Many readers will remember our critique of a paper by Douglass et al on tropical tropospheric temperature trends late last year, and the discussion of the ongoing revisions to the observational datasets. Some will recall that the Douglass et al paper was trumpeted around the blogosphere as the definitive proof that models had it all wrong.
At the time, our criticism was itself criticised because our counterpoints had not been submitted to a peer-reviewed journal. However, this was a little unfair (and possibly a little disingenuous) because a group of us had in fact submitted a much better argued paper making the same principal points. Of course, the peer-review process takes much longer than writing a blog post and so it has taken until today to appear on the journal website.
The new 17-author paper (accessible pdf) (lead by Ben Santer), does a much better job of comparing the various trends in atmospheric datasets with the models and is very careful to take account of systematic uncertainties in all aspects of that comparison (unlike Douglass et al). The bottom line is that while there is remaining uncertainty in the tropical trends over the last 30 years, there is no clear discrepancy between what the models expect and the observations. There is a fact sheet available which explains the result in relatively simple terms.
Additionally, the paper explores the statistical properties of the test used by Douglass et al and finds some very odd results. Namely, that their test should nominally inadvertently reject a match 1 time out 20 (i.e. for a 5% significance), actually rejects valid comparisons 16 times out of 20! And curiously, the more data you have, the worse the test performs (figure 5 in the paper). The other aspect discussed in the paper is the importance of dealing with systematic errors in the data sets. These are essentially the same points that were made in our original blog post, but are now much more comprehensively shown. The data sources are now completely up-to-date and a much wider range of sources is addressed – not only the different satellite products, but also the different analyses of the radiosonde data.
The bottom line is best encapsulated by the summary figure 6 from the paper:
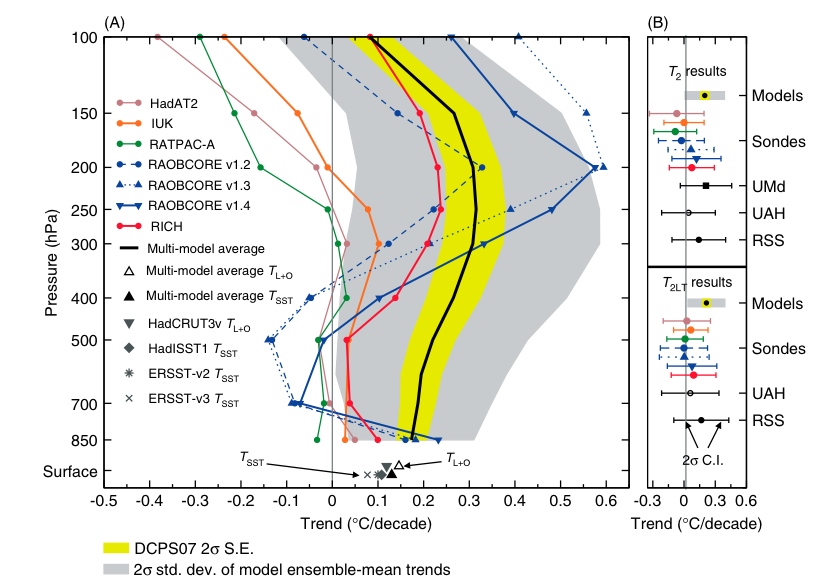
The grey band is the real 2-sigma spread of the models (while the yellow band is the spread allowed for in the flawed Douglass et al test). The other lines are the different estimates from the data. The uncertainties in both preclude any claim of some obvious discrepancy – a result you can only get by cherry-picking what data to use and erroneously downplaying the expected spread in the simulations.
Taking a slightly larger view, I think this example shows quite effectively how blogs can play a constructive role in moving science forward (something that we discussed a while ago). Given the egregiousness of the error in this particular paper (which was obvious to many people at the time), having the initial blog posting up very quickly alerted the community to the problems even if it wasn’t a comprehensive analysis. The time in-between the original paper coming out and this new analysis was almost 10 months. The resulting paper is of course much better than any blog post could have been and in fact moves significantly beyond a simple rebuttal. This clearly demonstrates that there is no conflict between the peer-review process and the blogosphere. A proper paper definitely takes more time and gives generally a better result than a blog post, but the latter can get the essential points out very quickly and can save other people from wasting their time.
Alan Millar Says: ““BTW isn’t the 1940-1977 cooling is attributable to aerosols?” (Gavin, no not that one, a different one)
Well there is conjecture that that is so (unproven but). If that is a fact, what trend is it actually masking?”
As I said in my earlier post, you need to look at the plausibility of the mechanism underlying each hypothesis to decide. If you can provide a plausible mechanism for long term cooling or switching between warming and cooling phases then go ahead and we can discuss their merits relative to the existing explanations (contained for instance in the IPCC reports), which IIRC suggest warming in the first part of the 20th century due to solar forcing, warming due to greenhouse gas since approx 1970 and a plateau in the middle due to aerosols.
BTW it is rather doubtful that any hypothesis can be unequivocally proven based solely on observationsal data (only refuted). If you are willing to dismiss an explanation as being unproven conjecture then there is very little that you will be willing to accept on either side of the debate if you are to remain consistent!
Re: #41 (Tamino)
Thanks for explaining part of the story. I can’t really judge how correct your explanation is, although it seems plausible to me, but maybe more knowledgable people can comment? Also the question about Lomborg’s sea level statements still stands. I read Lomborg’s book Cool Climate and think he’s very selective and doesn’t take extreme risks into account, but he’s sort of smart and influential people (can) use him to postpone radical climate policies endlessly. So it seems important to keep following his ‘arguments’ closely and to correct him where he’s wrong.
Hi Gavin
In the figure of your factsheet, why did you compare SST and LT tropical temperatures?
Why not to account a mix of SST and land temperatures to compare it to LT temperature?
I don’t think it’s very important because there is a high proportion of ocean’s area, but I think it’s worrying because, in principle, the trend of land temperatures is higner than SST’s trend.
Alan Millar writes:
It’s a technical term in information theory. A communication is made up of noise and signal.
The World Meteorological Organization defines a climate as mean regional or global weather over a period of 30 years or more. The periods you are mentioning are considerably less than that, thus more likely to represent noise than signal.
What in the world are you talking about? More CO2 in the air leads to greater forcing, not less.
It’s true that the response is not linear. It’s not true that a linear response would have led to a runaway greenhouse effect. Do you understand what a “runaway greenhouse effect” actually is?
Extrapolating from trends, I guess.
Anyone who thinks the climate hasn’t warmed significantly since 1978, as several of comments on this blog imply, hasn’t been outside enough. If you’re trapped in the office and haven’t had any direct observations of nature in the last 30 years ask someone who has. Talk to a local forester or farmer who has been “in the field” for a couple of decades. They can add to your knowledge base considerably.
Alan Millar writes:
Do you know what a straw man argument is? No climate scientist has ever said CO2 was the only influence on climate. Where are you getting your information? I’m guessing denialist web sites. It certainly isn’t anything you’d get from a climatology textbook.
Patrick Hadley writes:
How many times does this urban legend need to be refuted?
There is not a recent period of “no warming.” Eliminate the spaces and look here:
http://www.g e o c i t i e s.com/bpl1960/Ball.html
http://www.g e o c i t i e s.com/bpl1960/Reber.html
RE: #25
The results (surely worth a glance) reflect all known temperature perturbations, including the 1988 peak. They are published and plotted every month, (Google Global Warming at a Glance), and overlaid onto the GISS surface data on which Anthony Watts (Watts up with That) labours so strenuously.
Global Warming at a Glance takes you to JunkScience.com. Oh, my, what junk it is!
They make the reader compare an anomaly of satellite observations with base value 1978-2008 (?, they just say ‘average’) with a surface temperature anomaly of GISS with base value 1951-1980!
No wonder the values differ.
50 Bobzorunkle falls for the fallacy that the warming trend is short.
Uh, Bob, look at this graph:
http://www.globalwarmingart.com/wiki/Image:Instrumental_Temperature_Record_png
Now, what I see is a pretty consistent trend of warming from about 1900 through the present. Yes, there are drops and rises, but the thing about climate–and especially CO2’s influence on climate–is that the longer the time series, the more it is evident.
Now look at this one:
http://www.globalwarmingart.com/wiki/Image:Instrumental_Temperature_Record_png
Doesn’t the 20th century look a bit anomalous to you? What Alan Millar has is a conservative talking point–if you chop up the temperature record into tiny little bits and don’t look at the whole thing, it doesn’t look so scary.
Alan Millar posits a “natural trend” is responsible for climate change. So, Alan, how does this “natural trend” create energy and can we harvest it to solve all of our energy needs. Moreover, look closely at your temperature graph–the first half shows no warming. What is more, if you extrapolate to the left and right, the dichotomy between 18th and 19th centuries becomes more dramatic.
http://www.globalwarmingart.com/wiki/Image:Instrumental_Temperature_Record_png
Now, since the LIA was an 17th-18th century phenomenon wouldn’t you expect “recovery” to be most rapid early and not to accelerate the further away we get? I anxiously await your resolution of this little problem with your theory, as well as the amazing new discovery of how to create energy you posit.
#59
Ray, the problem here is that the first half of the century is attributed to natural causes, the second half to CO2. Why is this a problem? Well, we hear that the 1980-present warming is “unprecedented” when in fact it’s very close to the warming from 1910-1940, which supposedly is natural. This is easily verified if you use the HadCRU data. So how can this be “unprecedented” when it’s happened before?
Also, what drove the warming during 1910-1940? The sun? Not according to Leif Svalgaard. He has theorized that TSI has had no appreciable change since the 1700s. If he’s correct, then our understanding of the role in TSI on climate is fundamentally flawed.
One of the main areas where analyses gets into trouble is in not understanding our assumptions. We assume 1950-1980 was driven by aerosols. we don’t “know”. We assume the natural phenomenon are well understood, we don’t “know”. Each of these assumptions carries with it a likelihood of being correct. As an example of this, we do have a pretty good understanding of how large volcanic eruptions affect global temperatures.
Another example, no climate model predicted the melt-off of the arctic last year. not a single one. Even if we assume AGW had an impact, it would not have melted so much of the arctic. Therefore, something “natural” overcame/supplemented the warming and caused the ice to melt. What was this natural cause?
Also, on the subject of noise: How can the short term variations in temperature be considered “noise”? Noise has no impact on the overall trend (it averages out to zero over long time frames). In this case, however, variations in temperature when averaged ARE variations in climate! To say that variations in temperature is purely noise is to de-link temperature from climate. You can assume it’s noise and show that the variation isn’t out of the typical range of the noise (Tamino has done just this on his blog), but you cannot claim for certain that the variation IS noise. You can gain confidence in trying to rule out other causes, but again, that’s only as good as your knowledge of said causes.
As Jimmy Buffett says, “don’t ever forget that you just may wind up being wrong”.
ENSO indexes suggest:
La Nina drove the cool 1950s – mid 1970s.
El Nino drove the warm and humid mid 1930s – 1940s.
—
What drove the warm and dry dust bowl years in early 1930s?
But what drove the warming during 1910-1940?
#61:
Another example, no climate model predicted the melt-off of the arctic last year. not a single one.
Pray tell, what climate model would be used to make a point prediction about the near future? I work with the CCSM, and I can’t imagine using it to make a short-term prediction about a seasonal fluctuation in a parameter such as Arctic ice.
Now, if what you really mean is that the models used to predict ice-sheet fluctuations were off, then we can start talking from there. The simple answer is that the anomalous melt last year can be attributed to weather conditions that tended to amplify melt. It was sort of a “perfect storm” convergence of parameters which amplified melt – a relatively warm season, coupled with wind patterns which tended to push ice into warmer waters, increasing the probability that it would melt.
I don’t think anyone here will defend the models as “perfect.” If they were perfect, then some of us would be out of jobs, because there wouldn’t be any work to be done on them. Instead, models are just as their name implies. They’re useful tools which do a large number of calculations for us. There are bound to be uncertainties and poor parameterizations in them; however, as time goes on, we are ironing out those deficiencies intrinsic to the model or developing the understanding necessary to cut them out as smoothly as possible.
Last year’s melt isn’t some death-blow to the idea of modeling, particularly because there is an accepted hypothesis (the pro-icemelt weather conditions) which supplements the model predictions to explain what we observed.
#59 – Thanks Ray, but the graph suggests to me a 100 year cycle where temperature anomolies were 0.2 to 0.4 degrees below (whatever the baseline was) for the 100 years from 1850 to 1975 and then perhaps a new cycle where the anomolies flip to 0.2 to 0.4 above. And since this graph is based upon the instrumental temps, the recent warm anomolies would be even smaller if the graph used the satellite temps and were continued to 2008. I’m not denying there has been warming – just saying that instead of closing our minds in favor of the AGW/CO2 arguments, there could be other “natural” factors we haven’t yet properly assessed.
I can’t see anything wrong or implausible with Allan MiIlar’s suggestion #39 that we are riding on a long term natural warming trend as we are coming out of the LIA, a trend temporarily interrupted in the period 1945-1975 due to aerosols and slightly accelerated by CO2 emissions (but with far less climate sensitivity than assumed) thereafter. Indeed, as long as we are not able to pinpoint the cause of the warming between 1910 and 1945 it is quite conceivable that this natural trend continues to play a role in today’s climate change/global warming.
Dean, your attribution of early 20th century warming to natural forcers is false. Look at this graphic:
http://www.globalwarmingart.com/wiki/Image:Climate_Change_Attribution_png
Yes, insolation did increase about 1900. However greenhouse gasses also play an increasing role that runs a close second to insolation. It is only in about 1960 that ghgs predominate, but to dismiss them entirely is inappropriate. In any case to average across the boundary of the 19th/20th centuries is incorrect, as there is clearly a change in the importance of the forcers in the middle of this period.
Your contention on noise doesn’t make sense, it is only by averaging over short-term variations that the long-term trend (climate) emerges. Of course you can’t say whether any short-term trend is only noise–that’s because it’s a short-term trend! And again, what do you propose as a “cause”. Climate science has a model that explains most of the observed trends (real trends, not short-term variation masquerading in the fevered denialist mind as a trend) quite well. The denialists have bupkis, which, incidentally is why they don’t publish.
Alan (32), a minor (??) clarification. Forcing from increased CO2 is greater than a linear response.
[Response: No it isn’t. It’s logarithmic which goes up much more slowly than linear. – gavin]
From around 1940 to 1975 there was a period of about 35 years with no long term warming trend. In 1975 a strong warming trend began and in 1988 James Hansen went to Congress and made a big deal about a warming period of just 13 years. If you read his talk you will see he talked about the statistical significance of the near 0.4C anomaly of a period of just one year. I cannot find any contemporary reports of climate scientists condemning him for make long term conclusions about climate change based on a warming period of just 13 years.
> no single model
Except several. Look up Dr. Bitz’s more recent work in Google Scholar after reviewing the older topic here:
https://www.realclimate.org/index.php/archives/2007/01/arctic-sea-ice-decline-in-the-21st-century/
Mike (55), that’s the Ted Turner school of analysis: “Have you been outside today? It’s hotter than hell out there!”, which I find totally unconvincing.
Gavin (re 57), I think that is incorrect. I don’t recall the exact figure but the increase is not just logarithmic but 4-5 times the ln of the concentration ratio (or the ln of the ratio to the 4th or 5th power) which increases much faster (initially) than linear until you get to a concentration ration of 10-15. Is this not accurate?
[Response: The forcing is ~ 5.35 log(CO2/CO2_orig). If you linearise at today’s concentration, the forcing would be approximated by 0.014*(delta CO2). So at 560ppmv it would be an increase of 2.52 W/m2. But actually the additional forcing is 2.07 W/m2 – i.e. less. Therefore forcing goes up less than linearly. – gavin]
Dean, et al,
I’m not following your logic. The modelers have indicated the climate is heading in a certain direction, based on increases in CO2 and other factors. Some sample data indicate we might be further in that direction than the modelers have estimated, and you use that as evidence to reject the prediction of what direction we are heading, or what is causing the movement?
Bobzorunkle says “I’m not denying there has been warming – just saying that instead of closing our minds in favor of the AGW/CO2 arguments, there could be other “natural” factors we haven’t yet properly assessed.”
Gee, Bob, and what might those “natural” factors be?
[cricket’s chirping]
Nothing? It’s OK, nobody else has come up with anything concrete and credible either. OK, how about we do science instead. You know, make a hypothesis and then look and see if the data support it. Climate science has done that, and the data are pretty darned supportive of anthropogenic causation. We’re waiting for alternative hypothesis.
Patrick Hadley–Nobody condemed Hansen because he was doing SCIENCE. You know, looking at trends since the dawn of the industrial age, seeing if they were consistent with his models, and finding that both those and the modern data (however limited) were consistent, he made a prediction. Anybody else you know of got a proven 20 year track record of climate prediction?
Re Patrick Hadley @68: “From around 1940 to 1975 there was a period of about 35 years with no long term warming trend.”
False. As has been discussed here repeatedly, there was a sharp drop in global mean temperatures between roughly 1945 and 1950, which was followed by a shallow warming trend until roughly 1975, when the slope of the warming trend increased sharply:
http://www.globalwarmingart.com/wiki/Image:Instrumental_Temperature_Record_png
Why rely on faulty analysis or repeat deliberate disinformation when the facts are readily available?
Or (re #73) the natural factor is our natural ability to think of how to burn oil and CO2’s natural ability to cause GW.
Re Ray Ladbury @73: “Gee, Bob, and what might those “natural” factors be?”
And Bob, don’t forget to explain just how these natural factors would negate the known and demonstrated radiative physics of greenhouse gases.
Gavin (re 71), maybe I’m not grasping the linearization part. What is the formula that arrives at F = 0.014*(deltaCO2)? i.e: how is the 0.014 derived? are the units of delta_CO2 raw ppmv? is F in watts/meter^2? I was using straight linear math as in when X doubles, so does Y, but it now occurs to me this gives me a big units problem. Similarly, where does the 5.35 come from, mathematical formula or laboratory observation? I assume the units of the “5.35” number must be watts/meter^2; how does that happen?
0.014*280 = 3.92 (280 is delta_CO2 = 560 – 280);
5.35Ln(2) = 3.71.
Where am I going wrong here?
Thanks for any help.
[Response: This stuff is not hard to find. the formula F=5.35*log(CO2/CO2_orig) comes from a fit to line-by-line calculations in Myhre et al (1998). If you linearise at 380 ppm (noting the d(log(C))/dC=1/C), the linear formula is F=(5.35/380)*(CO2-380). Plug in 560ppmv to get what I said above and compare with the full formula. Whatever value you pick, the log formula is always smaller than the linear one. – gavin]
#57 Barton Paul Levenson
“How many times does this urban legend need to be refuted?
There is not a recent period of “no warming.” Eliminate the spaces and look here: …..”
I agree that the lack of warming since 1998 is often over-emphasised. However, those who mention it do have a point. Here’s one way to rationalise it:
(Temperatures from Hadley http://www.cru.uea.ac.uk/cru/data/temperature/hadcrut3gl.txt )
By 1990 the global temperature anomaly had already reached +0.25C in an ENSO-neutral year (average ONI ~ +0.25, threshold required for weak El Nino = +0.5) http://www.cgd.ucar.edu/cas/ENSO/enso25.jpg )
Also the AMO was starting to switch to positive phase, just as it did in the late 1920s incidentally:
http://en.wikipedia.org/wiki/Image:Amo_timeseries_1856-present.svg
In the first 7 months of 1991 the temperature anomaly was +0.26C, and a strong El Nino was in the pipeline, later to peak in 1992. We will never know how warm temperatures *should* have got by 1995, when ONI finally went below -0.1 for the first time since 1989….. +0.45C perhaps? – see later…
Instead Mt Pinatubo erupted in summer 1991, and global temperatures were lowered as a result for several years.
Finally the knock-on effects wore off and a return to a particularly strong El Nino culminated in the record global temperatures of 1998. Let’s note the average global temperature in the 2-year period 1997-1998: +0.45C.
Then we had 2 years of La Nina, keeping temperatures down at +0.28C for the period 1999-2000.
From second half of 2001 to first half of 2007
(see also http://www.cgd.ucar.edu/cas/ENSO/enso26.jpg )
ONI showed only El Nino (weak to moderate) or neutral (apart from 3 months where it crossed the threshold into weak La Nina Dec 05 to Feb 06). Thus global temperature anomalies not surprisingly went higher again: +0.44C for the period 2001-7, slightly below the +0.45C noted earlier for the period 1997-8.
Therefore, I think it would be reasonable to suggest that the underlying trend without Pinatubo was a rapid warming in the 1990s from 0.25C in 1990 to ~0.45C by 2000, then a levelling off where the 1997-8 average was never substantially eclipsed (highest was +0.48C in 2005), even with years of broadly ENSO-positive conditions and no massive volcano-induced cooling earlier in the decade (unlike in the 1980s and 1990s).
Unlike others, I’m not saying that because of all this, “global warming stopped in 1998 therefore CO2 has little effect”. All I’m saying is that it’s a reasonable way of looking at the facts, and trying too strenously to refute it is perhaps not the best way to convert reasonable newbies to the subject to consensus views on global warming.
Also according to HadCrut, we’ve seen a global increase in temperature of ~0.4C from the peak of the early 1940s (last time strongly +ve AMO and PDO http://en.wikipedia.org/wiki/Image:Pdoindex_1900-2006.gif coincided) to the recent peak. If I’m correct in saying that the bulk of that increase was up to the late 90s, and *should* have been by the mid-90s or even earlier, then this leaves a tiny bit more room for changes in solar forcing – since it’s only after the solar max of the early 90s that the trend in solar activity from 1940 took a dive http://en.wikipedia.org/wiki/Image:Temp-sunspot-co2.svg#file. Let’s take a conservative +0.1C for solar forcing. This leaves 0.3C to be explained by natural variation in 50 years. Urban heat effects? Conservative +0.1C beyond what is already factored into the temperature series/models? That leaves about 0.2C for CO2. For the sake of argument.
I think what happens in the next few years could be very telling. At the moment, I genuinely don’t know how to call it. But with every year that the global temperature fails to break new ground (say +0.50 on the Hadley measure) the more receptive I will be to arguments for lower-than-consensus climate sensitivities.
Note: please don’t people accuse me of not seeing the wood for the trees. I got that in spades on the sea ice thread when I argued that 2008 was not on a surefire course to surpass 2007’s record, and rather was likely set for an earlier and stronger recovery – yet I was correct (and incidentally ice extent is now ~1.5 million km2 more than a year ago.)
OT: This interesting new paper (public access) claims to have found evidence for significant atmospheric CO2 fluctuations from 1000 to 1500 CE (and so including the MWP). They think the scale of these changes is enough to account for some of the climate change previously ascribed to solar and volcanic forcings (although note that the recent trend of the science has been to heavily discount the importance of solar forcing for that period), and that ocean changes drove the CO2 since there is a correlation with North Atlantic SSTs. (IIRC at least one of these authors [Wagner] has done some past similar work that used the same proxy [leaf stomata] to draw some conclusions that turned out to be unreasonable.)
> I argued that 2008 was not on a surefire course
> to surpass 2007’s record
So did Connolley. So did others. It’s not the ideas, it’s the verbose argumentative confusing presentation.
I note that even though the 2007/8 La Nina was (at least judging by ONI data) not as deep or certainly nearly as long as the 1999/2000 back-to-back La Nina, the three-month-average tropical LT temperature anomaly dipped even lower in 2008, to -0.54C (Mar-May) which was lower than at any time during the satellite era, apart from during the strongest La Nina of the era i.e. 1988/1989. The recent tropical LT anomalies have been way below the surface temperature as far as I can tell, and thus ought to bring down the tropical tropospheric temperature trend relative to the surface.
http://vortex.nsstc.uah.edu/data/msu/t2lt/uahncdc.lt
#73 – “Gee, Bob, and what might those “natural” factors be?”
I am not a climate scientist so I don’t have a clue. All I know is that, as I said in my first post, it doesn’t help for AGW theorists to keep saying “We’ve got a theory and you don’t, so we’re right and you’re wrong.”
In the past, various theories were put forward on the causes of earthquakes: the Gods are angry; herd of elephants; meteors striking the earth; volcano activity; plate tectonics; elastic rebound theory; etc., etc.. At any given point in time, a theory was accepted by a consensus – until new information came to light. Just because the volcanic activity theory contained some “science”, did not make it correct. Similarly, just because the CO2 theory is based on valid science, it may not correctly explain the cause of the recent warming. A new theory may well come along which supplants CO2 as the most important cause in warming of the planet. It does not make sense to bend ourselves out of shape trying to justify a theory if the facts don’t fit. If the current models didn’t predict the levelling off of the warming, or the unusual melting of the arctic icecap, then shouldn’t a reasonable scientist acknowledge that the confidence in those models should decline? Even a little bit?
Re #78: “Urban heat effects? Conservative +0.1C beyond what is already factored into the temperature series/models?” Tch.
Unscientific guesswork about short-term trends is boring unless you’re willing to bet on it. I believe there are still open offers on that here and here. If you just want to speculate, the Watts Up With That blog would be a better place.
78 Chris said, ” I argued that 2008 was not on a surefire course to surpass 2007’s record”
Arctic sea ice set a new record low in 2008. Ice has three dimensions, not two. Extent is an improper metric, especially since thickness is far more important than either of the other two dimensions. Thickness is inversely proportional to salt content, so it trumps all. 2008 set a new record for thinness, and also for lowest volume. Extent is a red herring which has been reported ONLY because it used to be difficult to measure thickness and volume. (NSIDC says that is changing right now)
http://nsidc.org/images/arcticseaicenews/20080924_Figure3.jpg
Age is an excellent proxy for thickness and inverse salt content. First year ice is almost irrelevant – movie set ice is a good description, while older ice tells the tale. Even with a cold winter and cool summer, arctic ice STILL declined to a new record low. Age^2 * extent is a reasonable first order approximation, at least for the first 3 years. After that, the increase gets more linear. Note that 2007 was mostly >2nd year ice, while 2008 was mostly 1st year ice.
RichardC’s point about the ice volume reaching a new minimum is worth repeating. It’s also true that this summer saw the most rapid rates of ice retreat yet:
“Arctic Saw Fastest August Sea Ice Retreat On Record, NASA Data Show”
ScienceDaily Sep. 28, 2008
Recall also that the record low area coverage last summer was also due to the wind / ocean circulation pattern at the time. This was used by some bloggers to claim that “wind was responsible”, but if climate skeptics are known for anything, it’s for oversimplifying complex issues.
Thinner, young sea ice is more susceptible to being compressed by wind than is older, thicker sea ice. The discussion of the role wind played in the record 2007 low is here:
http://www.nasa.gov/vision/earth/lookingatearth/quikscat-20071001.html
This kind of complex interaction should be expected – relative to the larger question of arctic warming and land-sea temperature trends, such complexities create “noise” – even though the so-called noise is itself of interest and is not all random. Like many other climate issues, the complexity lies in the interaction between the atmospheric and oceanic systems.
It is harder to measure ice volume, but this year was probably also a record low for sea ice:
http://www.sciencedaily.com/releases/2008/10/081002172436.htm
Given that Arctic warming is predicted to lead other signs of global warming, what are other regional indicators?
1) 99% of Alaskan glaciers are retreating or stagnating – Yes, a few have seen record snowfalls, but those are in Pacific coastal regions, where more moisture is evaporating off the Pacific, which is also in line with predictions about increasing water vapor, the main feedback-forced component of CO2-induced warming.
2) The largest ice shelf (Ward Hunt) in the N. Hemisphere fractured again this past year. That’s after losing much of its mass in 2003. Similarly, in 2006, Ellesmere Island’s Ayles ice shelf collapsed. Warming ocean and atmospheric temperatures appear to be why these shelves are steadily collapsing. Again, this is due to a complex interaction of factors:
3) You also have the warming ocean and atmosphere around Greenland, and the faster-than-predicted glacial outflow there. Last time CO2 levels were near today’s, Greenland was mostly ice-free. In several hundred or a thousand years, we should expect those conditions to return.
4) The permafrost, like the ice shelves, is buffered from temperature changes by arctic sea ice. As the ice goes, ocean warming will have a larger effect inland, leading to faster permafrost melting.
So, all indicators are that Arctic warming is proceeding as predicted, only somewhat faster than the climate models suggested. The faster we add fossil CO2 to the atmosphere, the faster the warming will proceed.
bobzorunkle writes:
What are you talking about? Are you talking about a natural deglaciation? We know what causes that — changes in the distribution of sunlight over Earth’s surface. Google “Milankovic cycles.” That isn’t what’s happening now.
Chris Schoneveld writes:
What is the mechanism which causes “coming out of the LIA?” Where is the energy coming from? How does it work?
chris writes:
No. It isn’t reasonable to believe something that is demonstrably wrong. Did you look at the links I provided?
#80 Hank Roberts: “So did Connolley. So did others.”
You’re confusing the issue. It was when the ice extent trend was pointing steeply downwards in early Sep that I was the only one on North Pole Notes to argue it would turn around quickly (you’re implying to people that I was instead talking about pre-season projections.)
At least you’re concise, accusing me of “verbose argumentative confusing presentation”. I can also do concise: you’re wrong, and are gratuitous in your use of unhelpful, dismissive and hypocritical adjectives.
#83 Steve Bloom. “Unscientific guesswork about short-term trends is boring unless you’re willing to bet on it.” Your comment does not connect with your quote from my post. Attributing 0.1C of the surface record increase to urban heat effects (from micro to macro) in 50-60 years is scientifically justifiable without guesswork, and does not refer to a short-term trend. I’m sorry if it’s boring – only as boring perhaps as unscientific guesswork about the extent of aerosol-induced cooling post-1940s perhaps, which many are more than happy to indulge in. (Note: I’m not saying that UH necessarily had the effect suggested, or that aerosols haven’t had a significant effect, before those skimming my words jump into attack autopilot.)
#84 RichardC. Should really take this to North Pole Notes. Volume has the virtues of (1) still being very hard to measure despite what you say
http://scienceblogs.com/stoat/2008/10/sea_ice_thinner.php
and (2) being the most lagged indicator of all of NH warmth i.e. it should be the last indicator to turn around in any longer-term Arctic ice recovery.
Remember that on the map you link to, despite the distracting psychadelic colours, in fact ALL the ice on the RH side will start 2009 as multiyear ice according to the NSIDC’s definition:
http://nsidc.org/cgi-bin/words/word.pl?multiyear%20ice
And if there’s less 4/6+ year old ice? Why do you think the average sea ice thickness in the Arctic never got far above 3m in the twentieth century? (And the average age of all ice never got above single digits) Because most of the thickness increases come in the first couple of years, and most old ice is “old” because it is nearing the end of its natural cycle (where it thins to zero.)
Chris your comparison of temp and specific La Nina and El Nino conditions is interesting. I agree that some of the elegance is lost in the length of the post. Temperature is not the only measure to consider in examining climate sensitivity. Sea ice extent, Greenland Ice Sheet melt extent are additional measures that are exceeding model expectations.
Bobzorunkle says: “In the past, various theories were put forward on the causes of earthquakes: the Gods are angry; herd of elephants; meteors striking the earth; volcano activity; plate tectonics; elastic rebound theory; etc., etc.. At any given point in time, a theory was accepted by a consensus – until new information came to light.”
Oh, come on. This is absolute horse puckey. Find me a peer-reviewed paper that attributes earthquakes to angry Gods! At least do us the courtesy of taking the discussion seriously and sticking to SCIENCE. And while you are at it, maybe learn the difference between climate and weather.
Pray, where are those inconvenient facts that current theory doesn’t explain. It certainly has not trouble showing that if you have a La Nina, temperatures on average will fall. As to the melting of sea ice, the theory has predicted summer melt would increase on average over time. It has. Here’s a clue: It is called GLOBAL CLIMATE CHANGE for a reason–all three words are important.
Thanks Mauri, for help focusing on the interesting question in Chris’s post. Who’s working in that field, do you have pointers?
Always worth remembering the American Petroleum Institute’s Global Climate Science Communications Plan (1998):
“GCSCT members who contributed to the development of the plan are A. John Adams, John Adams Associates; Candace Crandall, Science and Environmental Policy Project; David Rothbard, Committee For A Constructive Tomorrow; Jeffrey Salmon, The Marshall Institute; Lee Garrigan, environmental issues Council; Lynn Bouchey and Myron Ebell, Frontiers of Freedom; Peter Cleary, Americans for Tax Reform; Randy Randol, Exxon Corp.; Robert Gehri, The Southern Company; Sharon Kneiss, Chevron Corp; Steve Milloy, The Advancement of Sound Science Coalition; and Joseph Walker, American Petroleum Institute.”
A few quotes…
Global Climate Science Communications Action Plan
Here, the goal is to interject doubt into the discussion. If the target was AIDS, one could point out that HIV might not really be what’s responsible – maybe it’s due to genetic factors. We know now that genetics plays a role in many diseases, and this wasn’t understood 200 years ago, so maybe HIV has nothing to do with AIDS?
This is not normal advertising or PR; this is an attempt at large-scale modification of the public perception. It’s worth noting that a well-educated and scientifically literate population is less likely to fall for the claims of tobacco science experts – unless they think they are listening to “independent objective experts.” Thus, a major aim of PR firms is to cultivate apparently independent experts who will cooperate with PR efforts. The PR firm in question that is the American Petroleum Institute’s lead is Edelman, who likely used their experience defeating “secondhand smoke” regulations as a selling point.
So, that’s the agenda of the oil and coal industry, their financial backers, their trade association, the API, and their PR firm Edelman. Edelman maintains a stable of dozens of bloggers to push their agenda on blogs, and they are the recipients of a $100 million contract from the American Petroleum Institute to “clean up the industry’s image.”
This type of blanket propaganda effort has been going on for a long time, but for some reason the U.S. press is very reluctant to write any stories about it. The memo in question list tactics such as:
Notice that the NSTA has shown up here on realclimate before in regards to their refusal to distribute free copies of “An Inconvenient Truth” to science teachers, and they’re also heavily funded by ExxonMobil.
In short, it’s a campaign of lies that targets children, among others, (sounds like tobacco, doesn’t it?) managed by Edelman and the API, all intended to sway public, media and Congressional opinion in order to prevent any laws from being passed that will reduce fossil fuel combustion.
Re bobzorunkle @82: “I am not a climate scientist so I don’t have a clue.”
Points for being honest, at least.
“just because the CO2 theory is based on valid science, it may not correctly explain the cause of the recent warming. A new theory may well come along which supplants CO2 as the most important cause in warming of the planet.”
Then again, it may not. After all, theories don’t just “come along”, they emerge from sustained study of the actual evidence. All of it.
In the meantime we know, with certainty, that increasing atmospheric CO2 will make it warmer. We also know, with certainty, that will still be the case if and when your as-yet undiscovered and unexplained “natural” factor is revealed and explained.
Why do deniers so fervently pin their hopes on as yet undiscovered and unexplained “natural” factors when reality is staring them in the face?
In #78 Chris wrote: … “But with every year that the global temperature fails to break new ground (say +0.50 on the Hadley measure) the more receptive I will be to arguments for lower-than-consensus climate sensitivities”. …
Chris, I don’t think anyone should be receptive to that, for several reasons. e.g. S.H. temperatures for Jan-Jun 2008 had marginal positive anomalies but large (.76 .85 59) positive anomalies for Jul-Sept (Sept was highest of record for S.H. according to NASA).
http://data.giss.nasa.gov/gistemp/tabledata/SH.Ts.txt
gavin, WRT to your inline comments in #2 ands #21. You indicate that volcanic forcing was included in the models used in Santer et al. Figure 3 in that paper lists the models used for the hindcast. in AR4 section 10 I believe there is a chart showing which models use which particular forcings for the 20CEN hindcast. According to that chart some of the models used by Santer ( example FGoals, but there are others) did not model historic volcanic forcing. Am I reading the Santer paper wrong or misreading the chart in AR4? So, simple question.
Did all of the models used by Santer et all include volcanic forcing or not.
[Response: No. I never said they all did. – gavin]
Barton Paul Levenson #87.
Are you suggesting that there was no such thing as a LIA (after all the hockey stick doesn’t reveal one) because we can’t come up as yet with a mechanism that could have caused it?
Maybe it was due to changes in CO2 radiative forcing (in part) since historical CO2 levels weren’t as stable as assumed by the IPCC, at least that’s what van Hoof et al. conclude from CO2 data derived from stomatal frequency analysis. Here is a link to the abstract of their paper:
http://www.pnas.org/content/105/41/15815.full
Gavin,
Sorry for the misunderstanding. You wrote:
[Response: The volcanic effects were taking into account in the models, but the precise timing of El Nino events is going to be different in each model – that in fact is a big factor in the variability of the 20 year trends. – gavin]
Perhaps you meant to say was “taken into account in some of the models,but not all” or something like that, but I apologize misreading your inline reply.
It is true, you never said “all of the models.” Given that volcanic forcing is important, recalling the role that representing volcanic forcing plays in validating GCM work, some might find it odd that models that don’t include this important forcing would be used in Santer, much less AR4. then again, maybe not. Perhaps a comparison of models using volcanic forcing versus those that don’t would be enlightening.
http://www.google.com/search?q=%2B“steven+mosher”+%2B”volcanic+forcing”
Why not summarize the answers you’ve had on similar questions and post them as an article? It’d save some retyping.
#95 Pat Neuman: “S.H. temperatures for Jan-Jun 2008 had marginal positive anomalies but large (.85 .59 .76) positive anomalies for Jul-Sept (Sept was highest of record for S.H. according to NASA).”
The land temperatures you refer to were heavily skewed by the Antarctic, where NASA GISS has very sketchy coverage, and appears to “fill in” vast areas.
For skew caused by Antarctic see:
http://tinyurl.com/4le752
and http://data.giss.nasa.gov/work/modelEt/time_series/work/tmp.4_obserTs250_1_2005_2009_1951_1980-0/map.pdf [needs rotating]
and for hint at limitations of “filling in” compare with
http://climate.uah.edu/sept2008.htm
(SH anomaly +0.10C)
Having said that, I am certainly interested as to why part of Antarctica was so warm in Sep (just as I am incidentally interested as to why much larger areas were so cold in Aug:
http://climate.uah.edu/august2008.htm )
Looking through the Antarctic station data
http://www.antarctica.ac.uk/climate/surfacetemps/
it does appear that several stations on the Antarctic Peninsula/islands to the north had a record-breaking mild September. This is interesting, don’t want to diminish from its inherent importance. However, all of the stations in the rest of Antarctica (i.e. the other ~98 per cent of its area or whatever the exact figure is) had fairly average temperatures, from what I can tell.
The same issues apply to July:
http://tinyurl.com/43kcgu (+0.85C)
http://climate.uah.edu/july2008.htm (0.00C)
Hadley’s Crutem3 SH land figures for Jul and Aug (Sep isn’t out yet) were +0.66C and +0.14C respectively, or +0.40C for the two months, compared with +0.72C for GISS. I suggest they are also skewed, but not so badly.
http://www.cru.uea.ac.uk/cru/data/temperature/crutem3sh.txt
Note that according to Crutem3, SH land temperatures in August were the coldest since 1992 and 1994 (post-Pinatubo cooling) and below the 1980s average of +0.15C. This would fit with anecdotal evidence from various countries in the SH, notably Australia (coldest August since 1944 in Sydney, for example).
UAH had Aug SH anomaly at -0.19C
http://climate.uah.edu/august2008.htm