
The fast-tracked update of the 2009 EPA Endangerment finding from the National Academies for Science, Engineering and Medicine (NASEM), has now been released.
[Read more…] about Lil’ NAS ExpressClimate science from climate scientists...
The fast-tracked update of the 2009 EPA Endangerment finding from the National Academies for Science, Engineering and Medicine (NASEM), has now been released.
[Read more…] about Lil’ NAS ExpressSomewhat breaking news. A court filing (from 9/4) from DOE has noted that the Climate Working Group has been disbanded (as of 9/3). This was done to make the EDF/UCS lawsuit moot, but it also means that DOE is withdrawing the report, no-one will respond appropriately to the comments submitted, and (possibly) it becomes irrelevant for the EPA reconsideration of the Endangerment Finding.
What a farce.
Update: Via Andy Revkin, the EDF/UCS’s blistering response to the DOE filing. Pass the popcorn.
As we’ve mentioned, Andrew Dessler and Robert Kopp have been coordinating a scientific peer review of the DOW ‘CWG’ Critique of Climate Science. It is now out.
[Read more…] about Climate Scientists response to DOE reportGuest commentary by Kerry Emanuel
Executive Summary
Chapter 6 of the draft DOE report examines whether global warming exacerbates extreme weather. It rightly notes that because events such as hurricanes are rare, detecting their response to climate change in short and imperfect historical records is extremely difficult—if not impossible. Yet the authors devote most of the remainder of the chapter to attempting just that. By omitting to frame such efforts in the context of theory and models, they commit three fundamental errors: 1) searching for trends where none were predicted, 2) neglecting important variables for which trends were predicted and 3) overlooking—or failing to acknowledge—that some predicted trends are of a magnitude that is not a priori detectable in existing noisy and short data sets. The draft report also overlooks recent literature on climate change effects on weather extremes, and quotes selectively and misleadingly from the most recent report of the Intergovernmental Panel on Climate Change (IPCC). For these reasons, I find much of Chapter 6 to be of questionable utility. There are at least three climate change-induced trends in hurricane-related hazards that were predicted theoretically, simulated by models, and confirmed by observations:
There is no robust scientific finding that hurricane frequency is increasing or expected to increase. Thus, much of Chapter 6 of the DOE report is devoted to refuting a hypothesis unsupported by scientific consensus. The short section on tornadoes does not include other more destructive aspects of severe convective storms, such as hail and damaging straight-line winds, and as with the section on hurricanes, omits inferences from theory and models.
[This commentary is also available as a pdf file]
[Read more…] about Critique of Chapter 6 “Extreme Weather” in the DOE reviewThe first somewhat comprehensive reviews of the DOE critical review are now coming online.
[Read more…] about Critiques of the ‘Critical Review’The EPA, along with the “Climate Working Group” (CWG) of usual suspects (plus Judith Curry and Ross McKitrick) at DOE, have just put out a document for public comment their attempt to rescind the 2009 Endangerment Finding for greenhouse gas emissions.
[Read more…] about The Endangerment of the Endangerment Finding?Some intriguing new measurements of salinity in the oceans around Antarctica have set off reams of sensationalist speculations. Maybe some context is helpful…
[Read more…] about Ocean circulation going South?In honor of the revelation today, that Koonin, Christy and Spencer have been made Special Government Employees at the Dept. of Energy, we present a quick round up of our commentary on the caliber of their arguments we’ve posted here over the last decade or so.
TL;DR? The arguments are not very good.
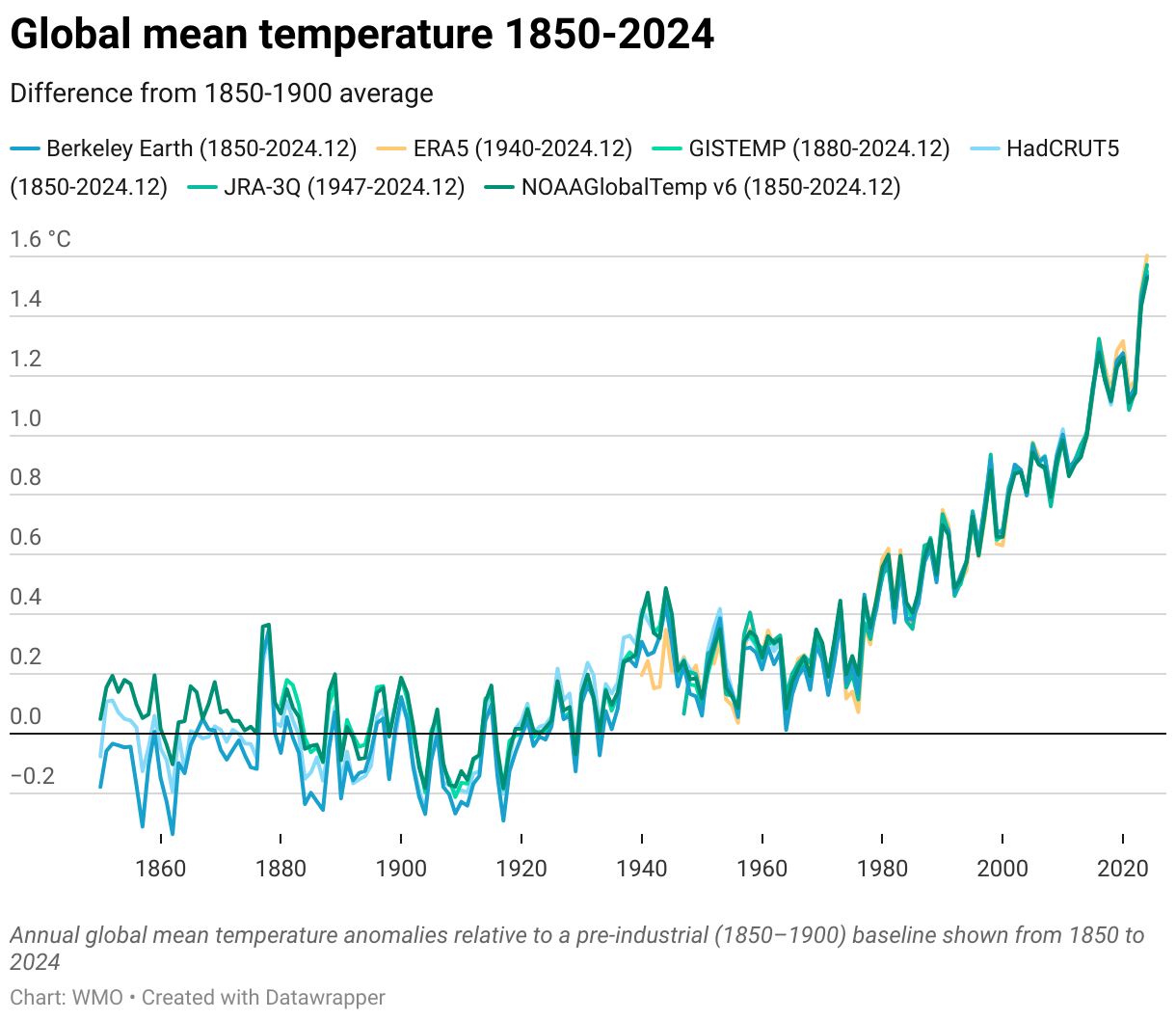
[Read more…] about Melange à TroisThe WMO released its (now) annual state of the climate report this week. As well as the (now) standard set of graphs related to increasing greenhouse gas concentrations, rising temperatures, reducing glacier mass, etc., Zeke Hausfather and I wrote up a short synthesis on the contributions to recent temperature anomalies.
[Read more…] about WMO: Update on 2023/4 AnomaliesGuest commentary by Robert Hart, Kerry Emanuel, & Lance Bosart

The National Weather Service (NWS) and its parent agency, the National Oceanic and Atmospheric
Administration (NOAA), delivers remarkable value to the taxpayers. This efficiency can be demonstrated by its enormous return on investment. For example, the NWS costs only several dollars per citizen to operate each year, yet results in an estimated 10-100 times larger financial return that includes: improved citizen preparedness, improved transportation efficiency and safety, increased private sector profits, improved disaster prevention and mitigation, and impressive scientific research innovation that is significantly also contributed to by other related federal agencies, the private sector, and the academic research community.
Recent NWS initiatives have even more directly connected weather and ocean observations and forecasts to emergency preparation and public impact. To quote a 2019 study referenced below, “Partnership with the NWS has revolutionized this Emergency Management community from on that reacts to events to one that proactively prepares and stays ahead of the extreme events.” The societal benefits of reasonably predicting the future cannot be understated, and such prediction and resulting benefits were unimaginable only 75 years ago.
Critical taxpayer-funded investments over the past decades have led to greatly improved weather forecast models, observations from the ocean, ground, aircraft, and space, and theoretical understanding through scientific research. These all have had an enormous impact on lives and property. The forecasts and associated critical watches and warnings we see every day on television, the internet, or phone apps could not be possible without NOAA and the NWS. It is estimated that the tax revenue generated from the private sector using NOAA data and services easily pays for the entire cost of the NWS.
Those who remember weather forecasts from the 1970s through 1980s can appreciate these dramatic evolutionary improvements given how inferior those forecasts were compared to today. Going further back, landfalling hurricanes in the first half of that century often came with no warning. If you read newspaper front pages from the mornings of September 7, 1900, or September 21, 1938, you will find there is no mention of the historic and catastrophic events about to unfold only hours later. This would be unthinkable today given the scientific investments we have paid for.
These massive improvements extend beyond hurricane (and also snowstorm) forecasting and preparedness. Tornado warning lead time has also improved markedly during the same time period. Casualty rates from tornadoes have not increased despite a very rapid increase in population. At minimum, hundreds of thousands of people are alive today who would not be without our investments in NOAA and NWS.
The advent of skillful weather forecasting, along with the increased preparedness it allows, remains a landmark achievement of not only this country but of the human race. There are few other fields in the sciences where skillful prediction not only has had immense impact on our society, but is even possible. We should be extraordinarily proud of this achievement.
The current expulsion of primarily younger NOAA employees without cause and with disturbingly short notice is cruel to them personally and professionally. The youngest employees are the future of any organization, government or otherwise, and bring with them unique energy, skills, and ideas. Every government organization should strive to become more efficient, and must be subjected to careful oversight, since taxpayer funding is precious and entrusted to the government by the people. However, the instrument of wise oversight is the scalpel, not the chainsaw. The recent seemingly arbitrary and capricious reductions, notably made without Congressional oversight, are seriously jeopardizing the future of the country and more generally the property and lives of hundreds of millions of tax-paying families who have invested in these truly remarkable achievements over many decades.
References:
“Evolving the National Weather Service to Build a Weather-Ready Nation: Connecting
Observations, Forecasts, and Warnings to Decision-Makers through Impact-Based Decision
Support Services”, Bulletin of the American Meteorological Society, October 2019.
“Using the National Weather Service’s impact-based decision support services to prepare for
extreme winter storms“, Journal of Emergency Management, November/December 2019.
“Impact-Based Decision Support Services (IDSS) and Socioeconomic Impacts of Winter Storms”,
Bulletin of the American Meteorological Society, May 2020.
“Communicating Forecast Uncertainty (CoFU) 2: Replication and Extension of a Survey of the US
Public’s Sources, Perceptions, Uses, and Values for Weather Information.” American
Meteorological Society Policy Program Study, September 2024.
“The Social Value of Hurricane Forecasts”, SSRN Journal, December 2024.
{kind=link}