Guest post by Jared Rennie, Cooperative Institute for Climate and Satellites, North Carolina on behalf of the databank working group of the International Surface Temperature Initiative
In the 21st Century, when multi-billion dollar decisions are being made to mitigate and adapt to climate change, society rightly expects openness and transparency in climate science to enable a greater understanding of how climate has changed and how it will continue to change. Arguably the very foundation of our understanding is the observational record. Today a new set of fundamental holdings of land surface air temperature records stretching back deep into the 19th Century has been released as a result of several years of effort by a multinational group of scientists.
The International Surface Temperature Initiative (ISTI) was launched by an international and multi-disciplinary group of scientists in 2010 to improve understanding of the Earth’s climate from the global to local scale. The Databank Working Group, under the leadership of NOAA’s National Climatic Data Center (NCDC), has produced an innovative data holding that largely leverages off existing data sources, but also incorporates many previously unavailable sources of surface air temperature. This data holding provides users a way to better track the origin of the data from its collection through its integration. By providing the data in various stages that lead to the integrated product, by including data origin tracking flags with information on each observation, and by providing the software used to process all observations, the processes involved in creating the observed fundamental climate record are completely open and transparent to the extent humanly possible.
Databank Architecture
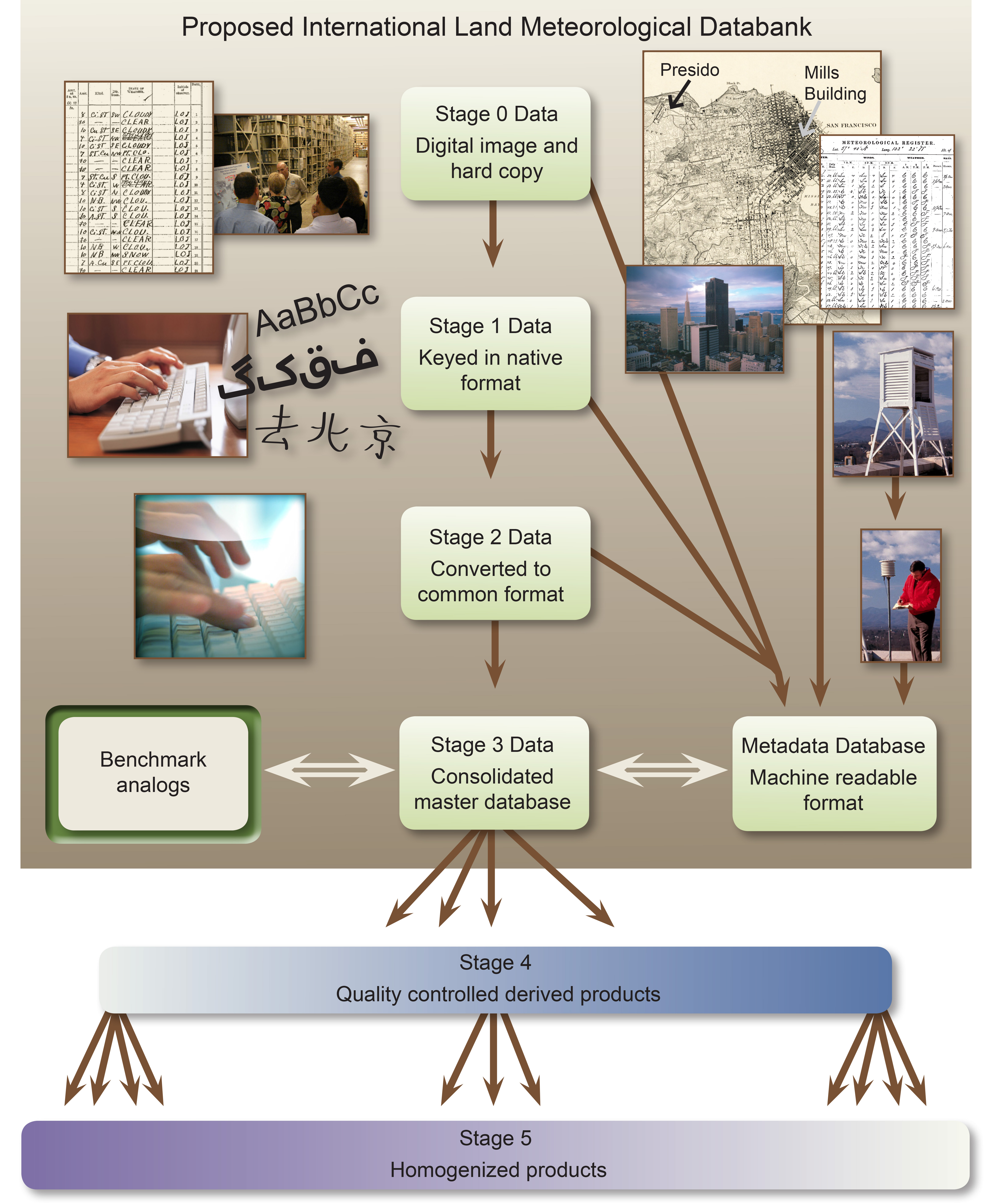
The databank includes six data Stages, starting from the original observation to the final quality controlled and bias corrected product (Figure 1). The databank begins at Stage Zero holdings, which contain scanned images of digital observations in their original form. These images are hosted on the databank server when third party hosting is not possible. Stage One contains digitized data, in its native format, provided by the contributor. No effort is required on their part to convert the data into any other format. This reduces the possibility that errors could occur during translation. We collated over 50 sources ranging from single station records to holdings of several tens of thousands of stations.
Once data are submitted as Stage One, all data are converted into a common Stage Two format. In addition, data provenance flags are added to every observation to provide a history of that particular observation. Stage Two files are maintained in ASCII format, and the code to convert all the sources is provided. After collection and conversion to a common format, the data are then merged into a single, comprehensive Stage Three dataset. The algorithm that performs the merging is described below. Development of the merged dataset is followed by quality control and homogeneity adjustments (Stage Four and Five, respectively). These last two stages are not the responsibility of Databank Working Group, see the discussion of broader context below.
Merge Algorithm Description
The following is an overview of the process in which individual Stage Two sources are combined to form a comprehensive Stage Three dataset. A more detailed description can be found in a manuscript accepted and published by Geoscience Data Journal (Rennie et al., 2014).
The algorithm attempts to mimic the decisions an expert analyst would make manually. Given the fractured nature of historical data stewardship many sources will inevitably contain records for the same station and it is necessary to create a process for identifying and removing duplicate stations, merging some sources to produce a longer station record, and in other cases determining when a station should be brought in as a new distinct record.
The merge process is accomplished in an iterative fashion, starting from the highest priority data source (target) and running progressively through the other sources (candidates). A source hierarchy has been established which prioritizes datasets that have better data provenance, extensive metadata, and long, consistent periods of record. In addition it prioritizes holdings derived from daily data to allow consistency between daily holdings and monthly holdings. Every candidate station read in is compared to all target stations, and one of three possible decisions is made. First, when a station match is found, the candidate station is merged with the target station. Second, if the candidate station is determined to be unique it is added to the target dataset as a new station. Third, the available information is insufficient, conflicting, or ambiguous, and the candidate station is withheld.
Stations are first compared through their metadata to identify matching stations. Four tests are applied: geographic distance, height distance, station name similarity, and when the data record began. Non-missing metrics are then combined to create a metadata metric and it is determined whether to move on to data comparisons, or to withhold the candidate station. If a data comparison is deemed necessary, overlapping data between the target and candidate station is tested for goodness-of-fit using the Index of Agreement (IA). At least five years of overlap are required for a comparison to be made. A lookup table is used to provide two data metrics, the probability of station match (H1) and the probability of station uniqueness (H2). These are then combined with the metadata metric to create posterior metrics of station match and uniqueness. These are used to determine if the station is merged, added as unique, or withheld.
Stage Three Dataset Description
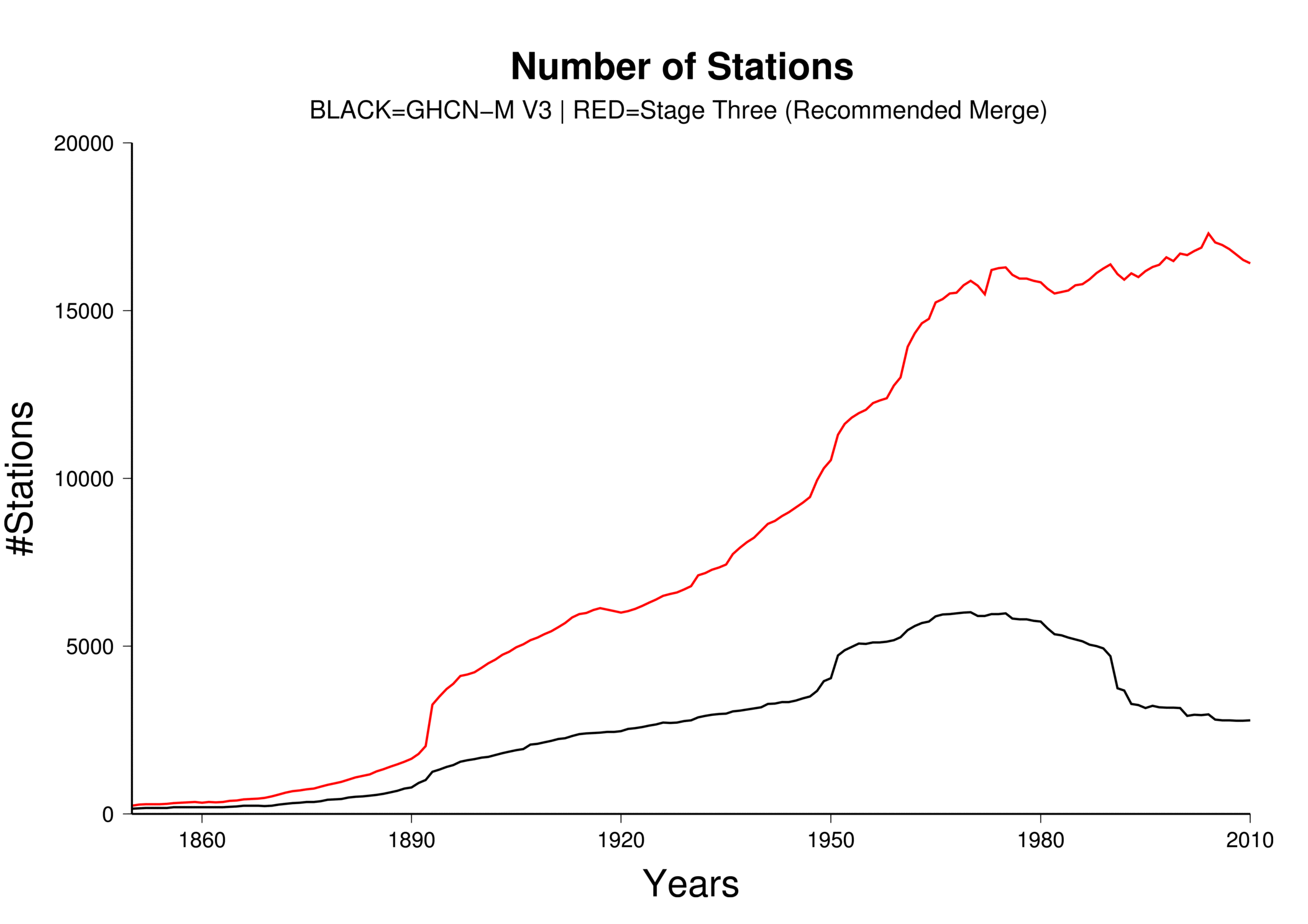
The integrated data holding recommended and endorsed by ISTI contains over 32,000 global stations (Figure 2), over four times as many stations as GHCN-M version 3. Although station coverage varies spatially and temporally, there are adequate stations with decadal and century periods of record at local, regional, and global scales. Since 1850, there consistently are more stations in the recommended merge than GHCN-M (Figure 3). In GHCN-M version 3, there was a significant drop in stations in 1990 reflecting the dependency on the decadal World Weather Records collection as a source, which is ameliorated by many of the new sources which can be updated much more rapidly and will enable better real-time monitoring.
Many thresholds are used in the merge and can be set by the user before running the merge program. Changing these thresholds can significantly alter the overall result of the program. Changes will also occur when the source priority hierarchy is altered. In order to characterize the uncertainty associated with the merge parameters, seven different variants of the Stage Three product were developed alongside the recommended merge. This uncertainty reflects the importance of data rescue. While a major effort has been undertaken through this initiative, more can be done to include areas that are lacking on both spatial and temporal scales, or lacking maximum and minimum temperature data.
Data Access
Version 1.0.0 of the Global Land Surface Databank has been released and data are provided from a primary ftp site hosted by the Global Observing Systems Information Center (GOSIC) and World Data Center A at NOAA NCDC. The Stage Three dataset has multiple formats, including a format approved by ISTI, a format similar to GHCN-M, and netCDF files adhering to the Climate and Forecast (CF) convention. The data holding is version controlled and will be updated frequently in response to newly discovered data sources and user comments.
All processing code is provided, for openness and transparency. Users are encouraged to experiment with the techniques used in these algorithms. The programs are designed to be modular, so that individuals have the option to develop and implement other methods that may be more robust than described here. We will remain open to releases of new versions should such techniques be constructed and verified.
ISTI’s online directory provides further details on the merging process and other aspects associated with the full development of the databank as well as all of the data and processing code.
We are always looking to increase the completeness and provenance of the holdings. Data submissions are always welcome and strongly encouraged. If you have a lead on a new data source, please contact data.submission@surfacetemperatures.org with any information which may be useful.
The broader context
It is important to stress that the databank is a release of fundamental data holdings – holdings which contain myriad non-climatic artefacts arising from instrument changes, siting changes, time of observation changes etc. To gain maximum value from these improved holdings it is imperative that as a global community we now analyze them in multiple distinct ways to ascertain better estimates of the true evolution of surface temperatures locally, regionally, and globally. Interested analysts are strongly encouraged to develop innovative approaches to the problem.
To help ascertain what works and what doesn’t the benchmarking working group are developing and will soon release a set of analogs to the databank. These will share the space and time sampling of the holdings but contain a set of known (to the originators) data issues that require removing. When analysts apply their methods to the analogs we can infer something meaningful about their methods. Further details are available in a discussion paper under peer review [Willett et al., submitted].
More Information
www.surfacetemperatures.org
ftp://ftp.ncdc.noaa.gov/pub/data/globaldatabank
References
Rennie, J.J. and coauthors, 2014, The International Surface Temperature Initiative Global Land Surface Databank: Monthly Temperature Data Version 1 Release Description and Methods. Accepted, Geoscience Data Journal.
Willett, K. M. et al., submitted, Concepts for benchmarking of homogenisation algorithm performance on the global scale. http://www.geosci-instrum-method-data-syst-discuss.net/4/235/2014/gid-4-235-2014.html
Nice work Jared! It will be good to have a single repository of all the world’s temperature records for folks to work with.
Thank you Jared Rennie for taking the time to write an informative post.
Will the results of this project only make a more robust record of surface air temperatures with maximum transparency, which is in itself a good thing? Do you and your collaborators expect anything that may be different enough from previous work on this subject that could lead to new conclusions about the temperature record?
Thank you, multinational group of scientists. Thank you RC for a new article, finally. It has been a long time.
Zeke, thanks very much! We have worked really hard on this, and will continue to do so in the future.
Joesph, that is what we are hoping for. The databank is designed so the community can go use the data to discover features about the temperature record that may have not been known before. We are really excited to see what comes down the road!
#2 Joseph O’Sullivan
Thanks for your interest. We expect better informed estimates of surface temperature changes from global to regional and from interannual to centennial timescale. The global mean is important but people live not in the global mean but in their home town / city / village / region. Providing better, more local, estimates will aid society, industry, planners and others to make more informed decisions. Having a better handle on the plausible range of the true evolution of surface temperatures across multiple space and timescales will provide undoubted benefits. This is why we need new analyses as a crucial next step. We need to explore potential solutions to addressing the undoubted non-climatic issues in these basic data holdings to get better estimates of the true nature of the evolution of surface temperatures.
As to what may be different. Its highly implausible that it will change the ‘direction of travel’ … the global mean will almost certainly still be going up (confidence in this would be about as high as that the sun will rise in the morning). Even if we had never invented the thermometer the evidence from multiple other facets would mean we would still conclude this (see e.g. FAQ 2.1 in IPCC AR5 WG1). But some important details may change. The changes will be larger regionally and locally in the global mean, particularly where before we had no or very little direct observational data and now we actually have enough data to perform meaningful analyses.
Peter
#4 Jared Rennie
I agree, it is exciting to see what this new project will lead to!
#5 Peter Thorne
The area that I am particularly interested in is how AGW will effect the ecosystems around the world, which if I understand correctly will require better knowledge of local temperature changes. It will be great to see further research based on this project.
This is great stuff, thanks Jared and Peter for answering my questions!
Jared Rennie wrote:
All processing code is provided, for openness and transparency. Users are encouraged to experiment with the techniques used in these algorithms. The programs are designed to be modular, so that individuals have the option to develop and implement other methods that may be more robust than described here. We will remain open to releases of new versions should such techniques be constructed and verified.
Such openness, although requiring extra effort, is a good tool to counter a large fraction of skeptics. Hidden data and hidden models invite suspicion. This does just the opposite. Congratulations and thanks.
Bob
OT, but mighty topical, The Heartland Las Vegas Conference has to be seen to be disbelieved !
> Hidden data and hidden models invite suspicion
Yep. The petroleum industry uses them, to know where and when petroleum started to form; continental drift has moved them, so they rely on data and models.
I recall decades ago reading about injury to whales along the US East Coast from illegal oil prospecting (air cannon and explosion for seismic surveying damaging hearing) — that was being done in advance of the industry’s acquiring the North Carolina legislature for leases and the federal government for permission, which it appears they have done.
They’re not going to make those data and models public, suspicion or not. Yet illegally obtained and hidden data and models, well, what do you think?
Question — this is about land surface temperature records, I understand.
Do you connect these with data on ocean temperature/circulation/depth?
I followed the last link in the main post for the FTP site.
The top there has this “Welcome Message” posted:
****** WARNING ** WARNING ** WARNING ** WARNING ** WARNING ******
** This is a United States Department of Commerce computer **
** system, which may be accessed and used only for **
** official Government business by authorized personnel. **
** Unauthorized access or use of this computer system may **
** subject violators to criminal, civil, and/or administrative **
** action. All information on this computer system may be **
** intercepted, recorded, read, copied, and disclosed by and **
** to authorized personnel for official purposes, including **
** criminal investigations. Access or use of this computer **
** system by any person, whether authorized or unauthorized, **
** constitutes consent to these terms. **
****** WARNING ** WARNING ** WARNING ** WARNING ** WARNING ******
So, this OK?
Hank,
With regards to your first question, I will say that one of the long term plans for ISTI is to incorporate other forms of temperature, including sea surface temperature.
In response to your second question, that is a generic warning that is placed on the NCDC FTP site. All of the data that are on this FTP are in the public domain and available for use by anyone. NCDC is aware of our efforts and knows about our openness and transparency.
In fact, all the source code we provide has this disclaimer:
! **COPYRIGHT**
! THIS SOFTWARE AND ITS DOCUMENTATION ARE CONSIDERED TO BE IN THE PUBLIC
! DOMAIN AND THUS ARE AVAILABLE FOR UNRESTRICTED PUBLIC USE. THEY ARE
! FURNISHED “AS IS.” THE AUTHORS, THE UNITED STATES GOVERNMENT, ITS
! INSTRUMENTALITIES, OFFICERS, EMPLOYEES, AND AGENTS MAKE NO WARRANTY,
! EXPRESS OR IMPLIED, AS TO THE USEFULNESS OF THE SOFTWARE AND
! DOCUMENTATION FOR ANY PURPOSE. THEY ASSUME NO RESPONSIBILITY (1) FOR
! THE USE OF THE SOFTWARE AND DOCUMENTATION; OR (2) TO PROVIDE TECHNICAL
! SUPPORT TO USERS.
I hope this helps
Great achievement, very good.
It seems that the priority in this project has been on quantity, traceability and availability of data and also flexibility in the analysis tool. There are still uncertainty about the long term quality and drift of each individual temperature measurement stations. However, a few hundred (say 500 with a daily reading) carefully selected temperature measurement stations will provide an average value with sufficient low uncertainty to see trends over decades. A plain simple average will be a well defined measurand for the selected stations. In this way no algorithms will add uncertainty or remove traceability for the results.
Why not invest in manual quality assurance of the siting, equipment, uncertainty and recorded temperatures for a few hundred high quality temperature measurement stations?
The European Union Regulation on Monitoring and Reporting on greenhouse gas emission put forward quite stringent requirements on each of the many many thousand measurement stations for measurement of CO2 emissions:
http://eur-lex.europa.eu/legal-content/EN/TXT/HTML/?uri=CELEX:32012R0601&from=EN
“Article 6 Consistency, comparability and transparency
1. Monitoring and reporting shall be consistent and comparable over time. To that end, operators and aircraft operators shall use the same monitoring methodologies and data sets subject to changes and derogations approved by the competent authority.
2. Operators and aircraft operators shall obtain, record, compile, analyse and document monitoring data, including assumptions, references, activity data, emission factors, oxidation factors and conversion factors, in a transparent manner that enables the reproduction of the determination of emissions by the verifier and the competent authority.
Article 7 Accuracy
Operators and aircraft operators shall ensure that emission determination is neither systematically nor knowingly inaccurate.
They shall identify and reduce any source of inaccuracies as far as possible.
They shall exercise due diligence to ensure that the calculation and measurement of emissions exhibit the highest achievable accuracy.
Article 8 Integrity of methodology
The operator or aircraft operator shall enable reasonable assurance of the integrity of emission data to be reported. They shall determine emissions using the appropriate monitoring methodologies set out in this Regulation.
Reported emission data and related disclosures shall be free from material misstatement, avoid bias in the selection and presentation of information, and provide a credible and balanced account of an installation’s or aircraft operator’s emissions.
In selecting a monitoring methodology, the improvements from greater accuracy shall be balanced against the additional costs. Monitoring and reporting of emissions shall aim for the highest achievable accuracy, unless this is technically not feasible or incurs unreasonable costs.”
Why not select a few hundred high quality temperature measurement stations let them be subject to similar requirements to evaluation, verification, traceability and documentation, and finally use these validated measurement stations to create a global average temperature record?
I am exited to see the following approach to verify the various methods used to combine the individual temperature data series into some kind of average or even “anomaly”:
“To help ascertain what works and what doesn’t the benchmarking working group are developing and will soon release a set of analogs to the databank. These will share the space and time sampling of the holdings but contain a set of known (to the originators) data issues that require removing. When analysts apply their methods to the analogs we can infer something meaningful about their methods.”
As far as I know there are only two methods available to ensure that a measurement (like global average temperature) is accurate and repeatable within stated levels of uncertainty:
1. Make sure that all individual measurements, which are combined to form the measurand, are calibrated and traceable to international standards for weight and measures (temperature). Verify by an independent calculation control that the individual measurements (each temperature measurement) are combined in a mathematically correct way. And, verify by an independent calculation control that the algorithms performed to combine the individual measurements into the measurand are performed correctly in accordance with an internationally accepted standard method for that measurement.
2 Calibrate the measurement method towards a reference method. The reference will then have to be a well defined measurand with a well known uncertainty. If the reference method is performed by combination of a synthetic data series, the calculations in the reference method will have to be verified by independent calculation control. It will also have to be verified that the algorithms performed in the reference method are correctly performed in accordance with the internationally accepted standard method for that measurement.
My point is, if the algorithms performed to combine the individual measurements are anything more than a simple mathematically combination you will need an internationally accepted standard for the combination of these into a measurement result. As no such standard currently exists, how will you propose to go about to verify that the various methods for homogenization, calculation of anomalies, construction of temperature fields, calculation of average temperature etc. are accurate and repeatable over time within some level of stated uncertainty?
#14–“… you will need an internationally accepted standard for the combination of these into a measurement result.”
(See more at: https://www.realclimate.org/index.php/archives/2014/07/release-of-the-international-surface-temperature-initiatives-istis-global-land-surface-databank-an-expanded-set-of-fundamental-surface-temperature-records/comment-page-1/#comment-573072)
Why? All sorts of complicated calculations are developed and used in scientific literature all the time, without the need for “international agreement.” They are vetted by normal scientific process–peer review, replication, critique and so on. Maybe I’m missing something here, but it appears that your proposal would be an extreme (and extremely cumbersome) departure from normal practice.
Having reviewed the paper I realize that you are in the planning stage of creating a reference towards which temperature data products can be benchmarked. I would like to make a few comments to some quoted parts of your plan:
“For the benchmarking process, Global Climate Models (GCMs) can provide gridded values of l (and possibly v) for monthly mean temperature. GCMs simulate the global climate using mathematical equations representing the basic laws of physics. GCMs can therefore represent the short and longer-term behaviour of the climate system re- sulting from solar variations, volcanic eruptions and anthropogenic changes (external forcings). They can also represent natural large-scale climate modes (e.g. El Niño– Southern Oscillation – ENSO) and associated teleconnections (internal variability).»
Global Climate Models have no merits at all in performing these things within reasonable level of uncertainties.
“By necessity, homogenisation algorithms have to make an assumption that a given station is at least locally representative at some point in its record.” …..”Conceptually, for any analog-station x as denoted by Eq. (1) a d term can be added to represent an inhomogeneity at time t and location l to give an observed value x′ which differs from the true value (x): x′ =ct,s +lt,s +vt,s +mt,s +dt,s. (2)”
“These d elements should be physically plausible representations of known causes inhomogeneity (e.g. station moves, instrument malfunctions or changes, screen/shield changes, changes to observing practice over time) as summarised in Table 1. « … “A range of frequencies and magnitudes should be explored. Ideally, they should take into account the effect on temperature from the change in climate covariates (e.g. rainfall, humidity, radiation, windspeed and direction) as accurately as possible at present, accepting that in the current state of knowledge this will in many respects be an assumption based on expert judgement.»
Can you please explain how you intend to produce an impeccable reference for algorithms by using Global Climate Models and expert judgement?
“Worlds should incorporate a mix of inhomogeneity types discussed above and the set of worlds should be broad, covering a realistic range of possibilities so as not to unduly penalise or support any one type of algorithm or too narrowly confine us to one a priori hypothesis as to real-world error structures.»
Can you please explain how Global Climate Model and expert judgement will not confine you to several a priory hypothesis?
“Any data-product creators utilising the ISTI databank and undertaking homogenisation will be encouraged to take part in the benchmarking as a means of improving the uncertainty estimation (specifically homogenisation uncertainty) of their product. This will involve running their homogenisation algorithms on the blind analog-error-worlds to create adjusted analog-error-worlds, just as they have done for the real ISTI databank stations.» … “There are two components of assessment: how well are individual change points located and their inhomogeneity characterised and how similar is the adjusted analog- error-world to its corresponding analog-clean-world?» … “For Level 1 assessment of large scale features (e.g. c, l and v in Eq. 1), a perfect algorithm would return the analog-clean-world features across a range of space and time scales. Algorithms should, ideally, at least make the analog-error-worlds more similar to their analog-clean-worlds.”
If I understand this correctly you expect the temperature data-product creators to replicate the assumptions you have made by using Global Climate Models and expert judgement and remove the artifacts which are implemented in the analogue error world. And if they use other models and other expert judgements which do not fully remove these artifacts their model will be regard to be uncertain. How do you know that your model and your expert judgement will produce reasonable artifacts? What about uncertainty in reference you have created?
I think you are planning a fundamental flaw in trying to make artifacts by models and expert judgement that you will expect other models and expert judgement to replicate. Can you please explain how your model and your expert judgement can be regarded as an acceptable reference?
DF:
Your pontifications on traceability are not news. The World Meteorological Organization (WMO) has guidelines and standards for maintaining the calibration accuracy of instruments used in meteorological and climatological monitoring networks. Most, if not all, major national agencies will follow those guidelines. The WMO, via various national members, also organizes many field tests to understand the behaviour of various instrumentation methodologies.
As for transforming a series of local temperature measurements into a global average: this is a question of statistical sampling. Although there is no One True Standard, the scientific literature has many papers on the subject and the various issues that present (coverage, discontinuities, etc.). A good recent paper is Cowtan and Way.
There are several major, well-known data sets that do such global trend analysis, and they all exhibit very similar behaviour. Try going to Wood for Trees to look at them. One standard methodology for assessing uncertainty in measurement is to try a variety of measurement methods and see how much they differ by. The similarity of the various global temperature sets puts some pretty tight bounds on how much uncertainty there is in the results.
In the paper you state:
“The crucial next step is to maximise the value of the collated data through a robust international framework of benchmarking and assessment for product intercompari- son and uncertainty estimation.”
There exists an international standard which is highly relevant when you intend to provide testing, benchmarking, the way you describe:
ISO/IEC 17025 General requirements for the competence of testing and calibration laboratories is the main ISO standard used by testing and calibration laboratories» … “And it applies directly to those organizations that produce testing and calibration results.» …”Laboratories use ISO/IEC 17025 to implement a quality system aimed at improving their ability to consistently produce valid results.[2] It is also the basis for accreditation from an accreditation body. Since the standard is about competence, accreditation is simply formal recognition of a demonstration of that competence.»
You should observe closely this international standard if you aim at receive a recognition of your ability to perform the tests, benchmark, you are intending to provide.
DF,
regarding your first post we have also been calling for almost a decade for a global surface reference network. But this will only help us moving forwards – we don’t have a Back to the Future Delorean handy to reverse instigate such a capability. This would build upon the principals in the US Climate Reference Network (http://www.ncdc.noaa.gov/crn/ – see http://dx.doi.org/10.1175/BAMS-D-12-00170.1 (OA)), and the GCOS Reference Upper Air Network (http://www.gruan.org). Given the significant costs involved in setting up and maintaining such a network its not a case of snapping your fingers and it happening. There are a number of people committed to trying to make this happen.
Regarding your second post we are following exactly metrological best practice for the historical measurements where we have no traceability. Metrologists would term this ‘software testing’ and it is covered with the GUM. We have, on the steering committee, two members of the Consultative Committee on Thermometry including the head on the newly constituted group on environmental thermometry, on which I also sit as a ‘stakeholder’.
So, yes we are to some extent a hostage to historical measurements and economic realities but we are doing our best within these constraints and we are working with metrology and statistics communities to do the very best that is possible.
Apologies for the delay – we were at a meeting with SAMSI and IMAGe (two statistics and applied maths groups) trying to entrain additional groups. A number of the presentations are available in delayed mode streaming. If interested these are linked from http://surfacetemperatures.blogspot.no/2014/07/talks-from-samsi-image-workshop-on.html.
# 19 Peter Thorne
Thank you for your reply. I understand that it will be impossible to perform quality assurance of all historical temperature measurement stations. Simply because we lack the information required to do so. And as you point out, we cannot travel in time. :) I also recognize that modern design and operation will provide very reliable temperature measurements. But it is a long time to wait until modern design has created a sufficient record.
However, I have the basic assumption that it has been possible to measure temperature with low uncertainty (say 0,5 K @ 95% confidence level) for quite a while. I also have the basic assumption that a metrological network should be able to identify a few hundred measurement stations that have produced accurate air temperature measurements in a basically unchanged physical local environment for let us say hundred years. If we can’t point out reliable measurement records we are left with only models and algorithms. Is it really the case that we are not able to identify a few hundred reliable measurement stations which has produced reliable records for hundred years? Records that should not be adjusted by models and algorithms?
#15 Kevin
You cannot quantify the uncertainty and systematic errors of a complicated calculation without performing a calibration.
See the following standards for definition of terms:
International vocabulary of metrology .
http://www.bipm.org/utils/common/documents/jcgm/JCGM_200_2008.pdf
or the guide to the expression of uncertainty in measurement
http://www.bipm.org/utils/common/documents/jcgm/JCGM_100_2008_E.pdf
Peer review, replication, critique are not relevant terms in accordance with these standards.
To be strict, benchmark does not seem to be a relevant term in accordance with International vocabulary of metrology.
However, in normal use of the word, the term benchmark can have several meanings:
1 Relative comparison of performance of similar products. 2 Evaluate a product by comparison with a standard.
In the first case the standard is not important at all, it is not needed, the benchmark is a relative comparison. The relative comparison can tell you something about one measurement compares to other measurements. But, you cannot quantify uncertainty or systematic errors from a relative comparison.
In the second case the standard is extremely important. The standard must have the same definition of the measurand and the same unit as the product you calibrate, the uncertainty of the standard should be lower than the uncertainty of the product subject for test and the test case must be relevant.
People tend to have strong belief in their own products, the moment a product owner is presented with a discrepancy between his product and a standard he will start to put the uncertainty of the standard and the relevance of the standard or test case in doubt. Imagine the current discrepancy between predicted temperature by global climate models and average temperature. If I had generated a test record looking like the late temperature record, I imagine that the product owner for the global climate model would blame my synthetic temperature record for not being realistic. While a product owner can blame a synthetic world for not being realistic, he cannot blame nature for not being realistic. If you generate an analogue world and analog error worlds you will risk that the product owners get a reason to blame the synthetic worlds for not being realistic. Hence the analog world should be real measurements.
Also you cannot compare apples and oranges, the various temperature products do not have the same definition and unit for their measurands. They do not provide the same output. Hence you will need to agree on definition and unit for the measurand (average temperature). You will also have to agree on how to arrive at the measurand from the individual temperature measurements. If not, product owners will question the standard and how the standard arrive at the measurand from the individual measurements.
The model and algorithms used to arrive at the measurand should be as simple as possible. Complexity will add uncertainty and weaken the traceability. This is why I tend to think that a simple average will be valuable because it will be traceable to the individual measurements, it will be verifiable and it will not involve complex algorithms and models that will have to be agreed upon. Any complex algorithm or model involved to arrive at the measurand from the individual measurements will add uncertainty and reduce the traceability.
# 19 Peter Thorne
No need to apologize for the delay. I also understand that normal working hours brings more than these comments. I´m glad for your reply. Thanks for the links, I will certainly have a look. Good to hear that you are working with metrology and statistics communities.
Regarding the following quote from your reply:
“Regarding your second post we are following exactly metrological best practice for the historical measurements where we have no traceability. Metrologists would term this ‘software testing’ and it is covered with the GUM.”
It is not clear exactly which best practice you are referring to. Can you please provide a link to the best practice(s) you use for historical measurement where you have no traceability?
Further, I cannot find the term “software testing” in Guide to the expression of Uncertainty in Measurement (Hope this is the correct interpretation of the acronym GUM). Can you please provide a link or a little more information also on this term?
DF,
Answering these the wrong way round chronologically (sorry).
you are correct it isn’t in the GUM – my apologies.
We had come in to the initiation meeting with some white papers and we had a fairly interesting meeting where one of the major challenges was understanding one another’s vocabulary. The metrologists from NIST and NPL pointed out that what we were talking about as benchmarking was interchangeable with what they would term ‘software testing’ whereby when the measurement is unknown at least you can verify independently how algorithms that purport to address suspected issues do actually perform. I don’t see it explicitly in the GUM but there are many links from a straight google search on software testing and metrology. Of the first page links that are freely accessible this NPL powerpoint looks reasonable: http://www.bipm.org/utils/common/pdf/nmij-bipm/WS-27.pdf.
One other thing to state on the software testing is that a key aspect of benchmarking will be our providing a range of benchmarks with a range of assumptions viz. underlying change, variability, and structure of non-climatic artefacts so we avoid over-tuning algorithms. Further, the whole thing will be cyclical. So, if you dumb luck out the first cycle with your algorithm you’ll be found out the second when the benchmarks change. Whereas if you are truly skilful in your algorithm that will come through over consecutive cycles. The whole thing should, if subscribed to, help to sort out the wheat from the chaff of algorithms leading to a more robust set of estimates (other aspects may be maturity, documentation, software provision etc.). That does not, of course, mean they will be correct. But at least we can weed out obviously sub-optimal contributions that do not stand up to reasonable scrutiny.
On the few hundred stations, yes, in theory, if such a subset existed and the sole interest was the global mean then we could just select them and be done. The issue is that I really do not know, at least a priori and with any certainty, what that subset is. In the meeting in Boulder we were shown a Canadian example where the instrument shelter was moved just three metres horizontally with negligible vertical displacement (mm’s) and yet there was an obvious demonstrable break in minimum temperature series (nothing ‘detectable’ in maximum). No instrument change, observer change, or time of obs change. And the siting was reasonable, not right up against a house or next to a road. Even small changes may impart biases and a station with truly no changes at all in 100+ years seems somewhat implausible. USCRN will get around this by constant annual checking and recalibration, triple redundancy and active monitoring / management. Sadly I know of no current long-running sites (century + records) that have benefitted from such careful curation such that I could hang my hat on the series and say it is truth within its plus or minus 2k-coverage factor.
Also, most people live locally and not globally and what matters to most people is local temperatures, local change, local extremes etc. So, even if we had a few hundred truly homogeneous sites capable of getting at the global mean evolution arguably for many applications we’d still want to consider additional data to get at that rich local data.
“You cannot quantify the uncertainty and systematic errors of a complicated calculation without performing a calibration.”
[See more at: https://www.realclimate.org/index.php/archives/2014/07/release-of-the-international-surface-temperature-initiatives-istis-global-land-surface-databank-an-expanded-set-of-fundamental-surface-temperature-records/comment-page-1/#comment-573763%5D
International agreements about calibration exist; but you scarcely need a new agreement in order to perform calibrations.
“Global Climate Models have no merits at all in performing these things within reasonable level of uncertainties.”
[See more at: https://www.realclimate.org/index.php/archives/2014/07/release-of-the-international-surface-temperature-initiatives-istis-global-land-surface-databank-an-expanded-set-of-fundamental-surface-temperature-records/comment-page-1/#comment-573763%5D
And that is what we technically term an “unsupported assertion.” It’s also one quite at odds with the published literature, which contains numerous examples of GCMs doing just what you claim they can’t. As a pretty much random example–top of search–here’s an April 2014 presentation from the AMS investigating tropical storms using reanalysis (i.e., GCM ‘data’.) As the abstract says, “The reanalysis data is constrained by observations, and can therefore be treated as ‘truth’.”
Of course, just what you deem ‘reasonable uncertainties’ may come into play here.
“If I had generated a test record looking like the late temperature record, I imagine that the product owner for the global climate model would blame my synthetic temperature record for not being realistic.”
I think your imagination is incorrect; individual model runs exist that are pretty close to the observations, and indeed there are runs that show still less warming. As far as I know, no-one has ever said that they were somehow ‘unrealistic.’ For instance, see graph 1 in the link below:
https://www.realclimate.org/index.php/archives/2013/02/2012-updates-to-model-observation-comparions/
#24 Kevin
Sorry for putting in unsupported assertions, and also for not quantifying «reasonable uncertainty».
The context for my comment is the suitability of the models for the use as stated in the paper:
http://www.geosci-instrum-method-data-syst-discuss.net/4/235/2014/gid-4-235-2014.pdf
As stated in the introduction, the paper is ambitious on being objective and reducing uncertainty both on a regional and global scale. Exemplified by the following quote:
“In addition to underpinning our level of confidence in the observations, developing and engendering a comprehensive and internationally recognised benchmark system would provide three key scientific benefits: 1. objective intercomparison of data-products, 2. quantification of the potential structural uncertainty of any one product 3. a valuable tool for advancing algorithm development.”
This illustrates how the error record will be produced: ”Conceptually, for any analog-station x as denoted by Eq. (1) a d term can be added to represent an inhomogeneity at time t and location l to give an observed value x′ which differs from the true value (x): x′ =ct,s +lt,s +vt,s +mt,s +dt,s. (2)” …. … “For the benchmarking process, Global Climate Models (GCMs) can provide gridded values of l (and possibly v) for monthly mean temperature.» (l is long-term trend in response to external forcings of the global climate system. v is region-wide climate variability.)
If I read the paper correctly a global climate model will be used to generate the temperature records for each individual station. What I am struggling with is that the selected global climate model can then produce a temperature record (for an individual temperature measurement station) that the homogenization routine will adjust when producing the global or regional temperature record. I believe this will affect the uncertainty evaluation for the homogenization routine. Which will then be correct, the global climate model or the homogenization routine?
The paper also mentions another approach: “The m and v (if not obtained from a GCM) component can be modeled statistically from the behavior of the real station data.» I think it would be a better approach to use real data than to use global climate models to avoid the that the homogenization routines may end up adjusting a record that has been produced by using a global climate model.
# 23 Peter
Vocabulary is often a challenge. Within the field of measurement the International Bureau of Weights and Measures has done a good job in defining a vocabulary. And their standards are freely available. That is not the case in many other disciplines. I also found an informative guideline on Measurement system software validation here: https://www.wmo.int/pages/prog/gcos/documents/gruanmanuals/UK_NPL/ssfmbpg1.pdf
Calibration, benchmarking, software validation can be quite different things. I think it is useful and necessary to be very clear about what will be performed. Depending on what will be performed there are international standards and guidelines within measurement which should be observed to get a recognized result, like: Vocabulary in measurement, guide to the expression of uncertainty in measurement, International system of units, General requirements for the competence of testing and calibration laboratories, Measurement system software validation etc.
I am still curious about which best practice handles the case: “metrological best practice for the historical measurements where we have no traceability». One fundamental principle I have been used follow, is to not correct a measurement unless it can be documented that a measurement error has taken place. In other words we have to live with a measurement and its uncertainty unless it can be document that it is wrong and another measurement method can be documented to provide a measurement with sufficiently low uncertainty without this systematic error. I guess a measurement can also be discarded if there are known errors without possibility for correction. If I correct a measurement I will have to document measured value, corrected value and the difference.
I would have hoped that the climate networks to a larger degree were able do identify a subset of temperature measurement stations without known issues. Stations with known issues should probably be discarded. No doubt, the uncertainty will increase for older parts of the temperature record. However following the practice above we would have to live with this increased uncertainty. Unless it can be documented that it can be replaced by a another measurement with sufficiently low uncertainty. I think, that if a temperature product produce a trend which deviates from a baseline made by simple averaging of real measurements, the product owner will have a burden of proof to estimate the uncertainty and to demonstrate that the result is free from systematic errors.
Lately, there has been some discussion about how the National Climatic Data Center seems to keep changing recent and old average temperatures in the United States Historical Climate Network over time. Will your benchmark be able to identify such effects? And more important will your benchmark be able to tell if such effects are OK or not?
DF,
regarding your response to Kevin I think there is some ambiguity in interpretation of the paper potentially here. There will be follow up papers describing in real technical details the actual derivation – the first paper is concepts. Anyway, as things stand the intra- and inter-station statisics are derived from the station charactistics themselves using a VAR and shock terms (basically adding correlated series behaviour and correlated weather-scale noise). So, small network inter- and intra-site characteristics will be entirely independent of the models. The climate model only comes in by providing the physical background field – the long-term trend and the large spatial-scale trends. This is necessary because statistics can only take us so far. Statistics may be able to give reasonable network correlation structures in the mean but it can’t get at the large spatial scale patterns or large-scale trends that are governed by large scale dynamics. If somebody comes along with a method that relies on e.g. EOFs or krigging using distal network locations to derive and adjust for breaks in individual series then its important to get that often if the US west is cold the east is warm and vice-versa for example or that when there is an El Nino there are characteristic patterns of response. Given the lack of available parallel real-worlds, models are a necessary evil here. Using multiple models as well as multiple forcing runs a. reduces dependency on any single model (models in some limit always being an approximation) and b. enables investigation of e.g. sensitivity of performance to presence of and phasing of underlying trends and variability. Williams et al., 2012 that applied benchmarks to the USHCN network and analysis may help here. The benchmarks being created by Kate and colleagues will be far more realistic than those used here. See also the analysis by Venema et al. for smaller network cases using more methods.
Regarding your response to my last comment. As I said, in an ideal world we would identify and use a backbone of unimpeachable records. But, given how we have taken the measurements and the fact that these are environmental and not lab based measures lacking repeatability I know of not even a single station that I could with any confidence assign as free of artefacts. We lack the metadata and the degree of data provenance necessary to do so. So, homogenisation is a necessary condition forced by the nature of the problem set rather than a luxury. The benchmarking exercise is a means to verify that any given algorithm put forwards is at a minimum doing something reasonable. That is why the benchmarking is such a key aspect of the initiative’s aims.
One of the key aims and expectations of the initiative is that there is absolute openness and transparency in all aspects. This includes providing all intermediate steps of analysis and code. In this regard all of these aspects are already available for GHCNv3 (and yes, the website architecture is frustrating …). So, in each analysis the hope is that everything that was done will be open – there will be no black box processes.
I had a post about the changing the past values, available from http://surfacetemperatures.blogspot.no/2013/01/how-should-one-update-global-and.html. NCDC in GHCNv3 undertake a daily refresh ingesting new sources. This makes marginal breaks appear / disappear often changing individual records in the deep past by dint of the method. On the expectation that this is the best possible estimate today this is reasonable. However, it is likely that the next version the update protocol will change to be clearer and occur much more irregularly with nrt updates solely being appending of new recent data. We will have to wait til the next version release is nailed down to be sure though.
The benchmarks will be able to say something about the verity of the algorithms. They won’t be able to say anything about whether a given group’s approach to updates is reasonable. Indeed it is hard to see how static benchmarks that mirror the static v1 databank release could or even should answer that question.
# 24 Kevin
Hi Kevin, You rightly pointed out that I provided an unsupported statement about the following claim in the paper: «Concepts for benchmarking of homogenisation algorithm performance on the global scale.»
http://www.geosci-instrum-method-data-syst-discuss.net/4/235/2014/gid-4-235-2014.pdf
“For the benchmarking process, Global Climate Models (GCMs) can provide gridded values of l (and possibly v) for monthly mean temperature. GCMs simulate the global climate using mathematical equations representing the basic laws of physics. GCMs can therefore represent the short and longer-term behaviour of the climate system resulting from solar variations, volcanic eruptions and anthropogenic changes (external forcings). They can also represent natural large-scale climate modes (e.g. El Niño– Southern Oscillation – ENSO) and associated teleconnections (internal variability).»
I stated: “Global Climate Models have no merits at all in performing these things within reasonable level of uncertainties.”
Table 2 in this paper indicates which levels of uncertainty can be regarded as significant.
Both the original claim and my rebuttal is broad. However, I hope you will consider some relevant parts of the following papers: North American Climate in CMIP5 Experiments. Part I: Evaluation of Historical Simulations of Continental and Regional Climatology
http://kiwi.atmos.colostate.edu/pubs/CMIP5_20C_evaluations_I_Final.pdf
In which: “The historical simulations are run in coupled atmosphere–ocean mode forced by historical estimates of changes in atmospheric composition from natural and anthropogenic sources, volcanoes, green- house gases (GHGs), and aerosols, as well as changes in solar output and land cover.» Section 3. b. «Seasonal surface air temperature climatology» summarize the results for temperature. Table 4 in the paper quantifies, in a way, the capability of the global climate models to provide regional temperatures. They could have been more clear about the method they used to determine the model bias. As far as I understand the average temperature for winter months december, january and february and summer months june, july and august. Over the period from 1979 to 2005 has been compared to measured and calculated average temperatures to determine the bias for each individual model and the bias for the average of all models. Intermodel standard deviation (60 % confidence level) has also been provided. To arrive at the commonly used confidence level of 95 %, the standard deviation in the paper will have to be multiplied by 2. We also have to take into account that the model result has been averaged over 2 periods of 3 months for 26 years. I would expect the standard deviation for an individual month to be significantly higher than the standard deviation of the average. There is no information on this in the paper.
The second paper evaluates the twentieth-century simulations of intraseasonal to multidecadal variability and teleconnections with North American climate: North American Climate in CMIP5 Experiments. Part II: Evaluation of Historical Simulations of Intraseasonal to Decadal Variability
http://web.atmos.ucla.edu/~csi/REF/pdfs/CMIP5_20C_evaluations_II_Final.pdf
It is worthwhile reading abstract and conclusion, in particular about teleconnections. I will not repeat it here.
These papers demonstrate that: 1. Even if a model is based on basic laws of physics, this is no guarantee that the result is accurate. 2. You cannot quantify uncertainty and systematic errors of complex models and algorithms without performing a calibration. 3 The uncertainty of a global climate model seems to exceed what can be regarded as useful for the purpose of benchmarking temperature products.
I will say that my rebuttal is reasonable. Further, I will say that the original claim is unsupported. I would also say that there is a burden associated with the original claim to demonstrate that the uncertainty of the models is sufficient low for the intended use. I think that global climate models should not be used in a concept for benchmarking of global and regional temperature products, because they will add uncertainty and reduce traceability.
#27 Peter
Many thanks for your response and your clarifications.
#28–Thanks for clarifying your idea, DF. I’m still not sure I agree, but there’s a fair amount to chew on here.
I sometimes wonder if we will reach the point of extreme accuracy in measuring temperatures and modelling the climate just when it is too late to matter. Climate throughout the geological record has tipped much faster to warming than switching back to cooling.
How much accuracy is enough before we decide the experiment has gone far enough?