Do you remember when global warming was small enough for people to care about the details of how climate scientists put together records of global temperature history? Seems like a long time ago…
Nonetheless, it’s worth a quick post to discuss the latest updates in HadCRUT (the data product put together by the UK’s Hadley Centre and the Climatic Research Unit at the University of East Anglia). They have recently released HadCRUT5 (Morice et al., 2020), which marks a big increase in the amount of source data used (similarly now to the upgrades from GHCN3 to GHCN4 used by NASA GISS and NOAA NCEI, and comparable to the data sources used by Berkeley Earth). Additionally, they have improved their analysis of the sea surface temperature anomalies (a perennial issue) which leads to an increase in the recent trends. Finally, they have started to produce an infilled data set which uses an extrapolation to fill in data-poor areas (like the Arctic – first analysed by us in 2008…) that were left blank in HadCRUT4 (so similar to GISTEMP, Berkeley Earth and the work by Cowtan and Way). Because the Arctic is warming faster than the global mean, the new procedure corrects a bias that existing in the previous global means (by about 0.16ºC in 2018 using a 1951-1980 baseline). Combined, the new changes give a result that is much closer to the other products:
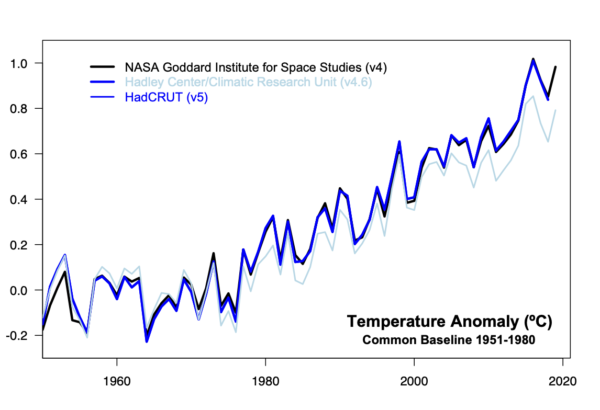
Differences persist around 1940, or in earlier decades, mostly due to the treatment of ocean temperatures in HadSST4 vs. ERSST5.
In conclusion, this update further solidifies the robustness of the surface temperature record, though there are still questions to be addressed, and there remain mountains of old paper records to be digitized.
The implications of these updates for anything important (such as the climate sensitivity or the carbon budget) will however be minor because all sensible analyses would have been using a range of surface temperature products already.
With 2020 drawing to a close, the next annual update and intense comparison of all these records, including the various satellite-derived global products (UAH, RSS, AIRS) will occur in January. Hopefully, HadCRUT5 will be extended beyond 2018 by then.
In writing this post, I noticed that we had written up a detailed post on the last HadCRUT update (in 2012). Oddly enough the issues raised were more or less the same, and the most important conclusion remains true today:
First and foremost is the realisation that data synthesis is a continuous process. Single measurements are generally a one-time deal. Something is measured, and the measurement is recorded. However, comparing multiple measurements requires more work – were the measuring devices calibrated to the same standard? Were there biases in the devices? Did the result get recorded correctly? Over what time and space scales were the measurements representative? These questions are continually being revisited – as new data come in, as old data is digitized, as new issues are explored, and as old issues are reconsidered. Thus for any data synthesis – whether it is for the global mean temperature anomaly, ocean heat content or a paleo-reconstruction – revisions over time are both inevitable and necessary.
“there remain mountains of old paper records to be digitized.”
Please, sir, can we have more scans and uploads of ancient White House climate policy documents and hot type & dead tree policy quarterlies ?
You might start with Ye olde Foreign Affairs and The National Interest
And then there is HadCRUT5 with Morice et al (2020) ‘An updated assessment of near-surface temperature change from 1850: the HadCRUT5 dataset’ explaining the whats & wherefores. Mind, until I learn how to unravel the content of NetCDF format files (or they change the format), the HadCRUT5 data will remain beyond my reach.
But it went UP! Clearly the global warming hoax cabal tampered with the data! Do your own research! Listen to the voices in my head!
A long overdue update. It is good to see the results of all of the improvements.
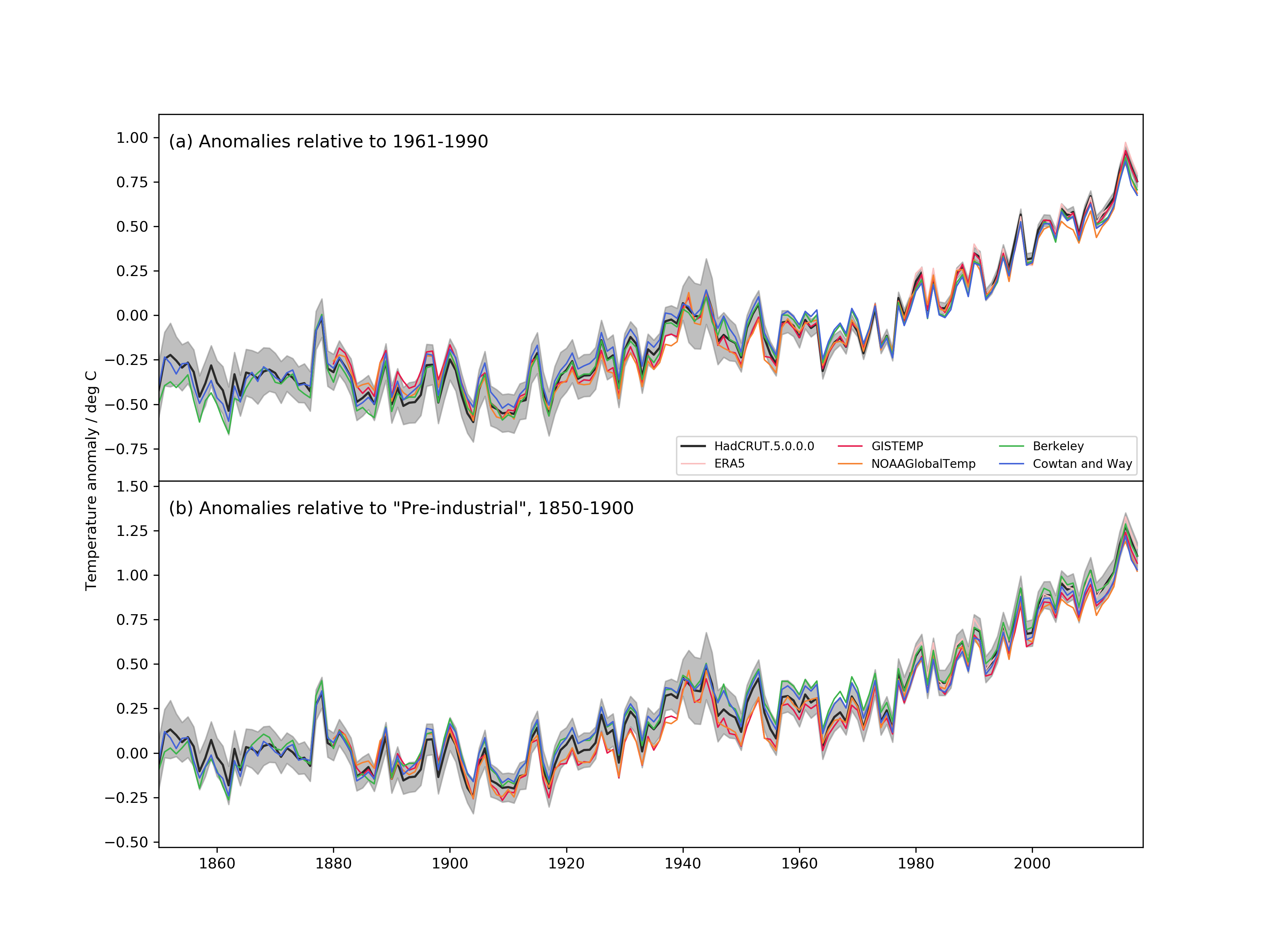
It’ll be interesting to see how this impacts discussion of recent global warming acceleration during the post-1979 time-period covered by ERA5 and other analyses. The basic idea is that, contrary to contrarian nonsense about a statistically significant post-1998 “pause” in global warming, warming instead accelerated.
– ERA5, GISTEMP, and NOAA showed statistically significant acceleration.
– JRA-55, HadCRUT4, Cowtan+Way, and Berkeley Earth didn’t.
https://twitter.com/AtomsksSanakan/status/1239307511783665667
Tamino (Grant Foster) has done a lot of work showing this:
https://tamino.wordpress.com/2020/01/22/is-the-apparent-recent-acceleration-in-temperature-significant/
https://tamino.wordpress.com/2019/11/08/global-temperature-update-6/
https://tamino.wordpress.com/2020/01/05/trend-pat-michaels-and-ryan-maue-ride-the-crazy-train/
The lack of acceleration in HadCRUT4, Cowtan+Way, and Berkeley Earth seemed largely due to their use of the older HadSST3 analysis that under-estimated recent sea surface warming. It’s nice to see this addressed with HadCRUT5; hopefully the same happens (or has already happened) with Cowtan+Way and Berkeley Earth. One might then see acceleration in those analyses, though Berkeley Earth may still have residual issues regarding under-estimating polar warming:
https://rmets.onlinelibrary.wiley.com/doi/epdf/10.1002/joc.4808
https://www.researchgate.net/publication/319406961_Continuously_Amplified_Warming_in_the_Alaskan_Arctic_Implications_for_Estimating_Global_Warming_Hiatus
JRA-55 has similar issues with its SST analysis. It uses COBE-SST1, which under-estimates recent sea surface warming:
http://archive.is/R00A1
JRA-55’s update will move on from COBE-SST1:
https://web.archive.org/web/20200326055002/https://climate.copernicus.eu/sites/default/files/repository/Events/ICR5/Talks/ICR5_R.05_Kobayashi_13pm.pdf
https://web.archive.org/web/20200326055015/http://ds.data.jma.go.jp/tcc/tcc/library/library2017/lectures/4_Introduction_to_Reanalysis.pdf
Anyway, folks can fiddle with the surface analyses over at:
https://psl.noaa.gov/cgi-bin/data/testdap/timeseries.pl
Hr. Schmidt
What interests me again is that fameous bump in the curve around 1940, that seems to start 1910 and end 1975, period 65 years. Which is not Saturnus. But it has been helping a lot of surrealism all the time that I have followed the climate dispute.
As a specialist on music acoustics feedback and oscillation however, I must take that quite more serious, and it is quite common in nature, the meandering of rivers, tigers, zebras and mackrels. Even some wild and domestic cats are obviously a bit striped.
So that some people state proof of a whole tiger from just a glimpse of a ruffled cat. Or they sell a tiny striped perch for a long mackerel.
To study this, I did take pictures for a while of all kinds of possible “mackerel- clouds” Altostratus undulatus, Kelvin- Helmholz oscillation, due to certain conditions and instabilities of “unlinear” kind in viscous systems.
It takes microchosmic forces, van der Waals- forces in addition to and different from “classical physics”, and thus very important to organology. And because the limits or boarders of noise /coherence decides on important effects like rumble or “wolf” in the tones or when a tone breaks and blows over. There you have molecular and dis- continous material, often called “unlinear” effects.
This is also an el- dorado of alarmism, where one must try and suggest possible cathastrophies and avalanche- effects. Or the quite opposite, Chosmos arises and assembles from chaos.
That together is easily shown experimentally on the oscilloscope.
The common contrarian belief is a smooth, classic mechanical cycle and nothing but a cycle, due to Saturnus. But I get it from material properties in several systems, where I find anything but a classical cycle.
I see clearly that the smaller and shorter details in the curve are chaotic, like “random noise”. But I lack the 11 year sunspot swells in your recent presentation, which are very important in order to be able to judge the order of magnitude, for solar variations possible effects on weather and climate, and even whether the long time curves are autentic. Then the Sun should also set its tiny marks.
Bumps and scratches in the waterline of the Oslo-Kiel- ferry, that even could be dated by the successive layers of paint… did follow the 11year +- sunspot- curve for years, because of varying ice in the fjords and the belts. And this could be given a possible natural explaination, if we also assume that the solar wind and fluctuating UV has its effect on the stratosphere and jet- stream in the north atlantic monsune where I live. (=Max draught in Mars, Max rain in August.)
But maybe the curve is normalized better now, to the whole world and not just England, EU, and the North atlantic.
And that this explains your vanishing of obvious solar cycle-swells from earlier curves.
MA Roger@2 My office created netCDF. Can we help?
@MA Rodger: we have text format files (i.e. not netCDF) for hemispheric and global mean timeseries on the CRU website. https://crudata.uea.ac.uk/cru/data/temperature/
Re: netCDF
QGIS and GRASS do netCDF well. I quite like the format, thank you Mr. Emmerson.
sidd
SE 7,
I would like to find a free way to convert netCDF files to anything else–Excel, text, anything. All the on-line stuff costs money and so does the downloadable software to do it. That’s no way to support research.
[Response: Use nco + unix. i.e. ncks -C -H -v var file | grep XXXX | awk ‘{print whateverformat}’ etc. Or upload into R (using ncdf4) and outputting whatever you want. – gavin]
Has anyone ever graphed the daily highs and low for Fairbanks, Alaska from say 1950 to 2020? Based on my experience there in the 70s, and comparing with temperatures today, I would say winter temperatures today are frequently 40 F higher than the mid 70s. In the 70s, several weeks would go by with highs around -30 F, with lows in the -40s and -50s. Today it seems that temperatures are not even below zero much of the time. I remember a bank time/temperature “digital” display (light bulbs back then) reading -50 F, 12:00, -50 F, 12:00 at noon. Now, it rarely gets to -20 AT NIGHT! You will know you are looking at legit data if around Halloween in 1975, the lows are -35 to -40 F. Those were records I believe, and because cold sinks to low spots, the numbers may be higher or lower depending on the location of the station. Typically in Fairbanks in winter there is no wind to mix the air, resulting in polluted air in town due to car exhaust, wood smoke, etc.
I think a linear graph of the daily temps for Fairbanks would be a shocker visually. It would be a big wide graph, not sure how to show it – perhaps in some kind of panorama mode. There are many government operations in the area that may have temperature records: Ft. Wainwright, Eielson AFB, USGS water resources office, school district, power plants at the University and in Fairbanks, University of Alaska (Arctic studies and other departments), Poker Flats Rocket Launch Facilities for Auroral and upper atmosphere research, Alyeska Pipeline pump stations, etc, etc, etc.
-41 at North Pole (Fairbanks suburb) Halloween 1975:
https://www.alaskapublic.org/2018/11/01/ask-a-climatologist-the-colder-snowier-halloweens-of-yesteryear/
https://en.wikipedia.org/wiki/Fairbanks,_Alaska#Climate
Although it does not seem anywhere near as cold as back in the 70s, it is true that the state records were mostly set in the early 1900s thru 1930s. Maybe the deniers are right and our current “warming” is just normal climate swings, but I’d still like to see a graph of daily high and low temps in the Fairbanks area.
Thanks Gavin.
If we shift the Baseline from 1951-1980 to 1750-1800 what would climate science estimate for the increase in world temperature? This seems to be one of the relevant data points for discussing policies in nation-states and which are reported in the press (rather than 1951-80).
BPL at 10:
This is a good tutorial on netCDF in R:
https://pjbartlein.github.io/REarthSysSci/netCDF.html
Re: netCDF
QGIS and GRASS and R are all free …
sidd
Hi. One thing that seems important to me, but is almost totally ignored in the wider discussion, is that temperatures over the world’s landmasses are rising much quicker than the global mean temperature. GISS graphs show this quite dramatically. Like the Arctic, landmass temperatures are rising twice as quickly. So since 1880 temperatures on land have already risen by 2 deg C. As all but a handful of the global population live in continental landmasses and very few in the oceans, the idea that we will limit the temperature rise that this population experiences to 1.5 deg C is plainly absurd, they’re already 0.5 C above this suggested limit, indeed it’s very likely this population will experience a 4 deg C rise by the end of the century at a minimum. That’s a profound disturbance of the holocene’s generally stead climatic condition. Why is interpretation of the figures never discussed or brought forward by concerned scientists and environmentalists? It really should frighten us rigid.
MKIA, here is the daily min/max for Halloween in Faibanks since 1948.
https://photos.app.goo.gl/rzPDzxTyLh4D1KF69
I don’t normally like doing a line graph when there is no logical reason to interpolate between points, but it figured some people may have had difficulty interpreting raw points
A key measure of global warming has been revised upwards. It suggests that we are already closer than we thought to the 1.5oC increase in average temperature compared to the pre-industrial era.All about the pink clouding
“The global average temperature is thought to have increased by about 1.07 degrees Celsius since the Industrial Revolution, not 0.91 degrees Celsius as previously estimated,” reveals the New Scientist, which reports on the Met Office’s fifth updated data, known as the Hadley Center Climatic Research Unit Temperature (HadCRUT5).Click here for more update
and last one ….
daily mean for a week either side of Halloween
https://photos.app.goo.gl/LhZcrX6Jr2dLrrVC6
Mr. KIA at 11: “Although it does not seem anywhere near as cold as back in the 70s, it is true that the state records were mostly set in the early 1900s thru 1930s.”
It’s not quite clear whether you’re referring to cold records or heat records, but as far as record heat goes, it’s much warmer in Alaska than it used to be, with seven of the ten warmest years occurring since 2000: http://berkeleyearth.lbl.gov/regions/alaska
What is the actual link to the HadCRUT5 global monthly average surface temperature file? Not gridded, not in a .nc form, just a plain old text file, or Excel file? There seem to be links to everything but this. Thanks.
[Response: It’s on the CRUTEM site – gavin]
John Monro:
Everyone is very well of your point.
David
John Monro: So since 1880 temperatures on land have already risen by 2 deg C.
AB: Yes, land temperatures are more important, and not just because we live there. Land temperatures are closer to where we’re heading, planet-wise, assuming we hold CO2 emissions and allow the oceans to drift atmospheric concentrations down to a more sane level.
We’re sitting next to a tub of ice water. Keeps us cooler, but the tub will warm to the new ambient, which will be somewhat warmer than we currently are, sitting next to our ice water tub.
KIA(11): “ Maybe the deniers are right and our current “warming” is just normal climate swings”
Fairbanks is about 0.0001% of Earth. So you have to fill in the remaining 99.9999% of the “global”, to prove your denier friends “right”.
Al Bundy, 22
“We’re sitting next to a tub of ice water. Keeps us cooler, but the tub will warm to the new ambient, which will be somewhat warmer than we currently are, sitting next to our ice water tub.”
As a global average, SST’s are about 10.0 C warmer than land surfaces, so I’m not sure your analogy is apt.
Reference for my reply to Al Bundy, #22
“The 1901–2000 average combined land and ocean annual temperature is 13.9°C (57.0°F), the annually averaged land temperature for the same period is 8.5°C (47.3°F), and the long-term annually averaged sea surface temperature is 16.1°C (60.9°F).”
https://www.ncdc.noaa.gov/sotc/global/201913
(I misremembered…. more like 8.0 C warmer)
Western Hiker: As a global average, SST’s are about 10.0 C warmer than land surfaces
AB: That sounds way wrong. Where did you find it? I’ve always read that the oceans are lagging, and that lagging gives us a bit of “ancient coolness”, especially at coasts.
“With respect to preindustrial conditions, the land warms 30%–70% more than the ocean in both observations and general circulation model (GCM) experiments.”
https://journals.ametsoc.org/view/journals/clim/24/13/2011jcli3893.1.xml
The average land temperature is probably lower because most land is elevated, and there’s a lapse rate. 8.5 C for land and 16.1 C for ocean gives a mean temperature of 0.292 (8.5) + 0.708 (16.1) or 13.9 C, which is about right.
Mr. Know Nothing @11
Highly unlikely if not impossible.
For global temperatures to warm per the extent shown in the graphs of this RC posting there must be a change in total energy of the climate system. Per the First Law, energy can neither be created nor destroyed–energy is conserved. For such a change in global temperatures as seen, either the amount of energy flux into the system must increase or the amount of energy flux out of the system must decrease. That is a scientific FACT.
We know the energy into the system isn’t increasing, the only source of energy in is the sun and solar irradiance has actually declined over the same period. It is possible that naturally occurring sun blocking aerosols from volcanos could have decreased allowing more solar irradiance to reach the surface, but in fact, volcanic activity has continued as normal through the same period. Or perhaps albedo from snow and ice cover has changed naturally allowing less solar irradiance to be reflected back to space. This isn’t really possible as the cause of the current warming because it takes warming to cause snow and ice to decline–it is a feedback. There just is zero evidence of an increase in energy into the climate system.
This leaves only one possibility–the amount of energy flux leaving the system must have declined. What naturally occurring change in forcing can cause this to happen? Naturally changing levels of greenhouse gases, but we know that the measured increase is anthropogenic and not natural. That’s it. We know the warming is due to increases in green house gases due to the physics and the tell tale way it is warming i.e. nights warming faster than days can only happen by decreasing heat loss as opposed to increases in energy into the system which would result in uniform heating throughout the day.
On the other hand, misinformers would have us believe that the warming might be due to natural unforced variation. Unforced variation is simply the changes in surface temperatures due to heat moving between the ocean heat sinks and the atmosphere. However, the degree of change caused by this is limited by the fact that per the Second Law heat flows from hot to cold so at some point the heat flowing out of the oceans must flow back as the system attempts to maintain thermal equilibrium. This type of natural variation can only account for a fraction of a degree of temperature change and is cyclical on relatively short time frames. AND we know this cannot explain the current warming trend because over the same period BOTH surface temperatures AND ocean heat content have gone up. The total system has gained energy which can only occur through an increase in energy flux in or decrease in energy flux out.
On top of all this, if the warming were natural one would have to explain why the increases in greenhouse gases are not doing what the laws of physics tell us. There would have to be significant negative feedbacks for which there is ZERO evidence.
So, the claim made by Mr. Know Nothing and the climate misinformers that perhaps the warming is just natural is nonsensical. It is a display of either willful ignorance or a blatant attempt to mislead.
Al Bundy (26): AB: That sounds way wrong. Where did you find it? I’ve always read that the oceans are lagging, and that lagging gives us a bit of “ancient coolness”, especially at coasts.
He is not “ way wrong“, because he is comparing the AVERAGE TEMPS., not ANOMALIES to which your “lagging” refers to.
So your are sitting next to the “tub of WARM water”, not “ice water”. Hence his:
“ I’m not sure your analogy is apt.“
Western Hiker: As a global average, SST’s are about 10.0 C warmer than land surfaces,
Al Bundy (26): AB: That sounds way wrong. Where did you find it? I’ve always read that the oceans are lagging, and that lagging gives us a bit of “ancient coolness”, especially at coasts.
Piotr: He is not “ way wrong“, because he is comparing the AVERAGE TEMPS., not ANOMALIES to which your “lagging” refers to.
First page Google sea surface temp query:
These warm waters are needed to maintain the warm core that fuels tropical systems. This value is well above 16.1 °C (60.9 °F), the long term global average surface temperature of the oceans.
and
the average surface temperature of the planet at 288 degrees kelvin (15 degrees Celsius or 59 degrees Fahrenheit).
—
1.9C is significant…
59 = .7(60.9) + .3X
42.63
16.37 = .3X
3.33
54.5121 (ooo haven’t done 3×4 in my head in a while. Did I get it right?)
60.9
5.4C
In the same ballpark, and could be true. In fact, I don’t doubt it. But so far 10C still seems high.
And yes, I was speaking of summertime comfort. It’s amazing how warm the Caribbean is getting, eh?
re: 28. I have pointed out time and time again to Mr. Know Nothing that the stratosphere has been cooling whereas it ought to be warming if global warming is due to natural causes. He ignores/can’t explain how it “must” be violating the basic laws of thermodynamics. He is an ignorant science denier. He does not even understand the basics of the scientific method. Worse yet, he thinks that somehow he and other non-peer reviewed climate scientists somehow know more than every professional climate science in the world. In short, he is a true coward, unable and too insecure to admit to being wrong.
BPL: The average land temperature is probably lower because most land is elevated, and there’s a lapse rate
AB: Thank you. My brain was stuck in 2D
AB, #30–
I think your multiplication is fine, but–3.0, not 3.33, in line #4, right? Which gives 54.5667, not 54.5121, for your average land temp. Not a big deal.
So you then subtract that from the SST value per Wiki–60.9F–getting 5.4 C. That would be 5.3, adjusting for the corrected rounding, but none of us much cares about that here.
But you forgot that you’ve been working in F units, my friend! So it’s 5.4F–or 5.3F!–which means:
5.4 x 5/9 = 27/9 = 3C
or
5.3 x 5/9 = 26.5/9 = 2.94C
Which, of course, actually gives increased support to your questioning of the proposed 10C difference between mean land and sea temps.
(BTW, I’m surprised that you can’t just search up a mean land-only temp so easily. Surely it exists in a data set or 3 somewhere. But the searching I did do reminds me that we have to differentiate whether we mean air temperature (as is usually measured), or actual surface temperature, because they are not the same thing.)
Al Bundy:
[After calculations leading to:] 5.4C In the same ballpark, and could be true. In fact, I don’t doubt it. But so far 10C still seems high.
L’esprit de l’escalier? ;-) Calculations you could have done, but didn’t, because you were talking about …something else?
When you wrote about Western Hiker that his ocean being 10C warmer than land was “ way wrong” – you didn’t mean it is should have been 5.4C warmer (or rather 7.6C as WH self-correction (25) and BPL(27) have shown), you have said it was “ way wrong” because:
AB(26) “ I’ve always read that the oceans are lagging, and that lagging gives us a bit of “ancient coolness” ”
This would make sense only if you confused difference in average temps. (oceans being 7.6C warmer) with current rate of warming (ocean warming indeed “lagging” behind that of land).
Al: And yes, I was speaking of summertime comfort. It’s amazing how warm the Caribbean is getting, eh?
sure, when I think ‘the Caribbean Sea in summer’ – the first thing that comes to mind is a “ tub of ice water” … ;-)
That’s why we need to be careful with analogies – get them right and they will help you to get your point across, get them wrong, e.g. by “crossing the wires”, say, by representing big with small, dark with white, or warm with “tubs of ice water” – and the analogy obscures the original point. Which was … ?
Al Bundy
“In the same ballpark, and could be true. In fact, I don’t doubt it. But so far 10C still seems high.”
10.0C was what I misremembered, and 8.0C is outdated. Here’s a more careful look:
According to NOAA, Earth’s land area in 2019 was 1.42C warmer than the 1901 – 2000 average of 8.5C
8.5C + 1.42C = 9.92C
https://www.ncdc.noaa.gov/cag/global/time-series/globe/land/ann/7/1880-2020
And according to NOAA, Earth’s SST in 2019 was 0.77C above the 1901 – 2000 average of 16.1C
16.1C + 0.77C = 16.87C
https://www.ncdc.noaa.gov/cag/global/time-series/globe/ocean/ann/7/1880-2020
So, a difference of 6.95C
Piotr,
[So you are sitting next to the “tub of WARM water”, not “ice water”.]
Yeah, that was my understanding, which is why Al’s comment to the contrary caught my eye. You can compare absolute values for land versus ocean here:
https://climatereanalyzer.org/wx_frames/gfs/ds/gfs_world-ced_t2_1-day.png
Notice that they’re very similar along the equator and most of the Southern Hemisphere, but a big difference shows up as you move north. I assume the pattern will be reversed in NH summer.
Kevin: 3.0, not 3.33, in line #4, right?
AB: 10 / 3 = 3.33. I showed ALMOST all of my work. Oops! But BPL solved the conundrum. Land has elevation and elevation makes it colder. (as did my brain freeze)
Piotr: That’s why we need to be careful with analogies – get them right
AB: OK. If you insist. Given the lapse rate, any land temperature needs to be adjusted to sea level. “sitting next to” requires this, right?
And yep, the ocean has ice that is residual, ice that is keeping us cooler for now and soon won’t. Yes. The more I think about it the more I like this really great analogy.
But my original 2D question remains:
What is the difference in land versus ocean temperature with all temperatures adjusted for elevation?
Al Bundy(37): “ BPL solved the conundrum. Land has elevation and elevation makes it colder. (as did my brain freeze)”
Yes, it was interesting (so we can learn something new on RC after all ;-)). Of course it is only a first approximation, e.g. it does not explain changes in the temperatures e.g. that ocean lagging in the warming behind land you wrote initially about (it’s not like the land level has recently been dropping much faster than the sea level … ;-))
Perhaps more evaporative heat loss in the ocean slows the warming of the ocean and when vapour condenses over land – adds heat there, thus accelerating its warming?
And it is usually easier to warm something that is cold (land) than something that is warmer (ocean). BTW, the same relationship may be one of the reasons why the Artic warms more than tropics …
Re:Al Bundy(38)
Piotr(34): “That’s why we need to be careful with analogies – get them right and they will help you to get your point across, get them wrong, e.g. by “crossing the wires”, say, by representing big with small, dark with white, or warm with “tubs of ice water” – and the analogy obscures the original point.”
Al Bundy (37): OK. If you insist. Given the lapse rate, any land temperature needs to be adjusted to sea level. “sitting next to” requires this, right? […]
The more I think about it the more I like this really great analogy.”
As I wrote to you in (34) – for analogy to work it should help getting your point across to the reader. To do so it has to be simpler that your original point, yet MUST still preserve the important relationships, without “crossing the wires” – “ice-cold” should not represent “warm” or “high”, because if it is – then it does not help, but the opposite – it “obscures the original point”.
In this case, if to understand your analogy the reader is expected to know that your “tub of ice water” represents … the effect of the lapse rate, i.e. the effect YOU YOURSELF have learned only after the fact from BPL (“Al Bundy(37): “BPL solved the conundrum. Land has elevation and elevation makes it colder”
– then your analogy obscures your original point, and as such – is not that really great analogy.
AB(38) The more I think about it the more I like this really great analogy.”
So … think less?
AB: What is the difference in land versus ocean temperature with all temperatures adjusted for elevation?
Most of the work has been done for you – BPL told you about the lapse rate, BPL and Western Hiker gave you the temps over land and ocean, all you needed to do was to look up on Wikipedia the average elevation of land (835m) and the realistic lapse rate. eg The environmental lapse rate (ELR) 6.49 K/km (https://en.wikipedia.org/wiki/Lapse_rate) and voila:
0.835*6.49 K/km = 5.4K, i.e. with the current ocean-land difference of 6.95K (W.Hiker 35), even after accounting for a realistic lapse rate, the ocean is STILL 1.5 K WARMER than the land.
Of course this is only a back of the envelope calculations, there are various nonlinearities, plus thermal inertia for the current warming, but even with that the analogy that portrays WARMER ocean as “tub of ICE water” – not as great as advertised.
Al Bundy, 38
“But my original 2D question remains:
What is the difference in land versus ocean temperature with all temperatures adjusted for elevation?”
Interesting.
A very, very rough estimate –
Mean elevation of land area: 2,615 ft.
https://en.wikipedia.org/wiki/Earth
Using the Standard Lapse Rate of 2.0 C/1000 ft …..
https://www.ctsys.com/standard-lapse-rate-the-origin-story/
….. gives a temperature increase of 5.23 C if land was at sea level.
So, if the current difference between SST and land is about 6.95C (see my last post), the difference adjusted for elevation is only about 1.72C
Of course, lower elevations have a lot less snow and thus less albedo, which would provide more warming than lapse rate alone. Also, lower elevations benefit from a greater GHE, so warmer still.
Apart from the elevation issue, though, the ocean still has a couple of things going for it compared to land:
– More absorbed sunlight per square meter.
– A lower net loss of LWIR per square meter (I assume because of more clouds and water vapor above the oceans?)
https://link.springer.com/article/10.1007/s00382-014-2430-z
OTOH, as Piotr mentioned, the ocean experiences more cooling from evaporation (hard to quantify – see article)
RE: Analogies.
An analogy is a type of model, and as George Box tells us–all models are wrong but some are useful. Leonardo da Vinci was never very proficient at mathematics–so analogy was his favorite way of understanding the world around him, and as he showed, analogies can be powerful tools of understanding.
Just as it is important to understand the limitations of any model, so with analogies. Quantum mechanics suggests that even physical reality is an analogy–our conception will never reflect reality in all its subtlety. It will get you a couple dozen places of accuracy, though, and that’s usually enough.
Just above, #41, I wrote, “Also, lower elevations benefit from a greater GHE, so warmer still.”
On second thought, the lapse rate probably involves the GHE, in which case the statement is ‘double counting’.