A recent sensible-sounding piece by Roy Spencer for the Heritage foundation is full of misrepresentations. Let’s play spot the fallacy.
Comparing climate models to observations is usually a great idea, but there are some obvious pitfalls to avoid if you want to be taken seriously. The most obvious one is to neglect the impacts of internal variability – which is not synchronized across the models or with the observations. The second is to avoid cherry picking your comparison – there is always a spread of results by just looking at one small region, in one season, in one metric, so it’s pretty easy to fool yourself (and others!) if you find something that doesn’t match. The third is to ignore what the rest of the community has already done to deal with what may be real issues. Spencer fails to avoid each one of these.
Where’s the model spread, Roy?
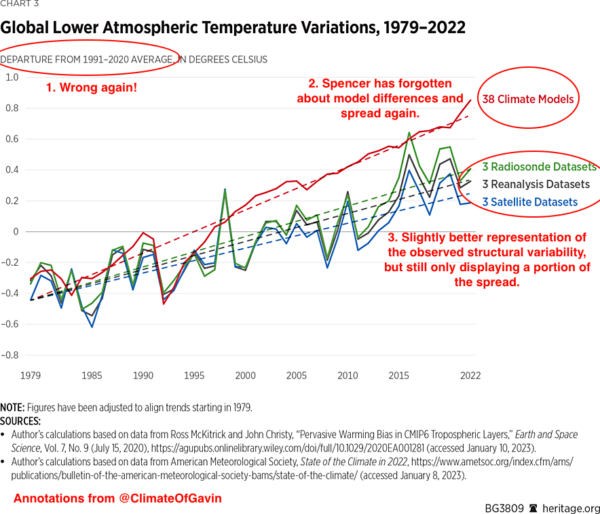
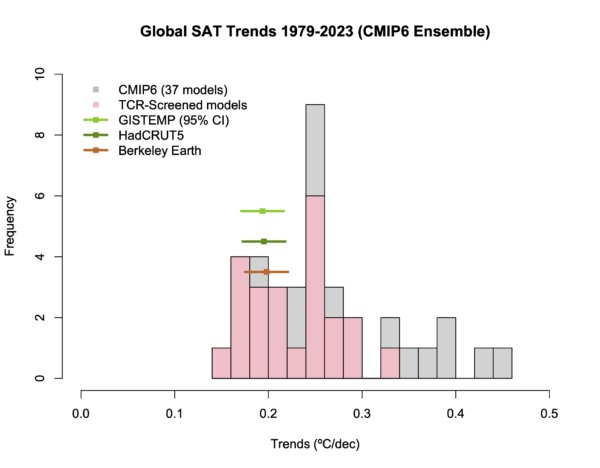
The first figure in Spencer’s article is the following – which I have annotated.
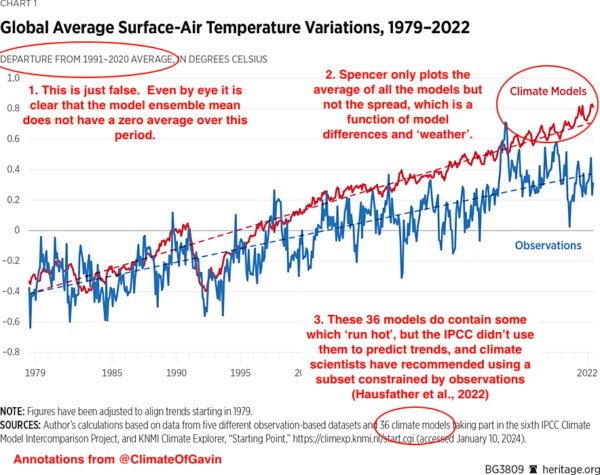
You can see the impact of his choices by comparing to this similar figure from our annual update:
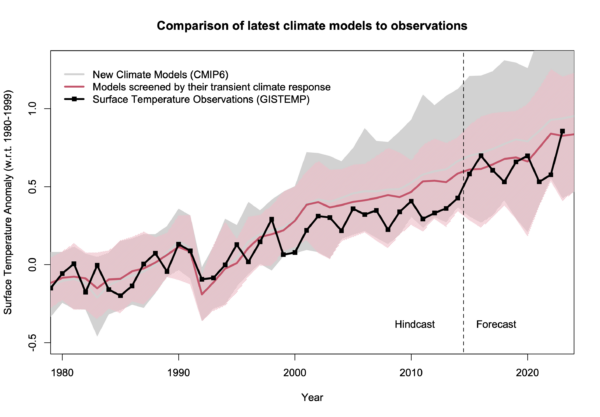
Our figure is using annual mean data rather than monthly (which is less noisy). First, the baseline is what it says on the box – there isn’t an extra adjustment to exaggerate the difference in trends. Second, you can see the spread of the models and see that the observations are well within it. Third, the impact of model selection – that screens the models by their transient climate sensitivity Hausfather et al., 2022 – is also clear (the difference between the pink and grey bands). To be quantitative, the observed trend from 1980 0.20±0.02ºC/dec (95% CI on the OLS trend). The full multi-model mean and spread is 0.26ºC/dec [0.16,0.46], while for the screened subset it’s 0.23ºC/dec [0.16,0.31]. Note that the SAT/SST blend in the observations makes a small difference, as would a different recipe for creating the mean from the individual simulations.
To conclude, the observations lie completely within the spread of the models, and if you screen them based on an independently constrained sensitivity, the fit is very close. Reality 1: Spencer 0.
Cherry-picking season
Spencer’s second figure reflects a more classic fallacy. The cherry pick.
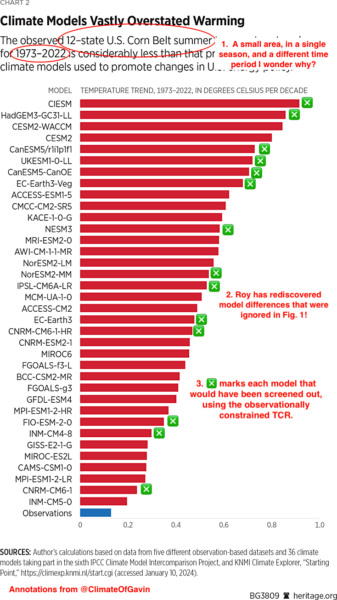
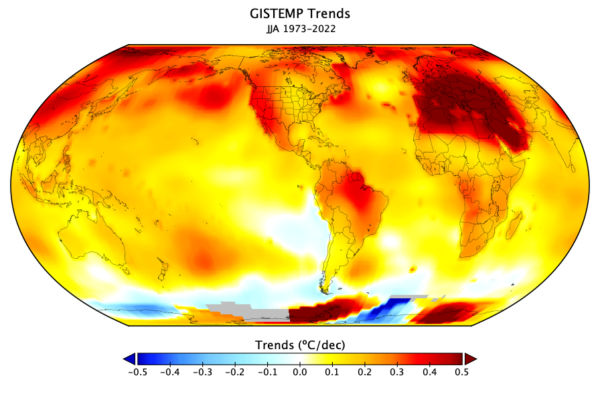
In this comparison, it suits Spencer’s purpose to include individual models, basically because he’s skewed the playing field. Why is this only showing summer data, for 12 US states (I think Iowa, Illinois, Indiana, Michigan, Ohio, Nebraska, Kansas, Minnesota, Missouri, South Dakota, North Dakota, and Wisconsin) and for the odd time period of 1973-2022? What about other seasons and regions? [Curiously, 14 out of the 36 models shown would have been screened out by the approach discussed in our Nature commentary]. We can perhaps gain some insight by plotting the global summer trends from GISTEMP (though it doesn’t really matter which observational data set you use). In that figure, you can see that there is minimum in the warming just to the south and west of the Great Lakes – corresponding pretty exactly to the region Spencer selected. The warming rate there (around 0.12ºC/dec) is close to the minimum trend for northern mid-latitudes and and half of what you would have got for the Pacific North West, or the South West, let alone anywhere in Europe! Therefore it’s the spot most conducive to showing the models overstating warming – anywhere else would not have had the same impact. Reality 2: Spencer 0.
Back to the future
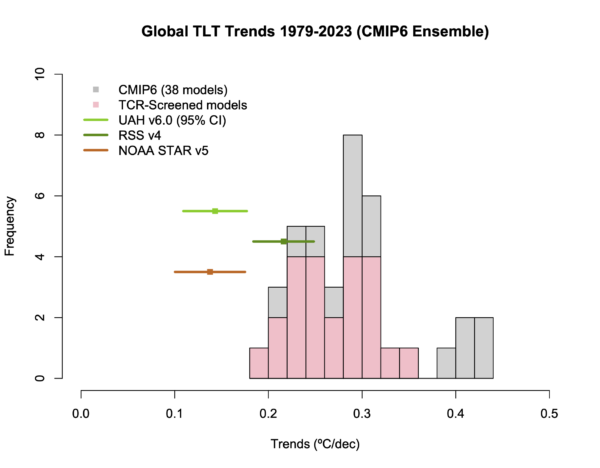
Spencer’s third figure is a variation on an old theme. Again, there is no indication that there is a spread in the models, only limited spread in the observations, and no indication that there is an appropriate selection to be made.
A better comparison would show the model spread, have a less distorting baseline, and show the separate TLT datasets. Something like this perhaps:
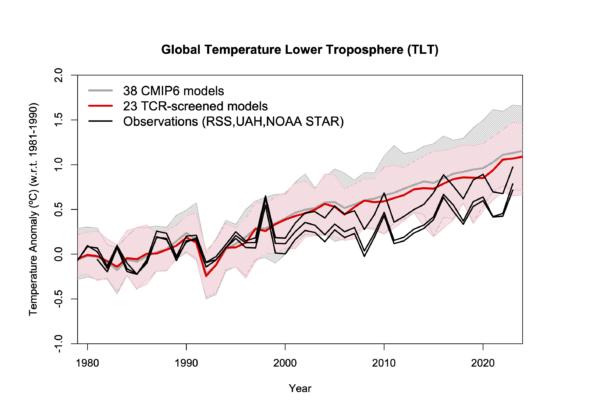
Now, this is the exact same model data that Spencer is using (from McKitrick and Christy (2020) (though the screening uses the TCR from our paper), and updated TLT satellite data. This does show a larger discrepancy than at the surface (and only a minor improvement from the screening) suggesting that there is something a bit different about the TLT metric – but far less than Spencer implies. So, Reality 3: Spencer 0.
Bottom lines
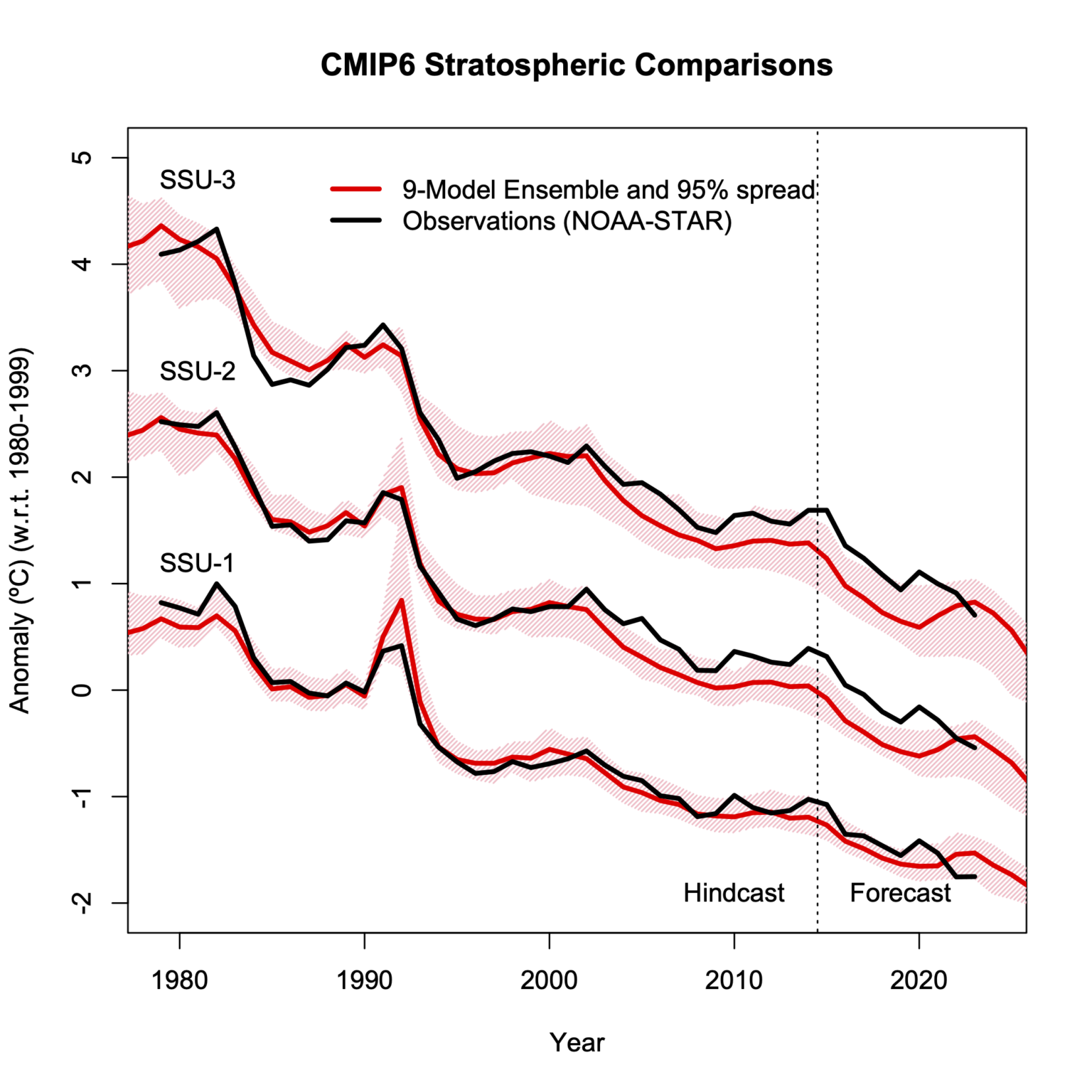
One final point. I don’t criticize Spencer (and Christy before him) because of any tribal or personal animosity, but rather it is because appropriate comparisons between models and observations are the only way to see what we need to work on and where there are remaining problems. The key word is ‘appropriate’ – if that isn’t done we risk overfitting on poorly constrained observations, or looking in the wrong places for where the issues may lie. Readers may recall that we showed that a broader exploration of the structural variations in the models (including better representations of the stratosphere and ozone effects, not included in the McKtrick and Christy selection), can make a big difference to these metrics (Casas et al., 2022).
Spencer’s shenanigans are designed to mislead readers about the likely sources of any discrepancies and to imply that climate modelers are uninterested in such comparisons – and he is wrong on both counts.
Postscript [1/31/2024] Spencer has responded on his blog and seems disappointed that I didn’t criticize every single claim that he made, but only focused on the figures. What can I say? Time is precious! But lest someone claim that these points are implicitly correct because I didn’t refute them, here’s a quick rundown of why the ones he now highlights are wrong as well. (Note that there is far more that is wrong in his article, but Brandolini’s law applies, and I just don’t have the energy). Here goes:
- 1.1 He agrees with me.
- 1.2 Spencer’s new graph shows that the observations are not distinguishable from the screened model ensemble. Which is what I said.
- 1.3 Spencer is backtracking from his original claim that models overpredict warming to now saying that only that the SAT observations are near the lower end of the model spread. Sure. But the SST observations are nearer the higher end. Does that mean that the models underpredict? Or does it mean that there is noise in the comparisons from multiple sources and expecting free running
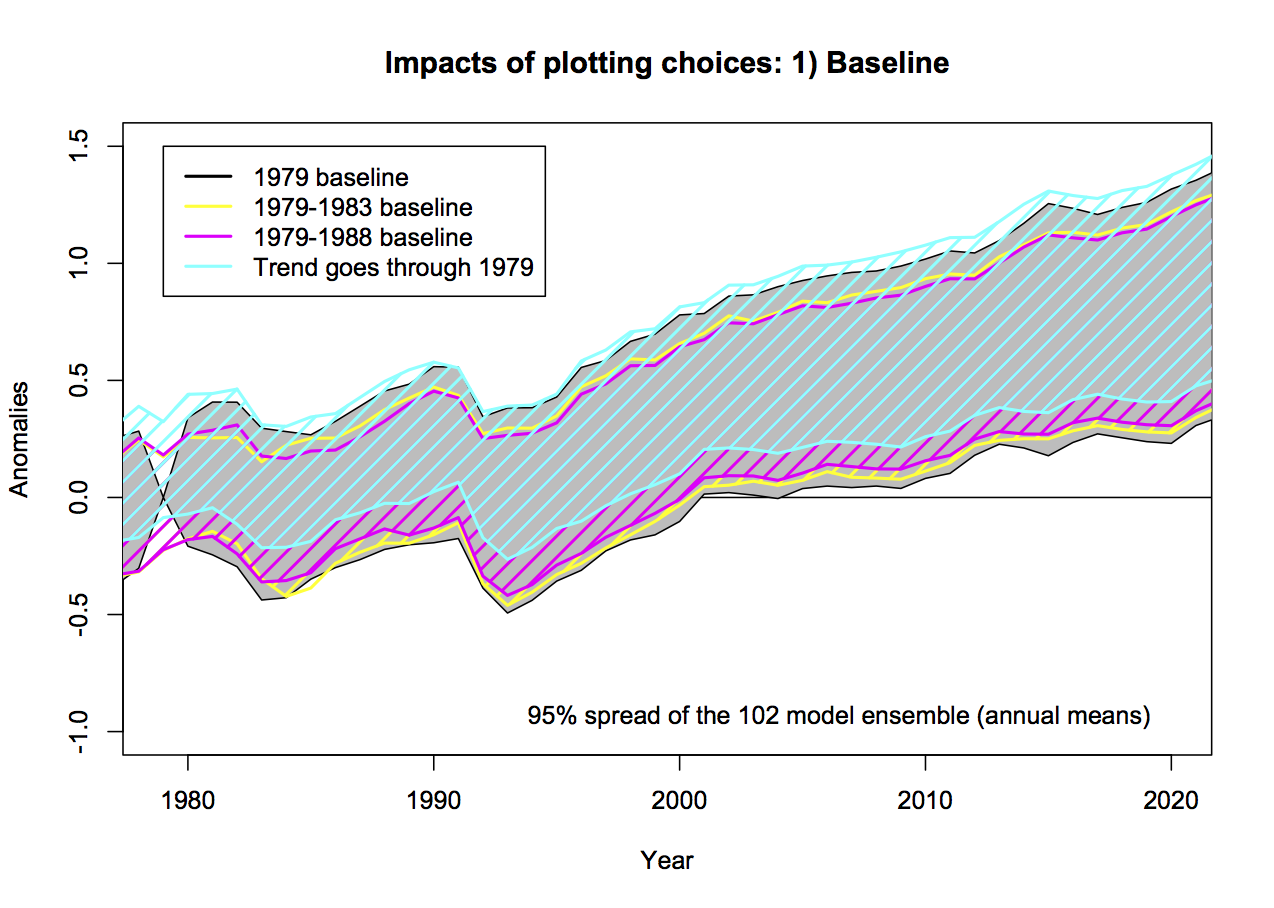
models with their own internal variability to perfectly match all observations would be overfitting? - 1.4 Quantitative trends don’t depend on baselines of course, but aligning the curves so that the trends to all have the same starting point in 1979 maximises the visual discrepancy. This leads to an incoherent y-axis (bet you can’t describe it succinctly!) and errors like in point 1.1. If Spencer just wanted to show the trends, he should just show the trends (and their uncertainty)!
{kind=link}
{kind=link}
- 2.1 Spencer is pretending here to be uniquely concerned about agriculture to justify his cherry-picking. I’ll happily withdraw my suggestion that this is just a cover for finding somewhere with lower warming when he does a weighted average of all soy or corn growing regions worldwide. I’ll wait.
- 3.1 After claiming that baselines don’t matter in 1.4, my choice in fig 3 above is ‘untrustworthy’ because it contextualizes the discrepancy Spencer wants to exaggerate. But again, if you want to just show trends, just show trends.
- 4. A claim that the observed EEI could be natural (without any actual evidence) is just nonsense on stilts. The current energy imbalance is clear (via the increases in ocean heat content) and accelerating, and is totally incompatible with internal variability. It additionally cannot be due to solar or other natural forcings because of the fingerprint of changes in the stratosphere.
- 5. Constraints on climate sensitivity are not determined from what the models do, but rather on multiple independent lines of observational evidence (historical, process-based and via paleo-climate). We even wrote a paper about it.
- 6. Do climate models conserve mass and energy? Yes. I know this is be a fact for the GISS model since I personally spent a lot of time making sure of it. I can’t vouch for every single other model, but I will note that the CMIP diagnostics are often not sufficient to test this to a suitable precision – due to slight mispecifications, incompleteness, interpolation etc. Additionally, people often confuse non-conservation with the drift in, say, the deep ocean or soil carbon, (because of the very long timescales involved) but these things are not the same. Drift can occur even with perfect conservation since full equilibrium takes thousands of years of runtime and sometimes pre-industrial control runs are not that long. The claim in the paper Spencer cited that no model has a closed water cycle in the atmosphere is simply unbelievable (and it might be worth exploring why they get this result). To be fair, energy conservation is actually quite complicated and there are multiple efforts to improve the specification of the thermodynamics so that the models’ conserved quantities can get closer to those in the real world, but these are all second order or smaller effects.
{kind=link}
Hopefully Roy is happy now.
References
- Z. Hausfather, K. Marvel, G.A. Schmidt, J.W. Nielsen-Gammon, and M. Zelinka, "Climate simulations: recognize the ‘hot model’ problem", Nature, vol. 605, pp. 26-29, 2022. http://dx.doi.org/10.1038/d41586-022-01192-2
- R. McKitrick, and J. Christy, "Pervasive Warming Bias in CMIP6 Tropospheric Layers", Earth and Space Science, vol. 7, 2020. http://dx.doi.org/10.1029/2020EA001281
- M.C. Casas, G.A. Schmidt, R.L. Miller, C. Orbe, K. Tsigaridis, L.S. Nazarenko, S.E. Bauer, and D.T. Shindell, "Understanding Model‐Observation Discrepancies in Satellite Retrievals of Atmospheric Temperature Using GISS ModelE", Journal of Geophysical Research: Atmospheres, vol. 128, 2022. http://dx.doi.org/10.1029/2022JD037523
Even if we just focus on the cornbelt region we already have a pretty good idea of why modeled temperature changes diverge from observations in this region.
Mueller et al. 2016 DOI 10.1038/nclimate2825 Cooling of US Midwest summer temperature extremes from cropland intensification
Lin et al. 2017 DOI 10.1038/s41467-017-01040-2 Causes of model dry and warm bias over central U.S. and impact on climate projections
Alter et al. 2018 DOI 10.1002/2017GL075604 Twentieth Century Regional Climate Change During the Summer in the Central United States Attributed to Agricultural Intensification
Zhang et al. 2018 DOI 10.1002/2017JD027200 Diagnosis of the Summertime Warm Bias in CMIP5 Climate Models at the ARM Southern Great Plains Site
Qian et al. 2020 DOI 10.1038/s41612-020-00135-w Neglecting irrigation contributes to the simulated summertime warm-and-dry bias in the central United States
Coffel et al. 2022 DOI 10.1029/2021GL097135 Earth System Model Overestimation of Cropland Temperatures Scales With Agricultural Intensity
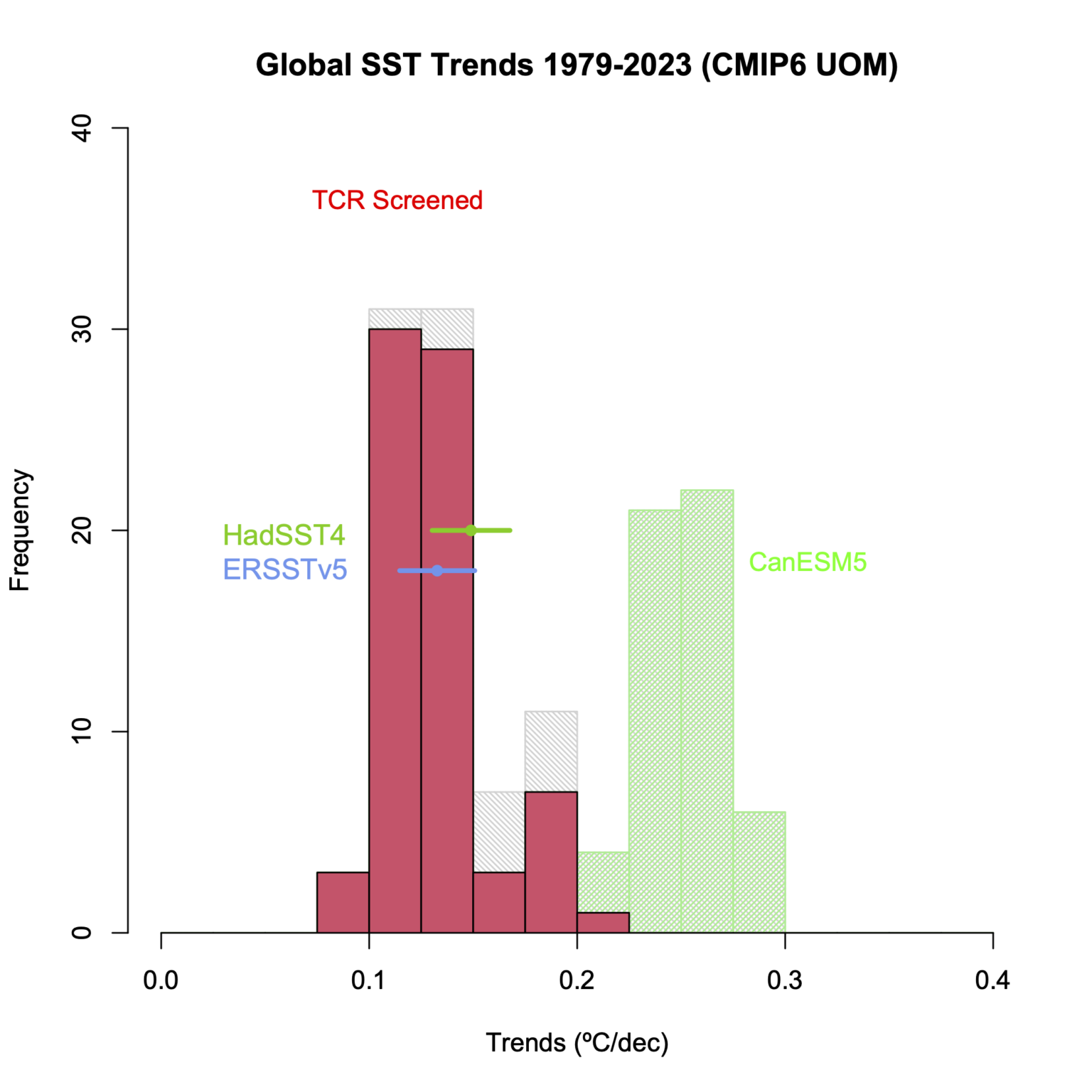
With respect to TLT for Spencer’s third figure, one can also look at the “State of the Climate in 2022” report that gives trends for 1979-2022. It provides values for the individual radiosonde and satellite analyses, along with individual reanalyses, capturing more of the structural uncertainty. Trends varied between 0.13°C/decade – 0.22°C/decade:
https://archive.is/TzabL
https://archive.is/f0j3C
[https://web.archive.org/web/20240113071904/https://ametsoc.net/sotc2022/SOTC2022_FullReport_final.pdf]
There’s a decent chance the satellite-based MSU analyses that Spencer cites are underestimating warming. For example:
“These concerning numbers support the hypothesis that corresponding MSU trend estimates are likely too small5,10,38. For the tropical upper troposphere as an example, MSU trend estimates are smaller by approximately a factor of two compared to GNSS RO (see Supplementary Fig. S1). The MSU measurements contain averaged information for a broad height layer, including regions with smaller temperature changes5. Part of the underestimation by MSU can also be explained by drifting orbits38.”
https://doi.org/10.1038/s41598-023-28222-x
The question to put to Spencer and those who support his views is: what climate models are you using, and what do they predict for future temperature trends? Then they would be doing real science: putting forward hypotheses that could actually be falsified.
Spencer’s approach is about as empirical as one can get short of the USCRN, which unfortunately is short and only covers the U.S. His approach is far more rational than than asking what model he is using. The less modeling the better in the real world!!!
Spoken like a man who has never done science. I suspect the “dr” is short for “durr…” rather than doctor.
“The less modeling the better in the real world!!!”
Why do you say that? Accurate models are how we come to understand and manipulate the world. You seem to be laboring under the misapprehension that temperature is “real”. The act of recording a temperature value itself is a model. for something far more complex (see Boltzmann).
As well, since illusions exist in every sense including touch it is trivial to show our brain isn’t showing us “reality”, it’s showing us a model of reality.
The very best science is when the models are very, very skilled and show us relationships we can use to understand–i.e., model–many more things.
Denial types–not making any statement about you unless you want it to apply–LUV to say, “It’s just a model/theory/whatever” thinking that somehow denigrates/debunks the science inherent in the statement*. What they are really showing is their complete ignorance about the depths of their scientific ignorance.
_______
*It’s happened in one of the active threads this one or the monthly variations thread just in the past few day or a week if I’m remembering correctly.
BTW, Boltzmann’s models are also [gasp on] models [gasp off].
Shorter version – if all you are doing is looking at data, you’re only seeing squirrels.
Re: “The question to put to Spencer and those who support his views is: what climate models are you using, and what do they predict for future temperature trends? Then they would be doing real science: putting forward hypotheses that could actually be falsified.”
Spencer once tentatively put forward predictions for a bet in September 2013, as did Patrick Michaels. Their predictions contrast with those from the IPCC’s 2007 Fourth Assessment Report and climate models in CMIP5:
“Dr. Michaels is betting on no statistically significant warming (at the 95% confidence level) in the HadCRUTx data for the 25 year period starting in 1997. Scott is betting on at least that much warming.
[…]
I’m also in discussions with Scott over betting on a trend that would be 1 standard deviation below the average model warming, which would be +0.162 deg. C/decade for 1997-2021, compared to the 90-model average of +0.226 deg. C/decade. He laid down the gauntlet, not me. I try not to forecast future temperatures…too much like betting on a roll of the dice.”
https://archive.ph/wB3pc#selection-157.0-157.357
“For the next two decades a warming of about 0.2°C per decade is projected for a range of SRES emissions scenarios [page 7].”
https://web.archive.org/web/20231218105205/https://www.ipcc.ch/site/assets/uploads/2018/02/ar4_syr_spm.pdf
page 45: https://web.archive.org/web/20230908172149/https://www.ipcc.ch/site/assets/uploads/2018/02/ar4_syr.pdf)
the modeled warming is projected from 2000, as shown on page 763 of: https://web.archive.org/web/20230605202129/https://www.ipcc.ch/site/assets/uploads/2018/02/ar4-wg1-chapter10-1.pdf
The IPCC and the CMIP5 models were correct, while both Michaels and Spencer were wrong. But instead of admitting that, Spencer just moved on to the next set of climate models he would distort: models in CMIP6. This is consistent with his pattern going back to at least 1997, where he misrepresented model-based projections from the IPCC’s 1990 First Assessment Report to avoid acknowledging those projections held up well:
– 1997-2020 HadCRUT5: 0.21°C/decade
– 1997-2021 ERA5: 0.23°C/decade
– 1997-2021 NASA’s GISTEMP: 0.21°C/decade
– 1997-2021 JRA-55: 0.16°C/decade
– 1997-2021 Berkeley Earth: 0.20°C/decade
– 1997-2021 NOAA: 0.21°C/decade
https://archive.is/tCHMh#selection-873.0-885.9
https://archive.is/INEBB#selection-881.0-885.9
https://archive.is/XHDPF#selection-873.0-885.9
data source:
https://psl.noaa.gov/data/atmoswrit/timeseries/
[ https://doi.org/10.1175/BAMS-D-13-00192.1 ]
CMIP5 comparison:
https://www.realclimate.org/index.php/climate-model-projections-compared-to-observations/
Spencer on the IPCC’s 1990 report:
https://www.realclimate.org/index.php/archives/2024/01/spencers-shenanigans/#comment-818864
@ July 2023
In the 18 years between the 1997-98 and 2015-16 El Ninos, global temperature increased 0.43°C,
thus at rate of 0.24°C per decade, larger than the 1970-2010 global warming rate (0.18°C/decade),
see Fig.5 Edges of the predicted post-2010 accelerated warming rate (see text) are 0.36 and 0.27°C per decade.
In that case, the 2023-24 temperature curve (red curve in Fig. 4) is likely to fall substantially above the
(green) curve for the prior El Nino and may set new global temperature records continually during
the next 12 months. It seems that we are headed into a new frontier of global climate.
http://www.columbia.edu/~jeh1/mailings/2023/ClimateDice.13July2023.pdf
@ Jan 2024
A declining strength of the El Ninos only enhances our conclusions.
How do we know global temperature will continue to grow in the next 5-8 months, carrying the 12-
month running-mean to at least 1.6-1.7°C? The main reason is the large increase of global absorbed
solar radiation (ASR) since 2015 (Fig. 4), which is a decrease of Earth’s albedo (reflectivity) by
0.4% (1.4/340).9
This reduced albedo is equivalent to a sudden increase of atmospheric CO2 from
420 to 530 ppm.
http://www.columbia.edu/~jeh1/mailings/2024/AnnualT2023.2024.01.12.pdf
That Spencer is out of kilter biased or wrong does not make everyone else right on the really critical issues at hand.
Re: “In the 18 years between the 1997-98 and 2015-16 El Ninos, global temperature increased 0.43°C, thus at rate of 0.24°C per decade, larger than the 1970-2010 global warming rate (0.18°C/decade)”
You only get that if you put a strong El Niño year at the end, but not at the beginning, of a short trend such as 1999-2016:
– 1999-2016 ERA5: 0.24°C/decade
– 1999-2016 NASA’s GISTEMP: 0.23°C/decade
https://archive.is/5xIfV#selection-873.0-885.9
That’s as misleading as placing a strong El Niño at the beginning, but not the end, of a short trend, as occurred with all the nonsense on a supposed ‘pause’/’hiatus’ in warming. Spencer misleadingly minimizing warming is not an excuse to then exaggerate warming in that manner.
“We find that the public discussion of time intervals within the range 1998–2014 as somehow unusual or unexpected, as indicated by terms like ‘hiatus’, ‘pause’ and ‘slowdown’, has no support in rigorous study of the temperature data. Nor does recent talk of sudden acceleration based on three record-hot years in a row and the exceptional value in 2016.”
https://doi.org/10.1088/1748-9326/aa6825
“The denialists really like to fit trends starting in 1997, so that the huge 1997-98 ENSO event is at the start of their time series, resulting in a linear fit with the smallest possible slope.”
https://archive.is/BslvQ#selection-385.448-390.0
“Trends starting in 1997 or 1998 are particularly biased with respect to the global trend. The issue is exacerbated by the strong El Niño event of 1997–1998, which also tends to suppress trends starting during those years*”
https://doi.org/10.1002/qj.2297
Reply to Atomsk’s Sanakan
Thanks for the response. You are equating James Hansen el al scientific work and commentary to climate science deniers. In twisting both what he has said in the referenced article along with his clear and obvious intentions.
I am quite content accepting Hansen’s work at face value and looking at that objectively without your faulty and unfounded characterizations getting in my way. I am not interested in ’tilting at windmills of the mind’. Thanks anyway. My apologies for the interruption.
Lavrov’s Dog: “That Spencer is out of kilter biased or wrong does not make everyone else right on the really critical issues at hand.”
Well, no. But those who aren’t working, publishing members of the peer community of climate specialists, don’t know anything more than the consensus of those who are. If there’s no strong consensus, scientifically meta-literate non-experts will reserve judgement!
Lavrov’s Dog: “You are equating James Hansen el al scientific work and commentary to climate science deniers.”
Take it easy, my dog! Climate scientists who publish claims that are more alarming than the consensus of their peers, may at a minimum be denying the principle of least drama. If you’re easily offended by criticism of Hansen’s claim of accelerated warming, then you don’t have a career in peer-reviewed science.
Nothing in your reply cogently addresses what I said, nor the research cited to you. Again, it’s misleading to claim an acceleration (or deceleration) in warming by comparing a longer multidecadal time-period to a much shorter time-period of less than two decades that is cherry-picked to end in a strong El Niño year without an El Niño near the beginning (or begin in a strong El Niño year without an El Niño near the end). For example, it’s selection bias with use of a broken trend, consistent with the 2nd link below. One shouldn’t have a double-standard and motivated reasoning on acceleration vs. deceleration.
The material is there for you to read, if and when you want to see sound methods for detecting statistically significant accelerations or decelerations in warming.
“In addition, our nuanced analysis gives much needed rigor to the claim that using 1998 as a reference year amounts to “cherry picking” (Leber 2014; Stover 2014), see also Supplemental Section for detailed discussions).”
https://doi.org/10.1007/s10584-015-1495-y
https://doi.org/10.1088/1748-9326/aaf342
https://doi.org/10.1029/2021GL095782
https://tamino.wordpress.com/2019/11/08/global-temperature-update-6/
https://tamino.wordpress.com/2020/01/22/is-the-apparent-recent-acceleration-in-temperature-significant/
I think there might be some confusion. Hansen *is* going from strong El Niño to strong El Niño here.
http://www.columbia.edu/~jeh1/mailings/2024/AnnualT2023.2024.01.12.pdf
Looks like this article is straight from the Tobacco Institute files. Hits about every tenet of the syllabus of Propaganda 101.
I’ve worked with stats all my adult life. I’ve never understood the minds of propagandists. It just doesn’t make any human sense.
Sadly, prostituting judgment in the service of desire is all too human.
Thanks for attempting to keep the deniers honest. A truly Sisyphean task.
I wonder how much irrigation water had to be pumped in order to bring about what the reported record U.S. corn crop in 2023.
Enough to make a contribution:
https://www.scientificamerican.com/article/rampant-groundwater-pumping-has-changed-the-tilt-of-earths-axis/
Thank you for that reply.
Also discussed on Scott Simmons’ excellent blog:
https://woodromances.blogspot.com/2024/01/roy-spencer-on-models-and-observations.html
Il faut imaginer Sysyphe heureux.
Hi Gavin,
All of this is utterly useless handwaving unless you can show us scientifically that all this warming is causing any real harm, and not only causing real harm, but also showing what the “optimal” temperature truly is.
Is the optimal temperature the early 1800’s when the life expectancy was roughly 30-40 years?
https://ourworldindata.org/life-expectancy#:~:text=Key%20Insights%20on%20Life%20Expectancy&text=In%202021%2C%20the%20global%20average,expectancy%20higher%20than%2040%20years.
Is the optimal temperature the early 1900’s when we had the dust bowl and the great depression?
https://en.wikipedia.org/wiki/Dust_Bowl
Is the optimal temperature in the 1300’s to 1400’s when the black death decimated about 50% of Europe’s population?
https://www.history.com/topics/middle-ages/black-death
Do tell, Gavin, what is the optimal temperature for human thriving, and how do we turn that knob down when we get to cold? Speaking of cold, you do know that around 4-8X (depending on the source) more people die of cold than heat globally each year? When is that going to start shifting? After all, more people die of flu, covid, pneumonia during winter WHEN IT’S COLD than in the summer WHEN IT’S HOT.
https://www.demographic-research.org/articles/volume/37/45/
After all, we had a huge spike in global temps the past few months, so now is your time to shine! Y’all warned us this would happen, and here it is! We hit a new record! So now where are the catastrophes? Right around the corner? Just a little…bit…more….time….
Why don’t you come with me on my next medical trip to Africa and find out how fossil fuels have saved millions from starvation, freezing, and ignorance. There’s some mighty perspective for ya.
Scott: – “All of this is utterly useless handwaving unless you can show us scientifically that all this warming is causing any real harm, and not only causing real harm, but also showing what the “optimal” temperature truly is.”
Back again for another regurgitation of more climate science denying memes, aye Scott?
https://www.realclimate.org/index.php/archives/2023/11/science-denial-is-still-an-issue-ahead-of-cop28/#comment-816745
2023 shattered climate records, with major impacts.
https://wmo.int/news/media-centre/2023-shatters-climate-records-major-impacts
Extreme weather events are the top risk facing supply chains in 2024, according to an annual outlook report from Everstream Analytics.
https://www.supplychaindive.com/news/extreme-weather–top-supply-chain-risk-2024-everstream-climate-change-food-shortages/704232/
What are the odds that extreme weather will lead to a global food shock? A 2023 report by insurance giant Lloyd’s explored the odds of such a scenario. The report looked at “major,” “severe,” and “extreme” scenarios. The “major” case would cost the world $3 trillion over a five-year period, which they estimated has a 2.3% chance of happening per year. Over a 30-year period, those odds equate to about a 50% probability of occurrence. It get worse for the “severe” and “extreme” cases.
The caption for Figure 4 includes:
https://yaleclimateconnections.org/2024/01/what-are-the-odds-that-extreme-weather-will-lead-to-a-global-food-shock/
It seems global undernourishment is on the rise…
Global food production is at risk as rising temperatures threaten farmers’ physical ability to work, a new study finds.
https://phys.org/news/2024-01-global-food-production-temperatures-threaten.html
Scott: – “Is the optimal temperature the early 1800’s when the life expectancy was roughly 30-40 years?”
Did humanity have access to antibiotics then, Scott? Nope. The first antibiotic, salvarsan, was deployed in 1910 (I didn’t know that until now). In just over 100 years antibiotics have drastically changed modern medicine and extended the average human lifespan by 23 years.
https://doi.org/10.1016/j.mib.2019.10.008
And vaccines? Per the 2014 PNAS paper by Rino Rappuoli titled Vaccines: Science, health, longevity, and wealth, included:
https://doi.org/10.1073/pnas.1413559111
But you should already know this as a physician, surely Scott? So why propagate the bogus narrative, aye Scott?
To answer your question, I’d suggest the optimum global mean surface temperature for humanity is what has been experienced by humanity in the stable Holocene period (i.e. zero to +0.5 °C global mean surface temperature, relative to the 1850-1900 baseline), when agriculture and civilisation became established and then developed.
Every °C above the 1850-1900 baseline global surface temperature represents of the order of about 10 to 20 metres of sea level rise (SLR) above the highly stable Holocene global mean sea level baseline (at equilibrium, which would take centuries to millennia to stabilize). Glaciologist Prof Jason Box said: “…we’ve committed already to more than 20 metres of sea level rise.”
https://www.realclimate.org/index.php/archives/2023/08/the-amoc-tipping-this-century-or-not/#comment-813939
Unless the planet now begins to cool, SLR is unstoppable and will change every coastline. Do you have any interest in any coastal real estate, aye Scott?
https://oceanservice.noaa.gov/hazards/sealevelrise/sealevelrise-tech-report.html
Per the IPCC, coral reefs would decline by 70-90% if average global air temperatures warm by +1.5 °C (2.7 °F) above pre-industrial values. That number jumps to a 99% decline at +2 °C (3.6 °F) of warming. While they cover less than 1% of the ocean floor, healthy coral reefs provide homes to approximately a quarter of all known marine species.
https://climate.nasa.gov/explore/ask-nasa-climate/3273/vanishing-corals-part-one-nasa-data-helps-track-coral-reefs/
So sea food will likely become scarce and unaffordable for many…
But I’d not be at all surprised you may well argue that this is all ‘hand waving’ or “irrelevant”, aye Scott?
It seems to me we don’t have long to wait for breaching the +1.5 °C multi-year global mean temperature threshold (2028 perhaps?).
https://climatecasino.net/2024/01/how-hot-is-hell/
That’s when I’d suggest it starts to get really interesting (and not in a good way)!
Have you looked at any of the papers previously cited for you yet? Your comments suggest that the answer is “no.”
And if not, why should I (or anyone else) repeat the exercise?
But if you are actually interested, and not simply indulging your preconceptions ad infinitum, you could always start with the bibliography here:
https://www.ipcc.ch/report/ar6/wg2/downloads/report/IPCC_AR6_WGII_Chapter07.pdf
Hi Kevin,
I’ve looked at that reference thoroughly. Thanks though.
You’re welcome. But how is “looking thoroughly” consistent with your implied denial that “all this warming is causing any real harm?”
Since you mention Africa, let’s take as example the papers cited in regard to the malaria burden there: M’bra et al (2018); Caminade et al (2019); Gibb et al (2020); Tompkins and Caporaso (2016b); and Ebi et al (2021a). Looked at any of those, have you? Doesn’t matter presently, as I’m about to.
[Off to the chapter bibliography… reads… ]
M’bra et al: https://pubmed.ncbi.nlm.nih.gov/29897901/
Nutshell: Warming actually decreases malaria burden, but precipitation increases it, and probably is a considerably stronger effect. A measure of “greening”, the NDVI is also very strongly associated with increased malarial burden. So climate change will increase malarial burden in some places, but not where it results in aridification. (Of course, some might say that that’s a bit of a Hobson’s choice between two evils.)
Caminade et al: https://pubmed.ncbi.nlm.nih.gov/30120891/
Paywalled, and the abstract isn’t as informative as one would wish. “Our review highlights significant regional changes in vector and pathogen distribution reported in temperate, peri-Arctic, Arctic, and tropical highland regions during recent decades, changes that have been anticipated by scientists worldwide. Further future changes are likely if we fail to mitigate and adapt to climate change.”
Sounds worrisome, but you’d have to access the paper itself to really know.
Gibb et al: https://www.nature.com/articles/s41586-020-2562-8
Nutshell: Human-managed landscapes have higher risks of zoonotic disease than relatively undisturbed ecosystems. (A conclusion not really relevant to current issue–although land use certainly affects climate, and vice-versa. Quite possibly there’d be relevant points if you read the whole paper.)
Tompkins and Caporaso: https://pubmed.ncbi.nlm.nih.gov/27063732/
Nutshell: Modeling results are inconclusive, with 3 ESMs finding limited impact, while the fourth saw:
“…more intense transmission and longer transmission seasons in the southeast of the continent, most notably in Mozambique and southern Tanzania. In contrast, warming associated with LUC in the Sahel region reduces risk in this model, as temperatures are already above the 25-30°C threshold at which transmission peaks.”
That’s reminiscent of the first study examined.
Ebi et al: https://iopscience.iop.org/article/10.1088/1748-9326/abeadd
This one actually looks at global risk. “Recent climate change has likely increased risks from undetectable to moderate for heat-related morbidity and mortality, ozone-related mortality, dengue, and Lyme disease. Recent climate change also was assessed as likely beginning to affect the burden of West Nile fever. A detectable impact of climate change on malaria is not yet apparent but is expected to occur with additional warming. The risk for each climate-sensitive health outcome is projected to increase as global mean surface temperature increases above pre-industrial levels, with the extent and pace of adaptation expected to affect the timing and magnitude of risks.”
So, increased malaria risk is, per them, not yet observed; but the contrary is true for “heat-related morbidity and mortality, ozone-related mortality, dengue, and Lyme disease.” I’d consider that to be “real harm.”
FWIW, let me quickly list the other areas of concern tabulated in the figure:
Dengue, with Asia the most affected: Negative impacts
Diarrhoeal diseases, Asia: Mixed impacts
Salmonella, Africa: Negative impacts
Respiratory Tract infections, Asia: Mixed impacts
Non-communicable respiratory illness, Asia: Negative impacts
Cardiovascular disease, Asia: Negative impacts
Fatal malignant neoplasms, Asia: Negative impacts
Diabetes, Asia: Negative impacts
Thermal exposure (heat/cold), Asia: Negative impacts
Nutritional deficiency, Africa: Negative impacts
Altogether:
That’s the current ‘background’ level, so it’s not by itself evidence of current climate-related harm. But it does show that the potential for very large harm indeed is there.
Were you able to read any of the actual words? Do you need help with that? A grown up? A policeman?
S: Do tell, Gavin, what is the optimal temperature for human thriving
BPL: The 287 K our entire agriculture and civilization developed in.
S: Why don’t you come with me on my next medical trip to Africa and find out how fossil fuels have saved millions from starvation, freezing, and ignorance.
BPL: You can do that with renewable energy, and more and more Africa is doing just that. In any case, we have to stop burning fossil fuels as soon as we can replace them, since they’re causing global warming, and global warming is likely to kill our agriculture. Then Africa will die along with the rest of us.
Are you suggesting he sails there?
Why not? Increasingly, modern cargo ships are installing sails to supplement their engines. If the power is free, why not use it?
Scott,
The negative correlation between GDP growth and rising temperatures is well established. Warming temperatures lower productivity. This has been known to economists for nearly a century. Even the FED branches are doing research to model the effects to come.
And 2023 was indeed a historic year for climate-related disasters in the US:
https://www.climate.gov/news-features/blogs/beyond-data/2023-historic-year-us-billion-dollar-weather-and-climate-disasters
You do know that you can look these things up yourself, right?
So maybe Scotty’s crank call and responses is one for the UV thread?
Scott,
This fallacy is so common it has a name. Denying the Antecedent. You did it twice.
Let P = [harm] and Q = [observations consistent with modeling]. You say not P therefore not Q which is denying the antecedent.
Let P = [existence of optimal value] and Q = [observations consistent with modeling]. You say not P therefore not Q which is denying the antecedent.
The fact is that models can be skillful in predicting temperatures without there being an optimal temperature and/or a harmful temperature.
Global warming is already costing us a lot of money in worsening heatwaves, droughts and floods. But get up towards 3 degrees and we really will see “catastrophes”. Remember the climate response is non linear – so above 1.5 deg c the Antarctic and Greenland ice sheets could collapse quite abruptly and SLR (sea level rise) will suddenly go up very fast.
Good Lord…NOT the old “What is the ‘optimal’ temperature for the Earth?” propaganda bromide again! Haven’t seen that one in probably 5 years and it was very dated even then.
Hint to scott: The ACTUAL question to be asking is, “What is the optimal RATE OF CHANGE in temps and other climate variables in any particular biome?” You see biomes develop in the context of a climate. Too fast a change in the climate and the biome ecology collapses one way or another.
For example, we appear in the process of greatly expanding grasslands/plains and greatly reducing forests in many areas. This is causing changes as it requres massive burnoffs and will cause rather large changes in the resulting biomes. Are you completely sure all of them are positive? Or even half?
Scott: – “All of this is utterly useless handwaving unless you can show us scientifically that all this warming is causing any real harm…”
ADDENDUM: Climate change has killed 4 million people since 2000 — and that’s an underestimate.
https://grist.org/health/climate-change-has-killed-4-million-people-since-2000-and-thats-an-underestimate/
Paywalled: https://www.nature.com/articles/s41591-023-02765-y
But I’d not be at all surprised you may well deny this as it’s inconvenient for your climate science denier narrative, aye Scott?
NOAA’s Coral Reef Watch has added a new risk level:
Bleaching Alert Level 5: Risk of Near Complete Mortality
https://twitter.com/LeonSimons8/status/1752734829227942335
Unless the planet now begins to cool, coral reefs are at high risk of becoming extinct in the coming decades.
https://theconversation.com/climate-tipping-points-are-nearer-than-you-think-our-new-report-warns-of-catastrophic-risk-219243
Losing coral reefs means losing homes to approximately a quarter of all known marine species.
https://www.nature.com/articles/s41598-023-37338-z
The 4 million deaths since 2,000 due to climate change is pure alarmist claptrap.
The total number of deaths due to all natural disasters is less than 50,000 a year. Since this includes earthquakes, volcanos etc. and weather related disasters have always occurred, and always will regardless of emissions, and yearly deaths are a fraction of what they were in the 1,930’s, 40’s, 50’s etc. the evidence completely fails to show that the small amount of, almost certainly natural, warming in the last 100 years has caused any additional deaths.
Matt Dalby: – “The 4 million deaths since 2,000 due to climate change is pure alarmist claptrap.”
IMO, like Scott, you are just another denier of reality…
Matt Dalby: – “The total number of deaths due to all natural disasters is less than 50,000 a year.”
And yet over 70,000 excess deaths occurred just in Europe during the summer of 2003., and an estimated 61,672 heat-related deaths occurred in Europe between 30 May and 4 September 2022.
https://www.nature.com/articles/s41591-023-02419-z
Heat-related deaths could more than quadruple by mid-century, per the 2023 report of the Lancet Countdown on health and climate change. Heat exposure may have led to 490 billion lost labour hours in 2022, up nearly 42% from the 1991 to 2000 period.
https://www.thelancet.com/infographics-do/climate-countdown-2023
Matt Dalby: – “…the evidence completely fails to show that the small amount of, almost certainly natural, warming in the last 100 years has caused any additional deaths.”
What evidence, Matt? You haven’t provided any; just your ill-informed opinion.
I’ve provided evidence that the number of deaths from natural disasters since 2,000 is way less than 4 million, so it’s no ill informed opinion.
I’m not denying reality because reality, backed up by the data I linked to, shows that climate change hasn’t caused 4 million deaths this century.
Please show, with actual data rather than mere claims, that about 1.2 degrees of warming in the last 100-150 years has led to an increase in deaths from natural disasters when http://www.ourworldindata.org/natural-disasters shows a massive decline in deaths.
I agree that there was a shockingly high number of excess deaths in Europe in summer 2023, , but excess deaths in most developed countries have been way above average every month since roughly mid 2021 when the majority of the population of these countries had been injected with experimental mRNA ‘vaccines’ against covid that were poorly tested, but this is a whole different discussion, although in the case of covid and climate change we were told to trust ‘the science’ although in both cases the science was based on unprovable computer models and even highly qualified scientists e.g. prof’s Sunetra Gupta of Oxford University and Jay Battachara were smeared and ridiculed for proposing an alternative to the ‘establishment view. I’m using this as an example of how any dissenting voice, including people like Dr Roy Spencer are attacked for not agreeing with the ‘consensus, whereas scientists should consider data or opinions that don’t fit in their views.
Matt Dalby (at 3 FEB 2024 AT 10:43 PM): – “I’ve provided evidence that the number of deaths from natural disasters since 2,000 is way less than 4 million, so it’s no ill informed opinion.
I’m not denying reality because reality, backed up by the data I linked to, shows that climate change hasn’t caused 4 million deaths this century.”
Um… What links, Matt? Your comments at 3 FEB 2024 AT 8:47 AM do not contain any links, and IMO just contains your statements of ill-informed denial.
Meanwhile, in my earlier comments in this thread I’ve provided links to:
1. Nature medicine Worldview paper by Colin J Carlson titled After millions of preventable deaths, climate change must be treated like a health emergency, published online 30 Jan 2024.
2. Nature medicine article by Joan Ballester et al. titled Heat-related mortality in Europe during the summer of 2022, published 10 Jul 2023.
3. Lancet Countdown on health and climate change infographic derived from The 2023 report of the Lancet Countdown on health and climate change: the imperative for a health-centred response in a world facing irreversible harms.
https://www.thelancet.com/journals/lancet/article/PIIS0140-6736(23)01859-7/fulltext
Matt Dalby (at 3 FEB 2024 AT 10:43 PM): – “Please show, with actual data rather than mere claims, that about 1.2 degrees of warming in the last 100-150 years has led to an increase in deaths from natural disasters when http://www.ourworldindata.org/natural-disasters shows a massive decline in deaths.”
Um… The discussion I initiated was about estimated deaths attributable to climate change, NOT about estimated deaths only from natural disasters. I’d suggest this is your attempt at a diversion with a straw man argument. Matt, did you actually read the Grist article that I linked to that refers to the then paywalled Nature medicine Worldview paper by Colin J Carlson, re climate change has killed 4 million people since 2000? An excerpt from the Carlson paper:
https://www.nature.com/articles/s41591-023-02765-y
Matt Dalby (at 3 FEB 2024 AT 10:43 PM): – “I agree that there was a shockingly high number of excess deaths in Europe in summer 2023…”
…and in Europe during the summer of 2003, with over 70,000 excess deaths, long before COVID emerged. And this is just in Europe, a relatively small part of the whole world. Therefore, when extrapolating for the rest of the world, you know, bigger places like Africa, South America, Asia, etc., and including all other contributing factors, like malaria and malnutrition, etc., it seems to me that 166,000 deaths per year is plausibly an underestimate.
Matt Dalby (at 3 FEB 2024 AT 10:43 PM): – “I’m using this as an example of how any dissenting voice, including people like Dr Roy Spencer are attacked for not agreeing with the ‘consensus, whereas scientists should consider data or opinions that don’t fit in their views.”
Matt, really? Conspiracy theories are not science!
“An emergent scientific truth, for it to become an objective truth; a truth that is true, whether or not you believe in it; it requires more than one scientific paper. It requires a whole system of people’s research all leaning in the same direction, all pointing to the same consequences. That’s what we have with climate change, as induced by human conduct. This is a known correspondence.”
“What will it take for people to recognize that a community of scientists are learning objective truths about the natural world and that you can benefit from knowing about it.”
– US astrophysicist Neil deGrasse Tyson in 2019
https://www.realclimate.org/index.php/archives/2023/07/back-to-basics/#comment-813512
What will it take for you, Matt?
Matt Dalby:
Your data is numerically correct, but are comparing “apples and oranges”. The study posted by Geoff stating climate change had killed 4 million people since 2000 is based on heat, diarrhea, malaria, and malnutrition. This is important as diarrhrea kills 1.5 million people annually so climate change only has to have a small effect on diarrhea to kill a lot of people. Please read the study.The numbers you posted claiming only around 1 million have been killed by natural disasters since 2000 are based on natural disaster including earthquakes, volcanoes, storms and floods but excluding disease and malnutrition and heat. Two different things.
The excess deaths since 2021 cannot be explained by MRNA covid vaccines. The following investigation on NZ shows the MRNA vaccines only killed a very small number of people (4) since 2021. Please note excess deaths were highest in 2020, before vaccines were introduced. The real reason for the deaths in the heatwaves was the heatwave made worse by anthropogenic global warming.
https://www.thepost.co.nz/nz-news/350124156/claims-excess-deaths-related-vaccine-labelled-nonsense
Nature doesn’t publish “pure alarmist claptrap” that I’ve noticed.
So, I guess we must ask:
a. Exactly how do you disagree?
b. Have your ruminations been subjected to peer review?
BTW: It’s not paywalled to me, at least, though I have university access when needed. Just did NOT here.
“Why don’t you come with me on my next medical trip to Africa and find out how fossil fuels have saved millions from starvation, freezing, and ignorance. ”
Beacuse I am not pleased with the prospect of tropical diseases migrating poleward as temperatures rise. : dengue put me in hospital the last time i went to West Africa, and I don’t at all care to risk a replay.
There’s an old pilot book chantey that runs:
Beware and take care of the Bight of Benin
For one that comes out, there’s twenty goes in.
Claims of tropical diseases migrating poleward are alarmist claptrap.
As one example look at malaria. Until the bungled global response to covid malaria deaths were declining despite population increasing, fastest in developing tropical countries where malaria is still endemic.
In 1,900 malaria was endemic in most of Europe, non Arctic Russia parts of the US etc. where it’s rarely if ever found today.
http://www.ourworldindata.org/malaria
In sure the data for other tropical diseases, if anyone looks, would also show no poleward spread.
The crows who died of West Nile virus might disagree, but hey, this sort of idiocy is what you get when you think anecdotes constitute proof.
It’s not an anecdote, it’s real, clear data. If you can’t understand this it’s your problem.
Matt, it’s not the data that’s the problem, it’s your inability to interpet it.
1) Your source shows malaria increasing to the mid-2000s, contrary to your claim.
2) Global rates increasing or decreasing say nothing about the poleward shift you are trying to rebut, anyway.
3). Don’t you think that maybe decades of mosquito suppression, public healtth efforts of all sorts, and improved therapies have a little something to do with those trends?
Some actual researchers actually HAVE looked and their work has been examined by other experts for at least obvious scientific errors. They appear to see more clearly than your non-researched and non-peer reviewed pejorative assessment it seems… https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7373693/
There are many more such studies of poleward drift in many different phenomena. For example, where I sail in the North Atlantic @ 47N, tropical giant molas are becoming more and more common in summers. Hurricane tracks are moving measurably poleward. Other phenomena as well.
Please explain why you think http://www.ourworldindata.org is an unreliable source of information. You’ve referenced anecdotal observations about a few species of this in response to a comment on tropical diseases back up with actual data. How pathetic is this?
If you can disagree, with actual scientific data, with the point I made I might take you seriously.
I gave you a peer reviewed ref. Peer-reviewed research is well available on hurricane tracks and poleward drift of many phenomena. Many of these articles have been discussed here in the past. If you are unfamiliar with them that is your problem.
Stats sites are valuable, but they are not generally geared towards fundamental research. into models and mechanisms For that you need to go to the research literature.
To give one example, I once worked on a year long grant to analyze a rather gigantic US database. ALL the stats were given to us up front. It still took out whole team of 4 PhDs most of said year to get all the stats cleaned and fully aligned such that actual research could be done on the raw stats. The analyses took a couple of weeks and then writing took a couple of months. But in NO wise at all could we have looked at the raw stats and made any scientific sense out of them at all.
Your ignorance of what science actually involves is showing again.
MD: Claims of tropical diseases migrating poleward are alarmist claptrap.
BPL: Then why do we now have dengue fever in Texas–and for that matter, how did kudzu reach Ontario?
Oh dear…will Richter’s still sell kudzu seeds then???!!!
No, Matt, it is not Data. Data is pluiral. Datum is singular. And moreover, it is a datum that you do not understand. Do you think that the decrease in malaria just happened spontaneously?
I don’t think the construction of experimental and quasi-experimental designs is his forte given his assertions, Ray.
Actually spent 2 years near the Bight of Benin and emerged unscathed. And Dengue is already here at least in the US South. And what scares me more are paleoviruses thawing out of the permafrost and migrating Equatorward.
Well, thankfully we have economists to sort that out.
https://www.sciencedirect.com/science/article/pii/S0301421523005074
The effects seem to start from a range starting with a negative figure.
Ah, Richard Tol, the “economist”. Is that what the kids are calling fossil fuel shills now?
“Grain yield declined by 10% for each 1°C increase in growing-season minimum temperature in the dry season, whereas the effect of maximum temperature on crop yield was insignificant. This report provides a direct evidence of decreased rice yields from increased nighttime temperature associated with global warming.” https://www.pnas.org/doi/full/10.1073/pnas.0403720101.
Does food insecurity contribute to political unrest, like the Arab Spring? Did that cause real harm?
70000 (seventy thousand) people died in France alone in the very hot july 2003. I haven’t seen anything close to such numbers for any winter in modern times. In winter cold you can heat your home and put on more clothing. In sweltering heat, you can’t do anything comparable. You can offer poor people to sleep at night in cooled spaces as they did in some cities in western US some years ago, but for how long? And how many?
It is meaningless to compare the survival rates in the nineteenth century to those today. They didn’t have the knowledge and the medicine and health systems we have today etc.
Scott even mentions the black death (began around 1349), the pest which halved the european population, but he doesn’t seem to know that this happened in a climate most climate denialists say was *warmer* than the climate we have now. It probably wasn’t, but most proxy data signals it was clearly warmer than 1700-1850, when the european population more than doubled from much higher numbers than lived in 1340. This population growth (the socalled demographic shift from phase one to phase two, the “explosive phase”) has nothing to do with climate change or the widespread use of fossil fuels, which happened after 1850, but everything to do with new agricultural methods, new crops (potatoes) resulting in far better food safety, better hygiene/sanitation, better housing standards, better technology: water mills, sailing ships, with main enlightenment, beginning education etc.
Thank you for your very interesting comment, Karsten. The historical relation between global human population and greenhouse forcing is a fascinating topic, which you’ve evidently studied in some detail. As you no doubt know, in addition to declining populations in Europe due to the black death, the European invasion of the Americas produced a demographic disaster of unknown magnitude, but potentially (according to Wikipedia) with premature deaths numbering in the 100s of millions. The slight dip in global temperatures known as the Little Ice Age may have been forced by regrowing New World forests. It appears that Europe’s population entered its explosive growth phase some decades after atmospheric CO2 reached a millennium-scale low. As you say,
This population growth (the socalled demographic shift from phase one to phase two, the “explosive phase”) has nothing to do with climate change or the widespread use of fossil fuels, which happened after 1850, but everything to do with new agricultural methods, new crops (potatoes) resulting in far better food safety, better hygiene/sanitation, better housing standards, better technology: water mills, sailing ships, with main enlightenment, beginning education etc.
IOW, the drivers of population growth in Europe were cultural developments, that environmental economists would include in the “(T)echnology” factor in I=PAT. In that heuristic framework, common-pool resource tragedies are subject to mitigation by collective human intention. In the case of climate change due to anthropogenic global warming, well-targeted collective intervention in the otherwise-“free” markets for both food and supplemental (i.e. non-food) energy can in principle drive T to near zero, leaving climate change decoupled from human (P)opulation or (A)ffluence (i.e. per-capita income) growth. That would at least buy us more time to collectively address all our other impacts on the biosphere!
Anticipating potential objections: “I=PAT” was introduced as a simple 0th-level heuristic model of humanity’s “environmental” impacts, i.e. social costs. It was intended as a starting point for environmental economics, not an endpoint, so investigators are free to expand any term they wish to focus on. For one thing, it’s evident that each of the right-hand terms are partial functions of each other! Still, what should be clear is that our accelerating impacts are the aggregate result of choices (T) that are *economically sound* for the individuals making them, because the private benefit of our choices exceeds our expected share of the social costs. Therefore, impact can only be reduced by “mutual coercion, mutually agreed upon” (G. Hardin): that is, only collective (i.e. government, for the most part) intervention in the otherwise-free market, can mitigate them.
While Roy ranks high oh Mark Steyn’s witness list, he now has some explaining to do, The judge in Mann v. Steyn changed courtrooms last Friday after the jury started to sweat— it hit 80 outside, the highest January temperature in the history of the nation’s capital.
And what did the defense have to say?
https://vvattsupwiththat.blogspot.com/2024/01/steyn-trial-runs-afoul-of-act-of-god.html
Sounds like a scene out of “Inherit the Wind.” Did they hand out fans for the sweltering spectators?
If Steyn was present, more like “Inherit the Breaking Wind”
Well, that would no doubt account for a significant portion of his carbon footprint.
RE: “Cherry-picking season”
Observation: USA looks to have highest density of observed weather station data (google station distribution of Berkley Earth or GHCN)
Question: Is a comparison of model to reality over a specific geographical region more robust for regions with a denser observational network?
Except for the areas over the poles, the global surface is oversampled compared to what is needed for a robust product/estimate. It adds some robustness, but nothing appreciable.
You could pick a random sample under the constraint that no two stations be closer than distance X and see. This was done repeatedly many years ago now. I don’t have the refs, but I think it was even done here as well.
Anyway, you can derive a clear climate change signal from a much smaller sample of stations. I think 30 sites was plenty, but my memory could be off.
I should add that those using ice core–and even tree core data to a much lesser degree–are using somewhat-to-extremely reduced sampling site variation. So the issue has been explored. Not my area at all though.
You may be thinking of stuff like this:
https://archive.is/rHXTu/6ea3401c2c56dd9385f3fe1330fcc471d49fbb1e.png
“Air temperature series at monthly to annual scales have the longest spatial correlation lengths of all atmospheric surface ECVs (Peterson et al., 1997), and Jones (1995) showed that a well-spaced network of 170 representative sites could be used to estimate the global mean LSAT [land surface air temperature] series on monthly to annual timescales with reasonable fidelity. This analysis is repeated and updated here using CRUTEM4.5 (Climatic Research Unit Temperature data set version 4.5) in Figure 3 using five unique subsets of 163 well-separated long-term stations. The spatial correlation length of annual average temperature is about 2,000 km, corresponding to about 85 evenly spaced stations (Briffa and Jones, 1993). In practice, achieving evenly spaced stations would be impractical, and thus c. 160 stations that are free of inhomogeneities would provide a sufficient sample for the annual means.”
https://doi.org/10.1002/joc.5458
“Nice comment from Kevin Cowtan suggesting that a somewhat more careful analysis would suggest that you need maybe 130 stations.”
https://archive.is/1XVwo#selection-335.1-339.115
[with:
– https://archive.is/IYeKc#selection-3957.0-5063.234
– from 14:13: https://www.youtube.com/watch?v=VR3j2Sl8CTo&t=853s
– https://doi.org/10.1093/climsys/dzy003 ]
https://twitter.com/DaleGribble_666/status/1147988211479666688
I wondered in 2014 why something like 65% of the difference twixt RSS & UAH was due to assessment of cooling after 1997/8 El Nino. I vaguely recall that I decided in 2014 that the same difference after another El Nino (2010 ?) was responsible for practically all the rest. I’m not bothering to plough through my 2014 notes. Carl Mears said or wrote somewhere “We make differing assumptions”, a useful explanation.
pgeo 30 JAN 2024 AT 2:48 AM Presumably so for that region but globally it’ll depend on the dates because there’s something like a decimal order of magnitude as many high-quality temperature measuring devices (static and roaming) around Earth as are required to get a good temperature anomaly result (like maybe +/- 0.02 degrees something like that) but in 1850-1860 that wasn’t the case. Canadian Francis Zwiers and Phil Jones of University of East Anglia CRU say some very few locations are required, like many hundreds of kilometres spacing, provided there are reasonable evenly spaced, well sited, accurate equipment correctly read at the proper regular intervals.
—————
Annoyingly, Simon Fraser University (SFU) took this talk on GooglesTubes video Private a couple years back after being Public abuot a decade (I had reviewed it now & then maybe once a year or so since finding it in 2014). If I’d known they’d do that I’d have made a lot more detailed notes of what’s in it instead of these little place markers.
https://www.youtube.com/watch?v=FQnt73zJ-S4 Simon Fraser University Mar 2, 2011
The Instrumental Temperature Record and What it Tells us About Climate Change Francis Zwiers
This is cut’n’paste of my 2014 notes.
——–
6:55 correlating accuracy with distance between stations. Turns out one every 2,800 km on land (Siberia) and one every 1,000 km in ocean (north Pacific) gives all the accuracy needed (provided they are read properly/accurately 3+ times per day and well sited of course) and shown on the plots for 1-year averages (if you want monthly averages then closer spacing is required). Surprised me how few are required but Phil Jones has said 100 temperature stations for all Earth would give the Global Mean Surface Temperature (GMST) to the +/- 0.01 degrees accuracy you see provided that they are read properly/accurately and all are well sited). Of course, there are actually 7,411 temperature stations on land and ocean buoys plus continuous from ships and the roaming non-stop 3,820 Argo floats.
12:05 how the error because of sparse land instrumental 19th century is figured out from 1850 AD. You see how the errors decrease hugely from 1850 AD to 1920 AD. It’s like +/- 0.25 degrees circa 1850 AD and drops to <+/- 0.10 degrees error by 1920 AD (getting down to something like <+/- 0.01 degrees error by 1970 of course (technology). Although there's a very very slight possibility that the +1.06 degrees global warming since 1850-1900 AD might be as much as 0.25 degrees too low or 0.25 degrees too high, the odds are very highly in favour of it being within more like +0.96 to +1.16 degrees. That's how statistial uncertainties work, it's a bell curve.
18:00 Amos, Quebec 1910-1995 AD 1927 AD & (mostly) 1963 AD re-siting "artifacts" (false non-existent temperature change) shown, explained and correction shown to greatly *reduce* (not increase) the warming indicated from the incorrect +2.4 degrees 1910-1995 AD to a corrected +0.2 degrees 1910-1995 AD. The clever correction method is called "homogenization" (matching with other nearby stations to see whether it has anything odd and if so find out why).
20:52 "been done very carefully in Canada by the group at Environment Canada that's responsible for doing this work..". (Nostlagia: I briefly met a computer programmer at AES Dufferin Street Toronto in 1973 at the Varian 2-week seminar in Georgetown for the V73 computer with Vortex omnitask Operating System (O/S)).
21:26 Scatter chart of all thousands of adjustments (corrections) made to U.S. of America only records 1895-2007 AD showing very clearly that half were corrected upwards by 0.5 to 1.5 degrees and half were corrected downwards by 0.5 to 1.5 degrees, so the net change of thousands of adjustments 1895-2007 AD is definitely <0.01 degrees either way over 112 years. Summary at 23:33
25:06 Sea surface temperature (SST) global coverage pictorials 1830 AD to 2007 AD (177 years)
32:00 The bucket corrections (the only corrections ever made that amount to a global hill of beans, because they are in oceans).
Hah! It’s just barely possible that you met my former father-in-law–technically in-laws are supposed to be forever regardless of divorce, but that seems a confusing convention–who was an upper-level AES official at the time. (Not sure of the position, as I didn’t meet him ’til several years later.) Probably not, as he was an old-line forecaster by training, and had some skepticism regarding numerical forecasting, although he did clearly see it as the future direction of the profession.
Nostalgic to hear about the AES–that’s Atmospheric and Environment Service, for readers unfamiliar–as it’s been reorganized out of existence as such, subsumed into the current Environment and Climate Change Canada. I actually missed the last name change from plain “Environment Canada” ’til now, as I live in the US these days–but I’m sure many denialist Conservatives and their ilk are still stewing about it.
Re: this string. Tx for info.
Another question: For GCM does anyone know what is methodology for deriving grid cell average time series of eg emperature for calibration/validation phase?
Curious how GCM programmers deal with unequal distribution/density of meteorological station data.
Roy responds:
https://www.drroyspencer.com/2024/01/spencer-vs-schmidt-my-response-to-realclimate-org-criticisms/
That one is between you two.
[Response: I like that he points out that I didn’t refute all his points (not enough time in the day!). But maybe I’ll put in a PS. – gavin]
Once Roy’s status as a shill are clear, what is the point of further engagement?
Il faut imaginer Sysyphe heureux.
Roy is evidently not the “happy Roy” hoped-for with the PS as he has been tapping words out again on his computermachinething. With a link back to this web-page (presumably meaning to cite the PS), Roy insists that we should plot two divergent time series with common start points as that shows the divergence properly. Sadly, this doesn’t square in any way with the graph annotation the idiot provided. So he is evidently unable to be trusted putting graphics together (which makes you wonder what else he ballses up as graphics are hardily difficult) and now he is trying to make bogus excuses for his mistakes. (His original excuse was that the ‘base period’ error “appears to be a typo” so presumably he was initially unclear as to what had happened.)
MAR,
In the metaphor, Team Science (in our case, Gavin) has the Sysyphean task rolling shenanigans away.
Roy is rather even-keeled. Getting personal helps contrarians more than anything. So there’s no need to react to jabs such as:
https://www.drroyspencer.com/2024/02/gavins-plotting-trick-hide-the-incline/#comment-1609636
There are issues that need to be resolved, e.g. SST, y-axis, etc.
Let’s not forget that these comments are off-the-cuff. Just compare the titles from the Heartland Institute hit piece with what is really said in the notes and citations.
In the end, Sysyphus’ task is to move Team Science’s ball forward, not contrarian’s.
Spencer’s scientific credentials make him well-qualified to construct specious disinformation, and he’s on record as rejecting important aspects of the consensus of his peers for AGW, but we mustn’t dismiss his scientific claims just because we know that about him. Accordingly, Gavin has rigorously evaluated the substance of Spencer’s arguments on their merits, and found them to be misleading. Gavin explicitly disavows making the argumentum ad hominem:
I don’t criticize Spencer (and Christy before him) because of any tribal or personal animosity, but rather it is because appropriate comparisons between models and observations are the only way to see what we need to work on and where there are remaining problems.
Thank you, Gavin! With our due diligence done, we’re allowed to speculate on those two credentialed scientists’ cognitive motivations for propagating disinformation. Since Spencer made his latest claim in a non-peer-reviewed article on behalf of a notorious American conservative stinktank, we might ask “What more do we need to know?” Well, leaving pecuniary interest aside, why might Spencer and Christy stake their reputations on reanimating the undead “models are unreliable” denialist meme again, when it’s been iteratively slain already? As other RC commenters have often pointed out, one answer may be found in their shared religious faith. Both are open about their Evangelical Christianity, and have lent their names and credentials to the Cornwall Alliance for the Stewardship of Creation, an organization of evangelicals and their corporate allies (Russell came up with Cornball Alliance, because how could he not?). In 2000, the organization issued the (a href=”https://cornwallalliance.org/landmark-documents/evangelical-declaration-on-global-warming-2″>Evangelical Declaration on Global Warming. Its signers declare, among other things:
IOW, evidence be damned! One could scarcely ask for a more forthright repudiation of the basic principles of science. Spencer is listed among “Notable Signers”; though curiously enough, Christy is not. Spencer’s pretty testy about it, titling a blog post Science and Religion: Do your own damn Google search.
Like anyone else, I hope to avoid making ad hominem arguments, but Gavin’s thorough rebuttal of Spencer’s new claims tends to justify my prior skepticism of any scientific claim Spencer makes.
Spencers cherrypicking and missinformation made me wonder if Spencer is engaging in “motivated reasoning” due to his very strong religious beliefs.” Motivated reasoning (motivational bias) is an unconscious or conscious process by which personal emotions control the evidence that is supported or dismissed (wikipedia)”. He may be doing it subconsciously and that is a hard bias to control.
His cherry picking seems to be a habit: From Spencers wikipedia entry: “Andrew Dessler later published a paper opposing the claims of Spencer and Braswell (2011) in Geophysical Research Letters.[25] He stated, among other things: First, [they] analyzed 14 models, but they plotted only six models and the particular observational data set that provided maximum support for their hypothesis. Plotting all of the models and all of the data provide a much different conclusion..”
Actually, I guess the closest organizational successor to the old AES would be a division of EECC–the Meteorological Service of Canada.
https://en.wikipedia.org/wiki/Meteorological_Service_of_Canada
What say you, jgnfld?
Not an expert on the organization of climate physicists in Canada! I know a couple climate researchers here in Newfoundland associated with the University primarily on NSERC grants except for one geographer who is affiliated more through StatsCan..
Statscan, by the way, recently started a portal with low level climate data. It’s aimed at the provincial, regional, NGO, community planning and programme level. Talked to the Chief Statistician of Canada his very self about it, just last week! https://www.statcan.gc.ca/en/subjects-start/environment
The ECCC group I think reports more through the https://climatedata.ca site which is also a collaboration of groups providing regional, NGO, and community-level data.
I did watch as the previous conservative government threw the contents of the federal fisheries research library into the landfill as part of their quite conscious destruction of climate data across the country. I felt about the same that day as I felt watching the TV as a US citizen on Jan 6. Pure shocked, unbelieving horror.
Expect to see that again as Trudeau is likely to lose the next election as parliaments tend to flip every decade or two and the present conservative head is far stupider and far more populist that the last one (Harper).
JGN:
Please link some leads on the Newfoundland landfill story . It rings a bell:
https://vvattsupwiththat.blogspot.com/2013/02/postmodern-geochemistry-semiotic-carbon.html
Here’s a general Smithsonian article describing the atmosphere the prior conservative govt created… https://www.smithsonianmag.com/science-nature/canadian-scientists-open-about-how-their-government-silenced-science-180961942/. And, as I said, Harper was a _smart_ control freak. The present group under Pollievre is far more populist and far more likely to go further and more clumsily (though Harper went so far that people like me actually marched in a political demonstration for the first time in our rather introverted and cloistered lives).
Don’t see a quick link to the library here. Here is the experience around another library closing in Alberta (the policies were country-wide, of course). https://www.cbc.ca/news/canada/calgary/research-library-s-closure-shows-harper-government-targets-science-at-every-turn-union-says-1.3199761
There are any number of paywalled sources and several books describing the era. Simply google “Harper war on science”. One of the more famous events was of a salmon researcher whose research was published on the cover of SCIENCE, for heaven’s sake, but she was not allowed to speak about it even at science conferences on pain of termination. https://www.cbc.ca/news/canada/british-columbia/krist-miller-scientist-dfo-muzzled-1.3308549
Regarding Government of Canada organizational changes and meteorological and climate groupings.
Atmospheric Environment Service (AES) came into being decades ago (1970s?) as a relabeling of the former meteorological services. It reflected the additional importance of climate issues – beyond the former focus on weather. Even earlier, weather observations used to be part of the Transport portfolio, (linked to aviation needs).
At some point, AES was renamed back to MSC. I can’t remember the exact year. For a while, MSC included both the observational side and the research side. And it included both weather and climate groupings. I still have an “MSC Research” jacket they handed out at one point.
In the early 2000s, Environment Canada was reorganized, creating a Science and Technology Branch. The research part of MSC was moved out of MSC into that branch, as “Atmospheric Science and Technology Division” (ASTD). This created a split between operational and research activities, and that that split has caused all sorts of damage (IMHO). Too many MSC managers that don’t understand long-term climate and research needs, and too many ASTD managers that don’t value the transfer of knowledge to the monitoring networks. Too many managers saying “that’s not my job”.
Oops, HTML fail, I didn’t close the link to the Evangelical Declaration on Global Warming. The information is there, however.
Note, once again I don’t intend to imply that all Evangelical Christians are climate-science deniers, with Katharine Hayhoe the conspicuous counter-example to Spencer.
Mal. I fear Katharine’s audience is outnumbered by Megachurch & Bible Belt congregations who cleave to the view that oceanogaphic and isostasy data indicating sea level rise must be as apocryphal as the New Testament and the Pentateuch are real , because God told Noah it would never happen again.
Well, national policy is a numbers game. The goal of climate realists is to assemble an effective voting plurality within the American electorate. Practically speaking, the 2020 election was about climate, and so was the “Inflation Reduction Act” of 2022. A few compartmentalizing Evangelicals might win the next election for us. Speaking as an atheist, “God bless Katharine Hayhoe.”
I just wonder when the Democrats in the US will discover that the voting system there is the main reason you can expect Trump to win again without having gained a majority of the votes, just as he did in 2016, and nearly in 2020.
The US voting system (and the whole constitution for that matter) belongs before 1850 or further back in time.
We are many common people here in Europe wondering: How many centuries before the Democratic leadership discovers these problems? That the US constitution wasn’t written by God and can in fact be rewritten, thereby changing the system from oiligarchic democrazy to democracy. How long after the collapse of the West Antarctic ice shelves? In 2524? 3024? Will Biden still be running for president until then, maybe as ghost, against the ghost of Trump? “Modern” history is full of such exciting perspectives…
KVJ: I just wonder when the Democrats in the US will discover that the voting system there is the main reason you can expect Trump to win again without having gained a majority of the votes, just as he did in 2016, and nearly in 2020.
BPL: We’re well aware of the problem, but unfortunately, it would take a new constitutional amendment to get rid of the electoral college. A movement is taking place where states agree to aware all their electors to whoever wins the popular vote, but it’s mostly or all blue states so far.
award, I meant, not aware
KVJ: The US voting system (and the whole constitution for that matter) belongs before 1850 or further back in time.
The framers of the US Constitution, by and large believed that government was an unavoidable evil. They didn’t trust anyone who sought power, probably because they were ambitious men themselves. The system they left US citizens with wasn’t designed to facilitate social progress, but to forestall tyranny. It’s not supposed to be easy to make changes! Yet the amendments to the US Constitution now number 27, including the original 10. Slavery had to be abolished by the government’s monopoly on force, yet racial equality has since advanced as much as it has under the rule of law, albeit sometimes backed up by armed government personnel.
That’s our history. In the present, those who think our country’s founding document should be updated or even replaced with something different, may not realize the depth of polarization that has grown between Democratic and Republican voters, who are currently about evenly matched on issues such as collective action to decarbonize our economy. It’s been all too easy for modern disinformation professionals to intensify and exploit our polarization for the benefit of their plutocratic employers, who wish to secure the freedom to socialize the climate-change costs of their revenue streams. Under our de facto two-party system, every vote is a decision on the margin, and at best we can only choose the lesser of two evils. Foreign observers should therefore understand that any attempt to change the existing system could, by a bare majority of votes. give victory to the greater evil!
You have a point there. For instance, the call for a constitutional convention, sometimes heard from some on the left, could be disastrous from their point of view, if red states were able to implement some Dominionist ideas dismantling our already somewhat tattered “wall between Church and State.”
Thanks Kevin, that is what I meant by my comment.
Unfortunately, these ‘Christians’ don’t care for Jesus’s treachings. When confronted with actual Bible, they are horrified and reject him (Jesus is not a real Christian, go figure). They worship their egos and think god was created in their image (all too likely).
I do think more observant Christians are beginning to speak out, but they are threatened with violence and driven out of their ministries all too often.
“Jesus is not a real Christian, go figure”
Shade of the Barber Paradox in a new context?
The damage from their association with the racist far right may already have been done Over 28% of Americans do not believe in God–a record high for the country. Cheetolini kills everything he touches and he had his tiny hands all over evangelical Christianity.
Damage or no, the crazies make for a solid, motivated, and sizable voting block. This has been snowballing for a long time, IMO. I remember Pat Robertson decades ago, railing against the “liberal Supreme Court and claiming he could control hurricanes with his mind, all while leg-pressing 2,000 lbs (supposedly).
If Jim and Tammy Fay, Jimmy Swagert, and a long, long list of other cons, lesser lights and cult leaders seem like old news, surf your TV and scratch the surface of a whole new crop of loons in both English and Spanish, including Robert Jeffress mentioned below:
Tim Alberta interviewed on Firing Line
https://www.youtube.com/watch?v=ErbTbyvwpdQ
I think this is one of his better ones.
Also, Spencer would say climate models were wrong and over-estimated climate sensitivity, even if that wasn’t the case. He’s been doing that for decades, since at least 1997. Take the following 2022 video from Potholer54 (Peter Hadfield) on Spencer’s claims:
https://www.youtube.com/watch?v=29QDGEJC1fg
At about 0:20, 2:08, and 4:13 in that video, Potholer54 shows Spencer claiming that climate models predicted ~0.25 – ~0.3 K/decade of global warming. At about 2:08, Potholer54 suggests that this could be because Spencer cherry-picked particular models and ignored others. But it’s actually much worse than that.
Spencer gives his trick away when he mentions a “1990 report” at 4:13 in the video for his 0.3 K/decade model claim. That 1990 report is the IPCC’s First Assessment Report (FAR). The ~0.3 K/decade from that report was for a high greenhouse gas (GHG) increase, “Business-as-Usual (Scenario A)” scenario that didn’t happen. Spencer simply ignored the other scenarios in FAR, including scenario B that better matched the observed GHG increase and subsequent warming that actually occurred. When you compare how much warming occurred per unit of GHG increase (or more precisely: the amount of warming per unit of radiative forcing, also known as TCR or the transient climate response, representing shorter-term climate sensitivity), the IPCC’s model-based projections, and those of plenty of other models, did fine. Spencer hides that fact by only mentioning the high GHG increase scenario, and he’s continued to do so for decades.
This also allowed Spencer to pretend at 4:19 in the video that climate scientists dropped their model-based projections from 0.3 K/decade to 0.18 K/decade going from the IPCC’s 1990 report to their 1995 Second Assessment Report. In reality, 0.18 K/decade was basically the same as the scenario B that Spencer willfully ignored in the 1990 report. And that’s the same ~0.18 K/decade warming that actually occurred, as Potholer54 covered in his video. Spencer hid that from people as well.
Some further sources on this below:
– https://www.youtube.com/watch?v=cjk9zAGToyM&t=361s (from 6:01 onwards)
– https://www.youtube.com/watch?v=LiZlBspV2-M&t=68s (from 1:08 to 2:49)
– https://doi.org/10.1029/2019GL085378
– https://doi.org/10.1038/nclimate1763
IPCC 2021 Sixth Assessment Report:
“Under these actual forcings, the change in temperature in FAR [IPCC 1990 First Assessment Report] aligns with observations [page 186].”
https://web.archive.org/web/20230930165550/https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_Chapter01.pdf
[with: figure 1.9 on page 185]
IPCC 1990 FAR:
“Under the IPCC Business-as-Usual (Scenario A) emissions of greenhouse gases, the average rate of increase of global mean temperature during the next century is estimated to be about 0.3°C per decade (with an uncertainty range of 0.2°C to 0.5°C) [.] This will result in a likely increase in global mean temperature of about 1°C above the present value […] by 2025 and 3°C above today’s […] before the end of the next century.
[…]
Under the other IPCC emission scenarios which assume progressively increasing levels of controls, average rates of increase in global mean temperature over the next century are estimated to be about 0.2°C per decade (Scenario B), just above 0.1°C per decade (Scenario C) and about 0.1°C per decade (Scenario D) [1, page xxii].”
https://web.archive.org/web/20190314070419/https://www.ipcc.ch/site/assets/uploads/2018/03/ipcc_far_wg_I_full_report.pdf
“ERA5 does have the largest trend over the shorter 1991–2020 standard climatological reference period. Values in K/decade are 0.24 for ERA5, 0.23 for GISTEMP and HadCRUT5, and 0.21 for Berkeley Earth, JRA-55 and NOAAGlobalTemp in this case.”
https://doi.org/10.1002/qj.4174
Roy Spencer in 1997:
“I’m a member of this group, this 2,500 scientists that are involved in the IPCC process. In the 1990 report, it was estimated that future global warming, at least until the end of the next century, would run about three-tenths of a °C per decade. In 1992, they came out with an interim report and basically said there was really no new science that would substantially change the 1990 estimate of three-tenths of a degree warming although they hinted that we’re learning more about aerosols and that aerosols might indeed reduce the amount of warming. Now we’ve just had the latest report come out, 1995 report, which was released in ’96. And the estimate of global warming has been reduced to about .18 degrees per decade which comes from an estimate of 2 ° warming, 2 °C warming by the end of the next century.”
http://web.archive.org/web/20021127223256/http://cei.org/gencon/027,01481.cfm
To Gavin Schmidt:
Is it possible to add the model-based warming projections from the IPCC’s 1990 First Assessment Report to the “Climate model projections compared to observations” page?:
https://www.realclimate.org/index.php/climate-model-projections-compared-to-observations/
I ask because they’re far enough back that the subsequent anthropogenic signal has more time to rise out of the noise. And given the centrality of the IPCC in climate science discussions, it would be nice to have their oldest model-based warming projections on the page. I’m also annoyed by the number of contrarians like Roy Spencer who pretend only the BaU scenario (business-as-usual, or scenario A) was given and don’t account for observed radiative forcing being closer to scenario B than to BaU.
If including those projections is workable, then I have some suggested sources below, most of which you likely already know.
https://archive.is/QXJ0k/afe22294895246faa7202d65f0e4fdd185aa8635.png
– projected warming: figure A.9 on page 336, top-right of page xi, bottom-right of page xxii
– projected radiative forcing: figure A.6 on page 335
– projected greenhouse gas increases: figure A.3 on page 333
https://web.archive.org/web/20190314070419/https://www.ipcc.ch/site/assets/uploads/2018/03/ipcc_far_wg_I_full_report.pdf
prior assessments:
https://doi.org/10.1029/2019GL085378 (your paper)
https://doi.org/10.1038/nclimate1763
https://archive.is/aySSt/9d56525f6ba5a9ef23995280531220ad89daf7d4.png
“Under these actual forcings, the change in temperature in FAR [IPCC 1990 First Assessment Report] aligns with observations [page 186].”
https://web.archive.org/web/20230930165550/https://www.ipcc.ch/report/ar6/wg1/downloads/report/IPCC_AR6_WGI_Chapter01.pdf
Mal , Practically speaking the electorate didn’t much care- if I recall correctly, climate ranked 21st in descending order on the exit poll list of issues impacting the vote. with the economy as #1.
This is a pretty good treatment of the issue. More nuanced, but you are more correct than I thought. An exit poll, where? of whom? Pew August 2023, 17th out of 21 overall. https://www.pewresearch.org/short-reads/2023/08/09/what-the-data-says-about-americans-views-of-climate-change/
8. About three-quarters of Americans support U.S. participation in international efforts to reduce the effects of climate change.
Thanks , Susan, for refreshing my memory.
The Pew poll actually graphs 15 issue with climate at 13, in between government growth & ethnic and racial issues
The takeaway may be that more voters read the New York Post than the New Yorker
Indeed. The New Yorker is going downhill fast. Sad to hear the layoffs included Andy Borowitz. They print a lot of boosterist stuff on things for billionaires to buy these days. Still a few nuggets here and there, but the commercial side seems to be winning. I know they always exploited wealthy New Yorkers to subsidize the broad range. There’s still some good range on climate reporting. Sigh
“Condé Nast ,,, media brands attract more than 72 million consumers in print, 394 million in digital and 454 million across social media platforms. These include Vogue, The New Yorker, Condé Nast Traveler, GQ, Glamour, Architectural Digest, Vanity Fair, Pitchfork, Wired, and Bon Appétit, among many others.”
US voters seldom have more than two choices in the Presidential election, with the two candidates vying for the most votes on every issue. On the issue of climate change, the rightward of our two parties includes a climate-science denial plank in its platform. That leaves climate-realist voters with only one practical choice. The 2020 election was about climate, because a Republican victory in the White House would have postponed still further any federal legislation that recognized the risks anthropogenic climate change presents for our country. As it happened, a Democratic majority of 51.3% enabled a historic “tipping point” in US climate politics, namely the passage of the “Inflation Reduction Act” of 2022. The IRA passed by the slimmest of margins, even with its decarbonizing goals left out of the title. The votes in both houses were strictly party-line, with the Vice President breaking the tie in the Senate. Of course, ensuring the country stays tipped depends on sustaining Democratic majorities in future elections, at least until Republican candidates start defying their party on climate. We live in interesting times!
I confess up front that the following is off-topic, but few media outlets seem to be following the story (though perhaps over the interim that may not be such a bad thing, since the most cost-effective monitoring for now might well be satellite observation).
My query: what could both the path and the rate of melt for Iceberg A23a tell us about conditions in and adjacent to the Southern Ocean?
I wouldn’t expect any data to be too significant necessarily, but I wouldn’t think the data to lack all significance, either. (Were any models on its path and/or rate of melt offered previously? Measuring those models against actual outcomes could perhaps help only minimally, but then I don’t know a thing about data acquisition and analysis for such cryospheric and hydrospheric projects.)
I don’t have a problem with anchoring two series to the starting point of their trends. It’s something I do especially when I want to visualize the structural divergence.
The real issue here is that anchoring the series to the starting points of their trends from 1979 introduces a spurious divergence because CMIP6 was at a relative low point while the surface temperature was at a relative high point in 1979.
I plot CMIP6 vs BEST from 1850 to 2023 both anchored to their 1851-1880 averages.
https://i.imgur.com/YUye7VJ.png
Thank you for that point – I was wondering about that.
Per:
https://judithcurry.com/2024/02/02/two-model-observation-comparisons-confirm-cmip6-models-run-too-hot/
It appears thst Gavin loses on all points!!!
[Response: [Sure_Jan.gif] – gavin]
Hello,
I asked FrankB a question at Roy’s:
https://www.drroyspencer.com/2024/02/gavins-plotting-trick-hide-the-incline/#comment-1610760
Perhaps you could help him find the “false” in Gavin’s post?
If you can’t, it will appear that you haven’t read the piece you cite.
drhealy: – “It appears thst Gavin loses on all points!!!”
Dreamin’!
https://www.youtube.com/watch?v=dik_wnOE4dk
Observations indicate the Earth System is ‘running hot’ and getting hotter:
* Global surface temperatures were a record for the day, at +1.71 °C above the pre-industrial baseline, and the running 365-day average was +1.51 °C above the pre-industrial baseline.
https://twitter.com/EliotJacobson/status/1753403323909308736
* Jan 2024 ended with the highest global average Sea Surface Temperature in observational history.
https://twitter.com/LeonSimons8/status/1753140203802239177
* NASA scientists who compared hundreds of thousands of satellite images, believe the world’s second-largest body of ice has shrunk by a fifth more than previously estimated.
https://www.abc.net.au/news/2024-01-19/greenland-ice-sheet-shrinking-faster-than-thought-nasa/103363612
* The Antarctic sea ice extent anomaly appears to be on a trajectory towards more records broken in 2024.
https://zacklabe.files.wordpress.com/2024/02/nsidc_sie_ant_anomalies.png
* Dec 2023 Nature paper by Audrey Minière et al. titled Robust acceleration of Earth system heating observed over the past six decades, included in the Abstract (bold text my emphasis):
https://www.nature.com/articles/s41598-023-49353-1
Dude, I’m not sure Aunt Judy could still even identify “camel”
There are some issues with that article. For example, it says:
“It’s obviously: Two observational datasets (UAH and STAR) are generated by independent research groups and very similar.”
But they conveniently leave out reanalyses and radiosonde-based trends that align better with RSS’ trend than with UAH and than with NOAA/STAR’s newer trend (in contrast to NOAA/STAR’s older trend). That issue was covered in a prior RealClimate article, and is in keeping with the UAH team’s practice of underestimating tropospheric warming due to their poor homogenization. The authors also don’t mention criticism of UAH’s analysis nor evidence that those satellite MSU-based analyses underestimate global warming. That’s not surprising since the article is co-authored by Nic Lewis, whose work during the COVID-19 pandemic showed his contrarian takes typically conflict with the evidence; I could tell that, in part, because he was bungling my field of immunology in a way that conveniently suited his policy preferences. So I guess I know now how climate scientists feel seeing Lewis distort their field.
https://www.realclimate.org/index.php/archives/2023/04/a-noaa-star-dataset-is-born/
UAH’s past history on underestimating warming:
https://doi.org/10.1126/science.310.5750.972
[ https://archive.is/qfire ]
https://doi.org/10.1126/science.1216273
re-analyses + radiosondes:
https://archive.is/TzabL
https://archive.is/f0j3C
[ https://web.archive.org/web/20240113071904/https://ametsoc.net/sotc2022/SOTC2022_FullReport_final.pdf ]
“Close agreement of radiosondes with layer averages of MSU-AMSU is found for TLT and TMTcorr, except in the case of UAH satellite data (which has less warming than the RSS and STAR MSU-AMSU products).”
https://doi.org/10.1175/JCLI-D-19-0998.1
criticism of UAH’s analysis methods:
https://doi.org/10.1175/JTECH-D-16-0121.1
https://doi.org/10.1175/JTECH-D-12-00131.1
[ https://doi.org/10.1175/JCLI-D-13-00767.1 ]
https://doi.org/10.1175/JCLI-D-15-0744.1
[ https://doi.org/10.1175/JCLI-D-20-0768.1
https://doi.org/10.1175/JCLI-D-16-0333.1 ]
“These concerning numbers support the hypothesis that corresponding MSU trend estimates are likely too small5,10,38. For the tropical upper troposphere as an example, MSU trend estimates are smaller by approximately a factor of two compared to GNSS RO (see Supplementary Fig. S1). The MSU measurements contain averaged information for a broad height layer, including regions with smaller temperature changes5. Part of the underestimation by MSU can also be explained by drifting orbits38.”
https://doi.org/10.1038/s41598-023-28222-x
on Nic Lewis’ COVID-19 claims:
https://twitter.com/AtomsksSanakan/status/1577413265122267136
We didn’t leave out anything that was mentioned in Gavin’s post (also in his PS) , which we comment.
Yet you had to say this in the comments there when one of Curry’s crowd went awry because of what you left out:
“Hi Ron…to be fair, it was Gavin S. himself who announced the new STAR Dataset and made comparisons with other products, see https://www.realclimate.org/index.php/archives/2023/04/a-noaa-star-dataset-is-born/”
https://judithcurry.com/2024/02/02/two-model-observation-comparisons-confirm-cmip6-models-run-too-hot/#comment-1000510
So again, it’s misleading for the two of you to dodge the spread of analyses that contradict the lower trend in UAH and the newer version of NOAA/STAR, just so you can say:
“It’s obviously: Two observational datasets (UAH and STAR) are generated by independent research groups and very similar. The RSS set has a much steeper (factor 1.5) trend, coming from a divergence in 2000-2006. There seems to be a problem with RSS.”
You’re concealing the structural variability (likely stemming in large part of UAH’s faulty homogenization), a point Schmidt made in his comment on Spencer’s images. And you’re leaving out the wide literature on how the problem is primarily with UAH having too low of a trend, not RSS having too high of a trend. Your co-author Nic Lewis is no more credible on this topic than when he was falsely claiming Sweden achieved herd immunity to SARS-CoV-2 in April 2020.
No doubt that a NN should be trained on the satellite data so that it can supplement RSS and UAH. ChatGPT4 argues for and against:
https://chat.openai.com/share/f452ad4f-11f7-41ce-ab38-aae4dcd9c472
Hi Atomsk’s, as I wrote we didn’t leave out anything that showed Gavin. If you look carfully on his chart about “TLT” , there were included STAR, UAH and RSS. We comment the obvious. If you want to critizese the almost identical outcomes of STAR and UAH you should Email both research groupsto find out why.
And yes, well observed: in my comment: I try to be fair, marking a difference between somebody else.
best Frank
Frank, gaslighting isn’t going to work. You and Lewis left out points Schmidt shows. For example, Schmidt notes:
“3. Slightly better representation of the observed structural variability, but still only display a portion of the spread.”
In fact, you completely leave out Schmidt’s image showing the trends from reanalyses and radiosondes that are higher than UAH + NOAA/STAR:
https://archive.is/UOON4#selection-408.0-408.1
https://archive.is/uinWT
You don’t mention that because that structural variability illustrated by the reanalyses and radiosondes suggests UAH is, as usual, underestimating warming due to faulty homogenization. You and Lewis want to avoid that conclusion so you willfully ignore the broader literature I cited. But the rest of us aren’t required to do that; we can spot the low outliers here:
https://archive.is/TzabL
[https://web.archive.org/web/20240113071904/https://ametsoc.net/sotc2022/SOTC2022_FullReport_final.pdf]
And I don’t need to contact the UAH team; criticisms of their work are already published and were cited to you. Don’t worry, I’m not going to respond to you on Curry’s blog. I’ve been basically banned there since around the time I warned Lewis against his ridiculous insinuation that India achieved herd immunity by February 2021 just because SARS-CoV-2 reported cases were declining. Of course, India then had a massive wave of infections and deaths from delta variant, confirming my warning. You and Lewis are free to continue misinforming the credulous over there, as Lewis repeatedly did during the COVID-19 pandemic:
https://archive.is/8RRMM#selection-54051.0-54051.234
https://archive.is/S3HlE
Hi Atomsk’s, sorry for the delay, I wasn’t here for some time. Your last point 1st: I find it not very helpful banning people from discussions as long it’s not ad hom but factional. I don’t know enough about C-19 to discuss anything about this.
In our post we discussed the GMST and the TLT, not “near surface athmosphere temperatures”. And when it comes to STAR and UAH and you state that UAH is “faulty” you should ask the STAR-Team how it comes that they get almost identical results. Is NOAA also “faulty”?, this is here the question.
best Frank .
There is more heat storage in the ocean than actual, presumably as a result of “various correction schems.”
Here is the latest increase in ocean heat content:
https://www.nature.com/articles/s41467-023-42468-z
As you can see from Fig. 1 of this paper, it is inconceivable that the heat storage between 1950 and 2011 to be 6-10 times greater than that between 1750 and 2011 as IPCC AR5 shows in terms of forcing. Please compare Fig. 1 of the paper with Fig. 8.18 of Chapter 8 of IPCC AR5.
Nabil Swedan, https://orcid.org/0000-0003-1976-5516
I hope that you have taken into account that the numbers given in the paper you refer to is the heat uptake over a 11 year period, not the average for each year.
Figure 1 from the paper is ocean heat content, which has units of ‘joules’ on the y-axis. Figure 8.18 from AR5 is radiative forcing, with units of ‘watts per square meter’ on the y-axis. And ‘watts per square meter’ is the same as ‘joules per second per square meter’. So the graphs aren’t in the same units; they’re not measuring the same thing. One is measuring energy in the oceans and the other is measuring energy imbalance per unit of surface area per unit of time:
https://archive.is/aEP1u#selection-1756.1-1756.2
https://archive.is/cJ92S#selection-878.1-878.2
The figure you should be looking at in AR5 is figure 3.2 in chapter 3, since that’s a figure of ocean heat content. The units of its y-axis are ‘zettajoules’ (ZJ) or 10^21 joules:
https://archive.is/emvJb#selection-878.1-878.2
Figure 3.2 of AR5 also has an increase of ~200 – ~300 ZJ for 0 m – 2000 m depth from 1960 to 2010. Figure 1 of the paper has an increase of ~2o * 10^22 J to ~30 * 10^22 J for 0 m – 2000 m depth from 1960 to 2010; that’s equivalent to ~200 – ~300 ZJ, about the same as figure 3.2 of AR5.
So figure 1 from the paper is compatible with AR5, and you were wrong when you said otherwise.
But you have not compared Fig. 1 of the paper with Fig. 8.18 of Chapter 8 of IPCC AR5. When you do, you will find a huge discrepancy.
You have only compared IPCC figures with figure sources or equal published papers. They are bout the same, of course.
Nabil Swedan, https://orcid.org/0000-0003-1976-5516
I already compared them, as I told you. There is no discrepancy because they are not measuring the same thing. What you’re doing is as absurd as saying that there’s a discrepancy between a graph of volume (in liters) and a graph of density (in grams per liter). I’m beginning to see why almost everyone else here just ignored your question: you’re sealioning.
“Sealioning
A subtle form of trolling involving “bad-faith” questions. […] Instead, you react to each piece of information by misinterpreting it or requesting further clarification, ad nauseum.”
https://archive.is/3Ivi8
Here is a paper posted on this thread that converts Joules to WM-2 and vice versa:
https://www.nature.com/articles/s41598-023-49353-1
Nabil Swedan, https://orcid.org/0000-0003-1976-5516
Er, yes, he did “[compare] Fig. 1 of the paper with Fig. 8.18 of Chapter 8 of IPCC AR5.” And he linked to both graphs, so there’s no mistake. His links, copied:
Figure 8.18: https://archive.is/cJ92S
Figure 1 of Nature paper: https://archive.is/aEP1u#selection-1756.1-1756.2
Atomsk is correct: the graphs do not address the same issue at all. A couple of reasons why:
–ERF is global; OHC is not.
–ERF is “meaningfully evaluated at the tropopause and at the top of the stratosphere,” and is independent of the partitioning of energy in different parts of the Earth system; this is obviously not the case for OHC.
In terms of your argument, the Nature paper fig. 1 has no data before 1955, therefore it has nothing whatever to say about ocean heat “from 1750.”
The way it is typically agreed on is that the greenhouse gas effect causes energy imbalance at the top of the atmosphere and global warming occurs.
Please explain how giss climate model conserves energy and at the same the earth must be out if balance due to the greenhouse gas effect. Thank you.
Nabil Swedan, https://orcid.org/0000-0003-1976-5516
[Response: It conserves energy for all of the internal processes, but there can be net fluxes at the edges of the domain (ie. outgoing LW or incoming SW at the top of the atmosphere, or geothermal flux at the bottom of the soils/ocean/etc.). -gavin]
Nabil, you are making a basic error here.
Global Warming [increased GHG absorption of outgoing radiant energy and conversion to thermal energy] causes an energy imbalance at top of atmosphere.
See the difference?
Thank you, Zebra. I need your help with my comment just above this one? What do you think?
Nabil Swedan, https://orcid.org/0000-0003-1976-5516
I think several things:
1. You didn’t answer my question. Do you understand the difference?
2. I like to help people but it is not my job to look things up at your direction… provide a link to your reference.
3. Perhaps it is a matter of English not being your original language, but you seem confused about very basic concepts. What do you mean by “storage” and how do you understand usage of the term “forcing”?
I am not zebra, but will try to phrase it in even simpler terms.
If the amount of energy coming in from the sun equals the longwave going out then there is no imbalance.
GHG absorbs some of the longwave radiation. Since energy is conserved the amount of energy the Earth has to increase.
Oyvind, it is the increase in GHG that resulted in an increase of absorption of outgoing longwave and conversion to thermal energy.
If GHG content is held constant, then a new equilibrium will come to exist…. in = out.
My goal is to (attempt) having the language as simple as possible but also correct.
Øyvind: – “If the amount of energy coming in from the sun equals the longwave going out then there is no imbalance.”
But satellite-based CERES data indicates there is a planetary energy imbalance, and it’s increasing.
Per Berkeley Earth, currently:
EEI = Absorbed Solar Radiation – Outgoing Longwave Radiation = +2.1 W/m²
https://berkeleyearth.org/wp-content/uploads/2024/01/EEI-2023.png
From the Hansen et al. (2023) paper titled Global warming in the pipeline:
https://academic.oup.com/oocc/article/3/1/kgad008/7335889
The Earth Energy Imbalance (EEI) continues to grow. That’s what’s driving the acceleration of the Earth System warming rate.
https://www.realclimate.org/index.php/archives/2024/01/not-just-another-dot-on-the-graph-part-ii/#comment-818335
Geoff Miell: Yes I am very well aware that EEI is positive. I was writing about a steady state.
zebra: Yes, thank you for making my comment more precise ( and correct)
Spencer’s UAH has historically been more sensitive to El Nino warming, which is part of the reason that Roy Spencer can’t manipulate whatever horrendous Fortran spaghetti code is mapping the satellite readings to temperature. It sticks out like a sore thumb.
Look at what Sal aka @25_cycle is pointing out on Twitter: https://twitter.com/25_cycle/status/1753481652091691368
Lots of flopping around borne of desperation — of course the clown prince of analysis-obfuscation Nic Lewis is now chiming in:
https://judithcurry.com/2024/02/02/two-model-observation-comparisons-confirm-cmip6-models-run-too-hot/
Hi Paul, what’s the difference between UAH and the other products? Right: The others are T2m, not the Troposphere. Why do you think that the TLT’s have higher spikes ( especially when it comes to ENSO)? Because less mass is involved? Only a hint…
best Frank
Hi Frank,
Why do you not write your posts and your comments under the same name?
Let’s check this out. There are simultaneous spikes in 3 different ocean basins. A large spike in the equatorial Pacific Ocean corresponding to an El Nino event. A large spike in the Atlantic Ocean corresponding to a strong positive excursion in the AMO index. And a large spike in the Indian Ocean measured by the IOD index. Only the northern Pacific PDO is showing a negative excursion. Time to look for common-mode causative effects in ocean dynamics?
Just for the fun of it, I mocked up some fake temperature data in Excel for 1980-2030: I created 5 temperature time series with a slope of 0.02 degrees/year, and 3 with a slope of 0.03 degrees/year, and then added in noise every year of +/- 0.025 degrees.
Then I plotted them three different ways:
1) aligned with zero in 1980
2) aligned with average values for the 1980-2030 period (the Gavin method)
3) aligned the Spencer way, with linear trend lines all starting in the same place.
Unsurprisingly, 3>1>2 in terms of spread – both between the two clusters, and between the individual lines within a cluster. Now, one could disagree, but I think that the Gavin method does the best job of leading me to the right conclusion, which is that the slopes in the first 5 runs are not really that different, with the Spencer approach being the worst . But it seems like if one is arguing for one display method over another, creating fake data with a known real answer is a good way to judge. (my actual favorite method is the bar chart graph that Gavin included in his postscript)
That’s a real classic again:
First publish the gross mis-representation, then backtrack in a comment on a website.
Then rely on the fact, that all further disinformation pieces link to the original mis-representation.
It’s boring yet efficient…
Wow! “boring yet efficient” could be one of the simplest most direct descriptions of all fake skepticism (aka science denial). A keeper, thanks!
Arguing with deniers seems to be a sort of “comfort zone” for climate scientists. Perhaps because it’s an argument that has already been “won” millions of times over. And it must certainly be more comforting than, for example, trying to reconcile the differing views of Hanson and Mann on accelerating warming.
Secular animist mentioned: “comfort zone”
Many of the responses to climate change misinformation can be done by scientists in their sleep. Knocking down a strawman argument is easy compared to the challenge of fluid dynamics and trying to stay a step ahead of AI-based models.
And still the scientific peer-review process is pretty helpless to defend against the onslaught of junk. Several years ago, I initiated two PubPeer reviews of individually egregiously bad papers on climate change. One was a paper by Girma Orssengo “Determination of the Sun-Climate Relationship Using Empirical Mathematical Models for Climate Data Sets” in 2021 https://pubpeer.com/publications/347C628E625BD5498DB8CB29ED3086
The other was by Patrick Frank “Propagation of Error and the Reliability of Global Air Temperature Projections” in 2019 https://pubpeer.com/publications/391B1C150212A84C6051D7A2A7F119
The absolute absurdity of the situation is that the first paper has accumulated over 230 PubPeer comments and the second over 330 comments and it seems to be continuing at a steady pace. There is no doubt that each of these papers should be retracted by the publishers. The Patrick Frank paper actually had a couple of PubPeer comments by one of the original reviewers, the estimable Carl Wunsch of MIT, who admitted he made a mistake in giving the paper the go-ahead to be published.
But those retractions likely won’t happen because these particular Earth Science publishers don’t care about the quality of their journals. PubPeer has a good track in other scientific fields, especially medical, in provoking retractions, but evidently these predatory journals in climate sceince don’t pay attention to PubPeer. It’s therefore pointless to continue the PubPeer comments, but for the absurdity of arguing with unrelenting solipsists such as Girma and Patrick.
Hansen & Mann are thankfully easier to reconcile than Steyn & Mann. It’s too bad the latter did not spare us all the unedifying spectacle of litigation by amicably resolving their dispute in a boxing ring back when they were fit to do so as conflicts involving hockey sticks often end badly :
https://vvattsupwiththat.blogspot.com/2024/02/this-is-your-brain-on-sticks.html
Indeed, as Voltaire said: “I was never ruined but twice: once when I lost a lawsuit, and once when I won one.”
I’m not sure 15 rounds of Steyn gnawing on Mann’s ear in a clinch would be any more edifying.
Oddly enough they’ve brought back bare knuckle boxing claiming it’s marginally safer than using gloves (which add weight to fists). I don’t know about that, but Mann would have much more to lose in a fight since his brain has always been good and useful, whereas Steyn, well, he never had much to work with anyway.
Maybe a more relevant contest would be something like solving differential equations at twenty paces. Pretty sure that would wrap things up in a hurry.
Resolving insults to one’s honor by fisticuffs between the offender and the offended seems so inurbane. Modern gentlemen settle their differences between teams of savage attorneys.
RE: mann vs Steyn & Simberg:
https://portal-dc.tylertech.cloud/app/RegisterOfActions/#/39E6B1D3C30C2BB8B4486558221C8C0F621E97A8C8499E9C46C8336E44F4123B/anon/portalembed
Let download, then scroll down to end of Events and Orders of the Court.
That gets you the first few entries, starting in 2012.
Then click on LAST to get the most current ones.
The total, so far, is over 900 filings … even more than the ones in NY AG versus TrumpU.
And it’s being closely watched by legal scholars.
The trial is being televised, just not where I live. I guess it’s wrapping up today. Apparently all but one of Mann’s expert witnesses were rejected under the Daubert standard… That can’t be good, it sounds to me like they weren’t properly prepared by council?
———
Climate Science Legal Defense Fund
https://www.csldf.org
———
Center for Countering Digital Hate
https://counterhate.com/?s=climate+science
The new Climate Denial
How social media platforms and content producers
profit by spreading new forms of climate denial
January 16, 2024
https://counterhate.com/research/new-climate-denial/
Gavin – Two sincere thanks.
First, thanks for using the annual mean vs. monthly and for showing the pink and grey error bands Roy didn’t. They actually make his case better than he did. Even the casual observer notices just how large the divergence is between the “existential crisis” upwards bounds of RCP8.5 and its progeny are in retrospect. Good news for your fans and those with similar beliefs on this issue – the divergence is reducing over time now that we’re in to the CMIP6 suite (didn’t look so swell a few years ago with CMIP5 suite, IMO).
Second, thanks for confirming on X last year that climate scientists took the UN population data/trends at face value without checking the veracity yourselves (“I’m not a demographer”) going all the way back to the SRES/original RCP modeling. It was highly enlightening to see the effect this error had on future population projections and the correlated assumed energy use/CO2 emissions.
Thanks for some much needed chuckles from Russell’s vvatts va va voom and Ray L, Radge H, and Mal.
John Mashey’s substantive documentation is, as it has been for decades, valuable and useful. It is tiresome that insults make successful arguments which court proceedings are unable or unwilling to fully resolve. [See US polls on people who believe T can do anything other than exploit, threaten, and lie.]
Sadly, Mike Mann is also plagued with trolls from other lawsuits whose counterfactuals are staggeringly nasty and dishonest. Here’s Tim Ball, geographer, deceased: https://climatecasechart.com/non-us-case/michael-mann-v-timothy-tim-ball-the-frontier-centre-for-public-policy-inc-and-john-doe/
“On August 22, 2019, the court dismissed the case on account of delay. The court found that two periods of delay totalling 35 months constituted “inordinate delay” that could not be excused on account of the plaintiff being occupied with other matters. The court further found that this delay had caused prejudice to the defendant because three of the defendants’ planned witnesses had died. The court dismissed the case and ordered the plaintiff to pay the defendant’s court costs.”
The denialosphere claims this as equivalent to murder. Never mind the millions of deaths accumulating as a result of various forms of science denial.
[apologies for putting this here rather than in Unforced Vs due to context]
Arguing with people who don’t listen to arguments because they never intended to, is a complete waste of time and energy, which instead should be used to clarify to common people the threats from global heating, as they are playing out right now, and what needs to be done to avoid the worst case scenario we are still, contrary to what all the greenwashers and lukewarmers are saying while they put out their empty promises, heading straight into.
Look at this graph https://ichef.bbci.co.uk/news/976/cpsprodpb/3B9A/production/_132585251_era_5_global_sea_temp_lines_2024-02-03-nc.png.webp and you will have to realize how extremely scary the development now is.
This graph surely illustrates that *we are already *passing through* the plus 1,5 degree C world*, and it surely won’t be long before we are passing through the plus 2.0 degree C world. Ten to twenty years from now. There isn’t time to listen to the climate ignorants, their leaders are paid by The Heartland Institute etc. and behind them of course the fossil oligarchs like Charles Koch, Mohamed Bin Salman (the saudi murderer), the war criminal Vladimir Putin (who is openly supported by the US home made fascist and coup d’etat instigator, the demagogue Donald Trump). To think you can argue with these people is just like thinking Goebbels or Stalin, Mao or Pol Pot and their fanatic admirers would have listened to arguments. It’s not by chance Trump admires Putin and the little Stalin ruling family from North Korea and speaks about being a dictator himself. Time to wake up! But as history unfortunately shows us again and again, a lot of people, especially some academic types, are too far removed from the practical world and the lives common people have to endure, to understand this. They are very clever in their fields of expertice, but they know too little about history, and the last world war and fascism is too far away. Many believe this was just european matters, stuff old people speak about etc. Since the age which began with Reagan many have been made extremely stupid by TV and now the “social” media. The man who wrote “Amusing ourselves to death” (1985) was right.
Read the background articles and data here: https://climate.copernicus.eu/surface-air-temperature-january-2024
This is very important: “Differences between tropospheric and lower stratospheric temperature trends have long been recognized as a “fingerprint” of human effects on climate. This fingerprint, however, neglected information from the mid to upper stratosphere, 25 to 50 km above the Earth’s surface. Including this information improves the detectability of a human fingerprint by a factor of five.”
https://www.pnas.org/doi/10.1073/pnas.2300758120
Statistical details aside, this is what the discussion has to be focused on. And this:
https://www.theguardian.com/environment/2024/jan/17/greenland-losing-30m-tonnes-of-ice-an-hour-study-reveals https://e360.yale.edu/features/climate-change-ocean-circulation-collapse-antarctica
A sensible jury has found against Steyn in Mann v. Steyn , and awarded Mike $1,001,003 in damages ,
https://vvattsupwiththat.blogspot.com/2024/02/where-would-canadian-comedy-be-without.html
Is there any probability at all that this court ruling, as usual in the US, will just be appealed to a higher instance, which then (surprise, surprise!) comes to the opposite conclusion? As seems also to be happening in all the cases against Trump, the cause being the simple fact, that the higher you move upwards in the judicial hierarchy, the more overwhelming is the dominance of people belonging to the inner circles of the oligarchic ruling class.
Gavin,
I just came here after a period of staying away. from Real Climate. This blog web site is now very difficult to read the figures are OK, but all the text is a very light light gray that blends in with the background.!
I’m sure you are familiar with section 508 requirements at NASA, so I’m sure that you understand color/contrast tests for readability.. I know this is not a federal agency website, but please fix this blog so I can read it!
thanks,
Paul Donahue
Civil Engineer
Mine Safety and Health Administration
In the adding injury to insult departmant, Watts Up With That plans to charge admission to the echo chamber
There really wasn’t anything we could do, as Google essentially has a monopoly, until recently. A new ad provider has emerged that is not dependent on Google Adwords. So, starting Monday, we’ll be using them.
This is the beginning of a larger plan in which we will offer subscription tiers to premium content. WUWT will always remain free for the majority of content – but it will have advertisements – just like 90% of every other Internet sites out there. Some premium features will require subscription, much like what Dr. Roger Pielke Jr. has done on his substack website.
I hate begging like I had to do back in December, so this will put us back into revenue generation.
Here is what Watts hss coming:
“I am setting up an Internet TV studio. I’ve been working slowly on it for about a year. The challenge for me is to make it work with my hearing issues while making it look professional like I did during my many years of live television weather. The studio will be for weekly live broadcasts and for making instructional videos. With the new studio, there will be a regular weekly live interactive broadcast at WUWT to discuss the issues. That will be a subscriber based event.”
his is the beginning of a larger plan in which we will offer subscription tiers to premium content. WUWT will always remain free for the majority of content – but it will have advertisements – just like 90% of every other Internet sites out there. Some premium features will require subscription, much like what Dr. Roger Pielke Jr. has done on his substack website. “
Should we find it odd that Gavin’s rebuttal to Spencer’s average of the 36 climate models used by IPCC AR6,
did not include the average of the 36 models used by IPCC AR6, but rather only TCR?
Why was it necessary to change which models were represented for the comparison?