The detection and the attribution of climate change are based on fundamentally different frameworks and shouldn’t be conflated.
We read about and use the phrase ‘detection and attribution’ of climate change so often that it seems like it’s just one word ‘detectionandattribution’ and that might lead some to think that it is just one concept. But it’s not.
Formally, the IPCC definitions are relatively clear:
Detection of change is defined as the process of demonstrating that climate or a system affected by climate has changed in some defined statistical sense, without providing a reason for that change. An identified change is detected in observations if its likelihood of occurrence by chance due to internal variability alone is determined to be small, for example, <10%.
Attribution is defined as the process of evaluating the relative contributions of multiple causal factors to a change or event with a formal assessment of confidence.
IPCC SR1.5 Glossary
Detection is therefore based on a formal null hypothesis test (can we reject the null hypothesis that climate is stationary?), while attribution is a Bayesian statement about how much change is expected from what cause. They don’t formally have that much to do with each other!
Note too that detection requires knowledge only of the expected climate in the absence of the effect you are trying to detect, while attribution also needs knowledge of the expected climate with the effect included.
Historically, these steps were performed sequentially: first a change was statistically detected, and then, once there was a clear change, an attribution study was performed to see why. This makes sense if you want to avoid chasing a lot of false positives (i.e. finding non-random causes for things that turn out to be random noise). But there is a fundamental problem here to which I’ll return below. But first, an easy example:
Global mean surface temperatures
With respect to the global mean temperature, the detection of climate change was quite fraught, going from Hansen’s 1988 declaration, the backlash, and the tentative consensus that emerged after the 1995 Second Assessment Report (itself subject to a barrage of rejectionism focused on exactly this point). However, in hindsight, we can conclude that the global mean surface temperature signal came out of the ‘noise’ of natural climate variability (i.e. it was detected) sometime in the early 1980s. An example of how to show this uses a specific kind of climate model simulation (and lots of climate models) and the observational data. We look at a set of simulations (an ensemble) run with all the natural drivers (the sun, volcanoes, orbital changes etc.). The difference between this ensemble (which incorporates uncertainty in internal variability and some structural issues) and the observational data has grown over time, and the point at which the observations depart from the ensemble spread (at some level of confidence) is the point at which a change can be detected relative to an unperturbed climate. Compare the black line with the green uncertainty band in the figure below:
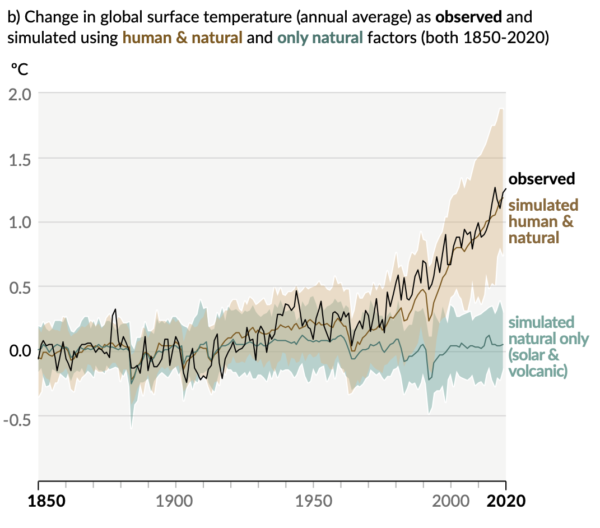
A second set of climate model simulations can be run with all of the factors we think of as important – the natural drivers of course, but also the anthropogenic changes (greenhouse gas changes, air pollution, ozone depletion, irrigation, land use change etc.). Like the observations, this ensemble starts to clearly diverge from the natural-drivers-only ensemble in the 1980s, and does a reasonable job of tracking the observations subsequently, suggesting that it is a more accurate representation of the real world than the original null hypothesis.
Note, however, that there are clear differences in the mean temperatures between the two ensembles starting in around 1920. With enough simulations, this difference is significant, even if it is small compared to internal variability. Thus we can statistically attribute trends in SAT to anthropogenic forcings for some 60 years before the anthropogenic effect was officially detected!
Another way of stating this is that, by the time a slowly growing signal is loud enough to be heard, it has been contributing to the noise for a while already!
Patrick Brown had a nice animation of this point a couple of years ago.
[As an aside, this features in one of those sleights-of-hand folks like Koonin like to play, where they pretend that anthropogenic greenhouse gases had no impact until the signal was large enough to detect.]
To summarise, uncertainty in detection depends on the internal variability (the ‘noise’) compared to the strength of the signal (the larger that is, the later the detection will be), whereas the uncertainty in attribution depends on the structural uncertainty in the models. The internal variability, which plagues detection, can always (theoretically) be averaged away in an attribution if the models are run enough times (or for enough time). Even small impacts can be attributed in this way in a statistically significant sense, even if they might not be practically significant.
Extreme events
As we’ve discussed many times previously (e.g. Going to Extremes, Extreme Metrics, Common fallacies in attributing extremes, extremes in AR6 etc.), we both expect, and have increasingly found, growing influences of anthropogenic change on many kinds of extremes – heat waves, intense rainfall, drought intensity etc. (CarbonBrief keeps great track of these studies). However, because of the rarity and uniqueness of particular extremes, it can be very hard to see trends – for instance, the UK had it’s first 40ºC day recently – and there is no time-series trend if you only have a single (unprecedented) point!
Trends can be seen if lots of events can be collated – for instance, in rainfall extremes or heat waves – over large areas (as discussed in Chp. 11 in AR6). For instance, if we aggregate the area covered by 2 and 3 sigma summer temperature extremes, you see a clear trend where a signal can be detected (after about the year 2000):
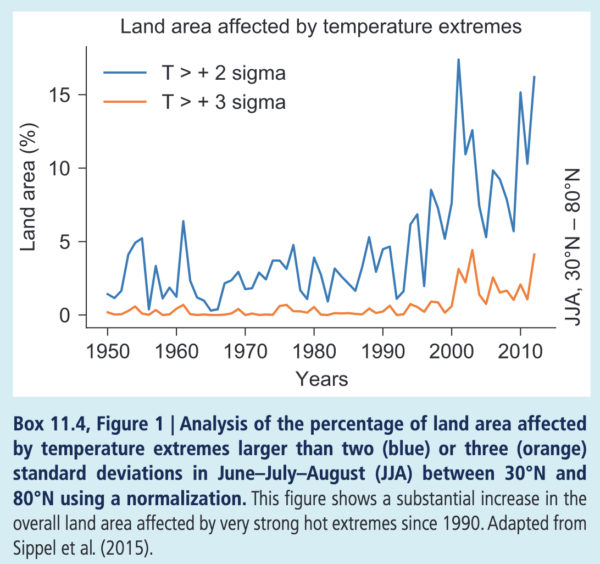
However, most of the other claims related to extremes are attributional, and not detections in the sense defined above. This should not however be shocking since it was clear in the surface temperature example that attributional statements are possible (and correct) long before a trend has come out of the noise.
There is one other point worth mentioning. Taken alone, an extreme defined by a record exceedance (the rainfall during Hurricane Harvey, the temperature in the recent UK heatwave, etc.) by definition doesn’t give a trend. However, if you lower the threshold, more events will seen, and if there is a trend in the underlying causes, at some threshold a trend will be clear. For instance, for the number of days with UK peak temperatures above 39ºC, or 38ºC or 37ºC etc., there aren’t perhaps enough events to see a trend, but eventually there will be a threshold somewhere between the mean temperature (which we know is rising) and the record where the data will be sufficient for a confident statement relating to trends to be made.
This state of affairs can (of course) be used to mislead. For instance, readers will be aware that trends in local variables or short time frames are noisier than the global or regional long-term means, and there will always be someone somewhere who tries to rebut the clear global trends with a cherry-picked short-term or local data-series (“You say the globe is warming? Well what about a single month’s trend at this island in Japan that you’d never heard of until just now?” Real example!). For extremes then, it’s a common pattern to attempt to rebut a claim about attribution related to specific event, with a claim that the local trend of similar events is not significant. As in the previous example, it’s not even wrong. Both of these things can be true – the intensity of an event can have been ‘juiced’ by anthropogenic climate change, and these kinds of events are rare enough locally not to see (as yet) a statistically significant trend. The latter does not contradict the former.
[One further aside, many claims about trends use a simple linear regression. However, uncertainty estimates from standard linear regression requires the residuals from the trend are Gaussian. This is rarely the case for time-series of episodic extremes, even if they come from the tails of a standard Gaussian distribution, and so the stated uncertainties on such calculated trends are almost always wrong – if they given at all. You are better off using some form of Poisson regression within a generalized linear model – easy in R, perhaps not so straighforward in Excel?]
Extreme impacts
How then should we think about the impacts, particularly going into the future? How can policy-makers make sense of clear attributions, global or regional detections, but statistically insignificant (so far) detections at the local scale? Assuming that policy-makers are interested in what is likely to happen (under various scenarios and with appropriate uncertainties), it’s should be clear that the attributional framework is more meaningful and that the timing of the detection of local trends is a mathematical sideshow.
But, but, but…
Hold on, some might argue, surely the detection step is necessary before the attribution makes sense? Isn’t the whole point about detection is so that you don’t spend unnecessary effort trying to attribute what might just be noise?
Let’s break down this argument though. If you know nothing about a system, other than a single historical time-series from which you can extract the underlying variability, you can assess the probability that a trend as large as that observed might happen by chance (under various assumptions). But now someone tells you that you have clear evidence that the process from which this data was drawn comes from a distribution that is definitely changing. That changes the calculation (in Bayesian terms, it changes the prior). The point is that your time-series of climate extremes is not isolated from the rest of the physical system in which its embedded. If there is a clear trend in temperatures above 36ºC, and also temperatures above 37ºC, but the data is too sparse to independently conclude the same for temperatures above 38ºC or 39ºC, this should still all inform your opinion about the growing chances of temperatures over 40ºC – even if that has only happened once! It is the attributional calculation gives you exactly what you need – an estimate of the increase in probability that this extreme will be reached, not the detection – that’s just candy.
Ok, that may be so, but the changes in the odds of an event derived from the attribution comes from a model, no? How reliable is that? This is actually a fair question. How robust changes in fractional attributions (or return times) are is an open question. It is hard to evaluate the tail of a distribution in a model with limited observational data. But when you get similar results with multiple and diverse models, applied to more and more examples across the globe, that helps build credibility. Longer time series and (unfortunately) growing signals will also reduce the uncertainty – as will better aggregations across regions for similar extremes – but conceivably we won’t know for a while if the changes of a rare event have gone up 5-fold or 10-fold.
That the odds have increased (for heatwaves, intense rain, drought intensity etc.) is, however, no longer in doubt.
“However, uncertainty estimates from standard linear regression requires the residuals from the trend are Gaussian”
I think your point in that paragraph overall is correct, but the statistical technical bit you mention not so much. Linear regression is well-defined without a Normality (Gaussian) assumption, as producing a linear, unbiased, minimum variance estimator. The estimator variance can be calculated, so the uncertainty estimate is technically correct in some sense. The Normality assumption however makes it easier to interpret the result probabilistically: this can be seen from the fact that a Bayesian formulation of the regression with Normality, under proper choice of priors, yields the same calculations and numerical result as the distribution-agnostic frequentist estimator. This is why I say that your point still holds; without Normality, the result must be interpreted much more carefully.
See, e.g., Gelman’s blog on Normality being the least important assumption:
https://statmodeling.stat.columbia.edu/2013/08/04/19470/
[Response: Thanks. That’s a good clarification. – gavin]
Missing the bigger picture, which is that detection and attribution of something as limited as a low-dimensional trend has little discriminating power. Can do all sorts of fancy statistical analysis of the residuals and it really won’t matter. As long as there is a mysterious natural variation of non-random character riding along with the time-series, that will always get in the way and make it difficult to definitively resolve the underlying trend.
And I’m not saying this to be a stick in the mud. Determining the trajectory of a natural climate behavior with as rich and complex a pattern as ENSO would likely enable any warming trend to drop out as a residual. The erratic pattern itself has much more potential discriminating power than a quasi-linear trend.
The adage should be that one can’t treat something as noise, when it’s not noise. Or to put it another way, one man’s noise is another man’s signal.
“Statistics” will not be of much help here, only for checkup and control given that you have first found out out and do not even have an idea of what it might be. .
It is about pattern recognition of unknown tings in common signals and random noise.
First when you know, that means have got an idea or a conscept of what to look for or what to listen for, then you will get it and get the meaning of it, and able to analyze and examine it critically.
“Is it dangerous? What is it? Is it an UFO or “alians” or is it a bear or a Dragon? Can it be The Russians?
Statistics will never find out that or decide on similar things if you have no idea of what Danger, UFOs, Alians, Bears, Dragons or Russians,.. etc etc etc looks or sounds or tastres or feels or measures like.
But given that you have an idea or a theory and a hypothesis of what it eventually might be or look or feel like, , then measurement and stratistics may be able to find that it is rather not what you believe or think that it is..
Your methods and tools must be phaenomenologically congruent and scaled first.
Your silly idea of real bears or whole elephants or horses can absolutely not be “emulated” in the lab, is helpless whenever you find bullshit or footprints or only a few hairs and go to the lab and teach: “Your lab methods can definitely not emulate whether this rubbish is due to a bear, a horse, or an elephant. The qualified lab will easily emulate and find out that for you, thus disqualify you. .
I have found out such things really many times enough in my lab. Even found out a few times that it is not what I thoutght it was, I was rather misconsceived of what it really is, and I will have to think again,…and find and design other methods in the lab for it
Statistics hardly works at all on such new and unknown things, You must first find out what it possibly might be.. Is it artificial? or is it rather natural? is it Extraterrestial? Or is it rather extreemly terrestrial?
Is it rather exactly what it looks like, fossile Troll- shit?
Wes it is. I can show people a prooven sample of that! Nobody would believe it and suggested all kinds of professionally destructive methods against such ridiculous rubbish and shit in my hands. But, I took it in then lab just by a tiny grain of sample substance.
Have to add this to highlight the reference https://youtu.be/snPDoXl9ZPs
Thanks for an illuminating piece.
I’m reminded of a discussion here on the ‘long before human influence could be significant’ meme, wherein it was pointed out that from sensitivity estimates we’d expect that CO2 should be causing a dT of maybe 20-30% of variability.
“…the intensity of an event can have been ‘juiced’ by anthropogenic climate change, and these kinds of events are rare enough locally not to see (as yet) a statistically significant trend…”
“Watching the detections” seems like it might be word play with the song “Watching the Detectives” by Elvis Costello.
[Response: You’d think so… – gavin]
Is that an attribution or a detection?
The simplest, most basic and elementary statistical point to be made here is that when a series is defined by y=error you of course see no trend and never will. When a series is defined by y = trend*x + error where the step values from the trend term is on the order of 1/10 the standard error of the error term (as actually observed in the various canonical series) you simply won’t see anything for a goodly number of steps (steps = years in this case usually). That is, in order to reach “significance” the series has to diverge by 2 full standard errors before it can BE detected in the first place and more like 30 years before it is reliably detected.
Of course denial types have capitalized on this statistical fact for decades generating all sorts of “findings”–e.g., the “hiatus” still beloved by a few denial types here to this day–when really all they were doing was to “infer” something from nonsignificant noise.
Tamino made this point and pretty much this same statement about inferring from noise on many occasions.
Paper on finding a difference in trend “”A Dilemma About Radiative Climate Feedback in Recent Decades” by Tim Andrews, et al (JGR Atmospheres, Aug 2022).
I asked why does the Indian Ocean Dipole, which is immediately west of the Pacific show a clear warming trend in contrast to the flat ENSO dipole which spans the main Pacific ?
see the Twitter thread:
https://twitter.com/Tim_AndrewsUK/status/1575911894816153600
I was also thinking that perhaps the trend was artificially removed from the NINO34 index but left in the IOD index (aka DMI)?
In any event, the Andrews paper suggests that spatial variability impacts the ability to infer the actual trend.
My former line manager reasoned along the idea that if natural variability dominates any trend in a timeseries, natural variability is the dominant factor when it comes to human impact from the severe/extreme events therefore climate change can only be contributing a small amount. I never felt comfortable with this argument although I found it difficult to solidly refute. There was a post on here I found somewhere which addressed this (I suspect flawed) claim (https://www.realclimate.org/index.php/archives/2014/03/the-most-common-fallacy-in-discussing-extreme-weather-events/), although I am still unsure whether or not there is a climate change influence on tropical cyclones. I can see arguments for and against.
Talk about shifting priors-
Three New Zealand climate communication philosophers have come up with a workaround for confusion arising from Bayesian complexity in the climate wars:
They’ve published a paper in Climate and Development calling for a moratorium on climate change research:
https://vvattsupwiththat.blogspot.com/2022/09/think-of-all-money-it-will-save-on.html
Very interesting and clarifying indeed. Thank you, Gavin!
I just stumbled over this amazing presentation by Charles Long, Senior Research Scientist NOAA
Is it not amazing how global warming shows a strict north-south divide (with the excpection of Byrd station, lol), starting in the 1970s essentially? I know, there are plenty of add-ons to the plain vanilla CO2 forcing – feedback theory to account for all those specifics. Yet such add-ons hardly ever improve a theory and instead bringt up the question why they are required in the first place. Anyhow..
Charles Long:
“Usually what we do is we form a hypothesis and then we try our best to prove it false.”
Not in climate science, I guess ;)
Sorry for the cheap shot. Charles has something way more substantial to say, despite his best efforts to bite his tongue..
“There is not huge W/m2 thing. Though if the clouds were’t there over an increase of 4W/m2 per decade is much, much, much larger than the projected increase due to greenhouse warming. They are talking about 4W/m2 under certain scenarios over or 40 years. This is in 10 years..”
“In the greenhouse world.. I want to be very careful about how I say this because I don’t wanna, I don’t wa.. but part of the problem that we have is, we are talking about some change over a couple of watts/m2 over a 50 or a 100 years. It’s pretty hard to grasp that we are really doing this. This is a more emidiative thing and you can see this..”
https://www.youtube.com/watch?v=GoGZrwzWHJI&t=1313s
(Specifically from 0.34:00 on)
I’m sorry, but what was your point. Clearly Dr. Long is not casting doubt on the importance of greenhouse gasses. He is on record saying that the current climate change epoch is a threat that needs to be mitigated.
And the idea that one has to propose a “hypothesis” in this case is simply absurd. In this case–the theory–that greenhouse gasses would warm the climate–predates the observation of significant warming by decades! It was a prediction by the theory that was confirmed.
Methinks you are not listening to what is said with an open mind.
Long is actually talking about his hypothesis that jets are causing it. The guy asking the question said he didn’t hear him say it was a hypothesis, so he clicked back to the slide that states his hypothesis: it’s the jets. The paper is not about jets producing CO2. So yeah, he’s not listening to what was being said. Long was not being critical of climate science at all. Complete miss.
ES: “I know, there are plenty of add-ons to the plain vanilla CO2 forcing – feedback theory to account for all those specifics. Yet such add-ons hardly ever improve a theory and instead bringt up the question why they are required in the first place.”
BPL: Because more than one thing can affect something else. In this case, more than one thing can affect the surface temperature of the Earth. Here’s an example:
https://bartonlevenson.com/GreatStasis.html
True, a lot of things are affecting the (surface) temperature of Earth. Now what concers me, and concerned Dr. Long (who sadly passed away in 2019 as I only learned after my OP) is that we are whitening the skies due to aviation. We have confirmation on this from different occasions, like post 9/11, like the shutdown of air traffic over Europe due to the icelandic volcano with the unspeakable name, and of course more recent covid related lockdowns.
The physical basis is pretty straight forward, but let me explain it as Dr. Long did not. A total cirrus cover would theoretically produce a net forcing of 60-70W/m2. Current estimates are that contrails and/or aviation induced cirrus would cover ~0.1% of the global skies. And 0.1% of 60W/m2 are 0.06W/m2, which is exactly the figure the IPCC states.
This 0.1% figure however is in question and there Dr. Long’s presentation is quite explicit. And I tend to agree with him. We are talking about something magnitudes larger and it has not been accounted for.
I found this especially interesting “Note, however, that there are clear differences in the mean temperatures between the two ensembles starting in around 1920. With enough simulations, this difference is significant, even if it is small compared to internal variability. Thus we can statistically attribute trends in SAT to anthropogenic forcings for some 60 years before the anthropogenic effect was officially detected!
Another way of stating this is that, by the time a slowly growing signal is loud enough to be heard, it has been contributing to the noise for a while already!”
For long I have suspected this to be the case. But, at least in the scandinavian scientific litterature about climate change in the thirties, fx. the dramatic retreat of glaciers that began after 1930-31 (marked endmoraines from these years almost everywhere in Scandinavia and the Alps, in Iceland and many places in Greenland in the frontal zones) and didn’t end/pause until the cooling in the sixties to seventies), the marked warming in the climate from Greenland to Scandinavia and the Alps is always attributed to “the sun”, meaning the solar constant, Ts.
But *always without any evidence whatsoever*! That’s my point here: attributing warming to “natural causes” before ca. 1980 is almost always automatically seen as uncontroversial, with some known exceptions (see below) which are rarely discussed.
That’s rather strange, given fx. the fact, that the tiny airbubbles in the upper parts of icecores from the icesheets in Greenland and Antarctica definetely all show, that the CO2 level in the troposphere began to rise markedly from around 1750, exactly at the same time as the global advance of glaciers from around 1400 (“the little ice age”) came to an end. Fx. in 1648, the swedish army conquering Denmark was able to cross the broad (1,5 hours to cross by ferry) sound between the country’s two biggest islands on the seaice, and the peasants in parts of western Norway complained to the king in Denmark about advancing glaciers taking away their grasslands, some arms of Jostedalsbreen, the biggest glacier on the european mainland, advanced several kilometers in about ten years around 1750 (though it’s not clear if this was mainly due to snowy winters and/or cool summers). In Greenland it was bitterly harsh winters too. Generally, the little ice age is normally attributed to two factors 1) the “Maunder” and “Spörer” minimums in sunspot numbers and 2) a period of highthened .volcanic activity around the globe. Of these two, 1) is not very convincing, since attemps to couple the sunspot numbers with Ts show only variations of less than 0,1-0,2 w/m2.
Then we have the “early anthropogenic hypothesis” by Ruddiman et al., https://www.sciencedirect.com/science/article/abs/pii/S0277379120303486 which to me seems to be at least somewhat in conflict with the declining temperatures since the end of the climatic optimum i the beginning of the holocene and with the fact that CO2 levels in the Eem were higher than the 240 ppmv postulated by Ruddiman, namely 280 ppmv. I would like to hear some comments on that from the experts here.
One interesting approach is to look at the number of record-breaking events and relate this number to the null-hypothesis of the data being independent and identically distributed (iid). This may provide a framework for the detection of trends in extremes: http://onlinelibrary.wiley.com/doi/10.1029/2008EO410002/pdf
Ladies and Gentlemen
I wonder more and more how many of you can exel so proudly and boldly on statistical conscepts, doubting all the way that you have the datalogging and punching or tipping capacity for that. Statistical data programs of course, those are in free sale for your PC desctop computers , but what about the data- logging and input?
Me and a colleague once took out a patent that became “AGAs Geotracer” for logging of graphical data, that was quite a meticious and boring work traditionally, by millimeter ruler and pencil from online servography, even osvcilloscope photo. Then later I was asked to make an optical device for conscious cartographic work, where a conscious living person sat there day out and day in and examined air photography that is online and analogue data from Nature, stereoscopically in order to draw and print elevation curves on mass produced maps.
Now, what do you do with an elevation curve if a large house or a huge semitrailer suddenly has come up and expected to vanish again?
the problems and difficulties will not be different at mapping and statistics for the climate dispute data and information.
Objections are unqualified…
Because on the Internet you get 3×3 common photos of common , suburban reality for judging and examination, “Show that you are not a ROBOT, which of theese pictures contain a bicycle, a bus, a horse,…”
Which takes conscious brains different from statistics, virtual reality, virtual intelligence, and ROBOTs. The EXPERTS quite especially will fail and can be disqualified and sorted out there,
Again objections are unqualifried, I repeat…!
Are there any “pattern objects” in it?
Is it a Dragon? is it a horse? is it a bear? is it a Troll? Is it Bullshit?
No statistics no machines no Robots, can decide for sure on that. But conscious and trained experienced humans can.
Is it any danger? Is it any trend? Is it noise? Is it device error? Maybe it is fraud?
Have you actually got the judging and data logging data examining capacity for theese basic things inn all yo0ur statistics and confidence and error bars,….. or are you only eating and selling industrialized highly destilled and refined dilettantism of quite proud and most professioinal kind in virtual reality?
Traditional academically responsible students were set on very critical examinations. For instance in the chemical analytical lab. They get a messy mixture of powders in a glass, “The Substance” and had to identifry Kations and anions systematically and to put that together again as plausible pure chemical powders. Including some of the worst, such as pure white natural sand, strongly burnt or fossile rust, fossile carbon…, and BaSO4.
Arsenik was easy.
But then as last tests,… co0mmon sawdust and even …. bullshit… mixed int9o it to examine whether they had perhaps gone out of their mind and lost their common sense during their serious professional studies.
Q Is n`t there a lot of mess also in the climate and in the Data, and what is then the nature, confidence, the Std and the Error- bars of that?
Q2: in othe words, is your convensional professional operational standard theory and device compatible to Nature , to the Universe, and to the Real climate all then way?
How would the emerging “Storyline Approach” to climate change fit into this framework of distinguishing between detection and attribution? Would it be something like a likelihoodist school-of-thought approach, in contrast to how Gavin presents the frequentist school of detection and the bayesian school of attribution? Or merely a proposed solution to the problem of Type II errors in detection efforts? Is it a school of thought that has even garnered enough support to be taken seriously within the climate science community?
(I ask as someone with a science background from a totally different field, but my side gig supports climate research. So if my questions seem “not even wrong” it’s because that’s true lol)
[Response: That approach AFAICT works for thinking about impacts, worst case scenarios, climate-society interactions etc. and I suppose acts as a complement to probabilistic information. – gavin]
The air temperature near the earth’s surface is the measure of global warmth. The temperature depends on two sources: air’s temperature and the adjacent earth’s surface temperature.
Weather stations measure the air temperature. From these, meteorologists take the day’s high and low to calculate the day’s average. This calculation is for the daylight average when heating is occurring. Ignored is the nighttime cooling which is calculated based on today’s high and tomorrow’s low. Very seldom, do the degrees of heating equal the degrees of cooling. The unevenness in the heating and cooling is a result of cloud effects.
Global warming can only happen in two ways: a slight increase in heating or a slight decrease in cooling. Clouds control both. Fewer clouds cause more heating and more clouds cause less cooling.
Can the global warming issue be so simple as a cloud explanation? What is known about clouds?
The source of clouds is the water cycle
Clouds are contained in the troposphere
Cloud formation is determined by the dew point
Cloud life and shape change minute to minute
Cloud categories are, low, medium and high level
Cloud movement depends on the wind source
Cloud temperatures fall with an increase in elevation
Clouds dominate the pm period of the day.
Clouds dominate the Tropical Zone, less in the Temperate, and least in the Polar.
Clouds contain 0.2-0.5 grams of water per cubic meter
Cloud tops absorb and reflect the sun’s radiant waves
Cloud bottoms absorb infrared waves
Clouds produce rain, snow, and ice crystals
Low level clouds dominate over the ocean, high level over the land
Clouds provide shade during the daylight hours
Clouds are the source of lightening
The lack of clouds produce draughts
While mankind can alter the earth surfaces and cause climate change in local geographical areas, it is unlikely that any human actions can be of a magnitude that can measurably change the earth’s global cloud conditions and their effect on the earth’s temperature.
Delbert Lipps
B.S. Chemical Engineering, Louisianan State University
“it is unlikely that any human actions can be of a magnitude that can measurably change the earth’s global cloud conditions and their effect on the earth’s temperature.”
You provide no evidence other than your incredulity based on rather, uh, nebulous ideas. Consider it might be a tad arrogant for you to think that reality is bound by the limits of YOUR imagination. As well, it is more than a tad arrogant to think that your incredulity outweighs the evidence of thousands upon thousands of persons actually doing research in the field. You can view the compiled evidence many places which are all well-referenced on this very site. You could also read the latest State of the Climate and IPCC reports.
Utter bullshit!
That which is asserted without evidence can be dismissed without evidence–not that evidence against your point of view is in short supply. I just refuse to spend more than one second per denialist IQ point in arguing against them.
30…that’s about right.
Delbert Lipps: –
Delbert, then how do you explain the observed rapid rising of global mean surface temperatures (relative to the 1880-1920 average baseline) shown in Figure 1 in a commentary communication titled Global Temperature in 2021, published 13 Jan 2022 by Dr James Hansen, Makiko Sato and Reto Ruedy at the Columbia University’s Earth Institute?
http://www.columbia.edu/~jeh1/mailings/2022/Temperature2021.13January2022.pdf
Prof. Dr. Will Steffen, Professor of Climate Sciences at the Australian National University and contributing author to the IPCC Special Report on 1.5°C (2018), summarises the urgent and deteriorating state of the climate and ecological crisis and why we must confront this reality before we lose our ability to adapt, in the YouTube video titled SR Australia – Social and Earth System Tipping Points | Prof. Will Steffen + Dr. Nick Abel, published 3 Apr 2022, duration 1:02:28. From time interval 0:05:38, Will Steffen stated:
“So, this is a two thousand year perspective. So, this goes back to the time of the Roman Empire, and so on. So, you see that, um, there’s natural variability in the climate system, but the temperature never varies by more than one-tenth, or two-tenths of a degree – hardly noticeable. But this spike at the end – this is the human influence, and when you put it in a long-time perspective, you can see just how dramatic this is. This is an extraordinary change, ah, in the Earth’s climate, in fact in the Earth System as a whole. We can make some, ah, comparisons, ah, to what’s happened in the past in Earth System. So, if you look at the rate, how fast change is actually occurring, we’re pouring, ah, CO₂ into the atmosphere, ah, and over the past two decades that rate is about a hundred times faster than the maximum rate during the last time CO₂ went up, and that was when we came out of the last Ice Age, between twenty thousand and, ah, twelve thousand years ago. Over the last half century the average temperature, that’s that spike I showed you, has risen at a rate about two hundred times the background rate over the past seven thousand years of the Holocene, the epoch we’re in now. This last statement from the geologists I think is really important. These current rates of CO₂ and temperature change are almost unprecedented in the entire 4.5 billion year geological past. In fact, our planet is 4.5 million y… billion years old. Only one time do we have a record of CO₂ and temperature changing as fast as it is today, and that was 66 million years ago, when a meteorite strike then wiped-out the dinosaurs and caused a mass extinction event. Now that was an emergency for sure, in the history of the Earth System. So, what we’re saying here is that the current rates, um, are unrivalled except for that event. Another piece of strong evidence that in fact, we are in an emergency.”
https://www.youtube.com/watch?v=Mn3WQGS9wOI
Delbert, it seems to me you are challenging and denying the validity of the extensive body of evidence/data/analysis of thousands (perhaps hundreds of thousands) of climate scientists and technicians. What’s your credible evidence/data to support your referred statement above?
*A* measure of global warmth. There are others.
No, the air temperature “depends on” the air temperature.
Well, now, *that’s* a revelation.
More often reported are the daily highs and lows… and this ignores the fact that many stations these days do automated readings at 5-minute or even 1-minute intervals.
Er, no. The daily low occurs when the daily low occurs–very often around dawn. There’s no “ignoring” of nightly cooling. This claim is just bizarre.
What the hell is this even supposed to mean? Obviously, if days consistently warmed more than nights cooled, we’d soon be burning–literally.
“Lightning*–presumably.
“Droughts.”
The spelling issues, rank ignorance, and general style are reminiscent of this dude–a general-purpose denier, as so many are these days:
https://twitter.com/WeRone777
Related here is the error you are trying to avoid. Normally, we try to avoid the error of incorrectly detecting a signal that is not there (type I error). However, if the consequences of a change are too serious you may place less emphasis on avoiding type I error and more emphasis on not making type II errors (missing a signal that is there). A usefult way of thinking about this is in terms of a precautionary principle, where you want to avoid harm. With regards to tropical cyclones there is an interesting paper by Knutson etal in BAMS (2019) https://journals.ametsoc.org/view/journals/bams/100/10/bams-d-18-0189.1.xml with an expert judgement study on tropical cyclone change from the two perspectives. There is a clear difference in the way experts evaluate the evidence if they are working in the normal frame (“avoid type I error”) or if they are working in the precautionary frame (“avoid type II error”). See table I in the paper.
I have found this to matter in work on sea level changes, since the cost of a overstating an
increase in the risk of high sea level is far less than the cost of missing or understating anthropogenic influence. Thus the risk assessment can be more nuanced than the detection and attribution alone.
It may be worth noting additionally that impact does not necessarily increase linearly with deviation from the mean, so if a trend looks very small compared to natural variability, this doesn’t mean the trend is insignificant from a potential impact perspective. For example, in a flood event, the severity of the flood would be expected to increase with increased extremity of the rainfall, but if a 5% increase in the rainfall means a flood defence fails where it would have held without the increase, the increase in impact is a lot bigger than that apparently small change in the rainfall.