We’ve often discussed the how’s and why’s of correcting incorrect information that is occasionally found in the peer-reviewed literature. There are multiple recent instances of heavily-promoted papers that contained fundamental flaws that were addressed both on blogs and in submitted comments or follow-up papers (e.g. McLean et al, Douglass et al., Schwartz). Each of those wasted a huge amount of everyone’s time, though there is usually some (small) payoff in terms of a clearer statement of the problems and lessons for subsequent work. However, in each of those cases, the papers were already “in press” by the time other people were aware of the problems.
What is the situation though when problems (of whatever seriousness) are pointed out at an earlier stage? For instance, when a paper has been accepted in principle but a final version has not been sent in and well before the proofs have been sent out? At that point it would seem to be incumbent on the authors to ensure that any errors are fixed before they have a chance to confuse or mislead a wider readership. Often in earlier times corrections and adjustments would have been made using the ‘Note added in proof’, but this is less used these days since it is so easy to fix electronic versions.
My attention was drawn in August to a draft version of a paper by Phil Klotzbach and colleagues that discussed the differences between global temperature products. This paper also attracted a lot of comment at the time, and some conclusions were (to be generous) rather unclearly communicated (I’m not going to discuss this in this post, but feel free to bring it up in the comments). One bit that interested me was that the authors hypothesised that the apparent lack of an amplification of the MSU-LT satellite-derived trends over the surface record trends over land might be a signal of some undiagnosed problem in the surface temperature record. That is not an unreasonable hypothesis (though it is not an obvious one), but when I saw why they anticipated that there should be an amplification, I was a little troubled. The key passage was as follows:
{kind=link}
The global amplification ratio of 19 climate models listed in CCSP SAP 1.1 indicates a ratio of 1.25 for the models’ composite mean trends …. This was also demonstrated for land-only model output (R. McKitrick, personal communication) in which a 24-year record (1979-2002) of GISS-E results indicated an amplification factor of 1.25 averaged over the five runs. Thus, we choose a value of 1.2 as the amplification factor based on these model results.
which leads pretty directly to their final conclusion:
We conclude that the fact that trends in thermometer-estimated surface warming over land areas have been larger than trends in the lower troposphere estimated from satellites and radiosondes is most parsimoniously explained by the first possible explanation offered by Santer et al. [2005]. Specifically, the characteristics of the divergence across the datasets are strongly suggestive that it is an artifact resulting from the data quality of the surface, satellite and/or radiosonde observations.
(my emphasis).
For reference, the amplification is related to the sensitivity of the moist adiabat to increasing surface temperatures (air parcels saturated in water vapour move up because of convection where the water vapour condenses and releases heat in a predictable way). The data analysis in this paper mainly concerned the trends over land, thus a key assumption for this study appears to rest solely on a personal communication from an economics professor purporting to be the results from the GISS coupled climate model. (For people who don’t know, the GISS model is the one I help develop). This is doubly odd – first that this assumption is not properly cited (how is anyone supposed to be able to check?), and secondly, the personal communication is from someone completely unconnected with the model in question. Indeed, even McKitrick emailed me to say that he thought that the referencing was inappropriate and that the authors had apologized and agreed to correct it.
So where did this analysis come from? The data actually came from a specific set of model output that I had placed online as part of the supplemental data to Schmidt (2009) which was, in part, a critique on some earlier work by McKitrick and Michaels (2007). This dataset included trends in the model-derived synthetic MSU-LT diagnostics and surface temperatures over one specific time period and for a small subset of model grid-boxes that coincided with grid-boxes in the CRUTEM data product. However, this is decidedly not a ‘land-only’ analysis (since many met stations are on islands or areas that are in the middle of the ocean in the model), nor is it commensurate with the diagnostic used in the Klotzbach et al paper (which was based on the relationships over time of the land-only averages in both products, properly weighted for area etc.).
It was easy for me to do the correct calculations using the same source data that I used in putting together the Schmidt (2009) SI. First I calculated the land-only, ocean-only and global mean temperatures and MSU-LT values for 5 ensemble members, then I looked at the trends in each of these timeseries and calculated the ratios. Interestingly, there was a significant difference between the three ratios. In the global mean, the ratio was 1.25 as expected and completely in line with the results from other models. Over the oceans where most tropical moist convection occurs, the amplification in the model is greater – about a factor of 1.4. However, over land, where there is not very much moist convection, which is not dominated by the tropics and where one expects surface trends to be greater than for the oceans, there was no amplification at all!
The land-only ‘amplification’ factor was actually close to 0.95 (+/-0.07, 95% uncertainty in an individual simulation arising from fitting a linear trend), implying that you should be expecting that land surface temperatures to rise (slightly) faster than the satellite values. Obviously, this is very different to what Klotzbach et al initially assumed, and leaves one of the hypotheses of the Klotzbach paper somewhat devoid of empirical support. If it had been incorporated into their Figures 1 and 2 (where they use the 1.2 number to plot the ‘expected’ result) it would (at minimum) have left a somewhat different impression.
For reference, if you plot the equivalent quantities in the model that were in their figures, you’d get this:
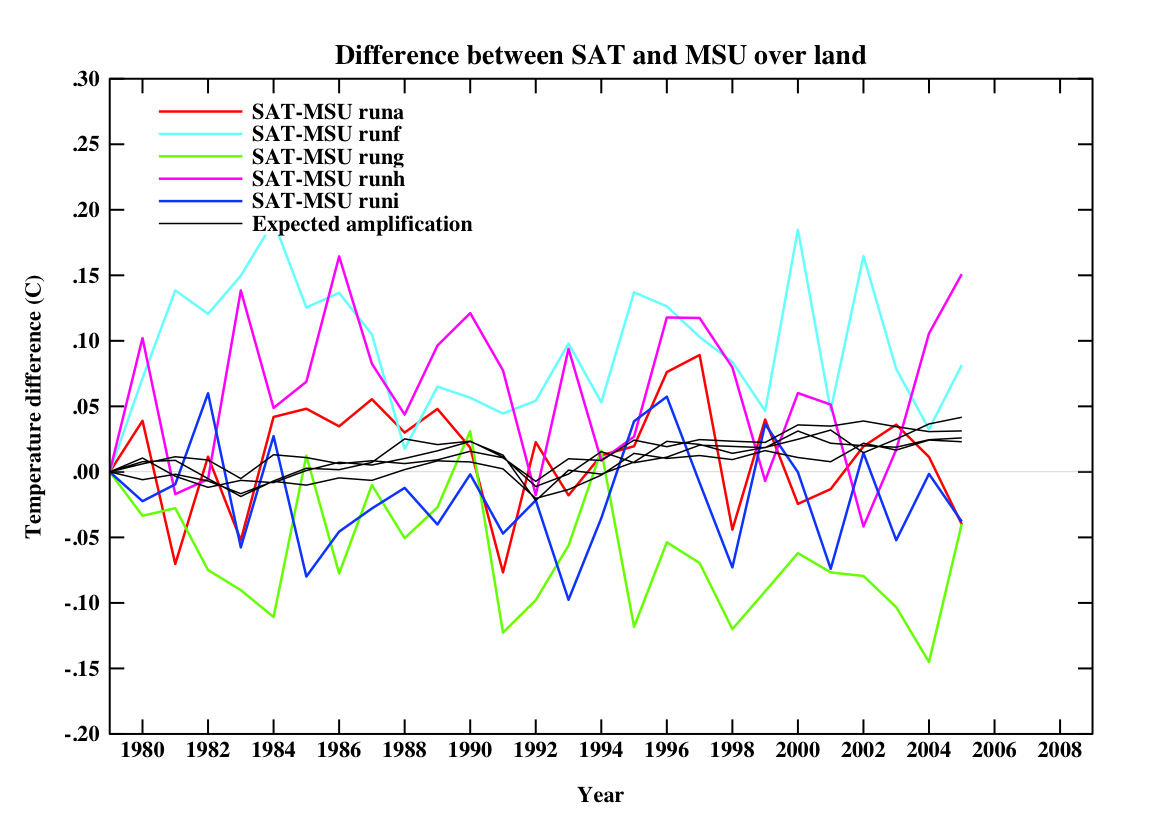
(for 5 different simulations). Note that the ‘expected amplification’ line is not actually what you would expect in any one realisation, nor the real world. The differences on a year to year basis are quite large. Obviously, I don’t know what this would be like in different models, but absent that information, an expectation that land-only trend ratios should go like the global ratios can’t be supported.
Since I thought this was very likely an inadvertent mistake, I let Phil Klotzbach know about this immediately (in mid-August) and he and his co-authors quickly redid their analysis (within a week) and claimed that it was not a big deal (though their reply also made some statements that I thought unwarranted). Additionally, I provided them with the raw output from the model so that they could check my calculations. I therefore anticipated that the paper would be corrected at the proof stage since I didn’t expect the authors to want to put something incorrect into the literature. After a few clarifying emails, I heard nothing more.
So when the paper finally came out this week, I anticipated that some edits would have been made. At minimum I expected a replacement for the inappropriate McKitrick reference, a proper citation for the model output, acknowledgment that the amplification assumption might not be valid and an adjustment to the figures. I didn’t expect that the authors would have needed to change very much in terms of the discussion and so it shouldn’t have been too tricky. Note that the last paragraph in the paper does directly link the non-amplification over land to possible artifacts in the data products and so some rewriting would have been necessary.
To my great surprise, no changes had been made to the above-mentioned section, the figures or the conclusion at all. None. Not even the referencing correction they promised McKitrick.
This is very strange. Why put things in the literature that you know are wrong? The weird thing is that this is not a matter of interpretation or opinion about which reasonable people could disagree, but a straightforward analysis of a model that gives only one answer. If they thought McKitrick’s source data were appropriate, why wouldn’t they want the correct answer?
It’s almost always possible to make some edits in the proofs, and papers can always be delayed if there are more substantive changes required. Indeed, they were able to rewrite a section dealing with a misreading of the Lin et al paper that had been pointed out in September by Urs Neu (oddly, there is no acknowledgment of this contribution in the paper). Is it because they want to write a new paper? That’s fine, but why leave the paper with the old mistakes up without any comment about the problems (and two of the co-authors have already blogged about this paper without mentioning any of this or any of the other criticisms)? If these issues are trivial, then it would have been easy to fix and so why not do it? However, if they are substantive, the paper should have been delayed and not put in the literature un-edited.
I have to say I find this all very puzzling.
Note added in proof: I sent a draft of this blog post to Dr. Klotzbach and he assures me that the non-correction was just an oversight and that they will be submitting a corrigendum. He and his co-authors are of the opinion that the differences made by using the correct amplification factors are minor.
When they go ahead and submit the literature, will the peer review give it a pass or fail in whole? This layman wants to know.
A reply:
http://rogerpielkejr.blogspot.com/2009/11/response-to-gavin-schmidt-on-klotzbach.html
[Response: Way to go Roger! Reduce everything to a triviality of attribution and completely ignore the substance. Just so we’re clear, ‘puzzled’ and ‘surprised’ doesn’t equal ‘angry’ and the issue is not who should get the credit but whether the answer is right. If you are happy putting your name on clearly incorrect work, go right ahead. Readers can judge your credibility accordingly. – gavin]
This is the problem. Many scientists were fooled in the seventies into thinking paranormal activity was real, because they were essentially trusting and couldn’t conceive of, let alone identify, the fraud that was committed. It took James Randi (a former professional magician) and others to point out the fraud, which was obvious to anyone with a similar background.
Your statement here is both refreshing as well as depressing:
“Why put things in the literature that you know are wrong?”
It is refreshing because it is naively honest, which is a good thing. It is depressing because it fails to recognize many people’s motives are less than pure. This is not an insult, without such a straightforward approach, science would never have advanced to where it is today.
As a small and simple blogger, I have wasted far too much time answering the same questions over and over, but I cannot imagine the difficulty scientists must face doing the same thing, with their mandatory (and often self-imposed) requirements of rigorousness and comprehensive documentation.
I realize much of what you must respond too has little validity, and would normally be ignored. Yet because of the political climate, especially in the US, many scientists feel obligated to respond, which results in, as you mention, a great deal of wasted effort that could better be spent elsewhere.
In terms of non-scientists, I have proposed that there are limits on free speech, and perhaps the public promotion of global warming denial might be classified the same as holocaust denial is in some countries:
http://www.selfdestructivebastards.com/2009/09/flat-earth-society-ain-so-bad.html
As far as scientists are concerned, I’m not suggesting a Soviet model. There should be no censorship of any kind. At the same time, gratuitous and flagrantly political publications should be treated as such. We must allow data, evidence and rationality to be the last word. Attempts to subvert the scientific process should be identified and dealt with appropriately. As I mention in the above article, this is not an academic issue (no pun intended), the lives of millions are at stake.
Just to be clear, I am absolutely not interested in having this comment thread devolve into a pointless round of misrepresentation, misquotation and mudslinging that seem to have enveloped other parts of the climate blogosphere in recent weeks. Please stick to substantive points and leave the distracting noise to people who have nothing better to talk about.
gavin,
I have seen the rationale given in Klotzbach et al. in public talks by John Christy concerning the usage of nighttime temperatures in estimates of global mean temperature anomalies. Specifically, he has made reference, several times, to a warm bias introduced in using the night-time boundary layer in detecting the accumulation of heat from GHG’s. Perhaps you can elaborate on the importance of this effect or if it’s of consequence?
[Response: It’s a complete red herring. If anyone had used the surface temperature record to estimate the accumulation of heat from GHGs then they may have had a point. But despite the fact that they have made this point numerous times, they have never once shown any paper or study that made this assumption. Levitus et al (2001) for instance used the reanalysis heat content changes directly in their assessment of heat content changes. Thus one is left with the impression that they are simply using this as a tactic to try and imply that there is something wrong with the surface temperature record as the surface temperature record. There may well be issues with this metric, but variations in PBL physics have nothing whatsoever to do with it. – gavin]
Gavin,
As the CTO of a high tech company, I often get frustrated when technical discussions and debate expand to a nontechnical audience. When that happens, the perspective or opinion that wins is often not the correct one. One big factor for nontechnical folks is how each side comports themselves. Arm waving, ad homenium attacks, and sloppy data are often noticed by the audience and can hurt ones position. Hyperbole often is noticed as well. In this case Klotsbach et al gets a strike for not changing their submission to reflect your data and its effect on their numbers. It makes them look sloppy.
What this dispute does confirm is that the peer review process is cumbersome and ineffective. Webblogs help but are not the solution. For me I like the idea that scientists with different points of view should produce a joint paper detailing the points of contention and their individual supporting evidence. Why not do that?
Your search engine isn’t working for me so I’m asking this here: Dave X handed me a quotation from Technology Review for 15 October 2004. It says that Stephen McIntyre and Ross McKitrick found a flaw in the computer program that produced the hockey stick. Dave X thinks that all of your data came out of a computer simulation, not from the actual data that I know that you used. Could you tell me the right files to download and print out for Dave X?
Hi Gavin
when I look at the folowing trends for land 1979-2008
NOAA :0.315°C/dec
GISS : 0.183°C/dec
RSS LT : 0.203°C/dec
the amplification coefficient is 0.64 for NOAA-RSS and 1.11 for GISS-RSS.
So, I suppose that there are some ocean influences in the GISS data.
But, I don’t know in fact.
Can you explain a little more?
[Response: Not sure what numbers you are actually quoting from (it matters). Cites? Note that indices that just use met stations are not ‘land-only’. – gavin]
Gavin: I sincerely hope your statement at point 4 will be chosen as the new motto for RC, all its contributors, and all its commenters!
A reply to your post and comment #2
http://pielkeclimatesci.wordpress.com/2009/11/12/comments-on-gavin-schmidts-statement-regarding-the-paper-klotzbach-et-al-2009/
[Response: Hi Roger, Please point me to one study anywhere in the literature which has used the surface temperature record to infer changes in the heat content of the atmosphere. Just one. – gavin]
Hello BoulderSolar,
Don’t you think it is an over generalization to claim the “…peer review process is cumbersome and ineffective.” based on any specific example? That tars and feathers a process that is self corrective (and this is the important point) over time? I know people are impatient and good at leaping to conclusions using simplistic black or white views of the world but I think the responses to this original paper, such as Gavin’s post above, are part of the process. Who knows? Papers have been effectively dismantled by the science community and in this case only the non experts will use Phil Klotzbach’s as a source as the data have now become suspect.
Also,
One of the original posts on Real Climate was about the peer review process and is well worth the time to read BoulderSolar.
Wow.
Looking at the difference in magnitudes from the published table 1 from Kea09, AND the altered table 1 that the authors redid with Gavin’s input which was posted during August in RPJr.’s blog here, AND seeing how the published figs 1 & 2 differ with the figure posted by Gavin here…It’s a pretty big stretch for the authors to conclude that “the opinion that the differences made by using the correct amplification factors are minor.”
Hi again Gavin
in response to #8,the sources are
for NASA :
http://data.giss.nasa.gov/gistemp/tabledata/GLB.Ts.txt
for NOAA
ftp://ftp.ncdc.noaa.gov/pub/data/anomalies/monthly.land.90S.90N.df_1901-2000mean.dat
and for RSS :
http://www.remss.com/data/msu/monthly_time_series/RSS_Monthly_MSU_AMSU_Channel_TLT_Anomalies_Land_v03_2.txt
[Response: For GISS the data you should be looking at is http://data.giss.nasa.gov/gistemp/graphs/Fig.A4.txt -gavin]
thanks Gavin
With this source the trend is 0.279°C/decade (1979-2009)
It’s nearer NOAA data.
I don’t understand the difference between the source I cited and “your” source.
But, if we take 0.28°C/dec for land, the difference with RSS TLT temperature is greater.
I understood that the models give an amplification factor of 1.
But If the data are now good the amplification factor is only 0.71.
[Response: Not sure. Some of it might be related to the latitudinal masks but you’d probably want to look at the full lat-lon data with consistent land masks to do this properly. – gavin]
add to my precedent post.
I computed the amplification by comparing trends but I think you are speaking about individual data, not trends.
Is it correct?
The corrections in the amplification factor obviate the conclusions of Klotzbach et al. I never did get around to doing a post on this, but in comments at James Annan’s blog, I made the following points, which still seem relevant to me.
http://julesandjames.blogspot.com/2009/08/curiouser-and-curiouser.html#comments
I’m particularly mystified at John Christy’s participation in this. He of all researchers should have realized that the land amplification facor was incorrect, even before Gavin Schmidt spoke up.
Dumbo Admission:
I have no idea of the issues at stake in this.
What is the point of the original study? What issue or issues does it address? Is it a substantive study or is it a curiosity designed for its rhetorical use?
#15
Gavin raises a valid point, namely that land masks may not be exactly the same in all data sets.
But there do seem to be significant discrepancies in differential rates of warming between land and ocean in the three surface data sets. Like the UAH-RSS discrepancy, this is a confounding factor for any analysis of tropospheric amplification that purports to pinpoint a consistent source of discrepancy between expected and observed amplification.
By the way, here is a link to the table of corrected discrepancies (with the older calculated discrepancies in parentheses).
http://2.bp.blogspot.com/_0ZFCv_xbfPo/SonBpl5IqRI/AAAAAAAAADw/KjWxz3Iqb-I/s1600-h/KlotzRespTable.jpg
Notice that when the corrected amplification factors are used, all comparisons now show significant difference, except HadCRU-RSS over land.
Klotzbach’s assertion that the correction engenders only “minor” differences can not be taken seriously.
Re: 17…
I also noted the discrepancy between UAH and RSS in the paper. Correct me if I’m wrong, but isn’t RSS the group that pointed out and correced the (substantially) flawed analysis of UAH on the satellite data way back when?
Here’s another way to look at it, based on ranking of discrepancies between expected and observed amplification (using an avearge for the two satellite sets).
Uncorrected amplification:
1) NCDC – UAH/RSS Land
2) HadCRU – UAH/RSS Land
3) HadCRU – UAH/RSS Ocean
4) NCDC – UAH/RSS Ocean
With corrected amplification:
1) NCDC – UAH/RSS Land
2) HadCRU – UAH/RSS Ocean
3) NCDC – UAH/RSS Ocean
4) HadCRU – UAH/RSS Land
Hi Gavin – In response to your reply to comment #10, the issue is the vertical distribution of positive temperature trends that is used as a measure of radiative forcing. There are many papers that discuss this, including what I presented in my post this morning [http://pielkeclimatesci.wordpress.com/2009/11/12/comments-on-gavin-schmidts-statement-regarding-the-paper-klotzbach-et-al-2009/]; i.e.
“Radiative forcing [RF] can be related through a linear relationship to the global mean equilibrium temperature change at the surface (delta Ts): delta Ts = lambda * RF, where lambda is the climate sensitivity parameter (e.g.,Ramaswamy et al., 2001).
The lower troposphere is also expected to have a linear relationship to the radiative forcing although amplified relative to the surface; e.g. see Figure 5.6 for the tropics in CCSP 1.1. Chapter 5.”
As another example, the National Research Council report[http://www.nap.edu/openbook/0309095069/html/] on pages 19 has the text
“According to the radiative-convective equilibrium concept, the equation for determining global average surface temperature of the planet is
dH/dt = f – T’/lambda,
where H is the heat content of the land-ocean-atmosphere system and T′ is the change in surface temperature in response to a change in heat content….. In principle, T′ should account for changes in the temperature of the surface and the troposphere, and since the lapse rate is assumed to be known or is assumed to be a function of surface temperature, T′ can be approximated by the surface temperature.”
[Response: I’m sorry but I don’t follow this at all. The relationship between radiative forcing and surface temperature defines climate sensitivity. You don’t come up with climate sensitivity independently of that definition and then redefine what Ts means. Please read Hansen et al (2005) for discussions of the various issues in that definition and the potential variation in that definition (or rather the definition of the effective forcing) dependent on different forcings. There is nowhere in that paper, or any other, that relies on some assumption about atmospheric heat content anomalies. Not a single one. The quote from the NRC report is, frankly, a little odd, since it is bizarre that anyone would attempt to calculate the surface temperature (which is well observed) using the atmospheric heat content and climate sensitivity (which are not). So can you point me to an independent study that has attempted to do this? – gavin]
To return to the finding of our paper, are you concluding, in contrast to our finding, that there are no statistically significant differences in the lower tropospheric and surface temperature trends?
[Response: Of course there are, but this has been known for years. The issue is whether those differences are important or expected as has been stated in multiple papers prior to this one. Half of your paper using an incorrect expectation (based on the McKitricks’ inadvertently mistaken calculation) and the other half doesn’t address the issue at all (since no real physical process in the PBL can cause a bias in the surface temperature records). At best, you could be arguing that improvements to the realism of the PBL physics in the models would change the expectation of the difference in MSU and surface trends, but this is not something you address at all. – gavin]
Gavin, point taken.
I hate to be off-topic, but did anyone see the November 2009 issue of Physics Today? Scafetta and West posted a letter in response to Duffy, Santer and Wigley’s January 2009 article, in which they provided a rebuttal of Scafetta and West’s March 2008 article on solar variability and climate change. In their letter, Scafetta and West actually bring up the petition of 30,000 scientists in their defense, saying there is no convincing evidence of anthropogenic global warming. Shocking, but not surprising!
[Response: Actually they do much worse. They claim that the evidence for Milankovitch forcing of the ice ages implies that the planet is hypersensitive to solar irradiance variations. They claim that mainstream science has declared that only humans can change CO2. They cite the NIPCC as a ‘comprehensive research review’ (ha!). Oh dear. – gavin]
Deep Climate wrote:
Personally I didn’t know why globally there should be greater warming in the lower troposphere than at the surface. I only knew that there should be.
However, Gavin had written in the main essay:
… and I knew that there should be a drying out of the continental interiors.
Oceans are by far the greatest source of moisture. But having a greater thermal inertia than land (in part no doubt to ocean circulation), they warm more slowly than land. Now since relative humidity remains roughly constant at the ocean surface and the air’s capacity to hold water increases with temperature, relative humidity will actually decrease over land, particularly as one enters the continental interiors.
But if the amplified warming of the lower troposphere relative to the surface is a function of the moist adiabat, what this would suggest is that in the continental interior the lower troposphere should warm more slowly than the surface. After all, what causes nights to warm more quickly than days as the result of enhanced greenhouse effect is the greater dependence of night-time heat loss upon thermal radiation rather than the moist air convection that dominates during the day.
Moist air is lighter air, and moist air rises. And the process of condensation where moist air forms clouds is the process by which the latent heat is released — warming the lower troposphere while cooling the surface. As such, the drying out of the continental interiors should result in a reduction in the rate at which heat is transfered from the surface to the lower troposphere.
And this seems to be what Gavin is describing — although it is still within the 95% range.
Gavin had written in the main essay:
Is the mistake minor or more than minor?
It seems that the main thrust of the paper (I only read the abstract) is to sow doubt about the scientific observations relating to global warming — which would make the errors major. Who reads past abstracts anyway?
It makes it seem the ground observations may be wrong, since as everyone knows satellites garner more public respect than boy scout weatherbird stations on ground. Ground people just lose in an “expert contest” with unmanned instrumentation on hi-tech flying machines. And most people (like me) don’t know much about “moist adiabat” or “convection” either.
The only we have to go on, besides RC, is one author’s name is “John Christy,” which for those laypersons in the know immediately makes it look like its from denialist-ville, or from the “how can we twist and tweak the ‘science’ to make it look like AGW is not happening” folks.
With respect to your statement that “No one calculates the surface temperature (which is well observed) using the atmospheric heat content”. I do not know how you made this bizzare interpretation of the quotes from the reports I provided to you!
[Response: Your quote stated exactly that the equation for determining T of the planet involved an equation using the rate of change of the heat content, the forcing and lambda. I do not recognise that anyone determines T in such a fashion. -gavin]
In your original post, you wrote
“Please point me to one study anywhere in the literature which has used the surface temperature record to infer changes in the heat content of the atmosphere”.
I have done that in the NRC (2005) report and the CCSP report which is in the chapter that Ben Santer authored.
[Response: Sorry, but no. I have no objection to the CCSP quote in the slightest. But it is completely un-responsive to my question since it does not address atmospheric heat content at all. And despite the NRC quote (on which you were a co-author) I still don’t see anyone actually calculating H using T. Show me one such calculation. – gavin]
Now that I have answered your challenge to the question in your original post, you have changed the question to “”No one calculates the surface temperature (which is well observed) using the atmospheric heat content”. Of course, we don’t and no one has claimed this! You have mis-represented what I wrote with this later claim.
[Response: I just read what you quoted. I agree it would be a bizarre thing to do (progress!). – gavin]
The authors of the [with the”odd” quote] NRC report, besides myself, were Daniel Jacob, Roni Avissar, Gerald Bond, Stuart Gaffin, Jeff Kiehl, Judith Lean, Ulricke Lohmann, Michael Mann, V. Ramanthan and Lynn Russell. For you then to state that the “quote from the NRC report is, frankly, a little odd” simply means you disagree with it. The peer reviewed NRC report assessed the climate communities perspective on the surface temperature anomaly and what this metric means in terms of radiative forcing and climate system heat changes. Your disagreement with the statement in that report is with a wider community than just the authors of the Klotzbach et al 2009 paper.
[Response: Had I peer reviewed it, I would have questioned it. I didn’t, and so there it is. I’m perfectly happy to be in disagreement with a few lines of an NRC report (these are good, but not infallible). However, there is still not a single calculation that uses this formulation that I can see. If this was so widely supported by the community, there would be an actual paper that used this equation to calculate atmospheric heat content anomalies surely? Yet there is not. – gavin]
On your statement that “Half of your paper using an incorrect expectation (based on the McKitricks’ inadvertently mistaken calculation) and the other half doesn’t address the issue at all (since no real physical process in the PBL can cause a bias in the surface temperature records)”
indicates that you still do not accurately report on (or understand) our paper. First, Ross McKitrick’s calculations were not mistaken but used a set of data from your GISS model output.
[Response: Unfortunately, it appears to be you that just doesn’t understand. The subset of model output that McKitrick used (which was provided for a completely different issue) is not capable of giving the metric you want. It doesn’t matter what model it came from. I did do the calculation that you wanted and let you have the full raw data to check it. The answer is very different from what you got from McKitrick. Did you find my calculation in error perhaps? If so, let me know and we can see what the issue is. In the meantime you appear to be arguing with me over what the GISS model shows for amplification of the MSU-LT trends over land. There is no argument here – McKitrick’s answer is not correct (though his error was inadvertent). Your refusal to take the correction on board appears to be quite deliberate. Why? – gavin]
Moreover, to state that “half” of our paper depends on that calculation is wrong. Our results are robust even without using an amplification.
[Response: This makes no sense. What is your result then? Comparing two trends without having a reason to think about how they should be related allows you to conclude nothing. – gavin]
Second, the bias in using the surface temperature trends is in its interpretation as a metric of temperature trends above the surface. We have clearly shown (in several of our papers) that a systematic warm bias exists when the surface temperature measurements are in a stably stratified boundary layer, and the lower troposphere warms. The Klotzbach et al 2009 paper examined this issue and concluded this is a robust result.
[Response: But (and now we are apparently back to square one), no one has ever made that interpretation! If they had, there might be some point to this, but they haven’t. The only paper I know that used the energy content of the atmosphere in a calculation (Levitus et al, 2001) used the energy content metric directly from a reanalysis. Perhaps you know of another example? – gavin]
As we have written before, we look forward to a formal exchange with you on this issue in the peer-reviewed literature as part of a Comment/Reply.
[Response: I tried really hard to help you guys out with this one, under the naive assumption that you would want to get it right all on your own. I didn’t have to check McKitrick’s calculation, let alone do the proper calculation myself and embroil myself in yet another pointless debate. You chose (are choosing) instead to persist in error despite having the right answer given to you, and the tools at your disposal to check the calculation any which way you want. Dr. Klotzbach said that you were going to put in a corrigenda and I urge you to do so and to make it substantive. – gavin]
Scafetta and West want the orbital forcing alone to explain all of the ice age variations? What climate sensitivity would that imply? What temperature rise and drop would they then expect through the 11-year solar cycle? This is fascinating.
Re Jeffrey Davis #18
In terms of the gold that a climate science denier might find in the paper, at the very least, they could argue that the fact that the troposphere isn’t warming more quickly than the surface shows that the climate models are unreliable — even though the models predict just the pattern of warming that we see — with the troposphere warming more quickly than the surface over the ocean but less quickly than the surface over land. But there could be bigger payoffs.
Previously, when it appeared that the tropical troposphere was warming no more quickly than the surface, they claimed that the view that the tropical troposphere would warm more quickly was specific to warming due to an enhanced greenhouse effect. They concluded that therefore with the tropical troposphere warming no more quickly than the surface, the warming trend had to be due to something other than the accumulation of greenhouse gases and enhanced greenhouse effect. Solar activity? Cosmic rays? Hot-tempered leprechauns? Didn’t matter so long as it wasn’t greenhouse gases. But they could make the same argument here.
Of course none of this is the intent of the authors of the paper and they would most assuredly find such misinterpretations of their work most distressing.
Roger Pielke Sr. opines:
We have clearly shown (in several of our papers) that a systematic warm bias exists when the surface temperature measurements are in a stably stratified boundary layer, and the lower troposphere warms.
One of these studies can be assumed to be the infamous Lin et al 07 paper based on the OKC mesonet, which RPSr. has often referenced as observational support for the Pielke & Matsui 05 paper (which is ALSO frequently used by RPSr.) for this particular hobbyhorse of his.
Yet, he writes this after being corrected on Lin et al 07 by Urs Neu:
“The actual bias from the Lin et al. data under light winds at night is a cold bias. The -0.46 +/- 0.29ºC per 10 meters per decade in Figure 3e means that the lapse rate at night became steeper. If this bias was representative of the land areas of the Earth, it would mean that the IPCC underestimated the magnitude of the IPCC estimate of global warming.” (my emphasis)
It gets better – despite this, RPSr concludes in the same blog post, in his favorite bold font, with underlined text no less:
“In summary, the error in my interpretation of the Lin et al lapse rate trends does not alter the conclusions in Pielke and Matsui 2007 (sic) and Klotzbach et al. 2009. We present scientific evidence that any effect which reduces the slope of the vertical temperature profile within a stably stratified surface boundary layer will introduce a warm bias, while any process that increases the magnitude of the slope of the vertical temperature profile in a stably stratified surface boundary layer will introduce a cool bias, remains a robust finding based on boundary layer dynamics.”
So is it a warm or cold bias then? Dr. Pielke, I’m sorry, but I’m terribly confused by your selective logic. Your only observational study contradicts your rather unconvincing theoretical 2005 paper. And now Gavin rightly points out that the Klotzbach et al. paper has a rather peculiar and apparently significant booboo, possibly negating the above conclusion on your blog post.
One thing’s for certain. That corrigendum will be an interesting read…
Sorry, this is just a little off topic.
I have been having trouble for over a year in getting into the http://www.remss.com site.
I would really like to see the figures showing tropospheric temperatures, and also the figure that shows SST by latitude over time. (That one is really scary.)
I’m in Brazil, and I have this problem with no other U.S. site.
I have even had to ask friends to go to the site and copy figures for me.
Does anyone else have the same trouble?
About this lack of correction by the authors — if it happens again with the same bunch, just indicate your concerns directly to the journal’s editor (but you’ve probably already thought of that).
#32
Here is an email I wrote to JGR back on Sept. 9:
Here is the reply:
Notice that the JGR response did not even address the notification of flaw issue. From this I concluded that the only way to get a revision was to alert the authors, as Gavin did.
I have to say, this is yet another black eye for JGR, on the heels of McLean et al and Lindzen and Choi.
This emphasizes the virtue of the open review process at such journals as Climate of the Past.
[Response: Only if you can get the authors to put themselves out there. – gavin]
Deep Climate,
Its not possible for the journal to adjudicate if there is a “flaw” in a paper that is about to be published just based on the say-so of a correspondent. If Gavin had written to the journal and complained of a flaw, should the editors have withdrawn this paper? Clearly the authors don’t agree with Gavin, and the peer reviewers did not pick up the flaw he noted, so either the reviewers were ignorant or careless, or the flaw is not obvious.
In this case, the proper thing to do is write the authors, as Gavin has done, and try and get them to fix their mistake. If they don’t, either because they are obstinate, or because they do not accept the argument given, then the paper will be published. If the point is important, then Gavin should either write a correspondence, which will be peer reviewed and to which the original authors can respond, or he could write a full paper. In either case, science has been served because a point that got past two or three peer reviewers has been a) shown to be important, and b) clarified or corrected.
Peer review is not a perfect system, but its relatively self-correcting. I expect it is strong enough to withstand a little “muddying”.
#35 Jody Klymak
I realize my foray was somewhat naive. I was hoping that JGR could be spared further embarrassment on the heels of the McLean et al debacle. Note as well that I was also asking JGR to confirm if the *authors* could withdraw the paper at that stage.
But as Eli implies, the real issue is that JGR’s peer review process appears to be broken. I’m not sure that science or public discourse is well-served by the publication of such clearly sub-standard papers as Klotzbach et al and McLean et al, although I suppose most of the damage will be to JGR’s reputation.
The process for selection of reviewers is not clear from my reading the AGU site. Perhaps there is a problem with that process, for example if authors can propose or nominate reviewers. But without more detail on how reviewers are chosen, it’s impossible to comment further.
I’m sure Gavin will submit a comment. But first he’ll have to wait for the corrigendum I suppose.
It seems that GS thought he had an understanding with the authors after all that correspondence.
Now it is going to be “once bitten, twice shy.”
If such a thing happened to me, just once, the next time it looked like occurring again, I would keep very meticulous recorded notes and records of the correspondence, and I would certainly get them to the journal editor.
These things are not as cut and dried as they may appear to be in the “Instructions to Authors” or the response given to Deep Climate (#33). I say this as a former technical editor for Elsevier Science Publishers in Amsterdam. Well, that was 25-30 years ago, and this is now, but the from manuscript to in print journal article still has flexibility in the process.
“The process for selection of reviewers is not clear from my reading the AGU site. Perhaps there is a problem with that process, for example if authors can propose or nominate reviewers. But without more detail on how reviewers are chosen, it’s impossible to comment further.”
AGU journals ask for nominations, and (it seems) editors rarely use their own initiative to stray outside that list (of course, some eds may do so). So all an author has to do to get something published is sign up a few friends who will willingly wave sub-standard research through the process if its conclusions suit their agenda.
FWIW, not so long ago I reviewed a particularly nonsensical paper for an AGU journal, I rejected it firmly twice, with clear explanations as to the error, and it was published anyway. I never received any notification of the decision or reasons behind it from the editor, the first I knew of it was when I saw the paper in print. I believe it will sink without trace as the whole concept is nonsense and has no significant implications, thus have no plans to write any comment. Peer review is only one small step towards an idea becoming established in the scientific community. In the context of this current debate, I think it is reasonable to predict that comment or not, Klotzbach et al 2009 will have little influence on future research directions and synthesis reports.
#37
I followed the exchange pretty closely at the time. The tone at the Pielkes’ site went from honey dripping invitations to collaborate to vituperation pretty quickly.
I had no impression that the authors actually intended to correct the paper, or that they even understood how monumental the amplification factor error was.
Frankly, one aspect that was a red flag was the immediate release of correspondence by Pielke Jr. That was a decidedly odd move under the circumstances.
#39 James Annan
I agree K et al will have little scientific impact, but it will enter the contrarian canon along with a handful of other papers that get touted over and over again in the blogosphere. That’s a valid motivation to counter it, in my opinion. The Foster et al response to McLean et al was salutary for the same reason.
Thanks for your insights into the AGU publication process. It explains a lot.
Gavin, I was one of the co-authors of the paper. In response to your assertion that surface temperatures have not been used to track the heat content of the atmosphere. Consider the following. Have historical surface temperatures been used as evidence of global warming? Is the threat of global warming only about surface temperatures? (Remember you don’t get any feedbacks if only the surface has warmed.} This implies that the global change community has always used surface temperatures as a metric (although not 1 to 1) for temperature change in the deep atmosphere.
[Response: Perhaps you misunderstand me. I would not claim that heat content and upper atmosphere temperatures are unconnected to the surface trends. But your papers claim of a ‘bias’ in the surface temperature record *if* it is used as a linear predictor of atmospheric heat content only makes sense *if* indeed people had used it in that sense. I can find absolutely no evidence for that. -gavin]
What the global change community (through the NRC and CCSP reports) always asserted and then used to discount the radiosonde and UAH satellite trends was that the deep troposphere should not warm less than the surface and in fact based on models globally the troposphere should warm 1.2 more (the amplification factor). Thus, global amplification factors that Klotzbach et al. used were in keeping with the past usage.
[Response: this is fine for the global temperatures. You however decided that this applied to land-only averages, for which previous estimates don’t hold (for clear physical reasons), based in part on a calculation which both you and McKitrick misinterpreted.]
Now your GISS amplification factors show over land the amplification is of order 1. rather than the 1.2 used. It is ironic that in all of the physical arguments in our paper we are actually arguing that due to sensitivity of the stable boundary layers that actual amplification factors should be less than one. In fact I suspect that the real amplification factors are well less than 1.0. Thus, to have an amplification factor of 1.2 is certainly wrong. While the paper posed the argument that using a model 1.2 amplification factor we reject that the troposphere and surface trends are the same. In fact our real argument turned around is that we reject a model amplification of 1.2 and even 1.0 over land since that is inconsistent with the observational analysis of observed ratios of surface and lower troposphere trends.
[Response: That would have been fine, though the structural uncertainties in the MSU records would have been an important caveat. ]
We never argued that the surface temperatures were wrong. We said they were biased if all you consider as having warmed the surface was greenhouse gas forcing.
[Response: That doesn’t follow, and in any case you did very strongly indicate that the surface records were contaminated. Nowhere in your paper did you discuss attribution, and so whether the trends were being caused by GHGs or solar or whatever was not tested or addressed.]
GCMs have a terrible time in resolving the physics of the stable boundary layer. The GCM model performance in warming in minimum temperatures through the long historical runs is not good at all. Thus, I contend that as we add more realism in terms of land use change and stable boundary layer resolution in GCMs that the model amplification will continue to go down over land. To the point that we will finally accept what the NRC report and CCSP would not – that surface temperatures have warmed more than lower tropospheric temperatures.
[Response: If the answer that you seem to prefer here had been explicit in your paper, there would have been no problem, and I don’t see why you would have been so hostile to the corrected calculation I made. Instead your co-authors seem to feel differently. Perhaps you should have a quiet word. – gavin]
It would be nice if just once McI would “audit” a “denier” paper. The last two highly touted ones, McLean, et. al. and Klotzbach, et. al. both had fatal flaws which were far worse than Mann, et. al. (2008) or Briffa, et. al. (2008).
Picking nits vs. utter destruction.
re 5 and others
The effect which should introduce a bias in the surface temperature record is the following:
The nocturnal boundary layer at light wind conditions decouples the surface from the troposphere above through cooling at the surface and building a so-called inversion (where temperature increases with height). The proposed effect is, that if the cooling at the surface and thus the building of the inversion is altered over time by any effect (be it GHGs, clouds, vegetation cover etc.), the difference between surface temperature and temperature of higher levels might change. This would mean that trends at the surface and in layers heigher above might be different.
There are several problems with this theory:
– This so-called bias only refers to the difference between surface and lower troposphere temperatures, and not to surface temperature as such
– This effect only occurs in some regions during light wind nights. There is no evidence, that this part-time and locally restricted effect has any significant effect on global temperature.
– This bias can be positive or negative and depends on the trends of the influencing factors. Klotzbach et al. just assume that it is a warm bias, without any observational evidence at all. In contrary, the only observational evidence shows a cold bias (as has been corrected for the Lin et al. paper after some e-mail discussion with the authors).
Although I think there might be such an effect (that’s where I agree with the authors), it is probably very small, it might be in both directions, and there isn’t any evidence for it by now (that’s where I disagree with the authors).
[b]
It would be nice if just once McI would “audit” a “denier” paper.
[/b]
Funny that.
Re Deep Climate 17:
You should also add NOAA NESDIS satellite analysis to the group with higher tropical troposhere trend compared to UAH or RSS:
http://www.star.nesdis.noaa.gov/smcd/emb/mscat/mscatmain.htm
http://www.star.nesdis.noaa.gov/smcd/emb/mscat/mscat_files/Zou.2009.ErrorStructure.pdf
I also wonder why the author of this paper included only the two MSU analysis with lower tropical trends and excluded vinnikov-grody and SNO analysis.
My last comment here:
Our paper depends upon a warming trend accompanied by increasing greenhouse gas concentrations. It is perfectly consistent with anthropogenic greenhouse warming (in fact it depends on it), and may suggest a mechanism for better reconciling divergent temperature trends at the surface and lower troposphere (See Urs Neu above at #43). The details will be worked out in the literature and our work is certainly not the last word. That is how the peer review process works. I hope that Gavin does submit a comment as that is how science works.
[Response: Science would work a lot faster if authors corrected their own work when errors were found. – gavin]
[edit]
[Response: I’m not in the least bit interested in your bruised feelings because of some manufactured slight that you perceive in the comments. In any case, commenters are responsible for their own words and publication in no way implies that they reflect the views of me or RC as a whole. I’m pretty sure that goes for your blog too. – gavin]
Also, the invitation to Gavin to collaborate on a subsequent piece remains open, however, so far he has declined the invitation. Surely that would be a good opportunity to work together rather than through blogs, which this post shows are not a particularly good way to advance understandings.
[edit]
[Response: That would be great, except… oh, I don’t know,… maybe the fact that you’ve recently called me a liar and a thief and accused me of ‘baiting’ our readers to be mean to you, all the while completely ignoring the pretty mundane substance of the complaint here in lieu of pretending this is just about me wanting a citation in your paper? Nah, that couldn’t be it.
If I might offer a little advice, you would do well to try and emulate your co-authors, particular your father and Richard McNider (above), who provide good object lessons of how people can disagree over substance and yet discuss issues without getting personal and without misrepresenting the other person’s statements. Try it and see. Who knows where that might get you? Thanks! – gavin]
#43 I read back through the chain of paper, and in Pielke and Matsui (2005) which is really a thin thing that comes down to calculating the potential temperature profile at a height z (more or less quoting here) Δθ(z) for a “continually turbulent stable clear night boundary layer over a flat surface”
Drive the wind speed to zero and you end up with a zero thickness scale length, an infinite temperature difference between ground and the layer a micron up. In other words, at some point this little model fails. It probably is not too bad for the upper range of the wind scale used, but, of course, in that case the scale length will also be larger, e.g. the layer thicker and the lapse rate not as extreme.
If this is correct, the entire house of cards falls, because the contribution from low wind speeds is overestimated drastically.
Roger Pielke Jr. writes: “Surely that would be a good opportunity to work together rather than through blogs, which this post shows are not a particularly good way to advance understandings.”
I hope Roger will keep that in mind before continuing to promote the various manufactured controversies and rantings of the McIntyre/Watts/contrarian crowd, almost exclusively a product of the blogosphere and not the peer-reviewed literature.
I also tend to concur with Gavin that scientists should work to correct clear errors identified before publication.
I am reliably informed that a couple more minor corrections might want to be made. The quotes and descriptions attributed to Santer et al (2005) appear to actually be from a much earlier (uncited) paper Santer et al (2000) – incidentally well before the last round of corrections to the UAH MSU data. And this is an amusing typo: apparently the “unexplained difference … still exits” (paragraph 4) – where does it go, we wonder? ;)
Interesting post by Pielke Sr., which mentions the Santer 2000 paper, claiming it backs his assertion of a significant surface record bias, and inappropriately compares it to the IPCC 2007 conclusions.
http://pielkeclimatesci.wordpress.com/2009/08/28/the-santer-et-al-2000-view-of-the-importance-of-error-in-the-surface-temperature-record-in-their-paper-differential-temperature-trends-at-the-surface-and-in-the-lower-troposphere/
Missing entirely from Pielke’s post is the fact that 2000 was before the major diurnal drift correction. UAH had a decadal trend of only 0.044 C as late as Jan. 2001.
http://www.nsstc.uah.edu/data/msu/t2lt/readme.18Jul2009
He then goes on to complain that the mainstream media has not yet covered his “clearly documented warm bias”, and uses it as an example of how most journalists don’t cover any perspectives that deviates from the IPCC. Is he serious? What world does he live in? If only journalists fairly represented the balance of evidence (as indicated by the IPCC report, based on thousands of peer-reviewed studies), rather than constantly promoting every contrarian study that slips through the cracks.