How should one make graphics that appropriately compare models and observations? There are basically two key points (explored in more depth here) – comparisons should be ‘like with like’, and different sources of uncertainty should be clear, whether uncertainties are related to ‘weather’ and/or structural uncertainty in either the observations or the models. There are unfortunately many graphics going around that fail to do this properly, and some prominent ones are associated with satellite temperatures made by John Christy. This post explains exactly why these graphs are misleading and how more honest presentations of the comparison allow for more informed discussions of why and how these records are changing and differ from models.
The dominant contrarian talking point of the last few years has concerned the ‘satellite’ temperatures. The almost exclusive use of this topic, for instance, in recent congressional hearings, coincides (by total coincidence I’m sure) with the stubborn insistence of the surface temperature data sets, ocean heat content, sea ice trends, sea levels, etc. to show continued effects of warming and break historical records. To hear some tell it, one might get the impression that there are no other relevant data sets, and that the satellites are a uniquely perfect measure of the earth’s climate state. Neither of these things are, however, true.
The satellites in question are a series of polar-orbiting NOAA and NASA satellites with Microwave Sounding Unit (MSU) instruments (more recent versions are called the Advanced MSU or AMSU for short). Despite Will Happer’s recent insistence, these instruments do not register temperatures “just like an infra-red thermometer at the doctor’s”, but rather detect specific emission lines from O2 in the microwave band. These depend on the temperature of the O2 molecules, and by picking different bands and different angles through the atmosphere, different weighted averages of the bulk temperature of the atmosphere can theoretically be retrieved. In practice, the work to build climate records from these raw data is substantial, involving inter-satellite calibrations, systematic biases, non-climatic drifts over time, and perhaps inevitably, coding errors in the processing programs (no shame there – all code I’ve ever written or been involved with has bugs).
Let’s take Christy’s Feb 16, 2016 testimony. In it there are four figures comparing the MSU data products and model simulations. The specific metric being plotted is denoted the Temperature of the “Mid-Troposphere” (TMT). This corresponds to the MSU Channel 2, and the new AMSU Channel 5 (more or less) and integrates up from the surface through to the lower stratosphere. Because the stratosphere is cooling over time and responds uniquely to volcanoes, ozone depletion and solar forcing, TMT is warming differently than the troposphere as a whole or the surface. It thus must be compared to similarly weighted integrations in the models for the comparisons to make any sense.
The four figures are the following:
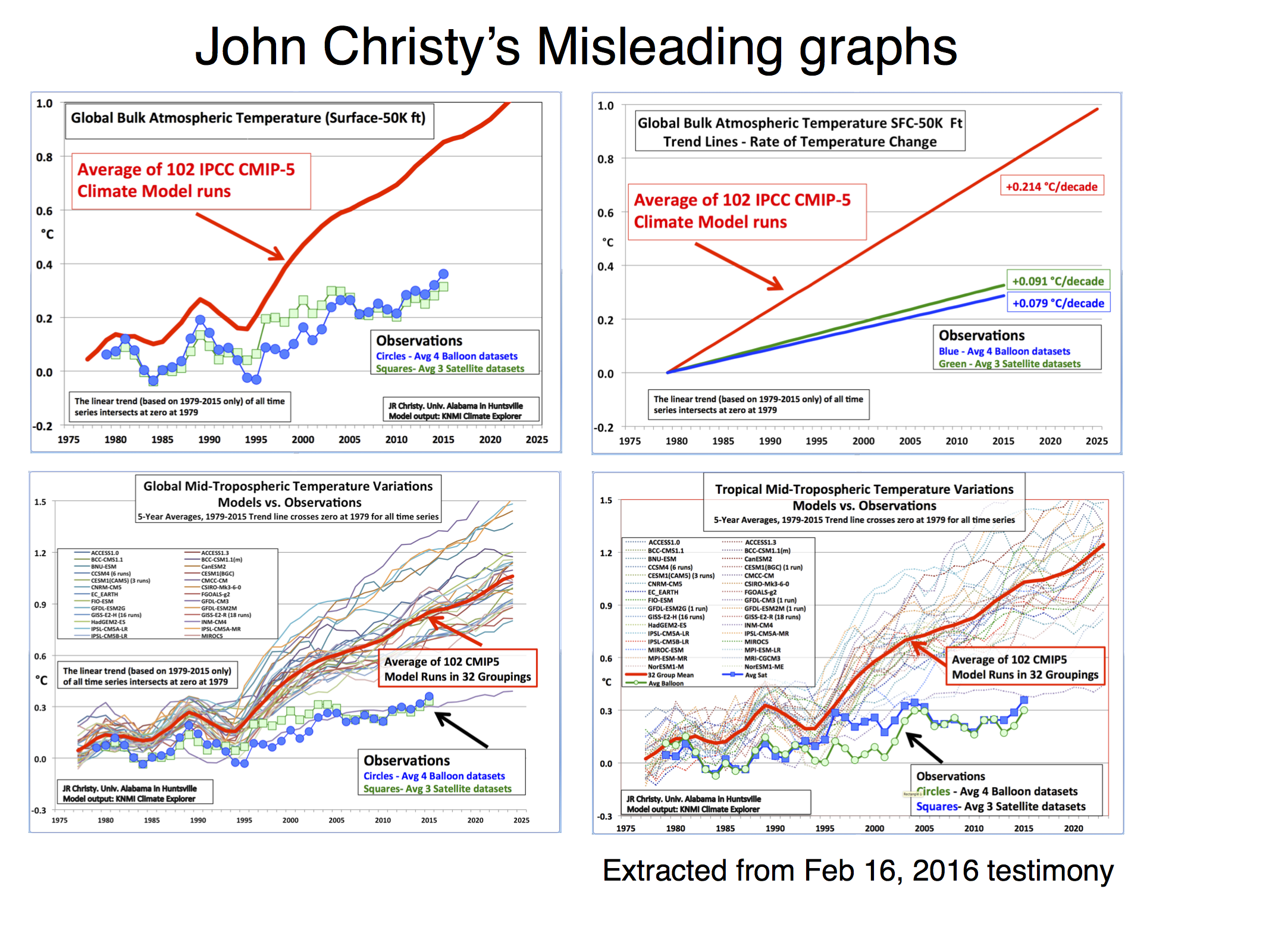
There are four decisions made in plotting these graphs that are problematic:
- Choice of baseline,
- Inconsistent smoothing,
- Incomplete representation of the initial condition and structural uncertainty in the models,
- No depiction of the structural uncertainty in the satellite observations.
Each of these four choices separately (and even more so together) has the effect of making the visual discrepancy between the models and observational products larger, misleading the reader as to the magnitude of the discrepancy and, therefore, it’s potential cause(s).
To avoid discussions of the details involved in the vertical weighting for TMT for the CMIP5 models, in the following, I will just use the collation of this metric directly from John Christy (by way of Chip Knappenburger). This is derived from public domain data (historical experiments to 2005 and RCP45 thereafter) and anyone interested can download it here. Comparisons of specific simulations for other estimates of these anomalies show no substantive differences and so I’m happy to accept Christy’s calculations on this. Secondly, I am not going to bother with the balloon data to save clutter and effort; None of the points I want to make depend on this.
In all that follows, I am discussing the TMT product, and as a shorthand, when I say observations, I mean the observationally-derived TMT product. For each of the items, I’ll use the model ensemble to demonstrate the difference the choices make (except for the last one), and only combine things below.
1. Baselines
Worrying about baseline used for the anomalies can seem silly, since trends are insensitive to the baseline. However there are visual consequences to this choice. Given the internal variability of the system, baselines to short periods (a year or two or three) cause larger spreads away from the calibration period. Picking a period that was anomalously warm in the observations pushes those lines down relative to the models exaggerating the difference later in time. Longer periods (i.e. decadal or longer) have a more even magnitude of internal variability over time and so are preferred for enhancing the impact of forced (or external) trends. For surface temperatures, baselines of 20 or 30 years are commonplace, but for the relatively short satellite period (37 years so far) that long a baseline would excessively obscure differences in trends, so I use a ten year period below. Historically, Christy and Spencer have use single years (1979) or short periods (1979-1983), however, in the above graphs, the baseline is not that simple. Instead the linear trend through the smoothed record is calculated and the baseline of the lines is set so the trend lines all go through zero in 1979. To my knowledge this is a unique technique and I’m not even clear on how one should label the y-axis.
To illustrate what impact these choices have, I’ll use the models in graphics that use for 4 different choices. I’m using the annual data to avoid issues with Christy’s smoothing (see below) and I’m plotting the 95% envelope of the ensemble (so 5% of simulations would be expected to be outside these envelopes at any time if the spread was Gaussian).
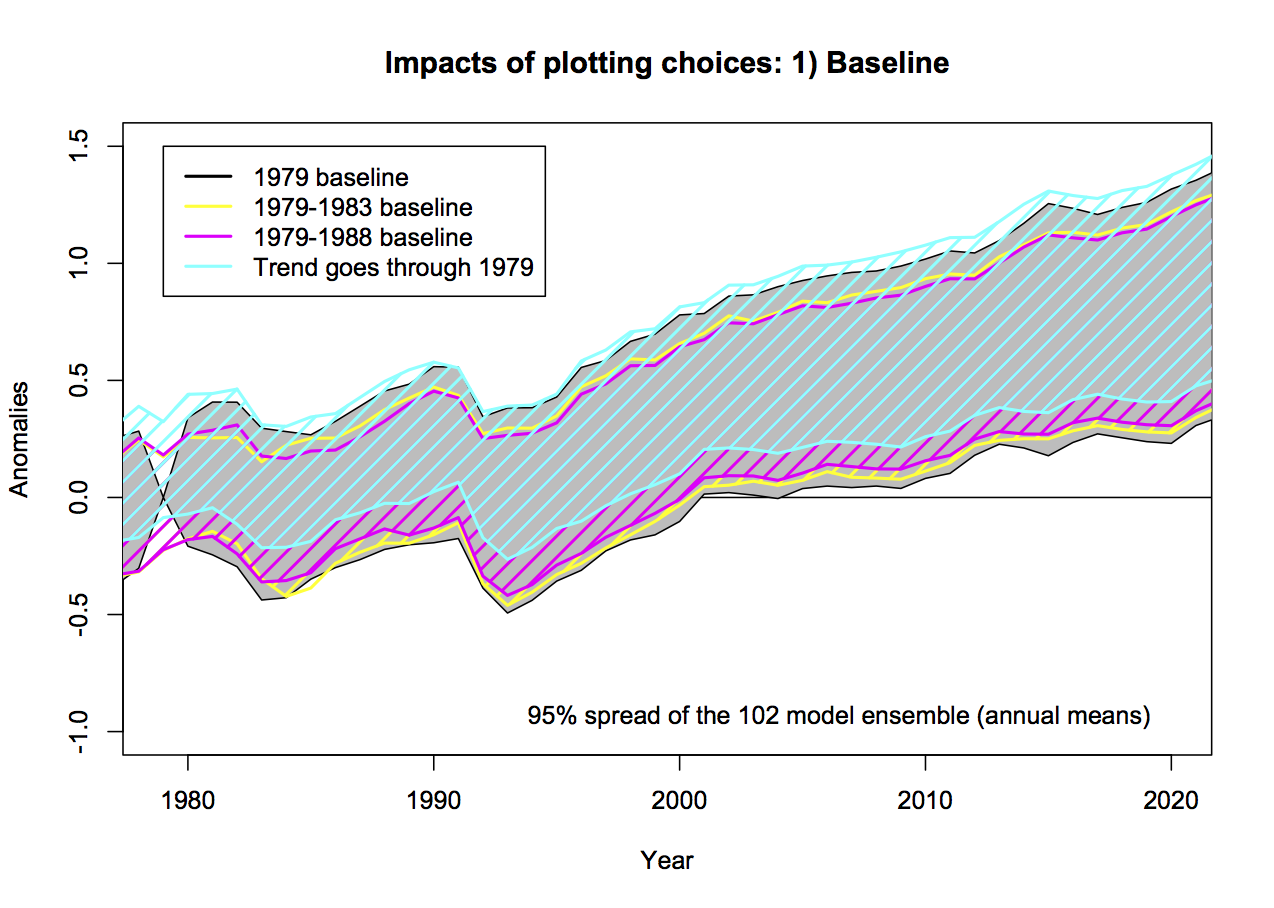
Using the case with the decade-long baseline (1979-1988) as a reference, the spread in 2015 with the 1979 baseline is 22% wider, with 1979-1983, it’s 7% wider, and the case with the fixed 1979-2015 trendline, 10% wider. The last case is also 0.14ºC higher on average. For reference, the spread with a 20 and 30 year baseline would be 7 and 14% narrower than the 1979-1988 baseline case.
2. Inconsistent smoothing
Christy purports to be using 5-yr running mean smoothing, and mostly he does. However at the ends of the observational data sets, he is using a 4 and then 3-yr smoothing for the two end points. This is equivalent to assuming that the subsequent 2 years will be equal to the mean of the previous 3 and in a situation where there is strong trend, that is unlikely to be true. In the models, Christy correctly calculates the 5-year means, therefore increasing their trend (slightly) relative to the observations. This is not a big issue, but the effect of the choice also widens the discrepancy a little. It also affects the baselining issue discussed above because the trends are not strictly commensurate between the models and the observations, and the trend is used in the baseline. Note that Christy gives the trends from his smoothed data, not the annual mean data, implying that he is using a longer period in the models.
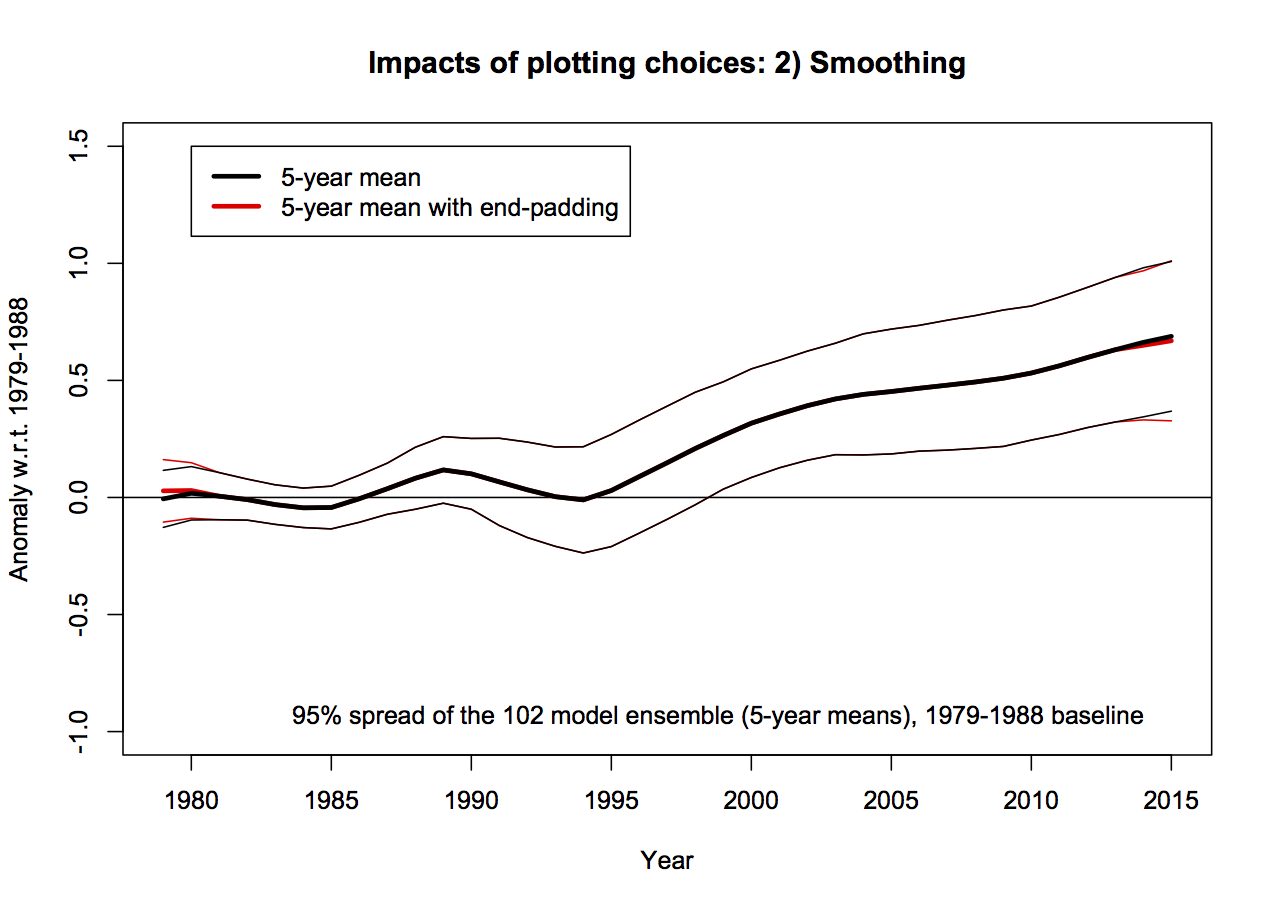
This can be quantified, for instance, the trend in the 5yr-smoothed ensemble mean is 0.214ºC/dec, compared to 0.210ºC/dec on the annual data (1979-2015). For the RSS v4 and UAH v6 data the trends on the 5yr-smooth w/padding are 0.127ºC/dec and 0.070ºC/dec respectively, compared to the trends on the annual means of 0.129ºC/dec and 0.072ºC/dec. These are small differences, but IMO a totally unnecessary complication.
3. Model spread
The CMIP5 ensemble is what is known as an ‘ensemble of opportunity’, it contains many independent (and not so independent) models, with varying numbers of ensemble members, haphazardly put together by the world’s climate modeling groups. It should not be seen as a probability density function for ‘all plausible model results’, nonetheless, it is often used as such implicitly. There are three sources of variation across this ensemble. The easiest to deal with and the largest term for short time periods is initial condition uncertainty (the ‘weather’); if you take the same model, with the same forcings and perturb the initial conditions slightly, the ‘weather’ will be different in each run (El Niño’s will be in different years etc.). Second, is the variation in model response to changing forcings – a more sensitive model will have a larger response than a less sensitive model. Thirdly, there is variation in the forcings themselves, both across models and with respect to the real world. There should be no expectation that the CMIP5 ensemble samples the true uncertainties in these last two variations.
Plotting all the runs individually (102 in this case) generally makes a mess since no-one can distinguish individual simulations. Grouping them in classes as a function of model origin or number of ensemble members reduces the variance for no good reason. Thus, I mostly plot the 95% envelope of the runs – this is stable to additional model runs from the same underlying distribution and does not add to excessive chart junk. You can see the relationship between the individual models and the envelope here:
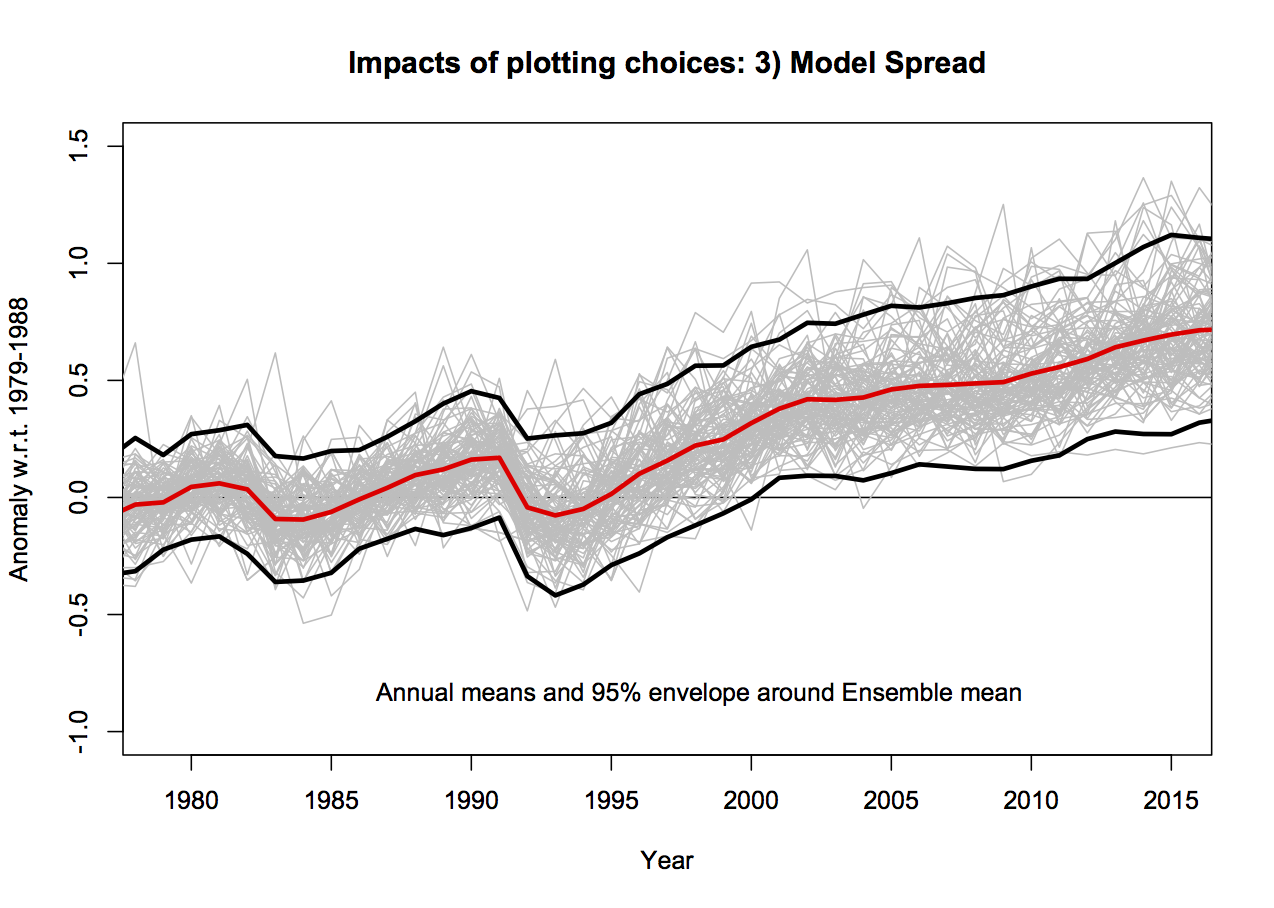
4. Structural uncertainty in the observations
This is the big one. In none of the Christy graphs is there any indication of what the variation of the trend or the annual values are as a function of the different variations in how the observational MSU TMT anomalies are calculated. The real structural uncertainty is hard to know for certain, but we can get an idea by using the satellite products derived either by different methods by the same group, or by different groups. There are two recent versions of both RSS and UAH, and independent versions developed by NOAA STAR, and for the tropics only, a group at UW. However this is estimated, it will cause a spread in the observational lines. And this is where the baseline and smoothing issues become more important (because a short baseline increases the later spread) not showing the observational spread effectively makes the gap between models and observations seem larger.
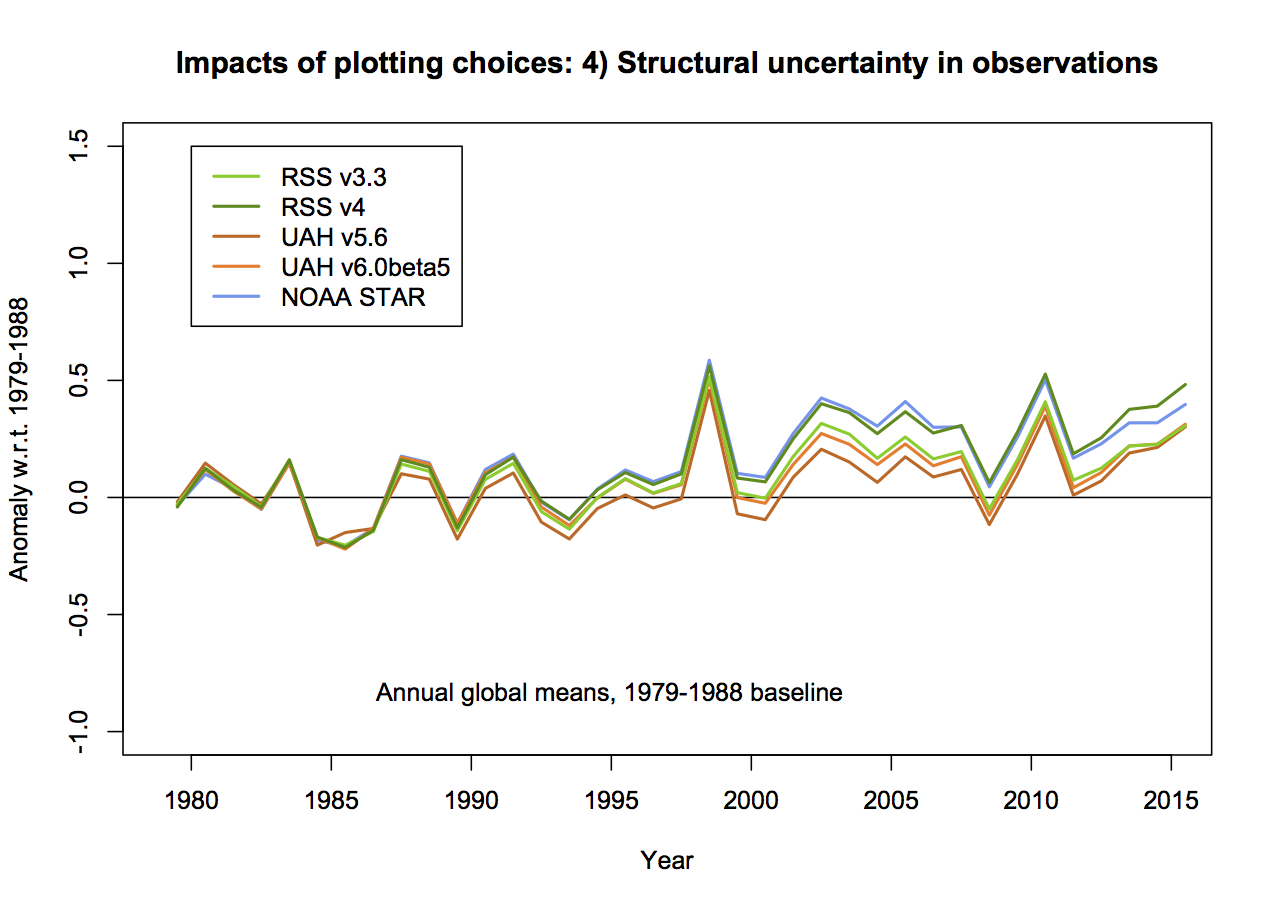
Summary
Let’s summarise the issues with Christy’s graphs each in turn:
- No model spread, inconsistent smoothing, no structural uncertainty in the satellite observations, weird baseline.
- No model spread, inconsistent trend calculation (though that is a small effect), no structural uncertainty in the satellite observations. Additionally, this is a lot of graph to show only 3 numbers.
- Incomplete model spread, inconsistent smoothing, no structural uncertainty in the satellite observations, weird baseline.
- Same as the previous graph but for the tropics-only data.
What then would be alternatives to these graphs that followed more reasonable conventions? As I stated above, I find that model spread is usefully shown using a mean and 95% envelope, smoothing should be consistent (though my preference is not to smooth the data beyond the annual mean so that padding issues don’t arise), the structural uncertainty in the observational datasets should be explicit and baselines should not be weird or distorting. If you only want to show trends, then a histogram is a better kind of figure. Given that, the set of four figures would be best condensed to two for each metric (global and tropical means):
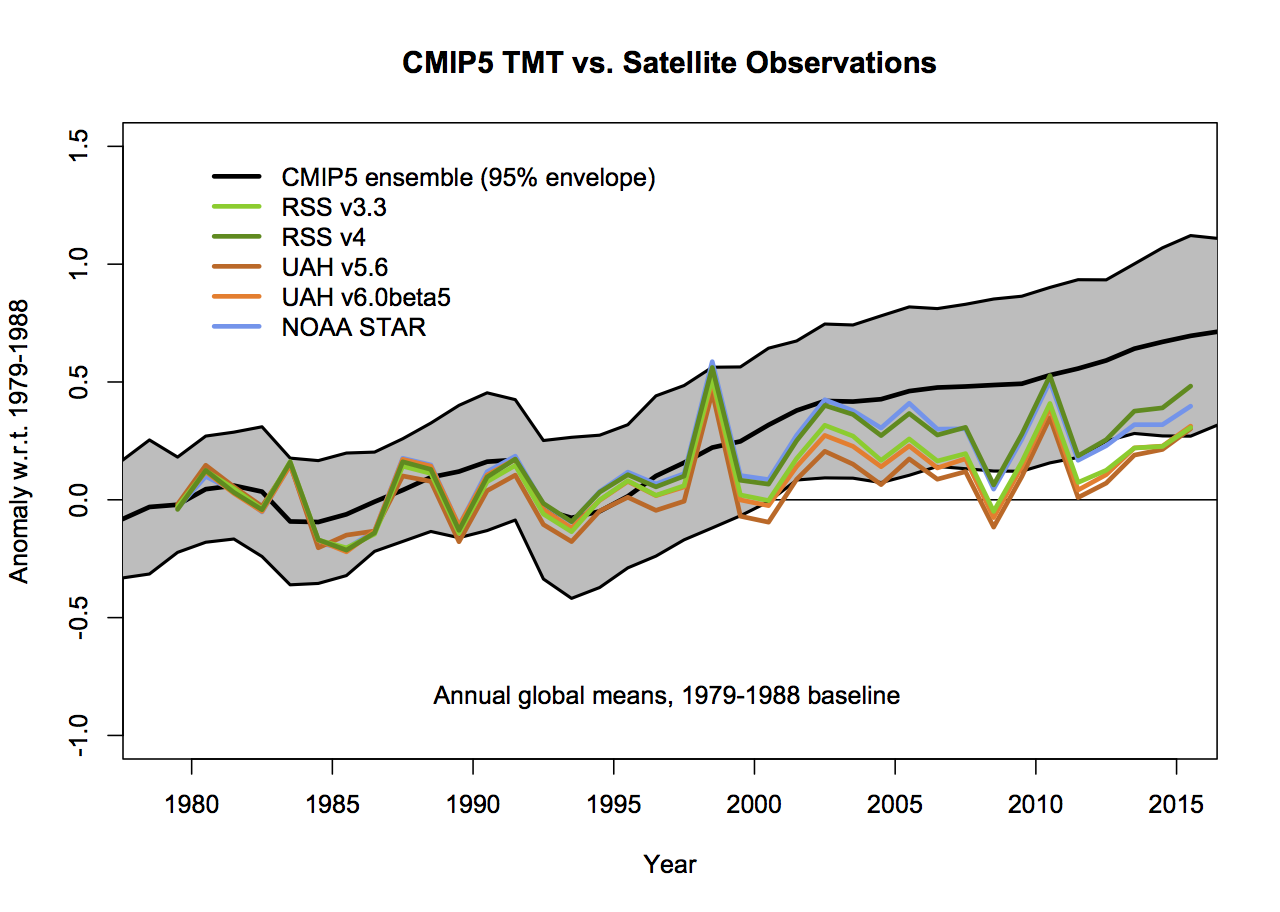
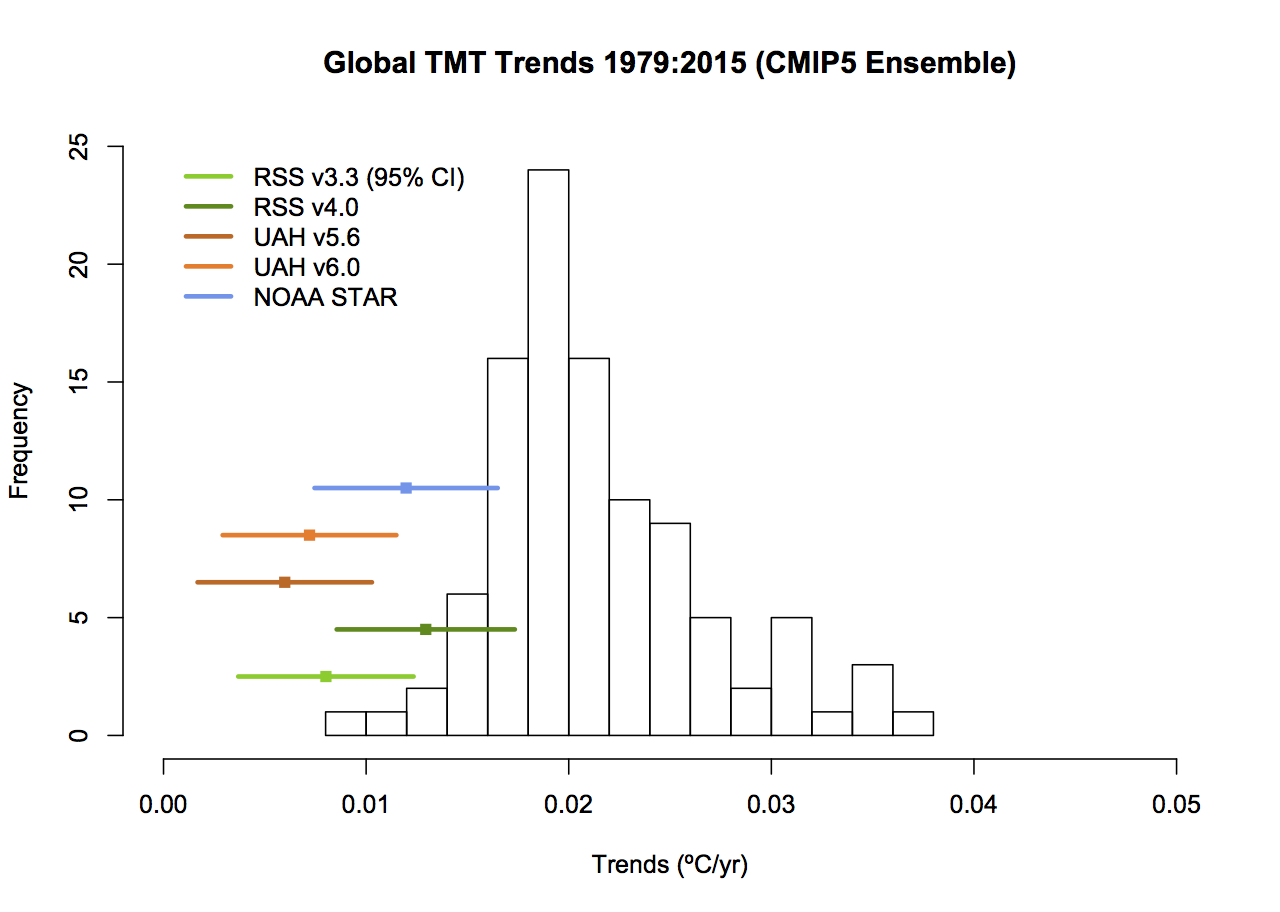
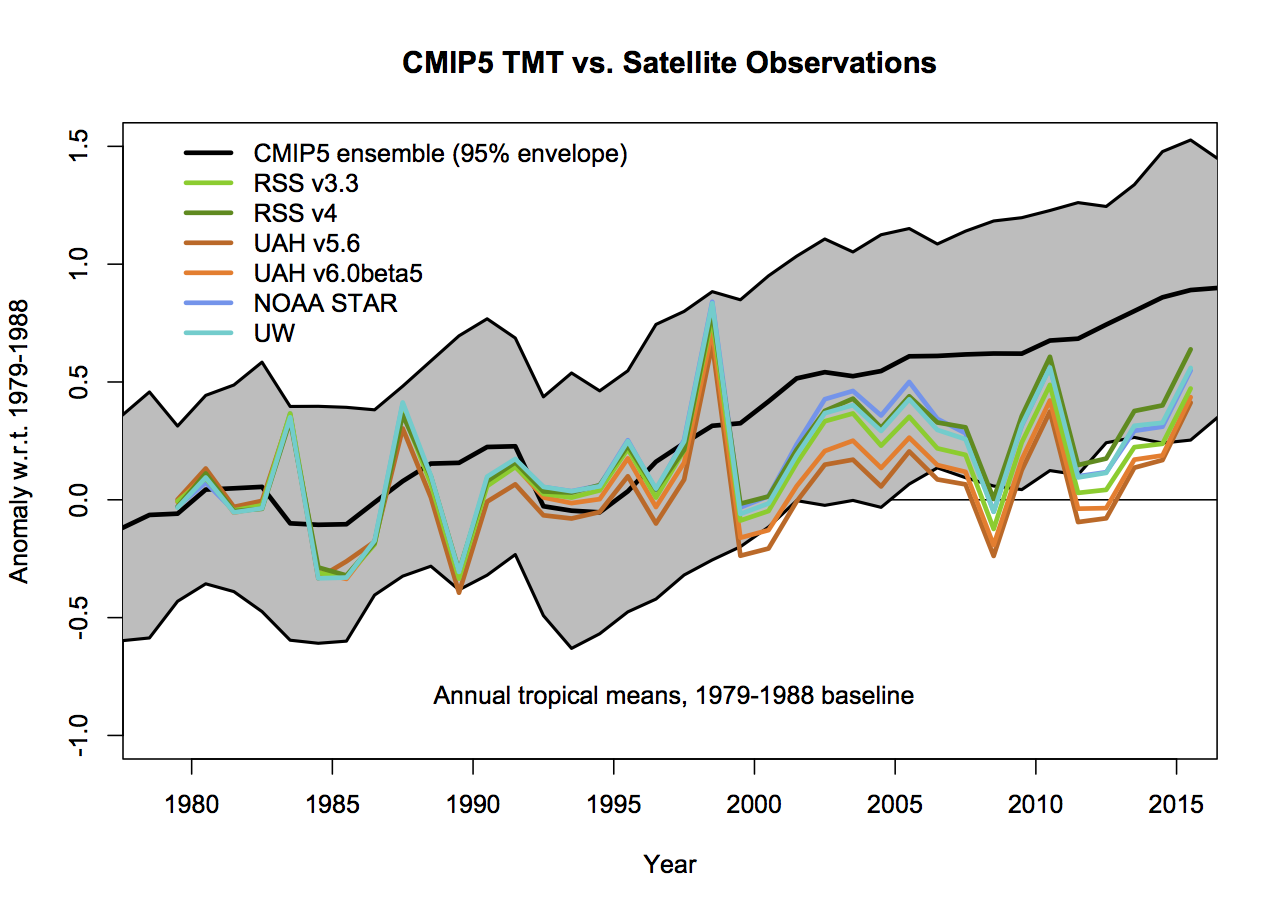
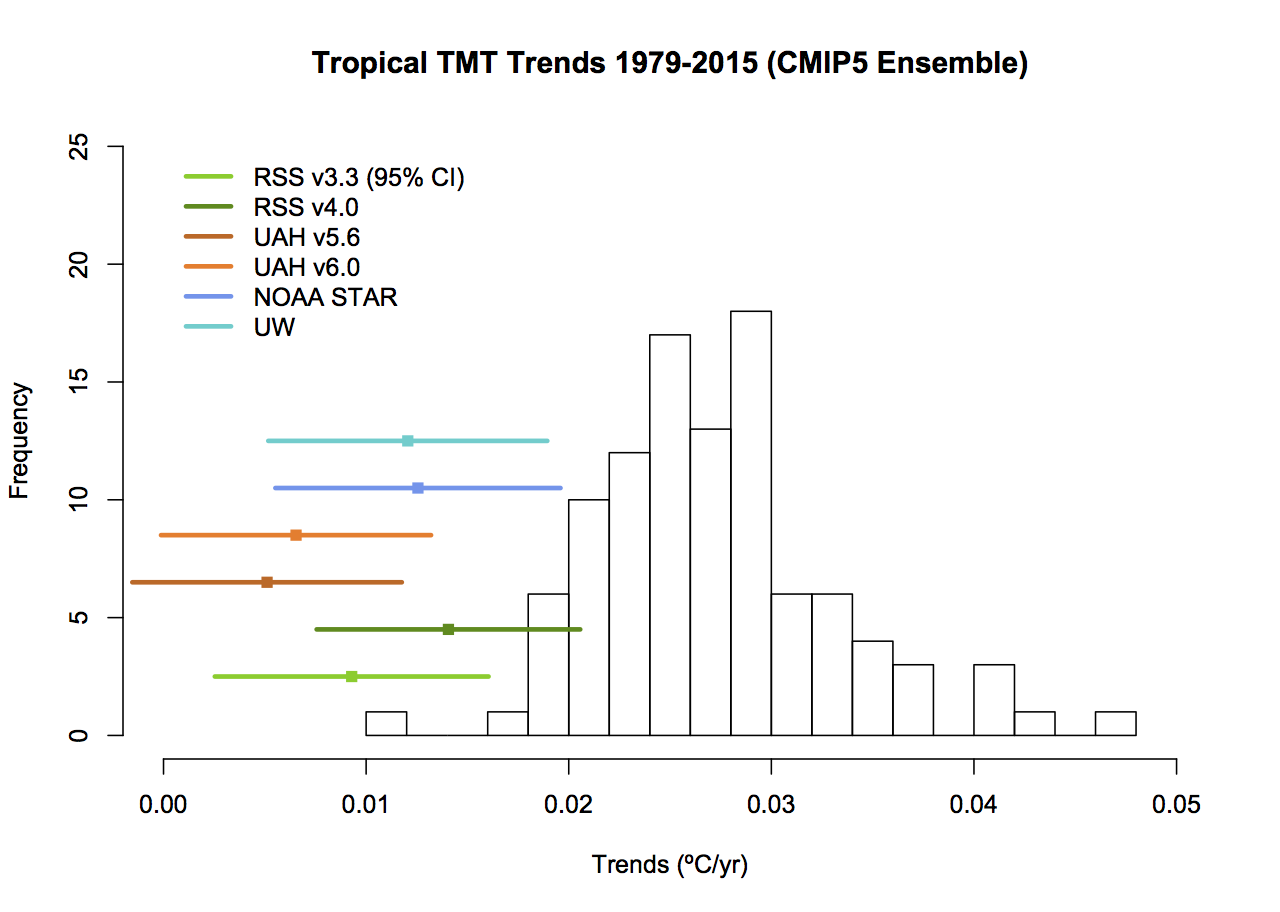
The trend histograms show far more information than Christy’s graphs, including the distribution across the ensemble and the standard OLS uncertainties on the linear trends in the observations. The difference between the global and tropical values are interesting too – there is a small shift to higher trends in the tropical values, but the uncertainty too is wider because of the greater relative importance of ENSO compared to the trend.
If the 5-year (padded) smoothing is really wanted, the first graphs would change as follows (note the trend plots don’t change):
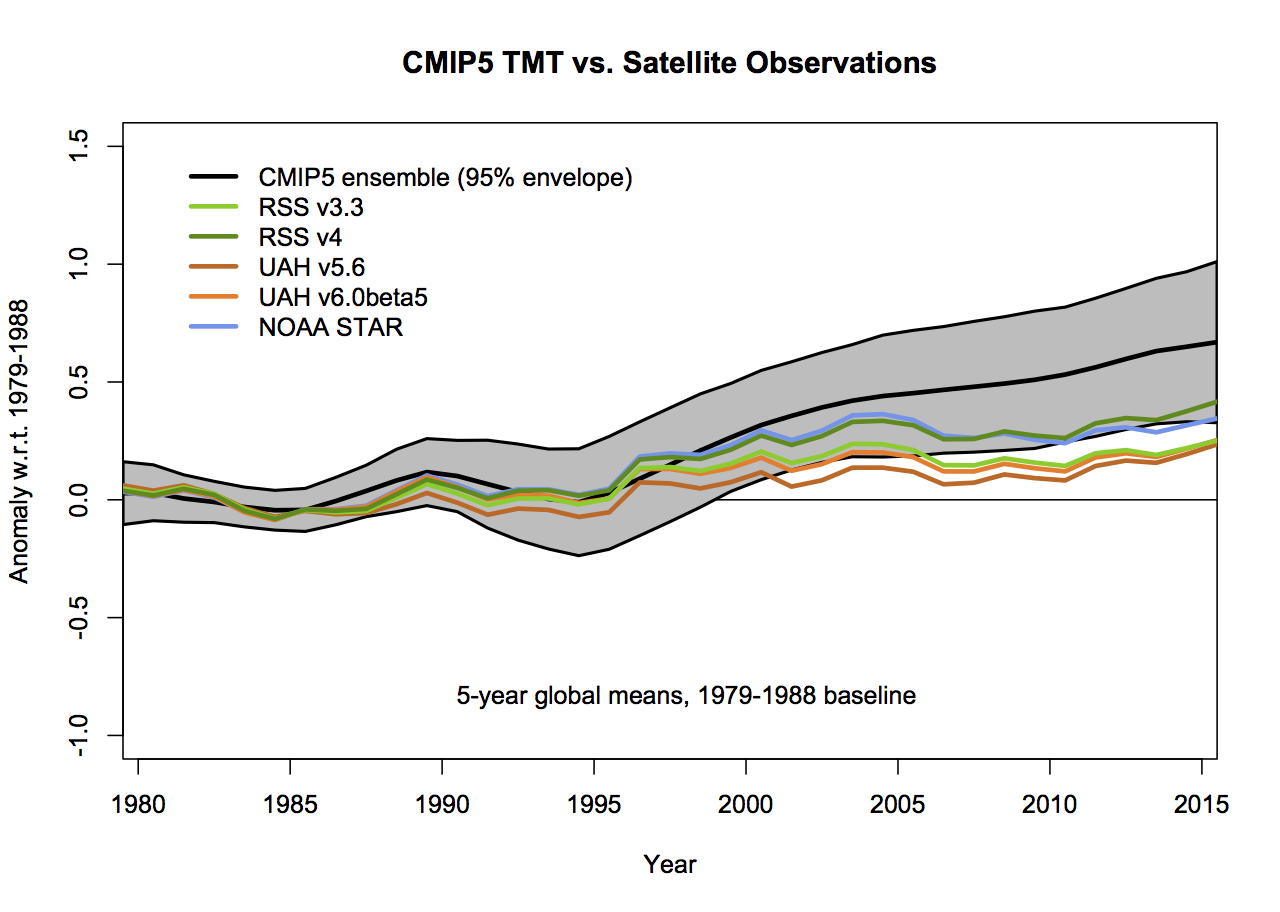
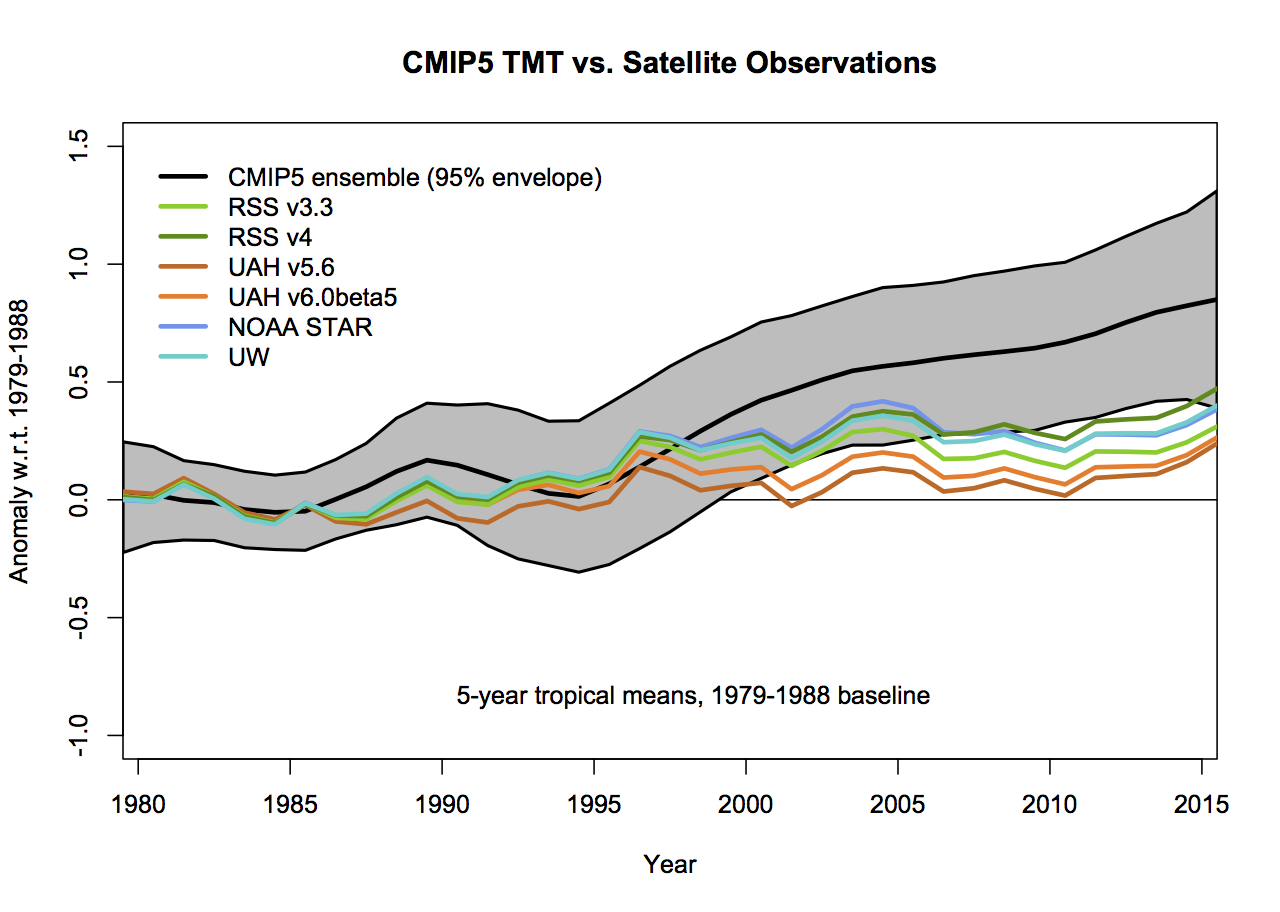
but the last two years will change as new data comes in.
So what?
Let’s remember the point here. We compare models and observations to learn something about the real world, not just to score points in some esoteric debate. So how does a better representation of the results help? Firstly, while the apparent differences are reduced in the updated presentation, they have not disappeared. But understanding how large the real differences actually are puts us in a better position to look for plausible reasons for them. Christy’s graphs are designed to lead you to a single conclusion (that the models are too sensitive to forcings), by eliminating consideration of the internal variability and structural uncertainty in the observations.
But Christy also ignores the importance of what forcings were used in the CMIP5 simulations. In work we did on the surface temperatures in CMIP5 and the real world, it became apparent that the forcings used in the models, particularly the solar and volcanic trends after 2000, imparted a warm bias in the models (up to 0.1ºC or so in the ensemble by 2012), which combined with the specific sequence of ENSO variability, explained most of the model-obs discrepancy in GMST. This result is not simply transferable to the TMT record (since the forcings and ENSO have different fingerprints in TMT than at the surface), but similar results will qualitatively hold. Alternative explanations – such as further structural uncertainty in the satellites, perhaps associated with the AMSU sensors after 2000, or some small overestimate of climate sensitivity in the model ensemble are plausible, but as yet there is no reason to support these ideas over the (known) issues with the forcings and ENSO. Some more work is needed here to calculate the TMT trends with updated forcings (soon!), and that will help further clarify things. With 2016 very likely to be the warmest year on record in the satellite observations the differences in trend will also diminish.
The bottom line is clear though – if you are interested in furthering understanding about what is happening in the climate system, you have to compare models and observations appropriately. However, if you are only interested in scoring points or political grandstanding then, of course, you can do what you like.
PS: I started drafting this post in December, but for multiple reasons didn’t finish it until now, updating it for 2015 data and referencing Christy’s Feb 16 testimony. I made some of these points on twitter, but some people seem to think that is equivalent to “mugging” someone. Might as well be hung for a blog post than a tweet though…
28, Icarus62: is that model outputs for global temperature are projections, not predictions.
When the projections turn out to be inaccurate, that is evidence that the models are wrong. No practical difference ensues from naming them “projections”, instead of “predictions”, “expectations”, simply “model outputs”, or any other name.
> No practical difference ensues from naming them “projections”, instead of “predictions”
In the same way there’s no practical difference between a shotgun and a rifle. Both go bang, both can miss, and if you don’t know the difference you’ll use the wrong tool for the job and get very disappointing results.
Especially if there are grues.
Model runs give a spread knowing each variable can affect others, so each run gives a different result, and the more money and time you have to do runs, the more different results you can project might occur depending on, well, everything. All models are wrong.
Marler, nice, you’re play acting as if you don’t know the difference. Projections are done instead of predictions because we do not know how much fossil fuel we will consume in the coming years. The physics is the same but a set of projections are made to account for the possibilities in FF consumption.
Maybe you should go back to your Judith Curry bunker where play acting is acceptable.
BTW, if you haven’t noticed, the Bakken shale output is undergoing a collapse because they are starting to severely deplete the cheap oil available. TANSTAAFL
Definitions:
projection: an estimate or forecast of a future situation or trend based on a study of present ones.”plans based on projections of slow but positive growth” synonyms: forecast, prediction, prognosis, outlook, expectation, estimate”a sales projection”
prediction: a thing predicted; a forecast.”a prediction that the Greeks would destroy the Persian empire” synonyms: forecast, prophecy, prognosis, prognostication, augury; More projection, conjecture, guess
“seven months later, his prediction came true” the action of predicting something. “the prediction of future behavior”
Very similar – but prediction feels like it has an author that is acting to endorse the outcome or projection. Projection seems less personal – more clinical, more easily tossed off after the fact as a simple mathematical run of a certain set of factors.
Jeane Dixon did predictions, not projections, right? Model outputs as a term also works as it seems quite clinical and does not seem to the authorial stamp of a specific scientist.
All models are wrong. My next tattoo. Less harsh than calling them shite.
Mike
53, webhubtel: Marler, nice, you’re play acting as if you don’t know the difference.
the only important difference is whether we are required to beliefe that the outcome might be true. For a “forecast”, we can ignore it; for a “prediction”, we are required to act as though it might be true. For modeling, if the forecast/prediction/outcome/result/expectation/etc is wrong, then it can be ignored until the model has been fixed sufficiently as to have a track record of accurate forecast/prediction/outcome/result/expectation/etc.
This repeated claim that the model results must be relied upon but that their errors can be ignored when the results are called “forecasts” instead of “predictions” is simply special pleading after the fact.
The models are “running hot”. Fix the models until they have a track record of accuracy sufficient to support that they might possibly still be accurate 4 decades hence. Then you can tell us what we have to do to achieve a good outcome 40 years hence.
How accurate? Here is a possibility: It has been shown that temps over the past few millenia are reasonably well fit by a low order harmonic regression; terms that have 11, 60, 950 year periodicities. Pure curvefitting. Extrapolate its results/forecasts/predictions/etc for the next few decades, and compute the integrated mean square error. When a GCM can beat it over a two decade period, then the GCM can be considered at least a start. Right now the GCMs’ are no more important than the various estimates of the mass of the “cold dark matter”, WIMPs, or whatever that stuff is. NOTE: beating a pure least squares fitted harmonic model is not an impossible standard — the predictions have already been made.
52, Hank Roberts: All models are wrong
But some are accurate enough to depend upon, such as the models embodied in the computer programs of the GPS system.
MM 55: It has been shown that temps over the past few millenia are reasonably well fit by a low order harmonic regression; terms that have 11, 60, 950 year periodicities. Pure curvefitting.
BPL: Who wants to bet he doesn’t see it?
Matthew, the models are not ‘running hot’ – that mistaken conclusion is the result of mistaking projections for predictions.
Model projections are based on multiple different forcing scenarios, and different patterns of natural variability (ENSO timing etc.) but the real world follows only one scenario – the one that actually happens. If you look at the particular subset of model runs in which climate forcings and natural variability happen to match the real world, the modeled temperature output is remarkably accurate. That’s why we can be confident that models are giving us useful projections of future warming for given forcing scenarios.
All you’re saying is that modeled temperature was higher than reality in those model runs where the forcing scenario was also higher than reality… which is, of course, how it should be.
> such as the models … GPS
Nonsense. There’s no model reliable enough to know where any orbiting satellite will be — beyond a few days or weeks.
Look up the ISS sightings page. It’s moving around a lumpy planet, and the expectation of seeing it overhead is impossible to model for more than a few days.
And that’s true for the GPS satellites as well, even though they don’t change position to dodge garbage or recover lost altitude
And you’re conflating several very different kinds of model, intentionally.
You know better.
Here’s a week’s worth of weather forecasts — a spaghetti chart.
http://forecast.io/lines/
Hank Roberts: And you’re conflating several very different kinds of model, intentionally.
You know better.
I am contrasting models that have demonstrated reliability or accuracy to other models where demonstrated reliability and accuracy are lacking.
And that’s true for the GPS satellites as well
You made that up. If it were true, no one could use cell phones for navigation.
57, BPL: BPL: Who wants to bet he doesn’t see it?
I look forward to the day when the GCMs make more accurate predictions (with respect to integrated mean square error over two decades) than Scafetta’s phenomenological modeling. How about you and the other RealClimate denizens? Is that an impossible or unrealistic standard?
58, Icarus62: Matthew, the models are not ‘running hot’ – that mistaken conclusion is the result of mistaking projections for predictions.
Review the histograms presented by Gavin Schmidt in the essay that heads this thread. The main question addressed by Dr Schmidt is which graphing style most accurately describes the disparity between models and data. That the disparity exists is not disputed. Some day, I am confident, the models will be accurate enough, because talented people are hard at work on them. Now the models are not accurate enough.
OK…probably a daft question. Looking at the plots of 95% model spread v observations it is clear that the handful of models at the base of the 95% envelope agree more readily with the observational record. Why then do we not, as a minimum, abandon all of those models that currently lie above the ensemble mean? This would bring the mean and 95% envelope of the remaining, and arguably more meaningful, models in-line with observations. We could keep doing this every 5 – 10 years (or whatever period is agreed and appropriate) – with those models varying significantly from observations continually being dropped in favour of those that track well with observations. To me this seems a simple and pragmatic way forward.
[Response: Not a totally daft question, but if you think about it you are just assuming that you know the reason for the discrepancy. If that’s wrong (and I think it is), then you are likely to greatly underestimate subsequent changes. I have nothing against model selection, but it has to be well justified otherwise you lose predictability. – gavin]
Speaking of models, I’d like to say that this presentation is, for me, a perfect model for how controversies of this kind should be treated. It’s serious, respectful, objective, free of special pleading and, above all, the focus is on the science, NOT the ideology. No trace of bitterness, no sarcasm, no ad hominems, no defensiveness, just a serious, authoritative analysis of the problem and some meaningful thoughts on how to deal with it.
I’m not qualified to pass judgement on the validity of Gavin’s analysis, but I do respect it as a serious attempt to clarify the issue and offer a reasonable solution to a challenging problem.
For me, the question of whether or not the models fit the evidence is less important than the question of whether a true correlation between CO2 emissions and global warming has been established. But that’s a whole other matter. Thanks, Gavin.
> You made that up.
No I did not.
I asked the Russian and NASA satellite tracking web pages — years ago, in fact probably the USSR’s satellite tracking service at the time — why they couldn’t tell me the viewing times for the ISS months in advance.
I was given consistent explanations from both sites: Earth is lumpy, and any satellite (even geosync) drifts a bit. Those satellites in tipped orbits (launched from sites not on the Equator) drift more, because every time they go ’round the planet, they experience slight differences in gravity along their track, because they’re over a different part of a variable planet.
So they tweak the tracking because otherwise little errors become huge after a few weeks.
I recommend you pick your favorite satellite tracking service and inquire about it for yourself.
Don’t trust me, I could be just making shit up to score points on a science blog, eh?
I’m not, though.
Septic Matthew says the models aren’t “accurate enough”. Accurate enough for what purpose? For determining whether I will ever need a jacket for 2040? Probably not. For concluding that average temperatures around the globe will be warmer in 2040 than they are now? Almost certainly, they are.
And of course, the question is what would replace the models for guiding us if we were to abandon them. That anthropogenic CO2 is warming the planet is almost certainly true. That this could pose a threat to many critical aspects of infrastructure of the global economy is undeniable. So we have a climate risk we cannot bound without the models, and yet the folks who want us to do nothing are telling us the models are worthless. The only alternative approach when the risk is so large is the precautionary principle–and I doubt they would advocate abandoning fossil fuels altogether and immediately.
So, Matthew et al., on what do you propose we base policy? And please don’t say the mathturbatory efforts of Nicola Scafetta. We’re trying to be serious here.
I leave you with a quote by Richard Hamming: “The purpose of computing is insight, not numbers.”
Of course, we all know that Matthew and his ilk do not value insight or understanding.
Matthew, #62–I think a better verbal summation of the histograms is that they show the observations ‘running cool’–ie., they reflect the so-called ‘hiatus’ period. With current temps comparable to the model mean, we can expect some shifting of the distributions as that reality is reflected in the more recent 5-year smooths.
“Now the models are not accurate enough.”
Matthew Marler @62, did you consider the possibility that the *observations* are not accurate enough (either)? Granted, those ‘observations’ are in reality the outcome of a rather complex model, too, so the argument gets a little bit circular, but still…
63, Gavin Schmidt, in line: I have nothing against model selection, but it has to be well justified otherwise you lose predictability. – gavin
Why not do what they do in crop breeding, or Mother Nature does in “natural” selection: select the 25% or 10% best fitting models, study what they have in common and what distinguishes them, improve them in multiple ways, run them again and again select the best fitting models (survival of the “fittest”, so to speak), and repeat? It’s a strategy that works well in a variety of settings: “simulated annealing” in model fitting, crop breeding, antibiotic resistance (where it “outsmarts”, so to speak, the people who design antibiotics.) I don’t mean to recommend this as a substitute for thoughtful hypothesis-directed, knowledge-directed, model-building, but as an adjunct.
67, Marco: did you consider the possibility that the *observations* are not accurate enough (either)?
That could be the case.
65, Hank Roberts: I recommend you pick your favorite satellite tracking service and inquire about it for yourself.
My claim is that the models employed in the GPS provide enough accuracy for navigation in most parts of the Earth. That is an example supporting Box’s aphorism: All models are false. Some are useful. Box himself did not say that utility comes from accuracy, that was my addition (though in fact I got it from reading Bertrand Russell, a quote that focused on the complementary concept of approximation: Though it may seem paradoxical to say so, all of exact science depends upon the notion of approximation.)
Is it your contention that the models used in the GPS system are not accurate enough to be useful?
MM, you have this imaginary perfect model in mind that doesn’t exist — one that can forecast exactly where each GPS satellite will be into the far future so your cellphone will work. In fact, the satellite trackers tweak the the orbital data constantly to stay current, because the world they’re orbiting varies as does space weather.
You do recall one of the accusations made over and over against climate modeling is that they “tweak” the models, right?
http://phys.org/news/2014-07-vindicates-climate-accused.html
Read more at: http://phys.org/news/2014-07-vindicates-climate-accused.html#jCp
So, when you hear someone complaining that climate scientists have to tweak their models with new information to make them come out more like reality — instead of launching them originally and having them run forever with the original inputs — remind them that
(a) they usually don’t, as they don’t have the computer time and money, they’re still working on getting the basic structure of the models to come out about right, and
(b) when they do, the models work better — just like the models in the GPS system.
Yep, each GPS satellite contains a model. Yep, those models get tweaked regularly, or we’d lose track of the satellites fairly quickly.
http://www.fleetistics.com/how-gps-satellites-work.php
e·phem·er·is
əˈfem(ə)rəs/
a table or data file giving the calculated positions of a celestial object at regular intervals throughout a period.
Hello? Can you hear me now?
Do you know where you are?
72 Hank Roberts: MM, you have this imaginary perfect model in mind that doesn’t exist — one that can forecast exactly where each GPS satellite will be into the far future so your cellphone will work
That isn’t what I wrote. The models in the GPS system are accurate enough to be useful. In fact, they have a multidecade record in that regard, having, among other things, guided the armored assault in Gulf War I. It is my hope and expectation that some day the climate models will have a multidecade record of useful accuracy.
Have you found your cell phone to be unreliable in guiding you around cities and countryside? There are anecdotes of people making terrible mistakes relying on such devices while in their autos, but in the aggregate millions of people have made even more millions of good decisions, and have arrived at their goals.
Is there something about the twin goals of “demonstrated record” and “sufficient accuracy”, what I have been writing about, that you object to? You are arguing against some kind of model perfection that isn’t what I have been writing about.
69 – “select the 25% or 10% best fitting models”
The purpose of a model is often no so much to produce an accurate prediction via a physically unreal model, but to produce a reasonable prediction with a physically real model to facilitate understanding the physics of the system being modeled.
Model tweaking is performed, but not by the means you suggest.
“Matthew, the models are not ‘running hot’”
A sample space has an average of “A”. The next 19 readings return an average slightly less than “A”.
Your conclusion – The average is running hot.
“Matthew, the models are not ‘running hot’”
The evolution of the climate system has a roughly 0.5’C chaotic component that is superimposed on a non-chaotic drift that is a function of various known physical variables.
As a result, if the real climate system is restarted at some time, with the “same” starting state as some previous state, with some trivial differences, the system will evolve differently over time.
On what basis do you conclude that the evolution of the climate state over the last 2 decades is representative of the average evolution of the system?
If you can’t say that the state evolution over the last 20 years is representative of a typical evolution over that period then you have no legitimate reason for expecting the models to predict the weather over the last 20 years. At least not within the known variances in the weather over such periods.
The models produce a statistical output.
No single experiment produces a statistical result.
You have been comparing different things, and confusing yourself in the process.
Gavin, thanks for the response. I agree that justification would need to be provided if we were to ‘cull’ models. However, with there being slightly over 100 models the question has to be asked ‘Do we need all of them?’ I suppose the answer depends on what purpose each of the models fulfils. If they are simply to explore a range of future possibilities using a selection of parameters that may, or may not, have any basis in reality – then so be it, they can continue to be scientists play things and the divergence from the observational record can continue to be of no importance, as long as we all know that is the case. If they are to be used for policy development by our Political masters then that is an entirely different matter.
I had assumed that the institutions running the various models were not doing so in isolation i.e. there is some collaboration or sharing of information being undertaken. But if so then how to explain the model spread? If collaboration is not happening then I agree with Matthew that there is a need for all parties to review what distinguishes their model and what they have in common with others..but then again it depends on what function institutions believe their model has.
Presumably each model output is as a result of inclusion or omission (deliberate or otherwise) of some parameter or combination of parameters. If so then looking at the outliers (those at the top end of the 95% envelope) would suggest that the only learning to be gained from these is how not to select appropriate model parameters – these I would put in the ‘play things’ category. They have their place. We know they don’t reflect reality and there was probably never an expectation that they would or should do so. As we move towards the middle of the envelope the motive for any particular model becomes less clear – is it still a ‘play thing’ or is the intention to make it more functional and of value in policy development? This is not to say that those models that track the observational record are any better – they may match observation purely by accident or through omission of a parameter.
So yes I agree a justification should be provided if we are to discontinue any particular model. However it is equally important that a robust justification be provided for continuing to run a model. Running models does not come cheap – would the money currently being spent on 100+ models be better spent on 80, or 50 or 35? Think what resources, computer time etc. all that additional funding could bring to those few institutions that are left running models.
Ray @ 66
You mention ‘advocating for abandoning fossil fuels altogether and immediately’ – I doubt anyone with a rational mind would abandon fossil fuels ‘immediately’ i.e. now, this second – it simply couldn’t be done. Perhaps you don’t mean what you say? Could you perhaps mean ‘ at the earliest opportunity’?
73, Hank Roberts: Hello? Can you hear me now?
You wrote that all models are wrong, and I wrote that some models are accurate enough to be useful, with the models of the GPS system as one example of models that are accurate enough to be useful. I am hopeful that in the future there will be climate models with a demonstrated record of being accurate enough, over about 2 decades, to be useful.
Surely you are not trying to prove that the models of the GPS are not accurate enough to be useful; or that climate models, such as GCMs, can never be demonstrated to be accurate enough to be useful?
Matthew, #62:
“Why not do what they do in crop breeding…”
Per AR5, one reason is that it’s not easy deciding what metrics are the most useful in assessing how a given model is doing.
That may seem a bit odd in the context of the current discussion, where we’ve been focussed on just one parameter (surface temperature.) But in practice, it’s temps, not just at the surface, but through the depth of the atmosphere (“Tropical Tropospheric Trends”, anyone?) And it’s water vapor. And it’s circulation patterns. And it’s higher-order patterns of response, like monsoons, or ENSO. And there’s spatial and time scales, which connects with computational and budgetary realities as well. And so on, and so on.
All are important, and I gather that, unfortunately, the model that seems best to capture, say, the Indian monsoon, won’t necessarily also be the model that best projects global temperature trends over decadal time spans.
That’s not to say that progress in model selection isn’t possible; to return to your analogy, we do have animals bred to do different sorts of things (say, draft horses versus thoroughbred racers). In theory, one should be able to identify and develop differential strengths of models, too, and I think that may be being done. (Perhaps someone more informed will weigh in on this.) I don’t think the modeling community is going to be throwing their hands in the air and giving up any time soon.
But it is worth noting that the challenge of model assessment is, as they say, ‘non-trivial.’
81, Kevin McKinney: I don’t think the modeling community is going to be throwing their hands in the air and giving up any time soon.
I am optimistic that the modeling community will eventually produce models that are physically realistic and accurate enough for multidecadal prediction.
Per AR5, one reason is that it’s not easy deciding what metrics are the most useful in assessing how a given model is doing.
It’s not possible to turn back the clock, but I wish that about 30 years ago Hansen, Holdren, Schneider et al had told us how accurate they expected their forecasts to be by 2015, so we could judge them successful or not. Right now it looks to me like the reality is diverging from the model results so rapidly (ref. Dr Schmidt’s histogram) that the models clearly have no utility for planning decades into the future. But it isn’t too late to consider what metrics would show utility if met by 2045, or any two-three decades post prediction.
MM 82: I am optimistic that the modeling community will eventually produce models that are physically realistic and accurate enough for multidecadal prediction.
BPL: Oh my God, you just don’t get it, do you? Still talking about “prediction.”
A climate model is not a crystal ball and is not meant to be. It does PROJECTIONS (what happens IF the inputs are thus and such), not PREDICTIONS (history of the future). How many times do we have to make this point? Are you just trolling?
See, that was what I was trying to tell you above at #67. The histograms say nothing about ‘divergence’ or for that matter the converse, since the trend is effectively stripped out. They simply show that for a significant period of the record, the observations were cooler than the models. From the point of view of the present context, it’s just as likely that that is purely natural variability–particularly since current temps are pretty consistent with projections.
However, from a wider point of view, it’s much *more* likely than that. (I think Bayesian stats would be able to quantify that, but I’ll leave that to those who really know something about that topic.) For three quick instances, we know that ocean heat content continued to increase during the so-called ‘pause’ period; we know that radiative imbalance continued to increase; and we know that ENSO variability can explain much of the slowdown in surface and troposphere warming. There’s more, of course, but hopefully you get the idea: other knowledge supports the view that the discrepancy is basically stochastic, not systemic.
Model improvement will certainly continue. Even if it didn’t, though, regression to trend would very likely result in *convergence* between models and obs over the next few years.
Matthew Marler says: 15 May 2016 at 10:53 AM
…
Surely you are not trying to prove …
You missed the part about the necessity of updating models.
Can you imagine a sufficiently complicated clockwork orrery model of the solar system?
Imagine you have a dozen identical Earths — the real planet, not a model — and you start their climates running identically — do you imagine they would each behave exactly the same way?
Models are good for certain features over some time span, and running the model repeately gives a “spaghetti graph” of outcomes — not the same outcome each time.
http://phys.org/news/2015-04-ocean-bacteria-team-factors-impacting.html
84, Kevin McKinney:The histograms say nothing about ‘divergence’ or for that matter the converse, since the trend is effectively stripped out.
The histograms are of trends, and clearly labeled so.
85, Hank Roberts: You missed the part about the necessity of updating models.
No, I wrote that models can be accurate enough to be useful. You wrote that all models are wrong, and I countered that models can be accurate enough to be useful, and I gave the GPS models as examples. The famous “Digital Orrery” was subject to much testing and shown to provide accurate approximations to recorded data before its extrapolations into the future were calculated and reported.
83, Barton Paul Levenson: It does PROJECTIONS (what happens IF the inputs are thus and such), not PREDICTIONS (history of the future).
Whatever you call the model outputs, if the out-of-sample data differ reliably, the model can not be relied upon for policy and planning. Richard Feynman called the model in such a case “wrong”. Granting Hank Roberts’ claim (and others, not disputed by me) that all models are wrong, a record of accuracy is required for the models to be considered useful.
A reminder: the head article was about the most informative graphics for displaying the disparity between climate change and model output. I look forward to the day when such displays, and others, show close correspondence between model output and climate change over some decades. The models might still be “wrong”, or wrong, but at least then they will be reliable.
Tamino has a new post on this, further to this. It compares GISTEMP to 93 CMIP5 runs, and finds very good agreement.
https://tamino.wordpress.com/2016/05/17/models/
BPL, 83: Thank you very much.
Matthew Marler, 80 etc. — The GCMs are useful right now. That’s the whole point, if you get how and why. That’s what’s being shared here.
Otherwise, there’s always Tamino and/or his courses:
https://tamino.wordpress.com/2016/05/17/models/
https://tamino.wordpress.com/2016/05/11/time-series-is-coming-watch-this-space/#more-8529
Wait, this Matthew Marler?
If the Matthew Marler who publishes papers in the field of statistical analysis is this one here, then I’d guess he is here just trolling for bites from suckers, because the arguments he makes don’t seem to make sense.
The argument this MM seems to make is that stirring up the climate system will have predictable consequences at the local level that can be modeled eventually so local policy choices can be made to pick outcomes by preference.
Which results to pay for in advance?
Which to buy off to avoid?
Which to leave to the grandchildren rather than begin to pay any price or bear any burden that would restrain our current lifestyle choices.
Climate ain’t a simple system expected to have simple outcomes when fossil carbon is burned at rates with no precedent.
Sleeping beast. Stick. Poke. Prediction?
All global models are using the wrong dynamics.
https://drive.google.com/file/d/0B-WyFx7Wk5zLR0RHSG5velgtVkk/view?usp=sharing
Jerry
I bet my comment disappears because it mathematically shows that global models are using the wrong dynamics.
is it possible to agree that:
1. all the models are wrong (gavin’s statement)
2. many, perhaps most (maybe all?) of the models are unreliable
3. some of the models are useful for at least some applications and public policy planning, even after accepting that 1 and 2 are true or factual
My sense is that 1 and 2 could be combined giving this agreement:
1. all of the models are wrong and unreliable
2. some of the models are still useful in some limited ways
I think the climate system is so complex, and the impact that we are having on it with an amazing overload of CO2 into the atmosphere means that we are unlikely to devise and run any model that will produce an output that will match closely to the observational changes that we will see.
That is not to say that modelling should stop because some of the models are still useful in some limited ways even when they produce outputs that are so divergent to be useless in the largest consideration: how much CO2 can we load in to the atmosphere without producing a global calamity like the sixth great extinction.
This is the point where someone entranced by technology usually says, “we need better computers.” Kinda like smart bombs. We need smarter smart-bombs and better better-computers.
I think we are closing in on a blue ocean event, did any of the models produce such an output? Is a blue ocean event this year or this decade a “bad possibility” that we might have avoided in some way?
I think the planning needs to be geared around avoiding the bad possibilities now. It may, of course, be a little late for that, but who knows?
Your results may vary as they say.
Cheers
Mike
92, Hank Roberts: The argument this MM seems to make is that stirring up the climate system will have predictable consequences at the local level that can be modeled eventually so local policy choices can be made to pick outcomes by preference.
It’s no wonder you think I am not making any sense. That isn’t what I wrote.
90 Patrick: Matthew Marler, 80 etc. — The GCMs are useful right now
I think I am in between you and Hank Roberts, believing (or at least not ruling out) that the GCMs will eventually be developed to where they can demonstrate a multidecade record of accuracy.
Matthew Marler, #87–
“The histograms are of trends, and clearly labeled so.”
Yes, my thought was poorly expessed. Let me clarify.
The histograms express linear trends over a certain span. We already know that for a large fraction of that time, warming proceeded at a slower tempo than models predicted. (Ie., the so-called ‘pause.’) That slowdown is what shows up as a discrepancy in observed versus modeled trends in the histograms.
However, the actual trajectory of warming is manifestly not linear over decadal timespans. If the ‘pause’ was due largely to natural variability, then we may very well see a period of ‘accelerated’ warming once again, as for instance in the ‘post-Pinatubo’ period leading up to 1998. (Indeed, if 2016 continues as it has begun, that is just what 2013-2016 will look like.)
Should that continue for a bit, what you’ll see is a rightward creep for the observed trends in those histograms. And as I indicated in my previous comment, there is some physical reason to expect just that.
In this respect, Tamino’s comparison of modeled and observed surface temperature is suggestive–the longer record is less dominated by “pause” and “speedup” episodes, and for that matter, the surface record is a bit less variable anyway. I commend to your attention Tamino’s trend histograms.
Gerald Browning@94
Wrong. It will merely lie there undisturbed because, like all dog turds, no one wants to pick it up.
GB, I’ll bet YOU disappear because you’re using the wrong dynamics.
Gerald Browning:
Nope, your comment’s still here. And not just because it doesn’t show that global models are using the wrong dynamics. If it did, you can be sure we’d discuss it on RC.