microclimate of the station has a spuriously high or low diurnal range (as might be observed from a station placed near a man-made surface). However, that will only help some kinds of situations (and can even give detrimental adjustments in some cases). The general problem of disturbed variance is an issue I’d like to look more closely at, though I don’t know of any truly good solutions.
Of course, looking at individual station data is always an alternative when studying variability and extremes. If you really trust that those stations are reliable, then station data is probably the best thing one can use. However, both Berkeley and NOAA estimate that most stations longer than a couple decades have been subject to significant biasing events, which suggests that determining long-term trends from station data is likely to be a perilous endeavor.
One hopes that by carefully combining many stations into regional averages and identifying biasing events, one can extract more reliable information than from individual records. Such interpolated fields may work well for some kinds of questions and less well for others. For example, the resulting field generally captures information at a regional scale (e.g. 100 km) while true local effects may get mistaken for noise.
As you note, changes in station network composition can become a confounding factor for some kinds of climate analysis. This will be an issue for all kinds of reconstruction that allow network composition to vary over time (not just Kriging). We can’t eliminate it, but hopefully one can use statistics and simulated reconstructions on GCM data to determine the likely magnitude of the impact for various variables of interest and avoid drawing erroneous conclusions. In general, we would expect the fields to be very robust when densely sampled data is available, and perhaps less so at times and places that have been less well monitored.
Ultimately, all forms of climate and weather analysis are likely to suffer from limitations. It is our hope that this new data set will provide a useful point of comparison relative to other techniques, and that different ways of looking at natural processes will make it easier to get at the underlying truth.
I think I need a course in Kriging and some math courses in Hilbert space to go with it.
Is there a correction you can apply for being on a black roof? I don’t envy you having to deal with that historical data.
Berkeley Earth Temperature Analysis – possible flaws?
I have discovered that there are some flaws in Berkeley Earth’s temperature analysis.In several cases they have made a double counting of Danish weather stations. Below is a list of some of the double counted stations:
1. Vestervig and Vestevig-1
2. Nordby and Nordby(FANO)-1
3. HammeroddeFyr and Hammerodde Fyr-1
4. Maribo and Maribo Airport
5. Floro AP and Floro Lufthavn (Norway)
These examples can be used for testing the weather station identification computer program of BEST.
If there are many of these artificial weather stations, questions might be asked about the validity of BEST’s results.
The cause of the existence of the artificial stations might come from reading data from several sources with differences in the geographical coordinates and differences in data. It is a problem not created by BEST, but by the providers of temperature data.
It might be discussed who is responsible for checking the data before they are used, however I think it must be the responsibility of BEST to do it.
In respect of Prof. Richard Muller’s harsh critique of climate science, BEST cannot or should not ignore this double counting problem.
For more details:
http://www.climate-debate.com/forum/berkley-earth-temperature-analysis-possible-flaws–d11-e291.php
Jan Galkowski says: “These kinds of issues are one reason why I find Bayesian procedures in experimental work to be particularly compelling.”
I would personally expect that any gridding method would have problems with a changing number of stations. Studying variability and thus extremes is fundamentally more complicated as the means we are used to study.
Robert Rohde says: “As you note, spurious changes in variability are a particularly challenging problem. In some small part, we improve this situation by determining homogeneity adjustments for max, min, and mean temperatures separately. This will help in some situations where the microclimate of the station has a spuriously high or low diurnal range (as might be observed from a station placed near a man-made surface).”
The diurnal temperature range is a great variable to find breaks. Break in Tmin and Tmax are often negatively correlated.
Edward Greisch says: “Is there a correction you can apply for being on a black roof? I don’t envy you having to deal with that historical data.”
You can make two measurements in parallel. In this specific case: one on the roof and the other at the local airport. To study the problem of the roof itself, you can make a measurement on the roof and in a nearby garden.
Many such measurements exist and “only” need to be analysed, but we also need much more of such measurements.
Klaus Flemløse says: “In several cases they have made a double counting of Danish weather stations. Below is a list of some of the double counted stations: “
The International Surface Temperature Initiative (or more accurately Jared Rennie) has developed a merging algorithm that should remove such double counting. I would be appreciated if you could you have a look whether you can find similar problems here. How did you find these doubles?
Hi Klaus,
When there are two stations that do not have identical location data (lat/lon) or identical observations, our merging algorithm will tend to classify them as two different stations. This can happen occasionally when the same station appears in different datasets (say, GSOD and GHCN-D) but with different locational precision and different methods of calculating the mean. On the other hand, an algorithm that is too aggressive in merging datasets will result in stations being lumped together that should not be due to small overlaps of identical values (e.g. a station in one location that gets merged with a station in a new location in one database, and a different station at a new location in another). We’ve run into this issue a few times as well, most notably with the central park/Laguardia stations in New York City.
The good news is that having a few accidental duplicates will make no difference on the resulting temperature fields. Unlike a more traditional gridding analysis, where each station is given equal weight in estimating grid cell-level anomalies, the Kriging approach will give no additional weight to two locations at (effectively) the same location. The only time I could see it causing issues is if one duplicate station has significant differences in lat/lon coordinates compared to the other.
We are always working to improve our station merging process, but this is likely an issue that we can mitigate but not totally eliminate. As long as there are duplicate stations with different names, locations, and non-identical anomalies reported, it is difficult for us to automatically determine that they are, in fact, duplicates. We will maintain a list of ones that people have identified, and perhaps add in a manual duplicate removal step in a future release.
On the BEST homepage there is another funny flaws:
When you search for “Denmark”, there will be two cases:
DENMARK
DENMARK(EUROPE)
Flaw nr. 1.
The first DENMARK is a city in USA and not a Country or State. This means a wrong classification.
Flaw nr.2.
Both DENMARK’s have the same nearby city: Copenhagen, Malmø, Århus.
This is not correct.
These flaws are only funny formal flaws and might not affect the temperature estimation at all.
#24:
“I would be appreciated if you could you have a look whether you can find similar problems here. How did you find these doubles?”
I tried to compare BEST results with what I know as Danish weather stations. It is a manual process to compare.
There might be many more double counted weather station in Scandinavia and Germany. It is time consuming task to identify those.
In general, I am a fan of the Berkeley Earth approach for reconstructing past temperature variations – particularly because they present their data in an open user-friendly manner which should have long ago been adopted by some of the other groups. Mathematically the approach they use is fairly solid which allows for a higher spatial and temporal resolution of the end product.
However, there are a few concerns that I have – maybe not as strong as to say concerns – but perhaps questions is a better word.
[1] Approach – I believe they create a baseline climatology as a function of lat, long, elev for all land areas using what looks like a form of spline – Anuspline – a program for interpolating temperatures uses a similar approach. The residual from the climatology surface is then kriged and re-added to the climatology. They then subtract the baseline climatology for every station and krige the anomalies back through time. Once anomalies are spatially and temporally kriged they re-add the surface climatology to the anomalies to produce their absolute air temperature gridded product. Outliers are adjusted by comparing this surface climatology through time field to the actual observations and then the process is iterated with the variables recomputed.
My only questions pertain to how heavily reliant the approach is on a surface climatology that is unlikely to be simply a function of X,Y,Z with a spline and re-adding interpolated residuals.
Perhaps it is naivité on my part but would it not be more accurate to produce a baseline surface by spatially interpolating the anomalies from a CAM style calculation and then forward/backward model the stations which are not available during the CAM period using this kriged anomaly surface to then cover the CAM period and then estimate the surface climatology. My intuition tells me that there is less uncertainty is estimating the monthly baseline temperature at position X using the forward/backward model with spatially kriged anomalies than using an X,Y,Z function where the errors can be an order of magnitude greater.
[2] The adjustments – I’ve examined a lot of individual high latitude stations in BEST and I find it curious how frequently the raw temperatures are adjusted (even by small amounts). I can understand how the BEST approach works very well for monitoring long term temperature trends but for absolute values I am somewhat concerned in using the adjusted series. If there is a high quality series which has not changed position or had any other inhomogeneities I’m having trouble understanding why this series would be adjusted. I guess what I’m describing is that I am concerned that the tolerance threshold for deviation from the regional expectation is too low and that series which have local variations which differ from the regional expectation might experience some smoothing.
Overall very good work though and well-documented. Thank you for your contributions.
Hi Zeke
I am pleased to know that the BEST is aware the double counting in the database. But it is not sufficient to recognize the problem. You must estimate the extent of the double counting. Is it 1%, 5% or 10% of all weather stations ?
For your information, there are two additional double counting from Norway
OKSOY FYR and OKSOEY FYR
KJEVIK and KRISTIANSAND/KJEVIK
I could probably continue for some time to find the double counting of weather stations in the BEST database.
You will end up with additional examples to test the merging algorithm. I suppose you will be happy as well as angry with me at the same time. However, I have other things to do.
Hi Zeke,
It appears that there is a slight difference between the version of the land-ocean summary you show at bottom right and that available in the archive (dated Febuary 13).
http://berkeleyearth.lbl.gov/auto/Global/?C=M;O=D
My emulation of your figure is exactly the same for the other series, but Berkeley Earth is slight warmer in 1980 and slightly cooler in 2010 in the archived series, compared to your figure.
See:
http://deepclimate.files.wordpress.com/2014/03/global-surface-temps-1980-2013.jpg
Below are trends (in deg C per decade) for 1979-2013, 1998-2012 and 1999-2013. I have included both the hybrid and infilled versions of Cowtan and Way, version 2. As mentioned previously, Berkeley Earth is much closer to NASA GisTemp, than it is to Cowtan and Way.
79-13 | 98-12 | 99-13
====================
0.174 | 0.119 | 0.143 C&W (hybrid)
0.175 | 0.108 | 0.133 C&W (infill )
0.160 | 0.082 | 0.105 Berkeley Earth
0.157 | 0.070 | 0.098 GISTemp
0.154 | 0.042 | 0.073 HadCrut4
0.148 | 0.035 | 0.068 NOAA
=====================
Deep,
Looks like I was using a pre-release version that was slightly different than the final released version, particularly in 2010. Here is a figure showing the differences: http://i81.photobucket.com/albums/j237/hausfath/berkeleynewoldCWGISS1979-2013_zps8ef7a0c1.png
I’ll check with Robert to see what the difference in the code was for those two runs.
I agree that trend-wise we are closer (albeit slightly warmer) to GISS, at least for the modern period (1979-present). We are notably closer to C&W in the earlier part of the record, however. We are working with Kevin and Robert to explore difference between our results in more detail.
Robert,
The former is more of a question for Robert Rohde, and I’ll pass it his way. As far as the latter goes, its quite possible that the Berkeley approach overly smooths at a local level. Its an issue we’ve known for some time, and a consequence of our decision to focus on getting the best regional climate reconstruction rather than the best local fidelity. NCDC’s PHA will likely give you better local temperatures, though (we’d argue) somewhat more inhomogenious regional trends (see our AGU poster this year for some comparisons).
“Ask any climate scientist: Carbon pollution from dirty energy is the main cause of global warming.” http://clmtr.lt/c/DXT0cd0cMJ
Hi Zeke,
Here are recent trends (again in deg per decade) for land surface. Over the satellite period, Berkeley Earth has the lowest trend, but does show a bit less “slowdown” than HadCrut4 and NOAA. NASA Gistemp appears warmer over the entire period, and in the recent short term.
79-13 | 98-12 | 99-13
====================
0.261 | 0.125 | 0.169 NASA
0.267 | 0.100 | 0.144 NOAA
0.253 | 0.091 | 0.129 HadCrut4
0.250 | 0.115 | 0.149 Berk. Earth
=====================
As I first noted in 2012, the Berkeley GHCN (using GHCN stations only) series is warmer than the various regular Berkeley Earth vesrions. See this update:
http://deepclimate.files.wordpress.com/2014/03/berkely-earth-comparison1.jpg
Trends for 1979-2011 are:
=================
0.26 Berk. Earth
0.27 NASA
0.27 HadCrut4
0.28 NOAA
0.28 BE GHCN
=================
Berkeley Earth has the lowest trend while the BE “GHCN only” is up with NOAA. This suggests that there may well be a cool bias related to additional stations added in certain regions. Alternatively, some sparse regions may have bona fide regional cooling that is not captured from GHCN. Careful testing of the Berkeley Earth sensitivity to different data scenarios in different regions is required to resolve this discrepancy.
Hi Zeke, hi Robert,
great that you have made a BerkeleyEarth land and ocean dataset of global mean temperature.
I have a question regarding absolute temperature.
The BerkeleyEarth 1951-1980 land+ocean global mean temperature is stated as 14.774 °C.
This is substantial more then HadCRUT 13.9 °C (1961-1990) and NOAA/NCDC also 13.9 °C (1901-2000).
Is this difference due to the ocean or due to the station data?
Or there are differences at the seaice area? Or maybe with the altitude?
At least HadCRUT gives a 5°x5° gridded file with absolute temperature. So I ask what is the spacial distribution of the difference between the BerkeleyEarth and the HadCRUT in absolute temperature? Is this difference rather uniform or are there a large scatter? Depend this on the month?
Any reason for that? Especially because you use the HadSST3 data for the ocean.
Hi Uli,
Regarding the average temperature values, there are some spatial differences in temperature pattern but the bulk of the difference relates to a systematic question of comparing sea surface temperatures to air temperatures.
Spatially the principal differences between HadCRUT and Berkeley annual averages occur over two regions, Antarctica and the North Atlantic (60-80 N). Over Antarctic land there are both warmer and colder spots in Berkeley’s estimation, though warmer on average. HadCRUT uses very little data over Antarctica, so I wouldn’t be surprised to see differences here. In the the North Atlantic, we are systematically warmer over the sea ice regions and somewhat colder over Greenland. The spatial differences vary locally from a few degrees to several degrees C.
Those differences, though interesting and warmer on average, occupy relatively little surface area and aren’t the main reason for a different average. The biggest difference is a small systematic offset over the bulk of the oceans. To understand this I need to go on a little digression.
The HadCRUT absolute climatology is a quasi-independent data product that uses land and ocean data, but isn’t directly constructed from HadCRU’s land and ocean anomaly data sets (see Jones et al. 1999). For example, the HadCRUT absolute field brings together more station data in many land regions than they use in their anomaly data (see New et al. 1999). Another difference is that though sea surface temperature (SST) is used for determining HadSST and HadCRUT anomalies, the absolute temperature field over the oceans reported with HadCRUT is calibrated to match marine air temperature (MAT). SSTs are typically 0.5-1.5 C warmer than MAT at the same location.
In the Berkeley Land + Ocean data we consistently used SST values for both anomalies and absolute values over the open ocean. Doing so results in an estimate of the absolute field over oceans that is systematic warmer than if you do the calibrations in terms of MAT. Using MAT is probably more consistent with the notion of defining a global average temperature over both land and ocean, so there is a argument to recommend that approach. On the other hand, creating data sets that mix MAT absolutes and SST anomalies is likely to cause confusion for some users. At present, we opted to use a consistent data type (all SST) for the oceans, though it is a question we may revisit in the future.
Hi Robert,
thank you for the answer. So the main difference in is due SST/MAT calibration.
Dataset experts needed. This should be easy for you. I refer to tamino
http://tamino.wordpress.com/2014/03/19/what-were-up-against/
The original base line mistake is just standard error for the source, but there still seems to be non-correspondence with the mapping program here:
http://data.giss.nasa.gov/gistemp/maps/
Can you straighten this out?
Hi Robert,
I have another question regarding absolute temperatures.
I’ve been looking at european countries for temperature timeseries here:
http://berkeleyearth.lbl.gov/country-list/
Most countries seems so far ok, but the absolute temperature of Monaco is far too cold.
http://berkeleyearth.lbl.gov/regions/monaco
http://berkeleyearth.lbl.gov/auto/Regional/TAVG/Text/monaco-TAVG-Trend.txt
It is given at 9.11+/-0.43°C, colder even then France.
http://berkeleyearth.lbl.gov/regions/france-(europe)
http://berkeleyearth.lbl.gov/auto/Regional/TAVG/Text/france-(europe)-TAVG-Trend.txt
France is given at 10.49+/-0.23°C mean temperature, which seems plausible.
Wikipedia gives 16.4°C yearly average for Monaco, which seems plausible.http://en.wikipedia.org/wiki/Monaco#Climate
What causes this error?
Are other countries affected? Maybe in a less obvious way?