How should one make graphics that appropriately compare models and observations? There are basically two key points (explored in more depth here) – comparisons should be ‘like with like’, and different sources of uncertainty should be clear, whether uncertainties are related to ‘weather’ and/or structural uncertainty in either the observations or the models. There are unfortunately many graphics going around that fail to do this properly, and some prominent ones are associated with satellite temperatures made by John Christy. This post explains exactly why these graphs are misleading and how more honest presentations of the comparison allow for more informed discussions of why and how these records are changing and differ from models.
The dominant contrarian talking point of the last few years has concerned the ‘satellite’ temperatures. The almost exclusive use of this topic, for instance, in recent congressional hearings, coincides (by total coincidence I’m sure) with the stubborn insistence of the surface temperature data sets, ocean heat content, sea ice trends, sea levels, etc. to show continued effects of warming and break historical records. To hear some tell it, one might get the impression that there are no other relevant data sets, and that the satellites are a uniquely perfect measure of the earth’s climate state. Neither of these things are, however, true.
The satellites in question are a series of polar-orbiting NOAA and NASA satellites with Microwave Sounding Unit (MSU) instruments (more recent versions are called the Advanced MSU or AMSU for short). Despite Will Happer’s recent insistence, these instruments do not register temperatures “just like an infra-red thermometer at the doctor’s”, but rather detect specific emission lines from O2 in the microwave band. These depend on the temperature of the O2 molecules, and by picking different bands and different angles through the atmosphere, different weighted averages of the bulk temperature of the atmosphere can theoretically be retrieved. In practice, the work to build climate records from these raw data is substantial, involving inter-satellite calibrations, systematic biases, non-climatic drifts over time, and perhaps inevitably, coding errors in the processing programs (no shame there – all code I’ve ever written or been involved with has bugs).
Let’s take Christy’s Feb 16, 2016 testimony. In it there are four figures comparing the MSU data products and model simulations. The specific metric being plotted is denoted the Temperature of the “Mid-Troposphere” (TMT). This corresponds to the MSU Channel 2, and the new AMSU Channel 5 (more or less) and integrates up from the surface through to the lower stratosphere. Because the stratosphere is cooling over time and responds uniquely to volcanoes, ozone depletion and solar forcing, TMT is warming differently than the troposphere as a whole or the surface. It thus must be compared to similarly weighted integrations in the models for the comparisons to make any sense.
The four figures are the following:
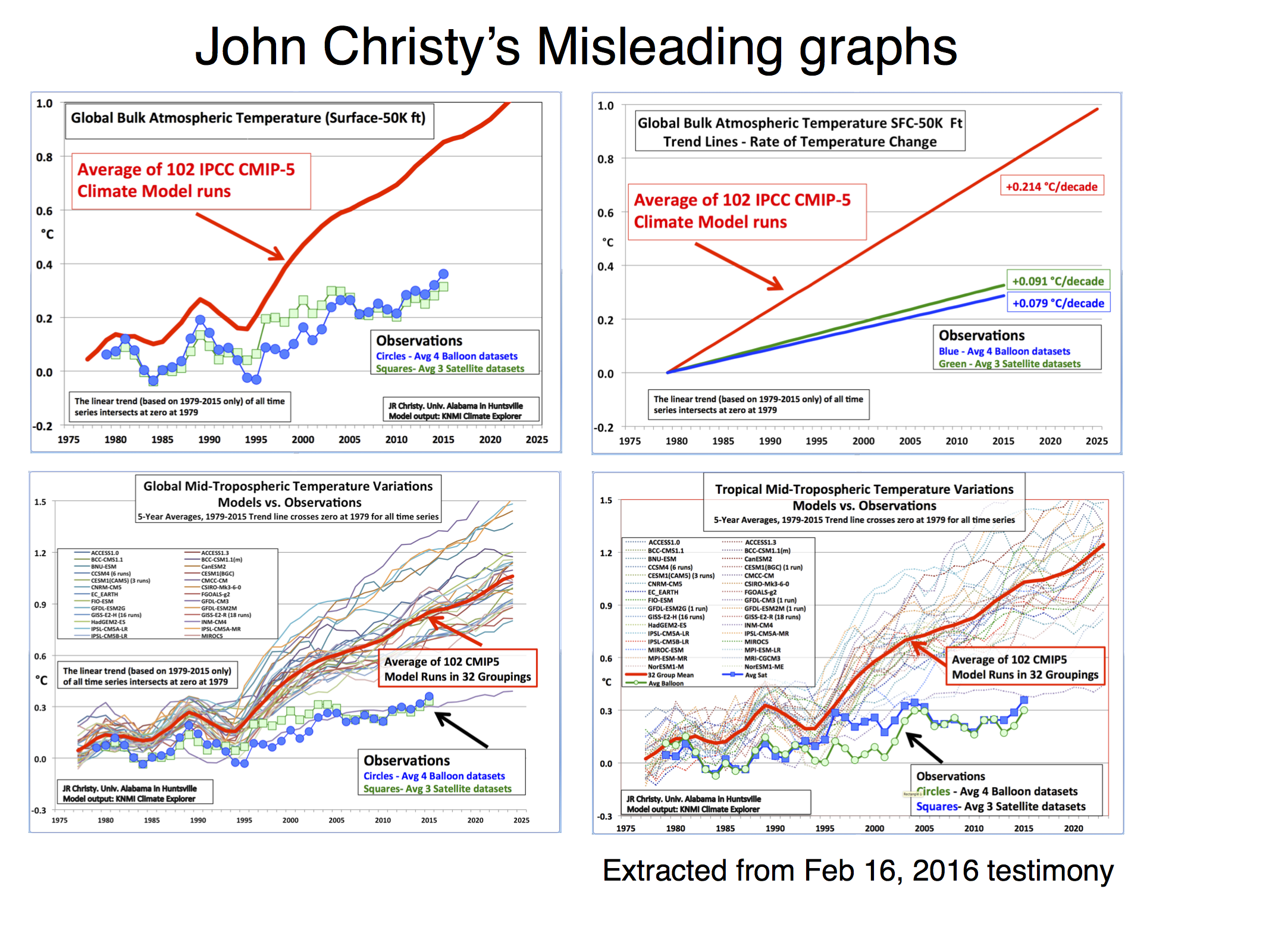
There are four decisions made in plotting these graphs that are problematic:
- Choice of baseline,
- Inconsistent smoothing,
- Incomplete representation of the initial condition and structural uncertainty in the models,
- No depiction of the structural uncertainty in the satellite observations.
Each of these four choices separately (and even more so together) has the effect of making the visual discrepancy between the models and observational products larger, misleading the reader as to the magnitude of the discrepancy and, therefore, it’s potential cause(s).
To avoid discussions of the details involved in the vertical weighting for TMT for the CMIP5 models, in the following, I will just use the collation of this metric directly from John Christy (by way of Chip Knappenburger). This is derived from public domain data (historical experiments to 2005 and RCP45 thereafter) and anyone interested can download it here. Comparisons of specific simulations for other estimates of these anomalies show no substantive differences and so I’m happy to accept Christy’s calculations on this. Secondly, I am not going to bother with the balloon data to save clutter and effort; None of the points I want to make depend on this.
In all that follows, I am discussing the TMT product, and as a shorthand, when I say observations, I mean the observationally-derived TMT product. For each of the items, I’ll use the model ensemble to demonstrate the difference the choices make (except for the last one), and only combine things below.
1. Baselines
Worrying about baseline used for the anomalies can seem silly, since trends are insensitive to the baseline. However there are visual consequences to this choice. Given the internal variability of the system, baselines to short periods (a year or two or three) cause larger spreads away from the calibration period. Picking a period that was anomalously warm in the observations pushes those lines down relative to the models exaggerating the difference later in time. Longer periods (i.e. decadal or longer) have a more even magnitude of internal variability over time and so are preferred for enhancing the impact of forced (or external) trends. For surface temperatures, baselines of 20 or 30 years are commonplace, but for the relatively short satellite period (37 years so far) that long a baseline would excessively obscure differences in trends, so I use a ten year period below. Historically, Christy and Spencer have use single years (1979) or short periods (1979-1983), however, in the above graphs, the baseline is not that simple. Instead the linear trend through the smoothed record is calculated and the baseline of the lines is set so the trend lines all go through zero in 1979. To my knowledge this is a unique technique and I’m not even clear on how one should label the y-axis.
To illustrate what impact these choices have, I’ll use the models in graphics that use for 4 different choices. I’m using the annual data to avoid issues with Christy’s smoothing (see below) and I’m plotting the 95% envelope of the ensemble (so 5% of simulations would be expected to be outside these envelopes at any time if the spread was Gaussian).
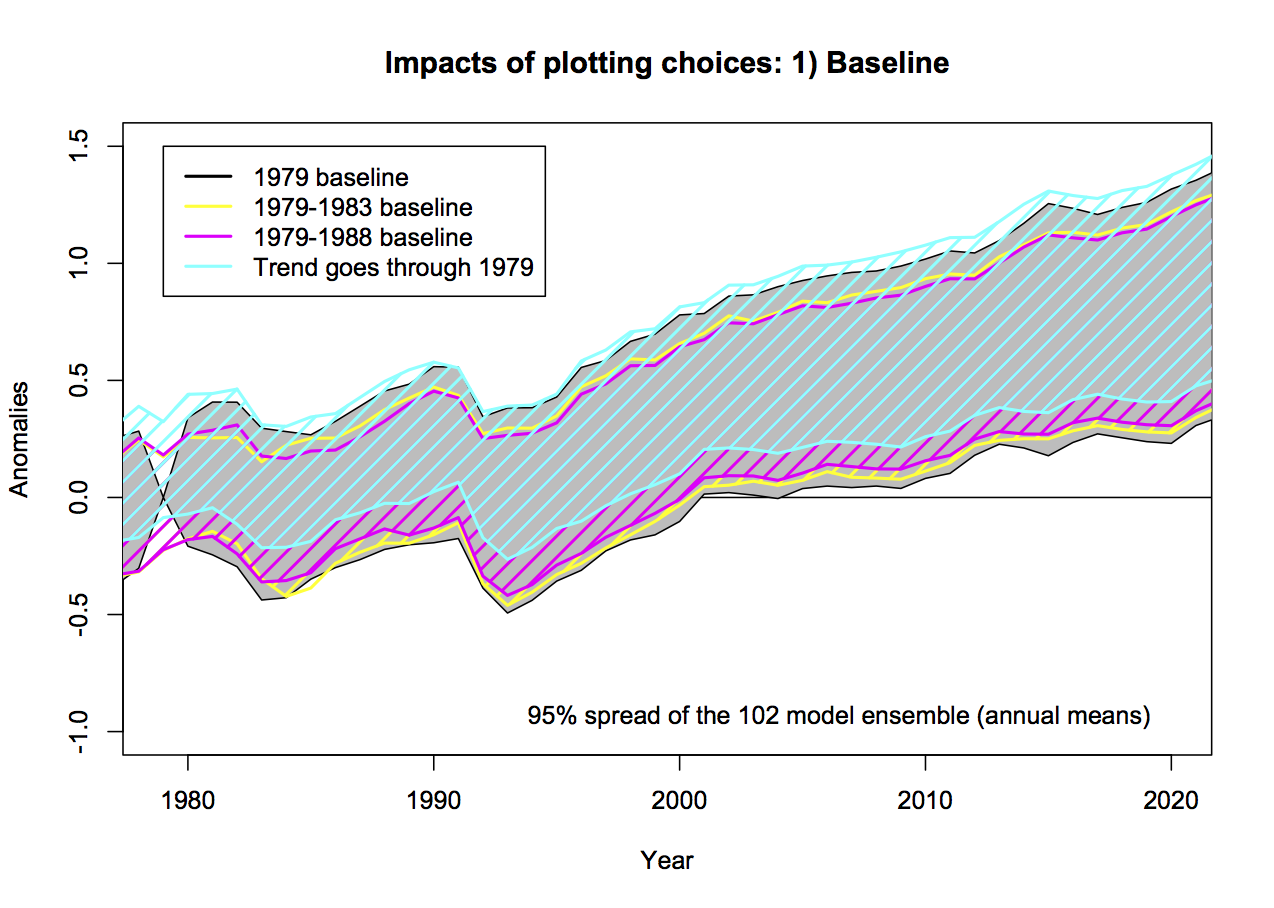
Using the case with the decade-long baseline (1979-1988) as a reference, the spread in 2015 with the 1979 baseline is 22% wider, with 1979-1983, it’s 7% wider, and the case with the fixed 1979-2015 trendline, 10% wider. The last case is also 0.14ºC higher on average. For reference, the spread with a 20 and 30 year baseline would be 7 and 14% narrower than the 1979-1988 baseline case.
2. Inconsistent smoothing
Christy purports to be using 5-yr running mean smoothing, and mostly he does. However at the ends of the observational data sets, he is using a 4 and then 3-yr smoothing for the two end points. This is equivalent to assuming that the subsequent 2 years will be equal to the mean of the previous 3 and in a situation where there is strong trend, that is unlikely to be true. In the models, Christy correctly calculates the 5-year means, therefore increasing their trend (slightly) relative to the observations. This is not a big issue, but the effect of the choice also widens the discrepancy a little. It also affects the baselining issue discussed above because the trends are not strictly commensurate between the models and the observations, and the trend is used in the baseline. Note that Christy gives the trends from his smoothed data, not the annual mean data, implying that he is using a longer period in the models.
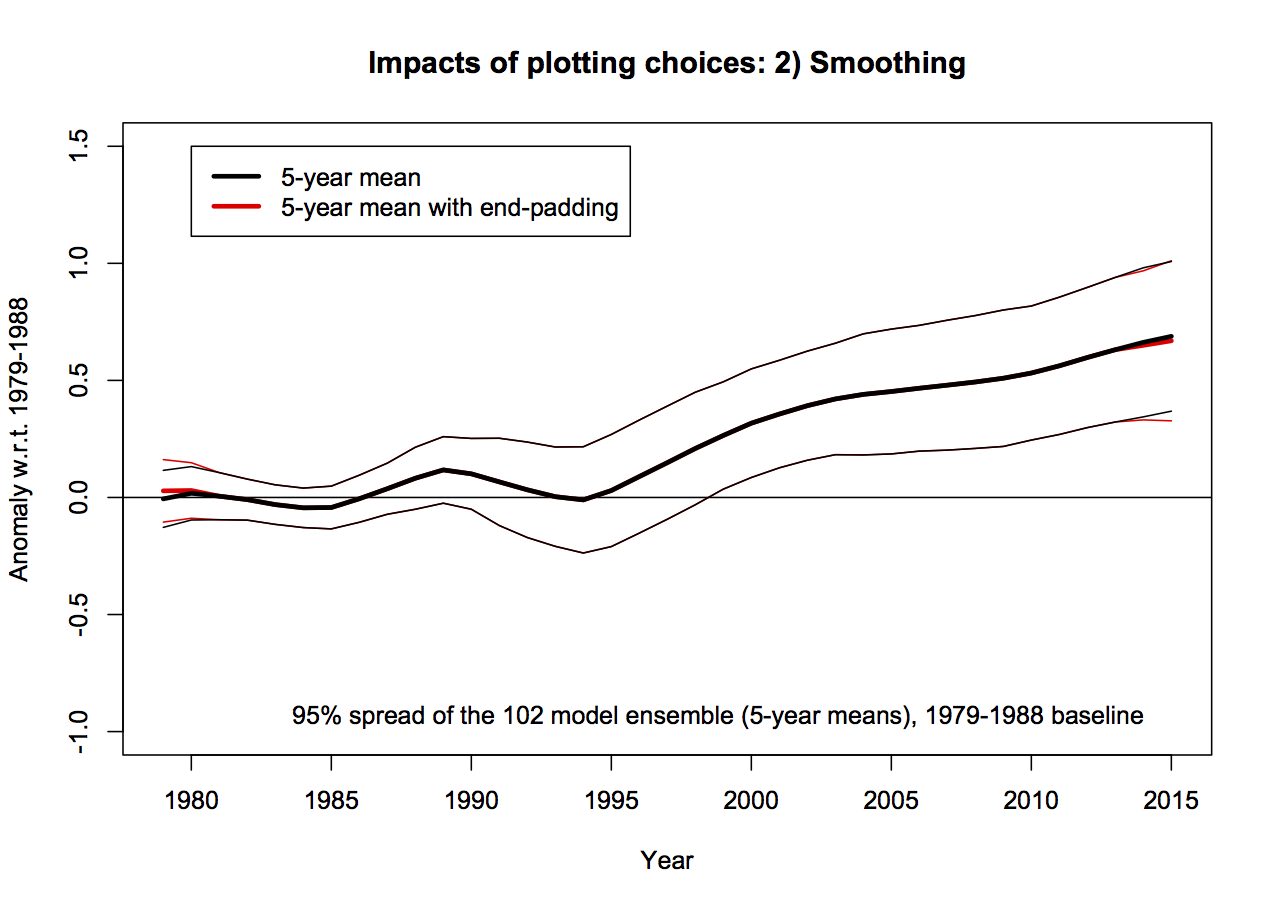
This can be quantified, for instance, the trend in the 5yr-smoothed ensemble mean is 0.214ºC/dec, compared to 0.210ºC/dec on the annual data (1979-2015). For the RSS v4 and UAH v6 data the trends on the 5yr-smooth w/padding are 0.127ºC/dec and 0.070ºC/dec respectively, compared to the trends on the annual means of 0.129ºC/dec and 0.072ºC/dec. These are small differences, but IMO a totally unnecessary complication.
3. Model spread
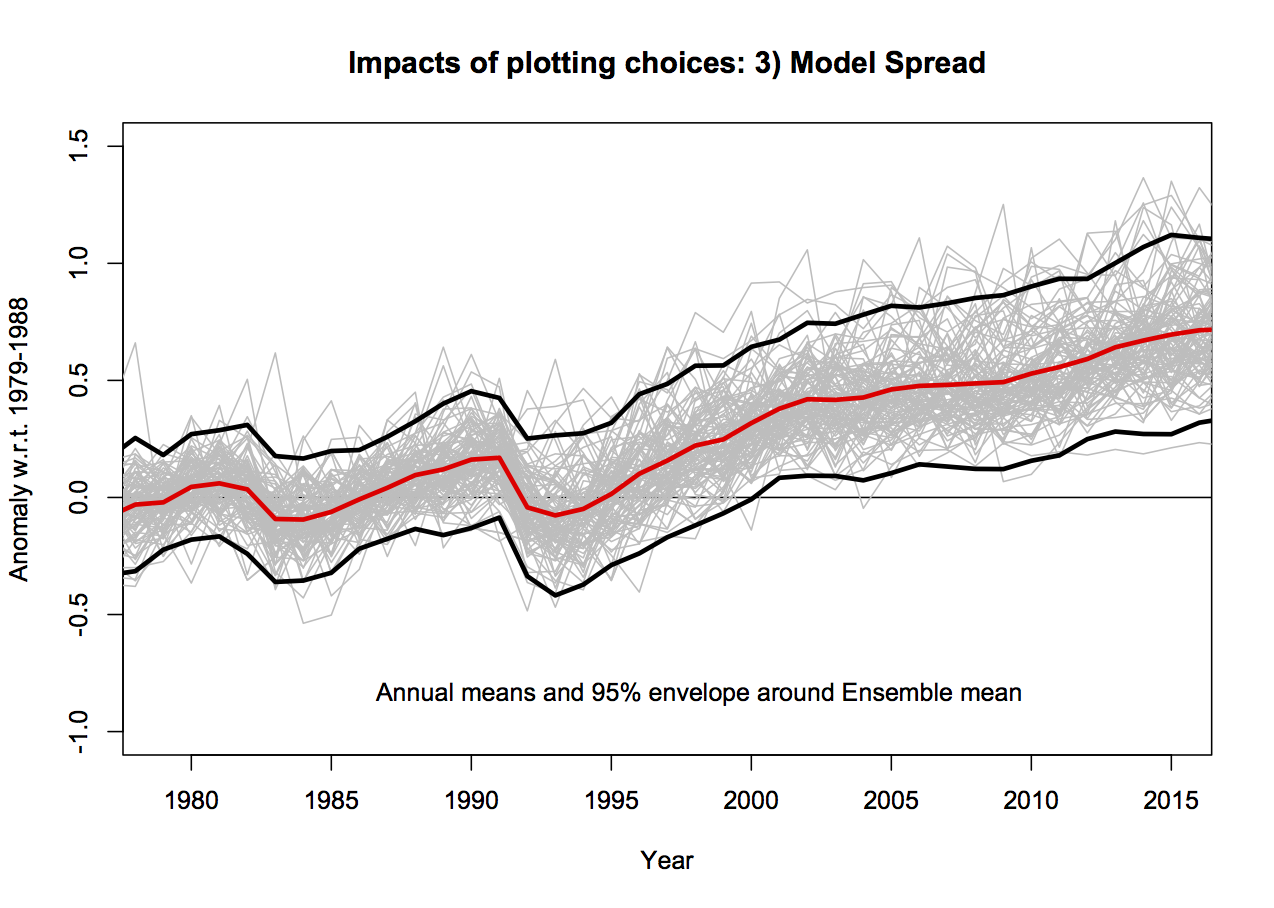
The CMIP5 ensemble is what is known as an ‘ensemble of opportunity’, it contains many independent (and not so independent) models, with varying numbers of ensemble members, haphazardly put together by the world’s climate modeling groups. It should not be seen as a probability density function for ‘all plausible model results’, nonetheless, it is often used as such implicitly. There are three sources of variation across this ensemble. The easiest to deal with and the largest term for short time periods is initial condition uncertainty (the ‘weather’); if you take the same model, with the same forcings and perturb the initial conditions slightly, the ‘weather’ will be different in each run (El Niño’s will be in different years etc.). Second, is the variation in model response to changing forcings – a more sensitive model will have a larger response than a less sensitive model. Thirdly, there is variation in the forcings themselves, both across models and with respect to the real world. There should be no expectation that the CMIP5 ensemble samples the true uncertainties in these last two variations.
Plotting all the runs individually (102 in this case) generally makes a mess since no-one can distinguish individual simulations. Grouping them in classes as a function of model origin or number of ensemble members reduces the variance for no good reason. Thus, I mostly plot the 95% envelope of the runs – this is stable to additional model runs from the same underlying distribution and does not add to excessive chart junk. You can see the relationship between the individual models and the envelope here:
4. Structural uncertainty in the observations
This is the big one. In none of the Christy graphs is there any indication of what the variation of the trend or the annual values are as a function of the different variations in how the observational MSU TMT anomalies are calculated. The real structural uncertainty is hard to know for certain, but we can get an idea by using the satellite products derived either by different methods by the same group, or by different groups. There are two recent versions of both RSS and UAH, and independent versions developed by NOAA STAR, and for the tropics only, a group at UW. However this is estimated, it will cause a spread in the observational lines. And this is where the baseline and smoothing issues become more important (because a short baseline increases the later spread) not showing the observational spread effectively makes the gap between models and observations seem larger.
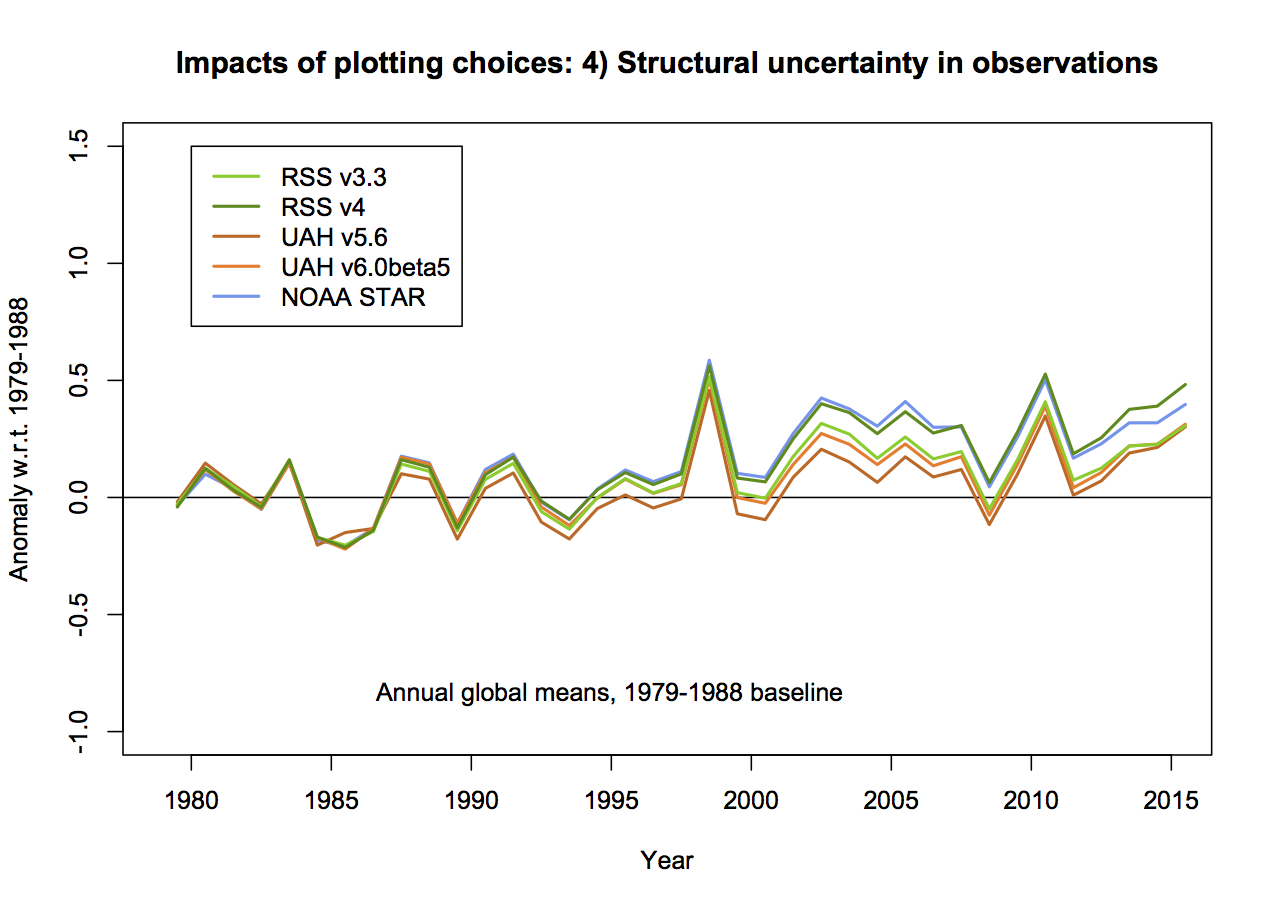
Summary
Let’s summarise the issues with Christy’s graphs each in turn:
- No model spread, inconsistent smoothing, no structural uncertainty in the satellite observations, weird baseline.
- No model spread, inconsistent trend calculation (though that is a small effect), no structural uncertainty in the satellite observations. Additionally, this is a lot of graph to show only 3 numbers.
- Incomplete model spread, inconsistent smoothing, no structural uncertainty in the satellite observations, weird baseline.
- Same as the previous graph but for the tropics-only data.
What then would be alternatives to these graphs that followed more reasonable conventions? As I stated above, I find that model spread is usefully shown using a mean and 95% envelope, smoothing should be consistent (though my preference is not to smooth the data beyond the annual mean so that padding issues don’t arise), the structural uncertainty in the observational datasets should be explicit and baselines should not be weird or distorting. If you only want to show trends, then a histogram is a better kind of figure. Given that, the set of four figures would be best condensed to two for each metric (global and tropical means):
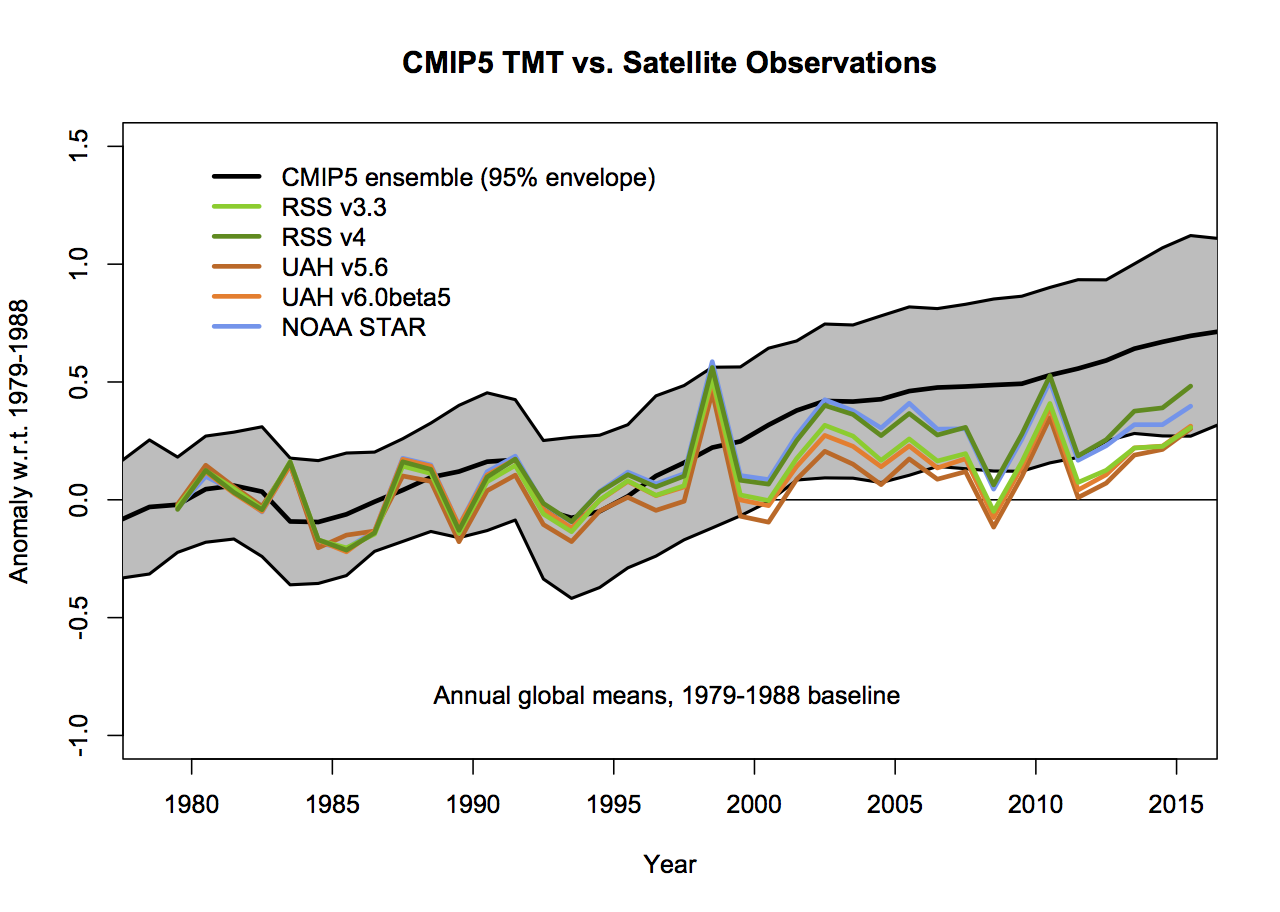
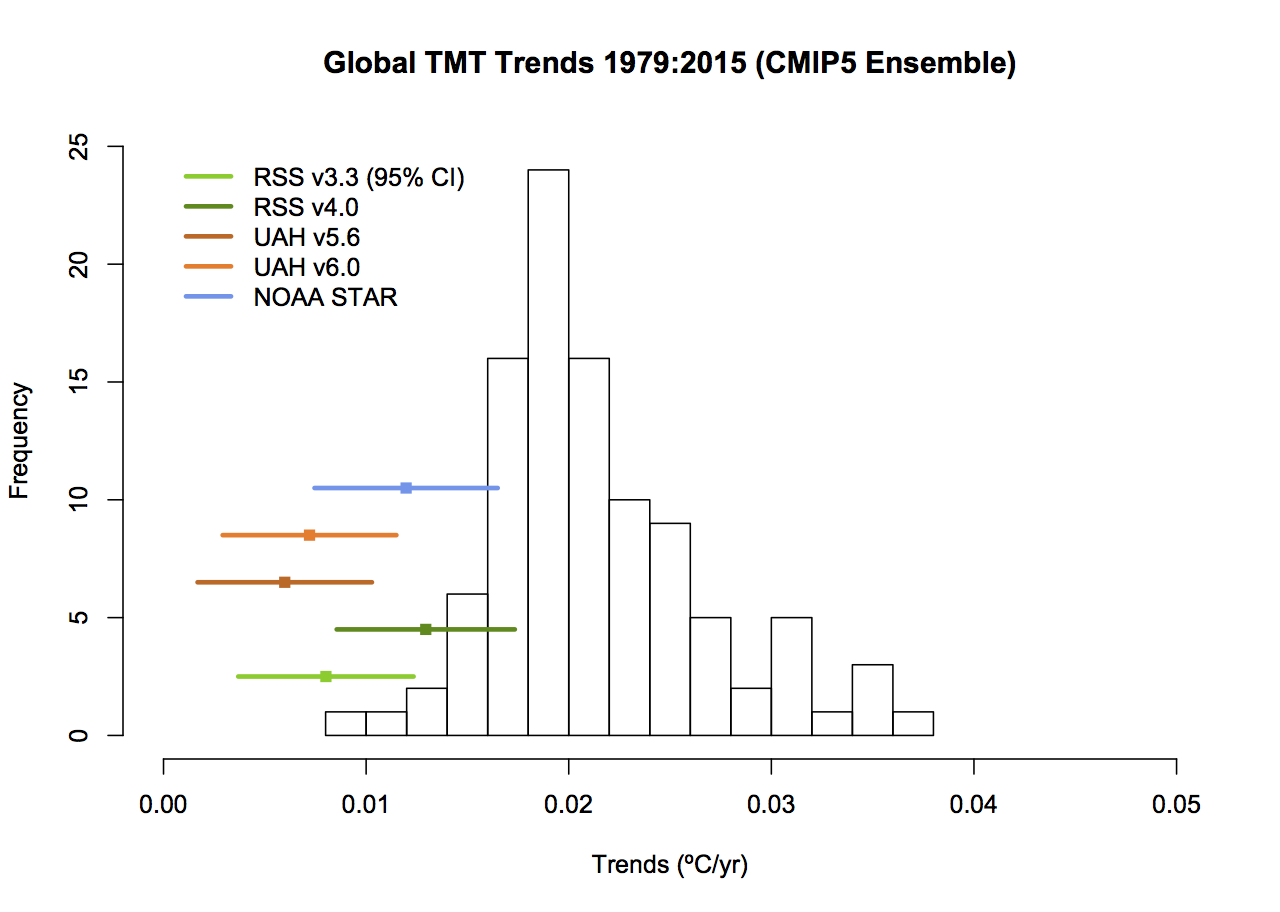
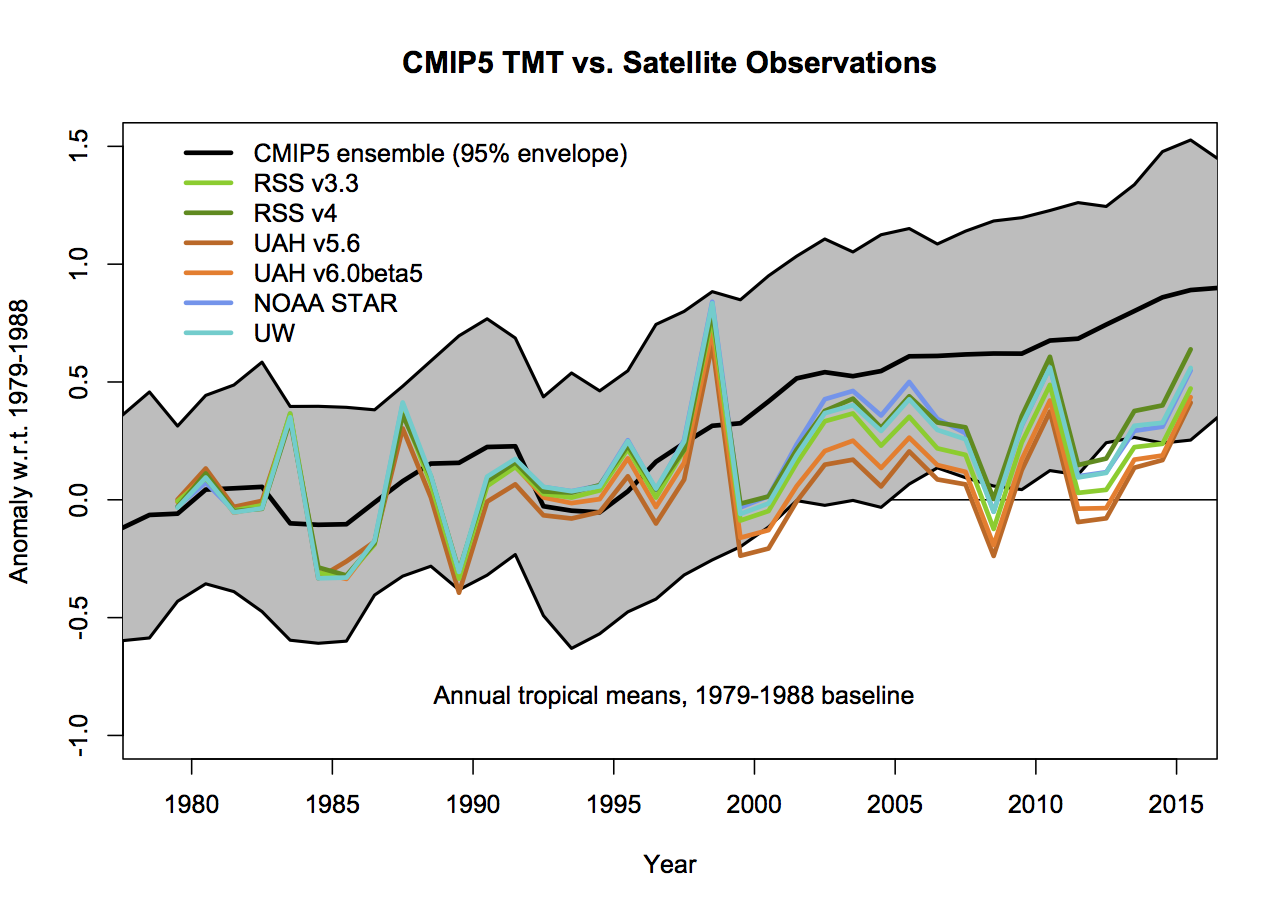
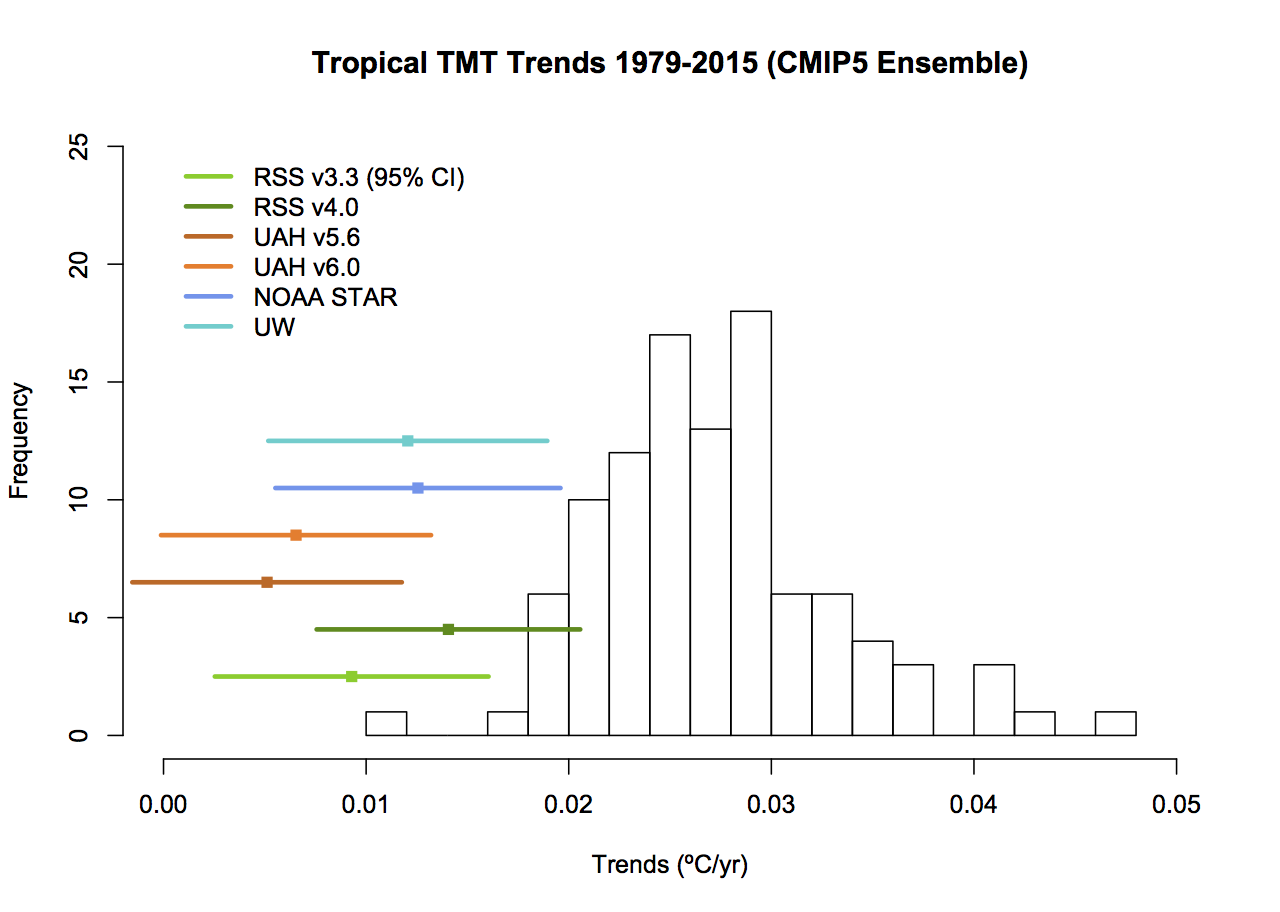
The trend histograms show far more information than Christy’s graphs, including the distribution across the ensemble and the standard OLS uncertainties on the linear trends in the observations. The difference between the global and tropical values are interesting too – there is a small shift to higher trends in the tropical values, but the uncertainty too is wider because of the greater relative importance of ENSO compared to the trend.
If the 5-year (padded) smoothing is really wanted, the first graphs would change as follows (note the trend plots don’t change):
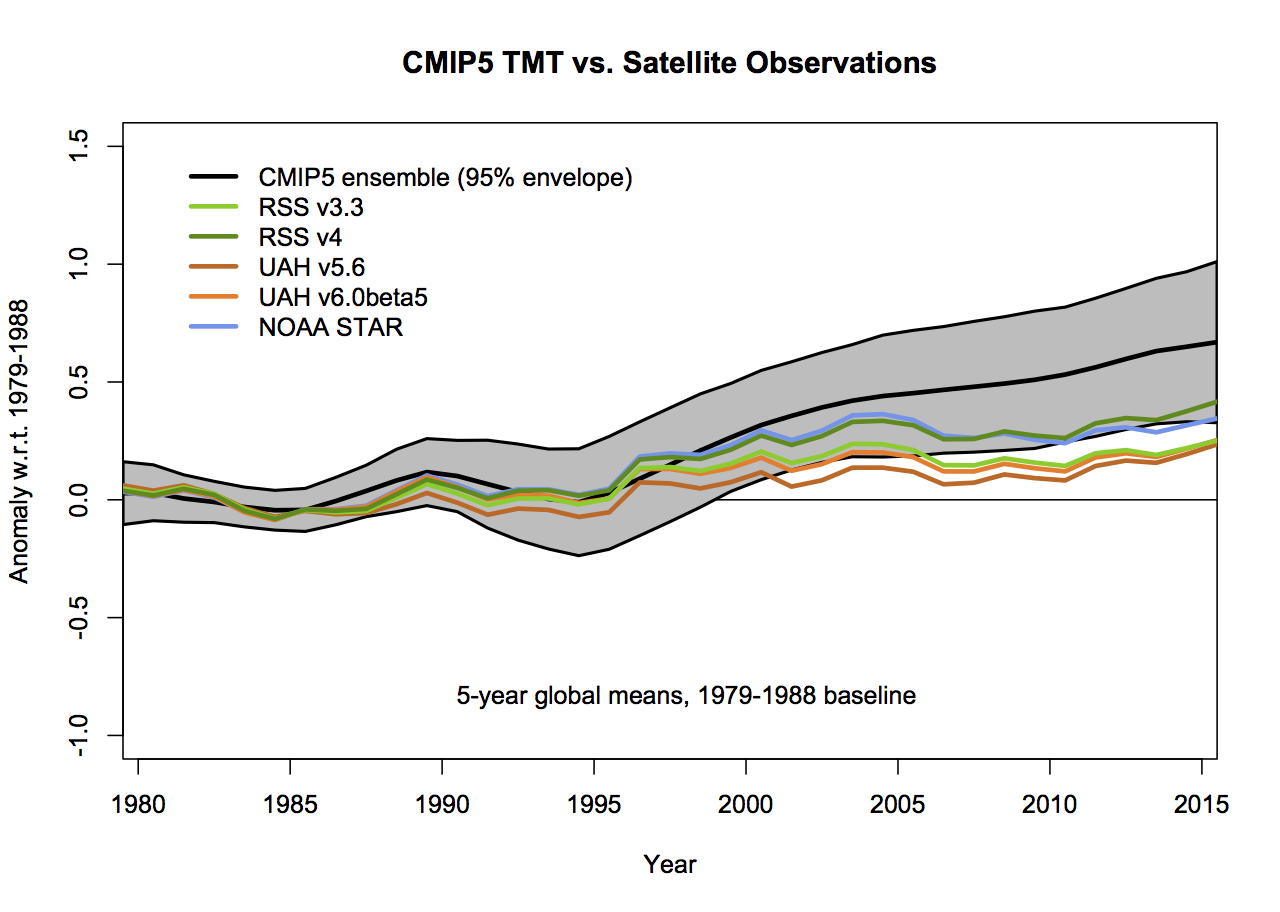
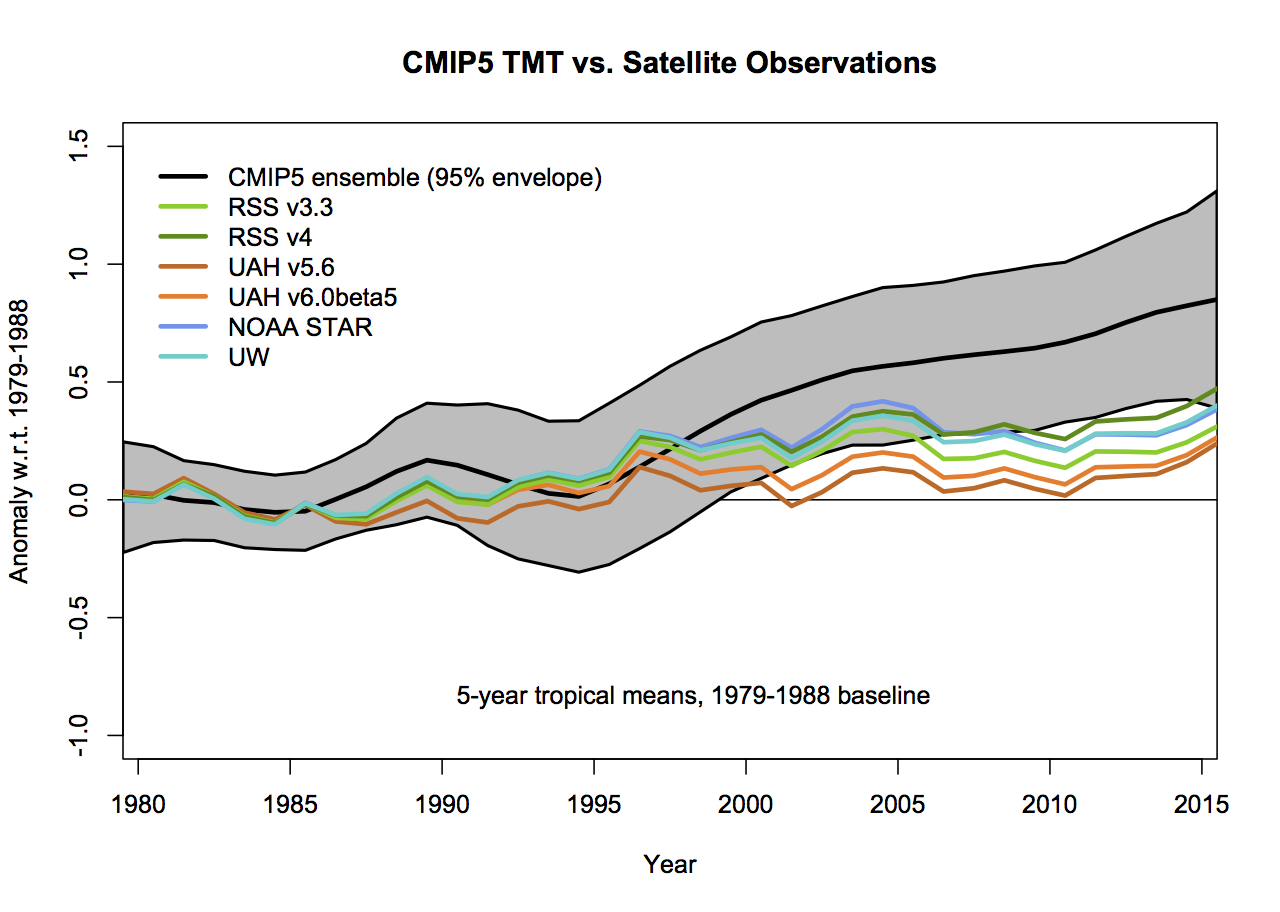
but the last two years will change as new data comes in.
So what?
Let’s remember the point here. We compare models and observations to learn something about the real world, not just to score points in some esoteric debate. So how does a better representation of the results help? Firstly, while the apparent differences are reduced in the updated presentation, they have not disappeared. But understanding how large the real differences actually are puts us in a better position to look for plausible reasons for them. Christy’s graphs are designed to lead you to a single conclusion (that the models are too sensitive to forcings), by eliminating consideration of the internal variability and structural uncertainty in the observations.
But Christy also ignores the importance of what forcings were used in the CMIP5 simulations. In work we did on the surface temperatures in CMIP5 and the real world, it became apparent that the forcings used in the models, particularly the solar and volcanic trends after 2000, imparted a warm bias in the models (up to 0.1ºC or so in the ensemble by 2012), which combined with the specific sequence of ENSO variability, explained most of the model-obs discrepancy in GMST. This result is not simply transferable to the TMT record (since the forcings and ENSO have different fingerprints in TMT than at the surface), but similar results will qualitatively hold. Alternative explanations – such as further structural uncertainty in the satellites, perhaps associated with the AMSU sensors after 2000, or some small overestimate of climate sensitivity in the model ensemble are plausible, but as yet there is no reason to support these ideas over the (known) issues with the forcings and ENSO. Some more work is needed here to calculate the TMT trends with updated forcings (soon!), and that will help further clarify things. With 2016 very likely to be the warmest year on record in the satellite observations the differences in trend will also diminish.
The bottom line is clear though – if you are interested in furthering understanding about what is happening in the climate system, you have to compare models and observations appropriately. However, if you are only interested in scoring points or political grandstanding then, of course, you can do what you like.
PS: I started drafting this post in December, but for multiple reasons didn’t finish it until now, updating it for 2015 data and referencing Christy’s Feb 16 testimony. I made some of these points on twitter, but some people seem to think that is equivalent to “mugging” someone. Might as well be hung for a blog post than a tweet though…
Superb article. thank you so much.
Missing is the unstated character of the kerfuffle — This has the appearance of carefully prepared PR tactic.
It fits nicely into the campaign to wedge apart scientific certainty. Promoting a lack of precision, is promoting uncertainty, which delays action and suspends the next step – which should have been curtailing carbon emissions four decades ago. Subsequent super profits from carbon fuel is all we have to blame for the now greater difficulty in facing this problem.
http://www.skepticalscience.com/examining-christys-skepticism.html
http://reason.com/archives/2006/09/22/confessions-of-an-alleged-exxo
His tactic seems like “Since we are in full discussion of the science, we should not move on to acting on this with energy policy” This maneuver continues to be enormously effective. And it is too bad you afford him the unearned respect of a scientist – just for building of charts from twisted and contrived data. You are correct, this is political grandstanding – and a PR campaign.
It seems foolish of him to be so obvious about it. Kind of Mark Morano-ish.
Thanks, Gavin! Been missing a recent models/obs discussion. These sorts of issues do keep coming up–of course.
Possible typo, 2nd last para–…”there is *no* reason to support these ideas over the (known) issues…”?
Nice. The part that struck me was the treatment of beyond-edge years during smoothing. Including the trend as a sloping line instead of a point when estimating missing values seems like an undergraduate-level issue to me. A smart undergraduate would naturally include it that way, while others may or may not do the mental work. But the prof would certainly correct them if they didn’t!
So this guy makes a mistake that would get marked up in undergraduate school. Why?
Richard Pauli’s cite: “And as with Dr. Lindzen’s alternative hypothesis, every single one of Dr. Christy’s arguments is directly contradicted by the observational data”
Me: A perfect example of how the peer-review literature needs serious reform. I think it’s a serious error to let such papers stand. As it is now, any idiot can legitimately quote crap science as “God’s Proclamations”. Why not fix the System? The blogosphere should be incorporated in the calculations. When a paper becomes publicly important, perhaps it should get a more thorough vetting?
Shouldn’t …
“but as yet there is reason to support these ideas over the (known) issues with the forcings and ENSO”
be …
“but as yet there is no reason to support these ideas over the (known) issues with the forcings and ENSO”
? (add the word ‘no’ before ‘support’)
[Response: Of course! Thanks. – gavin]
Eli also had a few earlier points to make showing that there is a systematic long term drift in the (A)MSU records
http://rabett.blogspot.com/2016/01/ups-and-downs.html
http://rabett.blogspot.com/2016/01/mind-bending.html
In my opinion Dr Christy used every trick possible to keep the satellite curve below the model curve on his chart.
Think about why he used a 5-year smoothing – why 5? Nothing wrong with annual smoothing.
Great post, critical subject, especially now. Graphics are a big key.
The good news is that things like the first video linked in the post are brilliantly done. By itself it’s a short course in climate-information media, I think. It shows what can be done with a dedicated (tightly purposed) combo-media essay. Thank you Gavin Schmidt. Thank you Yale Climate Connections.
Your histograms and Christy’s graphs convey the same message: the models are over-stating the warming rate, even if warming is occurring. Christy’s graphs help to elucidate what your histograms are about.
But still they diverge.
Yes, the testimony does follow whatever the political party in charge decided before witnesses were selected. The congressman was bought. That is the way it goes these days. See the book: “Too Smart for our Own Good” by Craig Dilworth. The hearing is just for show. We are already under a dictatorship/oligarchy of the richest few people. Telling the truth here will accomplish nothing.
Of course, there is also the parametric uncertainty in the estimates, as well as structural. Mears et al (caveat emptor applies) showed this parametric term to be large for the RSS product:
http://onlinelibrary.wiley.com/doi/10.1029/2010JD014954/abstract
This uncertainty is distinct from the trend-fit uncertainty and if accounted for would further expand the range of trend values that would be consistent with the RSS data processing algorithm compared to those shown. Quite how you would combine the two though …
[Response: Good point, but I’m including parametric uncertainty in what I call structural uncertainty – I don’t think they can be meaningfully distinguished. – gavin]
When the IPCC said the climate would warm between 1.4 to 5.8C from 1990 to 2100 in 2001, it gave a very high confidence in its own understanding of the climate which far from decreasing as the temperature failed to warm as predicted, instead increased. That was delusional and/or dishonest.
We have now waited waited and waited and waited for those involved to admit the simple fact that the models have proven to be invalid. In real science that is not a big deal. One simply says “the models appear to have errors” – new models are created and we go back to wait to see whether they are an improvement on the previous models. THAT IS NOT A BIG DEAL IN REAL SCIENCE.
But this is not real science,. This is jumped up politics and propaganda. And for that reason you on this website cannot admit the models are wrong and more forward. And so instead you are tying youself in knots trying to prove the frankly ridiculous idea that the models are “predicting” the climate.
The big issue, is not whether the models need improving – it’s the fact the whole subject is so biased and politicised & full of people with a financial interest that it can’t admit the simple scientific fact that the models need improving.
[Response: You are arguing against phantoms. Literally every paper I’ve written about models has discussed the need for improvements. In my TED talk I specifically said (pace Box) that all models are wrong. You are also myopic if you think that observations are perfect or that the experiments we perform in order to compare to reality are ideal. Indeed, all of those things need improving as well. But none of that undermines the fact that CO2 is a greenhouse gas, we are putting a lot of it out and the planet is warming (and will warm more) as a result. – gavin]
Geoff Sherrington.
“But still they diverge.”
The curves do diverge, but they also overlap. The overlap is not visible in Dr Christy’s graph.
Thank you for this article. It will be a handy reference for months and perhaps years to come. Thanks too for the spreadsheet of the model results for the tropical mid-troposphere. It’s probably too much to hope that John Christy will stop using these sort of tricks. (He’s been doing it for too long to expect he’ll break the bad habit.)
“Instead the linear trend through the smoothed record is calculated and the baseline of the lines is set so the trend lines all go through zero in 1979. To my knowledge this is a unique technique”
Not entirely. I advanced it here, as a way of best putting current station values on the same basis for spatial plotting. And I think it will liberate dealing with station anomaly from the requirement to have data in a specified period; using a trendline value rather than a mean diminishes the effect of using years that don’t exactly correspond to other stations.
But as used here by Christy it does increase the spread over time. A way to think about it is this. if you use a 30-year period, say 1981-2010, and use the trend value in 1996 (mid-point), then that is the same as the mean. If you change to use the trend value at 1981, you push upward all the lines with high trend, and downward all the lines with low trend. This diminishes spread near 1980, but increases it over most of the range. If you wanted to focus on behaviour near 1980 I think that makes sense, but as a fair picture over time, not.
Is it just me, or has realclimate suddenly started writing in tongues (Finnish tongues)?
MH 13: the models have proven to be invalid.
BPL: Is this some new definition of “invalid” I haven’t encountered before? Here are 17 correct model predictions I know of:
http://bartonlevenson.com/ModelsReliable.html
No models works like the global planet ,which is very complex.Here in province of Québec we have colder climate since 2014 (north of St-Laurence River).
We have records of cold weather and I read and watch all the scientific debates around the world (French,English)
My pessimist conclusion is focus on OCEANS Streams (Gulf stream and Labrador stream)
Just listen to Dr.James Hansen about the famous models………https://youtu.be/JP-cRqCQRc8
We do not have the time to discuss climate models.
Let’s make models about how to feed more than 7 billions humans on a planet that goes back to an ice-age long period.
With all my regards
Looking at Hansens original predictions one is amazed at how accurate they have turned out to be
If economist in particular and financial services in general could get model runs (and forward predictions) as accurate they would lauded as “masters of the universe”
Further proof that science is hard, conspiracies are easy
And the important point is that science moves forward
13 – “which far from decreasing as the temperature failed to warm as predicted, instead increased.”
Climate models do not forecast weather, and the “failed to warm” period you allude to is weather and not long enough to be called climate.
Essentially you are claiming that averages don’t work because you feel that they should capture the sample by sample variations in a data set.
Look you say… The last 15 children to walk into a school were pretty much all at or below the average height, it can’t be that over time student heights are increasing over time. The average didn’t predict the decline.
Silly.
lv 19,
Mme. vallée,
Les âges de glace sont régles par des “Cycles Milankovic” (Google qui, s’il vous plait). Nous ne sommes pas en raison d’une autre pour 20.000 ans, plus probablement 50.000. S’il vous plaît, étudiez.
#19, Louise–Nice to hear from you.
But if I look at the GISTEMP maps for ’14-’15, what I find is that you have had cold *winters* (well, the ‘cold season’, per NASA), warmish ‘warm seasons’, and the year as a whole near ‘normal’. (Though, since the baseline for GISTEMP is 1951-80, and the global trend is warming, that zero anomaly IS somewhat ‘cooler’ by current conditions.)
http://data.giss.nasa.gov/gistemp/maps/
You’ll note, though, that eastern-central Canada, especially Quebec and Ontario, have been colder than almost anywhere during that time. So it doesn’t look much like we are due for a return to the ice ages (if that is what you were trying to say.)
And I’d have to add that, if you are talking about conditions since 2014, you are talking about *weather*, not climate. Climate is by definition a longer-term average than that–the WHO standard is 30 years.
Scottish “Skeptic”:
So many errors of fact and logic packed into a short post. We can grant that Mr. Haseler is an efficient AGW-denier. Rather than try to keep up with the Gish gallop, I’ll just hit a few highlights:
Impossible expectations is a hallmark of the pseudo-skeptic. Argument by bald assertion is another. Just how does he justify his claims that projections in 2001 of warming of 1.4 to 5.8C from 1990 to 2100 have failed? It’s not 2100 yet, AFAIK.
Claiming superior mastery of real science, despite meager credentials, is another popular pseudo-skeptical conceit. It’s often accompanied by bitter accusations against actual scientists for failing to fulfil their sacred obligation to the public, who have waited far too long for their auguries. Yet the pseudo-skeptic insists that as long as climate models are still being refined, their projections are nothing more than WAGs. When for a brief period observed warming was slightly less than the projected mean, although still within the projected lower bound, he declares that “the models have proven to be invalid”. Science, he implies, can’t predict future climate any better than divination with a sheep’s liver!
Never mind that successive model refinements have only narrowed the range of projections within the confidence bounds of previous iterations; or that the slowed warming of 1998-2013 has led to proposals for resolution of short-term “noise” to internal forcing, by observed tropical Pacific SST oscillations among other factors. The pseudo-skeptic pays no attention to the chorus of praise for such refinements, but pronounces:
With that, the most diagnostic character of the pseudo-skeptic is revealed: the inevitable resort to conspiracist ideation. Because the “simple scientific fact” of AGW is simply unacceptable to him, it can only be a diabolical plot, one that began at least two centuries ago, and along the way enlisted thousands of scientists celebrated and obscure, from around the world. Imagining himself the righteous prosecutor of this monstrous crime, he points to the overwhelming consensus of working climate scientists as prima facie evidence for it. His inability to credibly document an ulterior motive for supporting the consensus merely convinces him that it’s most cleverly concealed, so he doubles down with FOIA requests. Of course, he scoffs at the abundant documentation of financial motives for AGW denial, while defending his corporate sponsors’ rights to privacy and “free speech” vigorously and entirely without irony.
I could go on, but why bother? Any genuine skeptic can take it from here, and pseudo-skeptics are impervious to facts anyway.
Sou:
You too? I thought it was something I did to my own browser 8^}.
Harry Twinotter says: 8 May 2016 at 4:05 AM
Steve McIntyre treats this matter of overlap in some detail at Climate Audit. I agree with his assertion that those promoting AGW hypotheses would prefer to see some overlap rather than none. This is mainly a cosmetic effect, like a cartoonist might use to make a point.
The real substance is whether the models are diverging from observation over time. Yes, they are, on all available evidence. Time would be better spent in discovering the reasons for the divergence.
BTW, model outcomes should be kept away from public policy decisions until the reasons for the divergence become known.
Lovely, thank you.
Louise, surely you have observed that on this fine earthly globe of ours, there is one area with frequent cool spots, in the north Atlantic. Something to do with Arctic and Greenland meltout, perchance? An overstatement, I know, but it rather looks like it. Not good news, though one could wish the deceivers had the magic key they desire to roll back reality, which is punishing the just with the unjust.
https://svs.gsfc.nasa.gov/cgi-bin/details.cgi?aid=4419
Perhaps the biggest deception in Christy’s claims – the one thing he really wants people *not* to understand – is that model outputs for global temperature are projections, not predictions.
If we look at the subset of model runs where climate forcings and natural stochastic variability happen to match real world values, it turns out that model output matches observations remarkably well. This means we can have confidence that the models are giving us reasonably accurate projections for various forcing scenarios in future decades.
Christy and his ilk use every dirty trick in the book to obscure this fact and cast unwarranted doubt on the findings of climate science.
for Susan Anderson (and Louise):
https://www.realclimate.org/index.php/archives/2015/03/whats-going-on-in-the-north-atlantic/
(found thus: https://www.google.com/search?q=site%3Arealclimate.org+cold+spot+north+atlantic+greenland
For anyone new these claims about models diverging — claims that keep being reposted as though they were fresh and new:
http://rabett.blogspot.com/2014/03/early-footnoteology.html
https://tamino.wordpress.com/2015/07/30/getting-model-data-comparison-right/
“Time would be better spent in discovering the reasons for the divergence.
BTW, model outcomes should be kept away from public policy decisions until the reasons for the divergence become known.”
Geoff Sherrington @26: I think one Gavin Schmidt has a paper on that. And waddayaknow, there’s even a link to that work in the second to last paragraph…
Needless to say, these show up often, in one form or another.
Here’s Roy Spencer, in Surrebuttal testimony (PDF p.5) as part of this MN court case on Social Cost of Carbon.*
The judge didn’t buy any of this.
* People sometimes get “session expired” messages, just try the URL again.
As a climate novice I’m frequently confused or uncertain, but is there another factor involved here?
I seem to recall that previous comparisons by Spencer and/or Christy of model projections to the instrumental record deliberately used RCP 8.5 model runs — perhaps noted in inconspicuous fine print? — which would predictably maximize discrepancies compared with actual observation.
Is this a factor here or is it irrelevant in what Christy is doing?
Thanks.
[Response: No. We’re using the RCP45 runs here (2006 onwards), but in any case, the difference with RCP85 would be barely noticeable on these timescales. – gavin]
Regardless of how interesting or important is this particular discussion of satellite data compared with models, is there a larger and more important reality that’s worth keeping in view?… The surface temps compared with models?
At some intuitive level I’d want the satellite discrepancies to be smaller, but if the modeling of surface temps where we live shows better agreement with observation, isn’t that more important? Even as we admit that tropospheric modeling — and the oft-adjusted satellite data itself — lags behind?
[Response: I posted the comparison with surface data on twitter (also here) a couple of months ago. – gavin]
13# Mike Haseler.
No models have proven to be invalid. All modelling states that temperatures going forwards will be non linear, and will have flat periods due to natural variation. It is impossible to predict start and end points for flat periods, so the models have error bars. Temperatures are within these error bars.
Thanks for doing this, Gavin.
Over at Bishop Hill (the blog of Andrew Montford) I’ve been discussing this, one commenter, Spence_UK defends Christy’s graph with a Gish Gallop of McIntyresque handwaving and molehill-to-mountainery, He objects to your baseline graph thus
“The first thing that Schmidt does is compare apples to oranges – yep he plots lines from different baselines on the same chart and then compares the lines directly. You can’t directly compare a baseline that centres in 1983/4 with a baseline that centres on 1979 – you need to shift the X-axis to align the centres to form a valid comparison. I can’t believe Schmidt has made such a dumb error! ”
I am not sure (a) why, (b) how or (c) what difference adjusting the x-axis would as described would make. Anyone got a clue what he’s on about?
http://bishophill.squarespace.com/blog/2016/4/23/gav-loses-it-josh-371.html?currentPage=3#comments
“There are two ways to be fooled. One is to believe what isn’t true; the other is to refuse to believe what is true.”
― Søren Kierkegaard
Satellite and ground temperature measurements agree at the surface. And with the recent rapid warming, I’d guess that the observed global average surface temperature and the model ensemble mean would have to be in the same ballpark.
Is it then fair to say that the issue is that the model ensemble has under-predicted stratospheric cooling? I say this for a few reasons.
One, the Realclimate posts on why the stratosphere should cool made that seem like a fundamentally complex topic with some evolution of thinking over the past decade. So I wonder if that might be a fundamentally weak point of the model ensemble. If some models don’t do a good job of capturing those processes, then, sure, the model ensemble will under-predict stratospheric cooling. And so over-predict average temperatures for that entire slice of the atmosphere.
Two, are those temperatures mass-weighted, or just simple spatial averages? Averaging temperatures by area makes good sense for ground measurements, but makes no sense at all (to me) for measurements through the thickness of the atmosphere. If I’m reading the data right, 90% of the mass of the atmosphere is below 10 miles above the surface. If they aren’t weighted by mass, they grossly overstate the problem if “the problem” is really the heat content of the of the atmosphere. If the models get it right at the surface, but wrong at 50,000 feet, then a) nobody lives in the stratosphere, and b) there isn’t much air there either. I’m not exactly saying “who cares”, more like, the models are much close to the actual observed energy budget than these graphs would suggest.
Third, this changes the characterization of the error. Christy’s testimony characterized the model ensemble as overstating the problem. Damn those lying scientists. But, heuristically, it’s hard for an average of a bunch of disparate models to over-predict anything, relative to observations, absent some fundamental structural issue that they all share. At least in the long run, observations tend to vary more than the average. By contrast, it would seem relatively easy for them to under-predict something. So if this could accurately be characterized as “the ensemble under-predicts stratospheric cooling”, then at that point, the model ensemble appears conservative relative to observations, which is kind of what I would expect. And the the conversation should then be about why the models are understating this aspect of global warming, not overstating it.
Regarding Section 2 – Inconsistent smoothing
I don’t know exactly how Christy treated the end points of his 5 year moving average. However, in his other work presenting monthly average data, he doesn’t actually pad the endpoints the way you describe. His posts include 12 month moving averages, showing data points beginning with December 1978, the first month for which measurements are available. On other occasions, Christy simply extended the 12 month moving average, using “NUL” values to fill the missing values beyond the end of available data. Thus, there’s no actual padding in the calculation, but the sum of available points is still divided by the averaging period. With his October 2015 example, that resulted in values being entered thru the end of the year, which, of course, hadn’t happened yet. His latest post (archived HERE) somehow manages to provide values thru December 2016, a truly great scientific advancement in forecasting if ever there was one…:-)
Perhaps it’s time for Dr. Christy to retire, so he can pursue his favorite pass times, marathon running to feed his endorphin habit, teaching Sunday School and presenting papers at NIPC conferences…
Geoff: The real substance is whether the models are diverging from observation over time. Yes, they are, on all available evidence.
Richard: Why did you choose to pretend that it’s still 2013? Here in 2016, it’s hotter than models predicted. Catch up, and start harping in the other direction! (I’m assuming you’re honest and consistent, so I fully expect to see you complaining that models UNDERESTIMATE warming.)
comment to Christopher Hogan who wrote on May 10th, 2016 at 8:36 AM
“, I’d guess that the observed global average surface temperature and the model ensemble mean would have to be in the same ballpark.”
Depends on your ballpark. In general, it is *not* expected that model ensemble mean should project real surface or tropospheric temperature.
As explained above, the planet is effectively executing only one of the models.. Not their average…
*hanged. :)
Good post Gavin,
However, it is quite obvious that the satellite temperatures run in the lower end of the model ensemble.
That does not mean that the models (or model mean) are bad.
There are problems with the satellites:
-The record is short (37 years) and starts during a warm period (topped by a strong el Nino in 1982-1983) following a fast increase from cool conditions in the mid-seventies.
-Satellites have poor vertical resolution. The TMT-layer includes a large share of the stratosphere, which has cooled faster than expected by the models. What about the troposphere part, does the warming follow that projected by the models?
-There are issues with the satellite record. Satellite data diverge markedly from radiosondes during the AMSU period (after 1998).
Here is a comparison between UAH v6 TLT and Ratpac A:
https://drive.google.com/open?id=0B_dL1shkWewaVUdobkJYcjM5VmM
It shows the distinct trend break at year 2000, which is typical for all satellite/radiosonde troposphere dataset comparisons. It has been partially amended with the new RSS v4 product.
It also shows that subsampling of satellite data to match radiosonde locations doesn’t change the result, nor does a TLT-weighting of radiosonde data..
It also demonstrates that the Ratpac product, despite being based on only 85 stations, gives a fair global representation.
Finally, here is a Ratpac vs Model mean comparison of global troposphere temperatures between 1970 and 2016:
https://drive.google.com/open?id=0B_dL1shkWewaaDdkMFN1NUMxUGM
There is a quite good fit if one accepts the “noise” due to natural varions, etc. Strictly speaking, the model mean trend is slightly larger, 0.24 vs 0.20 C/decade, but right now we are above the model mean, and the 12-month Ratpac running mean (the Nino-peak) will likely continue to rise for at least two seasons..
To comment 41: I’m aware of that.
Christy compares observed data to the mean of the model ensemble. Right now, I think the observed surface temperature should be close to the ensemble mean. If so, then the entire discrepancy that Christy shows is due to discrepancies away from the surface.
So, is the tail of the stratosphere wagging the dog of the atmosphere, in this particular comparison? That’s all I’m trying to get at.
E.g., if these are spatially-weighted temperatures, then the Christy analysis does not show that modeled and observed trend in the heat content of the atmosphere have diverged significantly. That was the point of my mass-weighted comment above.
Is this, then, a cherry-pick of sorts? Despite being of deep scientific interest? I think that depends on the definition. If you define “cherry pick” as focusing on a small subset of the system, then, maybe it is.
If Christy had picked off some small fraction of the surface where there was a large model-observation discrepancy, the cherry-picking aspect of that would be obvious. And if the discrepancy here is due to a model-observation divergence for a small fraction of the atmosphere’s mass, maybe that’s just a more subtle cherry-pick.
It just has to do with the weighting. If the stratosphere is 1/10th the mass of the atmosphere, then spatially-weighted temperature discrepancies will end up being (roughly) 10x larger than the actual model-observation differences in heat content.
As noted in the post, denialists focus on this to the exclusion of large number of other model-data comparisons. Maybe we’re seeing that because this is a seemingly honest comparison (of scientific interest) that just happens greatly to magnify a discrepancy in modeling the energy budget of the atmosphere.
Well, I answered my own question. It looks like the peak of the TMT distribution is low enough that this should not be an issue.
Richard, #40:
“Here in 2016, it’s hotter than models predicted. Catch up, and start harping in the other direction!”
Just so.
To comment 44.
If I read it right Gavin used those model runs here which correspond to tropospheric measurements.. I am not sure if Cristy used them or model runs for surface temperature. In any case these selections should automagically cover your concerns regarding mass of air.. But I may be mistaken..
Re: My post @39
I looked more closely at the UAH data for TLT v6b5 which I linked to in the post. By recalculating the moving average, I found that Christy had indeed padded the beginning of the average data by padding with ever smaller slices of the original data, down to the first values, which were identical to the corresponding point in the original data.
Another issue not discussed is the creation of the simulated satellite data from the model output, which I think is what is plotted. This process has never been documented (as far as I know), so I assume that a model of the emissions is calculated, then fed into the UAH v5.6 algorithm. But, the algorithm was developed using the US Standard Atmosphere, which is itself an ideal model that assumes a surface temperature of 15C, 70% humidity, and clear skies. But, we know that the actual MSU2/AMSU5 measurements are sensitive to rain and hydro-meteors, ie., precipitable water, as well as surface type, including ice and snow cover. In addition, on one graph, Christy claims to have used model data from the KNMI Climate Explorer, which lists output only monthly at the surface, Z200 and Z500 elevations. One is left to guess how accurate it is to use monthly data for what are essentially daily measurements. Without the details of the method used to calculate the simulated model temperatures, the resulting comparisons would be suspect, IMHO.
I criticized Christy’s use of a short and early baseline a couple of years ago:
https://ourchangingclimate.wordpress.com/2014/02/22/john-christy-richard-mcnider-roy-spencer-flat-earth-hot-spot-figure-baseline/
For this post, Jos Hagelaars reproduced a previous Christy figure with different baselines to see the visual effect it has. The use of a short and early baseline maximizes the visual appearance of a discrepancy.
Thanks to Gavin at 13 response with “all models are wrong.”
I also skimmed and can’t find the point that the models furnish projections, not predictions, but thanks for that reminder.
I also like the observation above that the planet is executing a single climate model, not the average or mean of the various models.
I gained a lot from reading this post and the comments. thanks to all who put effort into this discussion.
(and, yes, Hansen is looking like a genius with his career assessment of AGW. Well done, sir!)
Warm regards
Mike