What do you need to know about climate in order to be in the best position to adapt to future change? This question was discussed in a European workshop on Copernicus climate services during a heatwave in Barcelona, Spain (June 12-14).
The answer is not clear-cut, even after having some information about user requirements from a survey to identify a direction for data evaluation for climate models (DECM). The survey is still being carried out.
Some of the key issues concerning user requirements include essential climate variables (ECVs), climate data storage (CDS), evaluation and quality control (EQC), and fitness for purpose (F4P). I include their acronyms here since they often appear in reports and discussions and their meaning is not always obvious.
The ghost that keeps coming back is “uncertainty”. The data give an incomplete description of the world, and include some inaccuracies. How significant are these, and how closely do they represent the aspects which they are meant to describe?
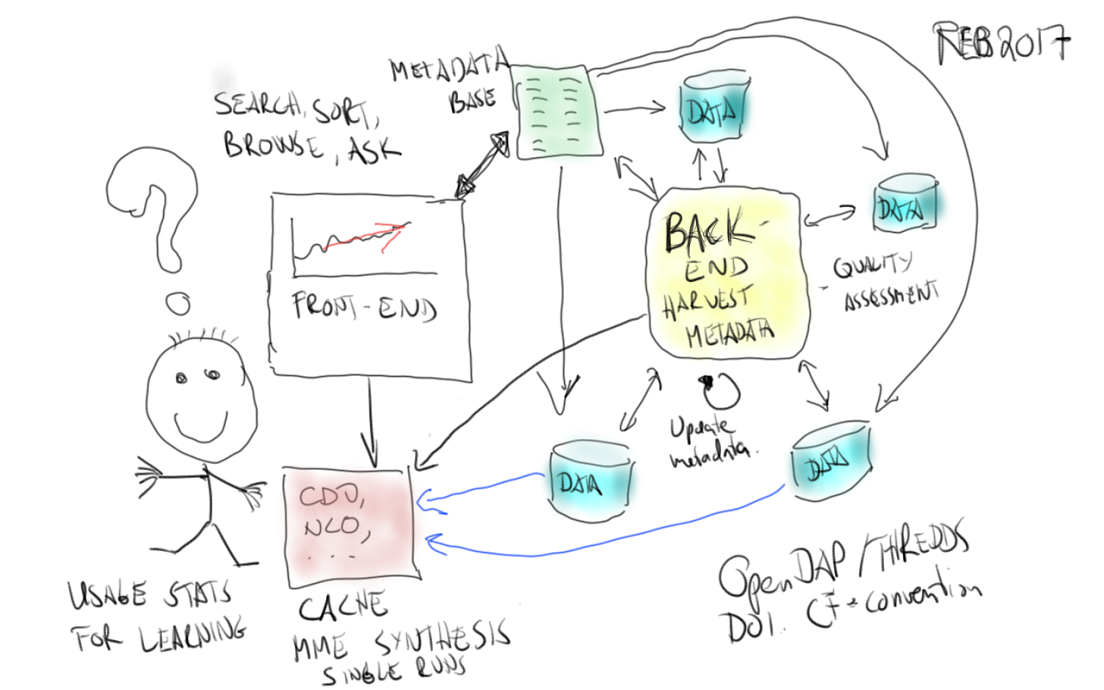
The Copernicus climate services will be able to provide a lot of data and information, which includes observations of past climate, seasonal forecasts, and projections for the future. It will provide both global and regional/local data in addition to metadata and information about their quality.
There will also be a set of tools to search, sort, visualise, process and access the data. Exactly what the tool will look like is still not determined, although it is likely to be partly based on some tools which already exist.
For future climate change, the climate data store will provide a large number of simulations derived with different climate models.
Users, however, often do not want a large number of model simulations, but results from a “best” model. This requirement is problematic, and the question how to solve this took up some of the time (as it often does).
In my opinion, we need to emphasize the information that can be distilled from the data. Information should be distinguish from data, and there are statistical methods that can find the most robust information in large data sets. Furthermore, the information is often more robust if it is drawn from multiple and independent sources.
It is important to understand that one simulations cannot give a reliable indication of the future state on a regional scale because the future outcome is subject to pronounced natural variations. This would be true even if the climate model gave a perfect representation of the climate system. The reason is that it is impossible to predict the exact course of such natural variations due to their chaotic nature.
We can nevertheless estimate statistics describing the range of likely future outcomes. Large ensembles of climate simulations may serve as a basis for estimating their statistical characteristics. The ensembles are not perfect, but do nevertheless give a reasonable indication.
Another question is whether it is feasible with a general framework for describing the quality of the wide range of data types such as observations, seasonal forecasts, and projections. In many cases, the question is context dependent. The accuracy of satellite data and the realism of model results are two different examples.
Transparency, openness, and provenance (the history of data processing) will ensure that the data can be trusted, and a unique digital object identifier (DOI) will make the replication of results easier. It is essential that people know exactly what the data really represent, their limitations, and how to interpret them. There are many instances where data have been misinterpreted.
If you have some experience with using climate data and requirements concerning climate data, I’m sure the people who carry out the survey would like to know.
I do not like the emphasis on climate adaption. Adaption strategies take the focus from the struggle for necessary political steps to avoid AGW. The most extreme suggestions in this respect is of course Stephen Hawking’s complete retreat to an other planet! It is sad that we have lost him as an allied to abate AGW on earth.
AWG is not inevitable, it is a choice. The humanity can choose if it wants to stabilize the CO2 concentration on 450 ppm or something else. It is easy to make these choices, therefor we should all join forces to change the direction. The Paris agreement was one step, but it need to be reinforced (stronger cuts, pledges) and enforced (a regulatory framework for how to make the pledges committing will eventually be needed).
I do not say that this site is a deliberate diversion. It also important to study the consequences of climate warming and to disseminate the knowledge, but I do not like the adaption idea of Copernicus C3S. Mitigation is mentioned on the site, but here it is to mitigate the consequences for the citizens from climate-related hazards rather than mitigate to the AGW.
You mention uncertainty and it is of course very difficult to predict what consequences a given CO2 concentration will have. The largest uncertainty is, however, not in the uncertainty in the physics and biology. At the present, the largest uncertainty is what common choice we are going to make limiting the AGW itself.
[Response:The climate is changing as we speak, and there is more in the pipeline, even if we cut the emissions today. Therefore, we also need to adapt. This does not imply that we should give up mitigation – it is crucial that the greenhouse gas emissions are curbed in order to limit the future global warming and accompanied climate change. THe greater the change, the more costly will the adaptions be. -rasmus]
This is a skeptical article. Watch out, go to far and you will be branded a denier.
[Response: No, your perception is misunderstood. It is exactly because of anthropogenic climate change Europe sees a need to prepare climate information for the use of climate change adaptation. This happens in parallel with mitigation and curbing the emissions of greenhouse gases. Both are necessary because the climate is currently changing and will continue to change in the future with the old emissions in the pipeline, even if the emissions were to be cut today. -rasmus]
Re 1: I have to somewhat disagree with you here. Adaptation is going to be necessary, at the very least for those who currently live in marginal climates, where even a small perturbation to their local climate can render their current way of life unfeasible. It is one thing saying in theory that if everyone can choose to take action to stabilise CO2, but the reality is that most people aren’t, and are constantly choosing not too, and this is after 50 years of promotion of AGW and its potential threat to humanity. People in the pampered West aren’t en-mass going to give up driving, flying abroad on holidays, using supermarkets instead of growing their own food, living in bigger houses than they need, eating meat, buying lots of plastic/metal tat that gets thrown out after six months. The reason being is that giving up these things results in at least, a perceived decrease in quality of life, but without any perceived benefit (since AGW is an invisible enemy). You also have a couple of billion in China and India that are aspiring towards Western standards of living, and the consumption and consequences that go with this. What we have to deal with is reality, not the utopian ideal of everyone doing what is necessary or desirable. Until there is evidence, beyond a few localised projects and political greenwash, that large scale efforts towards sustainability and bringing carbon footprint right down are happening, I can only conclude that we have to assume the most likely outcome is 2+ degrees of warming, estimate the best estimate of the global and regional effects of this, and how to assist those who will get whacked with the consequences.
Adam,
I would have to agree with you, and adaption is not unique to today’s changes. People have had to adapt for ages, due to changing climates. I also agree that people will not willingly decrease their quality of life in order to reduce CO2 emissions. Hence, adaption will be a real solution.
Re 4 Adam Lea:
Adam talk much sense.
There are already quite enough problems with a mis-match between population density and natural resource availability/usage especially water. Witness the middle-East and North Africa.
There is a desperate need for a wide range of plant growth/soil response models (land use suitability)partly on the macro-scale but specifically on the micro-scale. Any attempt to thing about plant/crop suitability under rapid change is to be welcomed -forget the petty politics.
Based on the presently accepted data there is every reason to believe the unavoidable effects of climate change as of now will be more of a patchwork with a great deal of variation. This will affect the viable distribution of the bulk of the widely used food crops – not a big range of plant species at best anyway. Agri-scientists need a steer as to where to focus on seed stocks.
Aaron Thierry, really summed it up …
https://www.youtube.com/watch?v=r7TL_BbAd-s
T 5: Having a central committee of sorts decide which model the rest of us should accept reinforces my belief that climate change has morphed from a scientific debate to an unyielding religion in which anyone who doesn’t worship precisely as ordered is deemed a heretic and symbolically burned at the stake.
BPL: But aside from that, Mrs. Lincoln, how did you like the play?
[Response: The comment about having a central committee has been deleted because it was way off-topic and based on unjustified allegations. There is no a central committee, and any claim of such is based on delusions. We do not want the discussions here to derail or be hijacked by trolls. -rasmus]
#1. Erik Lindeburg: “AWG is not inevitable, it is a choice.”
Some commenters gratuitously assail others and it’s not always obvious to me why. So, while I can see where Erik is coming from, I do not actually know exactly what he means.
AGW may or may not be inevitable, but it is not a choice. It is an outcome. Individuals may or may not have choices, but to be able to make choices for other individuals you need a bloody great army.
In my opinion, after listening to the people I meet, nothing much will happen until there is something people will talk about. An event that frightens them. Like a sea level rise of 250mm/10inches in 20 years. That will happen, and it might happen in the next 20. I suspect most deniers would survive that with their crankery intact. A B C D, Anything But Carbon Dioxide Amen.
So. It looks to me alleviation is inevitable.
I am exercising regularly and keeping my weight down. Puffing insulation into the atmosphere is the grandest experiment I have ever been involved in and I want to be around to see the results.
@Tom
Interesting that you say you don’t have all the answers yet you seem sure the answer to the question of climate science results is that they are some sort of religious dogma and propose that there is a “debate”. Be specific: What particular issues do you see as up for debate at the present time? Spectroscopy? The greenhouse effect? Equilibrium and transient sensitivity? The specific rate of temperature increase? Rate of ice decline? What will happen weatherwise in Eastern Oregon on June 20th of 2053?
Was Linus Pauling “burned at the stake” or largely–and correctly–ignored scientifically when he decided there was a “debate” that vitamin C could cure terminal cancer but could produce no acceptable evidence of the effect?
It gets tiresome reading entries everywhere in which obvious nonscientists lecture about the scientific method and philosophy of science at a high school/freshmen level to practicing professionals. Oh…and there is no “central committee”. There are other competing jealous/competitive/cooperative/mean spirited/high minded/hateful/loving/interested in building up/interested in tearing down colleagues who “debate” all the time every day. Such is the wonder of the Enlightenment. It’s been a fragile wonder that has barely survived many assaults. We’ll see if it can survive the present assault. I must admit I have some doubts.
Thanks. There’s enough time wasted as is.
Jgnfld @10, I agree very strongly on all points.
Except maybe its fair to call the IPCC a sort of central committee. I would meet that attempted sceptical slur, or attempted put down head on, and not get too defensive or bogged down in precise definitions.
The IPCC reviews the science to see what it all adds up to, and committees review things. And there’s nothing wrong with committees of course, because committee processes have their place.
Sceptics need to think harder about why we need the IPCC, whether you call it a committee, or whatever. Given and we cannot put the entire planet in the laboratory, and do a couple of nice, neat little experiments,we are reliant on a huge volume of other evidence and evaluating what it all means. We have over 10,000 papers on climate change, a huge volume of multi faceted evidence to integrate together. This is beyond one person, and so it can only be reviewed by a team of people. Even just evaluating basic attribution and causes of climate change is challenging for just one person.
We are very reliant on collective knowledge and and team analysis. This is simply the reality we have to accept, even if its not ideal. There’s no alternative.
One other thing. Whenever I listen to climate doubters I observe the same mix of views. You get the usual sceptical myths, then a lot of political nonsense about big government, climate scams, people in it for the money etc. Its like humanity is two separate species, or sub species, with entirely different modes of thought.
[Response:This type of climate data store (climate services) is not connected to the IPCC (which does not do research nor operational monitoring of the planet. The research, by the way, is coordinated through the World Climate Research Programme – WCRP), but there is already some type of centralisation through the world meteorological organisation (wmo.int). All world weather services have been connnected to WMO for decades, as far as I know (Climate is weather statistics). The Copernicus effort is also connected to the European Space Agency (ESA, which is similar to NASA. Much of the observations are retrieved through satellites) and now the European Centre for Medium-range Weather Forecasts (ecmwf.int) will play a role in hosting Copernicus. Copernicus will also provide data from outside Europe, and there are many partners behind such partners. People are of course also free to get (the same) data from other sites. -rasmus]
. THe greater the change, the more costly will the adaptions be. -rasmus]
One way to accelerate adaption is to mitigate the animosity towards it those campaigning for carbon reduction all too often display:
Learning to reduce the impact of the first degree of AGW on water, agriculture, and urban climate is a necessary step towards coping with the second degree as it evolves.
rasmus, inline to #1:
Has it been pointed out yet that adaptation to AGW means the loss of homes, livelihoods and lives for millions? Dan H. appears to think that’s a “real solution”.
#9 Dennis N Horne
“AGW may or may not be inevitable, but it is not a choice. It is an outcome. Individuals may or may not have choices, but to be able to make choices for other individuals you need a bloody great army.”
The humanity can make collective choices on how the future will be, but I never suggested to use an army to make choices for other people. The collective choices can only be executed through the political system nationally and internationally. Any changes in climate polices will be a reflection on how strong the understanding of the AWG is among the population. How effectively the will of a majority in the population will result into political action varies between various system, but my belief is that the most effective action is best taken in democratic processes. To impose a climate policy that is not based on a majority opinion will only give short-sighted progress and will eventually backfire. To convince a majority may seem to be a long and tedious effort, but in my opinion still the most effective and the only method most of us have to hand. I do have a strong belief the creative force of the humanity.
For me the study of climate science is only to satisfy my scientific curiosity, but to prepare me better to disseminate scientific result among people I meet in daily life and through media. A guess also the discussions on this site is a part of this process.
To the people who imagine a central committee, it’s as if climate science was indistinguishable from magic. They can’t seem to figure out that cameras don’t steal your soul, no airplane is going to descend from the sky and disgorge any more of that wonderful cargo, and there’s no central committee enforcing orthodoxy in climate science, no matter how many times someone tells them.
France President Mr. Emmanuel Macron “Make Earth Great Again” and German Chancellor Angela Merkel ” Our Mother Earth”, both are great.
Our earth facing the end day between 2019-2030, to realize the great ambitions, a great action of saving the earth must to activate now.
Speak plus Action: A Great Earth. Speak not Action: A Great Disasters.
President of United States Mr. Trump made a right decision to pull out the Paris Agreement 2015, it is true because cut emission of greenhouse gas do not curbing the climate change, however,he did not promised that he has a way to resolve the problem of emission.
15. Eric, I don’t misunderstand what you are saying. You are saying that we have a choice and chose WWI, WWII, Korea, Vietnam, Iraq, Afghanistan … just to name the wars that affected my life.
Despite my best efforts, I have not changed the mind of one single climate science denier. Sadly, the more qualified in science they are, the more intractable they become. They were “got at” first by the liar-denier brigade, who fought a well funded and organised campaign. They are not going to change their minds. *Ever.
Can we afford to wait for them to die?
* https://www.pundit.co.nz/content/understanding-truthiness
Eric Linderberg @15, yes I agree the whole climate issue should be democratically handled. Forcing something on people is dangerous philosophical and highly authoritarian territory, possibly ending up as damaging or worse than the climate problem. (Although when I listen to dopey sceptical arguments it sure is tempting).
But if you look at decent quality polls like Pew Research The “majority” in many countries and even America do accept the science, and also want more action to reduce emissions.The thing standing in the way is politicians and lobby groups, and the incestuous relationships, and campaign funding.
Russell:
I agree with your second sentence, but how does it follow the colon after your first one?
Tegiri nanashi, Russell, sometimes I try to score too many rhetorical points in a single comment too 8^).
The claim that cutting emissions of greenhouse gases would not curb climate change is not true.
Please read more about this and when you post what you believe, tell us where you did read what you believe.
There are good sources, and there are other sources.
What you read makes a difference.
Some things just can’t be faked. That’s a beautiful meta-chart on usefulness, helpfulness, and learning. Drawn like a true data specialist.
19 nigelj says: “Forcing something on people is dangerous philosophical and highly authoritarian territory”
It’s all a matter of degrees. The above phrasing is SOP for every Government on the planet, including democratically elected ones. Joining the Paris agreement treaty is as authoritarian as leaving it. Both choices denotes “forcing something on people” who want the opposite. No less authoritarian than forcing people to wear seat belts or they will be fined by the State.
iow in regard to AGW/CC, decrying “highly authoritarian territory” as being dangerous is an invalid reason/excuse for both proponents of such fallacies and governments not acting rationally and not applying the full weight of their Authoritarian Powers afforded them by their Constitutions and the collective United Nations powers at their finger tips.
Nation states not acting or not fully acting in line with the known evidence is a choice they make consciously. That too is dangerous. And given the known evidence it’s also deadly dangerous for the unlucky.
19 nigelj, addendum. This issue is a good analogy to consider re govt binds surrounding “authoritarian territory” and democratic choice. Especially when it is a minority govt and a nation split 50/50 on most core issues immediately post a “democratic” election. Eye of the beholder and all that.
http://ukpollingreport.co.uk/blog/archives/9921
Another impressive meta-chart suggests climate communicators are better at scaring collectives than persuading individuals:
https://vvattsupwiththat.blogspot.com/2017/06/but-on-reflection.html
Thomas @23 @ 24
“Joining the Paris agreement treaty is as authoritarian as leaving it.”
I don’t see how you possibly conclude that. The vast majority of people in my country think we have a climate problem, and that we should be part of Paris, so we are not being forced collectively by government to be part of it against the wishes of the majority.That is clearly the point I was making, and also the other guy I was responding to. Again the majority support seat belts as well.
I would agree you can I suppose argue its still authoritarian to force decisions on the dissenting minority, but that is the price we pay for democratic government and the rule of law. ALL laws are forced on some people who might disagree. Its not possible to avoid this unless you promote total anarchy. Do you promote total anarchy?
Yeah I get the rest. Very fair point.
It’s a fine line.
Adhering to “Paris” is democracy, leaving is tyranny of the masses.
Ask Lee Kwan Yew.
Very good post by Thomas at #23. I agree.
Nigelj #26,
“all laws are forced on some people who might disagree”
Yes, exactly, otherwise we wouldn’t need the law in the first place. Laws, by definition, are coercive.
There is this bizarre conceptualization on both Left and Right that “government” is some entity existing outside of the interactions of the citizens governed– kind of like God, I guess.
If you don’t like “the government”, revolt. But understand that then you will be “the government”.
#28 BPL, TY, much appreciated.
#26 “Do you promote total anarchy?” No.
“Law” has it’s home in a nation’s Constitution with powers afforded the Govt that often (no always) overrides the majority view/opinions aka tyranny of the majority. eg citizen rights, property rights, UN human rights and all the other international treaties entered into by prior Govts. Govts are required to implement legal powers to decisions of a nations highest Court as well. Best example is US federal govt overriding State based powers and their denial of “civil rights” in the 60s. Some claimed this was an affront to state rights and individual freedom and liberty.
I say “tough”. The same goes with national Govt’s international joint actions regarding agw/cc. :-)
This is, imo, why Hansen and M Mann are putting so much effort into their Court cases, Our children’s Trust and Defamation by denier activists. This is in fact rep democracy in action – people for forget it’s not about popular opinion, polling results, nor majority voting for Party X.
If Children;’s TRust wins the Govt will have Court Ordered mandates to implement no matter who wins the elections. See? That is Democracy too.
Govts don’t only have mandates from the electorate they have ever present legal Responsibilities to abide by the Laws of the land and to act in the national interest and for the common good (even when the commoners do not know what is good for them.) See? That UK polling article really shows how complex and nebulous “public opinion” is and why it that does not equal “the democratic will of the people” (which doesn’t exist to the degree we think it does or the biased media and special interests would like us to believe it does.)
#27, yes. A very fine line.
Zebra @29
“Laws, by definition, are coercive.”
Yes, and so we are stuck with this, because the alternatives are even worse, anarchy. Laws are therefore not inherently wrong even if they are coercive to some extent.
It becomes “purely” a question of what laws do we have and how do we decide? Hopefully on a logical and evidence based basis, and avoiding petty laws and concentrating on things like health and safety. But that’s just my opinion.
However it most certainly means there is logical and proper justification for environmental laws!
And it’s a similar issue with taxes. Nobody particularly likes taxes and there is the crude but thought provoking taxation is theft argument. But nobody has a better way of funding government that is workable. The alternatives are worse, so its absurd to get stuck claiming taxes are theft, because they are lawfully collected. Its really a case of analysing what level of taxation is optimal, that provides sufficient income and doesn’t become a disincentive, and only careful research can define that.
Thomas @30, yes I accept you do have a point. Governments or courts sometimes do things not always accepted by the majority, and you and I would say these things sometimes seem right anyway. I gather that’s what you are saying?
I would just say that the more that governments or courts push unpopular views (ie, not supported by the majority), or are just generally coercive or pushy, the more trouble they are likely to be in, and it can lead to chaos and undermine trust in government. Remember we put them there to do our bidding, not to ignore us and listen to a small minority.
Trump is acting unilaterally and against majority views, and I’m not too impressed.
Of course it depends on another thing. Governments may be elected on a majority mandate, so can claim this gives them permission to implement laws that the majority may not want, which may have been in their manifesto, and I can agree to this to a point, but I suggest there is a limit to that process, before things go very bad, and you have a form of elected dictatorship. This obviously happens if they start passing laws that were not in their election manifestos, and The Trump administration may be in danger of this. But all political parties are at risk of this.
And remember while some unpopular views may be correct, many are not. In fact, populism has a very good side to it. I just think governments need to minimise making unilateral, brutal or unpopular sorts of decisions, yet I can understand that sometimes these things must be done for the good of society as a whole.
Switzerland tries to get around the dilemma by holding binding public referendums, which is an idea I quite like. I think this is workable and appropriate for big social issues but you cant do it for everything obviously and its harder in respect of economic issues, because people often just don’t understand the issues.
There is also the problem of the tyranny of the majority towards the minority. This is the big downside of democracy, and we are actually purely reliant on humanity having enough compassion to act responsibly, and not oppressing or taking advantage of minority groups.
He is a simpler explanation:
Climate 101
1. It’s warming
2. It’s us
3. We’re sure
4. It’s bad
Dan Miller says:
24 Jun 2017 at 3:53 PM
He is a simpler explanation:
Climate 101
1. It’s warming
2. It’s us
3. We’re sure
4. It’s bad
Ok. I have a scientific, even simpler explanation.
The earth surface temperature is equal to the absorbed solar irradiation which is received by the disc, pi*r^2, distributed over the hemisphere 2pi*r^2, absorbed in a volume of a sphere 4/3pi*r^3(atmosphere), absorbed in another volume 4/3pi*r^3(solid earth):
1/2(1361/(4/3)^2)=383W/m^2, 286.7K
The effective temperature emission observed by space is found through heat transfer(radiative) and the inverse square law:
(1361-383)/4=244W/m^2, 256K
The tropopause temp is found via gravity:
4/3*g^2
Which can be used in a formulation of gauss law of gravity:
1361/(4/3)=(383+128)-4g^2-(4/3)g^2
I guess you missed the fact that gravity is a force that needs a source power, which happens to be equal to surface temperature:
4g^2
In gauss law of gravity you use surface flux instead of a point force in the center of mass. By the way, this model works to find surface temperature on mars and venus as well. Venus is kind of a trophy in this discussion, since the greenhouse theory failed to show any calculations in that case.
[edit – you are free to post nonsense until it gets boring, but leave out the name-calling and pseudo-macho posturing]
zebra:
Upfront disclaimer: if I’m so smart, why aren’t I rich? I can’t claim it’s only because I’m righteous, but I have my idiosyncratic standards; let’s leave it at that 8^|.
Moving on: IMHO z’s ‘bizarre conceptualization’ is nevertheless accurate, depending on the details of ‘interactions’ and ‘citizens governed’.
For example: in recent years, annual profits to the fossil fuel industry were around $100G; about as much as the total wealth Charles Koch and his brother David currently control between them. The brothers Koch are today among the world’s richest men, while I OTOH am not. I for one am skeptical a hypothetical God intervened in this state of affairs. Again IMHO, it’s largely due to the ‘freedom’, afforded to generations of the Koch family and a few others by the US government and the ‘free’ global energy market, to privatize the benefits of the energy in fossil carbon while socializing the climate-change costs.
Regardless, wealth on that scale is empowering, as RC regulars and other sadder but wiser adults know; and as Charles Koch, a shrewd businessman himself, most assuredly does. In a 2012 interview with Forbes.com (“The Capitalists’ Tool”), he cautiously discussed his and his fellow fossil-fuel billionaires’ strategy for using their wealth to reshape the American republic to their liking:
Heh. He would say that, wouldn’t he? In any case, the anarcho-capitalists’ investment strategy is evidently working: only a generation ago, even $1G of personal wealth was “beyond the dreams of avarice”, and US voters still widely deplore the influence of money in politics as a national disgrace! So much that they keep voting, through their legislators, to make buying elections illegal, while bare pluralities of SCOTUS justices keep making it legal again.
Although he’s kept the law on his side so far, Charles Koch is still sensitive to public opinion. From the Forbes interview again:
Well, yes. Innate or otherwise, Charles Koch’s willingness to be quoted as above in 2012 is more evidence for the success of his family’s long-term investment strategy. Now, virtually open-ended political donations may legally be made by close-mouthed bagmen, while global mean surface temperature rises by 0.2 degrees per decade and fossil-fuel profits flow from a ‘free market’, untroubled by collective intervention to mitigate a Tragedy of the global climate Commons. Any questions?
K-Street has a new terminator on the block, to make sure your climate questions go officially unanswered:
https://vvattsupwiththat.blogspot.com/2017/06/they-dont-make-terminators-like-they.html
Afb 34,
Your explanation is pretty much just playing with numbers. Gravity does not need a power source, certainly not from temperature; it is a warping of space directly proportionate to the amount of mass involved, cold or hot. There are multiple physical processes you fail to account for in your calculations; you are simply indulging numerical coincidences. My advice would be to study an introductory text on physical climatology and/or planetary astronomy. For the former, Dennis Hartmann’s “Global Physical Climatology” is a good one. For the latter, try William K. Hartmann’s “Moons and Planets.” BTW, scientists have had good greenhouse models of the Venus atmosphere since the 1960s.
Jeff Harvey:
As someone who pursued a childhood fascination with ‘natural history’ through two years in a Ph.D. program in Ecology and Evolution, I’m receptive to Jeff’s message. The problem, not only with some commenters here but with a dismaying large fraction of my countrymen, is an abysmal ignorance of and indifference to all natural phenomena not obviously related to human welfare. I’m sure Jeff, at least, is acquainted with Aldo Leopold’s remark in “Round River”:
One of the penalties of an ecological education is that one lives alone in a world of wounds. Much of the damage inflicted on land is quite invisible to laymen. An ecologist must either harden his shell and make believe that the consequences of science are none of his business, or he must be the doctor who sees the marks of death in a community that believes itself well and does not want to be told otherwise.
FWIW, I attest the truth of Leopold’s lament.
Please make this statement of editorial policy a top-of-the-page banner.
It might help people understand what they see in the comments here.
It seems that some of the solar irradiance figures rejected from Willie Soon’s last published article have resurfaced at WUWT:
https://vvattsupwiththat.blogspot.com/2017/06/tell-damn-reviewers-it-will-make.html
” humans depend on nature in a myriad of ways for our survival.”
Journalists not so much:
https://vvattsupwiththat.blogspot.com/2017/06/the-school-of-journalism-at-end-of.html