There is a clever mathematical trick for comparing different data sets, but it does not seem to be widely used. It is based on so-called empirical orthogonal functions (EOFs), which Edward Lorenz described in a Massachusetts Institute of Technology (MIT) scientific report from 1956. The EOFs are similar to principal component analysis (PCA). The EOFs and PCAs provide patterns of spatio-temporal covariance structure. Usually these techniques are applied to datasets with many parallel variables to show coherent patterns of variability. Myles Allen used to lecture on EOFs at Oxford University about twenty years ago and convinced me about their value. Many scientists do indeed use EOFs to analyse their data. It is not that there is little use of EOFs (they are widely used), but the question is how the EOFs are used and how the results are interpreted. I learned that EOFs can be used in many different ways from Doug Nychka, when I visited University Corporation for Atmospheric Research (UCAR) in 2011. The clever trick is to apply these techniques to data compiled from more than one source of data. When used this way, the technique is labelled “common EOFs” or “common PCA”. There are some scientific studies that have made use of common EOFs or common PCA, such as Flurry (1988), Barnett (1999), Sengupta & Boyle (1993), Benestad (2001), and Gilett et al (2002). Nevertheless, a Scholar Google recent search with “common EOFs” only gave 101 hits (2020-03-05). I find this low interest for this technique a bit puzzling, since it in many ways has lots in common to machine learning and artificial intelligence (AI), both which are hot topics these days. Common EOFs are also particularly useful for quantifying local effects of global warming through a process known as empirical-statistical downscaling (ESD). It's pity that common EOFs aren't even mentioned in the recent textbook on ESD by Maraun and Widmann (2019) (they are discussed in Benestad et al. (2008)).
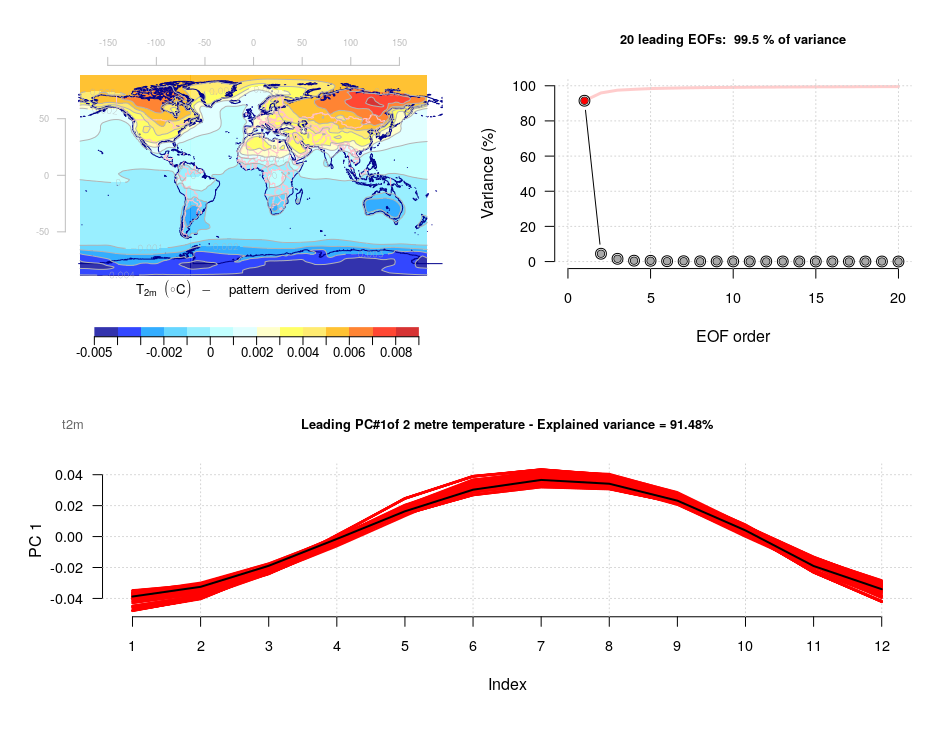
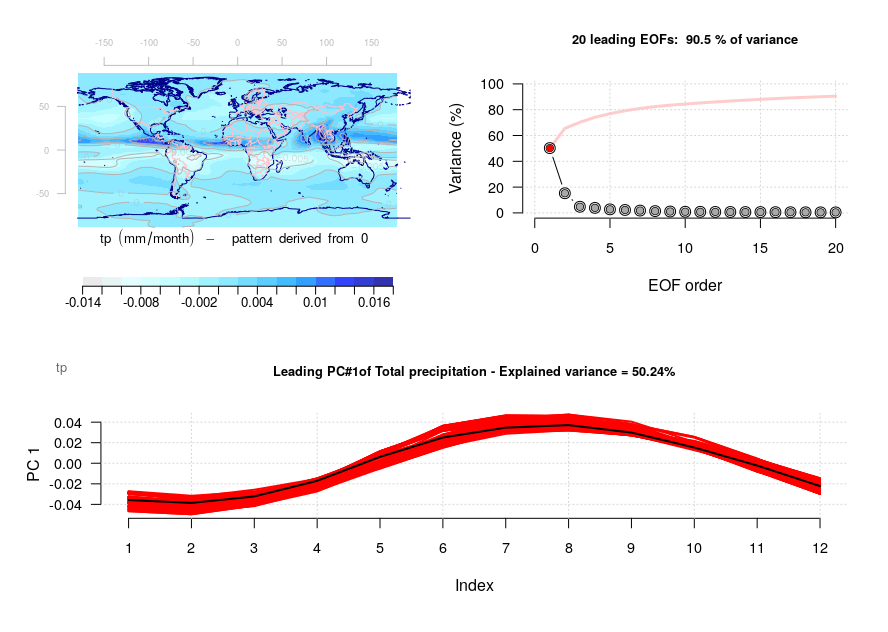
Figure. Examples showing how common EOFs can be used to compare the annual cycle in T(2m) in the upper set of panels and precipitation (lower panels) simulated by global climate models from the CMIP5 experiment (red) and compared with the ERAINT reanalysis (black).
The take-home message from these common EOFs, eigenvalues and principal components, is that the models do reproduce the large-scale patterns in the mean annual cycle. For those interested, common EOFs can easily be calculated with the R-based tool:
github.com/metno/esd.
References
- R.E. Benestad, "A comparison between two empirical downscaling strategies", International Journal of Climatology, vol. 21, pp. 1645-1668, 2001. http://dx.doi.org/10.1002/joc.703
- N.P. Gillett, F.W. Zwiers, A.J. Weaver, G.C. Hegerl, M.R. Allen, and P.A. Stott, "Detecting anthropogenic influence with a multi‐model ensemble", Geophysical Research Letters, vol. 29, 2002. http://dx.doi.org/10.1029/2002GL015836
Please, please Rasmus do not use the word “trick” in any of your climate science publications or other presentations. Anyone with any intelligence and appreciation of the truth can understand how you are using the term, but the entire denier complex will immediately leap on the term to label you a fraud and a liar and spread their contentions through their vast network of deception.
EOFs are also covered in:
D.M.Glover, W.J.Jenkins, S.C.Doney, Modeling Methods For Marine Science, Cambridge, 2011
D.S.Wilks, Statistical Methods in the Atmospheric Sciences, 3rd edition, Academic Press, 2011.
H. von Storch, F. W. Zwiers, Statistical Analysis in Climate Research, Cambridge, 1999.
They were also the key device used by Professor Michael Mann and colleagues in their tree rings work from some time ago that was so criticized by climate deniers. I found when engaging with them that they did not understand EOF methods or, actually, Singular Value Decomposition (SVDs) and confounded their use with literal-minded quotations from the Jollife presentations on PCA.
Thanks. Nice references. I think it’s true that they did not understand PCA, which I have explained in ‘Learning from mistakes in climate research‘.
I second what Ken D stated @1.
#4 Even if they know very well what is meant by the use of “trick” they will still use it to attack the veracity of the paper or the author.
Jan Galkowski and rasmus,
You both say that Michael Mann and colleagues did not understand certain math techniques. As a non scientist- I’m curious what the implication is of their failure to understand those techniques.
I think you interpreted my response wrongly – it’s the contrarians who don’t seem to understand these techniques, something that I also pointed out in ‘Learning from mistakes in climate research‘ in the case of McKitrick and McIntyre (which proppted a response from McKitrick where he tried to censor parts of our paper rather than trying to defend his position in a more traditional response – link to letter).
#6, JZ–
Neither rasmus nor Jan said that. The “them” in Jan’s comment pretty clearly refers to the deniers, not Dr. Mann. And rasmus doesn’t mention Dr. Mann at all.
If the denizens of the skeptiverse leap on the use of the word ‘trick’ here, let them point all and sundry to this post, and all but the wilfully blind will see what fools they are.
I’m sure you had that history in mind as you were titling, Rasmus. Nice one.
Joseph Zorzin #6, neither Rasmus nor Jan said Michael Mann and colleagues did not understand certain math techniques. They point out those who criticized Mann et al often did not understand these techniques.
I can see how this could be misunderstood from Jan’s comment, but Rasmus’ paper is a bit more clear on that.
Joseph Zorzin #6
Perhaps a misunderstanding of who exactly the pronoun “they” is referring to? :-) Also, I suspect Rasmus is being mischievous – amusingly so in my opinion – in using the much-weaponised term “trick”.
“I’m curious what the implication is of their failure to understand those techniques.”
According to the North Report, very little of consequence. According to subsequent research using independent, possibly “better”, methods, very little of consequence as well.
OK, everyone,thanks for responding to my dumb question- dumb because I didn’t read the article and other comments carefully.
Joe
From what I understand, the limiting aspect of the EOF approach is that it is at best a heuristic — it doesn’t explain any of the underlying physics, it just finds the eigenvalues that would occur IF some mix of linear differential equations described the situation. The latter is an assumption, because for example geophysical fluid dynamics is a nonlinear mix and the algorithm for expressing the eigenvalue roots would not strictly apply? Appreciate any corrections to my understanding.
[Response:Thanks for this comment. My take is that it depends on how you use the EOF analysis. If you apply the technique to data aggregated over e.g. a season or a year, then you may be able to discern some systematic features. They provide a statistical description, and you then need to see if the picture you see matches with what you understand in terms of physics. When it comes to common EOFs, it’s strictly a way to compare two or more datasets. -rasmus]
Full disclosure: I didn’t read the linked article. I comment only on the graphs shown here.
I’ve never heard of the term EOF but PCA is a standard data exploration technique in multivariate datasets. How the data are scaled? Because the Twenty Leading EOFs plot looks a lot like the mean of the data has not been removed. That’s why the first PC accounts for about 90% of the variance. On unscaled data, PC1 corresponds to the mean…when working with high SNR data.
Also, too, there are only 12 variables?
And if the data ARE scaled correctly, each factor from 4 to 20 appears to capture about the same amount of variance. Random factors could produce that result.
In chemometrics PCA is used mostly to identify unusual samples (outliers) and visualize groupings in categorical datasets.
MarlanaBeth
great questions and comments. I too, am wondering about these issues.
This link may be of assistance:
https://www.sciencedirect.com/topics/earth-and-planetary-sciences/empirical-orthogonal-function-analysis
Peanut butter jelly time
Please post my replies. Perhaps I should have put both comments in one section.
MarlanaBeth,
I share your concerns and questions.
Here is a link that helps answer those questions:
https://www.sciencedirect.com/topics/earth-and-planetary-sciences/empirical-orthogonal-function-analysis
How Will Probably Earth Look Like in 500 Years
read more about this https://www.beforeviral.xyz/post/How-Will-Probably-Earth-Look-Like-in-500-Years/0
Dear Rasmus,
before bashing other people’s books, you should maybe read them carefully. Maraun & Widmann, 2018 discuss common EOFs on page 163 in the predictor section of PP methods. We may not have covered them in the depth you would have done, maybe because we cover many other relevant issues and space is simply limited.
Regards,
Douglas