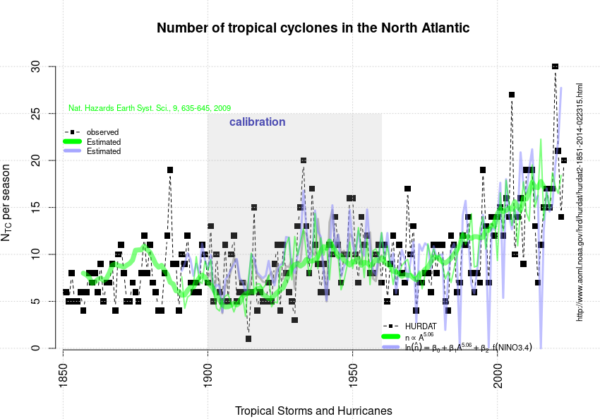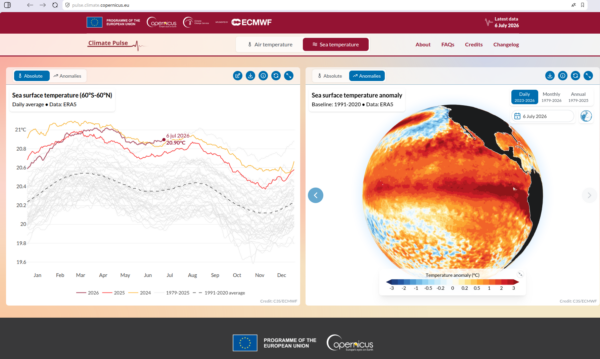
There is a new El Niño out there and it was officially declared already on June 11 by NOAA. This is both unusually early in the year and very soon since the last El Niño in 2023-24. Another remarkable thing is the seasonal forecasts, which for a couple of months have indicated that it may well be at strengths by the end of the year that we have not seen before. All these three aspects combined seem to make this El Niño different to the previous ones.
[Read more…] about This new El Niño is different