Last Friday, NASA GISS and NOAA NCDC had a press conference and jointly announced the end-of-year analysis for the 2014 global surface temperature anomaly which, in both analyses, came out top. As you may have noticed, this got much more press attention than their joint announcement in 2013 (which wasn’t a record year).
In press briefings and interviews I contributed to, I mostly focused on two issues – that 2014 was indeed the warmest year in those records (though by a small amount), and the continuing long-term trends in temperature which, since they are predominantly driven by increases in greenhouse gases, are going to continue and hence produce (on a fairly regular basis) continuing record years. Response to these points has been mainly straightforward, which is good (if sometimes a little surprising), but there have been some interesting issues raised as well…
Records are bigger stories than trends
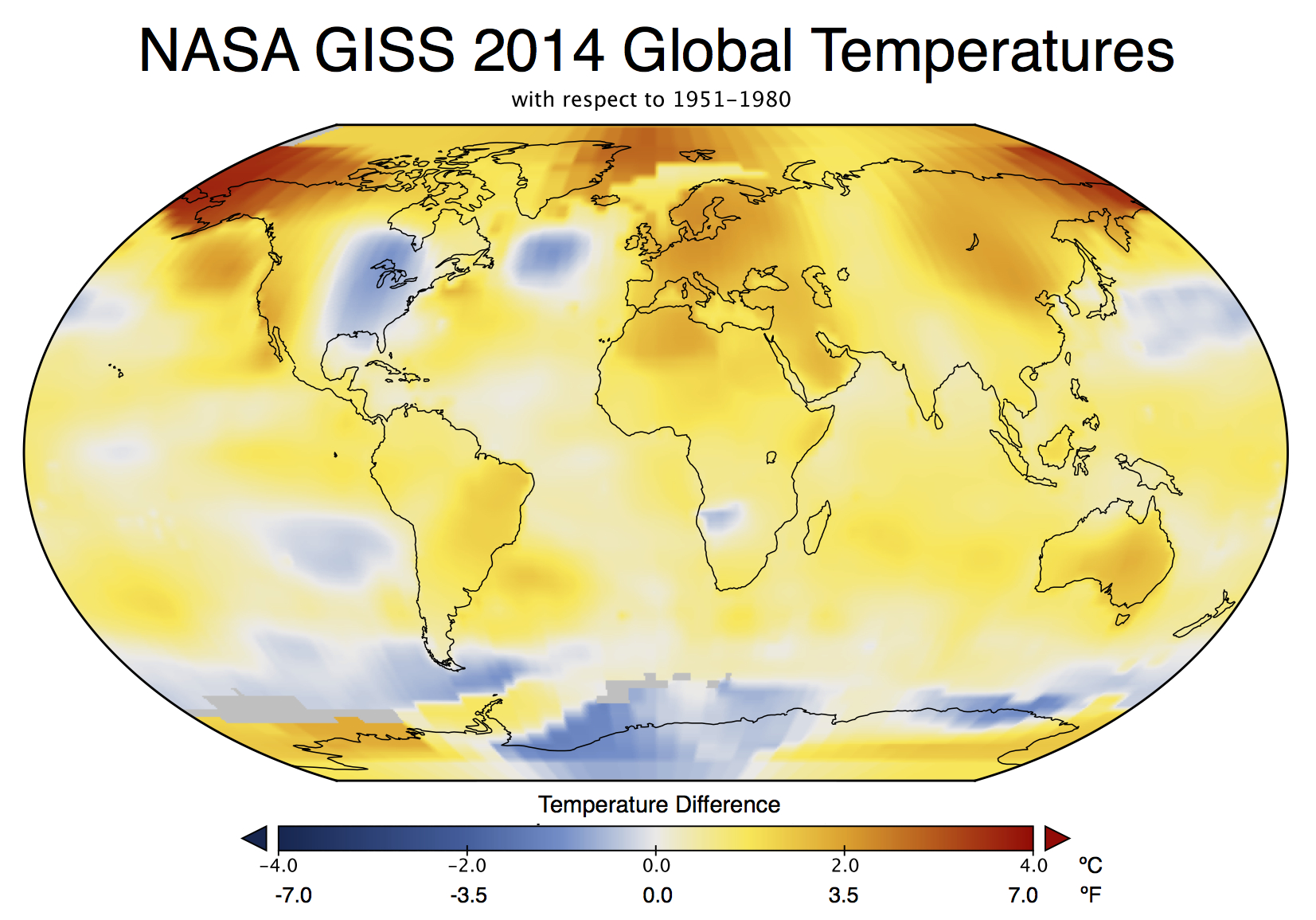
This was a huge media story (even my parents noticed!). This is despite (or perhaps because?) the headline statement had been heavily trailed since at least September and cannot have been much of a surprise. In November, WMO put out a preliminary analysis suggesting that 2014 would be a record year. Earlier this month, the Japanese Meteorological Agency (JMA) produced their analysis, also showing a record. Estimates based on independent emulations of the GISTEMP analysis also predicted that the record would be broken (Moyhu, ClearClimateCode).
This is also despite the fact that differences of a few hundredths of a degree are simply not that important to any key questions or issues that might be of some policy relevance. A record year doesn’t appreciably affect attribution of past trends, nor the projection of future ones. It doesn’t re-calibrate estimated impacts or affect assessments of regional vulnerabilities. Records are obviously more expected in the presence of an underlying trend, but whether they occur in 2005, 2010 and 2014, as opposed to 2003, 2007 and 2015 is pretty much irrelevant.
But collectively we do seem to have an apparent fondness for arbitrary thresholds (like New Years Eve, 10 year anniversaries, commemorative holidays etc.) before we take stock of something. It isn’t a particularly rational thing – (what was the real importance of Usain Bolt’s breaking the record for the 100m by 0.02 hundredths of a second in 2008?), but people seem to be naturally more interested in the record holder than in the also-rans. Given then that 2014 was a record year, interest was inevitably going to be high. Along those lines, Andy Revkin has written about records as ‘front page thoughts’ that is also worth reading.
El Niños, La Niñas, Pauses and Hiatuses
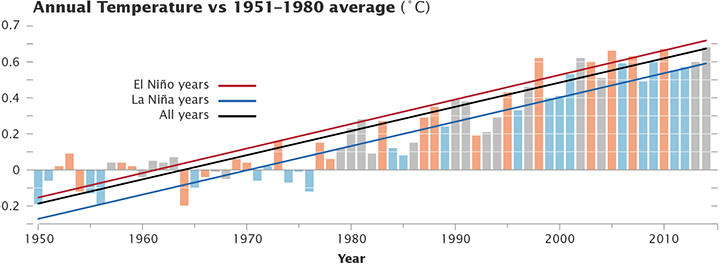
There is a strong correlation between annual mean temperatures (in the satellite tropospheric records and surface analyses) and the state of ENSO at the end of the previous year. Maximum correlations of the short-term interannual fluctuations are usually with prior year SON, OND or NDJ ENSO indices. For instance, 1998, 2005, and 2010 were all preceded by an declared El Niño event at the end of the previous year. The El Niño of 1997/8 was exceptionally strong and this undoubtedly influenced the stand-out temperatures in 1998. 2014 was unusual in that there was no event at the beginning of the year (though neither did the then-record years of 1997, 1990, 1981 or 1980 either).
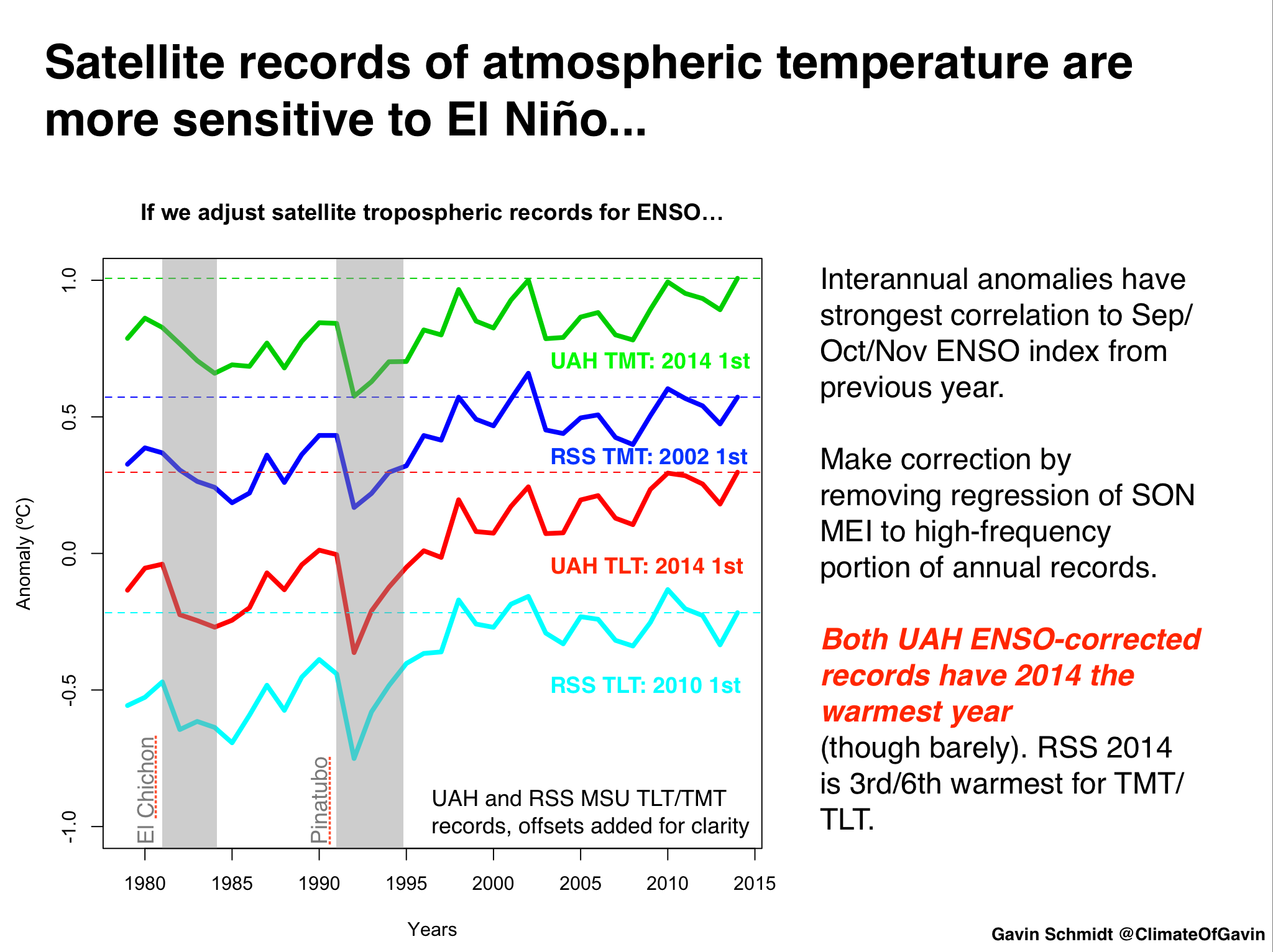
So what would the trends look like if you adjust for the ENSO phase? Are separate datasets differently sensitive to ENSO? Given the importance of the ENSO phasing for the ‘pause’ (see Schmidt et al (2014), this can help assess the underlying long-term trend and whether there is any evidence that it has changed in the recent decade or so.
For instance, the regression of the short-term variations in annual MSU TLT data to ENSO is 2.5 times larger than it is to GISTEMP. Since ENSO is the dominant mode of interannual variability, this variance relative to the expected trend due to long-term rises in greenhouse gases implies a lower signal to noise ratio in the satellite data. Interestingly, if you make a correction for ENSO phase, the UAH record would also have had 2014 as a record year (though barely). The impact on the RSS data is less. For GISTEMP, removing the impact of ENSO makes 2014 an even stronger record year relative to previous ones (0.07ºC above 2005, 2006 and 2013), supporting the notion that the underlying long-term trend has not changed appreciably over the last decade or so. (Tamino has a good post on this as well).
Odds and statistics, and odd statistics
Analyses of global temperatures are of course based on a statistical model that ingests imperfect data and has uncertainties due to spatial sampling, inhomogeneities of records (for multiple reasons), errors in transcription etc. Monthly and annual values are therefore subject to some (non-trivial) uncertainty. The HadCRUT4 dataset has, I think, the best treatment of the uncertainties (creating multiple estimates based on a Monte Carlo treatment of input data uncertainties and methodological choices). The Berkeley Earth project also estimates a structural uncertainty based on non-overlapping subsets of raw data. These both suggest that current uncertainties on the annual mean data point are around ±0.05ºC (1 sigma) [Update: the Berkeley Earth estimate is actually half that]. Using those estimates, and assuming that the uncertainties are uncorrelated for year to year (not strictly valid for spatial undersampling, but this gives a conservative estimate), one can estimate the odds of 2014 being a record year, or of beating 2010 – the previous record. This was done by both NOAA and NASA and presented at the press briefing (see slide 5).

In both analyses, the values for 2014 are the warmest, but are statistically close to that of 2010 and 2005. In NOAA analysis, 2014 is a record by about 0.04ºC, while the difference in the GISTEMP record was 0.02ºC. Given the uncertainties, we can estimated the likelihood that this means 2014 was in fact the planet’s warmest year since 1880. Intuitively, the highest ranked year will be the most likely individual year to be the record (in horse racing terms, that would be the favorite) and indeed, we estimated that 2014 is about 1.5 to ~3 times more likely than 2010 to have been the record. In absolute probability terms, NOAA calculated that 2014 was ~48% likely to be the record versus all other years, while for GISTEMP (because of the smaller margin), there is a higher change of uncertainties changing the ranking (~38%). (Contrary to some press reports, this was indeed fully discussed during the briefing). The data released by Berkeley Earth is similar (with 2014 at ~35%~46% (see comment below)). These numbers are also fragile though and may change with upcoming updates to data sources (including better corrections for non-climatic influences in the ocean temperatures). An alternative formulation is to describe these results as being ‘statistical ties’, but to me that implies that each of the top years is equally likely to be the record, and I don’t think that is an accurate summary of the calculation.
Another set of statistical questions relate to a counterfactual – what are the odds of such a record or series of hot years in the absence of human influences on climate? This question demands a statistical model of the climate system which, of course, has to have multiple sets of assumptions built in. Some of the confusion about these odds as they were reported are related to exactly what those assumptions are.
For instance, the very simplest statistical model might assume that the current natural state of climate would be roughly stable at mid-century values and that annual variations are Gaussian, and uncorrelated from one year to another. Since interannual variations are around 0.07ºC (1 sigma), an anomaly of 0.68ºC is exceptionally unlikely (over 9 sigma, or a probability of ~2×10-19). This is mind-bogglingly unlikely, and is a function of the overly-simple model rather than a statement about the impact of human activity.
Two similar statistical analyses were published last week: AP reported that the odds of nine of the 10 hottest years occurring since 2000 were about 650 million to 1, while Climate Central suggested that a similar calculation (13 of the last 15 years) gave odds of 27 million to 1. These calculations are made assuming that each year’s temperature is an independent draw from a stable distribution, and so their extreme unlikelihood is more of a statement about the model used, rather than the natural vs. anthropogenic question. To see that, think about a situation where there was a trend due to natural factors, this would greater reduce the odds of a hot streak towards the end (as a function of the size of the trend relative to the interannual variability) without it having anything to do with human impacts. Similar effects would be seen if interannual internal variability was strongly autocorrelated (i.e. if excursions in neighbouring years were related). Whether this is the case in the real world is an active research question (though climate models suggest it is not a large effect).
Better statistical models thus might take into account the correlation of interannual variations, or have explicit account of natural drivers (the sun and volcanoes), but will quickly run into difficulties in defining these additional aspects from the single real world data set we have (which includes human impacts).
A more coherent calculation would be to look at the difference between climate model simulations with and without anthropogenic forcing. The difference seen in IPCC AR5 Fig 10.1 between those cases in the 21st Century is about 0.8ºC, with an SD of ~0.15 C for interannual variability in the simulations. If we accept that as a null hypothesis, the odds of seeing a 0.8ºC difference in the absence of human effects is over 5 sigma, with odds (at minimum) of 1 in 1.7 million.
{kind=link}
None of these estimates however take into account how likely any of these models are to capture the true behaviour of the system, and that should really be a part of any assessment. The values from a model with unrealistic assumptions is highly unlikely to be a good match to reality and it’s results should be downweighted, while ones that are better should count for more. This is of course subjective – I might feel that coupled GCMs are adequate for this purpose, but it would be easy to find someone who disagreed or who thought that internal decadal variations were being underestimated. An increase of decadal variance, would increase the sigma for the models by a little, reducing the unlikelihood of observed anomaly. Of course, this would need to be justified by some analysis, which itself would be subject to some structural uncertainty… and so on. It is therefore an almost impossible to do a fully objective calculation of these odds. The most one can do is make clear the assumptions being made and allow others to assess whether that makes sense to them.
Of course, whether the odds are 1.7, 27 or 650 million to 1 or less, that is still pretty unlikely, and it’s hard to see any reasonable model giving you a value that would put the basic conclusion in doubt. This is also seen in a related calculation (again using the GCMs) for the attribution of recent warming.
Conclusion
The excitement (and backlash) over these annual numbers provides a window into some of problems in the public discourse on climate. A lot of energy and attention is focused on issues with little relevance to actual decision-making and with no particular implications for deeper understanding of the climate system. In my opinion, the long-term trends or the expected sequence of records are far more important than whether any single year is a record or not. Nonetheless, the records were topped this year, and the interest this generated is something worth writing about.
References
- G.A. Schmidt, D.T. Shindell, and K. Tsigaridis, "Reconciling warming trends", Nature Geoscience, vol. 7, pp. 158-160, 2014. http://dx.doi.org/10.1038/ngeo2105
Nice piece. On the issue of probabilities of a streak of warm months / years this isn’t the first time that the null of non-correlated data has been abused in such a manner.
We wrote a paper on that (behind a paywall, sorry) at http://onlinelibrary.wiley.com/enhanced/doi/10.1002/2013JD021446/ around the observation of a streak of 13 consecutive upper-tercile anomaly months over the CONUS. Getting the correlation structure (persistence) accounted for correctly fundamentally reduces the probabilities. The principles therein could be applied here and the code is available in the SI (which I don’t believe is paywalled).
These were some of the pre-eminent environmental timeseries statisticians … and then one dumbo (me …).
Please see also the news item published on ECMWF’s website: http://www.ecmwf.int/en/about/media-centre/news/2015/ecmwf-releases-global-reanalysis-data-2014-0
Excellent article, Gavin, the statistic has produced a song-and-dance from those who should know better and, really, the main conclusion from the records is that 2014 was yet another year that was much warmer than 1850.
The ins and outs are nice to discuss in this forum. The general public would be well served if reminded clearly and often that for a long time now each decade is warmer than the last. We now have half of 2010-2019, and certainly no contradiction to that easily absorbed message.
(I used to offer upper-middle-class-salary-sized bets on comparing decades, with the maximum bet being on decades 30 years apart, to obnoxious participants in blog comments, but I gave up, because they all demurred.)
Thanks Gavin. That’s a nice summary. I’d seen Tamino’s post and was hoping you would do one as well.
From the post, HadCRUT4 & BEST uncertainty are described ” These both suggest that current uncertainties on the annual mean data point are around ±0.05ºC (1 sigma).”
While this is right for HadCRUT4, it is not what BEST is saying. BEST says the ±0.05ºC value is for 2 sigma. “The margin of uncertainty we achieved was remarkably small (0.05 C with 95% confidence).”
If it had been 1 sigma, BEST presumably would then have been taking about nine years being equal-warmest instead of just three – in order 2014, 2010, 2005, 2007, 2006, 2013, 2009, 2002, 1998.
[Response: Thanks for spotting that! Taking the Berkeley errors as 2 sigma, makes their P(2014 record) = ~46%, and P(2010 record) = ~26%. Very similar to NOAA. – gavin]
Good post.
Thanks for another thoughtful post. As Tamino put it, ‘It’s the trend, stupid!’
https://tamino.wordpress.com/2015/01/20/its-the-trend-stupid-3/
In the OP: “Response to these points has been mainly straightforward, which is good (if sometimes a little surprising),”
Lolz, that WSJ news item is by Robert Lee Hotz!
Gavin,
Naysayers made a lot of your 38% figure, and I think this was possible because the basis for it wasn’t explained. I’ve tried to express my own understanding of it here. Basically, as I understand from Hansen et al 2010, it is spatial sampling error. The variation you would get if you sampled in different places. It may include the variation you might get with different weightings.
It’s not clear how you then went to the odds of 2014>2010. Because 2010 basically wasn’t sampled in different places. So it seems there is a major component of variation missing. How is that handled?
[Response: Nothing sophisticated. These estimates are based on a 1 sigma of 0.05ºC, increasing backwards in time, and assuming independence for any one year which seems reasonable. If you have something better and tractable, let me know. – gavin]
Thanks so much Gavin. It’s a pleasure to learn what a real scientist has to say on that “record breaking” year, as opposed to what I’ve been seeing in so many media accounts. I very much appreciate your willingness to take a balanced approach on this very contentious issue.
My only problem is that you’re too easy on the media. As I see it there is something profoundly dishonest in these many attempts to hype the “climate change” meme in any and every way one could possibly think of, from Polar Bear issues to the future prospects of the wine industry, plus just about anything else that could possibly be be relevant in any way. If I weren’t already a skeptic, such patently misleading and dishonest “reports” would tend to make me one. And as I’m sure you realize, such reporting only weakens the cause of those who, like yourself, see climate change as a genuine threat.
[Response: There are many issues with the media, but your characterisation of them as dishonest in general is not valid. Climate change will in fact affect a huge number of things that we think about as important. It won’t be the only effect, and many times won’t even be the dominant human effect, but what you are seeing is a large-scale, inefficient and sometimes confused public ‘coming to terms’ with the path we are embarked on. Your response to this is scorn, but I might suggest that a more constructive response is to acknowledge that complexity is not easy to write about and that the role of journalism to report news is a very different role than that of providing an education. Kneejerk dismissal of climate impacts on wine growing (real) and polar ecosystems (including bears) (also real), doesn’t do you any credit. – gavin]
Can anyone explain this 38% confidence thing in layman’s terms. I’m just a normal citizen who’s very interested in Climate change but I’m not a scientist or statistician.
Is it analogous to an election in which you have 135 candidates and one candidate get’s 38% of the vote?
[Response: That’s pretty good. – gavin]
Gavin,
“assuming independence for any one year which seems reasonable. If you have something better and tractable, let me know”
I don’t have anything more tractable. But independence seems clearly wrong. On a spatial sampling basis, they aren’t independent at all. They are sampled in the same places. It seems you should be way more than 38% confident. It may be hard to calculate, but there is no point including a badly wrong assumption.
[Response: I wouldn’t go that far. The HadCRUT4 estimate of sigma is more comprehensive and has similar magnitude and so to get a relatively conservative estimate of probabilities it is probably ok. As I said, I am open to exploring more sophisticated uncertainty models. – gavin]
> Records are bigger stories than trends.
Lesson learned and logged. So how about emphasizing record-warm decades, and the like? Isn’t it a happy medium, for communication? The 2013 WMO publication, “A Decade of Climate Extremes” was carried from Accuweather to DeSmog Blog to the main press as a record-warm decade story.
http://www.wmo.int/pages/mediacentre/press_releases/pr_976_en.html
http://library.wmo.int/pmb_ged/wmo_1103_en.pdf
Conceptualizing a reported (record) year as one of a record series works, I think. Great post.
So no acceleration over the last 50 years or so?
Whose answer would you consider reliable on that question?
How about this one?
That’s here.
Gavin, you write:
“Intuitively, the highest ranked year will be the most likely individual year to be the record (in horse racing terms, that would be the favorite) and indeed, we estimated that 2014 is about 1.5 to ~3 times more likely than 2010 to have been the record.”
The favorite in horse racing is determined/set before the race is run, not after. And if the favourite wins, the favorite will be recognised and recorded as the winner. – not ‘the most likely winner’.
[Response: You are taking the metaphor too literally. Obviously there is in the real world already a ‘winner’, we just don’t know perfectly which it is. That might change if more data can be brought to bear, or maybe we’ll never have more confidence than we do now. – gavin]
[edit – pointless insults are not welcome]
I am firmly in the camp that NASA GISS and NOAA NCDC had no business characterising 2014’s 2 hundredths of a degree/4 hundredths of a degree differences that fell well within error ranges, as evidence of anything other than a statistical tie with 2005 and 2010, i.e no warmer than 10 years ago.
[Response: This is the precision we’ve used since the beginning so changing now is not particularly sensible. If you don’t like it, feel free to reduce the significant figures. – gavin]
Berkeley Earth didn’t and they were right not to. That you guys did characterise it as a plain fact is really unprofessional in my view and lots of folks share my view, even Andy Revkin (although not as stridently of course).
[Response: Your concern is noted. – gavin]
To adopt your analogy, the fiction is trying to tell racegoers that the 3-way dead heat race they all just watched was in fact clearly won by horse A. I simply didn’t happen like you guys have said it happened. And the race has been run. So no amount of 38% likelihood or two and half times greater likelihood malarkey can change that.
[Response: You misunderstand totally that these statements are about our confidence of knowledge of a real world fact, not that the fact itself is a random variable. If you were a betting man you would lose money with your strategy. – gavin]
“It’s apparent that we’re already warming so rapidly that more than one year in three should be a new record, on average. Within a few decades it will be one year in two, then, late in the century, nearly every year will be a new record hottest year, if carbon emissions have not abated.”
The frequency of ‘records’
As I understand it, Tamino finds that the global annual averages are autocorrelated. I believe he uses an ARMA(1,1) model before applying the usual statistical measures.
Gavin, I just want to say you’re one of my all-time heroes. I’ve learned quite a bit on here. I’m still learning but I really appreciate you’re level headed intellect. Your command of science and language are very impressive. Thanks for all you do.
More on the use of statistics/odds to bring out a larger point, subject to the overt publication of the constraining assumptions:
Is there a probability/odds level “threshold” if-you-will, whereby if the odds of ‘x’ number of ‘y’ years of observed temperature anomaly all occurring outside the confidence interval for a model’s temperature projection, that it would be time for a paradigm shift in the particulars of the model, moreso than the normal tweaks?
As an assumption, presumably each successive year would be expected to more-or-less appear (or gravitate toward) the middle of the confidence interval, yes?
[Response: I’ve discussed this elsewhere many times. – gavin]
From the AP: “… the last 358 months in a row have been warmer than the 20th-century average … The odds of that being random are so high — a number with more than 100 zeros behind it — that there is no name for that figure …”
Indeed, using the HadCRUT data yields 253 consecutive months out of 609 positive months and 1,980 total months. Just for kicks, I calculated the probability P(253 consecutive months > 0) to be 1 / (9.79 x 10^148).
The favorite in horse racing is determined/set before the race is run, not after…,
One of the first attempts at the impossible, decadal forecasting:
Improved Surface TemperatureCPrediction for the Coming Decade from a Global Climate Model
Doug M. Smith,* Stephen Cusack, Andrew W. Colman, Chris K. Folland,
Glen R. Harris, James M. Murphy
…with the year 2014 predicted to be 0.30° ± 0.21°C [5 to 95% confidence interval (CI)]warmer than the observed value for 2004.
It’s based upon HadCrut3.
The horseracing analogy … to beat it to death. This was not a “dead heat” with a winner declared. It was a photo-finish, perhaps. But according to the understood rules of measurement (starting cue, length of race, position of finish line, etc.), 2014 won by a nose. The more appropriate (but imperfect) analogy for the uncertainty is using the results of the horserace to answer the question “which horse is the fastest?”, because the race itself may have been influenced by issues with the starting cue, slightly inaccurate length of race, angle of the camera, etc. But it was decidedly not a “dead heat”.
Another example of irresponsible reporting:
#22 From the AP: “… the last 358 months in a row have been warmer than the 20th-century average … The odds of that being random are so high — a number with more than 100 zeros behind it — that there is no name for that figure …”
What are the odds of any unusual or unanticipated event occurring? What are the odds of a volcano erupting during a given year, after thousands of years of quiescence? What are the odds of an ice age developing after a prolonged period of “normal” temperatures? What are the odds of the extreme warming that took place in Europe during the “Medieval warm period,” during which time Greenland was colonized and cultivated? What are the odds of you or I existing on Earth at this particular time and place, almost 14 billion years after the creation of the Universe?
Much ado about a record!
I wonder how much of this is cultural, that the general public, for instance, learn much of their statistics from baseball and soccer and basketball, and badly at that. “Hot hands”, indeed.
Still, to the degree to which statistical bludgeons are, to my mind, inappropriately raised at a short term record which could have turned out many other ways, each having no particularly special significance, the trumpeting of the breaking of the record is justified.
Also, while HadCRUT4 is an excellent dataset, its use in statistical inference regarding climate has a checkered history, in my personal technical opinion. This comes about because of a failure to understand and account for the limitations of ensembles in determining uncertainties in future evolution of climate when comparing these to actual time trajectories. See http://johncarlosbaez.wordpress.com/2014/06/05/warming-slowdown-part-2/
Thanks for engaging Gavin. We aren’t going to agree, it’s apparent but I am surprised you won’t let go of this fiction. I’ll try again to make my point. NASA GISS and NOAA NCDC plainly publicised that 2014 was ‘hottest year’ when it wasn’t. On the figures, as was found by Berkeley Earth, and will be found by the UK folks (next week I think) as well, (richardabetts tweets suggest this) 2014 was an unexceptional year, statistically tied with 2010 and 2005. And the retrospective probability confidence %s don’t change that one bit. If anything they’re evidence that GISS and NCDC knew the ‘hottest year’ statement was wrong but elected to go ahead with it anyway. It’s not relevant that they’re the same calculations that have always been done. in this case they didn’t support the ‘hottest year’ statement.
In one of your responses you’ve written:
“Obviously there is in the real world already a ‘winner’, we just don’t know perfectly which it is.”
We do know perfectly. GISS and NCDC particularly know, to the 2 hundredth or 4 hundredth of a degree, and well within error bars. Statistical tie. A three way dead heat going back 10 years. Your mischaracterisation that this is somehow in question, or that it is an issue of choice when GISS NCDC figures aren’t in question, is baffling to me. You seem to me to be missing the seriousness of what occurred with that ‘hottest year’ fiction. Anti-trust/misleading and deceptive conduct action is now an option. In all seriousness, a retraction of the ‘hottest year’ statement in favour of statistical tie would be the smart bet for GISS and NCDC now.
It’s a big year 2015 for climate change with the Paris conference being a real focus. A lot of scrutiny will be applied to anything that sounds like propaganda rather than science. Anyhow thanks again for engaging. We know where we stand.
@22 (Response)
Gavin, thank you for the links, particularly the second one:
http://www.nature.com/articles/ngeo2105.epdf?referrer_access_token=asYZi1f6hqm9PjPq5zbTcdRgN0jAjWel9jnR3ZoTv0N4NPgDFgfHJ2b91zjF64w3hINbUblPbMkf2xD1CI7KR6KuMO1sA-tDZqHPeonCAes%3D
I guess my question can now be further clarified (if the odds calculation shall be passed over) thusly–
When will “the use of the latest information on external influences on the climate system and adjusting for internal variability associated with ENSO” make its way into the projection model? Is this an impossible request? It appears that there needs to be some preparation to be continuously ‘inherently unsatisfied’ with model-data agreement, but if we already feel some models are ‘falling short’ is it something where more than half or more need to be before they will be actually modified?
Victor says “Another example of irresponsible reporting…”
That is a false comparison fallacy I believe. If you do want to compare, you would have to estimate the probability of each of those events occurring instead of “inviting” the reader to do it via rhetorical questions.
what those data sets also show that as the years progress the chances of ever again having a global temp below the long term average (1980) are becoming slimmer and slimmer. This is our new standard reality. I’m 48 and I doubt for a second that I will ever see again a year even comming close to the l.t.average. Notwithstanding a one in a million year volcanic event/s or nuclear winter.
#17–If you can point to ONE instance where these concerns were raised for any previous record year–for the same considerations have always applied–I will be shocked. In the meantime, this meme seems to me the epitome of bad faith and motivated ‘reasoning.’ Apparently, once again “Logic and proportion have fallen sloppy dead,” as denialism proceeds down the rabbit hole.
I think, too, that you may want to reconsider your horse race metaphor: it does happen that there are very close finishes in horse races. And what then? Why, track officials look closely at the evidence they have–think of the term “photo finish”–and then they make the best call they can. Just as was done with the 2014 warmth record.
Ah, Victor?
Victor, did you ever talk to a reference librarian? The questions you ask are good — but asking them of the wind, or typing them into the computer, does not get you the help for which you appear to be crying out.
Talk to someone near you who understands statistics.
Please. Otherwise you may — as appears so far — mistakenly convince yourself that ignoramus necessarily means ignorabimus.
At Azimuth, the topic that Jan Galkowski points to, ends with:
one thing I have notice is there is difference in temperatures between those given on the NASA/GISS map and those given on the NASA/GISS statistical page. on the map they give it as 0.67c above average on the statistics page as 0.68. Is there a reason for this?
[Response: http://data.giss.nasa.gov/gistemp/FAQ.html
“Q.Why is the number in the right hand corner of the global maps sometimes different from the corresponding value from the GISTEMP data files (tables and graphs)?
A.This is related to the way we deal with missing data in constructing the global means:
In the GISTEMP index, the tables of zonal, global, hemispheric means are computed by combining the 100 subbox series for each box of the equal area grid, then combining those to get 8 zonal mean series, finally from those we get the Northern (23.6-90ºN), Southern and tropical means, always using the same method. Hemispheric and global means are area-weighted means of the following 4 regions: Northern mid-to-high latitudes, Southern mid-to-high latitudes, and the Northern and Southern half of the tropics. For the global maps, we subdivide the data into the 4 regions 90-24ºS, 24-0ºS, 0-24ºN,24-90ºN and fill any gaps in one of those 4 regions by the mean over the available data in that region, and then get a global mean. For data-sets with full coverage, this should make no difference, but where there is some missing data, there can be a small offset. In such cases the number in the index files should be considered definitive, because in that method the full time series is involved in dealing with the data gaps, whereas for individual maps only the data on that particular map are used to estimate the global mean. ” -gavin]
Trends of “adjusted observations” that are not clearly labelled as such, and do not include the raw observations on the same graph are very misleading in my opinion. The ENSO adjustment is by definition not a measured value and there is no indication how large an adjustment was made.
I saw this same exact graphic posted on another blog without any indication it was ENSO adjusted. I looked at it and knew it wasn’t right for a raw temperature trend, but it sure had a nice NASA stamp of credibility on it. Now I know why. While you cannot prevent the misuse of graphics by others, this is a good reason to make it clear on the graphic exactly what it is.
[Response: The figure with adjusted trends is clearly labelled as such, and does not have a NASA logo. Next. – gavin]
It may not be priory obvious where the 48% chance of NOAA being a record year comes about. However, looking at the figure that Gavin shows with the distribution of estimates one can see that the distribution is fairly symmetric and in recent decades the width is fairly stable. So, this suggests we can simply use a normal distribution with the given sigma value (0.05) to approximate the uncertainty distribution for each year.
Thus, the simplest thing to do is to:
a) construct a time series of annual global temperature averages, add a random component to each year (value drawn from a gaussian with the given standard deviation and mean zero). This will constitute a possible series of annual temperatures (or a “realisation”).
b) Find at what year the temperature in the constructed time series is a maximum and store that value.
c) Repeat a) – b) as often as you like and summarize the results.
I find it easier to think about what is the statistical experiment under consideration by going over the process like this. Furthermore, this is really easy to code in any of the most common processing languages.
For those that read R, the code below does this:
# read data (using NOAA since it is easier to load than GISS)
aa=read.csv("http://www.ncdc.noaa.gov/cag/time-series/global/globe/land_ocean/p12/12/1880-2014.csv",header=TRUE, stringsAsFactors=FALSE,skip=2)
Year=trunc(aa$Year/100)
Tano=aa$Value
# calculate time series of annual average temperature
AnnualTano=tapply(Tano,Year,mean)
# construct a function that adds random gaussian values to the time series of annual values and then finds what year was maximum.
yearmax = function(annav,sigma) {
realiz=annav+rnorm(length(annav),mean=0,sd=sigma)
year_of_max=names(annav)[realiz==max(realiz)]
return(sample(year_of_max,size=1))
}
# run the function 1000 times with a sigma of 0.05 and summarise the results
table(replicate(1000,yearmax(AnnualTano,0.05)))
When I run the above code I get 2014 as the record year about 43% of the time. The fact that the actual distributions diverge from the gaussian is probably the reason for the slight under estimate in the frequency of 2014 as a record year.
It should also be clear it does not matter that the uncertainty is higher in the early part of the record, since these years will never become record years anyhow (as a consequence of global warming).
Victor (or anybody), we’re halfway through the calendar decade of 2010-2019. Keeping in mind my comment #4 above, would you care to predict a decade cooler than the last? Or even cooler than the one 20 or 30 years before?
Ever hopeful, I would be glad to elaborate on the bet in #4 if you feel confident in your prediction.
Re- Comment by Victor — 22 Jan 2015 @ 11:38 PM, ~#25
The AP quote suggests a test of two groups in order to determine how confident one is that the observed comparison could have occurred by chance. This sort of statistical test is the basis for a large proportion of scientific studies and is understandable and reasonable. When every data point of one group is above the mean of the other group, the difference will be significant. Other than the fact that this was stated as a news item (not science) what are you objecting to?
Worldwide, volcanoes erupt about once a week and odds could be easily calculated for any specified future period. Odds that one will occur during a specified four month period next year= High. Odds that Lassen will go off on January 23 of 2016= Low. What is the problem?
Odds of an ice age occurring? This is the same problem as for volcanoes except that it takes thousands of years for an ice age to develop and human prevention of this happening with greenhouse gasses will be very uncertain to predict for more than one hundred years so an odds calculation would, necessarily, require exact specification of conditions.
The problem with odds for the medieval warm period, as you have described it, is not possible because the warming was localized, patchy over time, and not “extreme.” Further, your Greenland comment is not appropriate because it was such a minor, although fascinating, event. Greenland was not, by any stretch of the imagination, green and the colony was quite small. The whole colony event could be described as a land swindle and the green part was hype.
What are the odds of one’s existence? Well, because I do exist the odds are 100%. This is such a silly question and is equivalent to measuring the positions of all the rocks in a field and asking what the odds are. The odds that you will win the big lottery are very low. The odds that someone will win the big lottery are very high. What is the point of your questions?
Steve
Err……… it is pretty simple isn’t it.
Yes 14 out of the last 15 years may be at the top of temperature table
What does it prove? It proves that we have had a warming period recently, that’s all.
Just extend the argument. If temperatures continue as they have this century,
(All data sources.
http://www.woodfortrees.org/plot/wti…rom:2001/trend
Satellite
http://www.woodfortrees.org/plot/rss…rom:2001/trend
Hadcrut, before they decided to alter their algorithms and spatial coverage.
http://www.woodfortrees.org/plot/had…rom:2001/trend
Hadcrut after their ‘adjustments’.
http://www.woodfortrees.org/plot/had…rom:2001/trend)
then in twenty years temperatures will still be the same and the logically challenged will be saying, ‘we are doomed 34 out of the 35 warmest years have just occurred’.
Continue further, say temperatures stabilise at this centuries trend. In a thousand years the logically challenged descendants will be saying ‘were doomed, 999 out of the 1000 warmest years have just occurred’!
Alan
#12 @Daniel, Revkin’s article is very good in exploring this topic. Gavin provided link in this post.
Nick Stokes: “It’s not clear how you then went to the odds of 2014>2010. Because 2010 basically wasn’t sampled in different places. So it seems there is a major component of variation missing. How is that handled?”
The first time I read you argument, I thought you were right. Now reading it again, I am wondering whether your argument may be valid for the error in the absolute temperature, but not relevant for the current case using anomalies. Due to the use of anomalies interpolation errors should again be independent from year to year, would be my guess. Thus the method used above by Gavin is right and it is no surprise that HadCRUT finds similar uncertainties.
So, how should somewhat complex matters relating to average global surface temperature anomalies be reported in the media?
Individual annual anomalies have the disadvantage that they are of little statistical significance, and yet they are the stuff of headlines, as we have seen. But being of little significance, they attract obfuscation and denial, as we have also seen.
On the other hand, long-term trends, whilst statistically significant, are difficult to understand and may simply be ignored.
Is there not a simple, more easily understood metric, with much greater statistical significance than the annual anomaly, available in the ten year running average anomaly? Using the January to December anomalies from http://data.giss.nasa.gov/gistemp/tabledata_v3/GLB.Ts+dSST.txt
this would have given the following ten year average anomalies since 2000 (apologies for the formatting):
Year … annual . 10 year
2000 … 40 … 36.4
2001 … 52 … 37.8
2002 … 60 … 41.9
2003 … 59… 45.8
2004 … 51… 48.1
2005 … 65… 50.4
2006… 59… 53.1
2007… 62… 54.8
2008 … 49… 53.6
2009 … 59… 55.6
2010… 66… 58.2
2011… 55… 58.5
2012… 57… 58.2
2013… 60… 58.3
2014… 68… 60
(divide by 100 to get anomalies in degC) Notice that nearly every ten year average is an increase on the previous. Isn’t that a better way to represent the data to the media?
I think Tamino once had a post called ‘Keep it simple, stupid’ saying much the same.
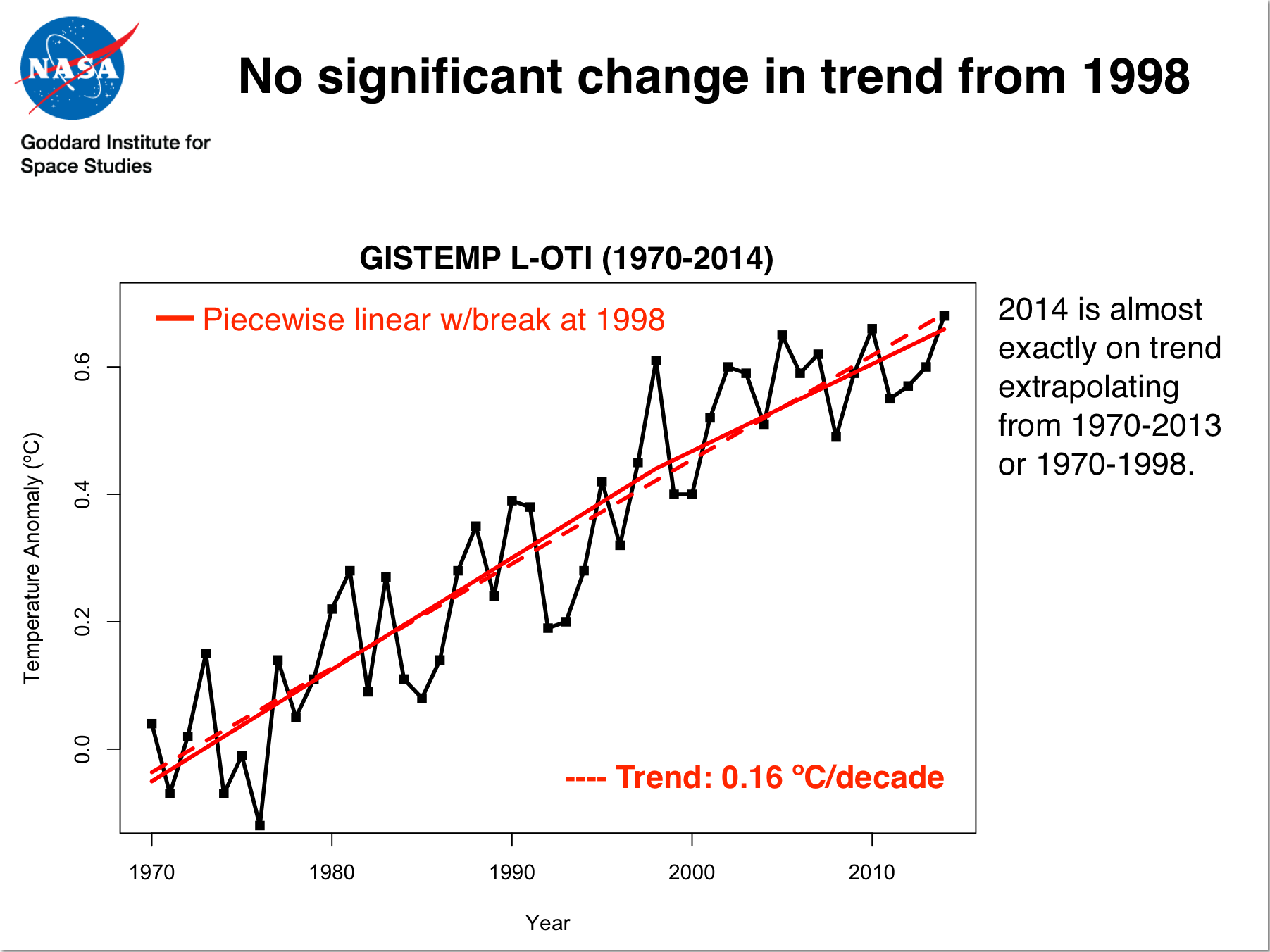
I can’t help but notice the obvious difference between the 4th figure in your post above
https://www.realclimate.org/images/hiatus.png
And this figure from early 2013.
https://www.realclimate.org/images/model122.jpg
I realise the that datasets get refined, but you can’t blame people for imagining there are ulterior motives
[Response: The obvious differences are the colour of the line, the baseline for the anomalies and the time period. Not sure what else. What ulterior motive might possess you to assert otherwise? – gavin]
David @19: Doubtless ARMA(1 year, 1 year) does a decent job. Despite being beloved of statistical modellers everywhere, ARMA is actually a pretty crude model — it’s just a linear autoregressive chain combined with weighted moving average white noise. Most importantly, it’s a discrete model, while many real-world autocorrelative processes are likely to be continuous. For example, if the best annual fit was actually going to be some equivalent of ARMA(0.7, 1.2), the model won’t cut it.
If you need to represent complex, fine-scale autocorrelation, best apply ARMA at suitably fine discretisation. For example, as I pointed out in note 4, the published best model for SOI is ARMA(1 month, 8 months; 1 month). Given the correlation, it’s likely that the a good monthly model of global temperature will have some similarity. Maybe ARMA(1,2,8;1), or perhaps even ARMA(1,2,8;0), which is of course just AR(1,2,8). We need Mr T to do some Akaike.
18: Glen Furgus, yep! that’s pretty much my way on interpreting the data as well. Similar to Jim Hansen’s favourite dice analogy.
25:I don’t understand your point victor? I think you are saying ‘even though it is not supposed to..shit happens’. Not a very a very scientific response you made, was it? The exactly why we have scientists, to understand how processes work, palio-climatologists to look far back to the beginning of our climatic system to establish the odds of this or that occurring. I’m sure you would like to know the odds of how many transmissive events it could take EBOZ to become airborne. I bet if you knew just how few, it would make the hair on the back of your neck stand right on end. So a figure which has a 100 ‘0s’ behind it to me says it wont happen again, especially taking an interval as long as a month.
With the possible exception of 1998 at the time in some of the canonical series, it is a simple fact that no one record year has EVER been “significantly” warmer than all other nearby years. It is a quite unlikely thing to happen given the magnitude of the trend and the magnitude of the measurement error.
So what, exactly, is the to do all about? Other than deniers trying to score FUD points yet again?
It’s interesting to notice the same denier crowd “accidentally” neglects to mention the up to ~7% measurement error in ice extent values at certain times of the year when trumpeting “record ice extent in Antarctica”.
Kevin’s reference to “motivated reasoning” is spot on.
I am open to exploring more sophisticated uncertainty models. – gavin – See more at: https://www.realclimate.org/index.php/archives/2015/01/thoughts-on-2014-and-ongoing-temperature-trends/comment-page-1/#comment-623870
I think publishing the Full Width at Half Max of the curves shown in the fifth figure, along with those not plotted would be helpful in allowing more sophisticated analysis. For example, selecting 2006 rather that 1998 as a break point in your fourth figure might end up with a reduced chi-square value that is better than your single slope fit as correct weightings are used.
Good piece Gavin,
“An alternative formulation is to describe these results as being ‘statistical ties’, but to me that implies that each of the top years is equally likely to be the record, and I don’t think that is an accurate summary of the calculation.”
What it implies it something rather different. It implies that there is nothing of great scientific importance to discuss. Nothing, that is, that one should stake one’s scientific reputation on, nothing that makes or breaks a theory.
Further, given that we had incomplete data at the time, one had to look at the possiblity that the .01 difference could become a -0.001 difference. So, while the odds of 2014 being the highest were the greatest, the penalty for losing the bet doesn’t look so good. We win nothing of scientific interest if 2014 is the warmest, we lose credibility if 2014 turns out not to be the hottest either by the additional data we will add or by comparison with C&W which we consider to be a method more reliable than NOAA or GISS. This is not just our opinion:it’s an opinion bourne out by recent publications which rely on C&W to solve some of the issues with the so called pause. Calling it the hottest when 2 weeks later you have to reverse yourself is a lousy payoff in my mind. If folks want to look at it as betting, then they have to consider what happens if you lose the bet. Calling it a tie takes into account not only our estimate but our guesses about C&W which has a warmer 2010 than we do. As the additional data has now been added I can report that the difference between 2014 and 2010 narrowed below .01C. Funny how that works. Go figure. I’d still call it a tie. If C&W turn out to have 2010 warmer than 2014. I’m glad with the call we made. And calling it a tie doesn’t mean that all odds are equal. They won’t be. It means winning or losing the bet is scientifically pointless.
#37 Steve Fish: “What are the odds of one’s existence? Well, because I do exist the odds are 100%.” Yes, and by the same token the odds of temperatures setting some sort of record between the 20th and 21st centuries are also 100%. Because that too actually happened, apparently. As I understand it, however, that is not the way odds are calculated — if it were then the odds of any thing occurring that actually has occurred would also be 100%.
In fact the odds against your existence or mine occurring at ANY give time and place are astronomical. Nevertheless, to quote another “expert” posting here: “shit happens.” In fact, the odds against ANY unexpected event occurring are always going to be high. And the assumption that such an event is unlikely for that reason, while technically correct, is also very dangerous. Read “The Black Swan” for the gory details.
Now certainly I realize that real scientists do take precautions when assessing such odds, and do take into consideration the various factors that might contribute to some unexpected event actually happening. If you reread my post you’ll see that my argument was not with any scientific finding, but with the way “the science” is being reported in the popular media. The implication of the article in question was: how could such a warming trend possibly be due to anything other than AGW given the overwhelming odds against any other possible explanation? Is that really a position any real scientist would be willing to endorse?
Based on the bar chart for temperature deltas, it is obvious that GW was started by Jimmy Carter.