The latest incarnation of the CRUTEM land surface temperatures and the HadCRUT global temperatures are out this week. This is the 4th version of these products, which have undergone a number of significant changes over that time and so this is a good opportunity to discuss how and why data products evolve and what that means in the bigger scheme of things.
The paper describing the new CRUTEM4 product is in press at JGR (Jones et al, 2012), and makes a number of important observations. First, on the evolution of the CRU temperature data set, from CRUTEM1 back in the mid 1980s, which used a limited selection of station data and ‘in-house’ homogenization, to CRUTEM2 around 2003, CRUTEM3 in 2006, and now CRUTEM4 which has a wider data sources and relies much more on homogenization efforts from the National Met Services themselves.
Second, the paper goes into some detail about how the access to data, and reasons for the above changes, the history of homogenization efforts, and the current status of those efforts. Much of this is excellent background information that deserves to be more widely known. For instance, the timing of the CLIMAT (monthly average reports) available almost immediately, MCDW (Monthly Climate Data for the World) after a few months, and the World Weather Records (WWR) (once a decade, last one issued for the 1990s, next one due soon) has a much larger influence on spatial coverage and station density than would be ideal.
The third point is how this product differs from similar efforts at GISTEMP, NCDC, and (though not mentioned) the Berkeley Earth project. The basis for GISTEMP and NCDC is GHCN for the majority of their records, so there is a lot of overlap (95% or so), but there are big differences in how they deal with grid-boxes with missing data. GISTEMP interpolates anomalies from nearby grid points, Berkeley uses kriging, while NCDC and CRUTEM estimate global means only using grid boxes with data. Since many missing data points in CRUTEM3 were in the high latitudes, which have been warming substantially faster than the global mean, this was a source of a low bias in CRUTEM3 (and HadCRUT3), when these data products were used to estimate global mean temperature trends. The increase in source data in CRUTEM4, goes some way to remove this bias, but it will likely still remain (to some extent) in HadCRUT4 (because of the sea ice covered areas of the Arctic which are still not included). Another improvement is in how the error bars are being estimated – due to data sparsity, autocorrelation, structural uncertainty, and assumptions in the synthesis.
The CRUTEM4 data is available here and here, along with links to the full underlying raw data (minus Poland) and the code used to process that data (this is not quite finished as of when this post went live). This is a big step forward (but like the release of the code for GISTEMP a few years ago, it is unlikely to satisfy the critics).
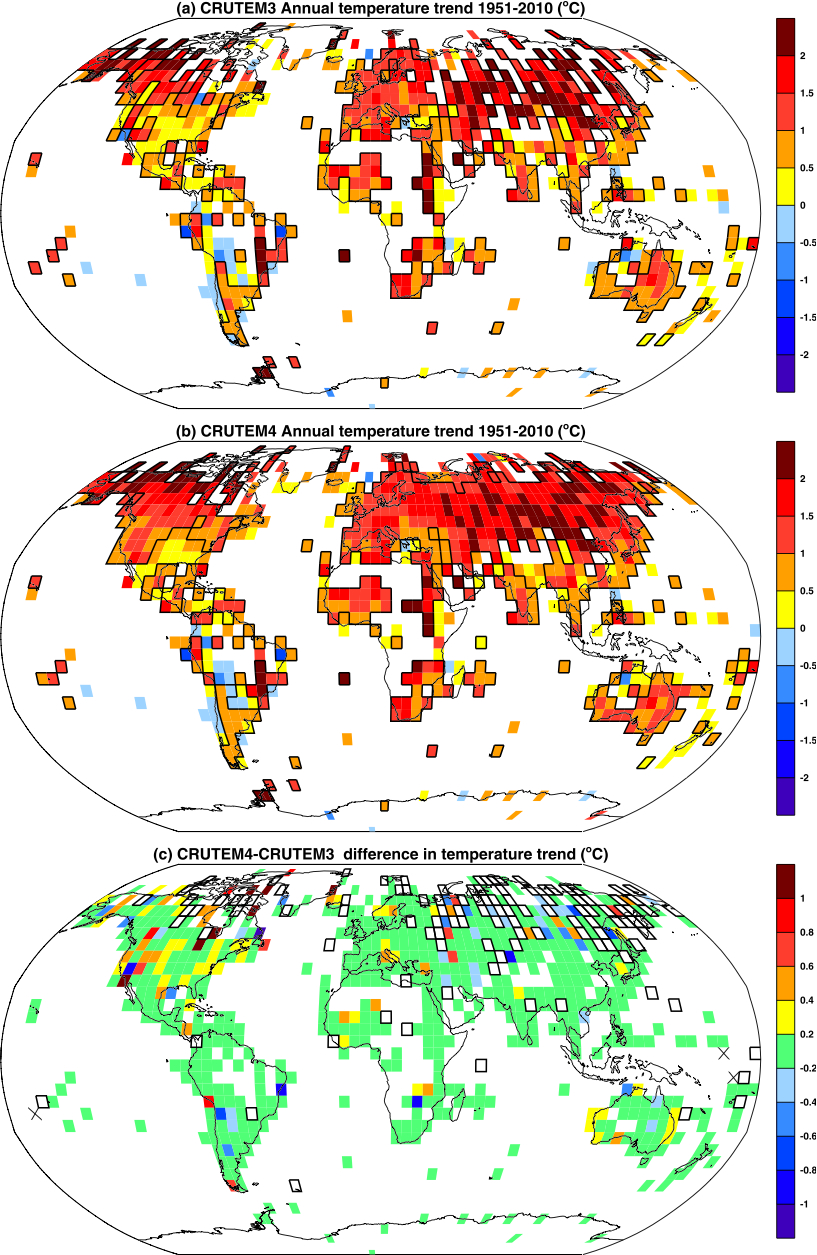 So what does the CRUTEM4 data look like?
So what does the CRUTEM4 data look like?
Overall, changes are small (see figure to the right, showing the trend (°C/60 years) for each CRUTEM3 (top), CRUTEM4 (middle) and the difference in their trends (bottom)). There is no change to the big picture of global warming in recent decades, nor in its regional expression. Where there are noticeable changes, it is in coverage of high latitude regions – particularly Canada and Russia where additional data sources have been used to augment relatively sparse coverage. Given the extreme warmth of these regions (and the Arctic more generally) in recent years, combined with the CRUTEM procedure of only averaging grid boxes where there is data (i.e. no interpolation or extrapolation), this extra coverage makes a difference in the trends.
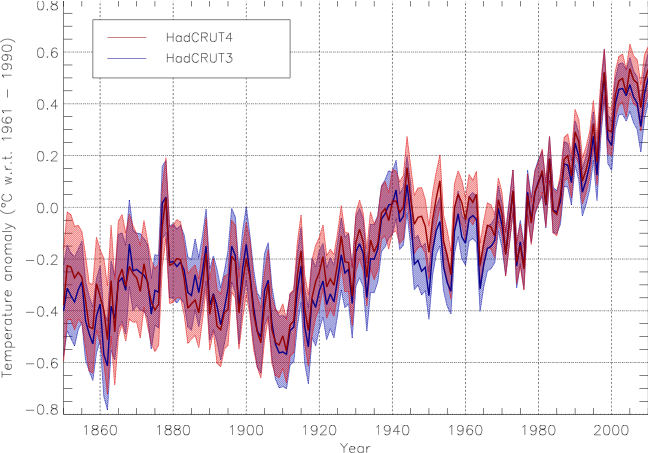
There will of course be an impact on the combined ocean and land temperature record, HadCRUT4. This incorporates (and bring up-to-date) the HadSST3 product that we discussed last year. The paper describing HadCRUT4 is also in press (Morice et al, 2012).
As expected, the changes (a little from both data sets) lead to a minor rearrangement in the ordering of ‘hottest years’. This is not climatologically very significant – the difference between 1998 and 2010 is in the hundredths of a degree, and most of the attribution work on recent climate changes is looking at longer term trends, not year to year variability. However, there is now consistency across the data sets that 2005 and 2010 likely topped 1998 as the warmest years in the instrumental record. Note that neither CRUTEM4 nor HadSST3 are yet being updated in real time – they only go to Dec 2010 – though that will be extended over the next few months.
There are a number of issues that might need to be looked at again given these revisions. Detection and attribution efforts will need to be updated using CRUTEM4/HadCRUT4, though the changes are small enough that any big revisions are extremely unlikely. Paleo-reconstructions that used CRUTEM3 and HadCRUT3 as a target, might be affected too. However, the implications will be more related to the mid-century and 19th C revisions than anything in the last decade.
We can make a few predictions though:
- We can look forward to any number of contrarians making before and after plots of the data and insinuating that something underhand is going on. Most of the time, they will never link to the papers that explain the differences. (This is an easy call because they do the same thing with GISTEMP all the time). (Yup).
- Since the “no warming since 1998/1995/2002” mantra is so seductive to people who like to focus on noise rather than signal, the minor adjustments in the last decade will attract the most criticism. Since these fixes really just bring the CRU product into line with everyone else, including the reanalyses, and are completely unsurprising, we can expect many accusations of groupthink, deliberate fraud and ‘manipulation’. Because, why else would scientists agree with each other? ;-)
- The GWPF will not update their logo.
Joking aside, there are some important points to be made here. First and foremost is the realisation that data synthesis is a continuous process. Single measurements are generally a one-time deal. Something is measured, and the measurement is recorded. However, comparing multiple measurements requires more work – were the measuring devices calibrated to the same standard? Were there biases in the devices? Did the result get recorded correctly? Over what time and space scales were the measurements representative? These questions are continually being revisited – as new data come in, as old data is digitized, as new issues are explored, and as old issues are reconsidered. Thus for any data synthesis – whether it is for the global mean temperature anomaly, ocean heat content or a paleo-reconstruction – revisions over time are both inevitable and necessary. It is worth pointing out that adjustments are of both signs – the corrections in the SST for bucket issues in the 1940s reduced trends, as do corrections for urban heat islands, while correction for time of observation bias in the US increased trends, as does adding more data from Arctic regions.
Archives of data syntheses however, are only really starting to be set up to reflect this dynamic character – more often they are built as if synthesis just happens once and never needs to be looked at again. There is still much more work to be done here.
But even while scientists work on ironing out the details in these products, it’s worth pointing out what is robust. All data sets show significant warming over the 20th Century – regardless of whether the raw data comes from the ocean, the land, balloons, ice melt or phenology, and regardless whether the data synthesis is performed by the scientists in Japan, Britain, the US, individual bloggers or ‘sceptics’.
References
- P.D. Jones, D.H. Lister, T.J. Osborn, C. Harpham, M. Salmon, and C.P. Morice, "Hemispheric and large‐scale land‐surface air temperature variations: An extensive revision and an update to 2010", Journal of Geophysical Research: Atmospheres, vol. 117, 2012. http://dx.doi.org/10.1029/2011JD017139
- C.P. Morice, J.J. Kennedy, N.A. Rayner, and P.D. Jones, "Quantifying uncertainties in global and regional temperature change using an ensemble of observational estimates: The HadCRUT4 data set", Journal of Geophysical Research: Atmospheres, vol. 117, 2012. http://dx.doi.org/10.1029/2011JD017187
Nice summary of the datasets. Of course, it could be noted that the community is still trying to rescue old observations from a range of sources to improve these reconstructions – including the ACRE project.
And, anyone can help by visiting OldWeather.org, and join the thousands of volunteers helping to improve our historical climate records – over 4 million sets of weather observations rescued already and still counting….
Ed.
Gavin,
Do you know if HadCRUT4 anomalies are available anywhere yet?
As far as before and after GISTemp plots go, I’ve always enjoyed the irony that (apart from things like the GHCN v2 to v3 shift) most of the small changes seen in GISTemp month to month are a result of the nightlight-based UHI correction that is applied.
[Response: I think they have just gone live – but no, I spoke too soon. You can make your own blend from CRUTEM4 and HadSST3 though… – gavin]
Dont be so sure that the GWPF won’t update their logo.
They were quicker than you to post their first thoughts on CRUTEM4 and HADCRUT4, which seem reasonable.
http://thegwpf.org/the-observatory/5262-hadcrut4-statistics-science-and-spin.html
Anyone interested in met/climate data usage, assimilation, etc. really should read “A Vast Machine” by Paul N. Edwards.
http://mitpress.mit.edu/catalog/item/default.asp?ttype=2&tid=12080
If nothing else, its list of references will keep you going for months.
I am getting a 403 for the raw data less Poland link.
[Response: Fixed – it now goes to the data description page. The zip file with all the station data less Poland is here (large). – gavin]
On the “reasonable” GWPF post: they say that “the only scientifically respectable way to describe the warmest years would be to say that 1998, 2005 and 2010 all tied, but that would have perhaps been a little to inconvenient.”
Hmm. Yes. If only GWPF had ever followed the philosophy of using “scientifically respectable” ways of describing things back when 1998 was the warmest year in the dataset… and it is funny that the author of this page is so up-in-arms about the 1998 thing, when he was the one who made a bet on 1998 records just four years ago (http://thegwpf.org/uk-news/4750-david-whitehouse-wins-bbc-climate-bet.html)… and I’m not at all sure of what he means when he says “Finally it has been suggested that if HadCRUT4 was used instead of HadCRUT3 i would have lost my recent climate bet. It wouldn’t have made any difference to the outcome”, since, as I read the bet, it was just about whether 1998 would be exceeded.
-MMM
(mind you, the real way to talk about this sort of thing is long-term trends alongside best estimates of forcing and heat uptake, not quibbling about the warmest year, or the trend for a 10 year period… did you know that if you start calculating trends in, say, 1979, the largest trend you get ends in 2005, not 1998?)
Is saying that “2010 and 2005 likely topped 1998 as the warmest years” or the that lead 2010 has over 1998 is in the “hundredths of a degree” a way to demonstrate a proper application of statistical understanding?
Would it not evoke a greater understanding of statistics to say in a completely un-caveated way that 2010, 1998, and 2005 are indistinguishable from one another as a “warmest” year, given the margins of error?
If it is truly “not that climatologically significant”, then why bother making statements that stretch the value/meaning of 2010 or 2005 in the way that others have done with 1998?
One of the strengths of the temperature data and individual records was that although they had negative and positive biases they correlated closely but emphasised individual regional climate trends at different times.
Therefore as a scientist maybe you would admit ‘bringing Hadcrut into line with everyone else’ represents a less useful collective product than before if it has lost that interesting mix.
You suggest the relatively insignificant changes Hadcut4 alone are minimal’This is not climatologically very significant’ but then point to the real motives behind the metric change
‘However, there is now consistency across the data sets that 2005 and 2010 likely topped 1998 as the warmest years in the instrumental record ‘ (you leave out the terms significant and unambiguous)
Well thats rather pedantic and its quite like something a sceptical blog would focus on.I am interested do you think that really means there is extra time before the lack of warming becomes siginificant?
[Response: If you think that short term trends – whether in HadCRUT4 or not – are significant either statistically or climatologically, then there isn’t much I can do. And your notion that somehow changing short term trends was the ‘real motive’ in updating the data sets, I really can’t help you. That is way out there in conspiracy theory land. – gavin]
When I hear people say they are really enjoying this late winter 80 degree weather, it seems analogous to somebody on death row who thinks things are looking up because the food just got a lot better all of a sudden.
I second the recommendation for Edwards A Vast Machine – see my review. That may be too technical for a general audience, though.
I think I was making it perfectly clear that the changes were not as statistically significant as you inferred when I commented on your article re
a)when you raised the issue of the new consensus between GIStemp and HadCrut4
b) when I questioned the significance of this
It undoubtedly has a political significance and the media will spin this
http://www.telegraph.co.uk/earth/earthnews/9153473/Met-Office-World-warmed-even-more-in-last-ten-years-than-previously-thought-when-Arctic-data-added.html
and even as you emphasise the issue of insignificance of short term analysis people do mind so much about the rankings and I think its unfair to suggest its just the sceptics
The link to ‘Jones et al, 2011’ being me back to RealClimate.
[Response: It should take you to the references, from where you can click on the DOI link to the original paper. We are using a version of kcite to produce exactly this functionality (you just find the doi, and the plugin creates the reference section and the link via citeref to the paper). – gavin]
I think I made it perfectly clear I was critical of your emphasis on the rankings while very clear the ‘new consensus’ is not statistically significant.(apologies if the sarcasm confused)
See comment on leaving out signifiance and unambiguous in ref to your enthusiasm over rankings
You yourself amplify the importance of this in the ‘new consensus’ comment
The new metric and new rankings are obviously of some political significance rather than scientific
http://www.telegraph.co.uk/earth/earthnews/9153473/Met-Office-World-warmed-even-more-in-last-ten-years-than-previously-thought-when-Arctic-data-added.html
I think it is obviously unfair to suggest the rankings only matter to sceptics given the work that went into this and F+R
NO. It is not. A way to demonstrate proper application of statistical understanding is to state as fact that the trend since 1975 has shown no sign of change.
Please vacate the high horse. If you were really interested in the truth this is what you would be saying, but you’re not.
I suggest criticism about overinflating the importance of single years should be directed at those who have made a big f***ing deal about it — maybe Anthony Watts, Christopher Monckton, the GWPF, etc.
The HadCRUT4 data set was constructed to improve the temperature estimate by including more data. That’s one of the things scientists do. I expect you to make the same lame accusation at the release of HadCRUT5 etc. F&R was to estimate of the impact on temperature of different known factors — that’s also one of the things scientists do.
It’s the mainstream climate scientists who have been assaulted, and the voting public who have been abused, by dishonest arguments about single years. That’s what you should be concerned with. Instead you choose to “blame the victim” when the scientists actually respond.
MMM
The Whitehouse climate bet was simple and was indeed set by james Annan in 2007 that between 2007 and 2011 there would be no new record (1998 was the warmest using HadCRUT3). Since in HadCRUT4 no new record was set over the same period the outcome of the bet would be the same. What is it you don’t understand?
Mind you, I don’t understand what you are on about in the rest of your comment.
Thanes at #8 said:
“When I hear people say they are really enjoying this late winter 80 degree weather, it seems analogous to somebody on death row who thinks things are looking up because the food just got a lot better all of a sudden.”
Very well put. If this pattern continues, it spells a VERY hot summer for much of the US.
Could this be its own tipping point in terms of public opinion on AGW here?
As C.S. Lewis put it: ‘Experience is a brutal teacher, but you learn. My God, do you learn.’
There is no denying CRU’s correction, not only by other big climate services. Optically speaking, 2010 blew all records of expanded sun disks by the spring in the Arctic, at that time it was strongly leaning to be #1. Summer 2010 montreal observations were off the charts as well. By summer of 2010 #1 was made official (as on my website, scroll down). 2011 was slightly cooler, 2012 has not beaten 2010 March observations, the season is still young, observations are hampered by exotic clouds and ice fog. 2011-12 was made quite complex by stratospheric ozone predilections with the usual ENSO and other influences.
@13 (Tamino)
The longer term trend (since 1975 or longer) has not changed signs to negative territory (as you were implying), and has stayed “non-negative” even if the recent 10-15 years or so is relatively flat at the highest level in the temperature record.
Being “interested in the truth” isn’t often a dominant force in the world of statistics (you should know that more than most, being well embedded in the field). You should also see clearly that I’m just working with what this RC has been putting forth (which is quite reasonable).
Yes, all the other folks you have mentioned have been making a big deal out of 1998 (and I said that)… It’s a nice attempt at simple deflection, but the scientists are the ones that shouldn’t be meddling with this overinflation. If the scientists are going to put forth arguments about 2010 and 2005 vs 1998 now, then they’re implicitly acknowledging that the others’ arguments using 1998 have validity. Throw-away teeny-tiny caveats inserted here and there aren’t going to help much.
Why not just say that 1998, 2010, 2005, etc. (there are others) are statistically indistinguishable from one another as the ‘warmest’… and just about every long term trend remains positive? The short-term variability has kept the recent values in a relative plateau (at the highest values), but one can only assume we’re an ENSO event away from a new record– perhaps one that can be reported with a legitimate statistical significance.
“The increase in source data in CRUTEM4, goes some way to remove this bias, but it will likely still remain (to some extent) in HadCRUT4 (because of the sea ice covered areas of the Arctic which are still not included).”
The difference panel in your first figure shows an impressive amount of extra gridboxes in CRUTEM4 compared to CRUTEM3. However, it is notable that now that a lot of gridboxes have been filled in the high latitudes a large number of the remaining data sparse regions are in the tropics – where one assumes the trends have been lower than in the Arctic sea ice areas.
I expect this is accounted for in the spatial uncertainty they have calculated – which was always quite large in HadCRUT3, but it’s worth bearing in mind that biases due to missing data likely act on the trend in both signs.
“It is worth pointing out that adjustments are of both signs – the corrections in the SST for bucket issues in the 1940s reduced trends, as do corrections for urban heat islands, while correction for time of observation bias in the US increased trends, as does adding more data from Arctic regions.”
The other difference I noted was a fair amount of blue in those areas of Russia that had data in both CRUTEM3 and CRUTEM4. Is that corrections for urban heat islands that you mention, or something else?
I don’t understand the obsession with “warmest year” on either side. What’s driving the mean the most on yearly scale is ENSO and for a year mean you always put half of it to one year and another half to another year which causes what is in signal processing known as aliasing errors. And for whole northern hemisphere it’s more about warm winters than about summer heat.
[Response: Quite right. But of course it quite understandable why there is an ‘obsession’ with the ‘warmest year’ idea. People (even scientists) tend to think simplistically about things when possible, and if it is warming up then records are going to get broken more frequently. So one expects a real ‘warmest year’ eventually. It has not happened yet within the uncertainty in the data. It is nevertheless significant (though completely unsurprising) that the 3 or 4 years that are in a dead heat for winning the race were all within the last fifteen years.–eric]
Salamano, “Why not just say that 1998, 2010, 2005, etc. (there are others) are statistically indistinguishable from one another as the ‘warmest’…”
Uh, I believe Gavin did that. As did Jim Hansen before him, and as did Tamino after him. Your obsession reminds me of the story of the novice Buddhist monk walking with his master when they came to a flooded road. A beautiful young woman was stranded, and the master offered to carry her across. Several miles later, the master remarked on the silence of his pupil. The novice said, “We are forbidden by our order from touching women, and yet you carried that beautiful, young woman across the river. Is that not a sin?”
The master was silent for a few more paces and then said, “I put that woman down miles ago. Why are you still carrying her?”
I am surprised that unremarked in the main post is the significant advance in the usability of the error model. The HadCRUT3 error model consisted of very difficult to apply statistical formalism and had to be recalculated for each and every application making it effectively unusable for any applications not needing products available off-the-shelf. HadCRUT4 continues to implement the type of model raised in your HadSST3 post but applies it globally. So, the 100 member ensemble solution effectively allows a consistent use of the error model for any application. Once a user can calculate their analysis it is simple to calculate additional realizations from the ensemble to gain their uncertainty consistent with any other analyst. So, it doesn’t matter if you are ranking years, calculating trends, looking regionally, globally etc. If you use the 100 member ensemble then your uncertainty estimates end up comparable to everybody else’s and the dataset originators best estimate of the underlying uncertainties which is appropriately documented in the paper.
Would that more products had their error models built from the ground-up and available as some sort of monte-carlo ensemble. This is by far and away the simplest possible way to construct and make usable error models and the easiest way to incorporate the understanding of the individual physical measurement characteristics (to the sadly not perfect extent known) in a formal manner.
A couple of other things. In response to the various comments about coverage, as a global community we are currently working very hard on creating a much more complete repository of global land surface air temperature data as part of the International Surface Temperature Initiative which started in 2010. We hope to release a first version of a databank in the summer. If folks want to see how this is looking thus far I’d suggest looking at this ftp area and in particular the stage2/maps directory. So far we have collected over 40 sources (not currently all up there – some are still being reformatted) ranging from massive data compilations to individual long records. I would estimate we will nudge 40K-45K stations in the first release all told. Many of these will fill gaps still present in CRUTEM4. We are now in the hard work of reconciling these disparate and substantially overlapping holdings.
With regards to the United States biases mentioned in the post I would note that our understanding of US records has been revised somewhat in light of a recent benchmarking of algorithm performance against analogs to the real-world raw data. That study is summarized (and a preprint of the JGR paper linked) at the surface temperature initiative blog here. The bottom line is that the raw data is definitely biased – showing too little warming. Perhaps more disheartening is that the operational dataset (which goes into CRUTEM4) may be underestimating the true rate of warming, in particular for monthly mean maximum temperatures.
Derek Siegler: “The Whitehouse climate bet was simple and was indeed set by james Annan in 2007 that between 2007 and 2011 there would be no new record (1998 was the warmest using HadCRUT3). Since in HadCRUT4 no new record was set over the same period the outcome of the bet would be the same. What is it you don’t understand?”
Apparently it is not so clear: http://julesandjames.blogspot.com/2012/03/hadcrut4-1998-and-all-that.html
-MMM
Here is a useful graph for folks interested in how CRUTEM4 stacked up against other temperature records.
1800-present: http://rankexploits.com/musings/wp-content/uploads/2012/03/Berkeley-GISTemp-NCDC-and-CRUTEM4-Comparison.png
1970-present: http://rankexploits.com/musings/wp-content/uploads/2012/03/Berkeley-GISTemp-NCDC-and-CRUTEM4-Comparison2.png
Eric in #19,
Not too sure we will get a standout year all that often. There may always be a group of two to four members of a statistical tie in the coming decades but the membership will shift with time with the nominally coolest member of the old group dropping out. 1998 was a standout year in the GISTEMP data but by 2001 is was part of a group again. Doesn’t look as though 1944 ever stood out on its own statistically in this representation: http://data.giss.nasa.gov/gistemp/graphs_v3/Fig.A2.gif
Spatial sampling will have to improve some more before error bars can typically be small enough to avoid a group tie as the normal state of the data.
Eric writes in a response on #19:
It is nevertheless significant (though completely unsurprising) that the 3 or 4 years that are in a dead heat for winning the race were all within the last fifteen years.–eric]
It’s also worth noting that 1998 got to the top on the back of the greatest el-nino ever observed and a solar maximum. 2010 tied it with a much smaller el-nino and during a solar minimum.
When one removes this noise, as done in F&R, 2010 is a very clear ‘winner’.
As Hansen has pointed out, the next average el-nino with average TSI will produce an unambiguously new high.
I’ll grant you that removing the noise in the minds of the public is a very hard thing. Perhaps, though, we can recognize such realities around here.
Salamano,
Corruption of the findings of science, no matter how subtly and thoroughly explained, will occur anyway, by those who have different interests. There are more than enough ways to do this in addition to the one you seem distraught about. Whichever way you look at it, data sets will show a certain ranking of hottest years on record, even if statistically ambiguous. Why not just keep that in mind? And instead wonder why, for example, even if the ordering is ambiguous, so many of those hottest years have occurred so recently?
It’s also false that, by making statements about this ordering, one implicitly acknowledges validity of arguments made in the past about 1998. An argumentation that was fallacious in the first place does not suddenly turn valid. Perhaps in rhetoric, not in logic.
Pete, thanks for helping me get the word out! Folks in the San Diego area who are interested in attending can reserve a spot on-line here: lordmonckton.eventbrite.com
And here’s hoping for a big turnout from UCSD/SIO!
Does Hadcrut cover the oceans?
@27 re Moncton: clicking the link got me the fact that “Americans Protecting Property Rights” is sponsoring the event. I hadn’t heard of them (though I could guess) so I googled and got … almost zero. They seem to be very, very new – no wikipedia entry, no sourcewatch entry. They themselves don’t even know who they are – go to http://americansprotectingpropertyrights.com/ (yeah, I wouldn’t usually recommend it) and click on ‘About Us’ and you will see what I mean.
Jim Larsen @28 — My understanding is that CRU does the land temperatures and Hadley Centre does the SSTs. The two are blended to make the HadCRUT global temperature products.
A layman question about the temperature data. Are the monitoring stations evenly spaced, if not then how are the localization effects taken care of ? Let’s say climate is different in two hemispheres and it swings periodically, then wouldn’t we get distorted results since landmass is concentrated in one hemisphere?
#32
That’s why area-weighting is used.
Here’s a very simple explanation.
Divide the world up into grid-squares of approximately equal area. Within each grid-square, average together all the station anomaly data to produce a single average anomaly result for that grid-square.
For a grid-square with 50 stations, your 50 stations will be merged/averaged into one anomaly number.
For a grid-square in a less-densely-sampled region (say, with 5 stations), then you just average 5 stations together to get the average result for that grid-square.
Then you just average together all the grid-square results to get your final global result. A grid-square with 5 stations will count just as much in the average as a grid-square with 50 stations.
This way, areas with dense station coverage won’t be overweighted relative to areas with sparse station coverage.
To keep things really simple, make your grid-squares big enough so that no grid-squares are empty (i.e. have no stations). Then you don’t have to deal with interpolation to “fill” the empty grid squares.
Code up something like this, run the raw GHCN data through it, and you will get results amazingly close to what the “pros” get — even if you take all kinds of simple-minded “shortcuts” in the processing. Even the crudest, most simple-minded “area weighted” averaging procedure will give you darned good global-average results.
Final note: The simple average (i.e. no area-weighting) will show *too much* warming. That’s because the more-densely-sampled NH has been warming more than the less-densely-sampled SH. Play around with the data enough, experiment with different approaches (area weighting vs. no area weighting, grid-square sizes, etc.), and you will see that the “fine-tuning” (vs. simple ham-handed approaches) done by NASA/NOAA/CRU climate-scientists generally *reduces* the amount of indicated warming. It’s almost as if scientists have been trying to *minimize* the warming in their results.
Do you have any doubts about accuracy of strong positive anomaly only within borders of Soviet Union?
http://www.vukcevic.talktalk.net/69-71.htm
How do they decide which station data goes in? What is the methodology?
Jason, your question asked at 1:02 pm had already been answered by Caerbannog at 9:23 am.
> vukcevic … anomaly only with borders of Soviet Union?
Vukcevic shows a picture for 1969-1971, when there _was_ a Soviet Union.
Start here instead: http://data.giss.nasa.gov/gistemp/maps/
Try this one: http://data.giss.nasa.gov/work/gistemp/NMAPS/tmp_GHCN_GISS_HR2SST_1200km_Anom02_1960_2012_1951_1980/GHCN_GISS_HR2SST_1200km_Anom02_1960_2012_1951_1980.gif
MalcolmT @ 30: their website address was registered 2012-01-15
vukcevic – This anti-variance between global average and North Asian temperatures is really very common.
Just over the past few years see:
http://data.giss.nasa.gov/cgi-bin/gistemp/do_nmap.py?year_last=2012&month_last=2&sat=4&sst=1&type=trends&mean_gen=0112&year1=2006&year2=2008&base1=1951&base2=1980&radius=250&pol=reg
and
http://data.giss.nasa.gov/cgi-bin/gistemp/do_nmap.py?year_last=2012&month_last=2&sat=4&sst=1&type=trends&mean_gen=0112&year1=2008&year2=2010&base1=1951&base2=1980&radius=250&pol=reg
Looks like a few folks who might be skeptical of the robustness of the global surface temperature record have popped by…
Guess it’s as good a time any to trot out (once again) my amateur “climate-scientist wannabe” global-average temperature results.
This time, I selected a total of 45 rural stations to process.
I chose them by dividing up the Earth into 30degx30deg-equivalent (at the Equator) grid-cells and then choosing the single rural station with the longest temperature record in each grid cell.
Since not every station reported data for every year, the actual number of the selected stations that reported data in any given year ranged from 10-12 (prior to 1900) up to a maximum of 44 (in the early 1960’s). The average number of selected stations reporting data in any given year over the entire 1880-2010 time period was 31.
Results were computed simply by averaging together all the station anomalies relative to the 1951-1980 baseline (Selecting a single station per grid cell made “area-weighting” irrelevant).
Got results that were surprisingly close to the official NASA/GISS land-temperature index.
A fully annotated plot of my results can be found by taking a gander at my twitter profile — https://twitter.com/#!/caerbannog666
So folks, you really can take a tiny fraction of the GHCN stations (chosen essentially at random), run them through a very simple anomaly-averaging procedure, and still get results very similar to the results that the “pros” publish.
The only place were my results deviated significantly from the NASA/GISS results was pre-1890, a time period where fewer than a dozen of my selected stations had any data to report.
And before I forget — yes, the results were generated from *raw* (i.e. not homogenized or manipulated in any way) GHCN temperature data.
I strongly encourage those of you out there who have doubts about the robustness of the global temperature record to take a good long look at my results and think about the implications.
Think about the fact that I was able to get pretty decent global temperature results from a very tiny fraction of the GHCN surface temperature stations the next time you hear Anthony Watts and his cohorts “diss” the surface temperature record.
Ray Ladbury@21
You are a fount of wisdom; the Buddhists have it. We could use a lot more reflective wisdom and a lot less noisy nonsense.
How incurious “skeptics” are.
On the article, I am a bit puzzled as to the necessity for the third bullet point. I’m sure GWPF is annoying, but wouldn’t silence have been more cutting?
Forgot to say, thanks very much for an explanation straightforward enough that someone like me could follow it. (Hence my remark about incuriosity; those who don’t bother to read this stuff, except for the purpose of finding something to quibble about or attack, demonstrate closed minds.)
“Hence my remark about incuriosity; those who don’t bother to read this stuff, except for the purpose of finding something to quibble about or attack, demonstrate closed minds.”
And that is another way to tell the players without using a scorecard.
In terms of measurements to asses the AGW thesis, basic temperature readings are obviously important. But what of other indicators – the apparently missing tropospheric hotspot, disproportionate polar warming (Arctic: Yes, Antarctic: No). Given that average surface air and shallow ocean temperatures are going sideways, and deep ocean temperatures not well enough known to asses if heat is “hiding” there, what efforts are there to seek some other, completely separate measurements to either support or falsify CO2 GW?
#33 “the [] NH has been warming more than the [] SH.”
But I thought this was strongly contested ?
(And isn’t the more industrialized NH assumed to be emitting more aerosol coolants?)
Convenient ‘truth’.
BTW, data are plural.
“Because, why else would scientists agree with each other? ;-)”
Well it’s a good question. One obvious answer is that they work for the same / parallel organization in society.
[Response: Umm… Try because they are similarly convinced by the evidence? Pretty sure that’s why you get mostly the same stuff in textbooks around the world. – gavin]
#8
PKthinks says:
I am interested do you think that really means there is extra time before the lack of warming becomes significant?
How much time *would* actually be significant ?
Gavin, your prediction comes true;
http://reallysciency.blogspot.co.uk/2012/03/real-science-makes-rael-climate-dreams.html
And not a computer model in sight.
#33 “the [] NH has been warming more than the [] SH.”
But I thought this was strongly contested ?
(And isn’t the more industrialized NH assumed to be emitting more aerosol coolants?)
Comment by Double Latte — 23 Mar 2012 @ 1:48 AM
#############
You can verify that the NH is warming faster than the SH by downloading the GHCN temperature data tarball (Google is your friend here) and crunching it yourself.