As we did roughly a year ago (and as we will probably do every year around this time), we can add another data point to a set of reasonably standard model-data comparisons that have proven interesting over the years.
First, here is the update of the graph showing the annual mean anomalies from the IPCC AR4 models plotted against the surface temperature records from the HadCRUT3v, NCDC and GISTEMP products (it really doesn’t matter which). Everything has been baselined to 1980-1999 (as in the 2007 IPCC report) and the envelope in grey encloses 95% of the model runs.
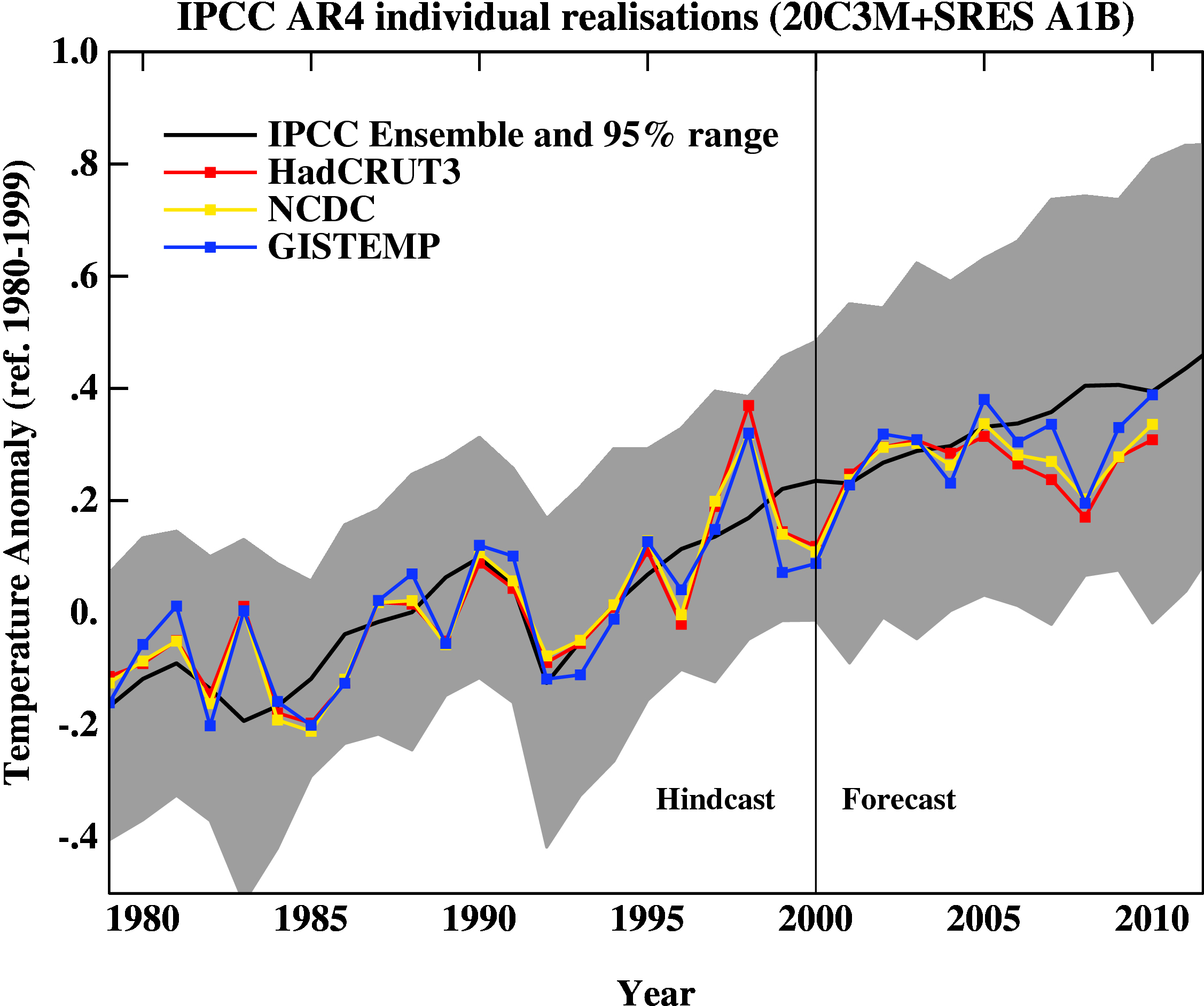
The El Niño event that started off 2010 definitely gave last year a boost, despite the emerging La Niña towards the end of the year. An almost-record summer melt in the Arctic was also important (and probably key in explaining the difference between GISTEMP and the others). Checking up on our predictions from last year, we forecast that 2010 would be warmer than 2009 (because of the ENSO phase last January). Consistent with that, I predict that 2011 will not be quite as warm as 2010, but it will still rank easily amongst the top ten warmest years of the historical record.
The comments on last year’s post (and responses) are worth reading before commenting on this post, and there are a number of points that shouldn’t need to be repeated again:
- Short term (15 years or less) trends in global temperature are not usefully predictable as a function of current forcings. This means you can’t use such short periods to ‘prove’ that global warming has or hasn’t stopped, or that we are really cooling despite this being the warmest decade in centuries.
- The AR4 model simulations are an ‘ensemble of opportunity’ and vary substantially among themselves with the forcings imposed, the magnitude of the internal variability and of course, the sensitivity. Thus while they do span a large range of possible situations, the average of these simulations is not ‘truth’.
- The model simulations use observed forcings up until 2000 (or 2003 in a couple of cases) and use a business-as-usual scenario subsequently (A1B). The models are not tuned to temperature trends pre-2000.
- Differences between the temperature anomaly products is related to: different selections of input data, different methods for assessing urban heating effects, and (most important) different methodologies for estimating temperatures in data-poor regions like the Arctic. GISTEMP assumes that the Arctic is warming as fast as the stations around the Arctic, while HadCRUT and NCDC assume the Arctic is warming as fast as the global mean. The former assumption is more in line with the sea ice results and independent measures from buoys and the reanalysis products.
There is one upcoming development that is worth flagging. Long in development, the new Hadley Centre analysis of sea surface temperatures (HadISST3) will soon become available. This will contain additional newly-digitised data, better corrections for artifacts in the record (such as highlighted by Thompson et al. 2007), and corrections to more recent parts of the record because of better calibrations of some SST measuring devices. Once it is published, the historical HadCRUT global temperature anomalies will also be updated. GISTEMP uses HadISST for the pre-satellite era, and so long-term trends may be affected there too (though not the more recent changes shown above).
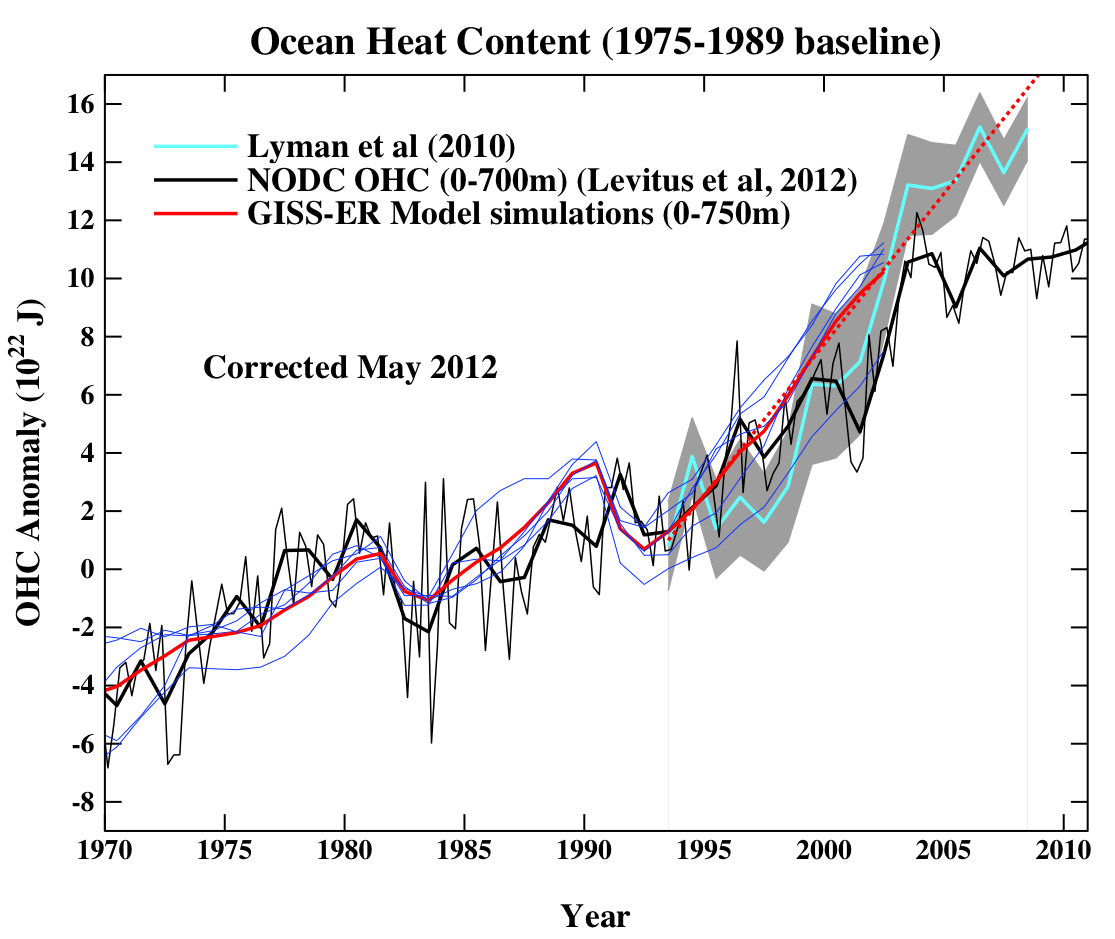
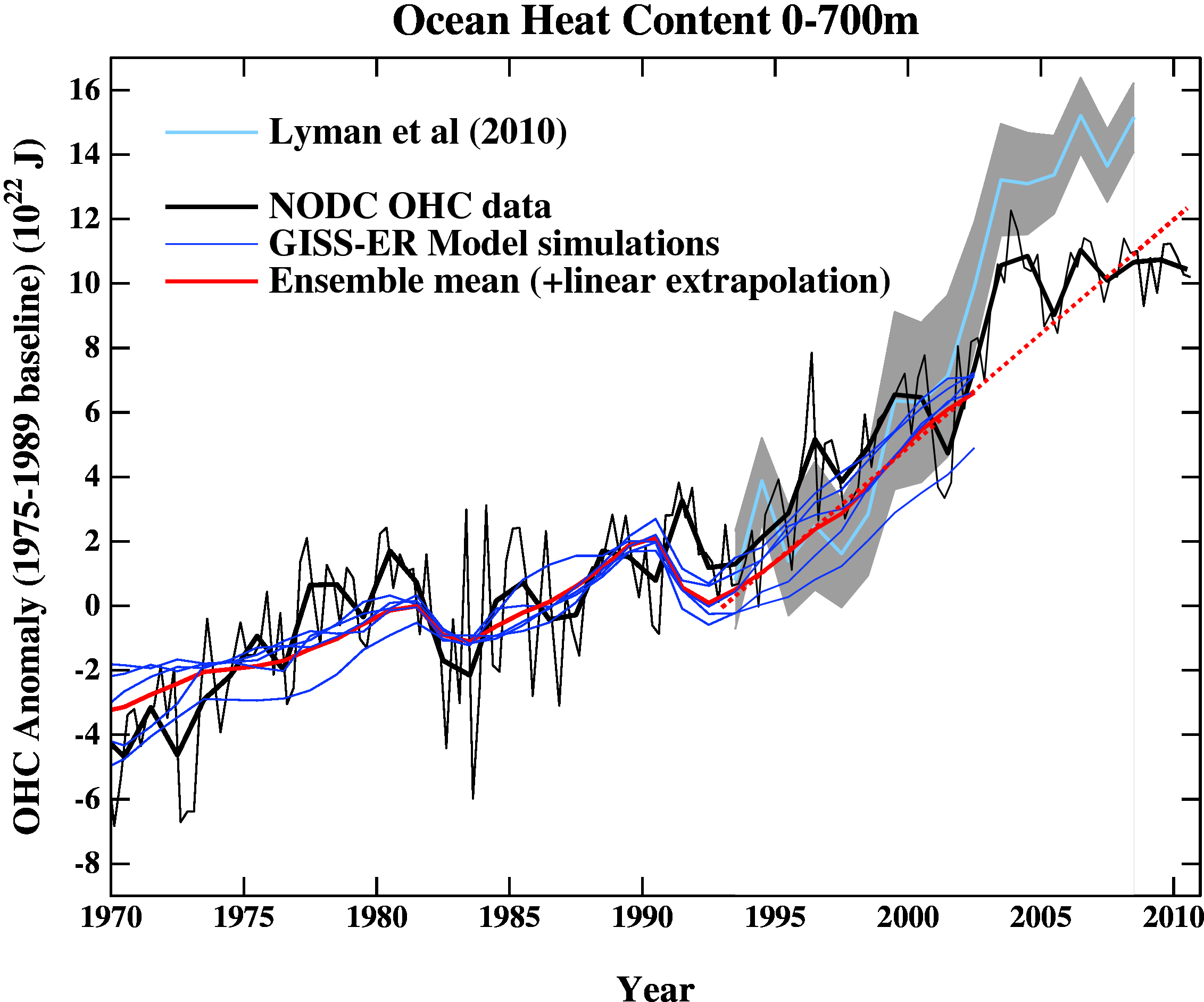
The next figure is the comparison of the ocean heat content (OHC) changes in the models compared to the latest data from NODC. As before, I don’t have the post-2003 model output, but the comparison between the 3-monthly data (to the end of Sep) and annual data versus the model output is still useful.
To include the data from the Lyman et al (2010) paper, I am baselining all curves to the period 1975-1989, and using the 1993-2003 period to match the observational data sources a little more consistently. I have linearly extended the ensemble mean model values for the post 2003 period (using a regression from 1993-2002) to get a rough sense of where those runs might have gone.
Update (May 2010): The figure has been corrected for an error in the model data scaling. The original image can still be seen here.
{kind=link}
As can be seen the long term trends in the models match those in the data, but the short-term fluctuations are both noisy and imprecise.
Looking now to the Arctic, here’s a 2010 update (courtesy of Marika Holland) showing the ongoing decrease in September sea ice extent compared to a selection of the AR4 models, again using the A1B scenario (following Stroeve et al, 2007):
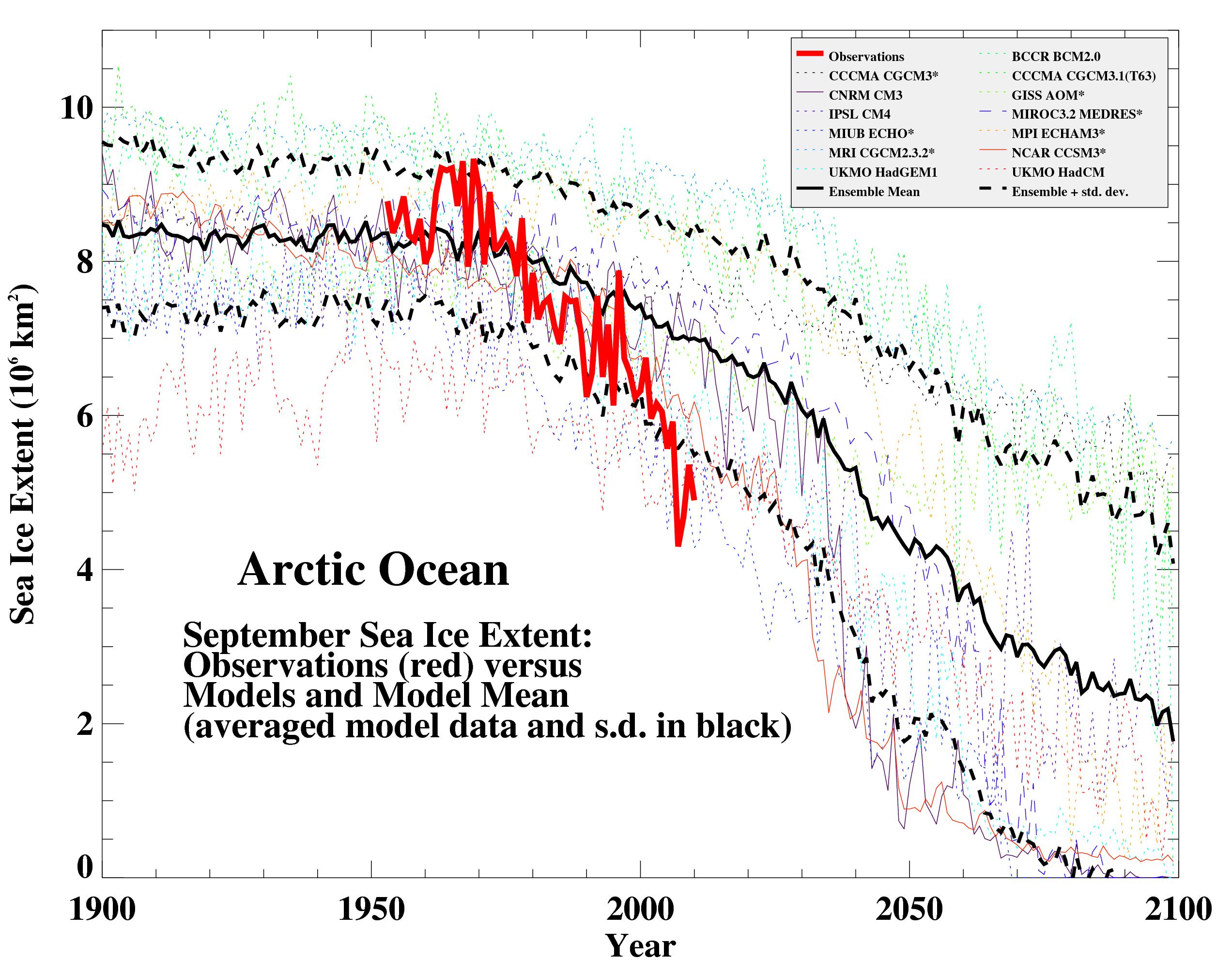
In this case, the match is not very good, and possibly getting worse, but unfortunately it appears that the models are not sensitive enough.
Finally, we update the Hansen et al (1988) comparisons. As stated last year, the Scenario B in that paper is running a little high compared with the actual forcings growth (by about 10%) (and high compared to A1B), and the old GISS model had a climate sensitivity that was a little higher (4.2ºC for a doubling of CO2) than the best estimate (~3ºC).
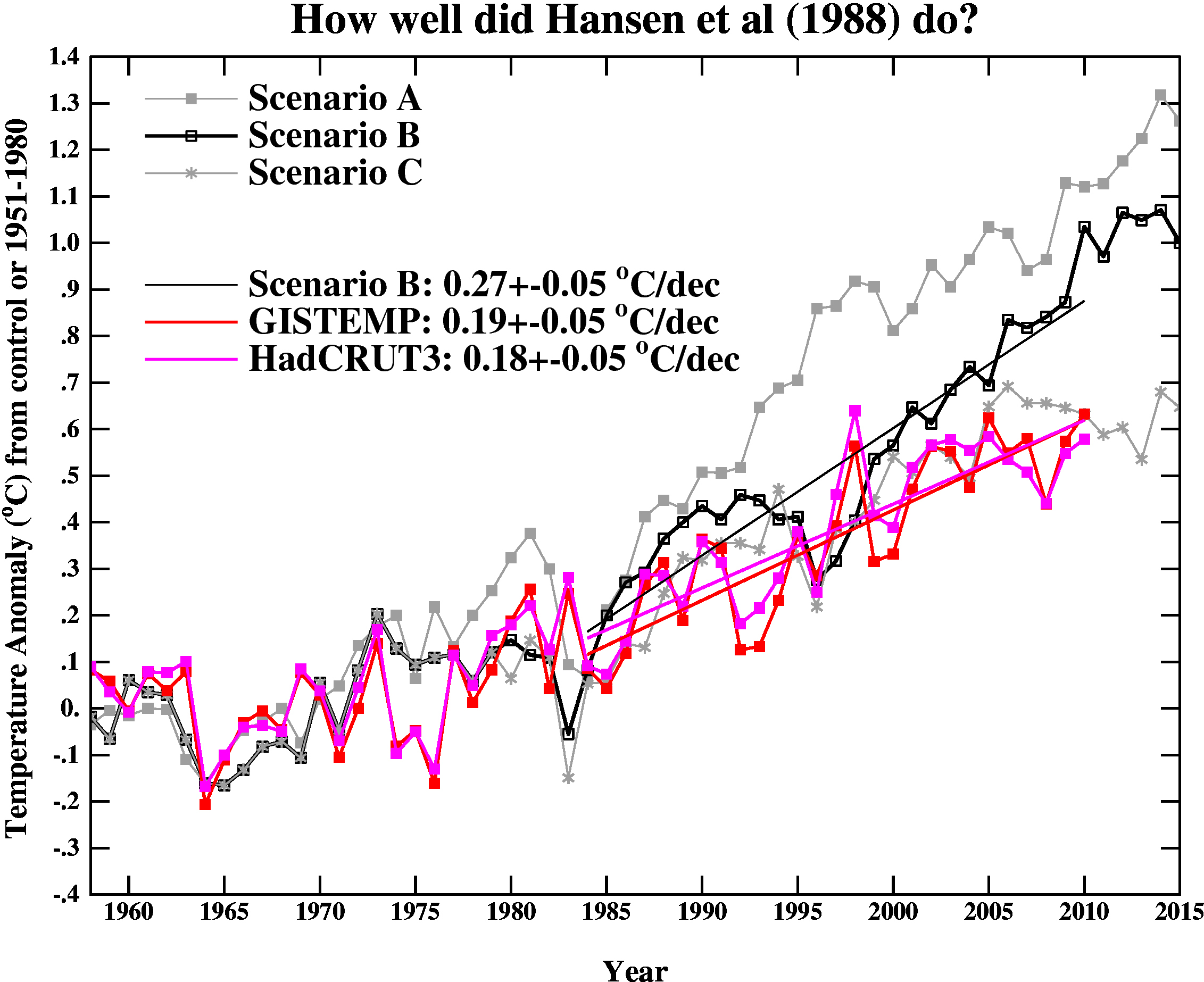
The trends for the period 1984 to 2010 (the 1984 date chosen because that is when these projections started), scenario B has a trend of 0.27+/-0.05ºC/dec (95% uncertainties, no correction for auto-correlation). For the GISTEMP and HadCRUT3, the trends are 0.19+/-0.05 and 0.18+/-0.04ºC/dec (note that the GISTEMP met-station index has 0.23+/-0.06ºC/dec and has 2010 as a clear record high).
{kind=link}
As before, it seems that the Hansen et al ‘B’ projection is likely running a little warm compared to the real world. Repeating the calculation from last year, assuming (again, a little recklessly) that the 27 yr trend scales linearly with the sensitivity and the forcing, we could use this mismatch to estimate a sensitivity for the real world. That would give us 4.2/(0.27*0.9) * 0.19=~ 3.3 ºC. And again, it’s interesting to note that the best estimate sensitivity deduced from this projection, is very close to what we think in any case. For reference, the trends in the AR4 models for the same period have a range 0.21+/-0.16 ºC/dec (95%).
So to conclude, global warming continues. Did you really think it wouldn’t?
captdallas 2, 189: I think it is safe to say we must use caution with any statistical method and analysis. Each method and application hold inherent limitations that can lead to issues in the results. In general, very low and high ends, various extremes and outliers should be eliminated, ideally, but that is not always the case. Whether linear or curvilinear correlations, and regardless of the regression method, or outlier elimination process for values in a data set +/- 3 s.d.’s from the mean, error analysis and going back to raw data are essential procedures. Sometimes even outside of bias, expectations and in the face of a considerable background, a few typos, blurry vision from tired eyes, or using a new computer program can greatly change the final results.
I agree with you, however, there are no strong reasons to rule out low values either. That may open the door to the possibility of higher values too, in conversation, but I think based upon data and statistically summary, the higher ends can in fact, be ruled out as in 0/(some value) as not being possible, but that will take some work and analysis to show. By higher values I mean anything above 3.5 degrees. I also think even the clustering at 3-3.2 degrees needs more evidence and reanalysis of raw data. What methods in particular and why are each authors in peer review being cited by others here, using? That goes a long way in recreating analysis and although models (usage of/interpretation) may be unavoidable in our discussion, they should and cannot be the main source of information, data and so forth.
# 195, I must disagree when you say 100 years of science as if the history settles the argument in and of itself. Many prominent scientists int he past 100 years have made false statements, still perpetuated and researched by current scientists.
[Response: Define false. And how many “prominent” scientists have made “true” statements in that same time?–Jim]
Sometimes a paper or two does turn a history of science on its head, and I do not mean, Galileo or anything from hundreds of years ago either. OF course cation should be used with individual papers and lack of replicability too. However, sometimes one or two papers get replicated thousands of times after and progresses science greatly. The 1950’s– 1970’s marks a 20 year period of great controversy in climate science where at times, one author or two, changed the perception of weather and climate.
[Response: These types of vague generalizations lead nowhere. Please talk specifics and back things up.–Jim]
Ray Ladbury, 197, let us start in Bayesian and work out from there. First I will read your link(s). Next I will consult my textbooks and some of the statistical work I do. I will get back to you beginning tomorrow. I am back to my night job. By all means let us keep the discussion open [edit; as before]
Ray Ladbury @184 — The point behind using a Cauchy distribution as the prior is that it is presumable completely uninformed about both physical laws and the actual data. Assuming S cannot be less than zero requires some degree of expertise. I find using Cauchy to be quite ingenious.
Re Geoff Beacon 194
“Thanks for your suggestion but I couldn’t find it on the intrade site. Can you point me in the right direction.”
In ‘The Predictions Market’ menu on the left the second category is ‘Climate and weather’. This opens a second level menu which includes:
NY City Snowfall,
Global Temperatures, and
Arctic Ice Extent
173crandles
Geoff Beacon 162
The site is http://www.intrade.com/jsp/intrade/contractSearch/index.jsp?query=Minimum+Arctic+ice+extent+for+2011+to+be+greater+than+2007
I went to intrade.com and started a search for arctic sea ice and it came up. As I read it, Geoff should get the 2 to 1 odds. They are betting that sea ice extent will not be lower than 2007. Geoff, I would almost bet you $100 because I would like to loose the bet. The fact that 2007 is the lowest has the deniers touting that sea ice is growing. It will be interesting to follow intrade, because I think 2012 might have a shot at being tie lowest.
David, The problem I have with a Cauchy Prior is that it is symmetric–when we know that the distribution for S is not! This is bound to under-estimate the high-end tail and over-emphasize the low-end tail. The result is also very sensitive to the position parameter. So, while I agree it is ingenious, I think it is also wrong, in that it violates the spirit that motivates using minimally-informative Priors. You get a VERY different result if you even use a lognormal prior with a standard deviation of 0.65-0.85 (which maximizes width/Kurtosis for a given mean).
I mean what Annan has done is essentially cut off the high-end tail and say it isn’t relevant. Fine, but be straightforward about it.
Ray Ladbury @202 — Aha, but the prior is to be the least informed possible. So one starts by assuming as little as possible. In particular the lognormal distribution assumes that S is not negative. Furthermore, a variable might be modeled as log-normal if it can be thought of as the multiplicative product of many independent random variables each of which is positive. from
http://en.wikipedia.org/wiki/Log-normal_distribution
so this distribution makes that assumption about the subjective pdf for S. One could consider adding another parameter to form the translated lognormal pdf, but the above objection still obtains.
An alternative is the translated Weibull distribution:
http://en.wikipedia.org/wiki/Weibull_distribution
but again there are objections to somehow relating a subjective pdf for S to failure rates.
The especial beauty of the Cauchy distributions is that those possess no mean and assign postive probablity to all possible values of S. The latter is important in a Bayesian analysis as then one does not apriori exclude any possible value. I suppose if one argues that the cloistered expert who is picking this prior knows some physics, then she might choose a translated Cauchy centered at 1.2 K for 2xCO2.
Once the Bayesian analysis is applied to whatever evidence one has, the influence of the prior begins to diminish. The long tails are still there when starting with a Cauchy prior but the symmetry quickly goes away, with the probability of large S vastly exceeding the probability of negative S.
I suspect that much of the motivation for Annan and Hargreaves is simply to highlight that the uniform prior gives excessive weight to very high sensitivity values, and that results can be very different with a different choice of prior. I think it’s quite valuable to emphasize the sensitivity of the final result to the choice of prior. However, that doesn’t give me much comfort in terms of climate change — it makes results less sure, more unsettling. For risk analysis, I’d suggest using the most pessimistic prior as a cautionary move.
To quote myself, I wouldn’t want to ride on an airplane whose safety depended on using the Jeffreys prior rather than a uniform prior. And I don’t want safe climate policy to depend on a Cauchy (or lognormal or Weibull) prior rather than a uniform prior.
David, The fact that the Cauchy does not preclude negative values for S is actually irrelevant. We know from physics that the data will preclude these values, so all the symmetric nature of the Cauchy is doing is robbing probability from the high-end tail. There is no good reason to do this from a physics perspective–or from that matter from a probability perspective. And from a risk mitigation perspective, it is potentially disastrous. Think about the equivalent situation at a F-annie M-ae. We can’t bound risk on the high end, so we introduce a symmetric Prior to beat down the high-end of our asymmetric likelihood. Sounds like a recipe for a mort-gage crisis to me. Sometimes our “uninformative” priors can be too clever by half.
I’ve been thinking about this of late. If you have a situation where you are pretty sure that the likelihood will beat down the tails of your distribution, then what you really want in an uninformative prior is one that maximizes your width rather than the extreme tails of the distribution–relatively high standard deviation and relatively low kurtosis. These aren’t even really defined for the Cauchy.
Uninformative does not necessarily mean unintelligent.
19 BPL Good luck.
TimTheToolMan asks : “Now I’m even more confused. How is it that arguably the most important aspect of AGW (ie the Ocean Heat Content) has not been calculated from the model output past 2003?”
Gavin Replies : “[Response: It has. But I didn’t do it, and I don’t have the answers sitting on my hard drive ready to be put on a figure for a blog post. And if I don’t have it handy, then I would have to do it all myself (no time), or get someone else to do it (they have more important things to do). If someone who has done it, wants to pass it along, or if someone wants to do the calculation, I’d be happy to update the figure. – gavin]”
So if you’re aware its been done, why not simply ask for the figures from whoever did it?
If you let me know who it was, I’ll ask if you like.
Brian Dodges “If that’s the case, then the economic arguments – that we should wait “until the science is settled” because the application of a discount rate makes solving AGW cheaper in the future, and we can’t afford the economic dislocation if we act now – are false. If we really can’t afford to fix it now, and are less able to in the future, then we are really screwed.”
Actually this is quite a possibility , but what do you mean exactly by “we are screwed” ? who are these “we”, and what would “screw” us? you seem to refer to two very different problems : the possible fading of the industrial society because we don’t have a good alternative to fossil fuels (which would happen even without GH effect), and the threat of a climate change (which could happen even if we found an alternative to fossil fuels, if there are in very large amount and we are too late to replace them).
These problems are often mixed and confused in public opinion and media, but they’re actually totally different, and in some sense contradictory. And a sensible discussion of what will really be the main problem is still lacking in my sense. Discussions around the climate favor the hypothesis that no real problem of fuel supply will occur, and that climate change will dominate by far all the other issues. I think this is by no means proved.
On priors:
I don’t think there is such a thing as an uninformative prior, in this case. Originally uninformative priors arise from symmetries that exist in models of physical systems. For example, an infinite euclidean space (or a sphere) have a translational (or rotational) symmetry, and the symmetry makes an uninformative prior over the space reasonable. The principle of maximum entropy, used to deduce uninformative priors, is intimately tied to these symmetries. But symmetries may not exist in real-world problems, especially if the domain is not physics.
For model hyper-parameters, especially for those limited to positive values, one can sometimes successfully use “uninformative” priors derived by maximum entropy, for the hyper-parameters are abstract and far from the likelihood. Conjugacy helps in a sense, because conjugate priors are often from the exponential family, and therefore they are always maximum entropy over some, more or less artificial symmetry.
In the case of CO2 sensitivy, I cannot see any symmetries at all, and the likelihood is not of exponential family. So there is simply no basis for uninformative priors.
In the context of model fitting, strong sensitivity to prior would mean that we have not enough data. In a sense this is the case with CO2 sensitivity as well. And because the prior is informative, one can argue whether it really represents the corrent prior information. :)
Then there is the assumption of independence between the likelihood and the prior – that the evidence presented by them arise from independent sources. Annan says the independence holds, and I’m not really able to argue convincingly against. But the experts (prior) and the evidence (likelihood) have lived for a long time in the same world.
I don’t know where all this leaves us. Maybe one should be careful with the bayesian formalism here?
BTW, Martin Weitzman’s work may be interesting for those who like the Annan approach. If I have understood correctly, Weitzman basically states that utility calculations are worthless in the case of climate change, because the posterior distribution is long-tailed enough, to the upper side, that expected utility cannot be computed at all! But his justification is kind of technical.
Crandles 206
Bibasir 205
Thanks very much for your help. I’m just getting to understand how Intrade works. The actual contract is for \MIN.ARCTIC.ICE:2011>2007\ and the Ask and Bid prices are 30 and 39. Because this is less than 50 I think this means that market sentiment is that the contract will fail. This means the expectation is that the minimum Arctic Sea Ice extent this year will be below that of 2007.
I want to bet on the Arctic sea ice being the lowest this year so I should register with Intrade and offer to sell.
Perhaps the traders have read Flanner et.al.
I haven’t seen this paper mentioned outside the denial space:
Uncertainty in the Global Average Surface Air Temperature Index: A Representative Lower Limit
Abstract
Sensor measurement uncertainty has never been fully considered in prior appraisals of global average surface air temperature. The estimated average ±0.2 C station error has been incorrectly assessed as random, and the systematic error from uncontrolled variables has been invariably neglected. The systematic errors in measurements from three ideally sited and maintained temperature sensors are calculated herein. Combined with the ±0.2 C average station error, a representative lower-limit uncertainty of ±0.46 C was found for any global annual surface air temperature anomaly. This ±0.46 C reveals that the global surface air temperature anomaly trend from 1880 through 2000 is statistically indistinguishable from 0 C, and represents a lower limit of calibration uncertainty for climate models and for any prospective physically justifiable proxy reconstruction of paleo-temperature. The rate and magnitude of 20th century warming are thus unknowable, and suggestions of an unprecedented trend in 20th century global air temperature are unsustainable.
[Response: The characterisation of the error in the global annual mean is wrong, and even if correct, the impact on the uncertainty in the trend is completely wrong. What journal was this published in? Quel surprise…. – gavin]
A whole lotta jargon goin’ on.
I’d make an elaborate emergency room joke (STAT!) but I can’t think of one.
If one of you statisticians regularly teaches the subject, please offer a two-bit explanation for the cheap seats about what the issues are.
Re: #216 (Martin Smith)
If the surface temperature record is so unreliable, then why does it agree so well with the satellite temperature record (also see this)?
Janne,
I think that is my basic point–that caution is warranted. What do you think of an Empirical Bayes method? It would yield a result similar to marginal likelihood. The thing is that I have serious qualms about using a Prior that looks very different from the likelihood. That is one of the problems I have with Annan’s approach–that and the fact that negative sensitivities are unphysical.
For an empirical Bayes method, we could use the agreement between the different methodologies on the best-fit sensitivity (~3 K/doubling) and then set the width so that the distribution is maximally uninformative. I also think that the skew of the Prior is important, especially if we are to bound the risk.
213 Gilles: Discount rate is irrelevant because extinction of the human race is an infinite cost. Regardless of the discount rate, the present cost is still infinite.
Economics is irrelevant because economics is not applicable to situations where there is not a civilization in which money is used. By “screwed” we mean at best the collapse of economics because money is worth nothing if there is no food.
Your economics arguments are irrelevant. Your fossil fuels arguments are also irrelevant because fossil fuels are useless in the absence of organized civilization that can use fossil fuels.
In order to maintain some remnant of civilization with some form of law and order, we MUST quit using fossil fuels immediately. Notice that this does not necessarily prevent gigadeath due to widespread starvation.
BPL has computed the date of collapse under BAU as some time between 2050 and 2055. That is very soon, and we have no time to waste.
Is that stark enough for you?
Re: #217 (Jeffrey Davis)
Not sure what your background is, but I think you’re talking about the discussion of priors in estimating climate sensitivity, so here’s some elementary info.
We’re trying to figure out the probability of climate sensitivity having any given value, i.e., the probability distribution for climate sensitivity. Many believe that a superior approach to statistics is what’s called a Bayesian analysis. It’s many things, but one of its key elements is that it enables us to combine what we learn from data — which gives us the likelihood — with what we already knew, or simply already believed based on expert knowledge — which we encode in the prior distribution. The prior expresses what’s possible and what we already know (or think we know). After combining prior and likelihood, we get the posterior probability, which is what we were after in the first place.
When we don’t have much knowledge prior to observations, we usually try to use a noninformative prior. Loosely speaking, this is one which doesn’t impose assumptions or restrictions on the final result. There’s more than one way to skin this cat, including a “maximum entropy” prior or a “Jeffreys prior” or “conjugate prior”, the form of which depends on how the system behaves (which itself may be uncertain).
Some analysis of climate sensitivity has worked with a uniform prior — that’s just one where all values are considered equally likely prior to incorporating our data. But Annan and Hargreaves have argued that this gives too much weight to very high values of climate sensitivity — after all, it makes no sense to assume as a prior that climate sensitivity of 3 deg./doubling CO2 is equally as likely as climate sensitivity of 3 million deg./doubling CO2.
Even so, when we apply our data, it so suppresses the 3-million-degree sensitivity that it’s not an issue. But it doesn’t suppress 20- or 30-degree sensitivity nearly as much as other choices of prior, and even though these high values end up not very likely they’re still possible, and lead to the “long tail” of the probability distribution. The long tail isn’t very big, but the consequences of such high values are so extreme that they may dominate risk analysis.
So, Annan and Hargreaves have explored other choices — first, to show that the uniform prior is the cause of the long tail, and second, to explore what other choices may indicate.
Most of the discussion here is about the appropriateness of one of Annan & Hargreaves’ choices for a prior, the Cauchy distribution. It moderates the long tail (solving the 3-million-degree-sensitivity problem) but not too much (some would say). Even so, it also includes nontrivial prior probability for “prior-unlikely” values, say, for negative climate sensitivity — when many believe that there’s very good reason a priori to exclude, or at least downweight, the possibility of negative climate sensitivity.
So, we’re not only discussing the issue in general, we’re also lobbying for our favorite priors, all of which are just well-known probability distributions we think might be useful choices for this analysis. These include the Cauchy distribution (which some object to because it gives equal prior weight to negative as to positive sensitivity values and besides, it’s symmetric) log-normal (which some object to because it excludes negative values altogether), the Weibull, etc.
I hope this helps.
Tamino: “I suspect that much of the motivation for Annan and Hargreaves is simply to highlight that the uniform prior gives excessive weight to very high sensitivity values, and that results can be very different with a different choice of prior.”
Yes, and anyone who takes a peek at James’ blog might also suspect he’s having some fun doing it. But sensitivity to the prior when one speculates over a broad range of priors isn’t exactly rare is it?
Why not use the paleo prior of e. g. Hansen? This has the unique advantage of actually being prior. Is this not in the spirit of Bayes? This yields S (sensitivity to forcing, not to the prior) = 3 as usual, and along the way goes far toward solving another problem: “You haven’t haven’t bounded the risk” – the proper polite and professional way of saying “It’s insane to go on burning carbon like there’s no next generation.” This is solved because S (from the paleo prior) depends on paleo temperature estimates. If the paleo temps are off, S will be higher or lower but the expected melting and sea level rise are the same.
“Two Bayesians can’t pass one another in the street without smiling at each other’s priors.”
– Cosma Shalizi
Maybe someone can answer a question I have been puzzled about for a while. The graphs compare the global mean temperature estimated by the models with that estimated from the data. However, this metric is only useful if “every degree is equal”, ie a rise in temperature of 1 degree in the arctic is of exactly the same consequence as the same rise in the tropics (or anywhere else). Now if the change in global mean temperature is supposed to be a measure of the change in energy content of the atmosphere (assuming we are using air temperatures) or as a proxy for the change in the energy content of the ocean, or in fact has anything at all to do with energy, surely the specific heat of the air should be taken into account? This must depend to quite a large extent on the humidity (and presumably also pressure and other factors) which must change dramatically around the globe. In particular it must be much higher in the tropics (on average).
[Response: The global mean temperature anomaly is the 2D integral of temperature anomalies over the surface. In models it is exact, while in the real world it needs to be approximated in various ways (2m SAT anomalies over land, assumptions about representativeness, SST over the ocean, corrections for inhomogeneities etc.). If you were to calculate a change in atmospheric heat content, that would be closer to your suggestion, and while I don’t think it would look much different, it is not the same metric. – gavin]
Geoff Beacon 215
I agree with your interpretation on intrade prices. It would cost US$7 to get $10 in 9 months time if you are correct and there is a record low.
>”Perhaps the traders have read Flanner et.al.”
Perhaps they have read it and got the same interpretation as you and maybe they haven’t read it. I have only read the abstract and there will be more in the paper but I do not see how it changes my assessment of the probabilities much so I am puzzled by your insistance on its importance.
The paper clearly does quantify the albedo feedback much better than before, but so what? We already knew the decline in sea ice was faster than models predict, presumably this effect was already acting over the last few years and we had records in 2005 and 2007 but not in 2006, 2008, 2009 or 2010. I would suggest that what you need is something to indicate that the effect is going to be much stronger in 2011 than in 2010 or 2009 so that it is likely to be more inportant than natural variability over one year. But perhaps there is something in the paper but not the abstract to indicate that.
Jeffrey Davis,
How familiar are you with Bayesian probability? Basically, the situation is that we have a set of data that favor a certain best-fit value for CO2 sensitivity, S~3, and a certain range S between 2.1 and 4.5. The question is whether we have any basis for a Prior expectation of what S should be and what the probability distribution over values of S should look like before we look at that data. That Prior expectaton (or PRIOR) can be updated with likelihood (e.g. combined probability) of our data using Baye’s theorem. With me?
The thing is that in Bayesian probability, there is always a degree of subjectivity to choosing a Prior. One way to minimize this is to use a Maximum Entropy Prior (really only applicable to discrete distributions) or a minimally informative prior (a generalization where you make the Prior as broad as possible subject to constraints like known symmetries). The goal in both cases is to minimize the effect of the subjective Prior on the results? OK?
The problem is that there’s this pesky tail on the distribution of sensitivities at the high end. James Annan did a very interesting analysis in which he showed that even if you use a Cauchy Prior centered on 3 K/doubling, you can make that pesky tail go away. (Note: the Cauchy is a really nasty distribution with tails so thick none of its moments exist) Basically, I think you could say that I am a critic of the approach because the Prior seems to violate symmetries of the problem. David Benson is a fan because the Cauchy is fairly uninformative and makes no assumptions about physics, etc. And Tamino and Janne think the approach is interesting but that the very fact that the result depends critically on the Prior argues for caution when applying Bayesian probability to the problem. I hope that is not too unclear, doesn’t do violence to the situation or distort anyone’s position.
BTW, Empirical Bayes is a bastardized Bayesian approach where you cheat and look at the data at least a wee bit to at least set the best-fit values for the parameters of your distribution.
Bibasir @ 206:
There seems to be a pattern where record low years have a several year period of recovery prior to making a new record low. I pointed this out a few years ago, after the 2007 low, and stated with a high degree of confidence that we wouldn’t have a new record low for several more years. At this point in the cycle, I wouldn’t bet against 2011 or 2012 being a new record.
I made the same comment a few years back, when Solar Cycle 24 was shaping up to be a dud, and so far we’ve not had an unabiguous and unarguable new record high. As SC 24 slowly reaches Solar Maximum, and CO2 concentrations continue to rise, the probability that we’ll see a new record high global temperature that no one can argue against likewise increases.
And I say this because =that= is when the deniers are going to have a very large face full of pie.
Have patience — the proof will be in the pudding in another year or three. All the right technologies to do something about CO2 emissions are maturing and we’ll be in better shape, in terms of the data supporting the science, to make aggressive changes by 2014.
#209 – Tamino
I’m I reading you right in saying, at least for A/C, you trust engineering standards more then the more exotic stats?
For TimTheTool:
Use the tool: http://scholar.google.com/scholar?q=Ocean+Heat+Content
See, e.g.: http://www.agu.org/pubs/crossref/2003/2003GL017801.shtml
re Gavin @223
I know what the mean global temperature is (actually, I don’t, see below) but the question was why is this a meaningful metric for looking at changes over time, when you could get the same global mean from very different distributions of temperature (eg increase the poles, decrease the tropics) which would have very different interpretations of energy balance (at least if I am right that humidity matters)?
I say I don’t know what the global mean is because what is actually estimated is a spatially weighted average of the (homogenised etc) data. While this is reasonable for looking at changes over time, it is certainly not an estimate of the true mean of the surface temperature of the globe. As everyone who has ever measured the temperature knows, if a station was moved even a few metres in any direction the temperature will change. Any station that is not very rural will suffer from a heat island effect, which may be constant over time but means the station does not give an unbiased estimate of the mean temperature for the area it is supposed to represent. The altitude of the station and the surrounding area are equally important. The mean temperature is therefore an estimate of the global mean plus an unknown constant, presumed constant in time. I’m rather surprised that this doesn’t matter, ie it is possible to model the global climate without any real idea what the true mean is.
Re: #227 (J.Bob)
No.
Geoff Beacon, before betting too much check papers like Zhang et al.
“Arctic sea ice response to atmospheric forcings with varying levels
of anthropogenic warming and climate variability”.
Above all do not bet with a crank (and how do you know online?). Even if you are sure you have won, the crank will be surer of the opposite and will hound and even sue you to get you pay off. That possibility alone makes your bet a poor one.
Ray Ladbury: “BTW, Empirical Bayes is a bastardized Bayesian approach where you cheat and look at the data at least a wee bit to at least set the best-fit values for the parameters of your distribution.”
IOW it spoils the fun (for certain values of fun). But haven’t you been suggesting to in effect look at the data just a little bit? Granted there is a difference between a little bit and a lot. Still, the discussion here seems to be about unempirical Bayes being unsatisfactory. And what was that you said about flying?
225, Ray Ladbury: BTW, Empirical Bayes is a bastardized Bayesian approach where you cheat and look at the data at least a wee bit to at least set the best-fit values for the parameters of your distribution.
You and the others are already fully informed about all extant data, so all of your priors are at least weakly data dependent, and most of them are strongly data dependent. For computing posterior distributions in the future from future data, you probably can’t do better than use the fiducial distribution from the current best data for S itself. Even though it assigns some probablility to negative numbers, the amount is tiny and negligible for practical purposes; if that annoys you, you could truncate the distribution at 0, or put all of the probability for negative values at 0.
In his book “A comparison of Bayesian and frequentist approaches to estimation” (Springer, 2010), F. J. Samaniego argues that in order for Bayesian inference to improve upon frequentist inference (in a Bayesian sense of improve!), the prior has to be at least accurate enough; he calls this the “threshold” that the prior has to pass. Granted that fiducial distributions are not highly regarded as probability distributions by Bayesians, they are probably more accurate in real settings than other proposed distributions. I think that you’d have a lot of trouble showing that either the Cauchy or lognormal is more accurate in this case. At least if you want the prior to represent shared evidence instead of private opinion.
Coming back to my favorite topic, (how) does the comparison of the data to scenarios a, b, and c affect the posterior distribution of S, starting either with the fiducial distribution, Cauchy, or lognormal as a prior? Is this something that can be done with EdGCM and Winbugs?
Here’s another peer-reviewed paper touted in the denialosphere, claiming recent decreased stratospheric water vapor: http://www.nature.com/news/2010/100128/full/news.2010.42.html
It might be worth your while to discuss it.
I’m concerned about my impact on the environment. I heat my home with heating oil but am worried about what this is doing to the environment. I live in a rural area of lincolnshire so there’s not much alternative to heating my home with oil except wood and LPG… but I don’t know if this is even more harmful. I have just found a heating oil website who offer Group Buying Days, this seems like a great way to help the environment because you can order with others which helps to keep tankers off the roads more, reducing CO2 emissions.
I would like to see more information on the internet about the effects of heating oil on the environment. On most climate change sites I go on there are articles on gas and electric heating but little on the effects of heating oil.
Does anyone have any figures about heating oil and ways to minimize my impact on the environment?
Edward :
“213 Gilles: Discount rate is irrelevant because extinction of the human race is an infinite cost. Regardless of the discount rate, the present cost is still infinite.”
do you have a serious evaluation of a threshold above which human race would disappear?
speaking for my own case : I’m living in a valley in France, close to a medium size city, under 3000 m (10 000 ft) high mountain. It’s pretty cold in winter, which allows a fair amount of snow to cover the summits, which gradually melt in summer, fueling small creeks and a river (there are huge dams insuring hydropower and regularizing the water supply some hundreds of km above). Well, not too bad a place to live in. The soil is rather fertile , I grow some vegetables in my garden , mainly for fun but I could grow more. There are a lot of woods above on the hills, providing heating wood and even chestnuts, mushrooms, animals…. Can you explain me exactly why everybody around me, including me, should die within some decades? do you think it is a LIKELY hypothesis, and why ?
”
BPL has computed the date of collapse under BAU as some time between 2050 and 2055. That is very soon, and we have no time to waste.
Is that stark enough for you?”
well, if mankind was to disappear between 2050 and 2055, it is pretty obvious that “B” couldn’t be “AU” well before this date, isn’t it ? so what’s the coherence of such an estimate ?
FurryCatHerder: “And I say this because =that= is when the deniers are going to have a very large face full of pie.”
I predict the standard response – deny harder. I also expect dropouts from the denier team, as more people think “Oh oh. We really do have a problem here.” I expect steady if slow movement toward the 65 – 75 percent majority that may be required to move politics against the force of money. But I should temper this mild optimism with the awareness that another IPCC AR is coming, and another denier onslaught is probably coming to counter it. I don’t know what the professional deniers can come up with to top the email attack, but I expect it to be surprising and impressive (to the low information majority). In other words, you’ll be surprised.
btw Ray Ladbury thanks. I looked up “empirical Bayes.” It looks like a recognized method.
Thank you to tamino and Ray Ladbury.
I have hardly anymore statistics than the rat we studied in Psych 101 over 40 years ago.
Septic Matthew:
https://www.realclimate.org/index.php/archives/2010/01/the-wisdom-of-solomon/
Re: Gavin’s response to #216, and #218 (tamino)
The blog of Patrick Frank’s paper that spammed denial space shows a graph of the surface temperature anomaly from 1880 to 2010 with gray vertical bars behind it representing Frank’s computed ±0.46 C uncertainty at each point. In 1880, the anomaly was about -0.25C, and in 2009 it was about (eyeballing) +0.45. Is he really just claiming that the anomaly trend in the graph is meaningless because each data point is indistinguishable from 0? If that’s really all he is saying, then is his claim wrong because the anomaly trend so closely matches the anomaly trend in the satellite data, or is he wrong because a trend is meaningful even if each data point is indistinguishable from 0?
Re: #240 (Martin Smith)
First, his argument about the uncertainty of the surface record is bull.
Second, even if each individual data point is indistinguishable from zero, it’s possible for the trend to be greatly distinguishable from zero.
Third, the surface temperature records match the satellite records not just in trend, but in fluctuations about the trend, and to a very high degree of precision (way better than 0.45 deg.). If he were right about the uncertainty of the surface record, this would be impossible.
[Response: I’ll add that I am reliably informed that Eq 9 (p976) and his case 3b (p 974/5) are clearly wrong. The equation for the mean of the error instead of the error of the mean has been taken from ref #17. Other issues are that he apparently claims the error has a similar value for 30-year means as it does for a monthly mean. And the N used in p982 is not the appropriate one. This is all apart from the obvious inconsistencies already noted. – gavin]
Pete Dunkelberg, Yes, I was probably to flippant in calling it a Bastardized Bayesian analysis. I merely mean that since the Prior is not independent, it is not really Bayesian, but really more likelihood based.
Septic Matthew, independent of scenarios A, B and C, the current climate state favors 3 K/doubling based on multiple studies.
Jim, I meant no specific claims against climate scientists or that science should be discarded. In the history of science over the past 100 years in all fields, there have deliberately falsified results. Recent ones include at Harvard with that professor of psychology, whose name eludes me at this moment. The others I recall in recent times are: In Korea (South Korea?) where the scientist was found to be falsifying stem cell results, and the so called human baby cloning in France a decade or so ago as well. In ths thread I am making mention of issues with GCM’s but I am NOT alluding that the models are being made to ‘lie’ or that anyone here is ‘lying.’ I do think there are issues that need to be looked at like: the whole global climate system cannot be truly quantified, estimates and approximations, may be far enough from being accurate that some improvements are of absolute necessity, and in my next post, today, in response to Ray Ladbury I am going to go from a general disucssion on Bayesian stastics, to specific methods and various advantageous and limitations.
[Response: OK hold on please. If the purpose of your earlier post that I commented on, was not to imply that your use of the term “false” equated to outright research misconduct via dishonesty, then why do you, here, defend yourself using two high profiles examples of exactly that very thing??? This makes no logical sense at all. Your claim here that you meant that scientists can sometimes get things wrong–well, thanks a lot for that light bulb insight.–Jim]
I think, starting out general and going to more specific examples is not a bad way to have a informed and intelligent dialogue, but by all means, please tell us more about your data collection and agreement with models.
[Response: Say what? The problem is you make lots of big sweeping generalizations and assertions with no logical defense of what you assert. Who exactly is it that you expect to just accept these things? And my “data collection etc” is 100% irrelevant.–Jim]
Finally, if you prefer specific reasoning first, then going out to generalized heuristics, that is just fine too. Neither you or I, may be seeking the other’s approval, but I do, want to talk some of thes things out. Bear with me, I hope, moderators when, in my next post I do like I used to in ,y earliest posts and show the equations, explain the general usefulness, specific utility and then in words both quote and interpret what Bayes is and is not good for, etc… much like my early post showed a link between thermodynbamics and relativity, when I first joined RC.
[Response: Bring it. And when you do, make it cogent and relevant and understandable. Otherwise you are wasting peoples’ time here–Jim]
239, Rattus Norvegicus,
Thank you!
I misread the reference and I thought that it was new today. bleh.
Crandles 224
You say
“We” may know but others may not acknowledge this. See my comments to “Loosing time not buying time. https://www.realclimate.org/index.php/archives/2010/12/losing-time-not-buying-time/ where I criticise the Trillion Tonne Scenario for being too optimistic. This says when we get to emissions of a trillion tonnes of carbon since 1750 and we will get a 2 deg C rise in temperature and that is just about bearable. But this scenario was created with models that may underestimate warming because they underestimate feedbacks, such as sea-ice albedo. (Also see “Fast and Super-fast – Disappearing Arctic sea ice”, http://www.brusselsblog.co.uk/?p=45)
Another feedback which may be underestimated is methane from Arctic tundra. The UK Government’s Climate Change Committee have said
See “The rise in methane and the Climate Change Committee”, http://www.ccq.org.uk/wordpress/?p=120.
To echo Tamino’s earlier comment – that doesn’t give me much comfort in terms of climate change . For risk analysis, I’d suggest using the much more pessimistic scenario. We need a plan B. See “Plan A might fail … so we need Plan B”, http://www.ccq.org.uk/wordpress/?p=139.
Thanks for the earlier help. I’ve placed a bet with Intrade (rather “offered to sell a contract”) on this year’s Arctic sea ice.
243, Ray Ladbury: Septic Matthew, independent of scenarios A, B and C, the current climate state favors 3 K/doubling based on multiple studies.
Sure. From those studies you can develop a prior distribution. Then as other data accumulate, data like the time series of global mean temperature, you can compute the posterior distribution given the new data. You could take something that approximates your idea of Hansen’s opinion back in 1988, using his actually chosen value as the mean of the prior distribution, and compute the resultant posterior distribution conditional on today’s data. Eventually data overwhelm differences between priors, so by now all reasonable priors from 1988 probably produce indistinguishable posterior distributions, don’t you think so? If not now, then soon in the future.
Of course it’s lots of work that I can not do myself right now, but accumulating evidence from diverse sources across time is one of the advantages of Bayesian inference. A plot, by year, of the 95% credible interval for S would be meaningful, don’t you think? That’s a way of doing sequential analysis.
@228, Hank Roberts
I’m well aware of the measured OHC figures and I’m aware Gavin co-authored a paper comparing the model output to measured values to 2003.
Instead of providing utterlessly useless links and mistakenly thinking you’re helping, how about you provide a link to OHC figures calculated from model output post 2003.
In case you’re not sure why you’re not helping. Your “eg” is “GEOPHYSICAL RESEARCH LETTERS, VOL. 30, 1932, 4 PP., 2003” Pay particular attention to the date.
Jakob Mack, Oh if only you’d come along sooner and told all those climate scientists that what they were trying (and succeeding at) was impossible. Think of the time you could have save them! Of course, there is that small matter of all those verifiable (and verified) predictions the scientists have made. Wonder how that works if the model they are using is impossible? Puzzle, that. Oh, wait! Maybe we need more than your personal incredulity on which to base our understanding of the Universe. Why, yes. That might be it. It appears argument from personal incredulity is a logical fallacy. Check ’em out, Jake. How many more can you collect:
http://www.theskepticsguide.org/resources/logicalfallacies.aspx
http://multi-science.metapress.com/content/c47t1650k0j2n047/?p=7857ae035f62422491fa3013c9897669&pi=4
Patrick Frank article in Energy and Environment stating that as a result of a +- 0.46 C instrumental uncertainty, the 20th century temperature rise is statistically indistinguishable from 0. Sounds like the Dunning-Kruger Effect at work.