As we did roughly a year ago (and as we will probably do every year around this time), we can add another data point to a set of reasonably standard model-data comparisons that have proven interesting over the years.
First, here is the update of the graph showing the annual mean anomalies from the IPCC AR4 models plotted against the surface temperature records from the HadCRUT3v, NCDC and GISTEMP products (it really doesn’t matter which). Everything has been baselined to 1980-1999 (as in the 2007 IPCC report) and the envelope in grey encloses 95% of the model runs.
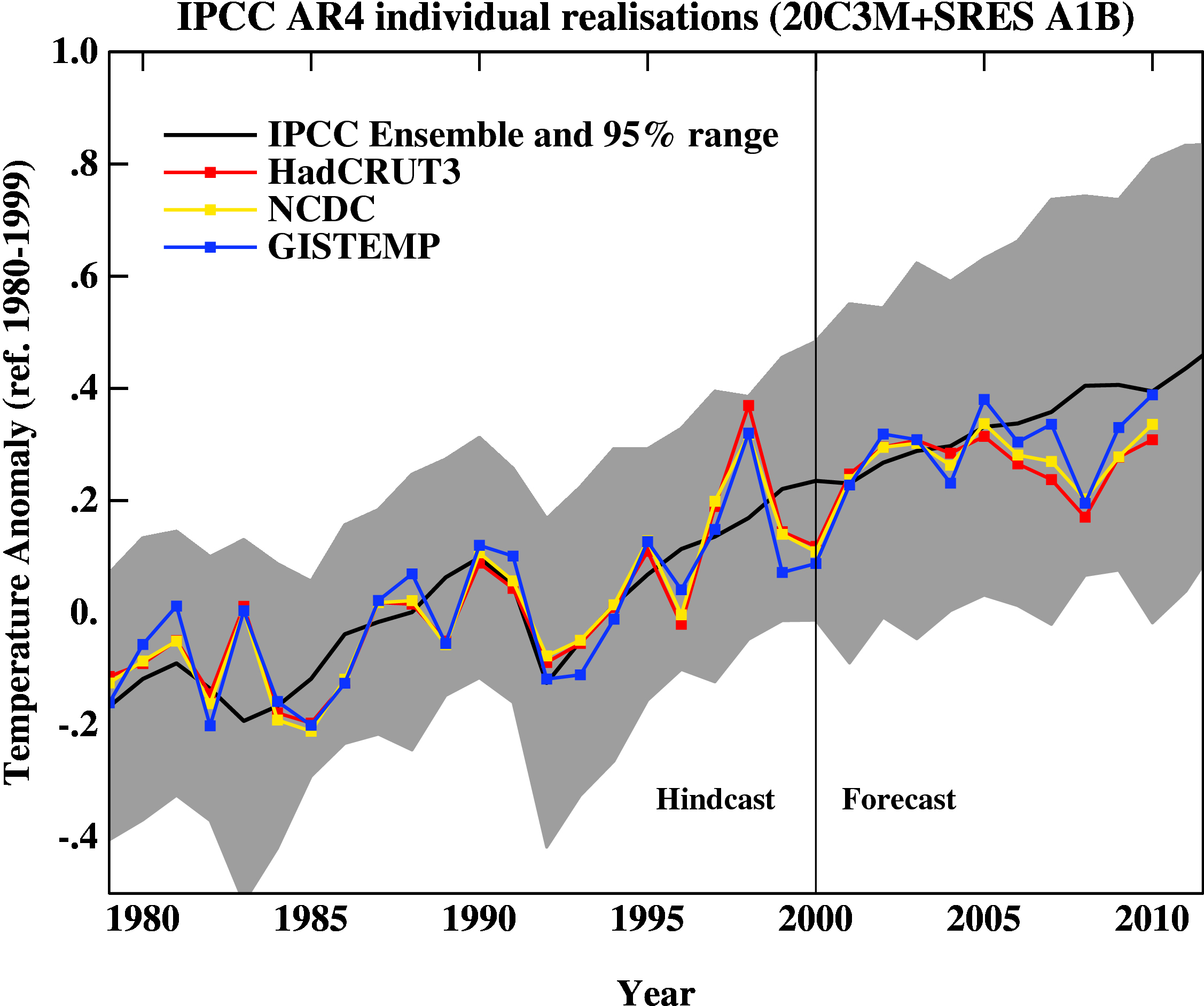
The El Niño event that started off 2010 definitely gave last year a boost, despite the emerging La Niña towards the end of the year. An almost-record summer melt in the Arctic was also important (and probably key in explaining the difference between GISTEMP and the others). Checking up on our predictions from last year, we forecast that 2010 would be warmer than 2009 (because of the ENSO phase last January). Consistent with that, I predict that 2011 will not be quite as warm as 2010, but it will still rank easily amongst the top ten warmest years of the historical record.
The comments on last year’s post (and responses) are worth reading before commenting on this post, and there are a number of points that shouldn’t need to be repeated again:
- Short term (15 years or less) trends in global temperature are not usefully predictable as a function of current forcings. This means you can’t use such short periods to ‘prove’ that global warming has or hasn’t stopped, or that we are really cooling despite this being the warmest decade in centuries.
- The AR4 model simulations are an ‘ensemble of opportunity’ and vary substantially among themselves with the forcings imposed, the magnitude of the internal variability and of course, the sensitivity. Thus while they do span a large range of possible situations, the average of these simulations is not ‘truth’.
- The model simulations use observed forcings up until 2000 (or 2003 in a couple of cases) and use a business-as-usual scenario subsequently (A1B). The models are not tuned to temperature trends pre-2000.
- Differences between the temperature anomaly products is related to: different selections of input data, different methods for assessing urban heating effects, and (most important) different methodologies for estimating temperatures in data-poor regions like the Arctic. GISTEMP assumes that the Arctic is warming as fast as the stations around the Arctic, while HadCRUT and NCDC assume the Arctic is warming as fast as the global mean. The former assumption is more in line with the sea ice results and independent measures from buoys and the reanalysis products.
There is one upcoming development that is worth flagging. Long in development, the new Hadley Centre analysis of sea surface temperatures (HadISST3) will soon become available. This will contain additional newly-digitised data, better corrections for artifacts in the record (such as highlighted by Thompson et al. 2007), and corrections to more recent parts of the record because of better calibrations of some SST measuring devices. Once it is published, the historical HadCRUT global temperature anomalies will also be updated. GISTEMP uses HadISST for the pre-satellite era, and so long-term trends may be affected there too (though not the more recent changes shown above).
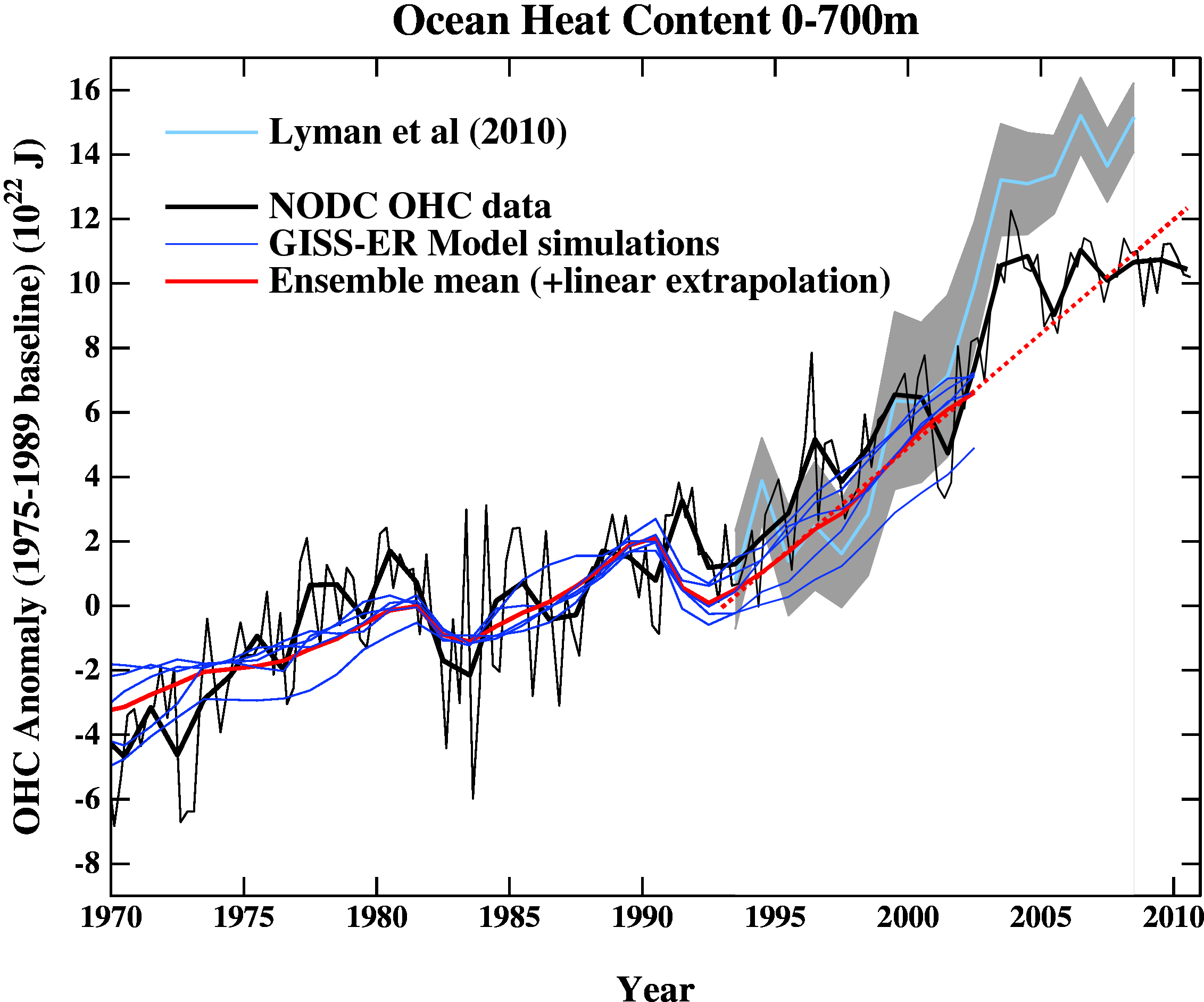
The next figure is the comparison of the ocean heat content (OHC) changes in the models compared to the latest data from NODC. As before, I don’t have the post-2003 model output, but the comparison between the 3-monthly data (to the end of Sep) and annual data versus the model output is still useful.
To include the data from the Lyman et al (2010) paper, I am baselining all curves to the period 1975-1989, and using the 1993-2003 period to match the observational data sources a little more consistently. I have linearly extended the ensemble mean model values for the post 2003 period (using a regression from 1993-2002) to get a rough sense of where those runs might have gone.
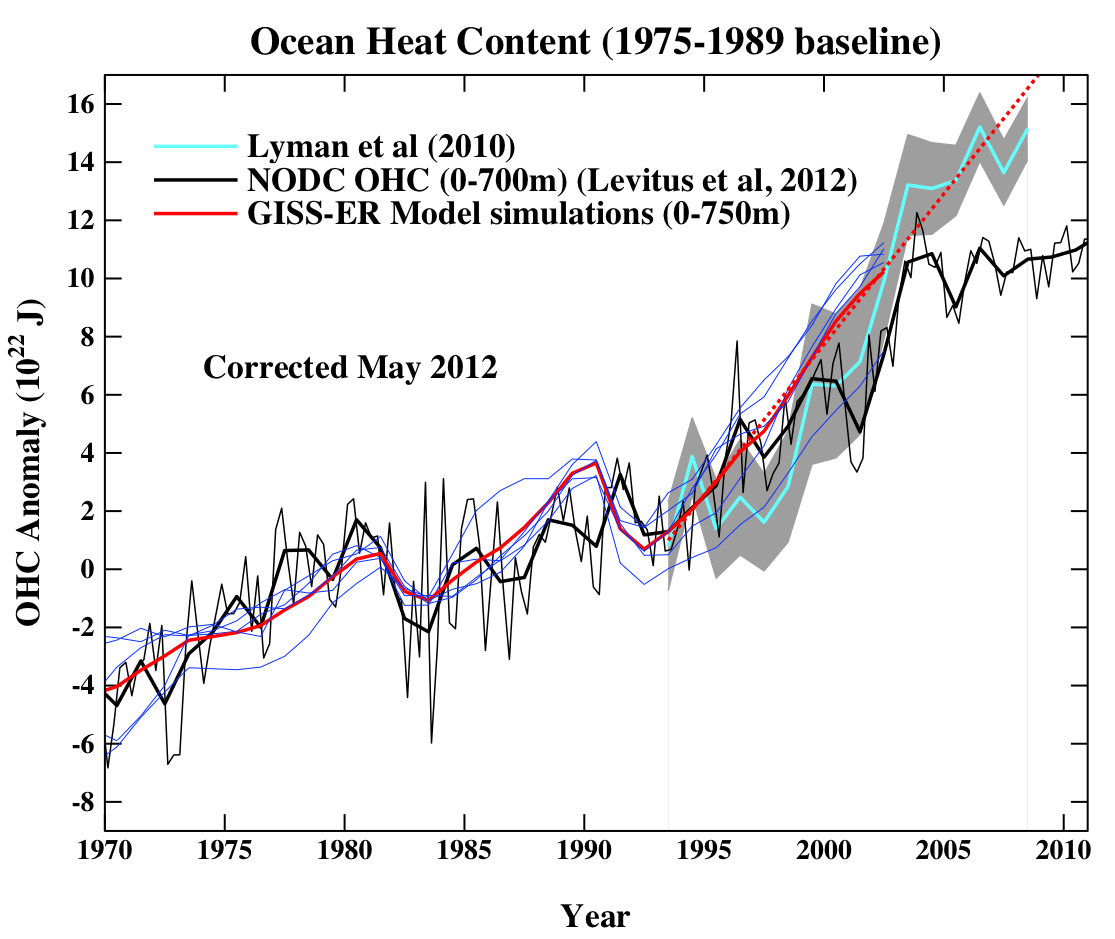
Update (May 2010): The figure has been corrected for an error in the model data scaling. The original image can still be seen here.
{kind=link}
As can be seen the long term trends in the models match those in the data, but the short-term fluctuations are both noisy and imprecise.
Looking now to the Arctic, here’s a 2010 update (courtesy of Marika Holland) showing the ongoing decrease in September sea ice extent compared to a selection of the AR4 models, again using the A1B scenario (following Stroeve et al, 2007):
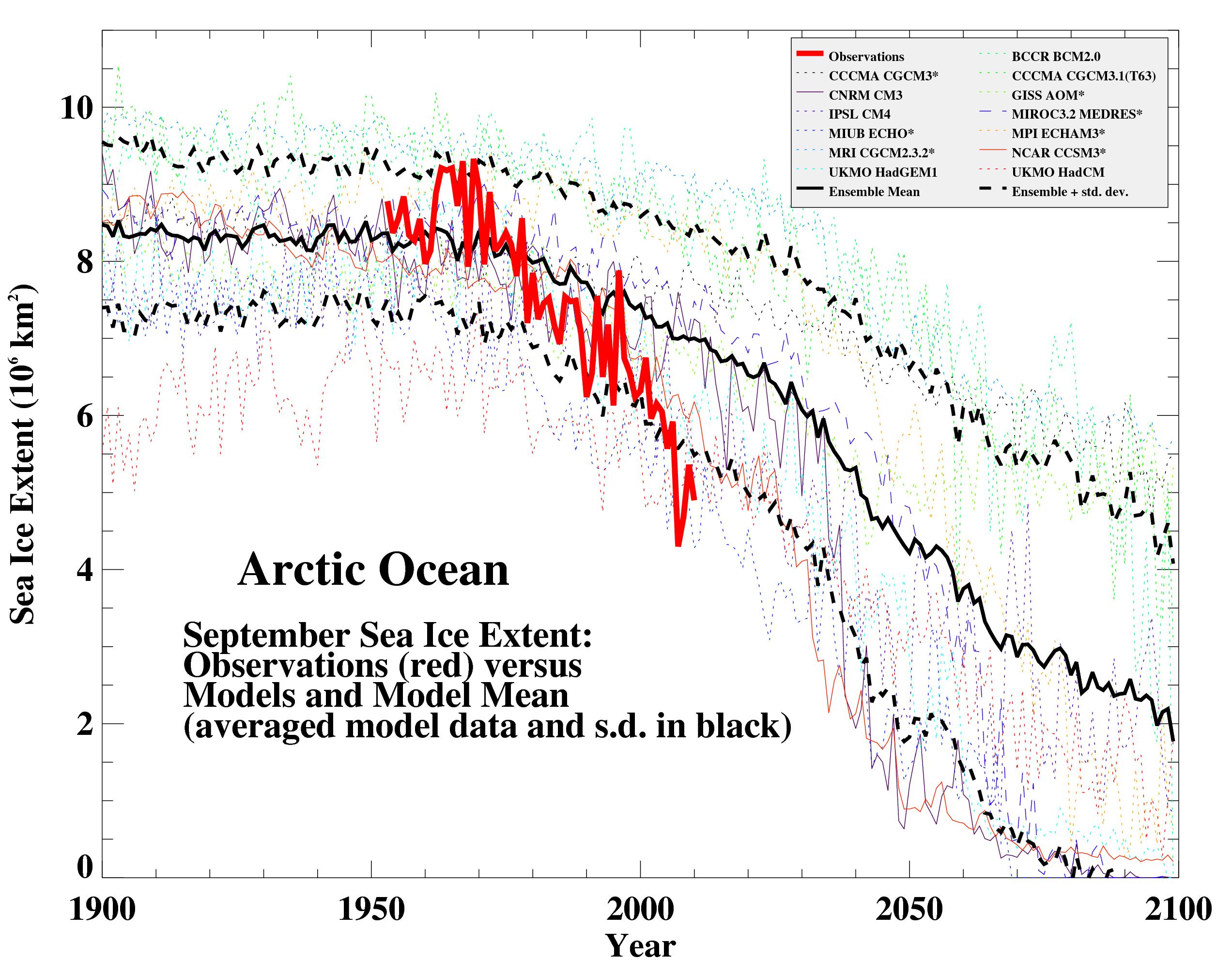
In this case, the match is not very good, and possibly getting worse, but unfortunately it appears that the models are not sensitive enough.
Finally, we update the Hansen et al (1988) comparisons. As stated last year, the Scenario B in that paper is running a little high compared with the actual forcings growth (by about 10%) (and high compared to A1B), and the old GISS model had a climate sensitivity that was a little higher (4.2ºC for a doubling of CO2) than the best estimate (~3ºC).
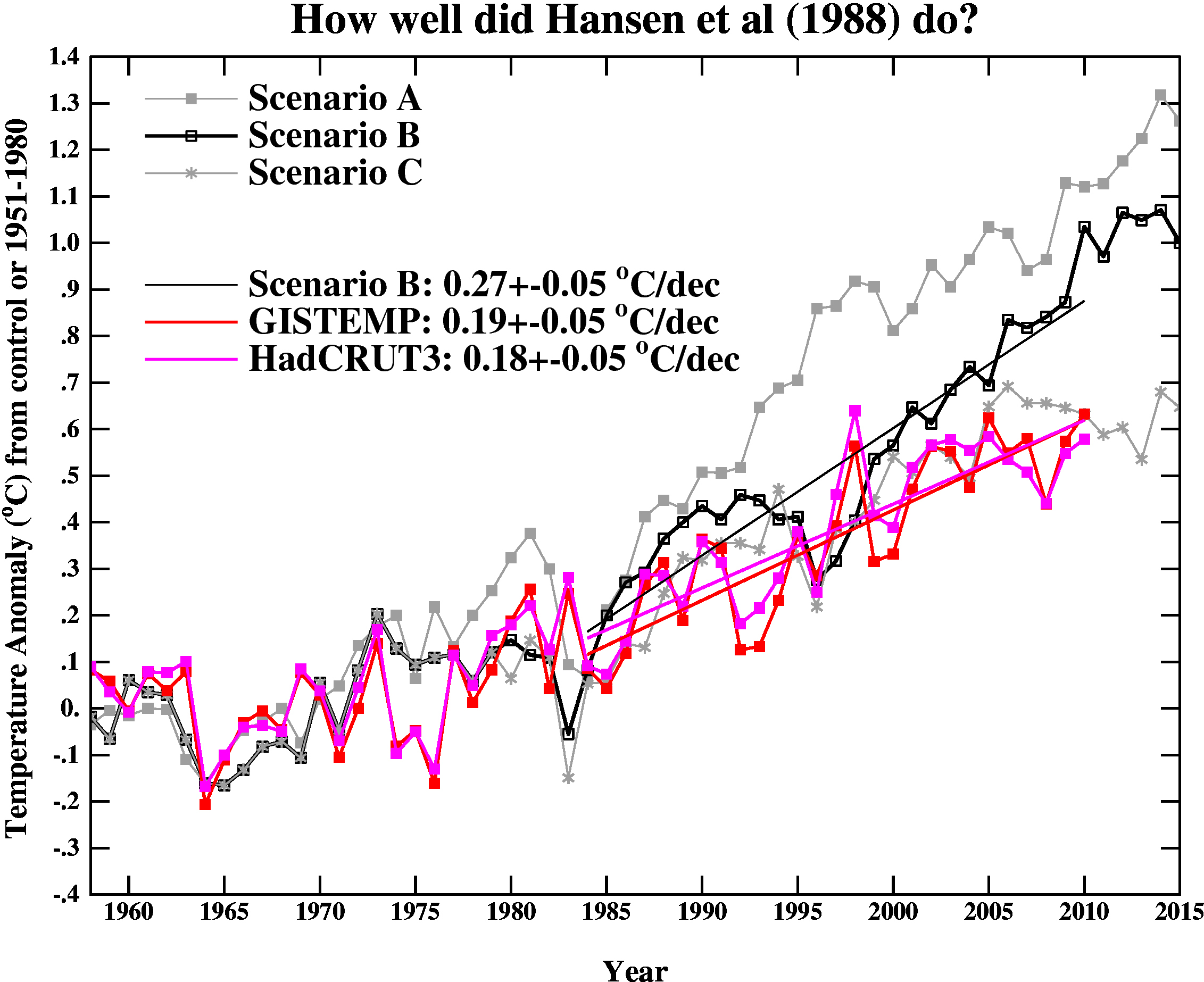
The trends for the period 1984 to 2010 (the 1984 date chosen because that is when these projections started), scenario B has a trend of 0.27+/-0.05ºC/dec (95% uncertainties, no correction for auto-correlation). For the GISTEMP and HadCRUT3, the trends are 0.19+/-0.05 and 0.18+/-0.04ºC/dec (note that the GISTEMP met-station index has 0.23+/-0.06ºC/dec and has 2010 as a clear record high).
{kind=link}
As before, it seems that the Hansen et al ‘B’ projection is likely running a little warm compared to the real world. Repeating the calculation from last year, assuming (again, a little recklessly) that the 27 yr trend scales linearly with the sensitivity and the forcing, we could use this mismatch to estimate a sensitivity for the real world. That would give us 4.2/(0.27*0.9) * 0.19=~ 3.3 ºC. And again, it’s interesting to note that the best estimate sensitivity deduced from this projection, is very close to what we think in any case. For reference, the trends in the AR4 models for the same period have a range 0.21+/-0.16 ºC/dec (95%).
So to conclude, global warming continues. Did you really think it wouldn’t?
> Would it not be more appropriate to rerun the models
Asked and answered repeatedly. You really should use the search tool.
Shorter answer: Why bother? Got a spare supercomputer, staff, and a year available?
[Response: Actually, this isn’t the case. It is more subtle. The actual model code is still available, but getting it to run on a more modern system with different compilers requires some work. In doing that work, and fixing various bugs that were found, the model becomes something a little different (look up EdGCM). The resolution of the model then (8×10) means you could run it trivially on laptop if you wanted. – gavin]
Anyone care to comment on Flanner et.al. “Radiative forcing and albedo feedback from the Northern Hemisphere cryosphere between 1979 and 2008”?
http://www.nature.com/ngeo/journal/vaop/ncurrent/full/ngeo1062.html
The abstract ends:
One of the authors, Karen Shell, an Oregon State University is quoted as saying
http://www.indymedia.org.au/2011/01/22/albedo-feedback-climate-models-underestimate-loss-of-reflectivity-in-the-arctic
143
Given that it has been shown that Temperature lags ENSO by about 6 months (Jones 1989),
and that inclusion of warm water volume data in ENSO prediction schemes significantly improves forecast skill at ~6 months (McPhaden 2003).
A 12 month prediction is much closer than you think:
http://www.pmel.noaa.gov/tao/elnino/wwv/gif/wwv_nino.gif
The weather-climate linkage is the first step towards understanding natural variability.
Taking advantage of a chance to advertise from gavin’s inline to #151, I’d highly recommend those interested in basic modeling to download EdGCM. It’s very user friendly and basic runs at least can be accomplished with no programming skill, runs fine on any home PC and takes about 24 hours to do a 150 year simulation.
We used it heavily as part of a Global Climate Processes course at UW-Madison for later undergrad and grad students, so it has a good deal of flexibility in what you can test (though the model blows up for extreme forcings like snowball Earth, I used CO2 at about 140 ppm and couldn’t get much lower than that). You can also create your own scenarios “A”, “B”, “C” etc in a text file and use your own forcings as part of the simulated projections to see how the climate responds. Alternatively, you can create your own CO2 concentration projections based on your own emission and ocean/biosphere sink/source scenarios using this carbon cycle applet created by Galen McKinley at Madison, which can then be integrated into EdGCM.
Roger Pielke Sr. has a comment on his website related to an inline response to comment #3 above.
The Lyman et al (2010) results (illustrated in the OHC figure above), are the best estimate yet of OHC trends and the associated uncertainties in the product. Explaining every wiggle in that curve is beyond the scope of a blog post, but the points I made above in discussing the potential mismatch between the GISS model AR4 runs and the observations are trivially true – they can be related to a) OHC changes not captured by the 0-700m metric, b) continuing problems with the Argo network and older measurement network, c) internal variability of the climate system that is not synchronised with internal variability in these models or d) inaccuracies in modelled ocean surface heat fluxes. The ‘truth’ is very likely to be some combination of all of the above.
Dr. Pielke ends his comment with a call for “independent assessments of the skill at these models at predicting climate metrics including upper ocean heat content”, which of course I have no problem with at all. Indeed, I encouraged him to pursue just such an assessment using the freely available AR4 simulation archive years ago. As I said then, if people want to see a diagnostic study done, they are best off doing it themselves rather than complaining that no-one has done it for them. That is the whole point of having publicly accessible data archives.
captdallas2 @140 — For the first half of the 20th century, volcanoes made a difference:
http://replay.waybackmachine.org/20090220124933/http://tamino.wordpress.com/2008/10/19/volcanic-lull/
155
I don’t need an assessment of the models at predicting climate metrics including upper ocean heat content.
They have zero skill, and the only skill they have for El Niño is because of the lag between the two.
Besides the historical behaviour of the phenomenon, there is nothing to say why the current La Niña will eventually decay.
That’s a very dangerous position to be in. If it doesn’t decay the change to the climate system would be off the charts.
[Response: And if my grandmother was a mouse, she’d eat cheese. Can we please have less of the evidence-free declaratory mode? Thanks. – gavin]
Ray Ladbury,
I am not particularly willing to bet anything, long shot or not. It just appears that the useful but imperfect models and the useful but imperfect data sets the models are working with, have more downside uncertainty (lower sensitivity) than upside. My fixation on the early 20th century warming is, it good period to spend more effort on, to help reduce uncertainty.
Solar influence during that period is much less than estimated less than a decade ago meaning that aerosols and/or natural climate oscillations played a greater than estimated role. The natural oscillations intrigue me because of their potential to dramatically increase precipitation on shifts, which reduces heat content that may not be accurately reflected in the surface temperature record.
With warming, those oscillations should produce even more precipitation, like more and more powerful storms. Imagine that. Increased precipitation will buffer warming somewhat. How much? Will the frequency of the climate shifts increase with warming? If they do, how strong would that feedback be on GTA?
Gavin, why didn’t comment #157 by Isotopious just go straight to The Bore Hole, where it belongs?
What the 1988 Scenarios were or showed is one of those zombie lies that keep coming back. Eli showed a long time ago that the Scenario B 1988 predictions were a little low until ~2000 and then a little high. Further B and C don’t really diverge until ~2000, so that effect would only show up about now anyhow. (Hint, click on the graphic to blow it up, the actual forcings until 2006are the blue line)
151, Hank Roberts: Got a spare supercomputer, staff, and a year available?
It’s something I hope to do in 2015-2020. I hope by then to be able to purchase a 64 core computer (mine only has 8 cores). I appreciate the comments by Gavin and Chris Colose about EdGCM. I’ll probably look into that.
I think that the divergence between scenarios a and b and the data shows that the model is defective. But it’s only one item of information.
[Response: Huh? Scenario A an B are different, why should the results be the same? – gavin]
I have bought the web name http://www.climatebet.com and will set up the site when I have a bet to post on it. I have been trying a few bookies to set the odds but so far I have failed. I wonder if anyone one this site would participate.
Earlier, #152. I asked about Flanner et.al. – no response yet. As I read the abstract, it is saying that all existing climate models underestimate an important feedback, the sea-ice albedo effect. I worry about such “missing feedbacks” and am willing to back my worries with a $1000 evens bet.
So who will take on a bet that this year will have the lowest sea-ice extent in the satellite record as published by the NSIDC.
I am happy to bet this even though the climate is in a La Nina phase.
Any takers?
Better still, does anyone know of a bookie that will take bets like this?
Re: 110
When you say a model is skillful, you must answer the question: skillful as compared to what? Skillful requires that the model performs better than a BASELINE model. One baseline model is a simple linear trend from the start of the century. This model performs as good or better than Hansen’s prediction. It takes less than 1 second to run, uses no physics, and is more accurate. (admittedly there are many possible different simplified models).
If you take a trend from 1900-1984 as the baseline forecast, the 2000-2010 forecasts from scenario B improve on the baseline RMS error by 20% (using each year as a forecast). A more appropriate baseline, in my view, would be the mean from 1900-1984, since it doesn’t include an assumption of warming. Scenario B improves on that forecast by 60%. There’s skill compared to both of those baselines.
captdallas says: “It just appears that the useful but imperfect models and the useful but imperfect data sets the models are working with, have more downside uncertainty (lower sensitivity) than upside.”
Huh? Where in bloody hell do you get that? Have you even looked at the data constraining sensitivity? Dude, there is zero convincing evidence for a low sensitivity. Read the papers by Annan and Hargreaves or the Nature Geo review by Knutti and Hegerl.
If we are lucky, sensitivity is 3 degrees per doubling. If very lucky, 2.7. If we win the frigging lotto, 2. The fact remains that we cannot rule out sensitivities of 4.5 or higher. Below 2 you simply don’t get an Earth-like climate.
Can anyone explain THIS COMMENT over at Policy Lass? (Seems relevant and I can’t think of anywhere more appropriate to ask)
[Response: Crank central. – gavin]
161, Gavin: Huh? Scenario A an B are different, why should the results be the same? – gavin
I meant that mean temperature of the world has developed (according to the data to date) differently from forecast (or “anticipated”) by scenarios A and B. It’s almost as if the increased CO2 since 1988 has had no effect.
[Response: Huh? (again). If CO2 had no effect, there would have been almost zero net forcing at all, and no reason for the observed trends. – gavin]
Does everyone agree with Eli Rabett in 160? That the scenarios are zombie lies?
to continue with my imaginary future computer, I probably will not be able to afford the electricity.
re: 110 Large positive CO2 forcings calls for accelerated warming as CO2 increases.
Since the effect of each equal increase in CO2 is less than the one before, I don’t see how this is true. Or who would claim it to be true. This is the 2nd time in recent weeks that someone has claimed that there’s a widespread assertion that the warming should be accelerating due to CO2 increases
All of the discussion about accelerating increases in temperature that I’ve read over the last couple of years pin the effect on feedbacks.Particularly changes in the land.
Who is asserting that there should be accelerating increases in temperatures due to increases in CO2?
[Response: This needs to be strongly caveated. For the 20th C, the increase in GHGs gave faster-than-linear forcing, and so a larger trend is expected for the last 50 years, as for the first 50 years (as is observed). Thus in that sense, there has been an acceleration. Moving into the 21st century, the IPCC figure on the temperature response to the scenarios shows that eventually we also expect an increase in trend above what we are seeing now. However, there are no results that imply that we should be able to detect an acceleration in say the last ten years compared to the previous ten years. Many of the claims being made are very unspecific about what is being claimed, and so one needs to be careful. – gavin]
Septic Matthew:
Why are you playing games?
Eli’s position is clear. On the 1988 paper: “The result was a pretty good prediction. Definitely in the class of useful models.”
The “zombie lies” are the perennial falsehoods that you and others dump on us from time to time, attempting to rewrite history by confusing the scenarios or just outright lying about what they are or which is closest to reality.
As for your plans to recreate a climate model…. I seriously doubt your ability to do that. However, I suspect you do actually understand more about models than you pretend to.
Septic Matthew – if increased atmospheric CO2 since 1988 were having no effect, given all the talk of natural cooling phases, wouldn’t the global mean temperature be on a distinct downward tack?
Apologies, Gavin. Rudeness is not helpful.
As parameters are changed, the models of 1988 can’t be compared to the results of 2010, I guess. Perhaps one could say that the mix of errors in 1988 Scenario C “looks” like it matches the history, suggesting that “up” errors of 1988 were compensated for by “down” errors as things turned out. And that right now Lyman 2010 might be observing something that will show up later when the time-lag is considered.
The goal of graphs is to reduce a complex relationship to a simple image that doesn’t distort the general connection. If Scenario C is not to be viewed “as is”, then the non cognoscenti would wonder about A and B also. And if the visual divergence between Lyman and the others is one of apples and oranges, then the presentation is misleading or disinformation.
What we really want is to see some simple comparison of temperature data since 1988 with projections circa 1988 beyond 2010 and hindcasts from 1988 with current (2010) understanding beyond 2010. Then we can see if prior warnings were excessive or underrated and see how possible troubles have changed over the years. Then, 22 years later, we’ll get a better feel as to how much confidence we, as non-statisticians and modellers, can place in forecasts from Hansen, the IPCC et al.
Again, I apologize for the rudeness.
“However, there are no results that imply that we should be able to detect an acceleration in say the last ten years compared to the previous ten years.”
but to reach more than 2°C at the end of the century, there must be undoubtedly a detectable acceleration at some moment – and it is somewhat surprising that no hint for any acceleration is detectable after 30 years of continuous increase of radiative forcing, isn’t it ? when is this acceleration supposed to become measurable?
[Response: Look at the projections – I’d say by mid-century. One could do a more quantitative analysis of course. – gavin]
concerning scenarios : first I don’t understand a continuous use of scenarios that were already wrong in the 90’s. Then the weak point of the scenarios used in SRES is that they all rely upon a continuous economic growth throughout the century -which is by no means granted- , and that they all exceed by far the amount of proven reserves for at least one fuel – which can hardly be considered as a likely event, by definition of “proven”. So the SET of scenarios does certainly not encompass all the possibilities of the future – it is strongly biased as a whole.
Geoff Beacon 162
Try intrade. They have a bet on JAXA IJIS extent record low. Implied probability of failing to get a record is 30% to 39% with last trade at 32%. No-one should offer you evens if they can get a better odds at intrade; so it appears you need to offer approx 2:1 to get someone to bet against a record.
SM, failure of reading comprehension.
You’re rapidly becoming boring and digging yourself deeper.
You ignore Gavin’s point that you can run EDGCM yourself on a home PC and redo the scenarios yourself, and whine about not having a supercomputer, presumably the 1980s vintage machine you’d need to exactly redo scenarios.
You write:
> Does everyone agree with Eli Rabett
> … That the scenarios are zombie lies?
That’s a pure example of what Eli describes, lying about what he wrote and misstating what the scenarios were or showed. It’s your spin. He wrote:
“What the 1988 Scenarios were or showed is one of those zombie lies …”
Why bother here if you’re just posting talking points and advertising ignorance while ignoring the answers given over and over to that stuff?
Please, we need smarter skeptics who can respond to facts, not deny’em.
Ray Ladbury, 24 Jan 2011 9:29 am
Perhaps I miss read. Annan and Hargreaves 2009. 2 to 3 C is the expert high probability range.
“If we were to further update each of these analyses with the FG likelihood, the posterior cost would reduce still further to 1.6% of GDP with a 95% limit for S of 3.5oC based on the Hegerl et al. analysis, and 2% of GDP with a 95% limit for S of 3.7oC for Annan and Hargreaves. At such a level of precision, it would probably be worth re-examining the accuracy of assumptions in some detail, such as those regarding the linearity of the climatic response to forcing, and the independence of the analyses of the distinct data sets. Nevertheless, such results may be interpreted as hinting at an achievable upper bound to the precision with which we can reasonably claim to know S, given our current scientific knowledge.”
So the 95% likelyhood range of 2xCO2 is 1.3 to 3.7, based on “our current scientific knowledge” Of course there are questions with their methods, but they are at least avoiding “overly pessimistic” priors. I will have to look into the other papers.
I guess looking back at 1913 to 1940 only intrigues me.
“Can anyone explain THIS COMMENT over at Policy Lass?” J Bowers — 26 Jan 2011 @ 9:53 AM
“…when you correct Sagan’s incorrect optical physics of sols, which started the whole CAGW scare, ‘cloud albedo effect’ cooling changes to heating, another AGW which is self-limiting.”
AHA! Now, I understand.
Sagan got cloud albedo effect backwards, and it should therefore be “nuclear summer” instead of “nuclear winter”. That misteak has fooled Lindzen into thinking there is a cloud Iris effect (GOOOOOAAAAAALLLLL – oops, OWN GOOOAAALLL, erm, own goal, uuuh, shhh,own goal). So actually the current warming from natural variation (NOT CO2, never CO2) will give more evaporation, which will give more clouds, which will magnify the warming(which will give more evaporation, more clouds, more warming, etc, etc, etc). This positive cloud feedback will self-limit when we reach 100% year round cloud cover everywhere, up from the current (~60% ?) average. Musta been what happened at the PETM – we can look forward to an Azolla swamp summers at the North Pole(which we can harvest to fertilize rice crops – fixes Nitrogen), and megafauna extinctions. Makes me feel all warm and fuzzy that we don’t have to work up a sweat over CO2 emissions.
There is that one niggling detail – are humans megafauna?
He goes on to claim that “Pollution increases the albedo of thin clouds because but, contrary to the present theory, decreases it for thick clouds. You can prove this by looking at thick clouds about to rain – they’re darker because increased droplet size means more direct backscattering, less light diffusely scattered.” This doesn’t make sense – more pollution, or more specifically, more Cloud Condensation Nuclei from sulfate or particulate emissions, result in more droplets. The start of cloud formation is dependent on a parcel of air reaching water vapor saturation(actually, some level of supersaturation); whatever that level is, it represents a fixed amount of water available at the onset of cloud formation. Larger numbers of CCN from pollution will divide that amount of water over a larger number of necessarily smaller droplets.
This has been observed.
google “pollution effect cloud droplet size”, or see “Aerosol Pollution Impact on Precipitation: A Scientific Review” By Zev Levin, William R. Cotton
Thick clouds about to rain are not the same as thick (fluffy, high albedo) clouds with lots of pollution caused CCN.
Alas, Policy Lass is Amiss, or a miss.
@ Gavin, many thanks for taking the time. I actually realised who he is not long after asking here. Ta.
Hi Gavin,
apropos Ray’s comment at 164 above:
“The fact remains that we cannot rule out sensitivities of 4.5 or higher”
Back in 2007 in your “Hansen’s 1988 Projections piece” at https://www.realclimate.org/index.php/archives/2007/05/hansens-1988-projections/
you noted that the sensitivity used in the Hansen model of about 4C per doubling was a little higher than what would be the best guess based on observations. You posed the interesting question:
“Is this 20 year trend sufficient to determine whether the model sensitivity was too high? ”
You answered in the negative at that time. Whilst in 2007 you noted that “Scenario B is pretty close and certainly well within the error estimates of the real world changes” that is clearly not the case now, as you acknowledge in saying that it (Scenario B) is running a little warm.
My question is this:
Given the fact that observations have continued to move away from model projections based on a sensitivity of 4.2C per doubling of CO2 (Scenario B), to what extent can we rule out, or at least consider as highly unlikely, sensitivities of 4.5C or higher?
Thank you.
166, Gavin’s comment: [Response: Huh? (again). If CO2 had no effect, there would have been almost zero net forcing at all, and no reason for the observed trends. – gavin]
I meant “increased” CO2, not total. Is there any good reason why, if the model is correct, the counterfactual scenario c fits the data better than the scenarios a and b, or is it merely a short-term statistical fluke with no long-term importance?
169 Didactylos (smart e-name, by the way. I think I mentioned that once before): However, I suspect you do actually understand more about models than you pretend to.
Thank you. I have more experience with models like this: http://www.sciencemag.org/content/331/6014/220.abstract
The actual model is in the Supporting Online Material behind the paywall, but it’s available to any member of AAAS.
Pssst, guys, look at the TOPIC you’re linking to, in Policy Lass.
You’re loooking at a post in The Climate Denier Dunce Cap topic.
Many have nominated excellent examples.
Volunteer dunces have contributed their best work.
Great site. Be aware of the context in which you’re reading.
“Then the weak point of the scenarios used in SRES is that they all rely upon a continuous economic growth throughout the century -which is by no means granted- …” Gilles — 26 Jan 2011 @ 11:59 AM
If that’s the case, then the economic arguments – that we should wait “until the science is settled” because the application of a discount rate makes solving AGW cheaper in the future, and we can’t afford the economic dislocation if we act now – are false. If we really can’t afford to fix it now, and are less able to in the future, then we are really screwed.
SM:
Actually, it’s almost as though the computed sensitivity of 4C to a doubling of CO2 in this early, 1988 model is too high (as has already been pointed out). Why, it’s almost as though the real sensitivity is more or less 3C, instead … I mean, it’s almost as though AR4’s most likely number for sensitivity, rather than the 1988 model’s higher computed value, is likely to be very close to the real value.
Despite this too-high sensitivity number, the scenario B projection (the only one worth looking at, since that most closely models actual CO2 emissions), was pretty darn good. As someone pointed out, it is skillful compared to simply extrapolating the trend from earlier decades …
PPS
It looks like J. Bowers set up the confusion by coming here, pointing to the guy’s post over there, misidentifying it as from “Climate Lass” — and over there telling the guy that he’s linked to him at RC to get him more attention.
“Oops” and “oops” again, twice linking to denier posts naively. Do better.
Re 126.
Thanks for the pointer, Hank. I will try it — and hope I get some clues on how this is done. I have done much modelling in my time and I find that making sure the input is properly constructed is the sine qua non of a good process. With that solved, I then move to the two natural elements in the sequence: the derivation of the relationships (statistical association, formulaic constructions, etc.) and ultimately to the results of the model and how to make sure that a good historical fit (of statistical associations) does not inadvertently slip into a conclusion of causality.
Captdallas2,
Huh? Where in bloody hell are you getting 1.3 to 3.7. The 90% CL is 2-4.5. If you are referring to Annan’s Bayesian approach where he uses a Cauchy Prior–I have severe qualms about any Bayesian analysis that significantly changes the best estimate. In any case, a Cauchy is not appropriate, because it is symmetric and so does not capture the skew in our knowledge of the quantity. It is probably best to go with a lognormal prior as this at least doesn’t violate the spirit of maximum entropy/minimally informative priors.
156 David Benson,
The volcanic lull persisted until circa 1960, 20 years after the period in question. It is also likely that other aerosols, dust from the dust bowl and accelerated manufacturing to build up for war, could have been significant. If the volcanic lull had a better fit to temperature, I would agree. The construction boom following the war may have contributed to the drop in temperatures, but the climate shift theory is a much better match to what happened.
@ 182 Hank
I (and others) have asked the guy to come to RC a number of times in the past on CIF to propose his pet theory, but he goes under a different name there, and it wasn’t until immediately after I genuinely asked here that I realised who he is (he sockpuppets in the UK MSM) – it’s not like his theory makes much sense to start with, and it’s even more difficult to follow each time he announces it in different ways. Pointing out I’d asked at RC was a kind of in-joke between us. I wasn’t spreading any confusion or attention seeking and I clearly said “Policy Lass” (read up). I frankly thought it was another faux “nail in the coffin of AGW” that crops up every week, and not being a climate modeller thought it would be a good idea to ask if someone could take a quick look in anticipation of a wave of zombie arguing points.
151, Hank Roberts: Got a spare supercomputer, staff, and a year available?
174, Hank Roberts: You ignore Gavin’s point that you can run EDGCM yourself on a home PC and redo the scenarios yourself, and whine about not having a supercomputer, presumably the 1980s vintage machine you’d need to exactly redo scenarios.
You two guys need to get together. And I did note the comments about EDGCM.
The Role of Atmospheric Nuclear Explosions on the Stagnation of Global Warming in the Mid 20th Century – Fujii (2011)
Hat tip to:
http://agwobserver.wordpress.com/2011/01/24/new-research-from-last-week-32011/
Ray Ladbury,
In the Annan Hargreave 2009 paper they did not discuss a lower limit as it had no meaning for their purpose, I assume. Their statement of 2 to 3 C as an expert excepted range and they calculated a 95% probability S was less than 4 C. 3.7 was the 95% limit for their study. The range 1.3 – 2.5 – 3.7 is implied from that study.
I agree that the Bayesian with Cauchy prior has issues, but my understanding is that if the prior is fairly “expert” the results will be reasonable. Other methods are more tolerant of ignorance, but the results tend to be less useful (too much area under the curve).
As far as departure from the accepted “norm” (2-4.5), 1.3 – 2.5 – 3.7 is not that much of a stretch. In any case, I expect more papers in the near future using various statistical approaches.
Aside — the above links lead to others including this tidbit modelers might find useful to crosscheck dust estimates from aerosol depth. (Pure speculation on my part.)
Plutonium fallout might track amounts of dust in the atmosphere recently picked up in dust storms. The age of the isotope identifies the source: http://dx.doi.org/10.1016/j.apradiso.2007.09.019
“Recently, the deposition rates have been boosted by the resuspension of radionuclides in deposited particles, the 239,240Pu content of which may originate from dusts from the East Asian continent deserts and arid areas.
Captdallas: “As far as departure from the accepted “norm” (2-4.5), 1.3 – 2.5 – 3.7 is not that much of a stretch.”
WRONG!! There is virtually no probability below about 1.5, and even 2 is stretching it. OTOH, the portion above 4.5 is quite thick-tailed. The distribution looks like a lognormal with standard deviation of about 0.91–and that’s got a pretty serious kurtosis. The problem with a Cauchy Prior is that it exaggerates the probability on the low side and under-estimates the probability on the high side. The prior should not drive the results, and it definitely should not have properties significantly different from the likelihood.
Hank 188, the nuclear hypothesis is a weak one; not impossible, ofcourse, to be sure, but not, on very solid data. For obvious reasons it cannot be replicated either:) I am not closed off to a possible cooling effect, as a result of nuclear explosions, but all conclusions on either side of the debate are too speculative for my blood. I still read these little contributions, just the same, as it makes for interesting reading.
Ray, 184. Let us back up for a minute. In your own words, how would you justify the best estimate as it is often called? What I mean statistcally speaking and based upon what you personally know about the data, what are the best indicators this range can be believed with with such confidence. I do not mean quoting the the IPCC report and their probability ranges, but what have your calculations, best estimates and background in physics shown you, and how do you articulate it? Maybe I am just too confident having completed a host of new grad stats courses and having some interesting input from a chemical engineer friend of mine, but I am curious about your critical thinking process and analysis of the claims made in this temp range and so forth.
Thanks,
Jake.
Crandles 173
Thanks for your suggestion but I couldn’t find it on the intrade site. Can you point me in the right direction.
But a bet doesn’t ally my fears about missing feedbacks. I had hoped for some guidance on the Flanner et. al. paper.
Captdallas2: “…but the climate shift theory is a much better match to what happened.”
Not even wrong. Dude you are arguing with 100 year old science. You might as well be arguing for the currant-bun theory of the atom!
Ray Ladbury, #191: Good start on talking point in statistics I. One question, and one comment: what do you base the claim of zero probability of 1.5 degrees? Comment: I would argue, the high end estimates have zero probability statistically due to empirically observed buffering.
Jacob Mack, do you want to talk in terms of Bayesian, Frequentist or Likelihood ratios? And what criterion do you want to base the designation of “best” on. The treatment by Knutti and Hegerl is quite readable and fairly comprehensive. Knutti proposes 9 criteria for evaluating the quality of a constraint, along with 9 separate constraints. You can find additional analyses at AGWObserver:
http://agwobserver.wordpress.com/2009/11/05/papers-on-climate-sensitivity-estimates/
Personally, I do not think any single criterion leaves the others in the dust. What is most impressive to me is the accord between the very different analyses and datasets. Almost all of them arrive at a best estimate of around 3 degrees per doubling and a “likely” range between 1.5 and 7. All are skewed right. They all pretty much preclude a sensitivity as low as 1.5. If the concept of CO2 sensitivity were wrong, or if the physics were seriously off, you would expect to get a broad range of estimates. You don’t. My takeaway from this is that CO2 sensitivity is most likely around 3 degrees per doubling, and that if that’s wrong, it’s most likely higher.
Now in terms of stats, I think likelihood is probably the best way to look at it. If you are going to look at it in a Bayesian way, your Prior should be as uninformative as possible. One useful way of looking at it is to look at how much the best-fit parameters of your distribution (again, you probably want to use a lognormal) change as you add data. You can also look at how your likelihood (or Posterior) for your best-fit value changes as you add data. Big changes indicate either very important or inconsistent data. What you notice about climate sensitivity is that the central tendency doesn’t change much–your distribution just mostly gets narrower as you add data–a lot at first, and less as you proceed. That is usually an indication that your data are pretty well in accord. Does that make sense?
Ray Ladbury,
So for lognormal SD ~1 there are a lot of random, multiplicative, feedbacks and all are positive? You have a much stronger grasp of statistics than I do. I was under the impression there might be a few negative feedbacks in a chaotic atmosphere.
Multi-decade long oscillations that impact climate go against 100 year old science?
Guess I need to hit the books.
ta
Jacob, What precisely do you mean by “empirically-observed buffering”? The analyses that place the most stringent limits on the high side, also show almost no probabilty on the low side (e.g. last glacial max, last interglacial and climate models). The climate models are particularly important for limiting the high-side probability. That is why I always laugh when denialists argue that the models are crap. If the models are wrong, we’re probably in real trouble! The thing is that none of these things work particularly well with low sensitivity. The claim of low (not zero) probability is due to the aggregate distribution.
Oh, BTW, I was in error–the lognormal standard deviation is probably about 0.25. That puts the probability of S less than 1.5 at about 0.3% On the high side to get to such a low proability, you’d have to go to about 6 degrees per doubling. The high-side will always drive risk.