The difference between a single calculation and a solid paper in the technical literature is vast. A good paper examines a question from multiple angles and find ways to assess the robustness of its conclusions to all sorts of possible sources of error — in input data, in assumptions, and even occasionally in programming. If a conclusion is robust over as much of this as can be tested (and the good peer reviewers generally insist that this be shown), then the paper is likely to last the test of time. Although science proceeds by making use of the work that others have done before, it is not based on the assumption that everything that went before is correct. It is precisely because that there is always the possibility of errors that so much is based on ‘balance of evidence’ arguments’ that are mutually reinforcing.
 So it is with the Steig et al paper published last week. Their conclusions that West Antarctica is warming quite strongly and that even Antarctica as a whole is warming since 1957 (the start of systematic measurements) were based on extending the long term manned weather station data (42 stations) using two different methodologies (RegEM and PCA) to interpolate to undersampled regions using correlations from two independent data sources (satellite AVHRR and the Automated Weather Stations (AWS) ), and validations based on subsets of the stations (15 vs 42 of them) etc. The answers in each of these cases are pretty much the same; thus the issues that undoubtedly exist (and that were raised in the paper) — with satellite data only being valid on clear days, with the spottiness of the AWS data, with the fundamental limits of the long term manned weather station data itself – aren’t that important to the basic conclusion.
So it is with the Steig et al paper published last week. Their conclusions that West Antarctica is warming quite strongly and that even Antarctica as a whole is warming since 1957 (the start of systematic measurements) were based on extending the long term manned weather station data (42 stations) using two different methodologies (RegEM and PCA) to interpolate to undersampled regions using correlations from two independent data sources (satellite AVHRR and the Automated Weather Stations (AWS) ), and validations based on subsets of the stations (15 vs 42 of them) etc. The answers in each of these cases are pretty much the same; thus the issues that undoubtedly exist (and that were raised in the paper) — with satellite data only being valid on clear days, with the spottiness of the AWS data, with the fundamental limits of the long term manned weather station data itself – aren’t that important to the basic conclusion.
One quick point about the reconstruction methodology. These methods are designed to fill in missing data points using as much information as possible concerning how the existing data at that point connects to the data that exists elsewhere. To give a simple example, if one station gave readings that were always the average of two other stations when it was working, then a good estimate of the value at that station when it wasn’t working, would simply be the average of the two other stations. Thus it is always the missing data points that are reconstructed; the process doesn’t affect the original input data.
This paper clearly increased the scrutiny of the various Antarctic data sources, and indeed the week, errors were found in the record from the AWS sites ‘Harry’ (West Antarctica) and ‘Racer Rock’ (Antarctic Peninsula) stored at the SCAR READER database. (There was a coincidental typo in the listing of Harry’s location in Table S2 in the supplemental information to the paper, but a trivial examination of the online resources — or the paper itself, in which Harry is shown in the correct location (Fig. S4b) — would have indicated that this was indeed only a typo). Those errors have now been fixed by the database managers at the British Antarctic Survey.
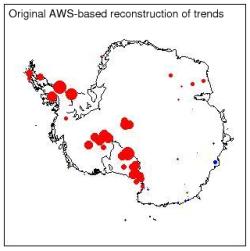 Naturally, people are interested on what affect these corrections will have on the analysis of the Steig et al paper. But before we get to that, we can think about some ‘Bayesian priors‘. Specifically, given that the results using the satellite data (the main reconstruction and source of the Nature cover image) were very similar to that using the AWS data, it is highly unlikely that a single station revision will have much of an effect on the conclusions (and clearly none at all on the main reconstruction which didn’t use AWS data). Additionally, the quality of the AWS data, particularly any trends, has been frequently questioned. The main issue is that since they are automatic and not manned, individual stations can be buried in snow, drift with the ice, fall over etc. and not be immediately fixed. Thus one of the tests Steig et al. did was a variation of the AWS reconstruction that detrended the AWS data before using them – any trend in the reconstruction would then come solely from the higher quality manned weather stations. The nature of the error in the Harry data record gave an erroneous positive trend, but this wouldn’t have affected the trend in the AWS-detrended based reconstruction.
Naturally, people are interested on what affect these corrections will have on the analysis of the Steig et al paper. But before we get to that, we can think about some ‘Bayesian priors‘. Specifically, given that the results using the satellite data (the main reconstruction and source of the Nature cover image) were very similar to that using the AWS data, it is highly unlikely that a single station revision will have much of an effect on the conclusions (and clearly none at all on the main reconstruction which didn’t use AWS data). Additionally, the quality of the AWS data, particularly any trends, has been frequently questioned. The main issue is that since they are automatic and not manned, individual stations can be buried in snow, drift with the ice, fall over etc. and not be immediately fixed. Thus one of the tests Steig et al. did was a variation of the AWS reconstruction that detrended the AWS data before using them – any trend in the reconstruction would then come solely from the higher quality manned weather stations. The nature of the error in the Harry data record gave an erroneous positive trend, but this wouldn’t have affected the trend in the AWS-detrended based reconstruction.
Given all of the above, the Bayesian prior would therefore lean towards the expectation that the data corrections will not have much effect.
 The trends in the AWS reconstruction in the paper are shown above. This is for the full period 1957-2006 and the dots are scaled a little smaller than they were in the paper for clarity. The biggest dot (on the Peninsula) represents about 0.5ºC/dec. The difference that you get if you use detrended data is shown next.
The trends in the AWS reconstruction in the paper are shown above. This is for the full period 1957-2006 and the dots are scaled a little smaller than they were in the paper for clarity. The biggest dot (on the Peninsula) represents about 0.5ºC/dec. The difference that you get if you use detrended data is shown next.
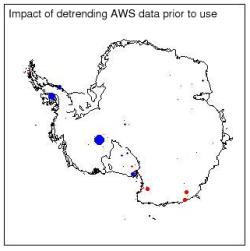
As we anticipated, the detrending the Harry data affects the reconstruction at Harry itself (the big blue dot in West Antarctica) reducing the trend there to about 0.2°C/dec, but there is no other significant effect (a couple of stations on the Antarctica Peninsula show small differences). (Note the scale change from the preceding figure — the blue dot represents a change of 0.2ºC/dec).
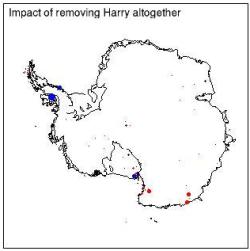 Now that we know that the trend (and much of the data) at Harry was in fact erroneous, it’s useful to see what happens when you don’t use Harry at all. The differences with the original results (at each of the other points) are almost undetectable. (Same scale as immediately above; if the scale in the first figure were used, you couldn’t see the dots at all!).
Now that we know that the trend (and much of the data) at Harry was in fact erroneous, it’s useful to see what happens when you don’t use Harry at all. The differences with the original results (at each of the other points) are almost undetectable. (Same scale as immediately above; if the scale in the first figure were used, you couldn’t see the dots at all!).
In summary, speculation that the erroneous trend at Harry was the basis of the Antarctic temperature trends reported by Steig et al. is completely specious, and could have been dismissed by even a cursory reading of the paper.
However, we are not yet done. There was erroneous input data used in the AWS reconstruction part of the study, and so it’s important to know what impact the corrections will have. Eric managed to do some of the preliminary tests on his way to the airport for his Antarctic sojourn and the trend results are as follows:
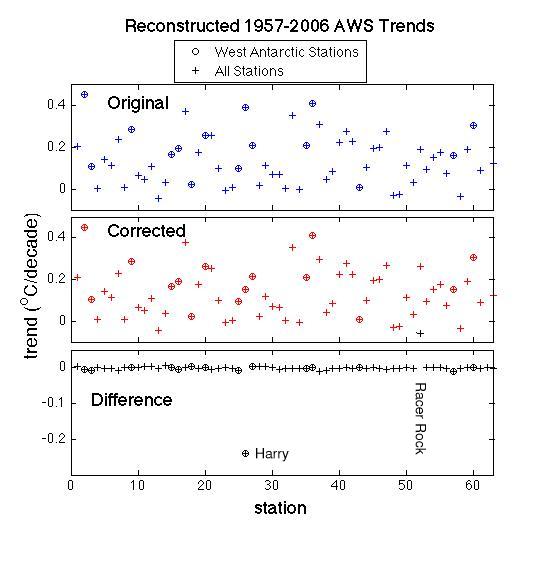
There is a big difference at Harry of course – a reduction of the trend by about half, and an increase of the trend at Racer Rock (the error there had given an erroneous cooling), but the other points are pretty much unaffected. The differences in the mean trends for Antarctica, or WAIS are very small (around 0.01ºC/decade), and the resulting new reconstruction is actually in slightly better agreement with the satellite-based reconstruction than before (which is pleasing of course).
Bayes wins again! Or should that be Laplace? ;)
Update (6/Feb/09):The corrected AWS-based reconstruction is now available. Note that the main satellite-based reconstruction is unaffected by any issues with the AWS stations since it did not use them.
Dr Schmidt,
I have three questions:
We now know there were errors at two Antartica stations. How do we know there were no errors in the measurements at the other stations ?
[Response: One never knows there are no errors. So you aim to show results are robust despite that possibility. – gavin]
What would be the normal procedure to inform the editors at Nature of the errors in the paper ?
[Response: People send in corrections if necessary, or refer to it in another publication. – gavin]
Have scientists also tried to interpolate data in undersampled regions that show warming – or only in those that show cooling ?
[Response: The interpolation doesn’t care what the trends are. Similar techniques have been used for sea surface temperature data and the like – they show warming, but I don’t really follow your question. – gavin]
[Response: Since the study clearly (e.g. Figure 3) reconstructs cooling over East Antarctica during certain sub-intervals (e.g. 1969-2000) and warming over others (e.g. the long term, 1957-2006) its hard to make any sense of the question. -mike]
There is very funny — and sad — animation video here about the north pole melting by New Jersey creator Dominic Tocci here:
http://toccionline.kizash.com/movies/the_north_pole_is_melting/
Again we have a debate around the small issues when the big issue of “is AGW real” loses out. Of course, if Antartica was cooling, that still made no difference to the predictions of how we must reduce emissions. This paper confirming that Antartica is in fact just like the rest of the planet, WARMING, is yet another nail in the coffin of the deniosphere.
I restate what I have said before on this site, the issue of reducing emissions is not political and will equally effect both side of politics.
We are intelligent beings capable of concieving what the future holds. We have to use this knowledge to act as stewards of this planet (the only one we have).
PS. not criticising RC, I think you guys are doing a realy important thing here — keep up the good work.
At the other end of the world USGS has published :Past Climate Variability and Change in the Arctic and at High Latitudes (http://www.climatescience.gov/Library/sap/sap1-2/final-report/)
Some of which is well worth reading. Chapter 6 has good tidbits about the Greenland Ice Sheet, and comments on modeling ice.
Above you say that the source for the Nature cover is the satellite data. Is that really so, i.e. the picture illustrates a ~25 year trend, or is the source the interpolated and extended ground station data over the full 50 years?
[Response: It’s the interpolated and extended trend over 50 years. – gavin]
A link to my recent post requesting again that code be released.
[edit]
I believe your reconstruction is robust. Let me see the detail so I can agree in public.
[Response: What is there about the sentence, “The code, all of it, exactly as we used it, is right here,” that you don’t understand? Or are you asking for a step-by-step guide to Matlab? If so, you’re certainly welcome to enroll in one of my classes at the University of Washington.–eric]
Eric, he’s convinced himself you have some seekrit code. Note how his line goes from “the” code to “your” code over a few lines of text.
He doesn’t want the tools. He wants paint-by-numbers advice on using it with the database. What he calls “antarctic code” — cookbook help.
Homework help. Science fair project help.
Heck, you might consider doing that when you’re back from Antarctica, not for the anklebiters, but for high schoolers; maybe someone like Tamino or Robert Grumbine would take it on as an educational toolkit.
“Here’s the tool kit. Here’s the database. Now, let’s look at the data, and think about how to use these tools. How do we approach a data set like this? Well, the first step is …..”
_________________
“Offices Nicelys” says ReCaptcha.
Ah, Eric’s inline response came as I was typing mine. Same conclusion.
__________________
“Quayle executors”
Query regarding manned stations and possible affect on validating Automatic Stations against manned stations.
Looking at Amundsen-Scott data from GISS (see link below) there is considerable difference in variability of readings between 1957-1977 and post 1977. The change appears to coincide with significant changes at the base.
Given there actually is such a thing as a measurable “heat island effect” on manned temperature stations in Antarctica (and the chart for Amunsen-Scott suggests there is) would such an effect affect your validation of automatic stations to manned stations such as Amundsen-Scott?
Any comments?
http://data.giss.nasa.gov/cgi-bin/gistemp/gistemp_station.py?id=700890090008&data_set=1&num_neighbors=1
This graph shows a zig-zag pattern from 1957 to about 1977 with a temperature range of about 1 degree. From 1977(?) onwards the amplitude of temperature range dramatically increases up to about 3 degrees C. The overall trend is gently upwards but there is a step down in 1977.
Well, here’s what Jeff Id is really saying …
[edit — thanks for your support dhogaza, but I’m not allowing ‘jeff id’s’ rants to show up here, even if passed on to me by someone else–eric]
Minus the bluster at the end, it’s the same-old same-old – climate science is a fraud.
People like this should simply be ignored. He’s going to claim fraud no matter how patient Eric is or how much help Eric gives him.
[edit]
Ah, Jeff Id, I thought I recognized the name …
He’s famous for mathematically proving that temperature reconstructions which have a hockey stick shape are a statistical artifact.
He’s eagerly awaiting notification that he’s won the Fields Prize.
Dear Gavin,
If I remember right, previously climate scientists were claiming that the cooling trend in East Antartic was anticiapted by climate models even as the West was warming. Now that it is shown East Antartica is also warming (is that the correct inference?), not just West Antartica, how to reconcile the claim?
thanks & best wishes,
rosli
[Response: Um.. No. You have most of this wrong. You might go back and read our earlier posts which explain this.–eric]
OK, fine … I understand … interested folks can just click on jeff id’s handle and judge for themselves …
any comments on how this will effect the error in the overall trend estimates?
is it still the same?
cheers,
[Response: I’m sure it will make no meaningful difference whatsoever. And keep in mind, as is very clear in the paper, the using the AWS is not the best method in the first place. There simply is not enough AWS data over enough time to demonstrate good validation at most places. That’s why we used the satellite data, not the AWS data, as our primary tool for estimating the spatial covariance of the temperature field.–eric]
“….that Antartica is in fact just like the rest of the planet, WARMING…”
(#3 Ricki)
True enough if you calculate the trend from 1957. However, how much has the continent warmed since 1980? I don’t see much of a warming trend over the last 25 years, certainly not in the biggest area, East Antarctica.
I would guess from looking at some of the station data that warmest year ever in the station record for most of Antarctica is 1980, so in that sense it’s certainly not like the rest of the planet.
Regards, BRK
[Response: Nope! Best way to do scientific work is to do it, rather than guessing (though as Gavin shows, thoughtful guessing often saves a lot of pointless speculation). The graph below shows the warmest monthly anomaly for each station; if you average over years first you get the same answer (the median warmest monthly anomaly is July 1992; median warmest year is 1991; if you look at the long term records only (so excluding the AWS) you get June 1989 and 1989, respectively. West Antarctica alone the warmest year in the records (have to include the AWS as there are no long term stations) is 1996. Of course, I’m not including 2007 or 2008 because our satellite data stops in 2006 so we cut everything off there for apples-to-apples comparison. Dave Bromwich tells me 2007 is the warmest at Byrd (central West Antarctica). I haven’t taken the time to look. You can though! It’s all on the READER web site.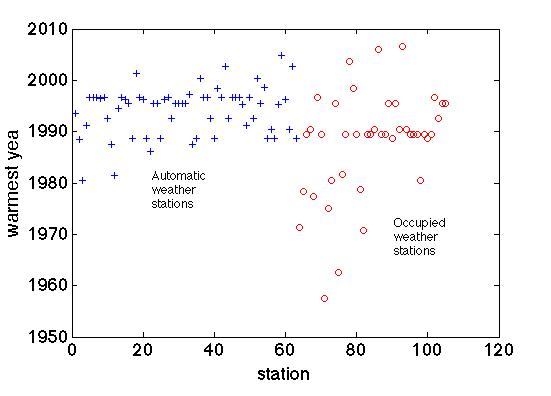
Still, your point is not unreasonable — not all of Antarctica has warmed significantly, and in the last few decades East Antarctica’s trend has flattened. Nowhere do we claim otherwise.–eric
I think François GM’s third question was trying to trick you into admitting that you fudged the data. Just say that you did no such thing. You turned the mathematical crank. You didn’t cherry pick the data. You used standard mathematics to test all of the data for errors in the data gathering machinery. The machinery broke down twice. End of story.
Most people don’t understand that science is a hard job. They may think that you have a “kushy” job. Nature never hands you textbook data. Scientists are NOT authorities. NATURE is the only authority. You are not a political movement, you are a scientist. Most people accuse scientists of sticking together. That is why everybody in the country or world needs to be trained in science. They need to experience for themselves the difficulties you went through in writing this paper. There are those that will say that your paper is completely wrong merely because it is less perfect than God could have done.
Q, on Star Trek, was correct when he called us a pathetic species. Or at least our K-12 science education is pathetic.
I just started reading “Only a Theory” by Kenneth R. Miller. He says that the feature of Americans that makes the US the most scientific country in the world and also the most anti-scientific country in the world is that Americans are DISRESPECTFUL. The problem is that most Americans misdirect their disrespect. YOU are our representative in Antarctica. You are the best and smartest person we have for finding out what is happening to the climate there. Other Americans should see you as a friend. Instead, they imagine all kinds of nonsense.
http://scienceblogs.com/aetiology/2007/09/deck_is_stacked_against_mythbu.php
Don’t repeat bad information; that’s its way of spreading, taking you over long enough to replicate. Defend yourself from the passionate urge to repeat bad information — even if you think you’re combating it. It wins when you let it repeat through you.
“Correcting misinformation can backfire.
“… within 30 minutes, older people misremembered 28 percent of the false statements as true. Three days later, they remembered 40 percent of the myths as factual.”
Somewhat loosely related, but also an example of binary thinkink.
There are reports about a paper http://www.theage.com.au/national/droughts-cause-found-20090204-7xxk.html that say a warm Indian ocean is responsible for Australia’s drought and that La-Nina doesn’t bring rain to the SE. I understand that the recent La-Nina have not brought rain as expected but surely that expection was based on previous observations.
Could this be an instance of a tipping point that “tipped” in 1992?
Re: #17
Hank, correlation is not causation, it could just be that comprehension and memory deteriorate with age. I’m 50 and I’m surprided “older people” even remeber that much about a leaflet. It’s also about how much you care, eg: name everything you ate/drank in the last 48hrs. If the subjects are sick, and do care, then a leaflet won’t cut it, they will want to talk to a doctor.
And even if there conclusion is correct then to me this just means the clarity and simplicity of the myth busting is important. I come here looking for that clarity and often find it (such as the elegant saturation argument for why water is a feedback and not a forcing). This partcular article has been no different and is an excellent reference for mythbusting the still sizable proportion of psuedo-skeptics amoungst the world’s opinon columnists.
re #19: “correlation is not causation”. How often is that seen, even when “causation” is never put forward, just the FACT of correlation.
If 80% of the myths are remembered as truths, then that is a correlation between repeated writing of the myth and the belief of that myth and a LACK of correlation between correcting the myth and the belief of that myth.
Where in there is the causation mentioned?
NEVER.
DO NOT overuse pithy little statements else you start using them when they do not belong. And it doesn’t belong here. No causation was proposed. Just there was correlation.
Gavin (or Eric assuming he’s not incommunicado),
I’m looking at the plot of the reconstructed AWS trends at the end of this entry and a few things jump out.
1. 62 stations???]
[[63 — the graph is cut off at 62 for some reason (hey, I’m traveling!). #63 was 0.124 degrees/decade, and is now at 0.120 degree/decade. O.M.G!]
2. It’s a plot so there are no significance details, but only 5 of 47 not in West Antacrtic show negative trend. How is it possible that all of Antarctica is not demonstrably warming?
3. Trying to think like a McIntyre now and pick on outliers, which stations are #2, #36 and #60?
[Response: #2 and #36 are at the base of the Antarctic Peninsula (on the Weddell side). #60 is ‘Theresa’, not too far from “Harry”. If you were still thinking like McIntyre, you’d accuse me of dishonestly including those two stations which are arguably ‘really’ on Antarctic Peninsula in my average for West Antarctica (they are just south of 72 S). Sorry, but doing that makes the comparison with the satellite data even better. Oh wait, about face! Channeling SM.. hang on a sec…. “Better idea: Steig is right about West Antarctica. It’s the Antarctic Peninsula where he made up data. Yeah, that must be it. The Antarctic Peninsula is cooling!!” …sigh…–eric]
In the maps above you are using a two dimensional figure (area of a circle) to graphically represent a one dimensional value (temperature). This makes your graphic a bit hard to follow and under-represents the point you are making. Also the data to ink ratio for those maps is low.
I refer you to “The Visual Display of Quantitative Information” by Tufte. If you haven’t already read it you will find it directly applicable to your work here.
Thanks for clarifying this issue as I appreciate the calm persepective on what it means.
Post #15 Brian
It’s possible that AWS’s don’t show a warmest year prior to 1980 because they had not been installed prior to 1979.
As pointed out elsewhere, Steig et al say the following:
“Although [Monaghan et al 2008] concluded that recent temperature trends in West Antarctica are statistically insignificant, the results were strongly influenced by the paucity of data from that region. When the complete set of West Antarctic AWS data is included, the trends become positive and statistically significant, in excellent agreement with our results.”
If I understand this correctly, you are saying that Monaghan et al 2008 did not use the complete set of West Antarctic AWS data, and that the statistical significance of the West Antarctic trends (in the surface data) depends on using data which Managhan et al did not. Is this correct?
I note that the selection of data in Monaghan et al was not arbitrary. In fact, they may have noticed the hiccup at Harry before anybody else:
“Harry Station data are suspicious after 1998; data used in analysis are through 1998.”
Does Eric have any comment on the respective decisions made as to the inclusion of data in Monaghan et al versus Steig et al?
Would Monaghan et al have reached the same conclusions as Steig et al if they were using AVHRR data?
Given the recent kerfuffle over the Harry data, is possible that the original Monaghan conclusion about the statistical insignificance of the West Antarctic surface data was correct?
[Response: You can search on Monaghan in google and you’ll see that he has publicly stated he likes our study. I’ve talked with Andy at length about this and they’ve redone their analysis and now get our result. I don’t know all the details. They are working on a paper on it. Andy might be willing to respond if you ask him, but I suspect he’s smarter than me (i.e. he doesn’t pay much attention to what a few random people with time to post comments on blog have to say. ;) –eric]
“…[Response: Nope! Best way to do scientific work is to do it, rather than guessing (though as Gavin shows, thoughtful guessing often saves a lot of pointless speculation)….”
The graph provided in the response shows the warmest year in the manned station record appears to be 1989. The AWS’s look to have a warmest year of 1997 or 1998. However, as evidence against my speculation of 1980 as the warmest year in Antarctica, the AWSs don’t go back to 1980 with a few rare exceptions, and probably a lot of the manned station’s don’t either.
[edit] If you looked at only the stations which span 1980, how many points on that graph would be eliminated?
I contend that 1980 was probably the warmest year in the Antarctic record, if you consider a spatially weighted average of the stations which span 1980.
Regards, BRK
[Response: Curious about what analysis your contention is based on, but no. the warmest year in the average of all occupied stations is 1996. Eric really has left the building now, so more detailed analysis you’ll have to do yourself or wait until he gets back in 3 months time. – gavin]
Alan riffs on what I posted, Mark riffs on Alan’s post. Look at the link, follow it to the WaPo article, to contribute your useful critique of the paper studying the effect of repeating myths to debunk them. Don’t rely on secondary or worse sources and believe you’ve criticized a research paper. That’s what’s happening with the Antarctic issue, eh?. Read the original, critique that. It saves much wasted time and confusion.
Eric – about your chart in #15, can I ask a few things?
1. Where would I find a database of the numbers you used?
2. Any particular reason you “split” the data into the automatic and occupied? Could they be re-grouped into west/east sites, irregardless of the type?
3. It appears, just from eyeball, that the “median warmest year” changes, depending on the type of station. The automatic median appears later (about ’98) than the manned does (about ’90). Would separate charts support this observation?
3. Is there data available of the coolest monthly anomaly for each station?
Just point me to the data, I’ll do the homework…
[Response: All of the data is at http://www.antarctica.ac.uk/met/READER . The quality of the manned station data is much better than the AWS stations, which only started to be deployed recently in any case. – gavin]
Oh, and, Alan — repetition of myth had been edited out of Dhog’s posting. That’s the reason I reminded Dhog, there’s a reason not to repeat myths when trying to debunk them. One myth, many pointers, eh?
These people never publish any of their oh-so-learned debunkings in peer-reviewed journals.
Yet they are so deluded that they think they are way ahead of the crowd.
I guess it is just one more conspiracy.
Recaptcha Antoinet Judging
#15 Brian
I went to Antarctic Data site provided by Gavin to Henry at #27 (http://www.antarctica.ac.uk/met/READER)and looked at all the temperature records for all 65 sites.
I’m not sure what the chart is trying to describe in terms of warmest year but 39 of the sites did not begin reporting data until 1991 or later. Only two sites were even operational in 1980. Additional sites began reporting temps by year as follows: 1981-(2), 1983-(1), 1984-(2), 1985-(2), 1986-(5), 1987-(4), 1988-(2), 1989-(1) and 1990-(5).
[Response: That’s the AWS data. The long term manned stations are here: http://www.antarctica.ac.uk/met/READER/surface/stationpt.html – gavin]
Re 19
NO! Hank has it exactly correct.
When correcting a myth or falsehood, NEVER repeat it. This is the advice that public relations firms always give their clients. Lawyers do NOT repeat the charges brought against their clients, they simply deny all wrong doing. At the highest level, White House press briefings for the last few years often did not even answer questions, they simply recited their side of the story. These guys (and gals) were pros. Watch the tapes and learn. Unfortunately, we have a more complex storyline to put across. Go take a course in public relations. Public Relations is different from teaching, because in a teacher-student relations are sustained and the student expects to be tested.
“…[Response: Curious about what analysis your contention is based on, but no. the warmest year in the average of all occupied stations is 1996. Eric really has left the building now, so more detailed analysis you’ll have to do yourself or wait until he gets back in 3 months time. – gavin]…”
(Gavin)
I took a sampling of stations, leaving out those right next door to another station to get as even a spatial representation as possible for all of Antarctica. I used Scott Amundsen, Scott Base, Vostok, Faraday, Halley, Casey, Syowa, Davis, Novolazarevskaya, and Dumont.
After rationalizing them to STDev numbers, I just averaged the series to get a crude but effective guess at the warmest year in Antarctica. 1996 is warm year, but the warmest is 1980.
Regards, BRK
Actually, no myth was edited out of my post (not that I buy into that particular argument in the first place). What was edited out was certain accusations made against Eric made by Jeff Id at his blog.
Hank, 26. I only riffed on the “correlation is not causation” being used when there was only the fact of correlation (without speculation as to whether there is “a causation”).
That and “Never attribute to malice that which can be explained by incompetence”. Both are HEAVILY overused. And the latter one where incompetence is, if anything, WORSE than malice.
#30 William
That explains it.
Thanks for the link Gavin!
http://www.newscientist.com/article/dn16545-antarctic-bulge-could-flood-washington-dc.html
Looks like Antarticas mass exerts a gravitational influence but as it lessens so does it gravity and hence water bulges around some parts of the USA. Interesting if true.
Pardon me for departing from the higher intellectual plane normal for RealClimate posts, but my comment is far simpler than the many eloquent and vociferous comments regarding technicalities in the Antarctic study in this thread.
I watched the catchy little cartoon mentioned by #2 (Danny Bloom) and although it is cute and some of it is even a bit thought-provoking, the animation is marred by an error that many of my students fall for, too, until they think it through. The cartoon implies that melting ice near the North Pole will cause sea level to rise. Of course, as the cartoon says, the North Pole is over ocean not land. Melting of LAND ice causes sea level to rise, or displacement of land ice into the sea, but melting of sea ice (pack ice) does not raise s.l. A simple demonstration it to monitor the water level in a glass both before and after an ice cube melts….the water level doesn’t change ( if the TEMP of the water increases, that will raise the level slightly as the warmer water has lower density and thus greater volume, but that’s minuscule in a glass of water).
> certain accusations made against Eric …
Label doesn’t matter. ‘Myth’ is from the newspaper or blog or press release. See the study for the research.
The point is, don’t repeat bad information.
Myth, accusation, whatever label you use — don’t repeat the bad information, it makes it more memorable.
Even when you follow with a correction, you aren’t helping if you’ve repeated the bad info first.
Clue. It’s how people work. Aaron is right. Look at how professionals convince. They understand the science. You should too, to be effective.
Repeating bad info in order to yell about it is self-indulgent and counterproductive. No rule against doing that if it’s what you like doing.
My advice — don’t. I’m delighted to see that kind of stuff edited out when it’s reposted here. Good.
You used 10 of the 62 stations used by Steig?
Read RC for a while, but never posted. Posting virgin here. Anyway, I have some input on this issue.
.
To check for a gross error due to the Harry-Gill merger (short of re-running the reconstruction with the corrected data), all you need to do is regress a time-series of the residuals between RegEM and the READER data for each station. If Harry led RegEM to infill inappropriately such that the trends (which is what the authors were looking at) were changed significantly, then the regression for each station would show a significant slope.
.
I did this for all 63 stations and found that the effect was very minor and irrelevant to Steig’s, et.al., conclusions. All of the stations show essentially no slope. So this skeptic has convinced himself that Harry is inconsequential to the conclusions in the paper.
.
Anyway, graphs and scripts are posted at CA. Cheers, guys.
Re Doug McKeever @37, true, floating ice does not normally alter water level as it melts, unless the ice is melting in salt water and the ice has a lower percentage of salt than the surrounding water. In that case there is a small, but never the less positive net increase in water level. That said, the net change is negligible in practical terms.
A big thanks to Gavin for pointing me to the Antarctic Climate Data used by Eric for this study.
As a learning experience, (and don’t laugh!) I’m entering the McMurdo Station average monthly temperatures from from 1956 to date into excel and then using one of the stats functions to plot a least squares line! So far I’m up to Dec 1976 and when I experimented with plotting a graph so far, viola! I got a chart showing a trend line with an upward slope.
Within excel it shows two results: r squared = .003 and y = .0066x-18.156. I understand that the first figure is the upward slope over the time period I have inputted but can someone explain what the -18.156 y intercept and r squared values are really describing for me in terms of the temperature information from McMurdo?
Sorry this is so basic, but I’m facinated to work with the real numbers for the first time especially since my last stats course was 30 years ago.
Thanks
Re: #32 (Brian Klappstein)
You should not have “rationalized to STDev numbers.” This reduces the impact of those series which show higher variance; your method is crude but not effective.
I ran the same sample, without “normalizing” the data, and for that sample 1996 is definitely warmer than 1980.
There seems to be some misunderstanding of the general business of attribution and robustness and causation and correlation when it comes to 1) trends in data produced from observing physical systems and 2) the predictions of numerical models of the physical system and 3) experiments involving the physical system.
In climate science, #3 is almost never possible. A physicist might run an experiment several times to collect more data; not possible on Earth-scale systems. Thus, you must rely on #1 and #2.
Take a related issue, the rise in ocean heat content over the past century or so: Simulated and observed variability in ocean temperature and heat content, PNAS, 2007
If the question is expansion of the subtropical dry zones and precipitation changes, then the data from rain guages, snowpack levels, soil water measurements, river flow etc. is compared to the predictions of forced climate models. For example, see Human-Induced Changes in the Hydrology of the Western United States, Science, Jan 2008. This is a pressing issue:
Regardless of what the question is, this is how the detection-and-attribution studies are done. If it’s Arctic sea ice thickness, then the data from nuclear submarines is compared to sea ice thickness models forced by observed greenhouse gas emissions and volcanic eruptions, etc. If the models and the data disagree, then something is missing – for example, the volcanic eruptions and aerosols were not included in early climate models. It’s also possible that the data collection was itself flawed, and that the model is correct.
The key issue is to make sure that models and data are kept separate. Here, we run into the complexitity of data-infilling procedures – models produce unlimited data, but the real world is a different story. Assumptions made during data-infilling may not be accurate (especially as regards ocean circulation). Still, it’s the only way to make comparisons, and the estimates are tied to real-world data. The only way to get better estimates is to collect more data.
These studies always include issues like the role of urban heat islands, the role of agricultural irrigation and surface cooling, the role of El Nino and other cycles, etc – those who claim that they don’t are either dishonest or ignorant. For example, in California the drought cycles are mostly set by El Nino cycles (say, 50% effect). However, this is against a background of steadily rising winter temperatures due to fossil-fuel and deforestation-induced global warming – meaning that when “normal” drought conditions occur, they are going to be worse than ever seen before, and the “normal” heat waves are going to break all records (as in Australia today).
Another related example of a detection-and-attribution issue is the steadily collapsing ice shelves around Antarctica. For example, Reuters states unambiguously that Antarctic ice shelf set to collapse due to warming – Mon Jan 19, 2009. Is that justified?
Well, if you look at the surface temperature ABOVE the ice shelf, as these recent realclimate posts do, then you see a warming trend, and if you look at the waters UNDER the ice shelf, you see a warming trend. So, yes, that is attributable to global warming – even though the exact date of the breakup might depend on “natural cycles”.
William, did you figure it out yet?
Secretary Active
“Correlation is not causation” – Seems like I poked a sacred cow.
Hank, I appologise I got your original post out of context, I thought you were talking about the article. However the correlation in the study is that “state a myth, old people become confused”. There is nothing that says it CAUSES people to become confused as everyone here seems to blighthly accept. I agree that repeating a myth will make it more well known, however repeatedly debunking it will it make well known for being a MYTH.
Oh and lawyers and politicians do not debate in order to enlighten, they debate to win. They do not have to worry about intellectual honesty they simply have to convince people. These are the people who create myths, they are not into busting them unless it’s politically convienient. The suggestion that science should use this style of debate completely misses the point of scientific debate.
Gavin, Please describe the meaning of climatology in this statement in methodologies. Is it meaning RegEm reconstructions of the temperature stations?
“We make use of the cloud masking in ref. 8 but impose an additional restriction that requires that daily anomalies be within a threshold of +/-10 C of climatology.”
[Response: The average temperatures for that month over the whole satellite record. Nothing to with the reconstruction. – gavin]
Pete (36), interesting and entertaining article. But was it tongue-in-cheek? Or were they smoking too many of those no-name cigarettes? :-P
Alan, well said post (46). But to be picayune, OT, and likely unpopular, I’ll stick up a little for lawyers. Lawyers can not introduce in a court anything that is not probative and has already been generally broached by other witnesses. They can’t really create myths. Politicians are not so restricted, so they can and do make up myths.
Sorry . . . should have asked this earlier with my other post. I was wondering if Dr. Steig was planning on placing the updated reconstructions on his website? I know he’s off to very cold places right now and this is probably the last thing on his mind. :) If he was planning on placing the updated reconstructions there, I would just like to thank him in advance.