What determines how much coverage a climate study gets?
It probably goes without saying that it isn’t strongly related to the quality of the actual science, nor to the clarity of the writing. Appearing in one of the top journals does help (Nature, Science, PNAS and occasionally GRL), though that in itself is no guarantee. Instead, it most often depends on the ‘news’ value of the bottom line. Journalists and editors like stories that surprise, that give something ‘new’ to the subject and are therefore likely to be interesting enough to readers to make them read past the headline. It particularly helps if a new study runs counter to some generally perceived notion (whether that is rooted in fact or not). In such cases, the ‘news peg’ is clear.
And so it was for the Steig et al “Antarctic warming” study that appeared last week. Mainstream media coverage was widespread and generally did a good job of covering the essentials. The most prevalent peg was the fact that the study appeared to reverse the “Antarctic cooling” meme that has been a staple of disinformation efforts for a while now.
It’s worth remembering where that idea actually came from. Back in 2001, Peter Doran and colleagues wrote a paper about the Dry Valleys long term ecosystem responses to climate change, in which they had a section discussing temperature trends over the previous couple of decades (not the 50 years time scale being discussed this week). The “Antarctic cooling” was in their title and (unsurprisingly) dominated the media coverage of their paper as a counterpoint to “global warming”. (By the way, this is a great example to indicate that the biggest bias in the media is towards news, not any particular side of a story). Subsequent work indicated that the polar ozone hole (starting in the early 80s) was having an effect on polar winds and temperature patterns (Thompson and Solomon, 2002; Shindell and Schmidt, 2004), showing clearly that regional climate changes can sometimes be decoupled from the global picture. However, even then both the extent of any cooling and the longer term picture were more difficult to discern due to the sparse nature of the observations in the continental interior. In fact we discussed this way back in one of the first posts on RealClimate back in 2004.
This ambiguity was of course a gift to the propagandists. Thus for years the Doran et al study was trotted out whenever global warming was being questioned. It was of course a classic ‘cherry pick’ – find a region or time period when there is a cooling trend and imply that this contradicts warming trends on global scales over longer time periods. Given a complex dynamic system, such periods and regions will always be found, and so as a tactic it can always be relied on. However, judging from the take-no-prisoners response to the Steig et al paper from the contrarians, this important fact seems to have been forgotten (hey guys, don’t worry you’ll come up with something new soon!).
Actually, some of the pushback has been hilarious. It’s been a great example for showing how incoherent and opportunistic the ‘antis’ really are. Exhibit A is an email (and blog post) sent out by Senator Inhofe’s press staff (i.e. Marc Morano). Within this single email there are misrepresentations, untruths, unashamedly contradictory claims and a couple of absolutely classic quotes. Some highlights:
Dr. John Christy of the University of Alabama in Huntsville slams new Antarctic study for using [the] “best estimate of the continent’s temperature”
Perhaps he’d prefer it if they used the worst estimate? ;)
[Update: It should go without saying that this is simply Morano making up stuff and doesn’t reflect Christy’s actual quotes or thinking. No-one is safe from Morano’s misrepresentations!]
[Further update: They’ve now clarified it. Sigh….]
Morano has his ear to the ground of course, and in his blog piece dramatically highlights the words “estimated” and “deduced” as if that was some sign of nefarious purpose, rather than a fundamental component of scientific investigation.
Internal contradictions are par for the course. Morano has previously been convinced that “… the vast majority of Antarctica has cooled over the past 50 years.”, yet he now approvingly quotes Kevin Trenberth who says “It is hard to make data where none exist.” (It is indeed, which is why you need to combine as much data as you can find in order to produce a synthesis like this study). So which is it? If you think the data are clear enough to demonstrate strong cooling, you can’t also believe there is no data (on this side of the looking glass anyway).
It’s even more humourous, since even the more limited analysis available before this paper showed pretty much the same amount of Antarctic warming. Compare the IPCC report, with the same values from the new analysis (under various assumptions about the methodology).
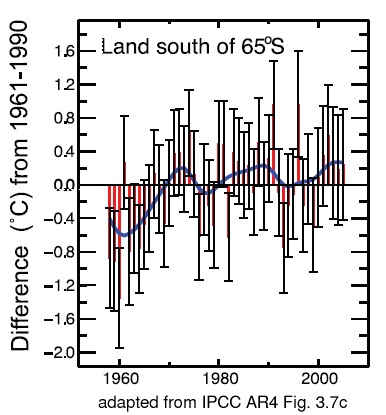
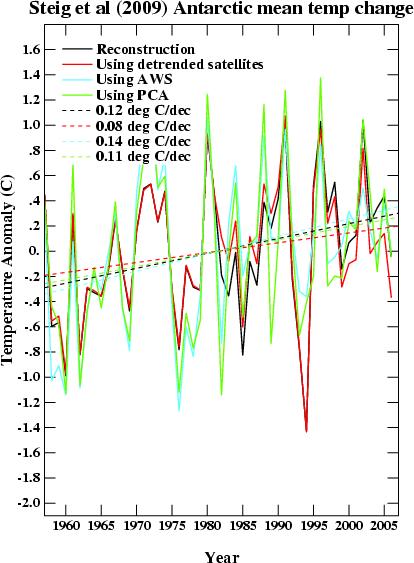
(The different versions are the full reconstruction, a version that uses detrended satellite data for the co-variance, a version that uses AWS data instead of satelltes and one that use PCA instead of RegEM. All show positive trends over the last 50 years).
Further contradictions abound: Morano, who clearly wants it to have been cooling, hedges his bets with a “Volcano, Not Global Warming Effects, May be Melting an Antarctic Glacier” Hail Mary pass. Good luck with that!
It always helps if you haven’t actually read the study in question. That way you can just make up conclusions:
Scientist adjusts data — presto, Antarctic cooling disappears
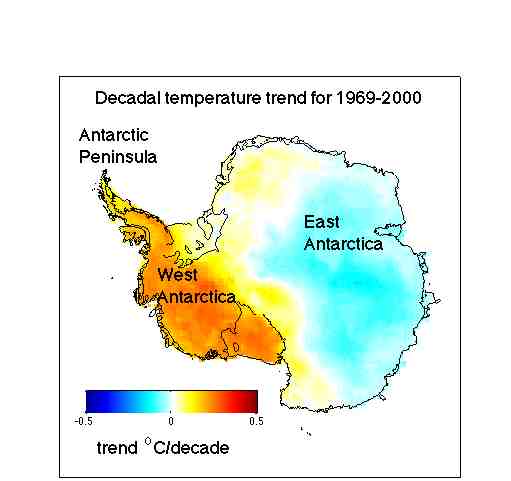
Nope. It’s still there (as anyone reading the paper will see) – it’s just put into a larger scale and longer term context (see figure 3b).
{kind=link}
Inappropriate personalisation is always good fodder. Many contrarians seemed disappointed that Mike was only the fourth author (the study would have been much easier to demonise if he’d been the lead). Some pretended he was anyway, and just for good measure accused him of being a ‘modeller’ as well (heaven forbid!).
Others also got in on the fun. A chap called Ross Hays posted a letter to Eric on multiple websites and on many comment threads. On Joe D’Aleo’s site, this letter was accompanied with this little bit of snark:
Icecap Note: Ross shown here with Antarctica’s Mount Erebus volcano in the background was a CNN forecast Meteorologist (a student of mine when I was a professor) who has spent numerous years with boots on the ground working for NASA in Antarctica, not sitting at a computer in an ivory tower in Pennsylvania or Washington State
This is meant as a slur against academics of course, but is particularly ironic, since the authors of the paper have collectively spent over 8 seasons on the ice in Antarctica, 6 seasons in Greenland and one on Baffin Island in support of multiple ice coring and climate measurement projects. Hays’ one or two summers there, his personal anecdotes and misreadings of the temperature record, don’t really cut it.
Neither do rather lame attempts to link these results with the evils of “computer modelling”. According to Booker (for it is he!) because a data analysis uses a computer, it must be a computer model – and probably the same one that the “hockey stick” was based on. Bad computer, bad!
The proprietor of the recently named “Best Science Blog”, also had a couple of choice comments:
In my opinion, this press release and subsequent media interviews were done for media attention.
This remarkable conclusion is followed by some conspiratorial gossip implying that a paper that was submitted over a year ago was deliberately timed to coincide with a speech in Congress from Al Gore that was announced last week. Gosh these scientists are good.
All in all, the critical commentary about this paper has been remarkably weak. Time will tell of course – confirming studies from ice cores and independent analyses are already published, with more rumoured to be on their way. In the meantime, floating ice shelves in the region continue to collapse (the Wilkins will be the tenth in the last decade or so) – each of them with their own unique volcano no doubt – and gravity measurements continue to show net ice loss over the Western part of the ice sheet.
Nonetheless, the loss of the Antarctic cooling meme is clearly bothering the contrarians much more than the loss of 10,000 year old ice. The poor level of their response is not surprising, but it does exemplify the tactics of the whole ‘bury ones head in the sand” movement – they’d much rather make noise than actually work out what is happening. It would be nice if this demonstration of intellectual bankruptcy got some media attention itself.
That’s unlikely though. It’s just not news.
Worrying post on Climate audit about Gill and Harry which appears to undermine Steig’s data. Any thoughts
[Response: See above – gavin]
Re response to 148: How does a typo like that get past 6 authors and peer reviewer(s)?
[Response: You’ve never worked as an editor have you? Typos happen, you just have to deal with it. – gavin]
Definitely some interesting points about the nature of journalism and how information spreads. This is stuff we need to know if we want to stop climate change.
gavin: “It would have been nice had SM actually notified the holders of the data that there was a problem (he didn’t, preferring to play games instead). If he hadn’t left it for others to work out, he might even have got some credit ;)”
Isn’t it rather petty (as well as possibly unethical) to refuse credit because you don’t like the source or their methods of communication?
[Response: People will generally credit the person who tells them something. BAS were notified by people Sunday night who independently found the Gill/Harry mismatch. SM could have notified them but he didn’t. My ethical position is that it is far better to fix errors that are found than play around thinking about cute names for follow-on blog posts. That might just be me though. – gavin]
First, there has to be an attempt to communicate…
Or are you suggesting that scientists have to monitor every whackjob blog out there in hopes that one author has found an error in the scientist’s work?
RE 148: gavin,
Steig asked SM not to communicate with him anymore. The only way to take this beyond personalities is for scientists to publish their data and publish their code so that others can reproduce the results and point out errors if any exist. Part of the appeal of CA is the “detective story.” That goes away when data and source code are freely published. As before when SM has found errors the best course of action is to thank him and move on with the science. It’s not that hard. “Thank you SM for finding this error.”
[Response: This data error has nothing to with Steig or any of his co-authors. SM should have contacted BAS. I’m sure BAS are grateful that someone told them about the data mess up – it just didn’t happen to be SM. If he wasn’t so set on trying to embarrass people or stir up fake ‘accusations against Hansen’ then he’d probably find people would be more willing to deal with him. But it is the same pattern every time. Some trivial thing is blown out of all proportion and the greek chorus start piling on, because of course, they knew it was wrong anyway. SM could have easily seen that the typo in the Table was just a typo (the actual lat/lon used are here) – but he chose not to bother for some reason, thus sprouting all sorts of ill-informed nonsense. By continually overblowing trivialities, he lacks credibility on anything more serious. Science is not a game of gotcha, it’s a serious endeavour to make sense out of a complex and confusing world. It’s difficult enough at the best of times, and very few people have the patience to deal with people who aren’t constructive. Life is just too short. – gavin]
Maybe this will be helpful thought. There is big difference between the level of analysis generally found on blogs, or the backs of envelopes, and what goes into a proper article in the literature. Technical papers like Steig et al don’t consist of just one calculation. Quite rightly, the results from such a calculation might be suspect because of the dependence on a single input dataset and a single methodology. Thus in preparing a paper, authors are generally careful to make use of alternate methodologies (in Steig’s case, using the AWS data or the AVHRR data, using PCA or RegEM, trending vs. detrending the data that goes into the covariance matrix etc.). In this way, the robustness of the results to relatively arbitrary choices can be assessed. This is the kind of thing that reviewers insist on and it is generally only the robust results that get published.
The other key point is that science works because it builds on the work of others – not because everyone else’s work is assumed to be perfect (it never is), but because it is impossible to progress otherwise. When issues are found in data that went into an analysis (such as in this case), the downstream work is re-assessed, but since the papers have already tested the robustness of the conclusions to including or not this source of data, the implications are generally going to be small.
Gavin said
My ethical position is that it is far better to fix errors that are found than play around thinking about cute names for follow-on blog posts. That might just be me though.
I generally agree. SM could be more constructive and I do think he has a quite remarkable talent for missing the wood for the trees in terms of his overall approach. That said, there does need to be a two way street. [edit]
[Response: This wasn’t Steig’s data. The communication should have been with BAS. – gavin]
So what do the errors noted by SM do to the results of Steig’s report? The error was used in the Steig analysis, was it not?
[Response: Very little, but we’ll post something on this tomorrow. In the meantime, note that it is basically only figure S3 that uses the Harry AWS data (along with a correlation used as validation in fig. S4b and the dashed line in fig 2). – gavin]
Has Steig archived all code and data used in the Steig et al paper to a publicly available website? Or did he just provide a reference to various sites holding the data (that can get revised)?
[Response: You raise a good question. Steig’s archiving is at http://faculty.washington.edu/steig/nature09data/ and you can see that the data sources are referenced to the originating organisations (who can and do update data, fix errors etc.). Ideally, for ‘movable’ datasets, one would want a system where snapshots in time were recoverable (and citable), along with pointers to the up-to-date versions, forward citation to publications that had used various versions and the ability to update analyses as time went on. What you don’t want is mostly duplicate data sets that aren’t maintained floating around in the grey zone – that will just lead to confusion. Google were actually working on such a system, but have unfortunately lost interest. Other organisations such as BADC are thinking along those lines, but it is a sad fact that such a system does not yet exist. – gavin]
Gavin, you say:
Are you saying that Harry is not used in the full reconstruction?
[Response: That is correct. – gavin]
I thought you earlier said:
How can Harry be removed if it isn’t in the reconstruction in the first place?
[Response: I think I misspoke there. Figure S4b is what you get if you use only 15 of the 42 manned weather stations. The correlations to the others and to the 4 AWS stations are given just as validation. What I should have suggested is that you compare fig S3a, with fig S4a – or indeed, fig 2. I will correct the comment above. – gavin]
It would be great if you could clarify this, as the Steig SI is frustratingly vague on this point. It says
However Table S2 has 46 series (including Harry). So is Harry in the full reconstruction or not?
[Response: Table S2 says it has “List of the 42 occupied weather stations … and four automatic weather stations (AWS)” (i.e. 46 entries). Only the 42 occupied stations are used to provide the data back to 1957. The AVHRR data, or the AWS data are used only for calculating the co-variance matrices used in the different reconstructions. Thus the reconstruction can either use the covariance with AVHRR to fill the whole interior back to 1957 (the standard reconstruction), or the covariance with the AWS data to fill the AWS locations back to 1957. – gavin]
RE Gavin’s response to my post #137, Gavin said, “When you go to the dentist, and he tells you to put fluoride on your kids teeth, do you do it?”
I place a lot of value on my dentist’s recommendations, but I would make sure that my decision was an informed decision. I am actually old enough to remember the flouride debate, and I would not need to discuss this particular issue with my dentist, but, I do take L****** (a anti-cholesterol) on my doctor’s advice, and I did ask questions of both my doctor and my pharmacist and did my own research before beginning the treatment.
[Response:I am going to jump in here, although I am very busy getting ready for my trip to Antarctica. First of all, I said this, not Gavin. Second, you are missing my point because you are quoting it out of context. My comment was made in response to someone saying “I don’t know who to believe.” The point is that we all have to make decisions in life, and we can’t possibly all research everything in great detail. We all constantly make decisions based on our trust in experts. It is impossible to operate otherwise — our society works because of it. I was not saying “trust everything scientists say”. I was saying “use your head and make an informed decision.” One has a responsibility to oneself — and one’s children, whether in the dentist example or in the case of environmental issues — to either inform yourself fully, or figure out whom to trust. What is irresponsible is to wallow in an “I don’t know whom to trust” limbo.–eric]]
I think this point is quite relevant to the AGW debate. While I do not reject most of the arguments supporting AGW, I do think it is somewhat arrogant of AGW supporters to use the argument that we should defer to the experts and accept their opinions without critically examining all of the aruguments ourselves. I think it is every citizens responsibility to make informed decisions on important topics, even if that means spending a great deal of time to understand the issues involved.
While the core science supporting AGW is sound, easily understandable and accepted even by a large number in the denialist camp (although not everyone), which is that the direct response to a doubling of CO2 from pre-industrial levels can be expected to increase global temperatures by approximately 1.2C, plus or minus some small uncertainity. Where the science is much less certain is both, what is the scale of the feedbacks and what are the consequences of the total effects (direct plus feedback) of CO2 warming?
I think that AGW science could benefit enormously from better transparency and spending less time being critical of its critics. It is my understanding that science is the process of developing a hypothesis, testing that hypothesis and then putting everything out in the open for others to prove or disprove. That is certainly the process by which the theory of relativity gained acceptance (way back at the beginning of the 20th century). It was not through peer review and consensus. And if climate science embraced this approach, then there would be much less room for debate.
Gavin said, “My ethical position is that it is far better to fix errors that are found than play around thinking about cute names for follow-on blog posts. That might just be me though.”
I fully agree with your statement Gavin, but don’t you think that if AGW papers such as the Steig analysis provided more transparency by providing all of the code and data upfront, that this would greatly disarm the opponents and contribute to advancing the science more than these blog wars do?
[Response: ALL of the data that were used in the paper, and EXACTLY the code used in our paper have been available for a long time, indeed, long before we published our paper. This is totally transparent, and attempts to make it appear otherwise are disingenuous. This has always been clear to anyone that asked. If you wanted to do the work yourself, for legitimate reasons, you could do so. If the point is to “audit” our work, it makes no sense whatsoever to provide all the intermediate products used in our analysis. That would defeat the purpose of the supposed “audit”.–eric]
Gavin, it’s simple question : “So is Harry in the full reconstruction or not?”
[Response: And he gave a simple answer, which is the same answer that is very very obvious to anyone reading our paper. The answer is NO.–eric]
Eric’s response in #162, “ALL of the data that were used in the paper, and EXACTLY the code used in our paper have been available for a long time, indeed, long before we published our paper. This is totally transparent, and attempts to make it appear otherwise are disingenuous.”
My mistake Eric, Gavin’s response on archiving in #160 showed up after I posted #162. Just one more question: Excluding your study, would it be your opinion that code and data archiving practices are adequate in the climate science community, overall? This is a common complaint on sites like CA.
Have a nice trip.
[Response: Yes, I think we do a fine job. We could do better, but we do very very well. I’ve never had trouble getting data that I need from others. Indeed, our Nature study was based entirely on freely available data and code.–eric]
“attempts to make it appear otherwise are disingenuous”
Eric, perhaps you know something I don’t, but don’t you think that statement is a bit strong? Maybe people were jumping to conclusions but disingenuous?
Personally, I would prefer to see open and unqualified access to data and code. Quackery would be exposed and legitimate scrutiny would advance the science.
[Response: Nope I don’t think it is a bit strong. I released an electronic version of our data and links to all the original data and code almost as soon as our paper was published. Anyone paying attention would know that. Releasing it earlier would have broken the embargo policy that I signed in agreeing to have my work published in Nature. The embargo policy is designed precisely to avoid the rampant speculation that we were seeing on the web, even before the paper was published. To wit: “This [policy] may jar with those (including most researchers and all journalists) who see the freedom of information as a good thing, but it embodies a longer-term view: that publication in a peer-reviewed journal is the appropriate culmination of any piece of original research, and an essential prerequisite for public discussion.”-eric]
“If the point is to “audit” our work, it makes no sense whatsoever to provide all the intermediate products used in our analysis. That would defeat the purpose of the supposed “audit”.–eric”
Sorry isn’t precisely what auditing is all about? Checking each and every step a CFO takes to create its balance sheet especially when data flaws are found?
[Response: A good auditor doesn’t use the same Excel spreadsheet that the company being audited does. They make their own calculations with the raw data. After all, how would they know otherwise if the Excel spreadsheet was rigged? Mike Mann articulated this distinction very thoroughly in the discussions with the National Academy during the “hockey stick” debate. You should read this material; it’s enlightening (I will post the link when I find it). In any case, you’re pushing this analogy too far. Science is not the same as business. The self-appointed auditors of climate science don’t seem to understand that science has a built-in-auditing system — the fact that by proving someone else wrong, especially about an important issue, is a great way to get fame and success. There is no comparable mechanism in business. The analogy between auditing business and auditing science is therefore a poorly conceived one. But as long as the analogy is out there, consider how auditors are chosen and regulated in the business world. You don’t get to be an auditor merely by launching a blog, and you certainly don’t publicly speculate about your findings before (or even after) you’ve done the analysis. Above all, you have to demonstrate competence and integrity, and the company you work with has to trust you, or they won’t hire you.–eric]
What’s wrong with the Filchner Shelf largest ever measured 331 km by 97 km 31,000 km2 ice shelf collapse “The largest iceberg ever spotted was sighted by the USS Glacier on November 12, 1956″. it measured 208 miles by 60 miles.”? It’s 10 times bigger than the Larsen B of 2002 and it happened over 50 years ago when CO2 level was less than now.
So either the reference to Larsen B in your post is relevant and thus my comment is by indeed offering a perspective to your readers or if my comment is irrelevant -hence its deletion- then it means your reference to Larsen B is just a cheap shot.
[Response: You are confusing a normal and periodic calving event with the total collapse of an ice shelf – kind of like the difference between a haircut and decapitation. -gavin]
Eric wrote: “A good auditor doesn’t use the same Excel spreadsheet that the company being audited does. They make their own calculations with the raw data. After all, how would they know otherwise if the Excel spreadsheet was rigged?”
Utterly wrong.
Auditors have access to all the company financial information including intermediate values across subdivisions and inclusive of budgets, forecasts and sales revenue. They rarely run the whole year’s financial data through again, that would be ridiculously expensive. Instead they do a series of tests against the accounts based on subsets of data. It is because of this that they need exactly the intermediate information that has been asked from climate researchers. The data used must (by law) be archived, not subject to the vagaries of external sources. The company directors are liable for the veracity of the data and its maintenance, punishable by imprisonment. No decent sized company uses “spreadsheets” for its accounts, [edit] and needs to have an audit trail that survives for 7 years.
(former CEO of a publicly listed company, Computer Scientist and researcher)
[Response: You didn’t read what I wrote. Try again.–eric]
re 1666
Eric Steig comments:
A business audit is an assessment of the judgments made by the financial department of a company. Creating the accounts of a company is a major undertaking. For a Fortune 500 company this would take hundreds or thousands of people working overtime to clear the books in time for the quarter or year end. Auditors would not be expected to replicate this work and it would be pointless if they did.
The auditors are not hired to replicate this work. They are hired to ensure that the judgments made in creating the books are sound. Their work goes far beyond Excel but, if necessary, they would check that the spreadsheets used were competently put together.
The output of the auditing process is a statement about whether the books can be relied on or not. It is not another set of books.
re 160
Gavin, you have pointed out Steig’s archiving a number of times in these comments: http://faculty.washington.edu/steig/nature09data/
But every time I try to follow this link it comes up blank. Am I missing something?
[Response: yes. It works fine for me. Try going to Eric’s faculty page and following the link from there. Or try a different browser. There was one very minor html error, which has now been fixed. – gavin]
I managed to find the raw data used in the study even though I didn’t know that Steig et al. had posted links or an archive. I used google.
I certainly don’t need their computer code. All the methods used are pretty standard these days, they’re well documented in the peer-reviewed literature, and if I wanted to check whether they got it right I wouldn’t use their computer code, I’d write my own.
But I’m not going to. I actually trust those guys. As for the folks flinging criticism and accusations — I do not trust those guys.
The accusations and implications of dishonesty and/or incompetence related to the Steig et al. paper are disgusting. The only thing they reveal is that some of the “critics” are ethically bankrupt.
Still on the auditor analogy: when an auditor says “how do you get to this number?” you don’t hand him a pile of receipts and tell him “work it out yourself”. If you do that, he will think there’s something funny with your numbers. You let him actually check the work that you’ve done.
It seems to me that SM constantly complains that he doesn’t get the intermediate workings, which would allow him to see which steps have been taken and replicate the results. And given that he does have a record of finding data errors (in this latest case, errors that had remained undetected for months, including while they were being included in a peer-reviewed paper) he probably has a pretty good idea of what is and is not needed, to check through a data analysis.
[No, he doesn’t. He has a good record of blowing typos in a paper all out of proportion, and using trivia and speculation to try to insinuate that researchers purposefully manipulated data, leading to a huge amount of wasted time on the part of researchers, not to mention government officials and the National Academy of Sciences. Nothing has been learned from this exercise other than one should be extremely careful in dealing with SM.–eric]
What I don’t understand is simply, why don’t you routinely publish those intermediate steps. Most people don’t have the scientific background, or the free hours, to truly dig into the data. However most people with real-world experience know transparency when they see it. And I don’t think most people would consider this transparency:
“If the point is to “audit” our work, it makes no sense whatsoever to provide all the intermediate products used in our analysis. That would defeat the purpose of the supposed “audit”.–eric”
[Response: I do routinely make all our data available, as does everyone else that I know. In this particular case, anyone legitimate who has asked for all our data, including the intermediate steps, has received it. To continue with the analogy with financial auditing, let me very clear on what I mean by legitimate: In the business world, auditors 1) don’t publicly accuse a company of withholding data prior to requesting said data; 2) are not self-appointed; 3) have to demonstrate integrity and competence; 4) are regulated. On this point, if you are suggesting that Steve McIntyre be regulated by an oversight committee, and have his auditor’s license revoked when he breaks ethical rules, then we may have something we can agree on.–eric]
RE: tamino – 3 February 2009 at 7:57 AM
I don’t think that it is a matter of trust or honesty. Science is advanced by others being able to replicate and confirm a study’s results and all of its methodologies. The more information that is provided to facilitate this process the more science is advanced. I realize that many people’s motives are questionable, but that shouldn’t be a consideration for determining how much documentation is provided. The goal should be to allow others to easily perform critical analysis of a given study and either confirm its conclusions or identify any problems that exist in its methodology or results. Science is advanced either way.
I work for a software development company that develops computer models for business and life science applications. I realize this is more of an engineering scenario, but we meticulously archive all of our code and data using an advanced version control system so that every step in the process can be revisited and evaluated at anytime there is a question about how we got to our final results. We want there to never be any ambiguities in any of our processes.
While I may be comparing apples to oranges here, it would seem to me that science would benefit from the same meticulous approach. And please don’t misunderstand me, I am not suggesting that there was anything sloppy in the way this was handled in this study or in any other particular study. But, I do think there is somewhat a lack of emphasis in climate science in performing the level of detail archiving (including intermediate steps) that is considered standard operating procedure in both business and engineering.
[Response: You are confusing a normal and periodic calving event with the total collapse of an ice shelf – kind of like the difference between a haircut and decapitation. -gavin]
Sorry, that’s a [edit] judgement call, especially if the total collapse is 10 times smaller than the calving…
[Response: Not in percentage terms. Filchner is just a much larger system, and you will note, it is still there. – gavin]
Dr. Steig,
As to your comments on auditors I think this analogy has been stretched beyond the breaking point. In the financial world there are lots of people who work outside of companies analyzing their financial results. Many companies find them very irritating, but they serve a useful function for investors, and sometimes find issues that the paid auditors didn’t find. As much as you seem to dislike Mr. McIntyre this seems to be how he is functioning in this area.
When you say that you will only supply data to people who are “legitimate” it would be possible that there is selection bias on your part, which would not be productive.
This is where SM’s auditing analogy breaks down.
In the US at least, auditors are required to be CPAs. They are subject to regulations designed to ensure ethical behaviors. These include confidentiality rules and the like.
What SM does is in no way analogous to how the auditing of business works.
Not that the auditing paradigm is particularly useful in the context of science. But if it were, if SM were serious about establishing such a system of accountability, he’s be pushing for licensing and ethical regulations that would very like put an end to most of his activities at CA.
Eric, intermediate operating processes are docmented and audited all the time. It is a way of checking to see if the steps taken to produce a product have followed pre-determined procedure. Whether the pre-determined procedure is “rigged” is a separate matter subject to other angles of quality scrutiny.
Nobody who knows anything about Excel or spreadsheets goes into a company to assess anything and relies on their Excel spreadsheets.
You’ve heard the phrase “Trust, but verify.”?
http://scholar.google.com/scholar?q=%22spreadsheet+errors%22
Note that auditors, at least in the USA, are not licensed. The successful resistance to the attempt to license auditing was one of the great victories of the opposition to the New Deal. We have “generally accepted auditing principles” as the measure of good work.
A history well worth reading on this is slowly being written, e.g.:
http://scholar.google.com/scholar?q=merino+auditing+history
ReCaptcha assesses auditors:
____________________
“available creative”
There is one thing I do not understand. My company’s software products are used by businesses to make multi-million dollar tactical and strategic planning decisions. Our systems collect data from many sources within a company, including from ERP systems such as SAP. We make no assumptions about the quality of the data, and the first thing we do is perform a myriad of quality checks before we use the data ourselves. Neither the Harry data nor the NOAA/GISS Septemeber/October Siberian data would have made it past our filters.
[Response: Could you pass them along then? Filters are great at finding issues that have been seen before and can be tested for. Filters that find errors independent of any context or history would be of great use in many fields. – gavin]
Given that these trivial data issues such as Harry provide so much fodder for your detractors, why is more effort not made to quality check the data. I really think the reasoning that the data belongs to someone else and it is their responsibility to perform the quality checks is a very weak and indefensible argument. The statistical checks to catch these types of errors are well known in the software industry and readily available in open source as well as commercial packages.
We could never allow our software and our company’s reputation to be subject to this type of embarrassment. Blaming a multi-million dollar failure on SAP because that is where we got the data from would just not be an option for us.
[Response: So how many millions of dollars do you invest to prevent it? Perhaps you could write to NASA and request an equivalent level of funding? The point being that millions of dollars don’t depend on a single Antarctic weather station. – gavin]
From this Home Page you’ll see the first item under Highlights an item that starts;
“NEW Geochemical Data Quality Control Issue:
Quality control issue identified with some geochemical data produced by the Denver Energy Geochemical Laboratory from 1996-2008.”
and these two links:
http://energy.usgs.gov/geochemstatement.html
http://energy.cr.usgs.gov/gg/geochemlab/labqc/labissue_table.html
Auditing and Verification are important.
[Response: Oh please. No-one is saying that quality control is not important, nor that lab-standards shouldn’t be checked. – gavin]
re 176.
But I don’t remember seeing part of the documentation “Checked the spreadsheet they used for accuracy and errors”.
And look at how well they’ve done auditing accounts for Enron, et al…
RE 171. Tamino.
Let me suggest that you might not have found the raw data used in the study. What you found was the current version of the data cited or referenced in the study. The difference is subtle but sometimes important.
I’ll explain. Let’s suppose that you write a paper in 2006. And lets suppose that you cite or point to a GISS dataset for GMST. In 2006 that dataset will have temperatures for 1880-2006. All well and good.
Now, in 2009 I seek to replicate the analysis and perhaps run some sensitivity analysis on your methods. What do I do? I go to the dataset you cite. I download the current version of GISS GMST, circa 2009. Correct? And I look at the data from the years 1880-2006. The assumption here is that
1. GSMT for 1880-2006 circa 2006 IS THE SAME AS
2. GSMT for 1880-2006 circa 2009.
But anyone who has looked at GISS GSMT over the months and years knows that is not the case. As new data comes in, changes are made that cascade back years and decades. I’m not criticizing that feature of GISS GSMT. It’s simply a fact. It’s not a fact that contradicts AGW, but it’s a fact. The subtle difference comes down to this. You actually want the data AS USED in the study, not the data AS CITED. Now if data were provided with versioning, change logs, etc then it would be easy to figure out the data AS USED. Does any of this make a difference WRT to the truth of AGW? I suspect not. But that’s not the point. What one really wants wants is the data AS USED, the code AS USED, and a description of the computer system the study was completed on.
[Response: Actually no. You want to know what is actually happening to the world. Well, scientists do. Knowing whether someone did their rounding correctly, or used the right formula for a linear trend 3 years ago is purely of academic interest (i.e. of no interest at all). If there is an analysis that uses the global mean temperatures, you definitely want to know whether the original conclusions are robust to updates in the data. That is much more scientifically interesting. Would it be nice if everyone used clever software that included a time history of all changes? sure. Is that scientifically interesting? no. For a product that is updated every month, and then periodically has tweaks to it’s algorithm, the only sensible way to do this is to have it built in to the design from the start, so that storage and accessibility don’t become burdensome. As I said above, Google developed a product that did this, but have since lost interest. Doing it on an adhoc basis just leads to confusion and a proliferation of out-of-date, unreferencable and orphaned datafiles. If you want to develop an open source software package that allows this – go ahead, there would be a lot of interest. Maybe it exists already? – gavin]
Gg Says (3 February 2009 at 10:13 AM):
“What I don’t understand is simply, why don’t you routinely publish those intermediate steps.”
It might be instructive to discuss some of the details of scientific publishing, such as page counts and charges. I’m sure the contributors could do a better job than I can (one of the benefits of being where I am is that I’m seldom a lead author or PI, and so can leave such nitty-gritty details to others), but the short message is that it takes money to publish a scientific journal, and part of the cost is often recouped by a per-page charge on published papers.
Each journal is also going to have a fixed number of pages available in each issue. If that number is for instance 80 pages, it can accept 10 8-page papers, or just one with all the intermediate steps included. So if you submit such a paper, guess what your chances of acceptance are going to be?
Re: 170
I can now successfully follow the link to the Met READER data, found here: http://www.antarctica.ac.uk/met/READER/data.html That web page currently shows the following text:
—-
Note! The surface aws data are currently being re-proccessed after an error was reported in the values at Harry AWS (2/2/09)
The incorrect data file for Harry temperatures will be made availabe once they are recovered from backups
—-
Let me just say, that I am not accusing anyone of anything, except perhaps having bad luck picking data that were not entirely correct. Which unfortunately went undetected.
What I am wondering is, with the corrected Harry data, will the calculations done in the paper still yield the same results and lead to the same conclusions?
[Response: Yes. Already done it. No meaningful change (except at Harry itself of course). Furthermore, the main figures in the paper use no AWS data in the first place. None. This is totally clear in the text, if you read it. The AWS data are only a double-check on the results from the satellite data.–eric]
People are making an error common to those comparing science to commercial software engineering.
Research: *insight* is the primary product.
Commercial software development: the *software* is the product.
Of course, sometimes a piece of research software becomes so useful that it gets turned into a commercial product, and then the rules change.
===
It is fairly likely that any “advanced version control system” people use has an early ancestor or at least inspiration in PWB/UNIX Source Code Control System (1974-), which was developed by Marc Rochkind (next office) and Alan Glasser (my office-mate) with a lot of kibitzing from me and a few others.
Likewise, much of modern software engineering’s practice of using high-level scripting languages for software process automation has a 1975 root in PWB/UNIX.
It was worth a lot of money in Bell labs to pay good computer scientists to build tools like this, because we had to:
– build mission-critical systems
– support multiple versions in the field at multiple sites
– regenerate specific configurations, sometimes with site-specific patches
– run huge sets of automated tests, often with elaborate test harnesses, database loads, etc.
This is more akin to doing missile-control or avionics software, although those are somewhat worse, given that “system crash” means “crash”. However, having the US telephone system “down”, in whole or in part, was not viewed with favor either.
We (in our case, a tools department of about 30 people within a software organization of about 1000) were supporting software product engineers, not researchers. The resulting *software* was the product, and errors could of course damage databases in ways that weren’t immediately obvious, but could cause $Ms worth of direct costs.
It is easier these days, because many useful tools are widely available, whereas we had to invent many of them as we went along.
By late 1970s, most Bell Labs software product developers used such tools.
But, Bell Labs researchers? Certainly no the physicists/ chemists, etc, an usually not computing research (home of Ritchie & Thompson). That’s because people knew the difference between R & D and had decent perspective on where money should be spent and where not.
The original UNIX research guys did a terrific job making their code available [but “use at your own risk”], but they’d never add the overhead of running a large software engineering development shop. If they got a bunch of extra budget, they would *not* have spent it on people to do a lot of configuration management, they would have hired a few more PhDs to do research, and they’d have been right.
The original UNIX guys had their own priorities, and would respond far less politely than Gavin does to outsiders crashing in telling them how to do things, and their track record was good enough to let them do that, just as GISS’s is. They did listen to moderate numbers of people who convinced them that we understood what they were doing, and could actually contribute to progress.
Had some Executive Director in another division proposed to them that he send a horde of new hires over to check through every line of code in UNIX and ask them questions … that ED would have faced some hard questions from the BTL President shortly thereafter for having lost his mind.
As I’ve said before, if people want GISS to do more, help get them more budget … but I suspect they’d make the same decisions our researchers did, and spend the money the same way, and they’d likely be right. Having rummaged a bit on GISS’s website, and looked at some code, I’d say they do pretty well for an R group.
Finally, for all of those who think random “auditing” is doing useful science, one really, really should read Chris Mooney’s “The Republican War on Science”, especially Chapter 8 ‘Wine, Jazz, and “Data Quality”‘, i.e., Jim Tozzi, the Data Quality Act, and “paralysis-by-analysis.”
When you don’t like what science says, this shows how you can slow scientists down by demanding utter perfection. Likewise, you *could* insist there never be another release of UNIX, Linux, MacOS, or Windows until *every* bug is fixed, and the code thoroughly reviewed by hordes of people with one programming course.
Note the distinction between normal scientific processes (with builtin skepticism), and the deliberate efforts to waste scientists’ time as much as possible if one fears the likely results. Cigarette companies were early leaders at this, but others learned to do it as well.
Dr. Schmidt,
I really don’t understand your point about data archiving. Since many data sources might be involved in a single paper, the simplest thing is for the author of the paper to archive the data that is actually used. A far more complex problem would be to allow any data set to be accessed as of any point in time. This is in fact not something that could be accomplished easily by someone like Google AFAIK.
It also seems quite simple that the actual code used to get from the data to the result be published.
These are very small things to ask from someone who is publishing a statistical paper. As Dr. Steig said, he has all this information he is just selective about who to send it to.
> many data sources might be involved in a single
> paper, the simplest thing is for the author of the
> paper to archive the data that is actually used
Er. No. First rule of database management: one list, many pointers.
A list of errata and corrections is appropriate in journals (in data source A, after publication, an error in this number was corrected, and changed to that number; the difference in the result that was published, when recalculated using the corrected data, amounts to so-much). That’s what’s being accumulated here; wait and see how the journal, more tersely, handles it.
Once you get multiple copies of database sources that appear to be complete copies, as over time errors in the original are found and corrected, the number of wrong versions and secondary copies of the wrong versions grows.
Google’s idea, as of a year ago. Did anybody reading get one of the data drives they were handing out?
http://arstechnica.com/science/news/2008/01/rumors-suggest-google-is-set-to-open-scientific-data-store.ars
“… Google has been helping scientists distribute large datasets, three terabytes at a time. That’s the capacity of the RAID cabinets that Google was shipping—on its dime—to scientists and other researchers that needed to get large volumes of data to other researchers around the world. As we noted, Google was keeping a copy of the data as well ….”;
That’s what got cancelled, apparently.
Hank (re. #187),
While I agree that when working with databases, you only want 1 version, but that’s not what this is about. This seems more akin to working with reports from the databases. Those reports are rather easy to copy and archive (with the appropriate dating/version). A change log in the database proper can track what adjustments are made and it’s then a trivial matter to go from the “report” to the current version.
Mr. Roberts, Dr. Steig has already said that he has a copy of the data, and that he sends it to “legitimate” researchers. I am not at all surprised since there would be no way to do this type of research if you had to scrape the data each time you ran the program. So the only question is whether he should just post it up and let everyone have at it, or selectively release the program and data. I don’t see why everything has to be a political debate with everyone taking sides.
> A change log in the database proper can track what
> adjustments are made and it’s then a trivial matter
Ah, problem solved then.
Hank (#187): Surely the point of this is that you want someone to be able to replicate the identical statistical calculations at any point in the future. Then if there is a change to the data, they can rerun the exact calculations and see if this makes any difference. To remove the data, as if it never existed, means the initial analysis cannot be replicated and is therefore not very useful.
James (#183): I agree that publishing intermediate steps in a scientific journal would be a non-starter, just as publishing (in a journal) the underlying data would be. However wouldn’t posting those intermediate steps along with the underlying data be absolutely straightforward?
On: “[No, he doesn’t. He has a good record of blowing typos in a paper all out of proportion, and using trivia and speculation to try to insinuate that researchers purposefully manipulated data, leading to a huge amount of wasted time on the part of researchers, not to mention government officials and the National Academy of Sciences. Nothing has been learned from this exercise other than one should be extremely careful in dealing with SM.–eric]”
Is it being suggested that this Harry data error is merely a typo? My understanding was that it was a case of SM finding a genuine data error, in which two different time series had been merged, and the resulting output used to make a point which would not have been justifiable if the correct data had been used. (The point made was to lend support to the conclusion, without being the primary data leading to the conclusion in its own right).
It looked to me like a good catch, given that the data had been out there for so long and given that the error had not been found in the peer review process.
[Response: You say “My understanding was …” but that’s exactly the point. Your understanding is wrong, because McIntyre has misled you. Yes, fair enough, it was useful to catch the error in the automatic weather station data. But then you say “the resulting output was used to make a point which would not have been justifiable if the correct data had been used.” SM doesn’t show that. He insinuates it, but it is wrong. We’ll have a blog posting on this up tomorrow to explain it (though it should actually be obvious to anyone thinking about the calculations carefully; certainly it should have been obvious to SM, who clearly understands the methods reasonably well). So no, sorry, this does not constitute a good track record. What it constitutes is a demonstration of lack of integrity, or, at best, a remarkable lack of competence.–eric]
Gavin, how much money does NASA spend yearly on climate research?
Jim N
[Response: Something like 1 billion dollars, the vast majority of which goes to satellites. GISS’s annual budget is ~$10-12 million for ~120 people. – gavin]
John Mashey #185: hear hear.
Let me further point out that what constitutes proper documentation of intermediate steps depends a lot on who is on the receiving end. Competent scientists don’t need a lot for successful replication. What Eric terms “legitimate” is actually an euphemism for non-moron. What busy working scientists want to avoid ending up doing is hand-holding morons, and additional demotivation is if the morons are of the delusionally paranoid, intellectually dishonest kind.
You don’t have to be formally a climatologist to qualify: John van Vliet single handedly replicated GIStemp, with his own code, and without access to more than what is already on the Web. I interacted with an RC scientist that shall remain unnamed, who didn’t know me or my reputation — zero in the field of climatology — yet he went out of his way to provide me with unpublished model runs from his archive and Matlab snippets to work with it.
It’s really not that hard to understand: scientists — real scientists — are compulsively interested in figuring out things, and will help whoever helps them do so. Replication is a small part of that picture. Interesting replication means varying things: use your own code — nobody wants to replicate other folks’ bugs –, try variants and new approaches to get to similar findings, etc. What interests scientists is whether what a colleague found out is actually true, not so much whether what that colleague did is step-by-step correct. Or even the precise version of the data used, or the presence of data errors, which should be immaterial for a real result.
[Response: Martin (and John) above. Thank you. Exactly. For the record though, I didn’t actually mean to refer to anyone as a ‘moron’. ‘Intellectually dishonest’ though, yes.–eric]
Re Martin Vermeer #194
“What interests scientists is whether what a colleague found out is actually true, not so much whether what that colleague did is step-by-step correct. Or even the precise version of the data used, or the presence of data errors, which should be immaterial for a real result.”
You can’t actually mean this…right?
[Response: What Martin means is that some errors may be trivial enough to be immaterial to the conclusions. Such errors are not very interesting. That’s not to say they shouldn’t be corrected; they should. But this is simply about seeing the forest for the trees. In this case, the forest is understanding Martin’s obvious point — “What interests scientists is whether what a colleague found out is actually true” — which you appear to have missed. –eric]
194: What interests scientists is whether what a colleague found out is actually true, not so much whether what that colleague did is step-by-step correct. Or even the precise version of the data used, or the presence of data errors, which should be immaterial for a real result.
Huh? How can something be “true” but not step-by-step correct? If it isn’t step-by-step correct then there’s something fishy going on, sort of like proving 2+2=4 by adding 3/0 to each side and viola they are equal.
What you’re describing is akin to the ends justify the means.
I don’t even know what to make of “presense of data errors which should be immaterial” I suppose the errors are immaterial if they aren’t close to the outcome — but for temperature increases those are on the order of a tenth of a degree. How much error is allowed when that’s what is being predicted?
Can you give a case of something that is “actually true” but the step by step process isn’t correct? Put it this way: can a creationist use this same argument to prove that intelligent design is correct / true? Is that something to be concerned about?
[Response: I don’t get your question about creationism, but here is a simple example to illustrate the point Martin was making.
2+2 = 4 right? OK, good.
What does 2.01 + 1.98 equal? Answer: 3.99.
OK, is the answer to the first problem different than the answer to the second problem (is 3.99 different from 4)? Answer: NO.
Surprised?
You shouldn’t be if you took highschool science.
The two numbers 3.99 and 4 have a different number of significant digits, and you have to use the same number of significant digits to answer the question.
Try again: what is 3.99 to 1 significant digit? Answer 4. So 3.99 = 4.
The only way the you could meaningfully say that there is a difference between (2.01 + 1.98) and (2+2) is if the latter is actually 2.00+2.00.
In my little example, I used, in a sense, “different steps” (or a different set of measurements) but I still got the same answer. It’s not about having no errors — that is impossible in the real world. Doing good science means asking questions that are robust to the available data quality. There is no point is asking about Antarctic temperature change based on just one weather station, such as South Pole, because that weather station has errors (that’s inevitable) and because it isn’t going to be very representative — one station gives you indadequate spatial coverage. But use enough weather stations, and your answer is not only better because you have better spatial coverage, but because errors — even pretty large errors — in one of the weather stations probably won’t affect your result.
Get it?
A slight disagreement with Martin in this case:
I’d replace “actually true” by:
“a better approximation to reality, that yields more insight into something that might actually matter.”
After all, there are many models that cannot possibly get perfect data and can only ever yield approximations, but are still extremely useful. (~”All models are wrong, some models are useful” – George Box).
Some people may know of the great statistician, now deceased, named John Tukey. I especially recommend contemplation of:
“Far better an approximate answer to the right question, which is often vague, than an exact answer to the wrong question, which can always be made precise.” J. W. Tukey (1962, page 13), “The future of data analysis”. Annals of Mathematical Statistics 33(1), pp. 1–67.”
Put another way:
No amount of endless nitpicking equals one real insight on a real problem.
Thanks Eric, that’s precisely what I mean. Good example. Folks typically don’t appreciate just how scientists use massive redundancy in the data to render any gross data error that slips through, harmless in the end result. In the surface data, e.g., this is the long range correlations in annual averages, that would make some 60 stations globally enough for getting a good global average, when we have thousands of them. Yes, in some parts of the world coverage is dangerously thin, but the USA is not among those…
And there will always be data errors when working with these very large, heterogeneous data sets. Mr. Murphy will be your co-author.
[edit]
Far be it from me to teach you about maths. However, surely the real issue is not a 0.25% deviation from the “mean” (the difference between 3.99 and 4.00), but that it appears that some are forming the view that the proposition being sold is that 2+1 = 5, or 2+1 =3. That is, we aren’t talking about rounding errors here – we are talking about much more fundamental differences that seem to be arising, that could in fact invalidate the hypothesis.
[Response: No. That’s only what you ‘d like to think you are talking about. – gavin]
Re #195 No Eric, I didn’t miss his point, but I still think that statement is outrageous. I know that my colleagues (scientists) would care whether what I did was step-by-step correct, or if I couldn’t produce the precise version of my data for the experiment, or if there was errors in the data, even if they are immaterial for a real result. I’m just going by what he said.
Mistakes happen, but it just bugs me to see all the nonchalance regarding sloppiness and lack of QC when it comes to data quality (not a comment on your issue- just in general).
[Response: It’s not nonchalance. Errors in data and code should be looked for and fixed when found. It’s simply that this is not the most important issue when deciding whether a result is interesting or not. Someone could have perfect data and absolutely correct code, but because their analysis is based on a fundamentally incorrect assumption, the result will be worthless. But errors in data are ubiquitos, as are bugs in code (Windows, anyone?) – interesting results therefore need to be robust to these problems. Which is why we spend time trying to see whether different methods or different data sources give the same result. That kind of independent replication is the key to science, not checking arithmetic. – gavin]