The first post in this series gave the basic summary of Marvel et al (2015) (henceforth MEA15) and why I think it is an important paper. The second discussed some of the risible immediate media coverage. But there has also been an ‘appraisal’ of the paper by Nic Lewis that has appeared in no fewer than three other climate blogs (you can guess which). This is a response to the more interesting of his points.
As is usual when people try too hard to delegitimise an approach or a paper, the criticisms tend to be a rag-bag of conceptual points, trivialities and, often, confused mis-readings – so it proves in this case. Nonetheless, no paper is ever totally complete, and there are often additional sensitivity tests that could have been added and further clarifications on the methodology would be useful. Indeed, sometimes there are even choices that in retrospect would have been chosen differently and, yay, even errors. Understanding what impact that might have on the paper’s conclusions are interesting things to explore in a blog since they rarely reach a level that would necessitate another paper.
Lewis enumerates 6 supposedly fundamental problems in the paper. To paraphrase, they are as follows:
- MEA15 is working with the wrong definition of climate sensitivity.
- All previous papers using the historical records to constrain ECS are only constraining ‘effective’ climate sensitivity which is smaller than ECS.
- MEA15 used the wrong iRF and ERF values for F2xCO2.
- MEA15 shouldn’t have used ocean heat content data (or should have done so differently).
- The regressions in MEA15 in the iRF case should have been forced to go through zero.
- The linearity of the different forcings is only approximate.
Point 1 is a misunderstanding of the concept of climate sensitivity and in any case would apply to every single paper being discussed including Lewis and Curry and Otto et al. It has nothing to do with whether those papers give reliable results. Point 2 begs the question entirely (why do analyses of transient simulations under-estimate ECS?). Point 3 is worth discussing in more detail and we do so below. Point 4 (on the OHC) misunderstands that MEA15 were trying to assess whether real world analyses give the right result. Using TOA radiative imbalances instead of ocean heat uptake (which cannot be directly observed with sufficient precision) would be pointless. But there are different ways to treat the OHC and we return to that below. Point 5 is easily tested and found not to matter in the slightest (as could easily be inferred from the graphs). Point 6 is freely admitted to, indeed, we already wrote a paper on that exact issue (Marvel et al, 2015a). It makes no difference to our conclusion since the breakdown into single forcings is in order to explain the fact that the historical all-forcing runs have a lower slope than the GHG or CO2 responses, and for that, the accuracy of the linearity assumption is totally adequate.
In making his points, Lewis makes a number of errors that all go the way of making his points superficially more plausible. He conflates different model versions (fully interactive simulations in Shindell et al (the p3 runs in CMIP5), with the non-interactive runs used in MEA15 (p1 runs)), and different forcing definitions (Fi and Fa). His calculations didn’t use the decadal mean forcings/responses that were used in MEA15 and thus he ‘found’ a -0.29 W/m2 ‘error’ in our graphs. [Despite having been told of this error weeks ago, no acknowledgement of this mistake has been made on any of the original posts].
I should be clear that we are not claiming infallibility and with ever-closer readings of the paper we have found a few errors and typos ourselves which we will have corrected in the final printed version of the paper. For instance…
The F2xCO2 value
In MEA15 we used a nominal F2xCO2 in equation 2 of 4.1 W/m2 to scale the slopes seen in Fig. 1 to a TCR and ECS for 2xCO2. This is strictly the stratospherically adjusted forcing (Schmidt et al, 2014) and was thus incorrectly described and incorrectly referenced in the paper [we have notified the Nature Climate Change editors of this and it will be corrected]. In our internal tests the difference the exact value made was small and we used a single value in the iRF and ERF cases. In retrospect, this was an inconsistent choice. A better choice would have been to use, separately, the iRF and ERF values in the two cases, namely 4.5 W/m2 and 4.3 W/m2. As can be seen in the update to our online material the redone Figs 1 and 2, with these choices still show the same results:
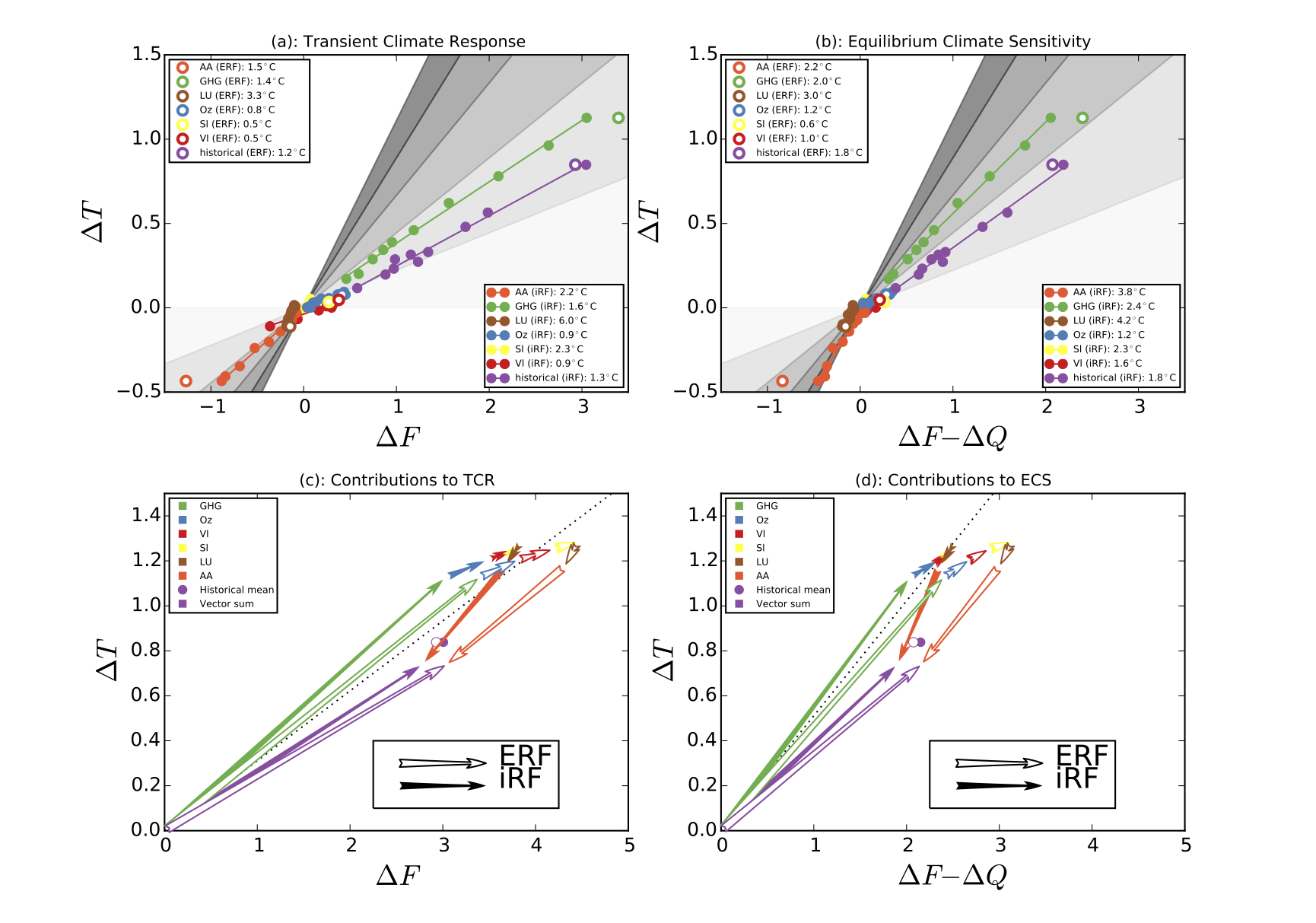
The bottom line conclusions are unchanged: taking account of the efficacies makes the resulting estimates for sensitivity larger. The likely ranges for the corrected analyses are slightly affected however.
Sensitivity studies
There are a couple of questions that have been raised that do bear further exploration. Would it make a difference if you used stratospherically adjusted forcings (Fa/RF in the IPCC AR5)? What if you account for the additional energy storage (apart from the ocean) in the system? These are relatively easy to do (though we did need to calculate the Fa terms).
The bottom line is that using adjusted forcings or assuming that ocean heat uptake is only 94% of the energy imbalance makes no qualitative difference at all.
Additional criticisms
Lewis in subsequent comments has claimed without evidence that land use was not properly included in our historical runs [Update: This was indeed true for one of the forcing calculations], and that there must be an error in the model radiative transfer. He has also suggested that it is statistically permissible to eliminate outliers in the ensembles because he doesn’t like the result (it is not). These are mostly simply post hoc justifications for not wanting to accept the results.
Summary
When there are results that have implications for a broad swath of other papers, it’s only right that the results are examined closely. Lewis’ appraisal has indeed turned up one error two errors, and suggested further sensitivity experiments, which have both ended up strengthening the robustness of the basic result. The conclusion remains that sensitivity calculations which assume the efficacies of each forcing must be exactly 1, with no uncertainty, are simply no longer credible.
As we stated in the paper, this is a result from a single model and given that all models are flawed, it really needs to be reproduced by some other groups. What prevents that is the lack of thorough calculations of the net and individual forcings in the other climate models. Hopefully some of this discussion might prompt this effort elsewhere.
We wrote the paper to be ecumenical with respect to the estimates of 20th Century forcings – hence we just took 3 previously published sets of estimates at face value and applied the efficacies calculated in two (now three) different ways to their calculations. If one was to redo those papers, you would choose the efficacies most relevant to their calculations (i.e. the ERF derived values for Otto et al) along with their adjustment for the ocean heat uptake (in our sensitivity test), and conclude that instead of an ECS of 2.0ºC [likely range 1.4-3.2], you’d get 3.0ºC [likely range 1.8-6.2]. A result far more consistent with other lines of evidence.
References
- K. Marvel, G.A. Schmidt, R.L. Miller, and L.S. Nazarenko, "Implications for climate sensitivity from the response to individual forcings", Nature Climate Change, vol. 6, pp. 386-389, 2015. http://dx.doi.org/10.1038/nclimate2888
- K. Marvel, G.A. Schmidt, D. Shindell, C. Bonfils, A.N. LeGrande, L. Nazarenko, and K. Tsigaridis, "Do responses to different anthropogenic forcings add linearly in climate models?", Environmental Research Letters, vol. 10, pp. 104010, 2015. http://dx.doi.org/10.1088/1748-9326/10/10/104010
- G.A. Schmidt, M. Kelley, L. Nazarenko, R. Ruedy, G.L. Russell, I. Aleinov, M. Bauer, S.E. Bauer, M.K. Bhat, R. Bleck, V. Canuto, Y. Chen, Y. Cheng, T.L. Clune, A. Del Genio, R. de Fainchtein, G. Faluvegi, J.E. Hansen, R.J. Healy, N.Y. Kiang, D. Koch, A.A. Lacis, A.N. LeGrande, J. Lerner, K.K. Lo, E.E. Matthews, S. Menon, R.L. Miller, V. Oinas, A.O. Oloso, J.P. Perlwitz, M.J. Puma, W.M. Putman, D. Rind, A. Romanou, M. Sato, D.T. Shindell, S. Sun, R.A. Syed, N. Tausnev, K. Tsigaridis, N. Unger, A. Voulgarakis, M. Yao, and J. Zhang, "Configuration and assessment of the GISS ModelE2 contributions to the CMIP5 archive", Journal of Advances in Modeling Earth Systems, vol. 6, pp. 141-184, 2014. http://dx.doi.org/10.1002/2013MS000265
- A. Otto, F.E.L. Otto, O. Boucher, J. Church, G. Hegerl, P.M. Forster, N.P. Gillett, J. Gregory, G.C. Johnson, R. Knutti, N. Lewis, U. Lohmann, J. Marotzke, G. Myhre, D. Shindell, B. Stevens, and M.R. Allen, "Energy budget constraints on climate response", Nature Geoscience, vol. 6, pp. 415-416, 2013. http://dx.doi.org/10.1038/ngeo1836
Thanks, Gavin. Not surprising, perhaps, but interesting nonetheless.
“Lewis’ appraisal has indeed turned up one error, and suggested further sensitivity experiments, which have both ended up strengthening the robustness of the basic result.”
Mwahaha. This gets to one of the most fundamental flaws of almost all climate deniers, the idea of robustness. Robust data survives if you find an error and fix it. Therefore, when the fundamental hypothesis is sound finding an error is not that big a deal and in fact most of the time correcting errors should strengthen rather than weaken any bottom line conclusion that aligns with reality.
Robust data also survives bootstrapping. If you start a temperature correlation in 1998 and end it in 2012 then you get one result. Start in 1997 and you get a different result. A scientist would say, that looks like a noisy trend. Instead of focusing on any one result, measure the correlation for every fifteen- or twenty-year window starting as far back as we have data and see whether the average slope is significantly different from zero (that is pretty close to basic data smoothing, something about the 1998 crowd particularly seems to miss). To find data points that particularly bias the conclusion, randomly remove points from the set and see how well the overall result holds up.
Legitimate data is robust. You can easily tell the difference between that and spurious conclusions with some basic tests that I almost never see from people who seem particularly motivated to deny warming.
I just wonder why there are no mentioning of cloud feedback effects in the paper?
As far as I understand the net surface warming is currently around 0.6 W m-2 (Wikipedia; Earths Energy budget) and the cloud feedback effect is of the same magnitude (ref. fig 7.10 in IPCC;AR5;WGI )
Thanks for taking the time to write a detailed response to a blog post.
Gavin wrote:
“[Lewis] has also suggested that it is statistically permissible to eliminate outliers in the ensembles because he doesn’t like the result (it is not). These are simply post hoc justifications for not wanting to accept the results.”
This is written as a blanket denunciation for post hoc decisions even though the run that Nic Lewis criticized looks wildly implausible. As somewhat of a layman, it seems that conclusions could only be improved by removing implausible results. Can you elaborate a bit on why this would be statistically impermissible?
[Response: Calculating the forced response to any particular effect is done by integrating over all the ensemble members which have varying internal variability. With a finite ensemble (in these simulations there are always 5), you only get to estimate that. With more resources you could do much larger ensembles and have a better estimate of course. The key however is to integrate over the whole space of internal variability – which includes variations in the North Atlantic Ocean convection. There will be ensemble members that have decreases and some with increases – but if you just remove runs with negative responses you are obviously biasing your sample. It is much better to use the spread to estimate the sampling uncertainty. – gavin]
First of all, thanks for putting the time in on this.
That said, there seem to be some errors in the corrected table S1. The ECS/iRF value for land-use efficacy is given as 1.27, which is inconsistent with the corresponding ECS in fig. 1 of 4.2 K. The latter figure, as well as my own attempt at reproducing the numbers, give an efficacy of 1.83. For the TCR/ERF case, my numbers broadly agree with your efficacies, but most of the TCRs listed in fig. 1 are inconsistent to varying degrees. The ECS/ERF case is trickier, since I’m considerably less confident in my own numbers here, but there are definitely inconsistencies between table S1 and fig. 1 for several entries: a land-use ECS of 3 K doesn’t fit with an efficacy of 1.64, similarly ozone ECS of 1.2 K vs efficacy 0.7, and volcanic ECS of 1 K vs efficacy 0.73. FWIW, my numbers for those are land-use: ECS 2.9 K/eff 1.26, ozone: ECS 1.4K/eff 0.62, volcanic: ECS 1.75K/eff 0.76.
On a slightly more positive note, the error bars on your efficacies look too wide to me, by about 50%. Entirely possible it’s my own calculations that are wrong, but it might be worth double-checking, just in case you have some more positive results lurking in there.
[Response: I’ll check the numbers later today. But the error bars are larger because they are for a Students t distribution rather than a Gaussian and so they have fatter tails. – gavin]
DF, I would say that the best estimate of earth’s energy imbalance is 0.96 W/m2 for the last 10 years.
According to NOAA/NODC the ocean heat content 0-2000 m has increased 12.23*10^22 J since 2005. That alone equals 0.76 W/m2. However, about 93% of the energy goes to the ocean, and about 15% of that goes deeper than 2000 m (Purkey and Johnsson 2010). Taking that into account suggests a total global warming of 0.96 W/m2 between 2005 and 2015.
@ O R
I agree that your estimates seems reasonable based on the (more recent) information you provide.
I used figures which are traceable to WGI;AR5 / Wikipedia.
Lewis has responded to this post at climate audit and the bishop, who probably doesn’t understand any better than I do, has a little “me too”. Seems like this discussion has legs.
By paraphrasing (incorrectly), you lose any credibility you thought you had in your response. eg, point Lewis point 1, “..This shows that for some forcing agents Marvel et al.’s methodology does not correctly quantify forcing in GISS-E2-R for recent decades of the Historical simulation, making its related efficacy and sensitivity estimates very doubtful.” is a far cry from your summary “1. MEA15 is working with the wrong definition of climate sensitivity”. You should withdraw this entire post.
[Response: If critics were less verbose and stuck to points that were actually salient, it’d be a lot easier to quote and rebut. My interest in going line by line is very limited. But if you want more, the line starting “By contrast” is a total non-sequitor, and the line afterwards is indeed a total mis-statement of how climate sensitivity and forcings are defined. His two examples come from misrepresentation of two different calculations, the second with a total different setup which has no relevance to the calculations here. His conclusion is thus posited on misstatements and irrelevancies. I leave it to readers to judge who should be withdrawing their posts. – gavin]
I read what Lewis had to say and nowhere did he say, or suggest, to “throw out” the outlier. I suggest you go to Climate Audit and read again what he actually said.
[Response: Quotes: “an outlier, possibly rogue”, “estimates are greatly reduced … if run 1 is excluded”, “I conjectured run 1 might be rogue”, “it seems pretty clear that run 1 is a rogue”, “whether or LU run 1 is rogue, there is a good case for excluding it”. Please forgive me for concluding that Lewis thinks that run 1 was a rogue result that ought to be excluded. – gavin]
No need to put words in his mouth, he expresses himself very clearly. Seeing how his work has already caused changes and corrections to be issued, a little more respect for his effort would be in order. Why the “sour-grapes” attitude. Isn’t this the way Science is supposed to work.
[Response: I’m totally happy to have people examine our work, point out issues, request additional tests or provide evidence for a counter-argument. What I find amusing is when people are so determined to dismiss a result that they find fault with everything regardless of its salience or quantitative impact in order to come to a totally predictable conclusion that the paper can be ignored. If that’s your definition of science, you’ve been sorely misinformed. – gavin]
It seems calling for retraction is the tactic de jour for followers of pseudoscience and numerology.
No one should be calling for a retraction, or stating that the results be ignored. One of Nicks points was addressed and that resulted in a change in the paper. That’s fine, no ones perfect.
I would like to see you address the other points in “specific” terms as Nick has stated them in “specific terms”. Generalities and straw men just don’t address his points.
Obviously he was correct on one point, and the paper was changed to reflect this. Can you specifically address his other points?
[Response: There is no ‘there’ there. But you tell me, what specific point do you think I’ve neglected that is actually relevant to the MEA15 results? – gavin]
Gavin – sorry, only just noticed your reply to my comment. I used Student’s t as well, so that’s not it, I’m afraid.
[Response: Agreed. We are looking into it. – gavin]
Gavin,
There appear to be a couple of issues which have been raised to which you have not yet responded. I have a few more questions arising from your latest results but this comment is already weighty enough.
a) Thank you for the correction and release of the ERF and Fa values for CO2. So far, you have provided a single corrected Fi value for 2xCO2, but have not yet provided any information on the relationship between Fi and concentration. The recently released data for ERF and Fa suggest a curve shape which is markedly different from Hansen 2005. Whereas on a plot of forcing vs log of relative concentration, Hansen showed a relationship which was concave upwards, the limited ERF and Fa data you have supplied for GISS-E2-R suggest a relationship which is concave downwards. I would be very grateful if you were to release your Fi values vs relative concentration upto 4xCO2, or at the very least your point 4xCO2 value. As I explained in an earlier request on 12th January, these data are critical to test that the aggregate response of GISS-E2-R conforms reasonably to your explicit assumption of a linear system.
[Response: The 4xCO2 values for Fa and Fs are on the forcings pages, for Fi it was 8.36W/m2. – gavin]
b) There are three lines of evidence which suggest that the LU forcing agent was not correctly switched on when you calculated the Fi values for the Historical simulation, none of them conclusive but each highly indicative. Can you please provide your assurance that this has been tested and that there is no doubt that LU forcing was included in the “All-forcings_together” values? [For the avoidance of any doubt, the question is not, repeat not, whether the LU forcing agent was switched on during the Historical simulation. I can and have independently verified this.]
[Response: There are lots of moving parts in the calculations, and there are sometimes anomalies. We are going back over the work done as far back as 2011 to see if there is anything amiss. If we find something, we’ll let people know. – gavin]
c) Both you and Dr Miller remarked in published papers in 2014 that an error had been identified in ocean heat transport in GISS-E2-R. Can you confirm that the results in the public domain have been corrected for this problem? If so, can you provide a pointer to the correction? If not, can you explain why you are confident that this error should not influence the values which you have used in Marvel et al?
[Response: All models have bugs – sometimes trivial, sometimes more important, sometimes due to to coding errors, sometimes due to conceptual issues. The specific issue we found in the GISS-E2-R runs was a mis-calculation of the isopyncal slope in the parameterisation of ocean eddy-related mixing. In our internal development process, this was fixed and, combined with a few more tweaks in the ocean model, gives a better simulation of ocean climatology. Those changes will be incorporated in the GISS-E2.1-R simulations which we are preparing for CMIP6. Whether all analyses done in CMIP5 will be robust to those changes remains to be seen. But as we stated clearly in the paper, we acknowledge that our results came from a single (imperfect) model and that it would be useful to have other model centers do independent calculations to see if this is indeed common. From personal communications it appears that it is, but we’ll need to wait on the papers for confirmation. Just so that you are clear on what is involved – the single forcing runs we did in HistoricalMisc compromise over 200 simulations, each 156 years long, which if run sequentially would have taken ~30 years to complete. It is therefore only possible to do large suites of these runs periodically when we have new frozen model versions available. – gavin]
d) If your CI values purport to be based on variance of the mean, they appear to be out by a factor of about two. [This is not a problem arising from the difference between Gaussian and t-distribution.]
[Response: I checked this. The uncertainties in the Table S1 are the 90% spread in the ensemble, not the standard error of the mean. The difference is the sqrt(n) term (=2.24). – gavin]
e) You appear to have sidestepped the key issue raised by Lewis with respect to your introduction and definition of “Equilibrium Efficacy”, which is that it confuses two quite separable concepts. Normally when new measures are invented by scientists and engineers their utility arises from their ability to elucidate, not to confound. Your definition specifically confuses the question of the efficacy of a forcing agent with the question of why there is a difference displayed in GCMs between their effective equilibrium temperature and their reported equilibrium temperature. The latter difference arises from the fact that most GCMs display “time-varying feedback”, which results in a curve on a Gregory plot rather than a straight line. We now know from Andrews 2014 that a key culprit for this curvature in most models is SW CRE; hence we still do not know whether this is entirely an artifact of cloud parameterization or whether such curvature represents a real-world phenomenon. If you wish to present an argument that it IS a realworld phenomenon, and hence observation-based methodology underestimates ECS, then by all means do so, and we can have an intelligent debate. However, let us not confuse that conversation with the question of efficacy. If I take the GISS-E2-R 1% p.a. data – the basis for your transient efficacy denominator – then I find the gradient of an F-N vs T plot (still using Hansen’s Fi data to define the F vs time relationship) is 2.28 W/m2/deg K. The data from the historic run, on the other hand, yields a value of 2.39 – almost identical. Hence, we might reasonably conclude that there has been no significant change in estimated effective equilibrium temperature, a very different picture from the result you obtain with your definition. The CO2-only case yields an estimate of Teq for 2xCO2 of 4.52/2.28 = 1.98 deg K. This compares with the reported ECS of 2.3 deg K. Hence, using your definition we find that CO2 has an Equilibrium Efficacy of 1.98/2.3 = 86%. So we deduce that CO2 has an Equilibrium Efficacy of only 86% relative to itself. You must see that this is an absurd result.
[Response: Our interest in the ‘effective climate sensitivity’ is very close to zero. As you say, new concepts are most useful if they elucidate rather than confound, and I don’t find that the ‘effective’ climate sensitivity adds very much. It is defined from an even more idealised simulation (abrupt4xCO2) than either the 1% CO2 experiment, and in almost every model gives an underestimate of the equilibrium value. Why you think that the linear regression from the first 140 years of a sensitivity run is more ‘real world’ than anything else is unclear. Why there is such a nonlinearity in the abrupt4xCO2 runs is interesting, and as the papers cited suggest it is likely related to spatial variations in the feedbacks combined differences in response times (particularly the southern ocean). However, this is also the issue at the heart of the differences seen by forcing agents since they trigger different spatial patterns of feedbacks and responses too. Thus the two issues are very likely to have the same underlying cause and thus can’t be ‘cleanly’ separated. There are some papers expanding on this in the publication pipeline. Your calculation simply begs the question of what impact these issues have on estimates of ECS – and let’s be clear, all of the comparisons of different constraints have been about ECS and TCR not ‘effective’ CS. All you are showing is that effective CS is smaller than ECS – and this is not absurd, it is already well-known. – gavin]
gavin, in line to #14:
Heh. Russell Seitz keeps insisting the failure of ever-finer-grained climate models to converge on a sensitivity value casts the entire modeling enterprise in doubt. Without that, all he’s got to sustain his opposition to government intervention against fossil fuels is the argument from consequences. I’m pretty sure he realizes it as a physicist, he just isn’t ready to admit it to himself as a Libertarian with anarcho-capitalist sympathies. Meanwhile, hardcore AGW-deniers are happy to cite him.
A good fifth grade explanation of this — how many simulation runs are done, how much computation time and hardware has to be dedicated — would be useful, sometime. It takes a while to comprehend.
Running multiple simulations with a climate model is always going to give results that have some inherent scatter from one to the next trial.
Each of the variables can be set somewhere on each simulation, right? And each of those kicks something else around, so you get a different result on each simulation run — a spread, not always the same line.
It’s like, say, you have a box of frogs, and you spill them out on the carpet.
They will never land in a nice cubical pile and stay there calmly.
Each one wiggles and pushes the others around and the result is a spread.
Not the same spread each time, but always a spread.
[Response: There is no ‘there’ there. But you tell me, what specific point do you think I’ve neglected that is actually relevant to the MEA15 results? – gavin]
Reading all the back and forth, it’s clear that you’ve misstated or misunderstood Nic’s response on several points. He gave you the courtesy of responding to each of your points in a professional manner. Instead of walking away, perhaps you should consider reciprocating in the interest of civil discourse. Just a thought.
That’s not clear to me at all. Perhaps it would have been clearer had you included specifics.
P.S., apropos “Running multiple simulations with a climate model is always going to give results that have some inherent scatter …”
This:
Recently, in a previous post, I stated to you that I felt you didn’t directly answer questions proposed by Nic Lewis…. you responded
“[Response: There is no ‘there’ there. But you tell me, what specific point do you think I’ve neglected that is actually relevant to the MEA15 results? – gavin]
Now i see, under the radar, giving no credit to Nick, we have a revision, a sort of mea culpa, that yes in fact he was right.
[Response: Please don’t play games. As we stated on the webpage for the study (which is linked above), we said weeks ago we would be correcting the paper for the F2xCO2 confusion. The updated paper has just gone online (Friday I think), along with a correction notice acknowledging Nic Lewis’ role. In the meantime we redid all the forcing calculations from Miller et al to make sure they were correct and found that in one case – the iRF for the historical (all-forcing) simulation, land-use had been effectively neglected (it was a complex error, but had the effect of not including LU as a forcing). We have now updated the webpage with the specifics (this afternoon), and so your accusation that this is ‘under the radar’ is false. The two points we corrected don’t really change much (though they do lessen the effect slightly) but do not support Nic Lewis’ overall contention that the results are ignorable. If you want to make further points, leave out the attitude. – gavin]
[edit]
Your acknowledgment of Nic Lewis’ role
“The authors thank Nic Lewis for his careful reading of the original manuscript that resulted in the identification of these errors.”
Why not “The authors thank Nic Lewis for his identification of these errors.”
It’s more honest and less mean-spirited.
Lewis was right about the LU being missing. You were initially skeptical and dismissive of this concern of his:
“Lewis in subsequent comments has claimed without evidence that land use was not properly included in our historical runs….”
But now it turns out the LU was missing. You acknowledge it now (good), but dismissed it at first (bad). I’m not a climate scientist, so perhaps the impact of LU being missing is small to your overall result. OK, whatever. But I still don’t like the initial defensiveness on the detail itself.
[Response: I was indeed initially sceptical – and I make no apology for that. But regardless of that scepticism, we investigated and we did turn up a subtle issue that had the same impact as if we had just left LU forcing out of that specific calculation. This has lead to an correction on the Miller et al (2014) paper (available here) and to some of the input values in the Marvel et al calculations. It’s useful to think of this as an example of Bayesian priors in action – given that 99% of the criticisms we hear about climate science are bogus or based on deep confusions about what modeling is for, scepticism is an appropriate first response, but because we are actually scientists, not shills, we are happy to correct real errors – sometimes they will matter, and sometimes they won’t. – gavin]
Michael Mayson, people who don’t routinely read academic papers shouldn’t try to tell professionals how to write their acknowledgements — you just end up sounding silly. Go read the acknowledgements in a few dozen papers and you’ll quickly see that this wording is commonplace. (Not that “you thanked him *too much*” is really coherent as a criticism.)
“This has lead to an correction on the Miller et al (2014) paper (available here)”
Link not working.
[Response: Fixed – gavin]
#22–
I agree with JBL; I see nothing either dishonest or mean-spirited about the wording used. Indeed the specific praise of “careful reading” gives more, rather than less, weight to Nic Lewis’s efforts.
And given that the authors had to redo “all the forcing calculations from Miller et al to make sure they were correct” to find “that in one case” there was an error, my take is that the wording is also more precise. Lewis provided, apparently, not a precise identification of the error, but rather a good pointer to it. That’s a valuable contribution, to be sure, but also one that the correction notice wording describes well.
I agree with KMK #26. Being thanked for “careful reading” is a compliment not to be diminished. It implies a lot more than the words convey. I wish I had time for “careful reading” of all the literature that passes over my desk.
And Miller et al (2014) acknowledge Lewis with
“The authors thank Nic Lewis for bringing this error to our attention.”
That’s more like it!
I have to thank you – but not the special pleaders represented in a few of these comments – for always putting first the science in science.
Even for the math challenged, this discussion and the meticulous responses from Gavin Schmidt – who, lord knows, doesn’t really have time for this sh** – demonstrate who is curious and wants to know, and who is advocating for stubborn resistance to knowing about and increasing understanding of the state of things as they are.
yes it was
One final point. This is not an example of ‘groupthink’ surpressing legitimate debate in estimating sensitivity – rather it’s the result of deeper explorations to examine why a certain type of estimate was an outlier, which had a conclusion that ended up reinforcing the existing, wider, body of knowledge. Surprising as it may seem to some people, this is actually the normal course of affairs in science. Mainstream conclusions are hard to shift because there is a lot of prior work that supports them, and single studies (or as here, a group of similar studies) have their work cut out to change things on their own. As with supposedly faster-than-light neutrinos, most anomalies eventually get resolved. But not necessarily on the IPCC timetable.