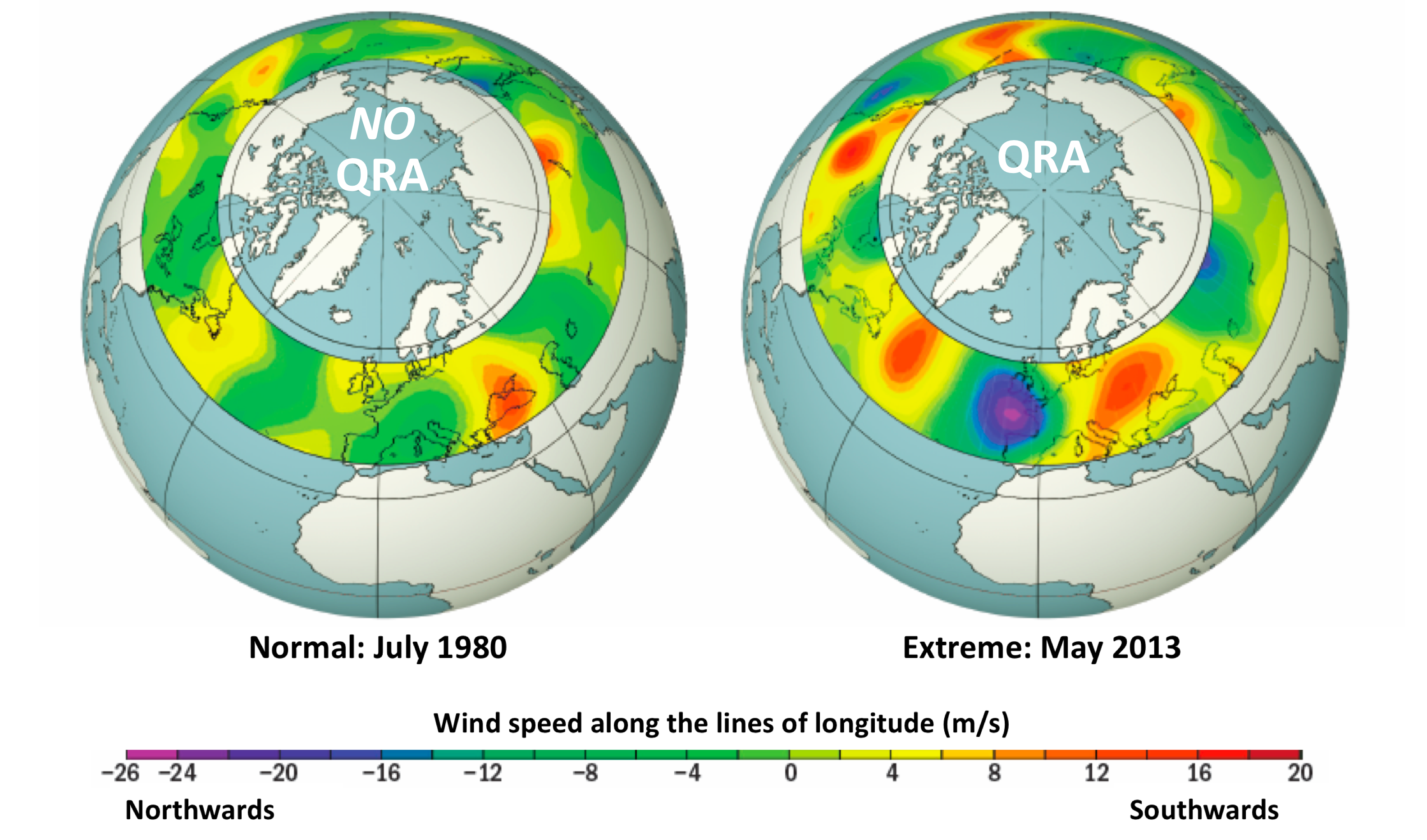
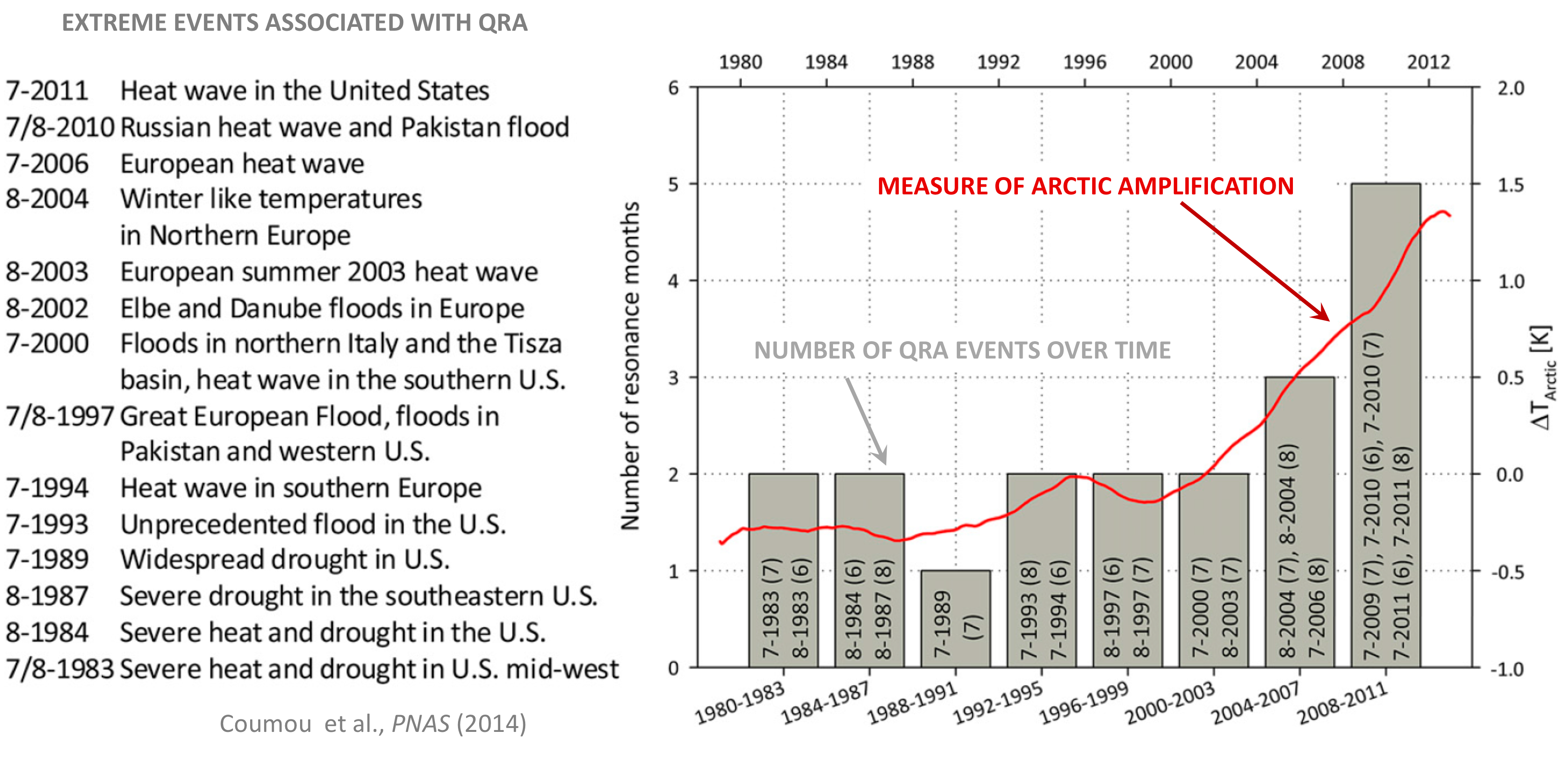
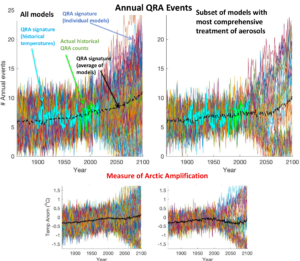
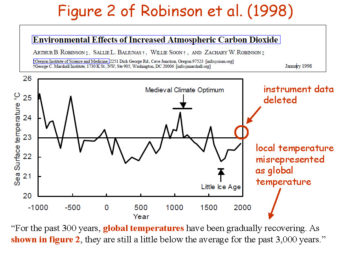
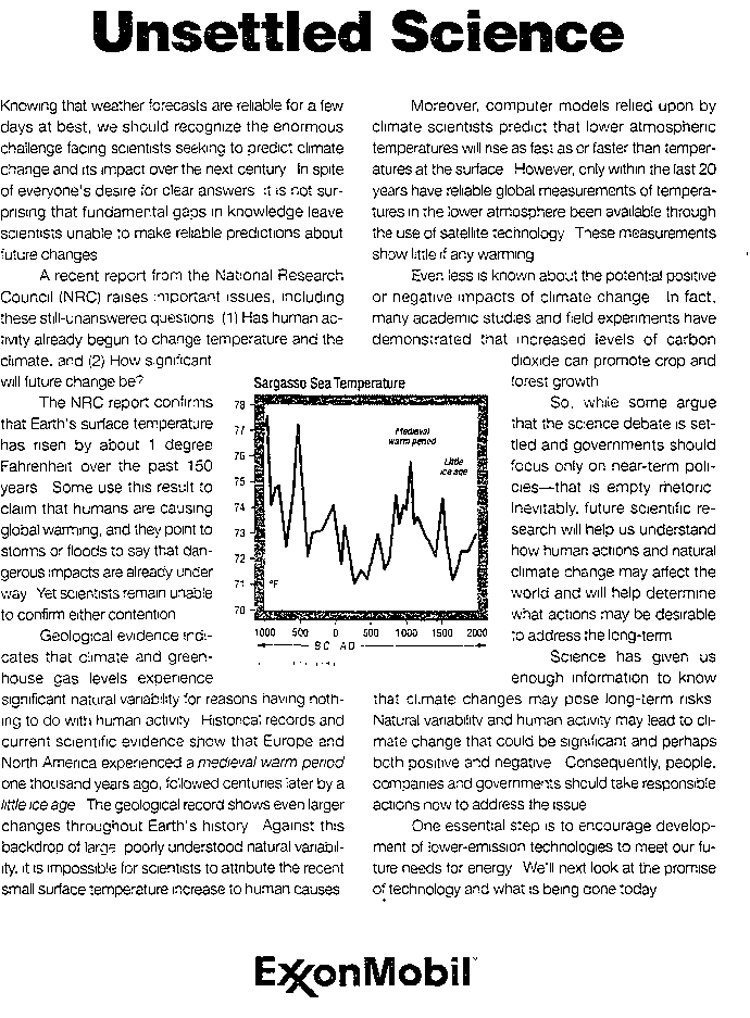
Two decades ago, the so-called “Hockey Stick” curve, published in 1999 by me and my co-authors (Mann, Bradley and Hughes, 1999), was featured in the all-important “Summary for Policy Makers” (SPM) of the 2001 IPCC Third Assessment report. The curve, which depicted temperature variations over the past 1000 years estimated from “proxy data such as tree rings, corals, ice cores, and lake sediments”, showed the upward spiking of modern temperatures (the “blade”) as it dramatically ascends, during the industrial era, upward from the “handle” that describes the modest, slightly downward steady trend that preceded it.
The Hockey Stick became an icon in the case for human-caused climate change, and I found myself at the center of the contentious climate debate (I’ve described my experiences in “The Hockey Stick and the Climate Wars”).
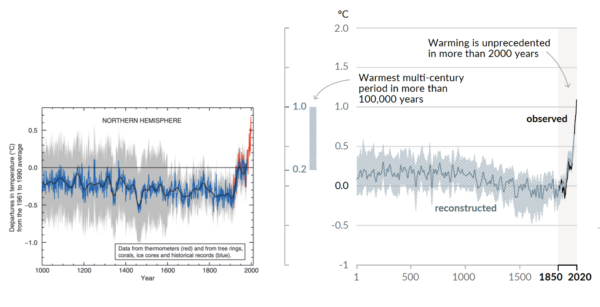
Featured two decades later now in the AR6 SPM is a longer Hockey Stick with an even sharper blade. And no longer just for the Northern Hemisphere, it now covers the whole globe. The recent warming is seen not only to be unprecedented over the past millennium, but tentatively, the past hundred millennia.
The relevant statements in the SPM and Technical Summary are:
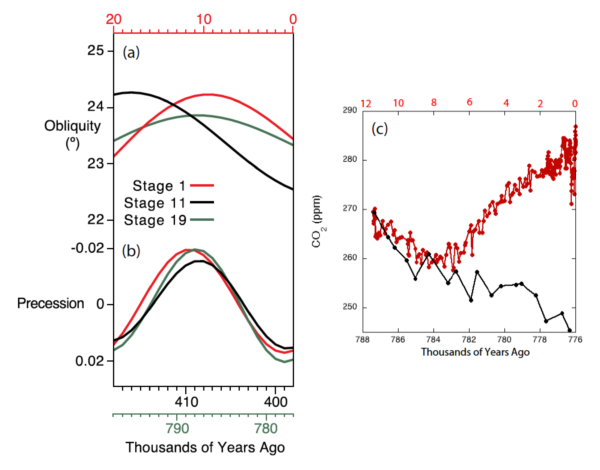
A.2.2 Global surface temperature has increased faster since 1970 than in any other 50-year period over at least the last 2000 years (high confidence). Temperatures during the most recent decade (2011–2020) exceed those of the most recent multi-century warm period, around 6500 years ago13 [0.2°C to 1°C relative to 1850– 1900] (medium confidence). Prior to that, the next most recent warm period was about 125,000 years ago when the multi-century temperature [0.5°C to 1.5°C relative to 1850–1900] overlaps the observations of the most recent decade (medium confidence). {Cross-Chapter Box 2.1, 2.3, Cross-Section Box TS.1}
SPM AR6
Global surface temperature has increased by 1.09 [0.95 to 1.20] °C from 1850–1900 to 2011–2020, and the last decade was more likely than not warmer than any multi-centennial period after the Last Interglacial, roughly 125,000 years ago.
Cross Section Box TS.1
As the new IPCC report lays bare (you can find my full commentary about the new report at Time Magazine), we are engaged in a truly unprecedented and fundamentally dangerous experiment with our planet.
References
- M.E. Mann, R.S. Bradley, and M.K. Hughes, "Northern hemisphere temperatures during the past millennium: Inferences, uncertainties, and limitations", Geophysical Research Letters, vol. 26, pp. 759-762, 1999. http://dx.doi.org/10.1029/1999GL900070