It’s worth going back every so often to see how projections made back in the day are shaping up. As we get to the end of another year, we can update all of the graphs of annual means with another single datapoint. Statistically this isn’t hugely important, but people seem interested, so why not?
For example, here is an update of the graph showing the annual mean anomalies from the IPCC AR4 models plotted against the surface temperature records from the HadCRUT3v and GISTEMP products (it really doesn’t matter which). Everything has been baselined to 1980-1999 (as in the 2007 IPCC report) and the envelope in grey encloses 95% of the model runs. The 2009 number is the Jan-Nov average.
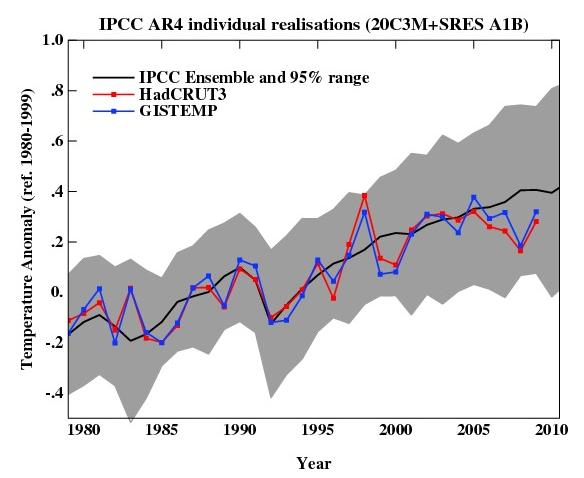
As you can see, now that we have come out of the recent La Niña-induced slump, temperatures are back in the middle of the model estimates. If the current El Niño event continues into the spring, we can expect 2010 to be warmer still. But note, as always, that short term (15 years or less) trends are not usefully predictable as a function of the forcings. It’s worth pointing out as well, that the AR4 model simulations are an ‘ensemble of opportunity’ and vary substantially among themselves with the forcings imposed, the magnitude of the internal variability and of course, the sensitivity. Thus while they do span a large range of possible situations, the average of these simulations is not ‘truth’.
There is a claim doing the rounds that ‘no model’ can explain the recent variations in global mean temperature (George Will made the claim last month for instance). Of course, taken absolutely literally this must be true. No climate model simulation can match the exact timing of the internal variability in the climate years later. But something more is being implied, specifically, that no model produced any realisation of the internal variability that gave short term trends similar to what we’ve seen. And that is simply not true.
We can break it down a little more clearly. The trend in the annual mean HadCRUT3v data from 1998-2009 (assuming the year-to-date is a good estimate of the eventual value) is 0.06+/-0.14 ºC/dec (note this is positive!). If you want a negative (albeit non-significant) trend, then you could pick 2002-2009 in the GISTEMP record which is -0.04+/-0.23 ºC/dec. The range of trends in the model simulations for these two time periods are [-0.08,0.51] and [-0.14, 0.55], and in each case there are multiple model runs that have a lower trend than observed (5 simulations in both cases). Thus ‘a model’ did show a trend consistent with the current ‘pause’. However, that these models showed it, is just coincidence and one shouldn’t assume that these models are better than the others. Had the real world ‘pause’ happened at another time, different models would have had the closest match.
Another figure worth updating is the comparison of the ocean heat content (OHC) changes in the models compared to the latest data from NODC. Unfortunately, I don’t have the post-2003 model output handy, but the comparison between the 3-monthly data (to the end of Sep) and annual data versus the model output is still useful.
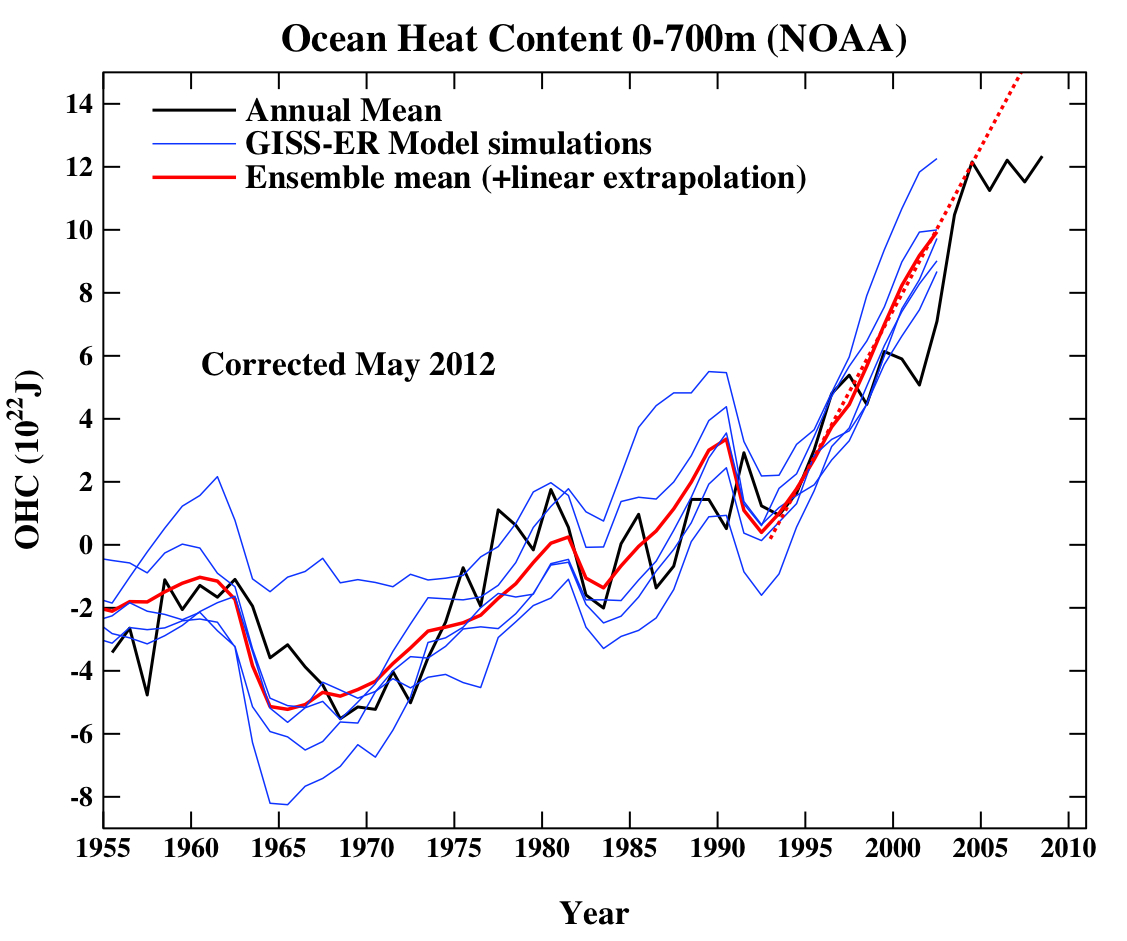
Update (May 2012): The graph has been corrected for a scaling error in the model output. Unfortunately, I don’t have a copy of the observational data exactly as it was at the time the original figure was made, and so the corrected version uses only the annual data from a slightly earlier point. The original figure is still available here.
{kind=link}
(Note, that I’m not quite sure how this comparison should be baselined. The models are simply the difference from the control, while the observations are ‘as is’ from NOAA). I have linearly extended the ensemble mean model values for the post 2003 period (using a regression from 1993-2002) to get a rough sense of where those runs could have gone.
And finally, let’s revisit the oldest GCM projection of all, Hansen et al (1988). The Scenario B in that paper is running a little high compared with the actual forcings growth (by about 10%), and the old GISS model had a climate sensitivity that was a little higher (4.2ºC for a doubling of CO2) than the current best estimate (~3ºC).
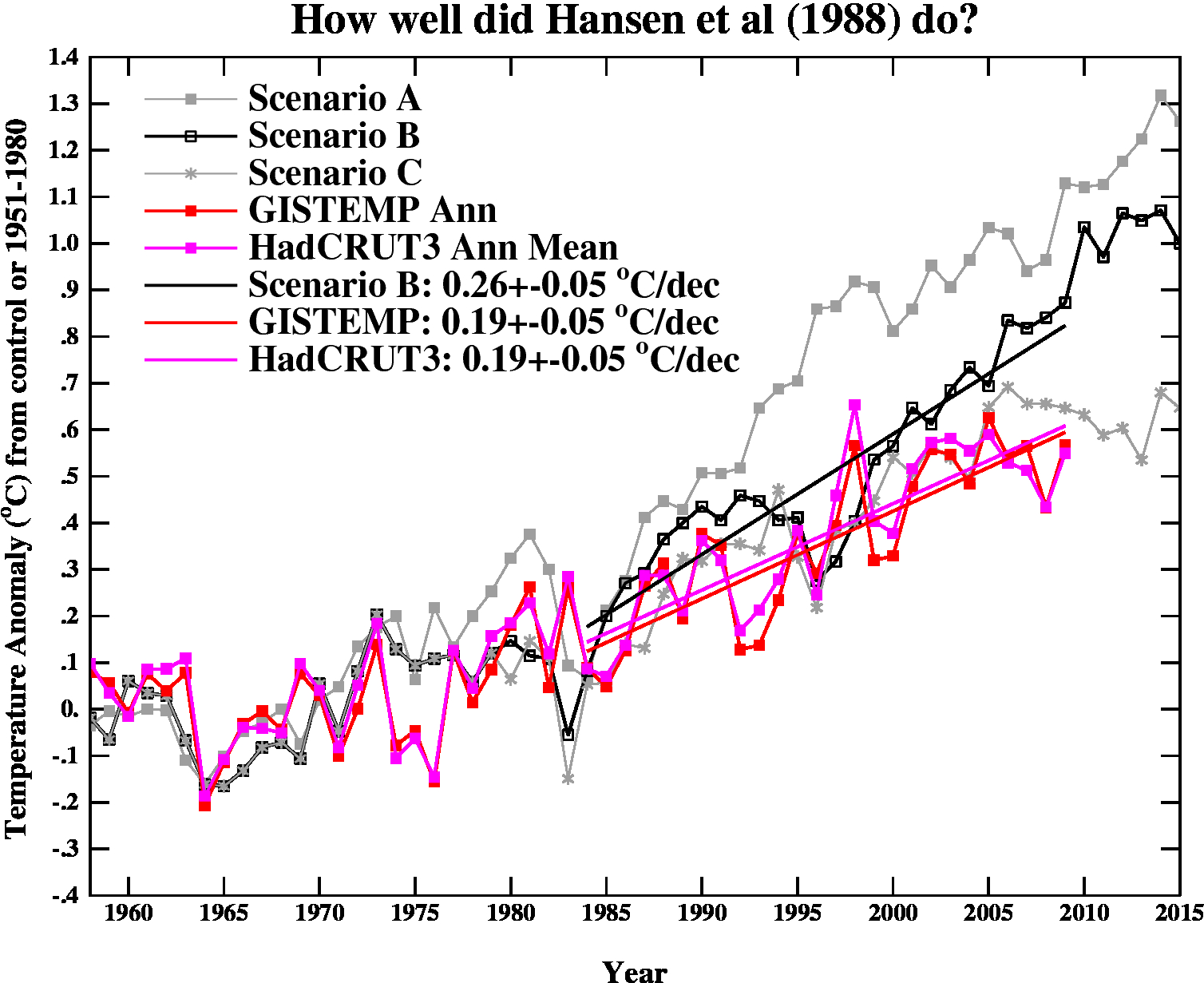
The trends are probably most useful to think about, and for the period 1984 to 2009 (the 1984 date chosen because that is when these projections started), scenario B has a trend of 0.26+/-0.05 ºC/dec (95% uncertainties, no correction for auto-correlation). For the GISTEMP and HadCRUT3 data (assuming that the 2009 estimate is ok), the trends are 0.19+/-0.05 ºC/dec (note that the GISTEMP met-station index has 0.21+/-0.06 ºC/dec). Corrections for auto-correlation would make the uncertainties larger, but as it stands, the difference between the trends is just about significant.
Thus, it seems that the Hansen et al ‘B’ projection is likely running a little warm compared to the real world, but assuming (a little recklessly) that the 26 yr trend scales linearly with the sensitivity and the forcing, we could use this mismatch to estimate a sensitivity for the real world. That would give us 4.2/(0.26*0.9) * 0.19=~ 3.4 ºC. Of course, the error bars are quite large (I estimate about +/-1ºC due to uncertainty in the true underlying trends and the true forcings), but it’s interesting to note that the best estimate sensitivity deduced from this projection, is very close to what we think in any case. For reference, the trends in the AR4 models for the same period have a range 0.21+/-0.16 ºC/dec (95%). Note too, that the Hansen et al projection had very clear skill compared to a null hypothesis of no further warming.
The sharp-eyed among you might notice a couple of differences between the variance in the AR4 models in the first graph, and the Hansen et al model in the last. This is a real feature. The model used in the mid-1980s had a very simple representation of the ocean – it simply allowed the temperatures in the mixed layer to change based on the changing the fluxes at the surface. It did not contain any dynamic ocean variability – no El Niño events, no Atlantic multidecadal variability etc. and thus the variance from year to year was less than one would expect. Models today have dynamic ocean components and more ocean variability of various sorts, and I think that is clearly closer to reality than the 1980s vintage models, but the large variation in simulated variability still implies that there is some way to go.
So to conclude, despite the fact these are relatively crude metrics against which to judge the models, and there is a substantial degree of unforced variability, the matches to observations are still pretty good, and we are getting to the point where a better winnowing of models dependent on their skill may soon be possible. But more on that in the New Year.
Looking at the annual update, I am struck by the fact that there was a temperature uptick in 2009 in the AR4 graph. It occurs to me that this inflicts some damage to the denialist argument that the atmosphere has not warmed in the past few years (and that therefore the entire notion of climate change is bogus). The reply is now, “yes it has warmed, and the red and blue lines on the graph seem ready to rejoin the black line expressing the overall trend”. The overall trend heading, of course, up.
Can we assume from this that the denialists will drop that argument and make up a new one, as is usual for them in such cases?
I notice the uptick in temperature on the AR4 graph. This event would tend to deflate the denialist argument that the warming trend has ended. No indeed, it has not ended, and the red and blue lines now are re-approaching the black line.
Time for the denialists to shift to new ground, as is their wont?
TRY wrote in 435:
The models are already calculating things that way. But its always finite mathematics, and as far as I can tell always will be. What used to be divided into 20 layers gets divided into 40. what was divided into grids of 2 degrees by 2 degrees gets divided into 1.25 degrees by 1.25 degrees. Same with time — although that may get divided dynamically. And that is whether you are dealing with the atmosphere or the ocean. Always dividing into layers and boxes, but the grids get smaller and more processes get taken into account.
Where radiation transfer calculations used to be based upon local thermodynamic equilibria and Kirchoff’s law we are now able to consider non-local thermodynamic equilibria and use Einstein coefficients. Where gids used to be static now they are dynamic, and in areas where flow and the transfer of momentum is greater than others the grid can be made finer. But computer power is always limited, and being limited the mathematics has to be finite, not continuous.
TRY wrote in 435:
Don’t you think that has already been occuring? With the expansion of the Hadley cells and the dry subtropics, the expansion of the range over which hurricanes are forming and Catarina in 2004 off the coast of Brazil? Ocean circulation — which models have been fairly successful at for the past few years. How well do they model precipitation patterns, the trends we are seeing, the polar vortex? The rise of the tropopause, the that the warming trends during winter have been greater than the warming trends during summer, that nights have warmed more than days, that the stratosphere would cool as the troposphere warmed.
TRY wrote in 435:
Short-term predictions are about weather, not climate. A model that is good at modeling weather is not necessarily good at modeling climate. In terms of weather, we can expand the time-frame over which we are able to make successful predictions from a few days to a couple of weeks, maybe longer. But the complexity involved in making longer term predictions grows as an exponential function of time.
Climate models aren’t about that. They don’t try to predict what the weather will be on a certain day in a particular city twenty years from now. They do things in broader strokes. Will summers typically be warmer forty years from now, by how much and with what variability in the Northeast? Weather is a question of the specific path taken by the earth’s climate system through an attractor that evolves over time. Climate is about the shape of that attractor, its statistical properties and how it evolves over time. And while weather is chaotic, as near as we can tell climate is not — although there will be branching points.
Moreover, given the fact that the models are based upon actual physical principles and actual emissions as best as they can be independently varified, it doesn’t make as much sense to distinguish between predicting the future as seeing how closely a model fits the past. But technically speaking, models don’t make predictions — as their runs have to assume different emission scenarios — which means what happens is dependent upon us and the choices that we make.
TRY wrote in 435:
Are you speaking of upwelling radiation spectra or overall radiation balance?
If you know the distribution of greenhouse gases, the aerosols, clouds and radiation entering an atmospheric column, calculating the radiation leaving the column is straightfoward. At the same time, knowing the balance of incoming over outgoing radiative energy is certainly something they are interested in, although there are other more roundabout ways of calculating it. But the feedbacks are where the real uncertainties lie, and therefore this is where the testing of climate models tends to focus. So for example there is a lot focus upon how well they model climate modes nowadays — which will be of considerable importance in terms of identifying mid-range trends.
But none of this will change the minds of those who are repeatedly told that climate models are nothing more than statistical models and thus a fancy form of line-fitting, that our belief in the relationship between temperature and carbon dioxide levels is based upon nothing more than statistical correlation, that its the sun that is doing all of the warming, the greenhouse effect violates the second law of thermodynamics, that global warming isn’t really taking place but just so much urban heat island effect or scientists fudging their results, the whole AGW-thing is an international conspiracy to establish a world social-ist government. It won’t keep certain authors from testing climate models against data that we know is wrong or out of date (e.g., earlier versions of Raobcore for tropical mid-tropospheric warming) then claiming that the mismatch is a problem with the hypothesis that warming trends are due to an enhanced greenhouse effect when the “problem” would be there independently of the specific cause of warming trends.
And it won’t in any way (at least directly) reduce the number of organizations that those authors belong to that receive funding from Exxon (Patrick J. Michaels (ExxonSecrets, SourceWatch) – 12, Fred Singer (ExxonSecrets, involved in the defense of tobacco, see: SourceWatch) – 13, Sallie Baliunas (ExxonSecrets, SourceWatch) – 11).
Its not a lack of evidence or the “immaturity” of climate science that is standing in the way of the public’s acceptance of either anthropogenic global warming or its seriousness.
Please see:
The American Denial of Global Warming (58 minutes)
Naomi Oreskes
http://www.youtube.com/watch?v=2T4UF_Rmlio
… and,
Climate Cover-Up: The Crusade to Deny Global Warming (Paperback – 2009) by James Hoggan, Richard Littlemore
Jason @446. Oh dear. Just, oh dear.
Jason at 444 says “I’m a big fan of waiting until I am convinced, and I highly recommend that you do the same if you ever find yourself in a similar situation… especially your only alternative is putting on a Waxman-Markey brand tin foil hat and praying that it somehow stops the bullet.”
Uh, Jason, given your most recent sputtering, maybe you want to ix-nay on-ay the in-tay-oil-fay hat-ay.
#391, Matthew, I was indeed motivated to mitigate climate change. After seeing the docu “Is It Hot Enough for You?” in 1989 (and reading science articles on which it was based), and seeing that the droughts in the African Sahel over the past several decades fit what was expected with global warming, if and when AGW reached scientific certainty, which it did in 1995, I first thought, “Why don’t THEY (gov, people) do something about this?” Then I realized I was part of the problem and I had to do something. And I wasn’t going to wait around for science to reach the great .05 (95% confidence); even .50 p-value would be more than enough confidence for me. At first I was willing to sacrifice, but as it turned out I was able to mitigate cost-effectively without sacrificing living standards.
As for my car, it is a 1997 Taurus we bought used in 2002, but we only drive about 2000 to 3000 miles per year, and I turn off the engine in drive-thrus, and run multiple errands, and carpool with my husband our 2 miles to work (I used to bicycle my 1 mile to work at our last place, but conditions here are not good for bicycling, and I’m getting old). Long ago, in the 70s, during the oil crunch, when I learned about entropy and finite resources, I decided we would always live as close as possible to work (so I don’t count that as part of my climate change mitigation, since I’ve already been doing that for 5 decades).
We are, however, thinking we might need another car in the next couple of years, and I’m waiting for affordable EVs or plug-in hybrids (with a range of at least 20 miles) to come out in our area, so I can drive on the wind.
But I do agree that people are not, as economists suggest, (completely) rational and economic. I would hope they would have a heart, a conscience. It is extremely demoralizing that many more people are so blinded and self-centered or ego-threatened that they can’t mitigate, even if they don’t completely agree with the science (as the U.S. Bishops and Popes JPII and BXVI have admonished us to do).
Simon@443, We’re all happy to have helped. Learning is what this blog is about for all of us readers–under the tutelage of St. Gavin and his equally patient(beatified, at least) entourage.
Face facts – the failure to collect data on the status of the ocean-atmosphere system puts the entire American scientific enterprise to shame – how is this any different from the Lysenkoism that dominatated Soviet science for decades? (Try applying Godwin’s Law to that statement, PR monkeys).
Can I ask a few ? from this group, not to do my work for me but to give me links where I can find the answers if I Study them.
1-On the temperature measurements-“average” and “mean” seem to be tossed out interchangably and of course they are different. Assuming we are talking “averages”-on surface averages-are these simple arithmetic averages, some kind of curve fit and integration or area weighted? Urbanization over tim could affect these depending on how you do it.. For “air temperatures” again are these simple or volume weighted averages? Also, why is the “average” the significant number? If I have my head in the freezer and feet in the oven I have an average temp.-but so what?
2-On the models
GAvin posted a subroutine which seemed to show the circumferencial elements based on longituede and latitude. IS this right and does this mean finite difference models not finite element. This would mean that interfaces between land and sea with steep T gradients would be difficult to handle.
How is the “lumpiness ” in CO2 , i.e unveven distribution over the world reported by NASA handled?-now and previously when basically unknown.
Sensitivity analysis. Has anyone done this in detail given that methane , water vapour etc. have a bigger incremental effect than CO2. These things can fool you . When we devloped complex models for nuclear reactor accidents, we found decay heat which we knew to .1% mattered to the result so much we needed to know it to .001% to get repeatable predictions. Other things we knew less well were less important.
Boundary conditions-it would appear from the discussion on El Nino these are not handled well. Are there any discussions on the
Initial conditions-errors multiplly over time-how are these handled. Any ionfo is greatly appreciated.
Clark Lampson@448
At ScienceDaily “No Rise of Atmospheric Carbon Dioxide Fraction in Past 160 Years, New Research Finds.”
Michael Savage is all over this on the radio. I’m guessing another sewer line is about to burst.
A couple of paragraphs down at SkepticalScience is this: “Over this period, an average of 43% of each year’s CO2 emissions remained in the atmosphere…”
Now maybe I’m missing something, but if that wording were used up front in reportage together with a sentence like “the emission rate and total global atmospheric CO2 continues to increase,” it would make it harder for the nutty to sow confusion. I find this very frustrating.
[Response: Actually I’m writing a post on this now. But if you have a library look up some letters between Lewis Kaplan and Plass in Tellus in 1960. – gavin]
Googling “Kaplan and Plass in Tellus” helped me find this:
http://www.americanscientist.org/issues/feature/2010/1/carbon-dioxide-and-the-climate/1
:)
That will do for now since I still have university access to online journals (but not to Tellus A before 1990 – scan in your archives now!).
Plus, I could also access all three of the related articles as well!
@Jason: “In most fields this is true, but not in Climate Science.”
Um, I got my Ph. D. in a group of climate scientists, although I am not a climate scientist. I can tell you straight up, having seen the progress of the careers of my colleagues, that there is not really much difference at all in what it took to get ahead academically. And it is a reasonable approximation of what it is supposed to be.
Frankly, one of the quickest routes to the top is to have the goods on a new idea that overturns a lot of established thinking. It’s the part about having the goods that the denialists are lacking.
Frankly I would say that most fields are filled with enough people who have become somewhat bored with the same old same old, and there is actually a bias in favor of novelty over quality.
Jason(446):
“And I wonder why McIntyre’s update of Santer et al ‘08 is still being reviewed? I don’t have a scintilla of proof, but I’d bet that one of your coauthors is a reviewer and “went to town” on it. What do you think?”
This is pathetic. Do you have anything else to contribute to the discussion, besides (self-admitted) baseless accusations? Or are you just trolling?
Great synopsis on what went wrong at copenhagen at http://news.ninemsn.com.au/article.aspx?id=989508
an exerpt from the article..”They blame the complex UNFCCC process, a spider’s web of a thousand interlinked strands, where decision-making is driven by consensus among 194 nations. This offers plenty of room for delaying tactics or sabotage.” They also raise the point that future climate deals may be better acheived by forging a ‘coalition of the willing’..coz you are never going to get economically obsessed countries like china to agree to anything that might not be 100% in their own vested interest..God! sounds just like the US doesn’t it!. They mentioned that the outcome of copenhagen was the enevitable lowest common denominator..an outcome so utterly weak and unbinding that everyobne felt safe with it.
Brazil shows hope in that they have legally comitted themselves into a 40% emissions reduction framework by 2030 I think it was. If anyone here can come up with a carefully thought out framework to convince me that a democratic process can work at establishing the required targets of CO2 reduction..please come forward..Those comments I have heard to date are very flawed in their knowledge of the democratic process and human nature and intention.
In my opinion a binding agreement by the coalition of the willing (major polluters) exluding the minor players might be our best hope. The human race does not seem nearly advanced enough to have a coherent global consensus involving up to 200 countries..we need to keep it simple!
Skeptical arguments in a less contentious context:
http://drboli.wordpress.com/2009/12/15/the-duck/
Good work Simon #443 — you’re getting there.
With regard to Knorr’s paper, I note that in para. 22, he writes: “The possibility, however, presents itself and, given the evidence from oxygen data [Bopp et al., 2002], would mean that a larger proportion of emissions is taken up by the ocean than what has been previously assumed. The analysis also shows that recent trends after 2000 can be explained by re-scaling land use emissions within their uncertainty ranges.”
Gavin is right, AFAICT: people are misinterpreting the paper.
Gavin, your patience with Jason has been amazing. Jason, you’re making yourself look more and more foolish. One does begin to wonder if you’re just trolling.
Based on the RealClimate article “Why greenhouse gases heat the ocean” and the fact I cannot find any science to quantify the effect demonstrated in that article as far as actual ocean heating goes, I have serious doubts about the model’s abilities to model anthropogenic warming of oceans.
So for the second time, can someone please tell me what mechanisms and assumptions the models (eg HadCM3) use to warm the oceans?
[Response: I don’t really know where you are coming from on this, but there is a demonstrable long-term rise in ocean heat content that is matched by the models. The actual mechanism is very straighforward – there is a net positive flux of heat at the surface which gets mixed through the mixed layer (mainly by wind stirring and convection) and which then is diffused and advected into the deep ocean. – gavin]
#464, Lawrence, there is this idea of “contraction and convergence” — see: http://en.wikipedia.org/wiki/Contraction_and_Convergence
The high per capita emitters contract, allowing the low emitters to economically develop and emit more, but the net emissions should continue to decrease.
That is a good way to think about the problem — on a per capita basis (which puts the U.S. way above China in emissions per capita). Also, I think there has to be some way of figuring in global trade, which would put China at an even lower per capita level, since a lot of their emissions are from making products for the rich nations — I think I read somewhere that 20% of their emissions go into export products (or net export), and 8% additional emissions (Americans buying Chinese products) are attributable to Americans (not sure if they included the emissions in shipping the products). You can see why China was in a double bind. They understand this, but to demand that rich nations reduce, would actually harm their budding economy.
Another plan promoted by Hansen it simply tax carbon emissions (or sales of fossil fuels), then return that money to the tax-payers (100% dividend) — see: http://www.columbia.edu/~jeh1/mailings/2009/20090226_WaysAndMeans.pdf . So a person pays a higher bill for coal-generated electricity and gasoline, but they in effect get that extra cost back as cash to spend any way they choose. Smart, economically minded people (even if they were not environmentally minded) would then figure out how to reduce consumption of fossil fuels — maybe go on wind-generated electricity, buy a fuel-efficient vehicle, move closer to work, spend vacations closer to home, etc., and have money left over to pay off their mort-gage, or whatever. Hypothetically their extra money would not go into buying fossil-fuel intensive products, since the emissions tax would also be included each step of the production/transportation process.
Prof. T. Heidrick,
It would seem that most of your questions are answered here:
http://www.aip.org/history/climate/index.html
Also, try here:
http://ipcc-wg1.ucar.edu/wg1/FAQ/wg1_faqIndex.html
Also here:
https://www.realclimate.org/index.php/archives/category/extras/faq/
Climate science is not in its infancy.
To move forward in 2010 there seemingly needs to be certain key steps taken in order to achieve better international consensus. I would suggest the following:
1. A new international task-force set-up, charged with the responsibility of establising an officially recognised database for ‘Global temeprature’ to support all future policy planning.
2. This database would be generated from an agreed set of globally-representative surface stations whose construction, siting and instrumentation would be documented to agreed standards and whose data would be available and auditable.This would be both retrospective and prospective.
3.The global database creation ,management and reporting would be subject to internationally recognised quality standards.
In essence, this is like moving a research project into development or production.
Globally , we dont really need to keep on discussing the relative merits of one dataset v. another, or to keep on with the rather sterile debates about the fragmented ( including the changes in station numbers over time ) raw data and whether its available because of local national agreements. We need to move on with the bigger global picture.
This type of international quality standardisation would be expected in many other fields of medicine, transport, construction etc, and with the global budgets being reported, amounting to ‘trillions’ if you believe Copenhagen, some structured cost-effective approach to underpin global policy decisions,seems long overdue.
Or, we can sit here and ‘blog’ and call each other ‘names’ and dismiss any contrary views …”oh please ….” for the next years. Just a thought !
Re#468, which datasets are you referring to ? Thanks
Bill,
While I appreciate the sentiment of #471, I would point out that that we now have 4 independent datasets–2 terrestrial and 2 satellite–that have been investigated and reviewed out the ying-yang. And they all pretty much agree as far as trend. You only need to debate the merits of different datasets when they disagree significantly. This is manifestly not the case, and what is more, the trends shown in these databases are backed by qualitative and quantitative observations of ice melt and other temperature sensitive indicators. I do not see the point in reinventing the wheel when the vehicle has 4 good wheels already.
I would also point out that the IPCC is just such an “international task force,” and look at how well that has been embraced by the denialists. It does not matter what standards we follow. It doesn’t matter how open we are. No matter what we do. No matter what evidence we have, the denialsophere will continue to denounce climate science and science in general as a fraud. Their position has never given consideration to such trivialities as evidence.
Jason- since when is a reviewer “going to town” on shoddy work a *bad* thing? It’s a pathetic accusation because not only does he have any evidence, but if there *were* evidence it would be that …
someone’s doing their job as a reviewer. Dismantling substandard work. That was the implication of that oh-so-evil e-mail that Jason’s snidely referring to. And this is now a bad thing, apparently.
TRY: maybe IR output signature is a predictable, testable item. Maybe not.
BPL: Already tested. Against time. AGW confirmed. But you just keep refusing to acknowledge it.
Ray, on #473.
I appreciate your response but I’m concerned that we are not moving forward in a systematic way. The more I look into the ‘terrestrial’ datasets which we rely on for long-term data ( not just trends’ but absolute values), the more I worry about their real independence and their derivation from the numbers collected from a hugely varying number of ground stations. The real raw data,in other words.
Secondly, some of this data is questionable, and in other fields of science, the best way to resolve this is to set-up an independent group to investigate and report, the IPCC has lost public credibility now…
I’m absolutely not suggesting reinventing wheels, but checking and tuning the engine, and then producing a certificate of airworthiness’ , so to speak
Yet, that’s exactly what your first sentence suggests.
Ray’s right, it doesn’t matter how research, review, and reporting is structured, denialists will deny, and claim it’s all fraudulent.
461: Gavin. In your comments on Plass’s paper you wrote: “First, although the residence time for carbon dioxide in the atmosphere (the total amount of CO2 divided by the flux in and out of the ocean) is on the order of a few years, the perturbation time is much longer—even up to a few tens of thousands of years—because of the slow uptake in the deep ocean and the buffering effects of the ocean chemistry.”
I’m trying to understand what you meant by “perturbation time”. If we write Co2_O for the concentration of CO2 in the ocean and Co2_A for that in the atmosphere and there were no chemistry one might write
d Co2_A/dt = (Co2_O-Co2_A)/tau_R
where tau_R is the residence time for CO2 in the atmosphere. In this case the perturbation time would be the residence time. But if you include ocean chemistry which involves Co2_O going up and down as well, that the evolution of a perturbation to atmospheric CO2 would take much longer than tau__R to equlibrate because of all these additional reactions? You might write:
d Co2_A/dt = (Co2_O-Co2_A)/tau_R + f(Co2_A,Co2_O, … )
d Co2_O/dt = (Co2_A-Co2_O)/tau_R + …
…
and now you ask on what time scales do perturbations to this system die out?
Or were you talking about something else entirely?
re#477.The resolution of source data questions should not be seen as denying or supporting . If you cannot accept that their is widespread public perception of ‘questioniable ‘about data ,policy and process, I dont know where you have been.
Any future global policy clearly needs widespread public support and what may swing that could be a credible new and independent approach using internationally acceptable standards for data quality in support of policy decisions. We are far from that today……..
Bill@476, One might accuse science of many things, but lack of systematic progress is not one of them.
You say you are disturbed by problems you see in raw data from terrestrial stations. Do you contend that the folks who process such data for a living (and have been doing so, I note, for decades) are unaware of these problems? They certainly go to great lengths to correct for any problems they do know about. I would say that evidently they are fairly successful, too, since the entire network of stations yields trends consistent with those using only “known good” stations:
http://www.skepticalscience.com/Is-the-US-Surface-Temperature-Record-Reliable.html
This coupled with the facts that:
1)Independent errors at over 1000 stations are unlikely to yield a “trend” but instead result in increased noise
2)Both independently processed terrestrial datasets yield consistent trends, and these trends are consistent with those revealed by satellite-based datasets.
3)The temperature trends we see in all 4 of these datasets are consistent with qualitative changes we see taking place globally today.
So, I think what you have is a solution in search of a problem. Remember, all data have errors. What matters is 1)whether you can correct or othewise mitigate them; and 2)whether the errors significantly affect results of the investigation.
Now as to your proposal for an independent body, who would you suggest. Clearly, given the villification of the IPCC, the UN would not be seen as an acceptable overseer. The science has already been reviewed by National Academies in every major industrial nation on the globe. Professional and honorific scientific societies have also looked in detail at the evidence and methods of climate science, and not one dissents from the consensus science. Hostile legislative committees have been over the whole enterprise and found nothing they could trumpet as a serious flaw.
So, I ask you, who is left?
Watch for this news, which will hit hard at the concern about verifying honest reporting of carbon controls, I expect.
http://www.google.com/search?q=chinese+stock+market+ponzi+scheme
Matthew states boldly: “There are lots of mitigation strategies. $1 trillion spent over 10 years by the US and EU, if used (as some has been up till now) to finance construction in India and China, will not lead to CO2 reduction before 2050, and maybe not in this century”
Please prove this or be ignored.
476 Bill. Its a done deal:
http://www.wmo.int/pages/gfcs/index_en.html
Standards of observation and data management have applied for about 100 years already, coordinated by agreements between the various governments.
A simplified standard accessing system is being added. It just takes some time as there are those 190-odd national governments involved.
Re #483, it looks like the WHO in medicine when we actually need a FDA !
dhogaza (474):
“Jason- since when is a reviewer “going to town” on shoddy work a *bad* thing?”
Well, we don’t know yet if it is shoddy work or not. It seems to me from the context of his post that he is suggesting that somebody is abusing the review process to keep McIntyre’s comment out of the literature no matter what.
I certainly agree that letting rubbish get published just to appease someone is nonsense.
469, Lynn Vincentnathan
I am in favor of lots of personal and societal investments to reduce energy use and address the possible consequences of CO2 accumulation, but not all proposed investments, and not without considering accurate computations of actual trade-offs. Beginning 20 years ago or so, I gradually replaced all my incandescent lightbulbs with compact fluorescents; now I am gradually replacing my compact fluorescents with full-spectrum LEDs. Doing so too rapidly would be a bad idea because the full-spectrum LEDs are manufactured in China using electricity from fossil fuels (or possibly nuclear, which I do not regard as bad.)
I also pay the premiums on term life insurance. But that does not mean that I actually believe that I shall die this year, or that I try to prove to all my friends that I shall die.
My real point in addressing the issue of motive is that every adult has multiple motives, and these ideas about motivated beliefs should be omitted from the discussion of the science of AGW. I hope I did not seem to impugn your motives personally.
482, Completely Fed Up: Please prove this or be ignored.
Which, that the EU is using its carbon offsets to finance the construction of CO2-spewing industries in China and India, or that CO2 production in China and India will not start to decline before mid-century, or that $1trillion could be wasted? I don’t care much if people ignore me, but evidence related to these possibilities is published every week, and available online. If there is a thread here devoted to public policies related to AGW, instead of evidence for and against AGW, then I’ll elaborate. For one example, the state of California subsidizes the purchase of PV cells, almost all of which are manufactured in other places, a majority of them in China; that does not reduce the carbon footprint of California, it merely moves it to China, which is in fact building its coal-fired electricity generating capacity faster than at any previous time in Chinese history. China is also building its non-fossil fuel power industry, but Chinese CO2 output will increase for decades.
What China does with coal and oil does not affect the evidentiary status of AGW (pending the Earth’s response to increased “Sinogenic” CO2), but it should affect the way Americans think about policy choices.
103, Lynn Vincentnathan: A helpful book re how we can reduce our GHGs by 75% without lowering productivity is NATURAL CAPITALISM – see http://www.natcap.org . Also http://www.rmi.org
Some of the debate is about timing, some is about goals (e.g., for some an important goal is to preserve/expand American military power, which is at serious risk if the military depends on oil shipping slowly across the oceans), some is about financing, some is about which technologies to use (e.g., some oppose nuclear but others support nuclear), and some is about government mandates.
210, Martin Vermeer: We know too much, not too little.
If that were true, the models would be exact over all time scales.
Background is that one of the purloined e-mails written by a reviewer used the phrase “going to town” describing the review task awaiting him. In the context it’s obvious the reviewer thought he was being asked to review crap, and by going to town he meant he was going to dismantle it thoroughly to back up his rejection.
And Jason would appear to think this is a bad thing.
[Response: I don’t really know where you are coming from on this, but there is a demonstrable long-term rise in ocean heat content that is matched by the models. The actual mechanism is very straighforward – there is a net positive flux of heat at the surface which gets mixed through the mixed layer (mainly by wind stirring and convection) and which then is diffused and advected into the deep ocean. – gavin]
If that long term rise in ocean heat cannot quantitatively be attributed anthropogenic causes then AGW science has a huge hole in it. The oceans are potentially free to both cool and warm as they like and take the global temperatures along with them.
In that case any AGW “effect” could be a small increment to an otherwise naturally varying climate and the case for continued increases at the observed rates diminishes considerably.
Currently to my knowledge there has been no work done to quantify the effect demonstrated in “Why greenhouse gases heat the ocean” and so I’m wondering what the models use as the basis for their heating but particularly with respect to any “forcing” from anthropogenic CO2.
[Response: Still don’t get the point you are making. People have been measuring heat fluxes, turbulence, mixed layer dynamics and the like for decades. Peter Minnett (who wrote that article) is a very active ocean-going scientist. The models warm the ocean when you increase the forcing, not through some special physics that only has to do with CO2, but because the net impact of increasing heating at the surface serves to warm the ocean. I don’t see why that is at all problematic. Perhaps if you were more explicit in what it is you don’t get, then I could be more use. – gavin]
Mark A. (344) & others — Here is some reading about GCMs:
“A Climate Modelling Primer” by Henderson-Sellers
Introduction to Three-Dimensional Climate Modeling 2nd Edition
Warren M. Washington and Claire Parkinson
http://www.palgrave.com/products/title.aspx?PID=270908
https://www.realclimate.org/index.php/archives/2008/11/faq-on-climate-models/
https://www.realclimate.org/index.php/archives/2009/01/faq-on-climate-models-part-ii/langswitch_lang/tk
http://www.climatescience.gov/Library/sap/sap3-1/final-report/sap3-1-final-all.pdf
http://bartonpaullevenson.com/ModelsReliable.html
[Response: …The models warm the ocean when you increase the forcing, not through some special physics that only has to do with CO2, but because the net impact of increasing heating at the surface serves to warm the ocean. I don’t see why that is at all problematic…. – gavin]
The effect is described in that article as a mechanism to “keep the heat in” and again as far as I’m aware there is no science that quantifies the effect. How can this not be problematic if it turned out that the effect could not account for the observed warming when it was further analysed?
It is those assumptions the models make and mechanisms they use to warm the ocean that I’m interested in. The oceans dont simply “warm” from CO2 downward longwave radiation as per the article and I’d like to see what the models DO use as far as anthropogenic forcings are concerned.
There must be a finite number of inputs to ocean heating and I’d like to know what they are. Can you please provide that?
[Response: The heat budget at the surface is made up of the latent heat of evaporation, sensible heat exchange, downwelling solar radiation, downwelling long wave, upwelling long-wave, and small terms associated with the temperature and state of any fresh water flux (rainfall or ice melt/formation). – gavin]
“Response: I don’t really know where you are coming from on this, but there is a demonstrable long-term rise in ocean heat content that is matched by the models. The actual mechanism is very straighforward – there is a net positive flux of heat at the surface which gets mixed through the mixed layer (mainly by wind stirring and convection) and which then is diffused and advected into the deep ocean. – gavin”
Is this theoretical or has it been observed empirically? Are you trying to tell us that heating of the oceans by this process is greater than the absorption of heat from direct solar radiation?
Please explain the advection process to the deeper layers. Have the deeper layers exhibited a significant increase in heat content as a result (Ref. please).
Tim, is this what you’re looking for? Oceans are more complex, but the basic mechanism of warmer air transferring heat to surface water happens in lakes too:
http://www.agu.org/pubs/crossref/2009/2009GL040846.shtml
Satellite observations indicate rapid warming trend for lakes in California and Nevada
“Large lake temperatures are excellent indicators of climate change; however, their usefulness is limited by the paucity of in situ measurements and lack of long-term data records. Thermal infrared satellite imagery has the potential to provide frequent and accurate retrievals of lake surface temperatures spanning several decades on a global scale. Analysis of seventeen years of data from the Along-Track Scanning Radiometer series of sensors and data from the Moderate Resolution Imaging Spectroradiometer shows that six lakes situated in California and Nevada have exhibited average summer nighttime warming trends of 0.11 ± 0.02°C yr−1 (p < 0.002) since 1992. A comparison with air temperature observations suggests that the lake surface temperature is warming approximately twice as fast as the average minimum surface air temperature."
Or are you looking for an explanation of why warm air transfers heat to water?
I have a question about long term solar cycles.
I understand that GISS includes the ~11year sunspot cycle, which has a minor effect. There is also a longer term variation, with a periodicity of about 200-300 years, shown here:
http://www.globalwarmingart.com/wiki/File:Carbon_Derived_Solar_Change_png
It seems from this that we are just passing the peak of the modern solar maximum, and that for the next 50-100 years we should hopefully be in a period of solar decline. There does seem to be a visual correlation between these solar declines and lower global temperatures.
http://www.globalwarmingart.com/wiki/File:Carbon_Derived_Solar_Change_png
(second figure down, apologies for crude nature of the work)
So the question is, can we run the models with these longer solar cycles included?
Dare we hope that a few decades of solar decline may give us much needed time to decarbonise the global economy effectively? Or would less severe projections simply give the denialists an opportunity to persuade the politicians to continue BAU?
As I see it now
Energy conservation in a single wavelength. The italicised conclusion in the penultimate paragraph of my comment (as I saw it then):
https://www.realclimate.org/index.php/archives/2009/12/updates-to-model-data-comparisons/comment-page-5/#comment-152066
was wrong. Energy cannot be conserved at a single wavelength. (Gavin response at #170 covered this more concisely). Although it appears at first sight that the radiation transfer equation decouples the wavelengths from each other an extra condition such as energy conservation cannot be applied to individual wavelengths without producing a contradiction. It is first necessary to integrate over all wavelengths. This allows energy to be transferred from one wavelength to another as TRY suggested.
But what about the rest of TRY’s argument? (S)he invoked a thought experiment in which a narrow band of wavelengths was fired upward into the atmosphere. Suppose that this was all there was, i.e the black body spectrum from the surface was replaced by a highly concentrated beam. Asssume that the wavelengths were chosen within the absorption bands of e.g. CO2. This may be a highly artificial experiment and many things would change. But for the sake of argument suppose that it happened for a brief interval of time.
Would this affect the downward greenhouse radiation? I don’t see why? Wouldn’t we still see the CO2 signature , as well as the CH4 signature and the H2O signatures just as before? If this downward flux changed with time wouldn’t it still be possible to attribute it to an increase of CO2, CH4 etc? Thermalisation is equivalent to a loss of memory of the character of the exciting radiation from the ground. You would still have a problem with overlapping absorption bands, which could be unravelled by doing the radiation transfer calculations.
TRY also enquired as to the ultimate fate of the energy of absorption. In the highly simplifed case of neglecting local heating it would all go into the energy of the downward flux of greenhouse emissions. But to answer it better you would need e.g Raypierre’s book and some runs with the radiation transfer programs.
Was TRY trying to throw doubt on these calculations? I wouldn’t be surprised. But I suspect that he would have to try really hard indeed.
[Response: The heat budget at the surface is made up of the latent heat of evaporation, sensible heat exchange, downwelling solar radiation, downwelling long wave, upwelling long-wave, and small terms associated with the temperature and state of any fresh water flux (rainfall or ice melt/formation). – gavin]
So am I to assume the downwelling long wave term is an approximation for the actual effect described in the article “Why greenhouse gases heat the ocean”?
Could you quote where the values used for term have come from?
[Response: Each term is calculated as a function of the temperatures, composition, cloud cover, etc at each time step in the model. Downward LW increases with higher CO2 and water vapour, but all of the terms vary with climate change and the net change is positive down. – gavin]
TimtheTool, If you’ve ever been diving, you know that visible light penetrates the water to at least about 10 meters, right? You know that as you go deeper, the light is extinguished, indicating that it is being absorbed, right?
You know the skin surface effect occurs and about what magnitude it is, right? We know that decreased gradients decrease heat loss, right?
And we certainly know the ocean is warming, right?
So, we have a mechanism that we can put in the models. We have model results that agree pretty well with observations. What is missing?
As you can see from Peter Minnett’s site, he’s been busy looking at stuff like this. http://www.rsmas.miami.edu/personal/pminnett/Complete_List/complete_list.html
Geoff,
I see no reason to doubt TRY’s bona fides. He/She was at least asking interesting questions that illuminated the physics–as evidenced by the fact that they helped you understand it better. I find equipartition to be a very powerful concept in understanding things. If you start out with an situation far from equilibrium–e.g. all radiative energy in a single wavelength–the system will move toward what it would look like at equilibrium if at all possible.
In the case you posit, the outgoing IR line will excite CO2 molecuses. These will relax–partly radiatively in the same line, but probably broadened by collision, but mostly collisionally. This will impart kinetic energy to other molecules, shift the distribution of energies upward, and any other modes that aren’t frozen out (e.g water vapor, CO2, N20,…) will also be excited.
My caveat wrt TRY’s suggestion is that we’re looking at a climatic process, so a mere snapshot will not be sufficient to demonstrate the long-term trend of warming. Snapshots taken at different times will give slightly different results. We have these snapshots. They look like what you’d expect from a world warming due to greenhouse effects. What we really need is to turn the snapshots into a movie covering 30 years.
486, Matthew:
“For one example, the state of California subsidizes the purchase of PV cells, almost all of which are manufactured in other places, a majority of them in China; that does not reduce the carbon footprint of California, it merely moves it to China, which is in fact building its coal-fired electricity generating capacity faster than at any previous time in Chinese history.”
I think it is worth noting that with an energy payback time of 1-4 years and consequently an Energy Returned on Energy Invested ratio of between 10 and 30, it does reduce the carbon footprint of California even while shifting it to China. It doesn’t really matter if the PV cells are manufactured using coal-fired electricity — it would still be a win to make them as quickly as possible (and therefore increase their contribution to the energy mix as rapidly as possible) rather than wait until there was sufficient “PV power” to manufacture them.
The EROEI ratio would have to be 1 or less for the net effect to be nothing more than shifting California’s emissions to China.
As an aside, China is also increasing its wind power electricity generating capacity faster than at any previous time in Chinese history — it looks like they hit 22.5 GW at the end on 2009 and are on target to beat their 2020 target of 30 GW by the end of this year. (If those figures are correct, they added 10.3 GW in 2009 alone.)
NB: I posted as “Jason” in the “CRU Hack: More context” thread. I’m sure you’ll forgive me if I change moniker at this point. :-)