Last Friday, NASA GISS and NOAA NCDC had a press conference and jointly announced the end-of-year analysis for the 2014 global surface temperature anomaly which, in both analyses, came out top. As you may have noticed, this got much more press attention than their joint announcement in 2013 (which wasn’t a record year).
In press briefings and interviews I contributed to, I mostly focused on two issues – that 2014 was indeed the warmest year in those records (though by a small amount), and the continuing long-term trends in temperature which, since they are predominantly driven by increases in greenhouse gases, are going to continue and hence produce (on a fairly regular basis) continuing record years. Response to these points has been mainly straightforward, which is good (if sometimes a little surprising), but there have been some interesting issues raised as well…
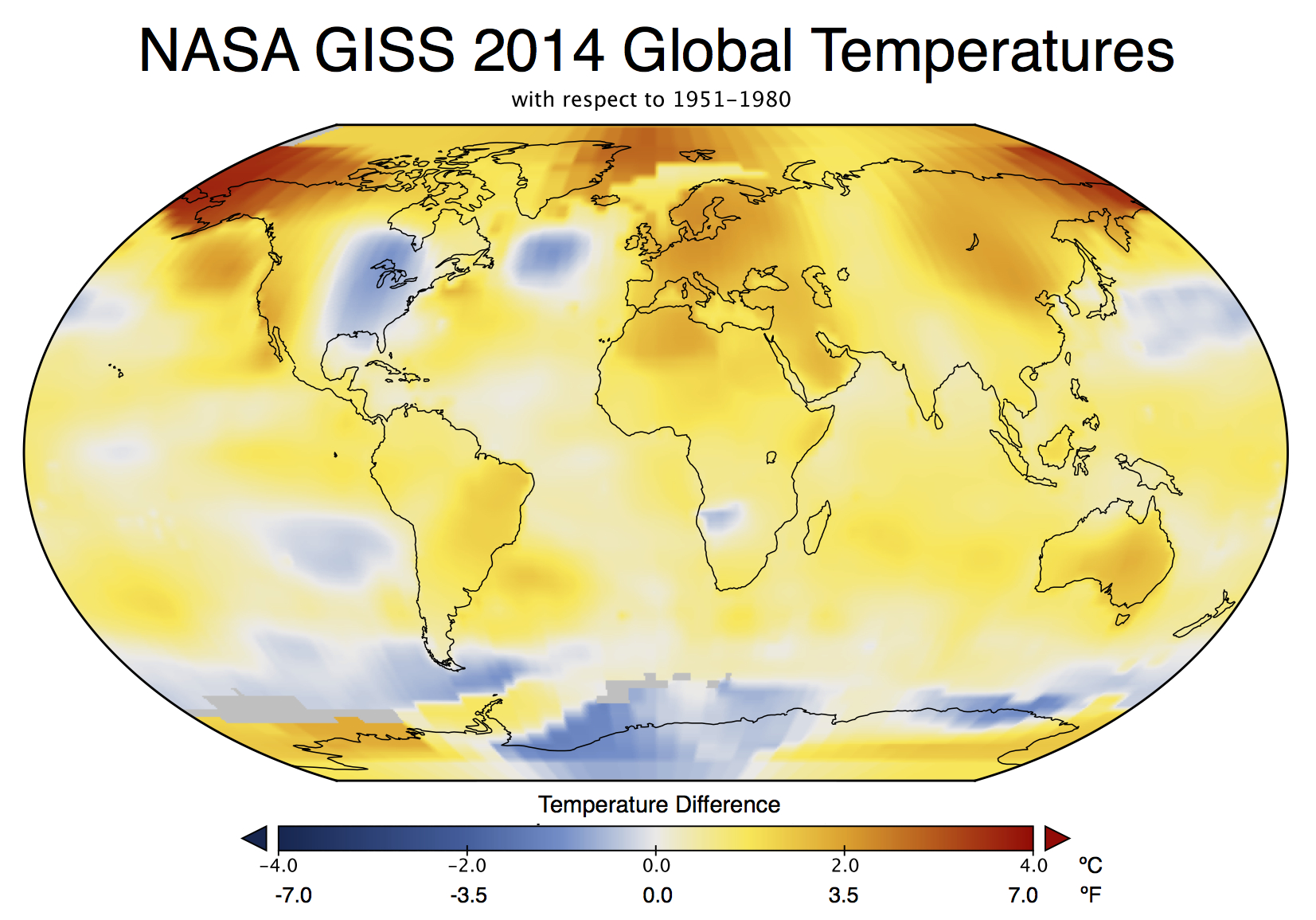
Records are bigger stories than trends
This was a huge media story (even my parents noticed!). This is despite (or perhaps because?) the headline statement had been heavily trailed since at least September and cannot have been much of a surprise. In November, WMO put out a preliminary analysis suggesting that 2014 would be a record year. Earlier this month, the Japanese Meteorological Agency (JMA) produced their analysis, also showing a record. Estimates based on independent emulations of the GISTEMP analysis also predicted that the record would be broken (Moyhu, ClearClimateCode).
This is also despite the fact that differences of a few hundredths of a degree are simply not that important to any key questions or issues that might be of some policy relevance. A record year doesn’t appreciably affect attribution of past trends, nor the projection of future ones. It doesn’t re-calibrate estimated impacts or affect assessments of regional vulnerabilities. Records are obviously more expected in the presence of an underlying trend, but whether they occur in 2005, 2010 and 2014, as opposed to 2003, 2007 and 2015 is pretty much irrelevant.
But collectively we do seem to have an apparent fondness for arbitrary thresholds (like New Years Eve, 10 year anniversaries, commemorative holidays etc.) before we take stock of something. It isn’t a particularly rational thing – (what was the real importance of Usain Bolt’s breaking the record for the 100m by 0.02 hundredths of a second in 2008?), but people seem to be naturally more interested in the record holder than in the also-rans. Given then that 2014 was a record year, interest was inevitably going to be high. Along those lines, Andy Revkin has written about records as ‘front page thoughts’ that is also worth reading.
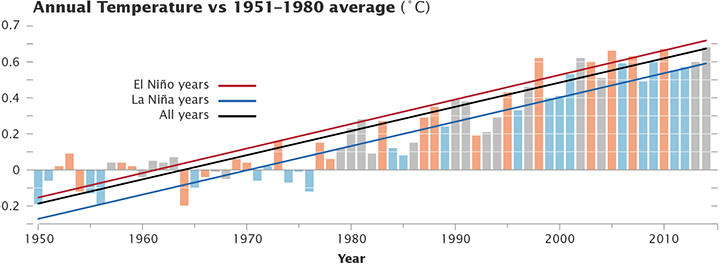
El Niños, La Niñas, Pauses and Hiatuses
There is a strong correlation between annual mean temperatures (in the satellite tropospheric records and surface analyses) and the state of ENSO at the end of the previous year. Maximum correlations of the short-term interannual fluctuations are usually with prior year SON, OND or NDJ ENSO indices. For instance, 1998, 2005, and 2010 were all preceded by an declared El Niño event at the end of the previous year. The El Niño of 1997/8 was exceptionally strong and this undoubtedly influenced the stand-out temperatures in 1998. 2014 was unusual in that there was no event at the beginning of the year (though neither did the then-record years of 1997, 1990, 1981 or 1980 either).
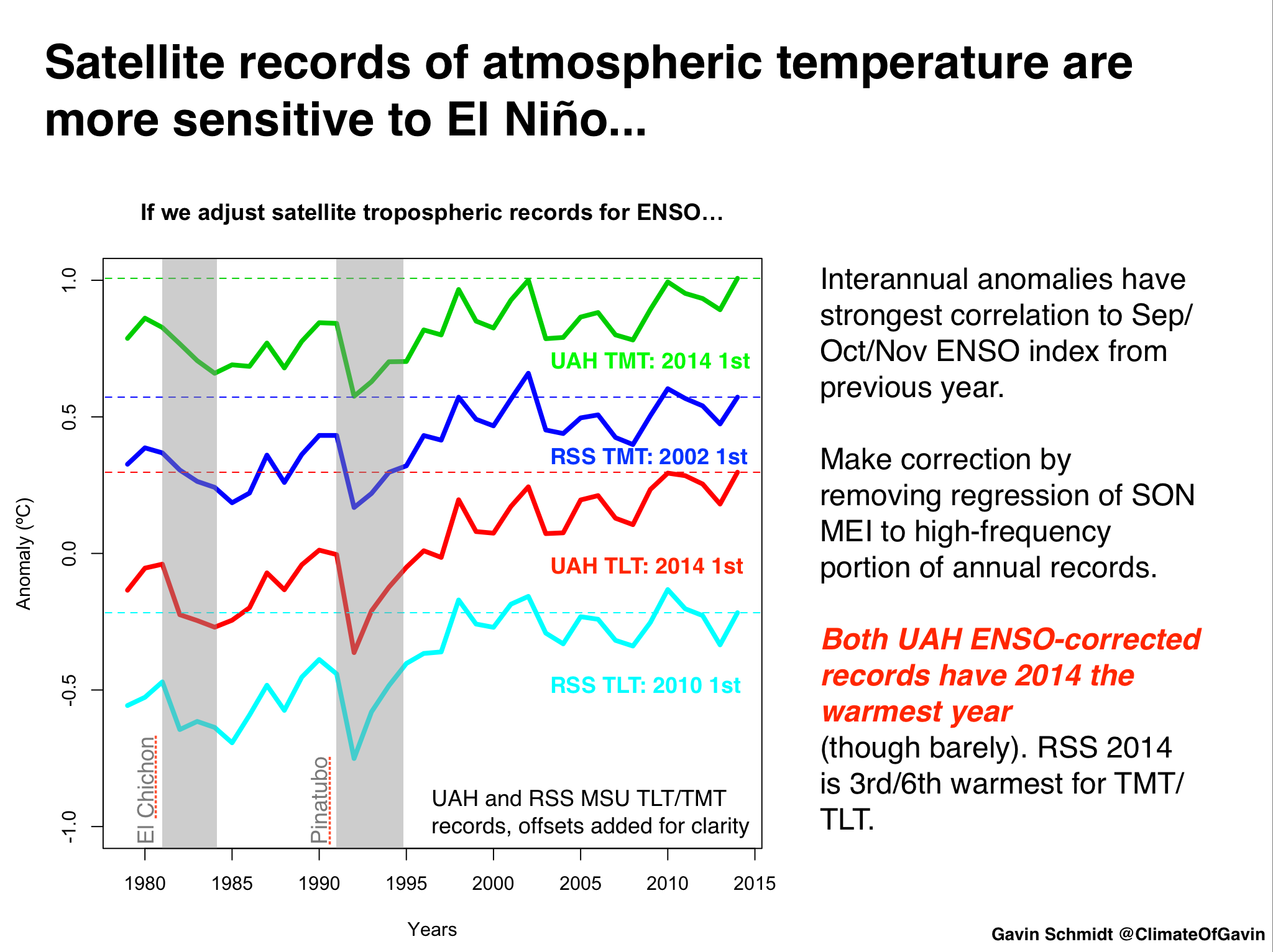
So what would the trends look like if you adjust for the ENSO phase? Are separate datasets differently sensitive to ENSO? Given the importance of the ENSO phasing for the ‘pause’ (see Schmidt et al (2014), this can help assess the underlying long-term trend and whether there is any evidence that it has changed in the recent decade or so.
For instance, the regression of the short-term variations in annual MSU TLT data to ENSO is 2.5 times larger than it is to GISTEMP. Since ENSO is the dominant mode of interannual variability, this variance relative to the expected trend due to long-term rises in greenhouse gases implies a lower signal to noise ratio in the satellite data. Interestingly, if you make a correction for ENSO phase, the UAH record would also have had 2014 as a record year (though barely). The impact on the RSS data is less. For GISTEMP, removing the impact of ENSO makes 2014 an even stronger record year relative to previous ones (0.07ºC above 2005, 2006 and 2013), supporting the notion that the underlying long-term trend has not changed appreciably over the last decade or so. (Tamino has a good post on this as well).
Odds and statistics, and odd statistics
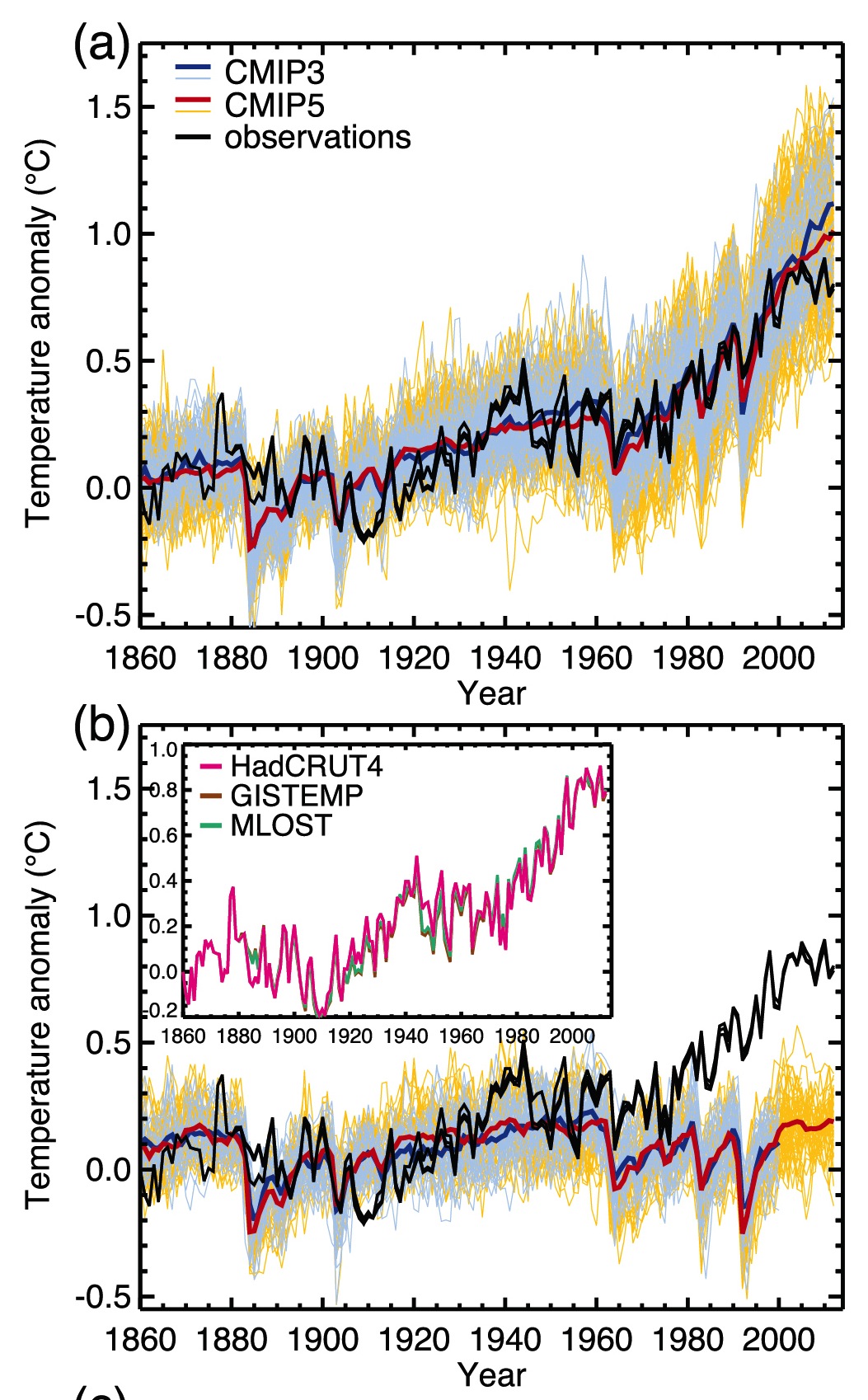
Analyses of global temperatures are of course based on a statistical model that ingests imperfect data and has uncertainties due to spatial sampling, inhomogeneities of records (for multiple reasons), errors in transcription etc. Monthly and annual values are therefore subject to some (non-trivial) uncertainty. The HadCRUT4 dataset has, I think, the best treatment of the uncertainties (creating multiple estimates based on a Monte Carlo treatment of input data uncertainties and methodological choices). The Berkeley Earth project also estimates a structural uncertainty based on non-overlapping subsets of raw data. These both suggest that current uncertainties on the annual mean data point are around ±0.05ºC (1 sigma) [Update: the Berkeley Earth estimate is actually half that]. Using those estimates, and assuming that the uncertainties are uncorrelated for year to year (not strictly valid for spatial undersampling, but this gives a conservative estimate), one can estimate the odds of 2014 being a record year, or of beating 2010 – the previous record. This was done by both NOAA and NASA and presented at the press briefing (see slide 5).

In both analyses, the values for 2014 are the warmest, but are statistically close to that of 2010 and 2005. In NOAA analysis, 2014 is a record by about 0.04ºC, while the difference in the GISTEMP record was 0.02ºC. Given the uncertainties, we can estimated the likelihood that this means 2014 was in fact the planet’s warmest year since 1880. Intuitively, the highest ranked year will be the most likely individual year to be the record (in horse racing terms, that would be the favorite) and indeed, we estimated that 2014 is about 1.5 to ~3 times more likely than 2010 to have been the record. In absolute probability terms, NOAA calculated that 2014 was ~48% likely to be the record versus all other years, while for GISTEMP (because of the smaller margin), there is a higher change of uncertainties changing the ranking (~38%). (Contrary to some press reports, this was indeed fully discussed during the briefing). The data released by Berkeley Earth is similar (with 2014 at ~35%~46% (see comment below)). These numbers are also fragile though and may change with upcoming updates to data sources (including better corrections for non-climatic influences in the ocean temperatures). An alternative formulation is to describe these results as being ‘statistical ties’, but to me that implies that each of the top years is equally likely to be the record, and I don’t think that is an accurate summary of the calculation.
Another set of statistical questions relate to a counterfactual – what are the odds of such a record or series of hot years in the absence of human influences on climate? This question demands a statistical model of the climate system which, of course, has to have multiple sets of assumptions built in. Some of the confusion about these odds as they were reported are related to exactly what those assumptions are.
For instance, the very simplest statistical model might assume that the current natural state of climate would be roughly stable at mid-century values and that annual variations are Gaussian, and uncorrelated from one year to another. Since interannual variations are around 0.07ºC (1 sigma), an anomaly of 0.68ºC is exceptionally unlikely (over 9 sigma, or a probability of ~2×10-19). This is mind-bogglingly unlikely, and is a function of the overly-simple model rather than a statement about the impact of human activity.
Two similar statistical analyses were published last week: AP reported that the odds of nine of the 10 hottest years occurring since 2000 were about 650 million to 1, while Climate Central suggested that a similar calculation (13 of the last 15 years) gave odds of 27 million to 1. These calculations are made assuming that each year’s temperature is an independent draw from a stable distribution, and so their extreme unlikelihood is more of a statement about the model used, rather than the natural vs. anthropogenic question. To see that, think about a situation where there was a trend due to natural factors, this would greater reduce the odds of a hot streak towards the end (as a function of the size of the trend relative to the interannual variability) without it having anything to do with human impacts. Similar effects would be seen if interannual internal variability was strongly autocorrelated (i.e. if excursions in neighbouring years were related). Whether this is the case in the real world is an active research question (though climate models suggest it is not a large effect).
Better statistical models thus might take into account the correlation of interannual variations, or have explicit account of natural drivers (the sun and volcanoes), but will quickly run into difficulties in defining these additional aspects from the single real world data set we have (which includes human impacts).
A more coherent calculation would be to look at the difference between climate model simulations with and without anthropogenic forcing. The difference seen in IPCC AR5 Fig 10.1 between those cases in the 21st Century is about 0.8ºC, with an SD of ~0.15 C for interannual variability in the simulations. If we accept that as a null hypothesis, the odds of seeing a 0.8ºC difference in the absence of human effects is over 5 sigma, with odds (at minimum) of 1 in 1.7 million.
{kind=link}
None of these estimates however take into account how likely any of these models are to capture the true behaviour of the system, and that should really be a part of any assessment. The values from a model with unrealistic assumptions is highly unlikely to be a good match to reality and it’s results should be downweighted, while ones that are better should count for more. This is of course subjective – I might feel that coupled GCMs are adequate for this purpose, but it would be easy to find someone who disagreed or who thought that internal decadal variations were being underestimated. An increase of decadal variance, would increase the sigma for the models by a little, reducing the unlikelihood of observed anomaly. Of course, this would need to be justified by some analysis, which itself would be subject to some structural uncertainty… and so on. It is therefore an almost impossible to do a fully objective calculation of these odds. The most one can do is make clear the assumptions being made and allow others to assess whether that makes sense to them.
Of course, whether the odds are 1.7, 27 or 650 million to 1 or less, that is still pretty unlikely, and it’s hard to see any reasonable model giving you a value that would put the basic conclusion in doubt. This is also seen in a related calculation (again using the GCMs) for the attribution of recent warming.
Conclusion
The excitement (and backlash) over these annual numbers provides a window into some of problems in the public discourse on climate. A lot of energy and attention is focused on issues with little relevance to actual decision-making and with no particular implications for deeper understanding of the climate system. In my opinion, the long-term trends or the expected sequence of records are far more important than whether any single year is a record or not. Nonetheless, the records were topped this year, and the interest this generated is something worth writing about.
References
- G.A. Schmidt, D.T. Shindell, and K. Tsigaridis, "Reconciling warming trends", Nature Geoscience, vol. 7, pp. 158-160, 2014. http://dx.doi.org/10.1038/ngeo2105
Entropic man @95.
Indeed Victor is presenting a denialist’s myopic version of AGW. His “Monkesque” account @91 is probably well introduced. The character Adrian Monk was after all exactly like Victor’s account – fictional. Monk also suffered conspiracy-delusions.
What I find misguided with Victor @90&91 is his adoption of a particular “hiatus” of his own contrivance (or one borrowed from fellow denialists) which he then tells us is accepted by climatologists when the climatological “hiatus” is a totally different phenomenon.
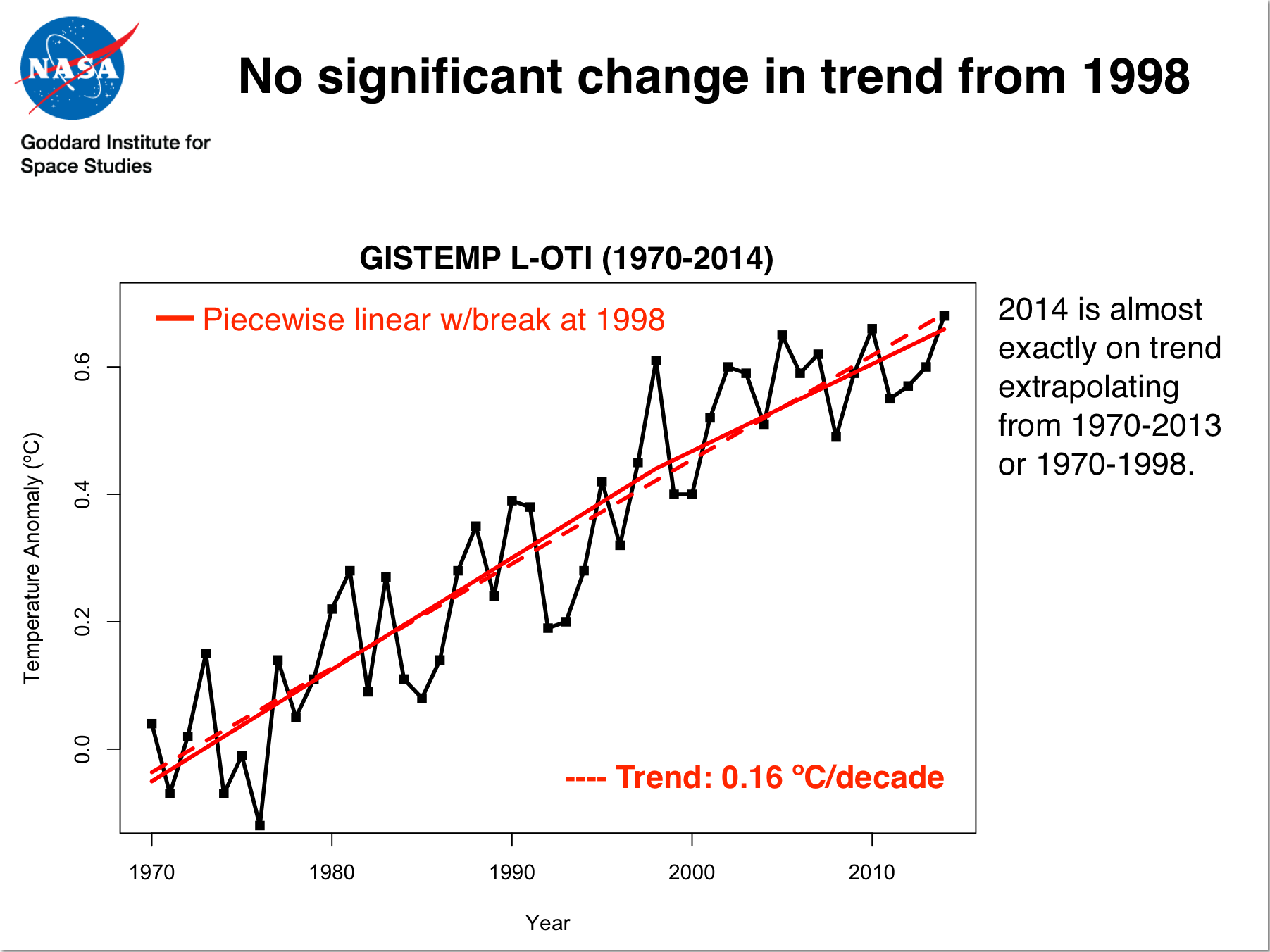
Perhaps worst of all is his refusal to admit that a regression though annual surface temperature data, say, 1980 to 1999, gives practically identical results for temperature rise as a regression 1980 to 2014. Using GISS(1980-99) yields 0.153ºC/decade. GISS(1980-2014) yields 0.156ºC/decade.
Instead, Victor dwells solely on the data 2000-14 which, because there was a lot of warming at the start of the 2000-14 period and less at the end does demonstrate a ‘flat period’, a “hiatus”. And a regression on GISS(2000-14) duly yields a temperature trend of 0.083ºC/decade.
Even accepting this denialist myopia from Victor, I do not believe he is justified in making what are exceptionally strong accusations. “A trend line is not necessary and, as in these cases, can be deceiving. I’m not claiming intentional deception. Many well meaning scientists have produced statistical artifacts, it’s an easy trap to fall into.” Accusations of gross stupidity from Victor? We have here an instance of the mucky old pot calling the shiny electric kettle “black”.
The only remaining question is whether Victor is entirely deluded (as are many denialists) or whether he is trolling. Perhaps it’s a bit of both. I do recall calling him previously “Victor the Troll” on more than one occasion here at RealClimate.
#95–True, but in my opinion not the most salient ‘fail’ in Victor’s post. The short version of what he is saying is “My visual assessment of the record trumps actual statistical analysis.” That, as Ray succinctly if a tad imprecisely points out, is “utter horsecrap.”
Worse, it’s been repeatedly and patiently (OK, sometimes rather less than patiently) explained to Victor just *why* it’s utter horsecrap. Yet here we are…
Re- Comment by Victor — 26 Jan 2015 @ 12:44 AM, ~#91
Victor, please point out the “15 to 18” year period where warming “vanished” in the graphs here: https://www.realclimate.org/index.php/archives/2013/09/the-new-ipcc-climate-report/ – more-15766
Oh, you can’t?
Steve
#95 “It is difficult to accept the hypothesis that global warming has stopped while ocean heat content continues to increase.”
Well, for one thing, it’s very difficult to understand how a warming process dependent on airborne greenhouse gases could suddenly, over a period of a year or two, shift heat from the atmosphere to the oceans. Here again, various theories have been produced as to how this could happen, but they seem extremely speculative at best.
The graphs I’ve seen suggest a more gradual process, involving a time delay between atmospheric and oceanic heating, which would make a lot more sense. See, for example, the following, from the recent AR5 report: https://curryja.files.wordpress.com/2014/01/presentation12.jpg
Looks like an oceanic warming trend corresponding to the atmospheric warming trend from 1979 through 1998 begins around 2000, suggesting a delay of ca. 21 years. Which seems reasonable if we want to assume that the transfer of warmth from the atmosphere to the ocean is going to take a fair amount of time. Given the necessity for some sort of time delay, it seems unreasonable to assume that the present state of the oceans reflects the current effects of airborne CO2 on the environment. If in fact the current rise in ocean temperatures reflects the earlier rise in atmospheric temperatures, then we might expect a corresponding leveling off some time around 2020. If that does not happen, then we can only conclude that something other than the state of the atmosphere is the principal driver of oceanic temperatures.
Of course the above are the speculations of a complete amateur, with littlle to no knowledge of climate science. For a professional opinion along different lines, I’ll refer you to Judith Curry: http://judithcurry.com/2014/01/21/ocean-heat-content-uncertainties/
#91 Victor
You claim the following:
1. “around 1979 … atmospheric temperatures began to climb in tandem with atmospheric carbon … . As the end of the century approached, the correlation seemed so obvious …”
2. “at the turn of the millennium …The correlation between CO2 emissions and “global warming” suddenly vanished.”
So. Could you answer the following questions?
1. What were the correlation coefficients between the logarithm of atmospheric CO2 and average annual global surface temperature as given by http://data.giss.nasa.gov/gistemp/tabledata_v3/GLB.Ts+dSST.txt between i) 1979 and 2000, ii) 1979 and the present iii) 1880 and 1979 iv) 1880 and the present?
2. What would the answers to the above have been if the climate sensitivity was indeed 3degC?
If you cannot answer those questions I would suggest that you are indulging in meaningless hand-waving.
You also earlier (#90) claimed, referring to one of Tamino’s graphs, that “the trend line remains unchanged despite the very obvious change of direction beginning in 1998”. The simplest (crude) way of assessing if there has been a trend line change in such circumstances is to count the number of points appreciably above and below the line after the purported change in trend. In the graph you cite, after 1999 there are seven years appreciably above the line and five below (and three more or less on the line). That evidence provides no support whatsoever for your claim.
Moreover, a “a mathematical technique known as “change point analysis””, see https://tamino.wordpress.com/2014/12/09/is-earths-temperature-about-to-soar/
also finds no evidence of any change in trend.
It seems to me that you fool yourself into seeing in graphs “very obvious” things that are not there, and you do so without any proper analysis or understanding. Your claims in that respect are completely bogus.
I’m trying to understand this and it was always confusing how they use words in statistics with different meanings than what we’ve grown to learn, but it’s been over a decade since I did any statistics. Is it a better way to put it, to say “IF an uncertain event were to happen, the probability of 2014 being the hottest record is 38%”.
This does not imply that there is a 62% chance that an uncertain event is likely to happen that would make another year hotter than 2014?
I think Deke Arndt touched on this in the Mashable article when he said…
“An uncertainty range “does ***NOT*** mean” that each temperature within the given range is “equally likely,” Arndt says.
“It resoundingly and definitively means something fundamentally different. Gavin’s slide from the presentation shows this pretty beautifully,” he said.”
Or am I completely misinterpreting what the 38% means?
@78 Victor wrote: ” “I don’t see much of a trend until ca. 1979.”
Seriously? Try putting your thumb over the hump between ~1935 and ~1949. Or the trough between ~1942 and ~1978. The Mark I Eyeball trend detector is very easily distracted by excursions above and below the long term trend line.
Looks like some sort of plateau has been reached. Temperatures still seem quite high, but regardless of how many “record-breaking” years we find from 1998 on, the slope from that year on has leveled off to approximately 0.”
The problem with your statement is that 1) 1998 was a rather large outlier caused by the strongest El Nino on record, meaning the underlying trend continued unperturbed right past 1998 until ~2002 in that graph (the Mark I eyeball at work again), and 2) 2002 to present (and even 1998 to present) does not constitute the long term trend as 12 (or 17) years is far short of the ~30* years needed to detect the underlying trend from the year to year noise of natural variability. *See Results On Deciding Trends
Even if we stick to just the steeper 1979 to present period, there is no evidence beyond the easily-fooled Mark I eyeball that the last 12 (or 17) years has deviated significantly from the underlying trend. See Tamino at It’s the Trend Stupid. (Sorry that’s not meant as an insult, it really is the title of Tamino’s post on the subject.)
Trying to teach chess to someone whose only interest is in tipping the board and knocking the pieces about is a waste of time and energy. Clearly what needs to be taught is outside the scope of the relevant topic.
The biggest lie of Victor is not about the ‘pause’. The big lie is the idea that scientists noticed a correlation between Co2 and temperature and then developed the idea that Co2 caused warming. In Victor’s delusion the scientists couldn’t think of anything other than Co2 to blame the warming on, so predicted further warming and these predictions were then followed by a failure of further warming after the predictions were made.
The actual fact is that Co2’s warming effect was not discovered based on a correlation between warming and Co2. It was predicted to cause warming because of the laws of physics. The earliest predictions were made in the late 19th century, and evidence of a building consensus emerges in the late 70s. During the 70s there was no clear warming signal, and even some speculation that the world was headed towards an ice age. A landmark paper in 1981, Hansen predicts that it would take up to 20 years for Co2 warming to rise above the noise of natural variation and be ‘detected’. This prediction has been clearly validated by an overall significant warming trend in the 34 years since this prediction was made. A corollary of the prediction that Co2 would take up to 20 years to rise above the noise of natural variation is that natural variation could conceivable cause a ‘pause’ of up to 20 years, and so the recent short period with a lack of warming is totally consistent with Hansen’s predictions.
Just for fun I tried my own Tamino style graph using GIStemp compare the 1970-2014 trend with the 1998-2014 trend, including (hopefully) sensible confidence limits.Hat tip to Woodforthetrees.
Three things stand out.
1) The 1998-2014 trend is slower than the 1970-2014 trend, but is NOT zero.
2) 1998 and subsequent years start well above the long term trend line and regress back towards it. It is not a pause, but a temporary excursion above the trend.
3) The 2014 data sits squarely on the 1970-2014 trend line, well above the 1998-2014 trend line.
In fairness to victor, the difference between the two is not yet statistically significant, but neither is his “pause” a significant deviation from the longer term trend.
Re- Comment by Radge Havers — 26 Jan 2015 @ 5:22 PM, ~#108
Radge, you are so cruel. Victor has special needs because of his dumbth.
Steve
Sorry, broken links.
Robert Grumbine’s “Results on deciding trends” is here: http://moregrumbinescience.blogspot.ca/2009/01/results-on-deciding-trends.html
Tamino’s “It’s the Trend Stupid” is here: https://tamino.wordpress.com/2015/01/20/its-the-trend-stupid-3/
For folks asking about the Booker piece in the Telegraph regarding temperature adjustments, Kevin Cowtan (of Cowtan and Way fame) recently made an excellent YouTube video dissecting his claims: https://www.youtube.com/watch?v=qRFz8merXEA
Brown, P. T., W. Li, and S.‐P. Xie (2015), Regions of significant influence on unforced global mean surface air temperature variability in climate models, J. Geophys. Res. Atmos., 120, doi:10.1002/2014JD022576.
http://www.eurekalert.org/pub_releases/2015-01/du-cmd012615.php
All I’ll say in response is that when one sees a claim that on its face makes no sense, then no amount of mathematical legerdemain is going to make it look any more convincing to anyone with critical thinking skills. The purpose of statistics is to clarify, not obfuscate. If you follow the literature in a field like physics, you’ll see how easy it is for one person’s neatly contrived theory to be blasted out of the sky by skeptics. Not because of any errors in his math, but because the theory either makes no sense, or cannot be verified by actual evidence (i.e., “eyeballing”). Happens all the time. But not in climate science? C’mon.
In any case, it really surprises me, I must say, that so many posting here find it so easy to dismiss the significance of the “hiatus,” “pause,” what have you. So here, for your edification, are a few quotes from some of your associates:
Yu Kosaka & Shang-Ping Xie, as published in Nature (http://www.nature.com/nature/journal/v501/n7467/full/nature12534.html): “Despite the continued increase in atmospheric greenhouse gas concentrations, the annual-mean global temperature has not risen in the twenty-first century1, challenging the prevailing view that anthropogenic forcing causes climate warming.”
Jeff Tollefson, in Nature (http://www.nature.com/news/climate-change-the-case-of-the-missing-heat-1.14525): “For several years, scientists wrote off the stall as noise in the climate system: the natural variations in the atmosphere, oceans and biosphere that drive warm or cool spells around the globe. But the pause has persisted, sparking a minor crisis of confidence in the field. . . On a chart of global atmospheric temperatures, the hiatus stands in stark contrast to the rapid warming of the two decades that preceded it. Simulations conducted in advance of the 2013–14 assessment from the Intergovernmental Panel on Climate Change (IPCC) suggest that the warming should have continued at an average rate of 0.21 °C per decade from 1998 to 2012. Instead, the observed warming during that period was just 0.04 °C per decade, as measured by the UK Met Office in Exeter and the Climatic Research Unit at the University of East Anglia in Norwich, UK.”
From http://www.washington.edu/news/2014/08/21/cause-of-global-warming-hiatus-found-deep-in-the-atlantic-ocean/: “Every week there’s a new explanation of the hiatus,” said corresponding author Ka-Kit Tung, a UW professor of applied mathematics and adjunct faculty member in atmospheric sciences. “Many of the earlier papers had necessarily focused on symptoms at the surface of the Earth, where we see many different and related phenomena. We looked at observations in the ocean to try to find the underlying cause.”
Joe Atkinson, NASA’s Langley Research Center (http://climate.nasa.gov/news/1141/): “Between 1998 and 2012, climate scientists observed a slowdown in the rate at which the Earth’s surface air temperature was rising. While the rise in global mean surface air temperature has continued, between 1998 and 2012 the increase was approximately one third of that from 1951 to 2012.”
Terrell Johnson, reporting on a recent NASA publication concluding that deep ocean temperatures have not increased since 2005 (http://www.weather.com/science/environment/news/deep-ocean-hasnt-warmed-nasa-20141007): “While the report’s authors say the findings do not question the overall science of climate change, it is the latest in a series of findings that show global warming to have slowed considerably during the 21st century, despite continued rapid growth in human-produced greenhouse gas emissions during the same time.”
While none of the above quoted sources claim the “hiatus” actually refutes the climate change paradigm and most in fact offer explanations for it, of one sort or another, all do clearly agree that it is real, and warrants an explanation. If they felt they could simply dismiss it by invoking statistics along the lines of what we’ve been seeing here, I’m sure they’d have done so.
#106–“IF an uncertain event were to happen, the probability of 2014 being the hottest record is 38%”
– See more at: https://www.realclimate.org/index.php/archives/2015/01/thoughts-on-2014-and-ongoing-temperature-trends/comment-page-3/#comment-624107
Can’t speak with authority, nor for everyone, but no, I don’t find that an improvement. Either 2014 was or it wasn’t the hottest; nothing will change that. What’s uncertain is our knowledge.
It quite obvious Victor or whoever he is, is not interested in the science but trying to peddle some vested interest. So many of you have tried to correct his gross misunderstandings to no avail, he keeps harping back to his old worn out rhetoric. So just ignore him and the pathetic bleatings of a delusional man will fade away. As nothing undermines good science…nothing!!
just been looking at The Nullschool wind/sea map at different altidues in re: to The massive blizzard in the US. Two rivers of Jetstream winds, one from the arctic traveling over Washington state to Nova scotia meet a very warm jet stream travelling from south to north along Americas east coast converge. Talk about high level instability. Then we have extremely moist surface winds heading due north being fed over the gulf. all meeting at new hamshire latitude.
Does anyone agree that the current jet stream over the north Americas bears a striking Rossby look to it. Very deep and meandering?. Creating the mother of all blizzads.
And once again Victor completely ignores the El Nino of 1998 which help create the outlier year that he has become obsessed with as the start of a “pause”. Furthermore, he completely ignores the many La Nina years of the past decade which have served to tamper global warming. Meanwhile, we just had the warmest year on record despite not having a big El Nino. How convenient of him. And how extremely anti-science.
Victor at comments 91, 115, etc., put forth the following and similar arguments:
“But then a funny thing happened. The correlation between CO2 emissions and “global warming” suddenly vanished. While temperatures continued to climb, producing year after year of record breaking warmth globally, the rate of climb reduced to almost nothing, while the increase in CO2 emissions remained as high as ever. This was at first dismissed as “noise,” but as the trend of no trend continued for a period of anywhere from 15 to 18 years, it became increasingly clear that the earlier correlation had been misleading. There was in fact no longer much evidence that CO2 emissions were the cause of the warming trend over the last 20 or so years of the 20th Century.
…
All I’ll say in response is that when one sees a claim that on its face makes no sense, then no amount of mathematical legerdemain is going to make it look any more convincing to anyone with critical thinking skills.”
Even though your whole line of argument (of which the above is but an example) is utterly inconsistent with so much physics (as some others have already shown), it is also the case that your whole line of argument is in the general or abstract case fallacious.
To see how, consider the following two conditions, one stronger, one weaker, both false:
Denote this following stronger condition as C_s: When real world cause and effect relationships are expressed in real world mathematical data in terms of functions on the real numbers, these real world cause and effect relationships must always be expressed in real world mathematical data as one-to-one functions such that the rates of change in the input data must always correlate perfectly with the rates of change in the output data.
Denote this following weaker condition as C_w: Real world cause and effect relationships must always be expressed in real world mathematical data as monotonic functions (monotonic functions are not necessarily one-to-one).
(Side note: In case you don’t know what graphs of these functions in question look like in, say, the real numbers, here’s an example: Strictly increasing or strictly decreasing graphs signify one-to-one functions.)
Now here’s the problem with your whole line of argument:
Not only does your whole line of argument assume C_s or C_w, but the following two implications are also the case: Your whole line of argument holds or makes sense only if C_s holds – that is, your whole line of argument does not hold or make sense without C_s. And it is also the case that your whole line of argument holds or makes sense only if C_w holds – that is, your whole line of argument does not hold or make sense without C_w.
In other words, based on what you’ve written, your position is that a cause and effect relationship makes sense or passes some critical thinking skills test only if the said relationship holds according to conditions like C_s and C_w.
(Side note: If you don’t follow, then see the convention that “only if” is equivalent to “implies” and see the definition of material implication and De Morgan’s identities.)
But again, C_s and C_w are false – they do not hold. This is because it is not uncommon in nature to have competing cause and effect relationships that result in mathematical data in which the target cause and effect relationship is expressed as a nonmonotonic function. (In the real numbers, an example of this phenomenon in graphical form would be a function whose graph is in the form of up and down fluctuations around an increasing curve.)
Therefore, by modus tollens on each implication and the implied falsity C_s or C_w, your whole line of argument does not hold.
@118 In the mid-Atlantic, warm air is being pumped north by a succession of lows traveling up the coast but NOT turning east. Forecast this weekend off southern Greenland is in the 40sF. Forecast tomorrow for eastern Newfoundland is 50F. http://meteocentre.com/models/get_anim.php?mod=gemglb&run=00&stn=TT2m&map=na&lang=en&mode=latest&yyyy=latest&mm=latest&dd=latest
If they felt they could simply dismiss it by invoking statistics along the lines of what we’ve been seeing here, I’m sure they’d have done so.
Comment by Victor — 26 Jan 2015
Lather, rinse, repeat….
So when we look back on 2014 and the records that fell, it gives us some pause about the so-called pause (hat-tip to Dr. Greg Laden for that phrase). Some people tried to tell us global warming had “paused”, that it ended in 1998, or that the past 15 years or so had not seen a change in the energy of the Earth. This ocean warming data is the clearest nail in that coffin. There never was a pause to global warming, there never was a halt, and the folks that tried to tell you there was were “lying”.
http://www.theguardian.com/environment/climate-consensus-97-per-cent/2015/jan/22/oceans-warming-so-fast-they-keep-breaking-scientists-charts
@Victor #115:
Read this quote from the NASA news report:
“Between 1998 and 2012, climate scientists observed a slowdown in the rate at which the Earth’s surface air temperature was rising. While the rise in global mean surface air temperature has continued, between 1998 and 2012 the increase was approximately one third of that from 1951 to 2012.
This trend — referred to as a “global warming hiatus”…”
and reflect on exactly what the various links you are referring to are trying to explain.
Again, consider that the conclusion of each of those links is that the oceans have been placing a massive thumb on the scales over the last 16 years, and consider whether that is encouraging or discouraging for the longer-term outlook.
#109, Michael H.–Yes, that is a good point–and an underappreciated one. Most of the familiar impacts associated with climate change were predicted long before being observed, based upon physical theory and logic. To a considerable degree, the story of the “IPCC era” has been detection of such: “Yup, sea level is rising, all right. Now, how are those glaciers doing? Hmm, not so good.” And so forth.
You’ll frequently hear denialists go on about “failed predictions”, but the real story is quite the reverse. I actually have a piece on this aspect of things in process. For me, it’s “practical epistemology.”
More nonsense from Victor the Troll @116 in the shape of “a few quotes from some of your associates” by which we are probably meant to conclude that the five “quotes” he presents are those of climatologists.
However, two are from journalists (I’m not sure what a discussion of ocean warming below 2000m has to do with the price of cheese, mind), one a quote from a piece written by a NASA employee interviewing a climatologist, and KKTung is some sort of misguided mathmatics professor and very denialist in his approach to AGW. This leaves one “quote”.
Kosaka & Xie for some reason do have a rather strange statement within their abstract: “…challenging the prevailing view that anthropogenic forcing causes climate warming”. I remember it at the time because it doesn’t seem to square in any way with the rest of the paper. I took it as an error left over from some poor editing.
I would urge Victor the Troll to try really really hard and take on board the words of the climatologist Norman Loeb interviewed by Joe Atkinson. “”It’s okay to be skeptical,” he said. “Scientists are skeptical by nature. But at the same time, we need to be reasonable.” If Victor fails in this and continues presenting his unabashed denialism, I will be renewing my calls that Victor’s time amongst us be terminated.
It is a little puzzling that Victor continues to post nonsense here. Is he merely trying to draw traffic to his own blog? Do any of you ever go there?
Or maybe he’s planning to run for political office? I’ll say this for him, he stays on message!
You’ve got to admit there is something weird with the data in that bar chart. Fitting a line overlaying two clearly different regions of the graph has little value for understanding. The NASA plot which shows only the region >1970 borders on lying if no explanation is given for the earlier flat region.
2 deg C and 2 feet of sea level rise. How much is this going to cost me in feel-good projects that won’t even solve the problem? 50k, 100K or more for each person over their lifetime? Where will that come from?
Back to the topic of the above post, I have written a new blog post on the interesting redefinition of the term record. Excerpt:
(Chris Dudley, WMO is a good idea, but big. I will ask around how that could go and who within WMO would be the best partner. Nice to see that there are already some less specific texts in the treaty. Also the complete and open international sharing of climate data should be formulated much stronger.)
Certainly we have been in a warming trend since we were able to start having some decent temperature measurements in the 19th century.
Given this trend I don’t see anything unusual in the 21st centuries temperatures. They look like you would have predicted looking at the overall trend.
http://www.woodfortrees.org/plot/hadcrut3vgl/from:1850/to:2013/compress:12/plot/hadcrut3vgl/from:1850/to:2013/trend/plot/hadcrut3vgl/from:1850/to:2010/trend/offset:0.3/plot/hadcrut3vgl/from:1850/to:2010/trend/offset:-0.3/plot/hadcrut3vgl/from:1850/to:2010/scale:0.00001/offset:-2
The slight rise in 2014 again should not surprise ENSO has been in positive territory for much of the period and we are at solar max. Given that the PDO is in its negative phase we can expect ENSO to be a bit negative overall in coming years until well into the 20s. Also the solar cycle will weaken till about the mid 20s when the AMO should start to fall into negative territory.
Seems like temperatures this century are more likely than not to follow the pattern seen since we started measuring.
This would indicate an overall warming this century of about 0.5c.
Not sure why people seem to think this is catastrophic.
Alan
Victor (#128),
Sounds like a good plan. If you want to make a full frontal assault, an email to WMO’s Ms. Carine Richard-Van Maele at WMO http://www.un-ngls.org/spip.php?page=article_s&id_article=833 with CC to UNESCO’s Ms. Marie-Ange Théobald and Ms. Noha Bawazir http://www.un-ngls.org/spip.php?page=article_s&id_article=816 and UN-NGLS http://www.un-ngls.org/spip.php?page=article_s&id_article=790 outlining the scientific need and the brain storming you have been doing might shake something lose too. UNESCO has money which might be sufficient for proposal development. At the least, I think you’d be directed to someone in WMO who is thinking about this.
I’ve noticed once again a correlation between troll feeding and my scroll wheel speed…
Here’s a newish subtopic: How long before we’re wondering whether we’ll ever see a year as cool as 1998 again, and speculating how much volcanism it would take to produce one?
Victor (#128),
Here’s a draft letter you can edit and use if you like:
Dear Ms. Richard-Van Maele,
This letter is to seek the involvement of the World Meteorological Society (WMO) in advancing world climate monitoring by a significant improvement in the method of gathering the temperature measurements used to calculate global average temperature at the Earth’s surface so that the precision of this calculation can be increased. The precision of this calculation has been improving with time. http://graphics8.nytimes.com/images/2015/01/20/blogs/warmestimates/warmestimates-blog480.jpg However, advances in temperature data collection in the deep oceans together with new capabilities in tracking the global distribution of greenhouse gases make the current precision inadequate to fully test our understanding of the the Earth’s heat budget and thus to carry out “systematic observation and development of data archives related to the climate system and intended to further the understanding and to reduce or eliminate the remaining uncertainties regarding the causes, effects, magnitude and timing of climate change” as required in Article 4 section 1(g) of the United Nations Frame Work Convention on Climate Change. Our advances are leaving our most basic measurements behind in terms of how they could be integrated into a clearer understanding of our climate system.
The main causes for lack of precision are well known. They include lack of adequate spatial sampling to leave instrumental noise as the major term, transcription errors which may be avoided with modern automation and inhomogeneities which dedicated climatological networks in some parts of the world have made strides in overcoming. Creating a worldwide well sampled climatological station network could (in preliminary calculations) improve precision by a factor of three over current capabilities.
Such improved precision would allow close study of decade scale fluctuations in surface temperature that can lead to much better calibration of climate models. Climate models’ transient response to forcing can be checked against the occurrence of equatorial volcanic eruptions, for example. However, only very strong eruptions are clearly seen in the temperature record owing to lack of precision. Improved precision could take advantage of weaker but more common eruptions to better understand climate transient response. Early stage climate mitigation as well as approach to the accepted 2 C limit also require greater precision to be observable in the temperature record.
Some preliminary checks on feasibility indicate that the envisioned worldwide well sampled climatological station network would be possible if the international cooperation that the COP in Paris this year represents is properly engaged.
I seek the assistance of the WMO in bringing a fleshed out proposal for such cooperation to the COP and I hope you can provide me with advice on how to engage that assistance.
With Warm Regards,
Victor Venema
Gavin, I must point out that a great deal of 2014 warming was in the Arctic, particularly during winter in darkness, no pavements, no industries to speak of, and with one of the smallest population densities in the world. The said “small amount” means something in Joules world wide, it should be quite a large number of Joules. Arctic winter formation has been largely hit by advection from cyclones easily punching through what was once a mighty fortress of cold air living in a physical symbiosis with much thicker sea ice. There is no imperfection in this reality, it is happening whether we miscalculate or misestimate, the correct focus would be on the polar regions which truly reflect world temperature trends.
This said I have potentially found a way to estimate cyclone energy levels by their twilight “brightness” in adjoining darker colder regions, so far this winter the Christmas Cyclone called “santa storm” shined brighter than all, unfortunately the latest on going storm can’t be compared due to waning bright moon.
I Need better instruments! http://eh2r.blogspot.ca/ please read 3 top articles.
#125 MARodger: “However, two are from journalists (I’m not sure what a discussion of ocean warming below 2000m has to do with the price of cheese, mind), one a quote from a piece written by a NASA employee interviewing a climatologist, and KKTung is some sort of misguided mathmatics professor and very denialist in his approach to AGW. This leaves one “quote”.”
Here are some more:
Richard P. Allan, Professor of Climate Science at University of Reading (https://theconversation.com/heat-accumulating-deep-in-the-atlantic-has-put-global-warming-on-hiatus-30805): “There seem to have been a dozen or so explanations for why the Earth’s surface has warmed at a slower rate over the past 15 years compared to earlier decades.”
Dr. Roz Pidcock, PhD in physical oceanography from the University of Southampton (http://www.carbonbrief.org/blog/2014/10/an-in-depth-look-at-the-oceans-climate-change-and-the-hiatus/): “Over the last 15 years or so, surface temperatures have risen much slower than in previous decades, even though we’re emitting greenhouse gases faster than we were before.”
Gerald A. Meehl, Haiyan Teng & Julie M. Arblaster, National Center for Atmospheric Research, Boulder, Colorado 80307, USA (http://www.nature.com/nclimate/journal/v4/n10/full/nclimate2357.html): “The slowdown in the rate of global warming in the early 2000’s is not evident in the multi-modal ensemble average of traditional climate change projection simulations.”
http://climate.nasa.gov/news/1141/: “Norman Loeb, an atmospheric scientist at NASA’s Langley Research Center, recently gave a talk on the “global warming hiatus,” a slowdown in the rise of the global mean surface air temperature. He does not believe the hiatus will develop into something permanent.”
Professor Matthew England — see youtube video at https://www.youtube.com/watch?v=RifZdKP3VPs
Andrew Dessler — see youtube video at https://www.youtube.com/watch?v=OD4BDpdJ1Vs from roughly 6 minutes in.
Alan Millar,
What have you got against physics?
Eric Zann,
Might I suggest reading the piece again for comprehension this time? Your comment makes no sense bases on the content of the article.
I’m not sure this is the place to suggest this, que so what, so what. I’d be curious to see Gavin & Mann do a joint piece on the “hiatus”. I know Mann (et al) have a 2008 paper attributing (at least in part) the decrease in the rate of increase to SO2 from Chinese power plants. Gavin has a paper attributing it to increased volcanism. I’d love to hear these two sources of GHG masking compared/contrasted.
Chris Dudley, thank you very much. Those sounds like good leads. We will contact them as soon as we have fixed our ideas how such a reference network should look like a bit more.
Ray Ladbury says:
27 Jan 2015 at 4:39 PM
Alan Millar,
“What have you got against physics?”
Nothing. I think we are in a warming trend and CO2 is the cause. However, i don’t believe that the Earth has a positive feedback to this if there is any feedback it is far more likely to be negative based on the long term stability of the Earth’s climate.
I rely on the physics, which indicate only a moderate rate of warming in the absence of positive feedbacks. The ‘Model’ I posted just indicates where I believe the climate is going. The temperature trend of the 20th century is well bounded within my projections. Also it seems to be on track this century as well, unlike the GCMs which are off and getting farther away from observations as time goes by.
I am confident that my ‘projection’ will be closer to reality come 2030, compared to the GCMs. The negative PDO, the solar cycle and the AMO going negative in the next ten years or so is unlikely to be going to be helping their cause.
Alan
Re- Comment by Victor — 27 Jan 2015 @ 3:43 PM, ~#134
Victor, previously you claimed that there has been a 15 to 18 year period where warming “vanished.” Now, like a good troll, you are shifting the goalposts to “a slower rate” of warming. I ask again, for the third time, please explain where this is in the first two graphs here:
https://www.realclimate.org/index.php/archives/2013/09/the-new-ipcc-climate-report/ – more-15766
Steve
134 Victor quoted: “There seem to have been a dozen or so explanations for why the Earth’s surface has warmed at a slower rate over the past 15 years compared to earlier decades.” – See more at: https://www.realclimate.org/index.php/archives/2015/01/thoughts-on-2014-and-ongoing-temperature-trends/comment-page-3/#comment-624199 ”
If you look at:
http://www.woodfortrees.org/plot/uah/from:1980/to:2015/plot/uah/from:1980/to:1997/trend/plot/uah/from:1998/to:2015/trend/plot/uah/from:1980/to:2015/trend
you will observe that the trend since 1998 is not much different than the trend for the 17 years that ended in 1997.
0.02C?! Some care about it more that others. My pears are blooming (70 days early) but the bees are not ready to pollinate.
The daffodils started blooming about Christmas. In John Muir’s day, this species bloomed in late February.
Oh, well, not sure there enough moisture in the soil for a crop of pears anyway.
The only real measure of temperature is how it affects important crops that you like to eat.
for John E. Pearson: LMGTFY, using the search box at the top of the page:
Recent global warming trends: significant or paused or what?
#140 Well, Steve, from the uppermost graph, looks very much like ca. 1998. If that bothers you because of El Nino, then skip a couple years to 2002. The graph just beneath it is a perfect example of what I’ve been writing about, lo these many weeks: fudging the statistics to conveniently erase inconvenient evidence. Magician’s call it “misdirection.” Hey, why not use a 30 year average? That way all you’d have is a sudden leap, with no “trend” at all.
As far as “vanished” vs. “slower rate” is concerned, by “vanished” I meant no significant increase. Yes, technically there’s been a minuscule degree of warming, but it’s been insignificant. Since a plateau was reached, then obviously, even the slightest amount of warming is going to produce a “record year.” I thought Gavin explained that.
Meanwhile, no one has yet responded to my discourse on “Ocean heat content.” (see #104)
Alan Millar @139.
The fluctuations in glonal temperatures over the last few ice ages and over past eons are impossible to understand if teedback to climate forcing is negative. That is one of the reasons why the UN IPCC say an ECS less than 1°C is extremely unlikely (high confidence). That is IPCC-speak for “impossible.”
You are at liberty to play fantasy-climate but climatology is science-based; it is not entertainment.
Victor the Troll @134.
If you seek scientific statements demonstrating a 15 year hiatus of your chosen form, do say when you’ve achieved it. @134 you are still quoting journalists and also scientists addressing the media, not all of whom say what you wanted them to say.
If this hiatus of yours is established science, climatologists will be debating it within scientific papers. At best, all I see you presenting here (and I honestly couldn’t be fagged to give more than a very cursory look) is the odd scientist responding to the myth of a hiatus spread by people like you, responding by saying it isn’t the hiatus you say it is.
It’s sad that the contrarians are fixated on starting their so-called hiatus at 1998 (or sometimes 1997). They should try starting at 1999 and see what the trend looks like. If it’s markedly different from the trend starting at 1998, then they should declare a trend change and become fixated on that.
#49: “how could such a warming trend possibly be due to anything other than AGW given the overwhelming odds against any other possible explanation? Is that really a position any real scientist would be willing to endorse?”
That would not be sufficient to just “endorse” some “alternative” explanation. One would also have to explain the established mechanism away, i.e. the completeley rocksolid and settled physics of radiative forcing by greenhouse gasses first hand, and the known feedback effects. Which (surprise, surprise) well explain the warming of the last century.
What the denialosphere completely lacks is some concept that is even remotely similar to a scientific theory. All what they do is “pointing out” issues, some real ones and many fake ones, and always blown up ones
All the best,
Marcus
Alan, we know with 100% certainty that there are positive feedbacks as well as negative feedbacks. We also know that there must be positive feedbacks in order for Earth to be at its current temperature–you wouldn’t get 33 degrees of warming from just the intrinsic radiative properties of the greenhouse gasses. You cannot be ignorant of this. Feedbacks do not necessarily destabilize the climate. Infinite series converge.
@troll comment 144: “Well, Steve, from the uppermost graph, looks very much like ca. 1998. If that bothers you because of El Nino, then skip a couple years to 2002.”
Translation: If cherrypicking by starting at one local max bothers you, well just start cherrypicking at the next local max and you’ll see the same effect!!! Wow! You actually say that with a straight face?
Victor. You are sinking into ridiculousness.