There is an interesting news article ($) in Science this week by Paul Voosen on the increasing amount of transparency on climate model tuning. (Full disclosure, I spoke to him a couple of times for this article and I’m working on tuning description paper for the US climate modeling centers). The main points of the article are worth highlighting here, even if a few of the characterizations are slightly off.
The basic thrust of the article is that climate modeling groups are making significant efforts to increase the transparency and availability of model tuning processes for the next round of intercomparisons (CMIP6). This partly stems from a paper from the MPI-Hamburg group (Mauritsen et al, 2012), which was perhaps the first article to concentrate solely on the tuning process and the impact that it has on important behaviour of the model (such as it’s sensitivity to increasing CO2). That isn’t to say that details of tunings were not discussed previously, but the tendency was to describe them briefly in the model description papers (such as Schmidt et al. (2006) for the GISS model). Some discussion has appeared in IPCC reports too (h/t Gareth Jones), but not in much depth. Thus useful information was hard to collate and compare across all model groups, and it turns out that matters.
For instance, if some analyses of the model ensemble tries to weight models based on some their skill compared to observations, it is obviously important to know whether a model group tuned their model to achieve a good result or whether it arose naturally from the the basic physics. In a more general sense this relates to whether “data accommodation” improves a model predictive skill or not. This is quite subtle though – weather forecast models obviously do better if they have initial conditions that are closer to the observations, and one might argue that for particular climate model predictions that are strongly dependent on the base climatology (such as for Arctic sea ice) tuning to the climatology will be worthwhile. The nature of the tuning also matters: allowing an uncertain parameter to vary within reasonable bounds and picking the value that gives the best result, is quite different to inserting completely artificial fluxes to correct for biases. Both have been done historically, but the latter is now much rarer.
A recent summary paper in BAMS (Hourdin et al., 2016) discussed current practices and gave results from a survey of the modeling groups. In that survey, it was almost universal that groups tuned for radiation balance at the top of the atmosphere (usually by adjusting uncertain cloud parameters), but there is a split on pratices like using flux corrections (2/3rds of groups disagreed with that). This figure gives some more details:
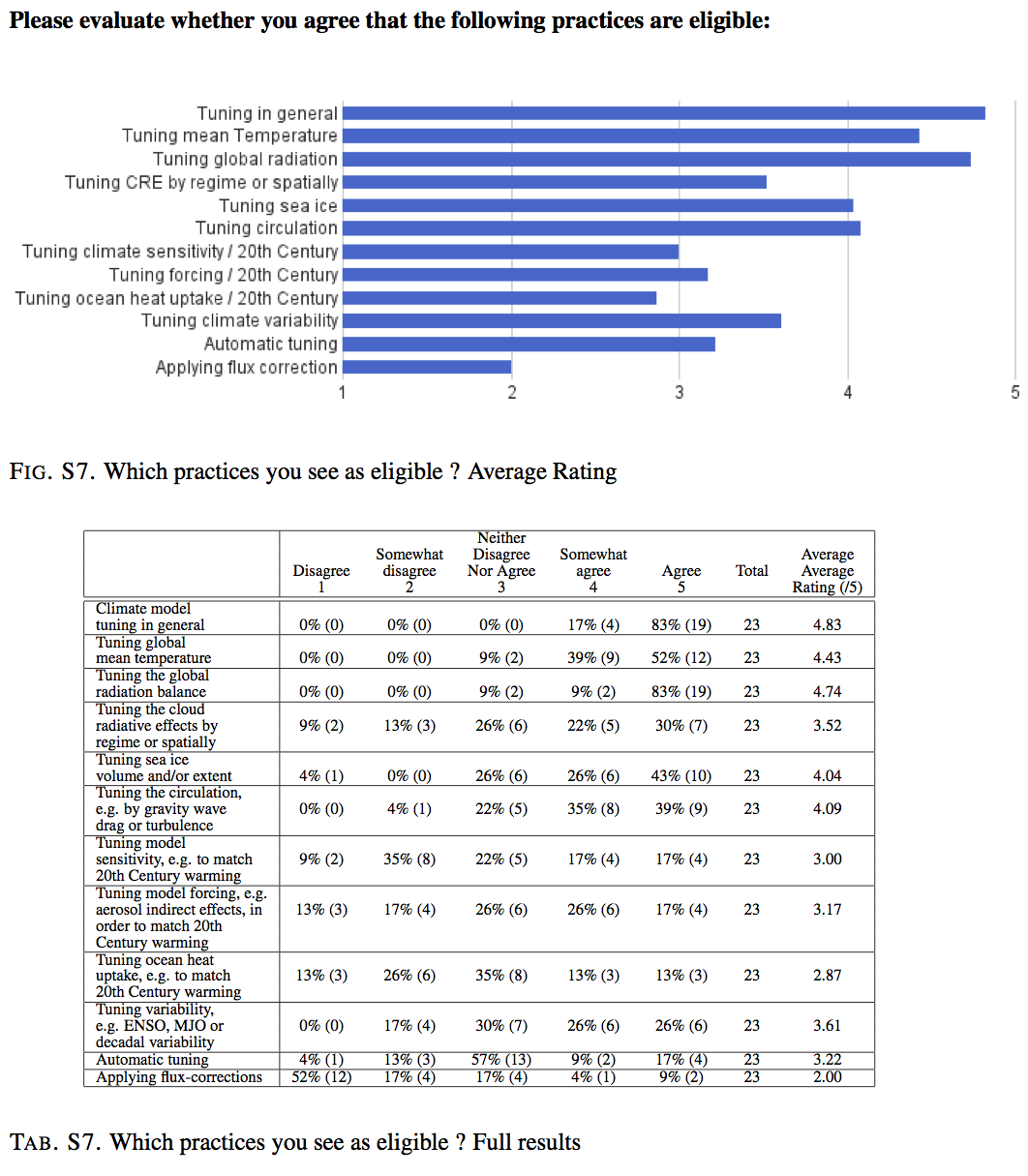
Summary results on tuning practices from the survey of CMIP5 modeling groups published in Hourdin et al. (2016).
The Science article though does make some claims that I don’t think are correct. I assume these are statements that are paraphrases from scientists that the writer talked to, but they would have been better as quotes, as opposed to generalisations. For instance, the article claims that
“… climate modelers [will now] openly discuss and document tuning in ways that they had long avoided, fearing criticism by climate skeptics.
…
The taboo reflected fears that climate contrarians would use the practice of tuning to seed doubt about models— and, by extension, the reality of human driven warming. “The community became defensive,” [Bjorn] Stevens says. “It was afraid of talking about things that they thought could be unfairly used against them.”
This is, I think, demonstrably untrue, since tuning has been discussed widely in papers including here on RealClimate. Perhaps it does reflect some people’s opinion, but it is not true generally.
The targets for tuning are vary across groups, and again, it matters which you pick. Tuning to the seasonal cycle, or to the climatological average, or to the variance of some field – which can be well characterised from observations, is different to tuning to a transient change of over time – which is often less well known. Indeed, many groups specifically leave transient changes out of their tuning procedures in order to maintain those trends for out-of-sample evaluation of the model (approximately half the groups according to the Hourdin et al survey).
The article says something a little ambiguous on this:
Indeed, whether climate scientists like to admit it or not, nearly every model has been calibrated precisely to the 20th century climate records—otherwise it would have ended up in the trash. “It’s fair to say all models have tuned it,” says Isaac Held.
Does that mean the global mean surface temperature trends over the 20th Century, or just that some 20th Century data is used? And what does ‘precisely’ mean in this context? The spread of 20th Century trends (1900-1999) in the CMIP5 simulations [0.25,1.17]ºC is clearly too broad to be the result of precisely tuning anything! On a similar issue, the article contains an example of the MPI-Hamburg model being tuned to avoid a 7ºC sensitivity. That is probably justified since there is plenty of evidence to rule out such a high value, but tuning to a specific value (albeit within the nominal range of 2 to 4.5ºC) is not justified. My experience is that most groups do not ‘precisely’ tune their models to 20th Century trends or climate sensitivity, but given this example and the Hourdin results, more clarity on exactly what is done (whether explicitly or implicitly) is needed.
One odd comment relates the UK Met Office/Hadley Centre models:
Proprietary concerns also get in the way. For example, the United Kingdom’s Met Office sells weather forecasts driven by its climate model. Disclosing too much about its code could encourage copycats and jeopardize its business.
It would be worrying if the centers didn’t discuss tuning in the science literature through fear of commercial rivals, and I don’t think this really characterises the Hadley Centre position. Some groups code’s (incl. the Hadley Center) are however restricted for various reasons, though I personally see that as an unsustainable position in the long-term if groups want to partake in international model intercomparisons that will be used for public policy.
The article ends up on an interesting note:
Daniel Williamson, a statistician at the University of Exeter in the United Kingdom, says that centers should submit multiple versions of their models for comparison, each representing a different tuning strategy. The current method obscures uncertainty and inhibits improvement, he says. “Once people start being open, we can do it better.”
I think this is exactly right. We should be using alternate tunings to expand the representation of structural uncertainty in the ensemble, and I hope many of the groups will take this opportunity to do so.
References
- T. Mauritsen, B. Stevens, E. Roeckner, T. Crueger, M. Esch, M. Giorgetta, H. Haak, J. Jungclaus, D. Klocke, D. Matei, U. Mikolajewicz, D. Notz, R. Pincus, H. Schmidt, and L. Tomassini, "Tuning the climate of a global model", Journal of Advances in Modeling Earth Systems, vol. 4, 2012. http://dx.doi.org/10.1029/2012MS000154
- G.A. Schmidt, R. Ruedy, J.E. Hansen, I. Aleinov, N. Bell, M. Bauer, S. Bauer, B. Cairns, V. Canuto, Y. Cheng, A. Del Genio, G. Faluvegi, A.D. Friend, T.M. Hall, Y. Hu, M. Kelley, N.Y. Kiang, D. Koch, A.A. Lacis, J. Lerner, K.K. Lo, R.L. Miller, L. Nazarenko, V. Oinas, J. Perlwitz, J. Perlwitz, D. Rind, A. Romanou, G.L. Russell, M. Sato, D.T. Shindell, P.H. Stone, S. Sun, N. Tausnev, D. Thresher, and M. Yao, "Present-Day Atmospheric Simulations Using GISS ModelE: Comparison to In Situ, Satellite, and Reanalysis Data", Journal of Climate, vol. 19, pp. 153-192, 2006. http://dx.doi.org/10.1175/JCLI3612.1
- F. Hourdin, T. Mauritsen, A. Gettelman, J. Golaz, V. Balaji, Q. Duan, D. Folini, D. Ji, D. Klocke, Y. Qian, F. Rauser, C. Rio, L. Tomassini, M. Watanabe, and D. Williamson, "The Art and Science of Climate Model Tuning", Bulletin of the American Meteorological Society, vol. 98, pp. 589-602, 2017. http://dx.doi.org/10.1175/BAMS-D-15-00135.1
““climate modelers [will now] openly discuss and document tuning in ways that they had long avoided, fearing criticism by climate skeptics.”
I would be surprised if that were true in general, especially in all the countries that are not invested by mitigation sceptics. Maybe I was a bit naive, but until I started blogging I was not aware of the scale of the problem in the USA.
Furthermore, there is completely no need to do so. On my blog I write a lot about real problems with climate station data. These ideas are not picked up by the mitigation sceptical movement, they prefer their own rubbish for some reason. My impression is that the more extreme and untrue a meme is, the stronger it functions as a pledge of allegiance to the mitigation sceptical movement.
Whatever the case, nothing scientists can do will ever appease this political movement and we should never in any way let our research be influenced by them.
I think Bjorn’s comment (“The community … was afraid of talking about things…”) has been over-interpreted.
I’ve met scores of modellers, including Bjorn, and not one of them has ever been afraid of talking with me about any aspect of modelling. However, most of them would never talk to, say, a journalist about any of technical details around modelling, for the simple reason that the chances of any of it being accurately represented in a news article is pretty close to zero. So when anyone says modellers are “afraid of talking”, I think it’s likely they just mean talking to people outside the research community.
“…they prefer their own rubbish for some reason.”
Three reasons:
1) It’s simpler, and takes less work, simply to invent something.
2) Real problems tend to be more boring, less extreme, and less dramatic. Boring doesn’t cut it in the world of ‘blog science’–especially not where the object is to create memorable sound-bites (or the written equivalent) that sow doubt.
3) They often don’t wish to take the trouble to actually understand the real problems–or don’t have the background to do so, even if they wished.
I use numerical models to simulate hydrologic systems. We calibrate the basic hydrologic variables in the models against historical data. This process should probably be called ‘history matching’. Our codes are based on very simple, irrefutable physics, but you can’t let the physics alone run the model as you need to specify the 3D distribution of hydrologic properties within the model domain. For GCM’s is ‘tuning’ equivalent to ‘history matching’ or ‘calibration’? If so, what’s the problem?
Victor,
I think that you meant to write “… in all the countries that are not infested by mitigation skeptics.”
What you are not being told is that these “tunings”, “adjustments”, “calibrations” and “tinkerings” are being used to cover up failings in the models, or “biases” as the modellers like to describe them. It is the multitude of errors in the models which the modellers do not wish to admit to, not the corrections which they feel are necessary. Those biases are all known unknowns.
At the heart of the problem is that the modellers have an “unknown unknown”. They are using the wrong equation of radiative transfer. The one they employ was first suggested by the astronomer Karl Schwarzschild to describe radiative transfer within the Sun. It is suitable for stellar atmospheres where Kirchhoff’s Law applies because there emission is equal to absorption. If that were not the case, there would be layers of the Sun where the temperature continually rose or fell.
The whole point about the greenhouse gases in a planetary atmosphere is that they absorb the infrared radiation emitted by the surface, and so Kirchhoff’s law does not apply. Rather than using Schwarzschild’s Equation of Radiative Transfer (Goody and Yung [G&Y], Eqn. 2.170) which is for blackbody radiation, they should be using the Microscopic Radiative Transfer Equation, which has terms for both spontaneous and stimulated emissions by greenhouse gases (Thomas and Stamnes [T&S], Eqn. 4.30).
T&S follow G&Y arguing that Schwarzschild’s equation can be derived from the Microscopic equation, but that is wrong.
Schwarzschild’s equation is roughly:
dI/dz = -k I + k B(T) = – k * sink function + k * source function
while the microscopic equation is roughly:
dI/dz = -n1 B12 I + n2B21 I + n2A21 = -n1 * sink function + n2 * source function
T&S claim that k = n1 B12 – n2B21 but that is obviously wrong!
I go into a little more detail about the problem and its consequence in a poster that I presented at the Royal Meteorological Society Conference in Manchester during the summer. See:
https://www.researchgate.net/publication/304897458_A_New_Radiation_Scheme_to_Explain_Rapid_Climate_Change
Is there no effort to use sensors to constrain the forcings empirically? Can we not measure the outward migration of the CO2-pause? Are there no TOA measurements of adequate precision? I follow along on this blog but do not recall seeing this topic discussed much here. I would like to think that there would be less wiggle room for fiddling with the tuning going forward, not more.
#4 Nick – well, basically I agree, but I suppose it depends upon which calibration metric or metrics one uses in the calibration, doesn’t it? And how many of the tuned or calibrated results one chooses to use for predictive/forecast purposes. Or if one uses a set of metrics, applying equal merit to each, or maybe giving greater merit to some than others, or maybe a GLUE or equivalent type of approach, etc. etc. There is also the need to ensure that the results of any calibration are physically sensible. Thus, I might by using Nash-Sutcliffe only (which I wouldn’t generally recommend) and obtain a high score (good calibration), but only at the expense of groundwater values which are unrealistic physically. Or the calibration is good (fits well to the observations) over one season but poor over another, or it does well over a set of years in the calibration data but not all of them, etc. etc., so which do you then use? And so on, and so on. The same applies in geormorphological modelling, and also mapping problems, and I find the whole thing gets really snarled up when applying the problem over space as well as time. It’s a problem I struggle with all the time in modelling, particularly using dynamical models but not restricted to those, and whatever the system being modelled or the discipline within which I’m working or conducting research.
@ Nick V #4,
I think it would be useful to discuss this with a non-climate change example, so perhaps you could elaborate? What specifically are you modeling?
ABM: The whole point about the greenhouse gases in a planetary atmosphere is that they absorb the infrared radiation emitted by the surface, and so Kirchhoff’s law does not apply.
BPL: Kirchhoff’s Law applies whenever the temperature can be measured. Most of the atmosphere is in thermodynamic equilibrium and therefore KL applies.
Well, I was going to disagree since GMD has always encouraged discussion of things like parameter tuning.
But the numbers agree with you:
22 papers in GMD (Geoscientific Model Development) with tuning in the abstract, but only 6 of those prior to 2015 !
4 papers with tuning in the title, 2 in 2015, and 2 in 2016 !
So it seems you are right – people are at last getting confident enough with open science concepts that discussion of things like tuning has become something they feel comfortable publishing.
Phew!
jules
Barton,
For the atmosphere to be in thermodynamic equilibrium, the greenhouse gases must be emitting as much radiation as they absorb. That is not what Tyndall or anyone else has found.
BTW, the atmosphere is thought to be in local thermodynamic equilibrium (LTE) where it emits like a black-body. This was a term invented by E. A. Milne (1930) to describe the part of the Sun which does emit like a black body, believing that the line radiation being emitted by the gases [!] there is broadened by the high pressure and temperature to produce a Planckian spectrum. These high pressures and temperatures do not exist in the Earth’s atmosphere and are only roughly true in that of Venus.
Zebra –
Hydrologic models are pretty simple, but perhaps illustrative. They keep track of mass exchange of water between the grid cells in the model. The basic governing equations are Bernoulli’s Equation for hydraulic potential and the continuity equation, a time variable form of the Laplace Equation. The dependent variable in each cell is potential. The potential is related to the mass exchange, calculated from the hydraulic gradient, conductivity and the potential change per unit change in mass. Stresses are measured quantities (rainfall, pumping, …). Calibration targets are observed fluxes (streamflow for example) and potentials (water levels). You vary (‘calibrate’) conductivity and potential change per unit mass change in each cell until your model can reproduce the observed values over a given historical period. The allowable range of variation in the independent variables is limited by prior, independent information. The calibrated model can be tested against another set of observed values and stresses to see if it can reproduce a data set outside of the calibration period. The governing statement is ‘if your model reproduces observed data it might be correct. If it can’t reproduce observed data you know it is wrong’. GCM’s are much more complicated as they have several dependent variables and you can’t assume incompressibility and isothermal conditions as we can in hydraulics. However, history matching is an accepted part of mathematical modeling. It can lead to biased results, as Nick O. suggests, but if the modeling is open, with publically available datasets and codes, deliberate attempts to bias the results become obvious. If different modeling codes get the same results, as in the CMIP5 results, that is an additional, and significant, check on model results.
I have always thought that numerical modelers would prefer to calibrate (which I think is the same as “tune”) their model to one dataset, and then validate the model by making predictions that are compared to an independent dataset. This approach was used in a case I am familiar with (3-D basin-scale modeling of air quality), although I recognize that this is a challenge when working at the global level.
It does seem to me that calibrating using a dataset that one then also uses for validation is a problem. Thanks for your thoughts.
For tunings and other estimates, the model parameters should show the uncertainty initially. That is, they should be distributions rather than point figures, representing distribution estimates as well as one can guess. The model outputs would than reflect the underlying uncertainty. That’s better than running models with alternate tunings. It will probably be awhile before computers can handle this task, however.
Nick V. #12,
Thanks. That’s pretty much what I was hoping for; “simple and illustrative”.
If we are trying to educate and communicate, an example like this… “Here’s how we figure out the downstream effects of building a levee.”… would perhaps, with appropriate modifications/simplifications of language, be more accessible to the public than GCM.
It wouldn’t change the mind of the usual suspects, of course, but it demonstrates the issues around modeling complex systems at a scale to which an interested lay person could relate.
t marvell is correct. If you can estimate a probability distribution for the values of each independent input variable in a model (called a probability density function or pdf), you can run many simulations where the value of each independent variable in each cell for each run is selected from the probability density function for that variable. At the conclusion of your many, many model runs, at each cell you have a pdf for each dependent variable, instead of a single, deterministic value for say temperature or hydraulic potential. The final results inherently reflect the uncertainty in the input variables. Even a simple, rectangular, ‘boxcar’ pdf for an input variable helps express the final uncertainty. This is the basic idea behind running ensembles of a GCM simulation, with the average (50% probability) of all runs very likely being a better estimate of the dependent variables than a single deterministic run. There are two significant problems of course. GCM’s are huge, complicated models with very long execution times. To run them stochastically for long simulation times requires using computational efficiencies that reduce complexity or spatial and temporal resolution. Also, pdf’s for input variables may not be easy to obtain. The ‘real’ pdf for a variable includes uncertainties beyond simple measurement error and can be difficult to estimate.
Have now got around to reading the Science News thingie. Bit annoying.
1.
“Indeed, whether climate scientists like to admit it or not, nearly every model has been calibrated precisely to the 20th century climate records—otherwise it would have ended up in the trash. “It’s fair to say all models have tuned it,” says Isaac Held, a scientist at the Geophysical Fluid Dynamics Laboratory, another prominent modeling center, in Princeton, New Jersey.”
I think you are too kind, and that this is more like utter rubbish. Certainly when we were in Japan it was clear they did rejection sampling at best (which means they throw it out if it is really embarrassingly bad but keep it otherwise). The computational overhead of the historical run was too great to do otherwise.
2.
“For example, the United Kingdom’s Met Office sells weather forecasts driven by its climate model. Disclosing too much about its code could encourage copycats and jeopardize its business.”
Very annoying. The Met Office code is indeed bound by copyright, but they have been superlative in arranging for GMD editors to see their code when editing their papers (although, of course we have to burn it after we have looked at it!). Yes it involved lawyers, quite a lengthy negotiation and a long copyright agreement, but they cared enough to go to the effort of doing it!
3.
““The model we produced with 7° was a damn good model,” Mauritsen says. But it was not the team’s best representation of the climate as they knew it.”
When I quizzed Thorsten about this a couple of years ago he told me that they hadn’t done a historical run (let alone an LGM) with the model and that he didn’t think it would be any good. So that kind of proves point 1 again as well!
jules
Dear Julia,
I just found your comment on our experience with the 7 degree model, and felt obliged to answer. Of course a single phrase citation in Paul’s news piece cannot provide a precise description of the complex situation, but I would maintain it was a damn good model in terms of the aspects we used to look at. It had smaller biases than any earlier MPI model, and perhaps for the first time in MPI model development history, it actually had low-level tropical clouds worth speaking of. This was exciting. But the extreme sensitivity would have likely made it overheat against the instrumental record by a factor two, or so, we judged. You are right, though, that I do not know for sure that this be the case, but hopefully we will soonish find out. This is a bit of work.
Cheers, Thorsten